

Hey Habr!
In this article, we would like to talk about network infrastructure automation. A working diagram of a network that operates in one small but very proud company will be presented. All matches with real network equipment are random. We will consider a case that occurred in this network, which could lead to a business stoppage for a long time and serious financial losses. The solution of this case fits very well into the concept of "Network Infrastructure Automation". With the help of automation tools, we will show how you can effectively solve complex problems in a short time, and reflect on why these tasks should be solved more promisingly in this way and not otherwise (via the console).
Disclaimer
Our primary automation tools are Ansible (as an automation engine) and Git (as a repository for Ansible playbooks). I'd like to point out right away that this isn't an introductory article where we discuss the logic behind Ansible or Git and explain basic concepts (for example, what roletasks, modules, inventory files, and variables are in Ansible, or what happens when you enter the git push or git commit commands). This isn't a story about practicing Ansible or setting up NTP or SMTP on your equipment. This is a story about how to quickly and, hopefully, error-freely resolve a network issue. It's also helpful to have a good understanding of how networks work, particularly what a protocol stack is. TCP/IP, OSPF, BGP. We'll also leave Ansible and Git out of the equation. If you're still deciding on a specific solution, we highly recommend reading "Network Programmability and Automation: Skills for the Next-Generation Network Engineer" by Jason Edelman, Scott S. Lowe, and Matt Oswalt.
Now to the point.
Formulation of the problem
Let's imagine the situation: 3 o'clock in the morning, you are fast asleep and dreaming. Phone call. CTO calls:
- Yes?
— ###, ####, #####, the firewall cluster has fallen and is not rising!!!
You rub your eyes, trying to comprehend what is happening and imagine how this could have happened. In the receiver you can hear how the hair on the head of the director is torn, and he asks to call back, because the general is calling him on the second line.
Half an hour later, you collected the first input from the shift on duty, woke up everyone who could be woken up. As a result, the technical director did not lie, everything is true, the main cluster of firewalls fell, and no basic gestures bring him to his senses. All the services offered by the company do not work.
Choose a problem to your taste, everyone will remember something different. For example, after a nightly update, in the absence of a heavy load, everything worked well, and everyone went to sleep happy. Traffic began to overflow, and interface buffers began to overflow due to a bug in the network card driver.
The situation can be well described by Jackie Chan.

Thank you Jackie
Not a very pleasant situation, is it?
Let's leave for a while our network bro with his sad thoughts.
Let's discuss how events will develop further.
We propose the following order of presentation
- Consider the network diagram and see how it works;
- Let's describe how we transfer settings from one router to another using Ansible;
- Let's talk about the automation of IT infrastructure in general.
Network diagram and description
scheme
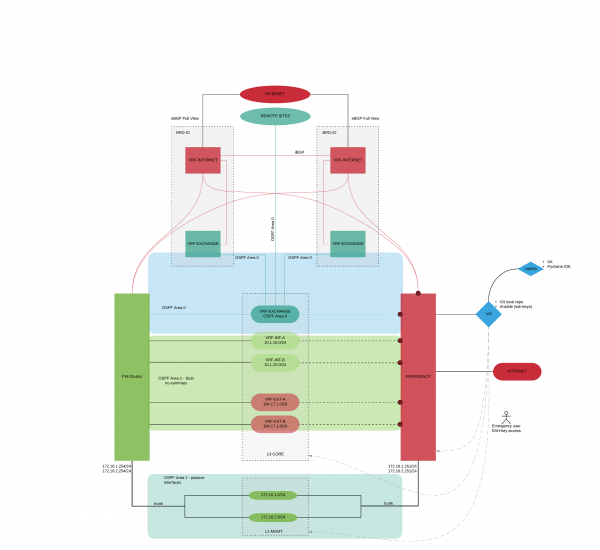
Consider the logical scheme of our organization. We will not name specific equipment manufacturers, it does not matter within the framework of the article. (Attentive reader will guess what kind of equipment is used). This is just one of the good advantages of working with Ansible, when setting up, we generally don’t care what kind of equipment it is. Just for understanding, this is equipment from well-known vendors, such as Cisco, Juniper, Check Point, Fortinet, Palo Alto ... you can substitute your own option.
We have two main tasks for moving traffic:
- Ensure the publication of our services, which are the company's business;
- Provide communication with branches, a remote data center and third-party organizations (partners and clients), as well as Internet access for branches through the central office.
Let's start with the basic elements:
- Two border routers (BRD-01, BRD-02);
- Firewall cluster (FW-CLUSTER);
- Core switch (L3-CORE);
- A router that will become a lifeline (as we solve the problem, we will transfer the network settings from FW-CLUSTER to EMERGENCY) (EMERGENCY);
- Switches for network infrastructure management (L2-MGMT);
- Virtual machine with Git and Ansible (VM-AUTOMATION);
- A laptop used for testing and developing playbooks for Ansible (Laptop-Automation).
