

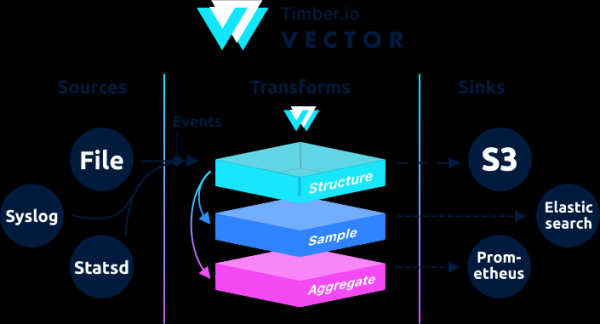
, designed to collect, transform and send log data, metrics and events.
→
Being written in the Rust language, it is characterized by high performance and low RAM consumption compared to its counterparts. In addition, much attention is paid to functions related to correctness, in particular, the ability to save unsent events to a buffer on disk and file rotation.
Architecturally, Vector is an event router that accepts messages from one or more sources of, optionally applying over these messages transformations, and sending them to one or more drains.
Vector is a replacement for filebeat and logstash, it can act in both roles (receive and send logs), more details on them .
If in Logstash the chain is built as input → filter → output, then in Vector it is → →
Examples can be found in the documentation.
This instruction is a revised instruction from . The original instructions have geoip processing. When testing geoip from the internal network, vector gave me an error.
Aug 05 06:25:31.889 DEBUG transform{name=nginx_parse_rename_fields type=rename_fields}: vector::transforms::rename_fields: Field did not exist field=«geoip.country_name» rate_limit_secs=30If someone needs to process geoip, then refer to the original instructions from .
We will configure Nginx (Access logs) → Vector (Client | Filebeat) → Vector (Server | Logstash) → separately in Clickhouse and separately in Elasticsearch. Set up 4 servers. Though it is possible to bypass 3 servers.
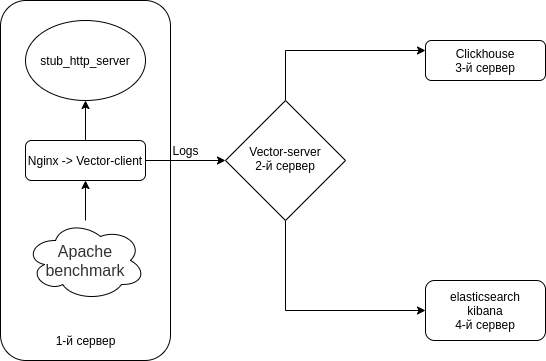
The scheme is something like this.
Turn off Selinux on all your servers
sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
rebootInstall the HTTP server emulator + utilities on all servers
As an HTTP server emulator we will use from
nodejs-stub-server doesn't have rpm. create rpm for it. rpm will be built using
Add antonpatsev/nodejs-stub-server repository
yum -y install yum-plugin-copr epel-release
yes | yum copr enable antonpatsev/nodejs-stub-serverInstall nodejs-stub-server, Apache benchmark and screen terminal multiplexer on all servers
yum -y install stub_http_server screen mc httpd-tools screenCorrected the stub_http_server response time in the /var/lib/stub_http_server/stub_http_server.js file to have more logs.
var max_sleep = 10;Let's start stub_http_server.
systemctl start stub_http_server
systemctl enable stub_http_serveron server 3
ClickHouse uses the SSE 4.2 instruction set, therefore, unless otherwise noted, its support in the processor used becomes an additional system requirement. Here is the command to check if the current processor supports SSE 4.2:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"First you need to connect the official repository:
sudo yum install -y yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64To install packages, run the following commands:
sudo yum install -y clickhouse-server clickhouse-clientWe allow clickhouse-server to listen to the network card in the /etc/clickhouse-server/config.xml file
<listen_host>0.0.0.0</listen_host>Change the logging level from trace to debug
debugging
Compression settings are standard:
min_compress_block_size 65536
max_compress_block_size 1048576To activate Zstd waiting, the config was advised not to be touched, but it is better to use DDL.
I did not find how to apply zstd compression via DDL in Google. So I left it as is.
Colleagues who use zstd compression in Clickhouse - please share the instructions.
To start the server as a daemon, run:
service clickhouse-server startNow let's move on to setting up Clickhouse
Go to Clickhouse
clickhouse-client -h 172.26.10.109 -m172.26.10.109 - IP of the server where Clickhouse is installed.
Create a vector database
CREATE DATABASE vector;Let's check that there is a database.
show databases;We create the table vector.logs.
