

In the article I will tell you how we approached the issue of PostgreSQL fault tolerance, why it became important for us and what happened in the end.
We have a highly loaded service: 2,5 million users worldwide, 50K+ active users every day. The servers are located in Amazone in one region of Ireland: 100+ different servers are constantly in operation, of which almost 50 are with databases.
The entire backend is a large monolithic stateful Java application that keeps a constant websocket connection with the client. When several users work on the same board at the same time, they all see the changes in real time, because we write each change to the database. We have about 10K requests per second to our databases. At peak load in Redis, we write 80-100K requests per second.
Why we switched from Redis to PostgreSQL
Initially, our service worked with Redis, a key-value store that stores all data in RAM. Server.
Pros of Redis:
- High response speed, because everything is stored in memory;
- Ease of backup and replication.
Cons of Redis for us:
- There are no real transactions. We tried to simulate them at the level of our application. Unfortunately, this did not always work well and required writing very complex code.
- The amount of data is limited by the amount of memory. As the amount of data increases, the memory will grow, and, in the end, we will run into the characteristics of the selected instance, which in AWS requires stopping our service to change the type of instance.
- It is necessary to constantly maintain a low latency level, because. we have a very large number of requests. The optimal delay level for us is 17-20 ms. At a level of 30-40 ms, we get long responses to requests from our application and degradation of the service. Unfortunately, this happened to us in September 2018, when one of the instances with Redis for some reason received latency 2 times more than usual. To resolve the issue, we stopped the service mid-day for unscheduled maintenance and replaced the problematic Redis instance.
- It is easy to get data inconsistency even with minor errors in the code and then spend a lot of time writing code to correct this data.
We took into account the cons and realized that we needed to move to something more convenient, with normal transactions and less dependence on latency. Conducted research, analyzed many options and chose PostgreSQL.
We have been moving to a new database for 1,5 years already and have moved only a small part of the data, so now we are working simultaneously with Redis and PostgreSQL. More information about the stages of moving and switching data between databases is written in my colleague's article.
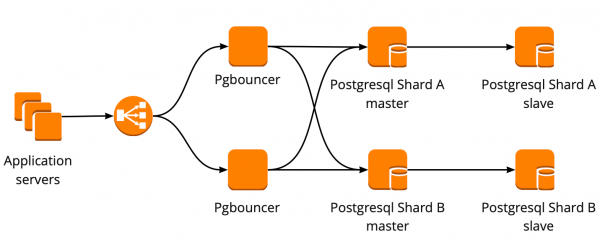
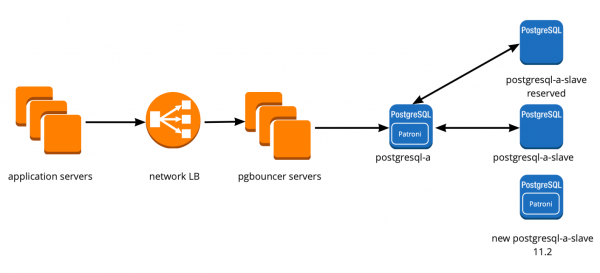
When we first started moving, our application worked directly with the database and accessed the master Redis and PostgreSQL. The PostgreSQL cluster consisted of a master and a replica with asynchronous replication. This is how the database scheme looked like:
Implementing PgBouncer
While we were moving, the product was also developing: the number of users and the number of servers that worked with PostgreSQL increased, and we began to lack connections. PostgreSQL creates a separate process for each connection and consumes resources. You can increase the number of connections up to a certain point, otherwise there is a chance to get suboptimal database performance. The ideal option in such a situation would be to choose a connection manager that will stand in front of the base.
We had two options for the connection manager: Pgpool and PgBouncer. But the first one does not support the transactional mode of working with the database, so we chose PgBouncer.
We have set up the following scheme of work: our application accesses one PgBouncer, behind which are PostgreSQL masters, and behind each master is one replica with asynchronous replication.
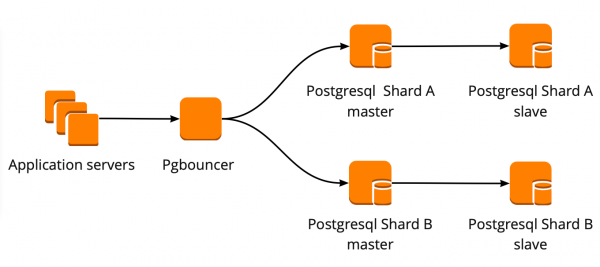
At the same time, we could not store the entire amount of data in PostgreSQL and the speed of working with the database was important for us, so we started sharding PostgreSQL at the application level. The scheme described above is relatively convenient for this: when adding a new PostgreSQL shard, it is enough to update the PgBouncer configuration and the application can immediately work with the new shard.