The network has a dynamic OSPF routing protocol configured with the following areas:
- Area 0 - the area that includes routers responsible for moving traffic in the EXCHANGE zone;
- Area 1 - the area that includes routers responsible for the operation of the company's services;
- Area 2 - the area that includes routers responsible for routing management traffic;
- Area N - areas of branch networks.
On border routers, a virtual router (VRF-INTERNET) is created, on which eBGP full view is raised with the corresponding assigned AS. iBGP is configured between VRFs. The company has a pool of white addresses that are published on these VRF-INTERNETs. Some of the white addresses are routed directly to the FW-CLUSTER (addresses where the company's services are running), some are routed through the EXCHANGE zone (internal company services that require external IP addresses, and external NAT addresses for offices). Then the traffic goes to virtual routers created on L3-CORE with white and gray addresses (security zones).
The Management network uses dedicated switches and represents a physically dedicated network. The Management network is also divided into security zones.
The EMERGENCY router physically and logically duplicates the FW-CLUSTER. All interfaces are disabled on it except for those that look into the management network.
Automation and its description
We figured out how the network works. Now let's take a look at the steps, what we will do to transfer traffic from FW-CLUSTER to EMERGENCY:
- Disable the interfaces on the core switch (L3-CORE) that connect it to the FW-CLUSTER;
- We disable the interfaces on the L2-MGMT core switch that connect it to the FW-CLUSTER;
- We configure the EMERGENCY router (by default, all interfaces are disabled on it, except for those associated with L2-MGMT):
- Enable interfaces on EMERGENCY;
- We configure the external ip-address (for NAT) that was on the FW-Cluster;
- We generate gARP requests so that poppy addresses change from FW-Cluster to EMERGENCY in the L3-CORE arp tables;
- We prescribe the default route with statics to BRD-01, BRD-02;
- Create NAT rules;
- We raise to EMERGENCY OSPF Area 1;
- We raise to EMERGENCY OSPF Area 2;
- Change the cost of routes in Area 1 to 10;
- Change the cost of the default route in Area 1 to 10;
- Changing IP addresses, related to L2-MGMT (those that were on FW-CLUSTER);
- We generate gARP requests so that poppy addresses change from FW-CLUSTER to EMERGENCY in the L2-MGMT arp tables.
Again, we return to the original formulation of the problem. Three in the morning, a lot of stress, a mistake at any stage can lead to new problems. Ready to type commands through the CLI? Yes? Ok, go at least rinse your face, drink coffee and gather your will into a fist.
Bruce, please help the guys.

Well, we continue to saw our automation.
Below is a diagram of how a playbook works in terms of Ansible. This scheme reflects what we described just above, just a specific implementation in Ansible.
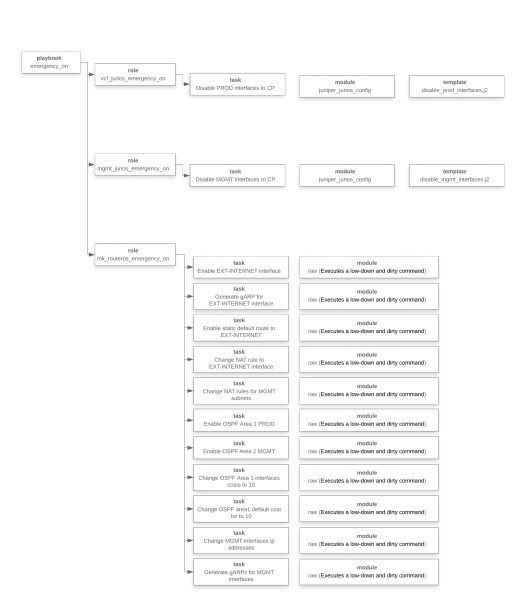
At this stage, we realized what needs to be done, developed the playbook, tested it, and now we are ready to launch it.
Another small lyrical digression. The ease of narration should not mislead you. The process of writing playbooks was not as simple and fast as it might seem. Testing took quite a long time, a virtual stand was created, the solution was tested many times, about 100 tests were carried out.
We are launching ... There is a feeling that everything is happening very slowly, somewhere there is an error, something will not work in the end. The feeling of a parachute jump, but the parachute does not want to open right away ... this is normal.
