


We all love stories. We like to sit by the fire and talk about our past victories, battles, or just about our work experience.
Today is just such a day. And even if you are not at the fire now, but we have a story for you. The story of how we started working with storage on Tarantool.
Once upon a time, our company had a couple of "monoliths" and one "ceiling" for all, to which these monoliths were slowly but surely approaching, limiting the flight of our company, our development. And there was an unequivocal understanding: one day we will hit hard against this ceiling.
It is now that we are dominated by the ideology of separating everything and everything, from equipment to business logic. As a result, we, for example, have two DCs that are practically independent at the network level. And then everything was completely different.
To date, there are a lot of tools and tools for making changes in the form of CI / CD, K8S, etc. In the "monolithic" time, we did not need so many foreign words. It was enough just to fix the “store” in the database.
But time went on, and the number of requests went along with it, shooting RPS sometimes beyond our capabilities. With the entry into the market of the CIS countries, the load on the database processor of the first monolith did not fall below 90%, and the RPS remained at the level of 2400. And these were not just small selects, but hefty queries with a bunch of checks and JOINs that could almost run through half of the data against the background of large IO.
When full-fledged sales for Black Friday began to appear on the scene - and Wildberries began to hold them one of the first in Russia - the situation became completely sad. After all, the load on such days increases three times.
Oh, those "monolithic times"! I am sure that you have experienced the same, and still cannot understand how this could happen to you.
What can you do - fashion is inherent in technology. About 5 years ago, we had to rethink one of these mods in the form of an existing site on .NET and MS SQL server, which carefully stored all the logic of the site itself. He kept it so carefully that sawing such a monolith turned out to be a long and not at all an easy pleasure.
A small digression.
At various events, I say: “if you didn’t saw the monolith, then you didn’t grow!” Interested in your opinion on this matter, write it, please, in the comments.
A Sound of Thunder
Let's go back to our "bonfire". To distribute the load of "monolithic" functionality, we decided to divide the system into microservices based on open source technologies. Because, at least, their scaling is cheaper. And we had a 100% understanding that we would have to scale (and a lot). After all, already at that time it was possible to enter the markets of neighboring countries, and the number of registrations, as well as the number of orders, began to grow even stronger.
After analyzing the first applicants for departure from the monolith to microservices, we realized that in 80% of them, writing to them is 99% from back office systems, and reading from the front office. First of all, this concerned a couple of subsystems that are important for us - user data and a system for calculating the final cost of goods based on information about additional client discounts and coupons.
As a retreat. Now it’s scary to imagine, but in addition to the above-mentioned subsystems, product catalogs, a user basket, a product search system, a product catalog filtering system and various recommender systems were also taken out of our monolith. For the work of each of them, there are separate classes of narrowly sharpened systems, but once they all lived in the same “house”.
We immediately planned to transfer data about our clients to a sharded system. The removal of the functionality for calculating the final cost of goods required good read scalability, because it created the greatest load on RPS and was the most difficult to execute for the database (a lot of data is involved in the calculation process).
As a result, we have a scheme that fits well with Tarantool.
At that time, schemes for working with several data centers on virtual and hardware machines were chosen for the operation of microservices. As shown in the figures, Tarantool replication options were applied both in master-master and master-slave modes.
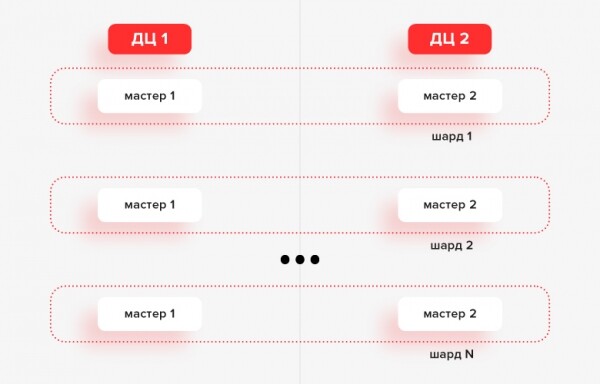
Architecture. Option 1. User service
At the current time, this is 24 shards, each of which has 2 instances (one for each DC), all in master-master mode.
On top of the database are applications that access replicas of the database. Applications work with Tarantool through our custom library that implements the Tarantool Go driver interface. She sees all the replicas and can work with the master for reading and writing. In essence, it implements the replica set model, to which the logic of replica selection, retries, circuit breaker and rate limit is added.
At the same time, it is possible to configure the replica selection policy in the context of the shard. For example, roundrobin.

Architecture. Option 2. Service for calculating the final cost of goods
A few months ago, most of the requests for calculating the final cost of goods went to a new service that, in principle, works without databases, but some time ago, all 100% was processed by the service with Tarantool under the hood.
The service database is 4 masters into which the synchronizer collects data, and each of these replication masters distributes data to readonly replicas. Each master has approximately 15 such replicas.
What is in the first, what is in the second scheme, if one DC is unavailable, the application can receive data in the second.
It should be noted that replication in Tarantool is quite flexible and is configured at runtime. Difficulties have occurred in other systems. For example, changing the max_wal_senders and max_replication_slots parameters in PostgreSQL requires restarting the master, which in some cases may lead to a disconnection between the application and the DBMS.
Search and find!
Why didn’t we do it “like normal people”, but chose an atypical way? Depending on what is considered normal. Many generally make a cluster from Mongo and spread it across three geo-distributed DCs.