PgBouncer failover
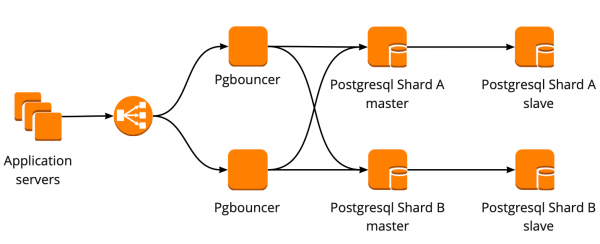
This scheme worked until the moment when the only PgBouncer instance died. We are in AWS, where all instances are running on hardware that dies periodically. In such cases, the instance simply moves to new hardware and works again. This happened with PgBouncer, but it became unavailable. The result of this fall was the unavailability of our service for 25 minutes. AWS recommends using user-side redundancy for such situations, which was not implemented in our country at that time.
After that, we seriously thought about the fault tolerance of PgBouncer and PostgreSQL clusters, because a similar situation could happen with any instance in our AWS account.
We built the PgBouncer fault tolerance scheme as follows: all application servers access the Network Load Balancer, behind which there are two PgBouncers. Each PgBouncer looks at the same PostgreSQL master of each shard. If an AWS instance crash occurs again, all traffic is redirected through another PgBouncer. Network Load Balancer failover is provided by AWS.
This scheme makes it easy to add new PgBouncer servers.
Create a PostgreSQL Failover Cluster
When solving this problem, we considered different options: self-written failover, repmgr, AWS RDS, Patroni.
Self-written scripts
They can monitor the work of the master and, if it fails, promote the replica to the master and update the PgBouncer configuration.
The advantages of this approach are maximum simplicity, because you write scripts yourself and understand exactly how they work.
Cons:
- The master might not have died, instead a network failure might have occurred. Failover, unaware of this, will promote the replica to the master, while the old master will continue to work. As a result, we will get two servers in the role of master and we will not know which of them has the latest up-to-date data. This situation is also called split-brain;
- We were left without a response. In our configuration, the master and one replica, after switching, the replica moves up to the master and we no longer have replicas, so we have to manually add a new replica;
- We need additional monitoring of the failover operation, while we have 12 PostgreSQL shards, which means we have to monitor 12 clusters. With an increase in the number of shards, you must also remember to update the failover.
Self-written failover looks very complicated and requires non-trivial support. With a single PostgreSQL cluster, this would be the easiest option, but it does not scale, so it is not suitable for us.
Repmgr
Replication Manager for PostgreSQL clusters, which can manage the operation of a PostgreSQL cluster. At the same time, it does not have an automatic failover out of the box, so for work you will need to write your own “wrapper” on top of the finished solution. So everything can turn out even more complicated than with self-written scripts, so we didn’t even try Repmgr.
AWS RDS
Supports everything we need, knows how to make backups and maintains a pool of connections. It has automatic switching: when the master dies, the replica becomes the new master, and AWS changes the dns record to the new master, while the replicas can be located in different AZs.
The disadvantages include the lack of fine adjustments. As an example of fine tuning: our instances have restrictions for tcp connections, which, unfortunately, cannot be done in RDS:
net.ipv4.tcp_keepalive_time=10
net.ipv4.tcp_keepalive_intvl=1
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_retries2=3
In addition, AWS RDS is almost twice as expensive as the regular instance price, which was the main reason for abandoning this solution.
owners
This is a python template for managing PostgreSQL with good documentation, automatic failover and source code on github.
Pros of Patroni:
- Each configuration parameter is described, it is clear how it works;
- Automatic failover works out of the box;
- Written in python, and since we ourselves write a lot in python, it will be easier for us to deal with problems and, perhaps, even help the development of the project;
- Fully manages PostgreSQL, allows you to change the configuration on all nodes of the cluster at once, and if the cluster needs to be restarted to apply the new configuration, then this can be done again using Patroni.
Cons:
- It is not clear from the documentation how to work with PgBouncer correctly. Although it’s hard to call it a minus, because Patroni’s task is to manage PostgreSQL, and how connections to Patroni will go is already our problem;
- There are few examples of implementation of Patroni on large volumes, while there are many examples of implementation from scratch.
As a result, we chose Patroni to create a failover cluster.
