

Hello, I work in the team of the DRD KP project (distributed data registry for monitoring the life cycle of wheel sets). Here I want to share the experience of our team in developing an enterprise blockchain for this project under the constraints imposed by technology. For the most part, I will be talking about Hyperledger Fabric, but the approach described here can be extrapolated to any permissioned blockchain. The ultimate goal of our research is to prepare enterprise blockchain solutions in such a way that the final product is pleasant to use and not too hard to maintain.
There will be no discoveries, unexpected solutions, and no unique developments will be covered here (because I don’t have them). I just want to share my humble experience, show that "it was possible" and, perhaps, read about someone else's experience in making good and not so good decisions in the comments.
Problem: blockchains are not yet scalable
Today, the efforts of many developers are aimed at making the blockchain a really convenient technology, and not a ticking time bomb in a beautiful wrapper. State channels, optimistic rollup, plasma and sharding may become commonplace. Some day. Or maybe TON will again postpone the launch for six months, and the next Plasma Group will cease to exist. We can believe in another roadmap and read brilliant white papers at night, but here and now we need to do something with what we have. Get shit done.
The task assigned to our team in the current project looks like this in general terms: there are many subjects, reaching several thousand, who do not want to build relationships on trust; it is necessary to build on DLT a solution that will work on ordinary PCs without special performance requirements and provide a user experience no worse than any centralized accounting systems. The technology behind the solution should minimize the possibility of malicious data manipulation – which is why blockchain is here.
Slogans from whitepapers and media promise us that the next development will allow millions of transactions per second. What is it really?
Mainnet Ethereum is currently running at ~30 tps. Because of this alone, it is difficult to perceive it as a blockchain that is in any way suitable for corporate needs. Among permissioned solutions, benchmarks showing 2000 tps are known () or 3000 tps (, there is a little less in the publication, but keep in mind that the benchmark was carried out on the old consensus engine). Was , which gave not the worst results, 20000 tps, but so far these are just academic studies waiting for their stable implementation. It is unlikely that a corporation that can afford to maintain a department of blockchain developers will put up with such indicators. But the problem is not only in throughput, there is also latency.
Latency
The delay from the moment a transaction is initiated to its final approval by the system depends not only on the speed of the message passing through all the stages of validation and ordering, but also on the block formation parameters. Even if our blockchain allows us to commit at 1000000 tps, but it takes 10 minutes to form a 488MB block, will it get any easier for us?
Let's take a closer look at the life cycle of a transaction in Hyperledger Fabric to understand what takes time and how it relates to block formation parameters.
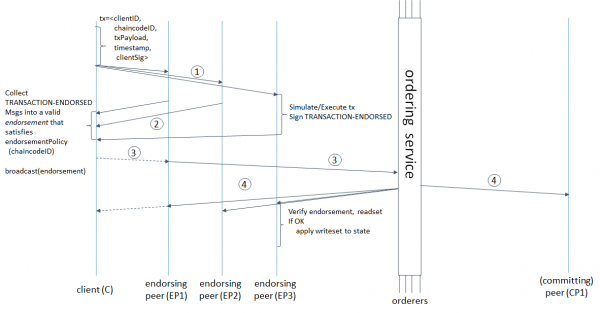
taken from here:
(1) The client forms a transaction, sends it to endorsing peers, the latter simulate the transaction (apply the changes made by the chaincode to the current state, but do not commit to the ledger) and receive RWSet - key names, versions and values taken from the collection in CouchDB, ( 2) endorsers send a signed RWSet back to the client, (3) the client either checks for the signatures of all the necessary peers (endorsers), and then sends the transaction to the ordering service, or sends it without verification (the verification will still take place later), the ordering service forms a block and ( 4) sends back to all peers, not just endorsers; peers check that the versions of the keys in read set match the versions in the database, the signatures of all endorsers, and finally commit the block.
But that is not all. Behind the words “orderer forms a block” is hidden not only the ordering of transactions, but also 3 consecutive network requests from the leader to followers and back: the leader adds a message to the log, sends to the followers, the latter add to their log, send confirmation of successful replication to the leader, the leader commits the message , sends commit confirmation to followers, followers commit. The smaller the block size and time, the more often the ordering service will have to establish consensus. Hyperledger Fabric has two block formation parameters: BatchTimeout - block formation time and BatchSize - block size (the number of transactions and the size of the block itself in bytes). As soon as one of the parameters reaches the limit, a new block is issued. The more orderer nodes, the longer this will take. Therefore, you need to increase BatchTimeout and BatchSize. But since RWSets are versioned, the larger we make the block, the higher the probability of MVCC conflicts. In addition, with an increase in BatchTimeout, UX degrades catastrophically. It seems to me reasonable and obvious the following scheme for solving these problems.
How to avoid waiting for block finalization and not lose track of transaction status
The longer the formation time and the block size, the higher the throughput of the blockchain. One does not directly follow from the other, but it should be remembered that establishing consensus in RAFT requires three network requests from the leader to the followers and back. The more order nodes, the longer it will take. The smaller the size and time of block formation, the more such interactions. How to increase the formation time and block size without increasing the system response time for the end user?
First, you need to somehow resolve MVCC conflicts caused by a large block size, which can include different RWSets with the same version. Obviously, on the client side (in relation to the blockchain network, this may well be a backend, and I mean it) MVCC conflict handler, which can be either a separate service or a regular decorator over a transaction-initiating call with retry logic.
