

Many people are familiar with the PostgreSQL DBMS, and it has proven itself well in small installations. However, the trend towards Open Source has become increasingly clear, even when it comes to large companies and enterprise requirements. In this article, we will describe how to integrate Postgres into a corporate environment and share our experience in creating a backup system (BMS) for this database using the Commvault backup system as an example.

PostgreSQL has already proven its worth - it works great, it's used by trendy digital businesses like Alibaba and TripAdvisor, and the lack of royalties makes it a tempting alternative to monsters like MS SQL or Oracle DB. But as soon as we start thinking about PostgreSQL in the Enterprise landscape, we immediately run into tough requirements: “But what about configuration fault tolerance? disaster tolerance? where is comprehensive monitoring? What about automated backups? What about using tape libraries both directly and on secondary storage?”
On the one hand, PostgreSQL does not have built-in backup tools, like "adult" RMAN-type DBMS from Oracle DB or SAP Database Backup. On the other hand, vendors of corporate backup systems (Veeam, Veritas, Commvault), although they support PostgreSQL, actually work only with a certain (usually standalone) configuration and with a set of various restrictions.
PostgreSQL-specific backup systems such as Barman, Wal-g, and pg_probackup are extremely popular in small PostgreSQL installations or where heavy backups of other IT landscape elements are not required. For example, in addition to PostgreSQL, the infrastructure may include physical and virtual servers, OpenShift, Oracle, MariaDB, Cassandra, etc. It's best to back up all of these using a common backup tool. Deploying a separate solution exclusively for PostgreSQL is a bad idea: the data will be copied to disk somewhere, and then need to be moved to tape. This duplication of backups increases backup time and, more critically, recovery time.
In an enterprise solution, installation backup occurs with a certain number of nodes of a dedicated cluster. At the same time, for example, Commvault can only work with a two-node cluster, in which Primary and Secondary are rigidly assigned to certain nodes. Yes, and it makes sense to back up only with Primary, because backup with Secondary has its limitations. Due to the peculiarities of the DBMS, a dump is not created on Secondary, and therefore only the possibility of a file backup remains.
To reduce the risk of downtime, when creating a fault-tolerant system, a "live" cluster configuration is formed, and Primary can be gradually migrated between different servers. For example, the Patroni software itself launches Primary on a randomly selected cluster node. The RMS has no way to keep track of this "out of the box", and if the configuration changes, the processes break. That is, the introduction of external control prevents the RMS from working effectively, because the control server simply does not understand where and what data needs to be copied.
Another problem is the implementation of backup in Postgres. It is possible via dump, and it works on small bases. But in large databases, dumping takes a long time, requires a lot of resources, and can lead to a failure of the database instance.
A file backup corrects the situation, but on large databases it is slow because it works in single-threaded mode. In addition, vendors have a number of additional restrictions. Either you cannot use file and dump backups at the same time, or deduplication is not supported. There are many problems, and most often it is easier to choose an expensive, but proven DBMS instead of Postgres.
There is nowhere to retreat! Behind Moscow developers!
However, recently our team faced a difficult challenge: in the project of creating AIS OSAGO 2.0, where we made the IT infrastructure, the developers chose PostgreSQL for the new system.
It is much easier for large software developers to use "fashionable" open-source solutions. In the state of the same Facebook, there are enough specialists who support the work of this DBMS. And in the case of the RSA, all the tasks of the “second day” fell on our shoulders. We were required to provide fault tolerance, build a cluster and, of course, set up backups. The logic of actions was as follows:
- Teach SRK to make a backup from the Primary node of the cluster. To do this, the RMS must find it, which means that integration with one or another PostgreSQL cluster management solution is needed. In the case of the PCA, the Patroni software was used for this.
- Decide on the type of backup based on the amount of data and recovery requirements. For example, when it is necessary to restore pages granularly, use a dump, and if the databases are large and granular restoration is not required, work at the file level.
- Attach the possibility of a block backup to the solution in order to create a backup copy in multi-threaded mode.
At the same time, initially we set out to create an effective and simple system without monstrous strapping from additional components. The fewer crutches, the less the burden on the staff and the lower the risk of failure of the IBS. We immediately ruled out approaches that used Veeam and RMAN, because a set of two solutions already hints at the unreliability of the system.
A bit of magic for the enterprise
So, we needed to guarantee reliable backup for 10 clusters of 3 nodes each, while the same infrastructure is mirrored in the backup data center. Data centers in terms of PostgreSQL work on the active-passive principle. The total volume of the databases was 50 TB. Any corporate-level RMS can easily handle this. But the nuance is that initially in Postgres there is no hook for full and deep compatibility with backup systems. Therefore, we had to look for a solution that initially has the maximum functionality in conjunction with PostgreSQL, and refine the system.