Patroni Implementation Process
Before Patroni, we had 12 PostgreSQL shards in a configuration of one master and one replica with asynchronous replication. The application servers accessed the databases through the Network Load Balancer, behind which were two instances with PgBouncer, and behind them were all the PostgreSQL servers.
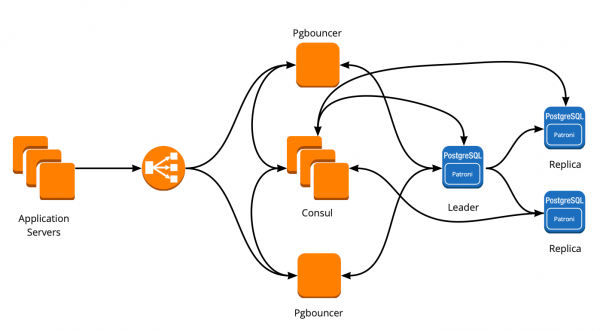
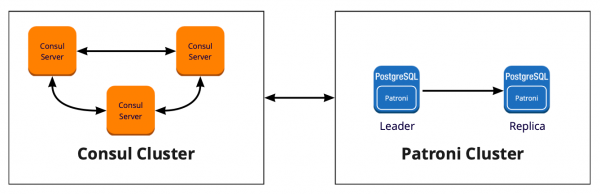
To implement Patroni, we needed to select a distributed storage cluster configuration. Patroni works with distributed configuration storage systems such as etcd, Zookeeper, Consul. We just have a full-fledged Consul cluster on the market, which works in conjunction with Vault and we don’t use it anymore. A great reason to start using Consul for its intended purpose.
How Patroni works with Consul
We have a Consul cluster, which consists of three nodes, and a Patroni cluster, which consists of a leader and a replica (in Patroni, the master is called the cluster leader, and the slaves are called replicas). Each instance of the Patroni cluster constantly sends information about the state of the cluster to Consul. Therefore, from Consul you can always find out the current configuration of the Patroni cluster and who is the leader at the moment.
To connect Patroni to Consul, it is enough to study the official documentation, which says that you need to specify a host in the http or https format, depending on how we work with Consul, and the connection scheme, optionally:
host: the host:port for the Consul endpoint, in format: http(s)://host:port
scheme: (optional) http or https, defaults to httpIt looks simple, but here the pitfalls begin. With Consul, we work over a secure connection via https and our connection config will look like this:
consul:
host: https://server.production.consul:8080
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}But that doesn't work. At startup, Patroni cannot connect to Consul, because it tries to go through http anyway.
The source code of Patroni helped to deal with the problem. Good thing it's written in python. It turns out that the host parameter is not parsed in any way, and the protocol must be specified in scheme. This is how the working configuration block for working with Consul looks like for us:
consul:
host: server.production.consul:8080
scheme: https
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}consul-template
So, we have chosen the storage for the configuration. Now we need to understand how PgBouncer will switch its configuration when changing the leader in the Patroni cluster. There is no answer to this question in the documentation, because. there, in principle, work with PgBouncer is not described.
In search of a solution, we found an article (I unfortunately don’t remember the title) where it was written that Сonsul-template helped a lot in pairing PgBouncer and Patroni. This prompted us to investigate how Consul-template works.
It turned out that Consul-template constantly monitors the configuration of the PostgreSQL cluster in Consul. When the leader changes, it updates the PgBouncer configuration and sends a command to reload it.
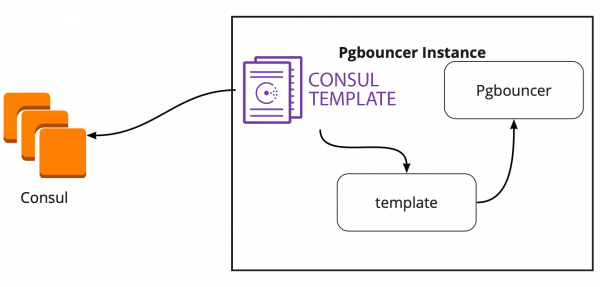
A big plus of template is that it is stored as code, so when adding a new shard, it is enough to make a new commit and update the template automatically, supporting the Infrastructure as code principle.