At that time, we already had two projects on Redis. The first is a cache, and the second was a persistent storage for not too critical data. It was quite difficult with him, partly due to our fault. Sometimes quite large volumes were in the key, and from time to time the site became ill. We used this system in the master-slave version. And there were many cases when something happened to the master and replication broke.
That is, Redis is good for stateless tasks, not stateful. In principle, it allowed solving most problems, but only if they were key-value solutions with a couple of indices. But Redis at that time was pretty sad with persistence and replication. In addition, there were complaints about performance.
We thought about MySQL and PostgreSQL. But the first one somehow did not take root with us, and the second one is a rather sophisticated product in itself, and it would be impractical to build simple services on it.
We tried RIAK, Cassandra, even a graph database. All these are quite niche solutions that were not suitable for the role of a general universal tool for creating services.
Ultimately, we settled on Tarantool.
We reached out to him when he was in version 1.6. We were interested in the symbiosis of key-value and relational database functionality in it. There are secondary indexes, transactions and spaces, it's like tablets, but not simple, you can store a different number of columns in them. But Tarantool's killer features were secondary indexes combined with key-value and transactionality.
The responsive Russian-speaking community, ready to help in the chat, also played a role. We actively used it and lived directly in the chat. And do not forget about decent persistent without obvious blunders and jambs. If you look at our history with Tarantool, we had a lot of pain and mess with replication, but we never lost data through its fault!
Implementation started hard
At that time, our main development stack was .NET, to which there was no connector for Tarantool. We immediately started doing something in Go. Lua worked well too. The main problem at that time was with debugging: in .NET everything is great with this, and after that it was difficult to plunge into the world of embedded Lua, when you have no debugging except logs. In addition, for some reason, replication periodically fell apart, I had to delve into the structure of the Tarantool engine. The chat helped with this, to a lesser extent - the documentation, sometimes they looked at the code. At that time, the documentation was so-so.
So, within a few months, I managed to get some bumps and get decent results when working with Tarantool. We formalized reference developments in git that helped with the development of new microservices. For example, when the task arose: to make another microservice, the developer looked at the source code of the reference solution in the repository, and it took no more than a week to create a new one.
Those were special times. Conventionally, then it was possible to approach the administrator at the next table and ask: "Give me a virtual machine." Thirty minutes later the car was already with you. You connected yourself, installed everything, and you got traffic to it.
Today, this will no longer work: you need to wind up monitoring, logging on the service, cover functionality with tests, order a virtual machine or delivery to Kuber, etc. In general, it will be better, although longer and more troublesome.
Divide and rule. How is it with Lua?
There was a serious dilemma: some teams could not reliably roll out changes to a service with a lot of logic in Lua. Often this was accompanied by the inoperability of the service.
That is, the developers are preparing some kind of change. Tarantool starts migrating, and the replica is still with the old code; some DDL arrives there via replication, or something else, and the code simply falls apart, because this is not taken into account. As a result, the update procedure for the admins was scheduled on sheet A4: stop replication, update this, enable replication, turn it off here, update there. Nightmare!
As a result, now we most often try to do nothing in Lua. Just using iproto (a binary protocol for interacting with the server), and that's it. Perhaps this is a lack of knowledge among developers, but from this point of view, the system is complex.
We do not always blindly follow this scenario. Today we don't have black and white: either everything is in Lua, or everything is in Go. We already understand how you can combine them so that you don’t get problems with migration later.
Where is Tarantool now?
Tarantool is used in the service for calculating the final cost of goods, taking into account discount coupons, aka "Promoter". As I said earlier, now he is retiring: he is being replaced by a new catalog service with pre-calculated prices, but six months ago all calculations were made in the Promoter. Previously, half of its logic was written in Lua. Two years ago, a storage was made from the service, and the logic was rewritten in Go, because the mechanics of how discounts work changed a bit and the service lacked performance.
One of the most critical services is the user profile. That is, all Wildberries users are stored in Tarantool, and there are about 50 million of them. A system sharded by user ID, spaced across several DCs with binding on Go-services.
In terms of RPS, "Promotizer" was once the leader, it reached 6 thousand requests. At some point we had 50-60 copies. Now the leader in RPS is user profiles, about 12. This service uses custom sharding with splitting into user ID ranges. The service serves more than 20 machines, but this is too much, we plan to reduce the allocated resources, because 4-5 machines are enough for it.
The session service is our first service on vshard and Cartridge. Setting up vshard and updating Cartridge required some work from us, but in the end everything worked out.
The service for displaying different banners on the website and in the mobile application was one of the first ones released immediately on Tarantool. This service is notable for the fact that it is 6-7 years old, it is still in service and has never rebooted. Master-master replication was used. Nothing ever broke.
There is an example of using Tarantool for the functionality of quick lookups in a warehouse system to quickly double-check information in some cases. We tried to use Redis for this, but the data in memory took up more space than Tarantool.
Waitlist services, customer subscriptions, trendy stories and pending products also work with Tarantool. The last service in memory is about 120 GB. This is the largest service of the above.
Conclusion
Thanks to secondary indexes, combined with key-value and transactionality, Tarantool is great for microservice-based architectures. However, we encountered difficulties when rolling out changes to services with a lot of logic in Lua - services often stopped working. We failed to defeat this, and over time we came to different combinations of Lua and Go: we know where to use one language, and where to use another.
What else to read on the topic
- Creating a highly loaded Tarantool application from scratch
- Reliable leader choice in Tarantool Cartridge
- Tarantool Telegram channel with product news
- Discuss Tarantool in the community chat
Source: habr.com