Retry can be implemented with an exponential strategy, but then the latency will degrade exponentially as well. So you should use either a randomized retry within certain small limits, or a constant one. With an eye to possible collisions in the first variant.
The next step is to make the client's interaction with the system asynchronous so that it does not wait for 15, 30, or 10000000 seconds, which we will set as BatchTimeout. But at the same time, it is necessary to retain the ability to make sure that the changes initiated by the transaction are recorded / not recorded in the blockchain.
A database can be used to store the status of transactions. The easiest option is CouchDB because of its ease of use: the database has a UI out of the box, a REST API, and you can easily set up replication and sharding for it. You can just create a separate collection in the same CouchDB instance that Fabric uses to store its world state. We need to store documents of this kind.
{
Status string // Статус транзакции: "pending", "done", "failed"
TxID: string // ID транзакции
Error: string // optional, сообщение об ошибке
}This document is written to the database before the transaction is sent to peers, the entity ID is returned to the user (the same ID is used as a key) if this is a creation operation, and then the Status, TxID and Error fields are updated as relevant information is received from peers.
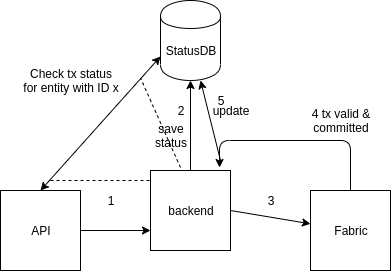
In this scheme, the user does not wait for the block to finally form, watching the spinning wheel on the screen for 10 seconds, he receives an instant response from the system and continues to work.
We chose BoltDB to store transaction statuses because we need to save memory and do not want to waste time on network interaction with a stand-alone database server, especially when this interaction takes place using the plain text protocol. By the way, whether you use CouchDB to implement the scheme described above or just to store the world state, in any case, it makes sense to optimize the way data is stored in CouchDB. By default, in CouchDB, the size of b-tree nodes is 1279 bytes, which is much smaller than the sector size on disk, which means that both reading and rebalancing the tree will require more physical disk accesses. The optimal size meets the standard and is 4 kilobytes. For optimization, we need to set the parameter btree_chunk_size equal to 4096 in the CouchDB configuration file. For BoltDB such manual intervention .
Back pressure: buffer strategy
But there can be a lot of messages. More than the system can handle, sharing resources with a dozen other services besides those shown in the diagram - and all this should work flawlessly even on machines on which running Intellij Idea would be extremely tedious.
The problem of different throughput of communicating systems, producer and consumer, is solved in different ways. Let's see what we could do.
dropping: we can claim to be able to process at most X transactions in T seconds. All requests that exceed this limit are dropped. It's pretty simple, but then you can forget about UX.
Controlling: the consumer must have some interface through which, depending on the load, he can control the tps of the producer. Not bad, but it imposes an obligation on the developers of the load client to implement this interface. For us, this is unacceptable, since the blockchain in the future will be integrated into a large number of long-existing systems.
Buffering: instead of contriving to resist the input data stream, we can buffer this stream and process it at the required speed. Obviously, this is the best solution if we want to provide a good user experience. We implemented the buffer using a queue in RabbitMQ.
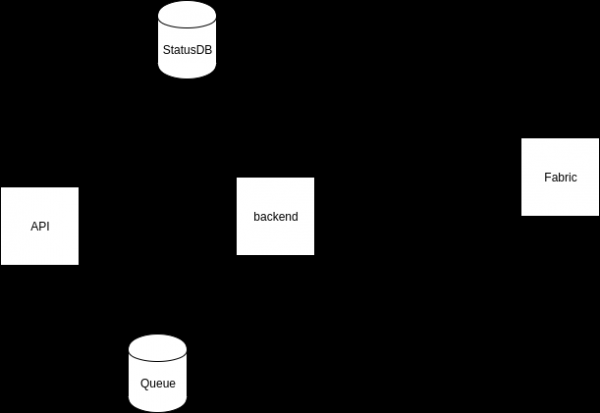
Two new actions have been added to the scheme: (1) after an API request is received, a message is queued with the parameters necessary to call the transaction, and the client receives a message that the transaction has been accepted by the system, (2) the backend reads data at a speed specified in the config from the queue; initiates a transaction and updates the data in the status store.
Now you can increase the build time and block capacity as much as you want, hiding delays from the user.
Other tools
Nothing was said here about chaincode, because there is usually nothing to optimize in it. The chaincode should be as simple and secure as possible - that's all that is required of it. The framework helps us a lot to write chaincode simply and safely. from S7 Techlab and static analyzer .
In addition, our team is developing a set of utilities to make working with Fabric simple and enjoyable: , utility for (add/remove organizations, RAFT nodes), utility for . If you would like to contribute, welcome.
Conclusion
This approach makes it easy to replace Hyperledger Fabric with Quorum, other private Ethereum networks (PoA or even PoW), significantly reduce real throughput, but at the same time maintain normal UX (both for users in the browser and from the side of integrated systems). When replacing Fabric with Ethereum in the scheme, only the logic of the retry service / decorator will need to be changed from handling MVCC conflicts to an atomic nonce increment and resending. Buffering and status storage made it possible to decouple the response time from the block formation time. Now you can add thousands of order nodes and not be afraid that blocks are formed too often and load the ordering service.
In general, this is all I wanted to share. I will be glad if it helps someone in their work.
Source: habr.com