New architecture with Patroni
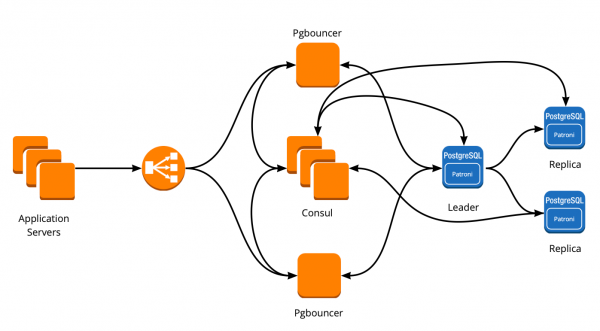
As a result, we got the following scheme of work:
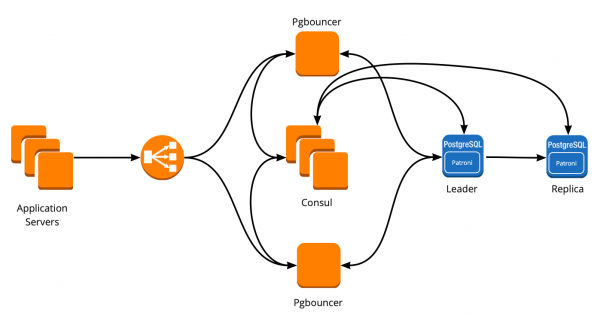
All application servers access the balancer → there are two instances of PgBouncer behind it → on each instance, Consul-template is launched, which monitors the status of each Patroni cluster and monitors the relevance of the PgBouncer config, which sends requests to the current leader of each cluster.
Manual testing
We ran this scheme before launching it on a small test environment and checked the operation of automatic switching. They opened the board, moved the sticker, and at that moment they “killed” the leader of the cluster. In AWS, this is as simple as shutting down the instance via the console.
The sticker returned back within 10-20 seconds, and then again began to move normally. This means that the Patroni cluster worked correctly: it changed the leader, sent the information to Сonsul, and Сonsul-template immediately picked up this information, replaced the PgBouncer configuration and sent the command to reload.
How to survive under high load and keep the downtime minimal?
Everything works perfectly! But there are new questions: How will it work under high load? How to quickly and safely roll out everything in production?
The test environment on which we conduct load testing helps us answer the first question. It is completely identical to production in terms of architecture and has generated test data that is approximately equal in volume to production. We decide to just “kill” one of the PostgreSQL masters during the test and see what happens. But before that, it is important to check the automatic rolling, because on this environment we have several PostgreSQL shards, so we will get excellent testing of configuration scripts before production.
Both tasks look ambitious, but we have PostgreSQL 9.6. Can we immediately upgrade to 11.2?
We decide to do it in 2 steps: first upgrade to 11.2, then launch Patroni.
PostgreSQL update
To quickly update the PostgreSQL version, use the option -k, in which hard links are created on disk and there is no need to copy your data. On bases of 300-400 GB, the update takes 1 second.
We have a lot of shards, so the update needs to be done automatically. To do this, we wrote an Ansible playbook that handles the entire update process for us:
/usr/lib/postgresql/11/bin/pg_upgrade
<b>--link </b>
--old-datadir='' --new-datadir=''
--old-bindir='' --new-bindir=''
--old-options=' -c config_file='
--new-options=' -c config_file='It is important to note here that before starting the upgrade, you must perform it with the parameter —Checkto make sure you can upgrade. Our script also makes the substitution of configs for the duration of the upgrade. Our script completed in 30 seconds, which is an excellent result.
Launch Patroni
To solve the second problem, just look at the Patroni configuration. The official repository has an example configuration with initdb, which is responsible for initializing a new database when you first start Patroni. But since we already have a ready-made database, we simply removed this section from the configuration.
When we started installing Patroni on an already existing PostgreSQL cluster and running it, we ran into a new problem: both servers started as a leader. Patroni knows nothing about the early state of the cluster and tries to start both servers as two separate clusters with the same name. To solve this problem, you need to delete the directory with data on the slave:
rm -rf /var/lib/postgresql/This needs to be done only on the slave!
When a clean replica is connected, Patroni makes a basebackup leader and restores it to the replica, and then catches up with the current state according to the wal logs.
Another difficulty we encountered is that all PostgreSQL clusters are named main by default. When each cluster knows nothing about the other, this is normal. But when you want to use Patroni, then all clusters must have a unique name. The solution is to change the cluster name in the PostgreSQL configuration.
load test
We have launched a test that simulates user experience on boards. When the load reached our average daily value, we repeated exactly the same test, we turned off one instance with the PostgreSQL leader. The automatic failover worked as we expected: Patroni changed the leader, Consul-template updated the PgBouncer configuration and sent a command to reload. According to our graphs in Grafana, it was clear that there are delays of 20-30 seconds and a small amount of errors from the servers associated with the connection to the database. This is a normal situation, such values are acceptable for our failover and are definitely better than the service downtime.