/* Это таблица где хранятся логи как есть */
CREATE TABLE vector.logs
(
`node_name` String,
`timestamp` DateTime,
`server_name` String,
`user_id` String,
`request_full` String,
`request_user_agent` String,
`request_http_host` String,
`request_uri` String,
`request_scheme` String,
`request_method` String,
`request_length` UInt64,
`request_time` Float32,
`request_referrer` String,
`response_status` UInt16,
`response_body_bytes_sent` UInt64,
`response_content_type` String,
`remote_addr` IPv4,
`remote_port` UInt32,
`remote_user` String,
`upstream_addr` IPv4,
`upstream_port` UInt32,
`upstream_bytes_received` UInt64,
`upstream_bytes_sent` UInt64,
`upstream_cache_status` String,
`upstream_connect_time` Float32,
`upstream_header_time` Float32,
`upstream_response_length` UInt64,
`upstream_response_time` Float32,
`upstream_status` UInt16,
`upstream_content_type` String,
INDEX idx_http_host request_http_host TYPE set(0) GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY timestamp
TTL timestamp + toIntervalMonth(1)
SETTINGS index_granularity = 8192;Check that the tables have been created. We launch clickhouse-client and make a request.
Let's go to the vector database.
use vector;
Ok.
0 rows in set. Elapsed: 0.001 sec.Let's look at the tables.
show tables;
┌─name────────────────┐
│ logs │
└─────────────────────┘Installing elasticsearch on the 4th server to send the same data to Elasticsearch for comparison with Clickhouse
Add public rpm key
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchLet's create 2 repos:
/etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md/etc/yum.repos.d/kibana.repo
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdInstall elasticsearch and kibana
yum install -y kibana elasticsearchSince it will be in 1 instance, you need to add to the /etc/elasticsearch/elasticsearch.yml file:
discovery.type: single-nodeIn order for vector to send data to elasticsearch from another server, we will change network.host.
network.host: 0.0.0.0To connect to kibana, change the server.host parameter in the /etc/kibana/kibana.yml file
server.host: "0.0.0.0"Old and include elasticsearch in autorun
systemctl enable elasticsearch
systemctl start elasticsearchand kibana
systemctl enable kibana
systemctl start kibanaSetting up Elasticsearch for single-node mode 1 shard, 0 replica. Most likely you will have a cluster of a large number of servers and you do not need to do this.
For future indexes, update the default template:
curl -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Installation as replacement for Logstash on 2 server
yum install -y https://packages.timber.io/vector/0.9.X/vector-x86_64.rpm mc httpd-tools screenLet's set up Vector as a replacement for Logstash. Editing the file /etc/vector/vector.toml
# /etc/vector/vector.toml
data_dir = "/var/lib/vector"
[sources.nginx_input_vector]
# General
type = "vector"
address = "0.0.0.0:9876"
shutdown_timeout_secs = 30
[transforms.nginx_parse_json]
inputs = [ "nginx_input_vector" ]
type = "json_parser"
[transforms.nginx_parse_add_defaults]
inputs = [ "nginx_parse_json" ]
type = "lua"
version = "2"
hooks.process = """
function (event, emit)
function split_first(s, delimiter)
result = {};
for match in (s..delimiter):gmatch("(.-)"..delimiter) do
table.insert(result, match);
end
return result[1];
end
function split_last(s, delimiter)
result = {};
for match in (s..delimiter):gmatch("(.-)"..delimiter) do
table.insert(result, match);
end
return result[#result];
end
event.log.upstream_addr = split_first(split_last(event.log.upstream_addr, ', '), ':')
event.log.upstream_bytes_received = split_last(event.log.upstream_bytes_received, ', ')
event.log.upstream_bytes_sent = split_last(event.log.upstream_bytes_sent, ', ')
event.log.upstream_connect_time = split_last(event.log.upstream_connect_time, ', ')
event.log.upstream_header_time = split_last(event.log.upstream_header_time, ', ')
event.log.upstream_response_length = split_last(event.log.upstream_response_length, ', ')
event.log.upstream_response_time = split_last(event.log.upstream_response_time, ', ')
event.log.upstream_status = split_last(event.log.upstream_status, ', ')