Next, we read the result of the performed operations of the Ansible playbook (ip-addresses have been replaced for the purpose of secrecy):
[xxx@emergency ansible]$ ansible-playbook -i /etc/ansible/inventories/prod_inventory.ini /etc/ansible/playbooks/emergency_on.yml
PLAY [------->Emergency on VCF] ********************************************************
TASK [vcf_junos_emergency_on : Disable PROD interfaces to FW-CLUSTER] *********************
changed: [vcf]
PLAY [------->Emergency on MGMT-CORE] ************************************************
TASK [mgmt_junos_emergency_on : Disable MGMT interfaces to FW-CLUSTER] ******************
changed: [m9-03-sw-03-mgmt-core]
PLAY [------->Emergency on] ****************************************************
TASK [mk_routeros_emergency_on : Enable EXT-INTERNET interface] **************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Generate gARP for EXT-INTERNET interface] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable static default route to EXT-INTERNET] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change NAT rule to EXT-INTERNET interface] ****************
changed: [m9-04-r-04] => (item=12)
changed: [m9-04-r-04] => (item=14)
changed: [m9-04-r-04] => (item=15)
changed: [m9-04-r-04] => (item=16)
changed: [m9-04-r-04] => (item=17)
TASK [mk_routeros_emergency_on : Enable OSPF Area 1 PROD] ******************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable OSPF Area 2 MGMT] *****************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change OSPF Area 1 interfaces costs to 10] *****************
changed: [m9-04-r-04] => (item=VLAN-1001)
changed: [m9-04-r-04] => (item=VLAN-1002)
changed: [m9-04-r-04] => (item=VLAN-1003)
changed: [m9-04-r-04] => (item=VLAN-1004)
changed: [m9-04-r-04] => (item=VLAN-1005)
changed: [m9-04-r-04] => (item=VLAN-1006)
changed: [m9-04-r-04] => (item=VLAN-1007)
changed: [m9-04-r-04] => (item=VLAN-1008)
changed: [m9-04-r-04] => (item=VLAN-1009)
changed: [m9-04-r-04] => (item=VLAN-1010)
changed: [m9-04-r-04] => (item=VLAN-1011)
changed: [m9-04-r-04] => (item=VLAN-1012)
changed: [m9-04-r-04] => (item=VLAN-1013)
changed: [m9-04-r-04] => (item=VLAN-1100)
TASK [mk_routeros_emergency_on : Change OSPF area1 default cost for to 10] ******************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change MGMT interfaces ip addresses] ********************
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+14.254', u'name': u'VLAN-899'})
TASK [mk_routeros_emergency_on : Generate gARPs for MGMT interfaces] *********************
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+14.254', u'name': u'VLAN-899'})
PLAY RECAP ************************************************************************Done!
In fact, not quite ready, do not forget about the convergence of dynamic routing protocols and loading a large number of routes into the FIB. We cannot influence this in any way. We wait. Agreed. Now it's ready.
And in the village of Vilabagio (which doesn't want to automate the network setup), the dishes continue to be washed. Bruce (albeit different, but no less cool) is trying to figure out how much more to manually reconfigure the equipment.

I would like to dwell on one more important point. How can we get everything back? After some time, we will bring our FW-CLUSTER back to life. This is the main equipment, not backup, the network must work on it.
Do you feel how networkers are starting to burn? The technical director will hear a thousand arguments why this should not be done, why it can be done later. Unfortunately, this is how the network works out of a bunch of patches, pieces, remnants of former luxury. It turns out a patchwork quilt. Our task as a whole, not in this particular situation, but in general in principle, as IT specialists, is to bring the network to the beautiful English word “consistency”, it is very multifaceted, can be translated as: consistency, consistency, consistency, coherence, consistency, comparability, connection. It's all about him. Only in this state is the network manageable, we clearly understand what works and how, we clearly understand what needs to be changed, if necessary, we clearly know where to look in case of problems. And only in such a network is it possible to perform tricks similar to those that we have just described.
Actually, another playbook was prepared, which returned the settings to their original state. The logic of its work is the same (it is important to remember that the order of tasks is very important), in order not to lengthen an already rather long article, we decided not to post a listing of the playbook execution. After conducting such exercises, you will feel much calmer and more confident in the future, in addition, any crutches that you piled up there will immediately reveal themselves.
Anyone can write to us and get the source of all written code, along with all palybooks. Contacts in profile.
Conclusions
In our opinion, processes that can be automated have not yet crystallized. Based on what we have encountered and what our Western colleagues are discussing, the following topics are still visible:
- device provisioning;
- data collection;
- reporting;
- troubleshooting;
- Compliance.
If there is interest, we can continue the discussion on one of the given topics.
I also want to talk a little about automation. What it should be in our understanding:
- The system must live without a person, while being improved by a person. The system should not depend on the person;
- Operation must be expert. There is no class of specialists who perform routine tasks. There are experts who have automated the whole routine and solve only complex tasks;
- Routine standard tasks are done automatically "on a button", no resources are wasted. The result of such tasks is always predictable and understandable.
And what should these points lead to:
- Transparency of IT infrastructure (Less risks of operation, modernization, implementation. Less downtime per year);
- The ability to plan IT resources (Capacity-planning system - you can see how much is consumed, you can see how much resources are required in a single system, and not by letters and going to the tops of departments);
- The ability to reduce the number of IT maintenance staff.
Authors of the article: Alexander Chelovenov (CCIE RS, CCIE SP) and Pavel Kirillov. We are interested in discussing and offering solutions on the subject of IT infrastructure automation.
Source: habr.com