We held 3 internal "hackathons" - we reviewed more than fifty developments, tested them, made changes in connection with our hypotheses, and checked again. After analyzing the available options, we chose Commvault. This product already "out of the box" could work with the simplest PostgreSQL cluster installation, and its open architecture gave rise to hope (which came true) for successful refinement and integration. Commvault can also back up PostgreSQL logs. For example, Veritas NetBackup in the PostgreSQL part can only do full backups.
More about architecture. Commvault management servers were installed in each of the two data centers in a CommServ HA configuration. The system is mirrored, managed through one console, and from the point of view of HA meets all the requirements of the enterprise.
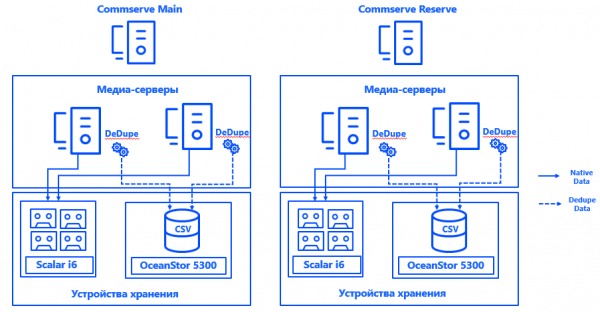
We also launched two physical media servers in each data center, to which we connected disk arrays and tape libraries dedicated specifically for backups via SAN via Fiber Channel. Extended deduplication databases ensured the fault tolerance of media servers, and the connection of each server to each CSV ensured the possibility of continuous operation in case of failure of any component. The architecture of the system allows backups to continue even if one of the data centers fails.
Patroni defines a Primary node for each cluster. It can be any free node in the data center - but only in the main. In the backup, all nodes are Secondary.
To ensure Commvault understands which cluster node is the primary, we integrated the system (thanks to the solution's open architecture) with Postgres. For this purpose, we created a script that reports the current location of the primary node to the manager. server Commvault.
In general, the process looks like this:
Patroni selects Primary → Keepalived raises the IP cluster and runs the script → the Commvault agent on the selected node of the cluster receives a notification that this Primary → Commvault automatically reconfigures the backup within the pseudo-client.
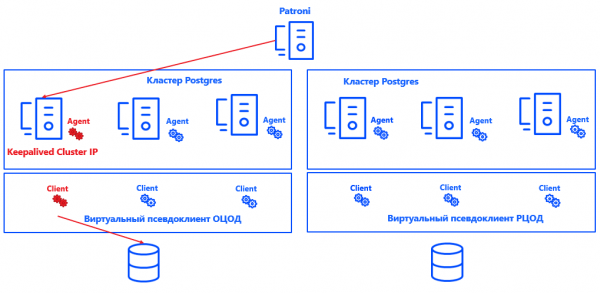
The advantage of this approach is that the solution does not affect either the consistency or the correctness of the logs, or the restoration of the Postgres instance. It also scales easily, because it is no longer necessary to fix for the Commvault Primary and Secondary nodes. It is enough that the system understands where Primary is, and the number of nodes can be increased to almost any value.
The solution does not claim to be ideal and has its own nuances. Commvault can only back up an entire instance, not individual databases. Therefore, a separate instance has been created for each database. Real clients are grouped into virtual pseudo-clients. Each Commvault pseudo-client is a UNIX cluster. The cluster nodes that have the Commvault agent for Postgres installed are added to it. As a result, all virtual nodes of the pseudo-client are backed up as one instance.
Within each pseudo-client, the active node of the cluster is indicated. This is exactly what our integration solution for Commvault defines. The principle of its operation is quite simple: if a cluster IP rises on a node, the script sets the “active node” parameter in the Commvault agent binary - in fact, the script puts “1” in the right part of the memory. The agent sends this data to CommServe, and Commvault makes a backup from the desired node. In addition, the correctness of the configuration is checked at the script level, helping to avoid errors when starting a backup.
At the same time, large databases are backed up blockwise in several streams, meeting the requirements of the RPO and the backup window. The load on the system is insignificant: Full copies do not occur so often, on other days only logs are collected, and during periods of low load.
By the way, we applied separate policies for backing up PostgreSQL archived logs - they are stored according to different rules, copied according to a different schedule, and deduplication is not enabled for them, since these logs carry unique data.
To ensure the consistency of the entire IT infrastructure, separate Commvault file clients are installed on each of the cluster nodes. They exclude Postgres files from backups and are intended only for OS and application backups. This part of the data also has its own policy and its own storage period.

Currently, RMS does not affect productive services, but if the situation changes, it will be possible to enable a load limiting system in Commvault.
Is it okay? Good!
So, we got not just a workable, but also a fully automated backup for a PostgreSQL cluster installation, which meets all the requirements of enterprise calls.
The RPO and RTO parameters at 1 hour and 2 hours are overlapped with a margin, which means that the system will comply with them even with a significant increase in the volume of stored data. Contrary to many doubts, PostgreSQL and the enterprise environment turned out to be quite compatible. And now we know from our own experience that backup for such DBMS is possible in a wide variety of configurations.
Of course, on this path we had to wear out seven pairs of iron boots, overcome a number of difficulties, step on a few rakes and correct a number of mistakes. But now the approach has already been tested and can be used to implement Open Source instead of proprietary DBMS in the harsh environment of the enterprise.
Have you tried working with PostgreSQL in a corporate environment?
Authors:
Oleg Lavrenov, Data Storage Systems Design Engineer, Jet Infosystems
Dmitry Erykin, Design Engineer of Jet Infosystems Computing Systems
Source: habr.com