if event.log.upstream_addr == "" then
event.log.upstream_addr = "127.0.0.1"
end
if (event.log.upstream_bytes_received == "-" or event.log.upstream_bytes_received == "") then
event.log.upstream_bytes_received = "0"
end
if (event.log.upstream_bytes_sent == "-" or event.log.upstream_bytes_sent == "") then
event.log.upstream_bytes_sent = "0"
end
if event.log.upstream_cache_status == "" then
event.log.upstream_cache_status = "DISABLED"
end
if (event.log.upstream_connect_time == "-" or event.log.upstream_connect_time == "") then
event.log.upstream_connect_time = "0"
end
if (event.log.upstream_header_time == "-" or event.log.upstream_header_time == "") then
event.log.upstream_header_time = "0"
end
if (event.log.upstream_response_length == "-" or event.log.upstream_response_length == "") then
event.log.upstream_response_length = "0"
end
if (event.log.upstream_response_time == "-" or event.log.upstream_response_time == "") then
event.log.upstream_response_time = "0"
end
if (event.log.upstream_status == "-" or event.log.upstream_status == "") then
event.log.upstream_status = "0"
end
emit(event)
end
"""
[transforms.nginx_parse_remove_fields]
inputs = [ "nginx_parse_add_defaults" ]
type = "remove_fields"
fields = ["data", "file", "host", "source_type"]
[transforms.nginx_parse_coercer]
type = "coercer"
inputs = ["nginx_parse_remove_fields"]
types.request_length = "int"
types.request_time = "float"
types.response_status = "int"
types.response_body_bytes_sent = "int"
types.remote_port = "int"
types.upstream_bytes_received = "int"
types.upstream_bytes_send = "int"
types.upstream_connect_time = "float"
types.upstream_header_time = "float"
types.upstream_response_length = "int"
types.upstream_response_time = "float"
types.upstream_status = "int"
types.timestamp = "timestamp"
[sinks.nginx_output_clickhouse]
inputs = ["nginx_parse_coercer"]
type = "clickhouse"
database = "vector"
healthcheck = true
host = "http://172.26.10.109:8123" # Адрес Clickhouse
table = "logs"
encoding.timestamp_format = "unix"
buffer.type = "disk"
buffer.max_size = 104900000
buffer.when_full = "block"
request.in_flight_limit = 20
[sinks.elasticsearch]
type = "elasticsearch"
inputs = ["nginx_parse_coercer"]
compression = "none"
healthcheck = true
# 172.26.10.116 - сервер где установен elasticsearch
host = "http://172.26.10.116:9200"
index = "vector-%Y-%m-%d"You can edit the transforms.nginx_parse_add_defaults section.
As uses these configs for a small CDN and there several values can arrive in upstream_*
For example:
"upstream_addr": "128.66.0.10:443, 128.66.0.11:443, 128.66.0.12:443"
"upstream_bytes_received": "-, -, 123"
"upstream_status": "502, 502, 200"If this is not your situation then this section can be simplified
Create service settings for systemd /etc/systemd/system/vector.service
# /etc/systemd/system/vector.service
[Unit]
Description=Vector
After=network-online.target
Requires=network-online.target
[Service]
User=vector
Group=vector
ExecStart=/usr/bin/vector
ExecReload=/bin/kill -HUP $MAINPID
Restart=no
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=vector
[Install]
WantedBy=multi-user.targetAfter creating tables, you can run Vector
systemctl enable vector
systemctl start vectorVector logs can be viewed like this
journalctl -f -u vectorThe logs should contain entries like this
INFO vector::topology::builder: Healthcheck: Passed.
INFO vector::topology::builder: Healthcheck: Passed.On the client (Web server) - 1st server
On the server with nginx, you need to disable ipv6, since the logs table in clickhouse uses the field upstream_addr IPv4 since I don't use ipv6 internally. If ipv6 is not disabled, then there will be errors:
DB::Exception: Invalid IPv4 value.: (while read the value of key upstream_addr)Perhaps readers, add support for ipv6.
Create file /etc/sysctl.d/98-disable-ipv6.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1Applying settings
sysctl --systemInstall nginx.
Added nginx repository file /etc/yum.repos.d/nginx.repo
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=trueInstall the nginx package
yum install -y nginxFirst we need to configure the Nginx log format in the /etc/nginx/nginx.conf file
user nginx;