Bringing Patroni to production
As a result, we came up with the following plan:
- Deploy Consul-template to PgBouncer servers and launch;
- PostgreSQL updates to version 11.2;
- Change the name of the cluster;
- Starting the Patroni Cluster.
At the same time, our scheme allows us to make the first point almost at any time, we can remove each PgBouncer from work in turn and deploy and run consul-template on it. So we did.
For quick deployment, we used Ansible, since we have already tested all the playbooks on a test environment, and the execution time of the full script was from 1,5 to 2 minutes for each shard. We could roll out everything in turn to each shard without stopping our service, but we would have to turn off each PostgreSQL for several minutes. In this case, users whose data is on this shard could not fully work at this time, and this is unacceptable for us.
The way out of this situation was the planned maintenance, which takes place every 3 months. This is a window for scheduled work, when we completely shut down our service and upgrade our database instances. There was one week left until the next window, and we decided to just wait and prepare further. During the waiting time, we additionally secured ourselves: for each PostgreSQL shard, we raised a spare replica in case of failure to keep the latest data, and added a new instance for each shard, which should become a new replica in the Patroni cluster, so as not to execute a command to delete data . All this helped to minimize the risk of error.
We restarted our service, everything worked as it should, users continued to work, but on the graphs we noticed an abnormally high load on the Consul servers.
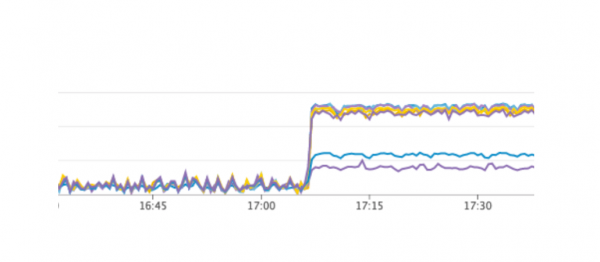
Why didn't we see this in the test environment? This problem illustrates very well that it is necessary to follow the Infrastructure as code principle and refine the entire infrastructure, from test environments to production. Otherwise, it is very easy to get the problem we got. What happened? Consul first appeared on production, and then on test environments, as a result, on test environments, the version of Consul was higher than on production. Just in one of the releases, a CPU leak was solved when working with consul-template. Therefore, we simply updated Consul, thus solving the problem.
Restart Patroni cluster
However, we got a new problem, which we did not even suspect. When updating Consul, we simply remove the Consul node from the cluster using the consul leave command → Patroni connects to another Consul server → everything works. But when we reached the last instance of the Consul cluster and sent the consul leave command to it, all Patroni clusters simply restarted, and in the logs we saw the following error:
ERROR: get_cluster
Traceback (most recent call last):
...
RetryFailedError: 'Exceeded retry deadline'
ERROR: Error communicating with DCS
<b>LOG: database system is shut down</b>The Patroni cluster was unable to retrieve information about its cluster and restarted.
To find a solution, we contacted the Patroni authors via an issue on github. They suggested improvements to our configuration files:
consul:
consul.checks: []
bootstrap:
dcs:
retry_timeout: 8We were able to replicate the problem on a test environment and tested these options there, but unfortunately they didn't work.
The problem still remains unresolved. We plan to try the following solutions:
- Use Consul-agent on each Patroni cluster instance;
- Fix the issue in the code.
We understand where the error occurred: the problem is probably the use of default timeout, which is not overridden through the configuration file. When the last Consul server is removed from the cluster, the entire Consul cluster hangs for more than a second, because of this, Patroni cannot get the status of the cluster and completely restarts the entire cluster.
Fortunately, we did not encounter any more errors.
Results of using Patroni
After the successful launch of Patroni, we added an additional replica in each cluster. Now in each cluster there is a semblance of a quorum: one leader and two replicas, for safety net in case of split-brain when switching.
Patroni has been working on production for more than three months. During this time, he has already managed to help us out. Recently, the leader of one of the clusters died in AWS, automatic failover worked and users continued to work. Patroni fulfilled its main task.
A small summary of the use of Patroni:
- Ease of configuration changes. It is enough to change the configuration on one instance and it will be pulled up to the entire cluster. If a reboot is required to apply the new configuration, then Patroni will let you know. Patroni can restart the entire cluster with a single command, which is also very convenient.
- Automatic failover works and has already managed to help us out.
- PostgreSQL update without application downtime. You must first update the replicas to the new version, then change the leader in the Patroni cluster and update the old leader. In this case, the necessary testing of automatic failover occurs.
Source: habr.com