# you must set worker processes based on your CPU cores, nginx does not benefit from setting more than that
worker_processes auto; #some last versions calculate it automatically
# number of file descriptors used for nginx
# the limit for the maximum FDs on the server is usually set by the OS.
# if you don't set FD's then OS settings will be used which is by default 2000
worker_rlimit_nofile 100000;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
# provides the configuration file context in which the directives that affect connection processing are specified.
events {
# determines how much clients will be served per worker
# max clients = worker_connections * worker_processes
# max clients is also limited by the number of socket connections available on the system (~64k)
worker_connections 4000;
# optimized to serve many clients with each thread, essential for linux -- for testing environment
use epoll;
# accept as many connections as possible, may flood worker connections if set too low -- for testing environment
multi_accept on;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format vector escape=json
'{'
'"node_name":"nginx-vector",'
'"timestamp":"$time_iso8601",'
'"server_name":"$server_name",'
'"request_full": "$request",'
'"request_user_agent":"$http_user_agent",'
'"request_http_host":"$http_host",'
'"request_uri":"$request_uri",'
'"request_scheme": "$scheme",'
'"request_method":"$request_method",'
'"request_length":"$request_length",'
'"request_time": "$request_time",'
'"request_referrer":"$http_referer",'
'"response_status": "$status",'
'"response_body_bytes_sent":"$body_bytes_sent",'
'"response_content_type":"$sent_http_content_type",'
'"remote_addr": "$remote_addr",'
'"remote_port": "$remote_port",'
'"remote_user": "$remote_user",'
'"upstream_addr": "$upstream_addr",'
'"upstream_bytes_received": "$upstream_bytes_received",'
'"upstream_bytes_sent": "$upstream_bytes_sent",'
'"upstream_cache_status":"$upstream_cache_status",'
'"upstream_connect_time":"$upstream_connect_time",'
'"upstream_header_time":"$upstream_header_time",'
'"upstream_response_length":"$upstream_response_length",'
'"upstream_response_time":"$upstream_response_time",'
'"upstream_status": "$upstream_status",'
'"upstream_content_type":"$upstream_http_content_type"'
'}';
access_log /var/log/nginx/access.log main;
access_log /var/log/nginx/access.json.log vector; # Новый лог в формате json
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}In order not to break your current configuration, Nginx allows you to have several access_log directives
access_log /var/log/nginx/access.log main; # Стандартный лог
access_log /var/log/nginx/access.json.log vector; # Новый лог в формате jsonDon't forget to add a rule to logrotate for new logs (if the log file doesn't end with .log)
Delete default.conf from /etc/nginx/conf.d/
rm -f /etc/nginx/conf.d/default.confAdd virtual host /etc/nginx/conf.d/vhost1.conf
server {
listen 80;
server_name vhost1;
location / {
proxy_pass http://172.26.10.106:8080;
}
}Add virtual host /etc/nginx/conf.d/vhost2.conf
server {
listen 80;
server_name vhost2;
location / {
proxy_pass http://172.26.10.108:8080;
}
}Add virtual host /etc/nginx/conf.d/vhost3.conf
server {
listen 80;
server_name vhost3;
location / {
proxy_pass http://172.26.10.109:8080;
}
}Add virtual host /etc/nginx/conf.d/vhost4.conf
server {
listen 80;
server_name vhost4;
location / {
proxy_pass http://172.26.10.116:8080;
}
}Add virtual hosts (172.26.10.106 ip of the server where nginx is installed) to all servers in the /etc/hosts file:
172.26.10.106 vhost1
172.26.10.106 vhost2
172.26.10.106 vhost3
172.26.10.106 vhost4And if everything is ready then
nginx -t
systemctl restart nginxNow let's install
yum install -y https://packages.timber.io/vector/0.9.X/vector-x86_64.rpmCreate a settings file for systemd /etc/systemd/system/vector.service
[Unit]
Description=Vector
After=network-online.target
Requires=network-online.target
[Service]
User=vector
Group=vector
ExecStart=/usr/bin/vector
ExecReload=/bin/kill -HUP $MAINPID
Restart=no
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=vector
[Install]
WantedBy=multi-user.targetAnd configure the Filebeat replacement in the /etc/vector/vector.toml config. IP address 172.26.10.108 is the IP address of the log server (Vector-Server)
data_dir = "/var/lib/vector"
[sources.nginx_file]
type = "file"
include = [ "/var/log/nginx/access.json.log" ]
start_at_beginning = false
fingerprinting.strategy = "device_and_inode"
[sinks.nginx_output_vector]
type = "vector"
inputs = [ "nginx_file" ]
address = "172.26.10.108:9876"Don't forget to add the user vector to the appropriate group so that it can read log files. For example, nginx in centos creates logs with adm group rights.
usermod -a -G adm vectorLet's start the vector service
systemctl enable vector
systemctl start vectorVector logs can be viewed like this
journalctl -f -u vectorThe logs should have something like this
INFO vector::topology::builder: Healthcheck: Passed.Stress Testing
Testing is carried out using Apache benchmark.
The httpd-tools package was installed on all servers
We start testing using Apache benchmark from 4 different servers in screen. First, we launch the screen terminal multiplexer, and then we start testing with the Apache benchmark. How to work with screen you can find in .
From the 1st server
while true; do ab -H "User-Agent: 1server" -c 100 -n 10 -t 10 http://vhost1/; sleep 1; doneFrom the 2st server
while true; do ab -H "User-Agent: 2server" -c 100 -n 10 -t 10 http://vhost2/; sleep 1; doneFrom the 3st server
while true; do ab -H "User-Agent: 3server" -c 100 -n 10 -t 10 http://vhost3/; sleep 1; doneFrom the 4st server
while true; do ab -H "User-Agent: 4server" -c 100 -n 10 -t 10 http://vhost4/; sleep 1; doneLet's check the data in Clickhouse
Go to Clickhouse
clickhouse-client -h 172.26.10.109 -mMaking a SQL query
SELECT * FROM vector.logs;
┌─node_name────┬───────────timestamp─┬─server_name─┬─user_id─┬─request_full───┬─request_user_agent─┬─request_http_host─┬─request_uri─┬─request_scheme─┬─request_method─┬─request_length─┬─request_time─┬─request_referrer─┬─response_status─┬─response_body_bytes_sent─┬─response_content_type─┬───remote_addr─┬─remote_port─┬─remote_user─┬─upstream_addr─┬─upstream_port─┬─upstream_bytes_received─┬─upstream_bytes_sent─┬─upstream_cache_status─┬─upstream_connect_time─┬─upstream_header_time─┬─upstream_response_length─┬─upstream_response_time─┬─upstream_status─┬─upstream_content_type─┐
│ nginx-vector │ 2020-08-07 04:32:42 │ vhost1 │ │ GET / HTTP/1.0 │ 1server │ vhost1 │ / │ http │ GET │ 66 │ 0.028 │ │ 404 │ 27 │ │ 172.26.10.106 │ 45886 │ │ 172.26.10.106 │ 0 │ 109 │ 97 │ DISABLED │ 0 │ 0.025 │ 27 │ 0.029 │ 404 │ │
└──────────────┴─────────────────────┴─────────────┴─────────┴────────────────┴────────────────────┴───────────────────┴─────────────┴────────────────┴────────────────┴────────────────┴──────────────┴──────────────────┴─────────────────┴──────────────────────────┴───────────────────────┴───────────────┴─────────────┴─────────────┴───────────────┴───────────────┴─────────────────────────┴─────────────────────┴───────────────────────┴───────────────────────┴──────────────────────┴──────────────────────────┴────────────────────────┴─────────────────┴───────────────────────Find out the size of tables in Clickhouse
select concat(database, '.', table) as table,
formatReadableSize(sum(bytes)) as size,
sum(rows) as rows,
max(modification_time) as latest_modification,
sum(bytes) as bytes_size,
any(engine) as engine,
formatReadableSize(sum(primary_key_bytes_in_memory)) as primary_keys_size
from system.parts
where active
group by database, table
order by bytes_size desc;Let's find out how many logs took in Clickhouse.
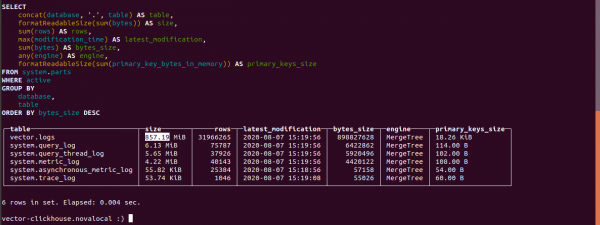
The size of the logs table is 857.19 MB.
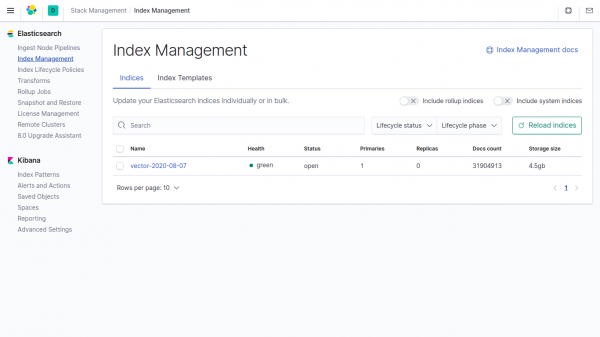
The size of the same data in the index in Elasticsearch is 4,5 GB.
If the vector parameters are not specified in Clickhouse, the data takes 4500/857.19 = 5.24 times less than in Elasticsearch.
In vector, the compression field is used by default.
Telegram chat by
Telegram chat by
Telegram chat by ""
Source: habr.com
