

This spring we found ourselves in very cheerful conditions. Due to the pandemic, it became clear that our summer conferences needed to be moved online. And in order to conduct them online with high quality, ready-made software solutions did not suit us, we had to write our own. And we had three months to do it.
Understandably, it has been an exciting three months. But from the outside it is not quite obvious: what is an online conferencing platform in general? What parts does it consist of? Therefore, at the last of the DevOops summer conferences, I asked those who were responsible for this task:
- Nikolay Molchanov - Technical Director of JUG Ru Group;
- Vladimir Krasilshchik is a pragmatic back-end Java programmer (you could also see his presentations at our Java conferences);
- Artyom Nikonov is responsible for all our video streaming.
By the way, at the autumn-winter conferences we will use an improved version of the same platform - so many habra-readers will still be its users.
The overall picture
- What was the composition of the team?
Nikolay Molchanov: We have an analyst, a designer, a tester, three front-enders, a back-ender. And, of course, the T-shaped specialist!
- What was the overall process like?
Nikolai: Until mid-March, nothing was ready for online at all. And on March 15, the whole online carousel began to spin. We started several repositories, planned, discussed the basic architecture and did everything in three months.
This, of course, has gone through the classic stages of planning, architecture, feature selection, feature voting, feature policy, feature design, development, testing. As a result, on June 6, we rolled out everything for sale. . There were 90 days for everything.
- Did you manage to catch up with what we committed to?
Nikolai: Since we are now participating in the DevOops conference online, it means that we succeeded. I personally committed to the main thing: I will bring to customers a tool with which it will be possible to make a conference online.
The challenge was: give us a tool to broadcast our conferences to ticket holders.
All planning was divided into several stages, and all features (about 30 global ones) were divided into 4 categories:
- which we will definitely do (we cannot live without them),
- which we will do in the second turn,
- which we will never do
- and which we will never, ever do.
We have done all the features from the first two categories.
— I know that there were 600 JIRA issues in total. In three months, you have made 13 microservices, and I suspect that they are not written only in Java. You used different technologies, you have two Kubernetes clusters in three availability zones and 5 RTMP streams in Amazon.
Let's now deal with each component of the system separately.
Streaming
- Let's start with when we already have a video image, and it is transmitted to some services. Artyom, tell us how this streaming happens?
Artyom Nikonov: Our general scheme looks like this: the image from the camera -> our control room -> local RTMP server -> Amazon -> video player. More on Habré in June.
In general, there are two global ways how this can be done: either on hardware or on the basis of software solutions. We chose the soft path because it's easier with remote speakers. It is not always possible to bring a piece of hardware to a speaker in another country, and it seems easier and more reliable to install software for a speaker.
In terms of hardware, we have a number of cameras (in our studios and remote speakers), a number of consoles in the studio, which sometimes have to be repaired right during the broadcast under the table.
Signals from these devices enter computers with capture, I/O, and sound cards. There, the signals are mixed, assembled into layouts:

Layout example for 4 speakers

Layout example for 4 speakers
Further, uninterrupted air is provided with the help of three computers: there is one main machine and a couple of workers in turn. The first computer collects the first report, the second the break, the first the next report, the second the next break, and so on. And the main machine mixes the first with the second.
Thus, a certain triangle is obtained, and in the event of the fall of any of these nodes, we can continue to deliver content to customers quickly and without loss of quality. We had such a situation. In the first week of conferences, we fixed one car, turned it on / off. It seems that people are happy with our fault tolerance.
Then the streams from the computers get to the local server, which has two tasks: to route RTMP streams and write a backup. So we have multiple entry points. The video streams are then sent to the Amazon SaaS part of our system. We use ,S3,CloudFront.
Nikolai: And what happens there before the video gets to the audience? Do you have to cut it somehow?
Artyom: We compress the video from our side, send it to MediaLive. We run transcoders there. They transcode the video in real time to multiple resolutions so that people can watch it on their phones, over bad internet in their country house, and so on. Then these streams are cut into , this is how the protocol works . We give a playlist to the frontend, in which there are pointers to these chunks.
Are we using 1080p resolution?
Artyom: We have 1080 pixels in width, like 1920p video, and a little less in height, the picture is more elongated - there are reasons for this.
Player
— Artyom described how the video gets into streams, how it is distributed to different playlists for different screen resolutions, cut into chunks and gets into the player. Kolya, now tell us what kind of player it is, how it consumes the stream, why HLS?
Nikolai: We have a player that is watched by all viewers of the conference.
In fact, this is a wrapper over the library , on which many other players are written. But we needed a very specific functionality: rewind and mark the place where the person is, what report he is currently watching. We also needed our own layouts, all sorts of logos and everything else that was built in with us. Therefore, we decided to write our own library (a wrapper over HLS) and embed it on the site.
This is the core functionality, so it was almost the first to be implemented. And then everything grew around it.
In fact, the player, through authorization, receives a playlist from the backend with links to chunks correlated with time and quality, downloads the necessary ones and shows it to the user, performing some “magic” along the way.
Timeline example
- A button is built right into the player to display the timeline of all reports ...
Nikolai: Yes, we immediately solved the problem of user navigation. In mid-April, we decided that we would not broadcast each of our conferences on a separate site, but would combine everything on one. So that users of Full Pass tickets can freely switch between different conferences: both live and past recordings.
And to make it easier for users to move around the current stream and switch between tracks, we decided to make the All Broadcast button and horizontal report cards for switching between tracks and reports. It has keyboard controls.
Were there any technical difficulties with this?
Nikolai: Were with a scroll bar on which the start points of different reports are marked.
— In the end, you implemented these marks on the scrollbar before YouTube did something similar?
Artyom: They had it in beta then. It seems to be quite a complex feature because they have been partially testing it on users over the past year. And now it's up for sale.
Nikolai: But we really brought it to the sale faster. To be honest, behind this simple feature there is a huge amount of backend, frontend, calculations and matan inside the player.
Frontend
- Let's see how this content that we show (report card, speakers, website, schedule) goes to the front-end?
Vladimir Dyer: We have several internal IT systems. There is a system in which all reports and all speakers are entered. There is a process by which the speaker takes part in the conference. The speaker submits an application, the system captures it, then there is a certain pipeline, according to which a report is created.
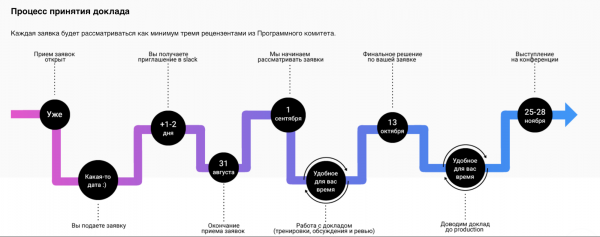
This is how the speaker sees the pipeline
This system is our internal development.
Next, from individual reports, you need to build a schedule. As you know, this is an NP-hard problem, but we somehow solve it. To do this, we launch another component that generates a schedule and puts it into a third-party Contentful cloud service. Everything looks like a table there, in which there are days of the conference, in days there are time slots, and in the slots there are reports, breaks or sponsorship activities. So the content that we see is located in a third-party service. And the task is to bring it to the site.
It would seem that the site is just a page with a player, and there is nothing complicated here. Except that it's not. The backend behind this page goes to Contentful, gets the schedule from there, forms some objects and sends it to the frontend. With the help of a websocket connection, which is made by each client of our platform, we send him an update in the schedule from the backend to the frontend.
A real case: the speaker changed jobs right during the conference. It is necessary to change his plate of the company-employer. How does it happen from the backend? An update is sent to all clients via the web socket, and then the front-end itself redraws the timeline. All of this runs seamlessly. The combination of the cloud service and several of our components gives us the ability to shape all this content and provide it to the front.
Nikolai: Here it is important to clarify that our site is not a classic SPA application. This is a made-up, rendered site, and SPA. In fact, Google sees this site as rendered HTML. This is good for SEO and for delivering content to the user. It doesn't wait for 1,5 megabytes of JavaScript to load before seeing the page, it immediately sees the already rendered page, and you feel it every time you switch the report. Everything turns out in half a second, since the content is already ready and posted in the right place.
- Let's draw a line under all of the above, listing the technologies. Tyoma said that we have 5 Amazon streams, we deliver video and sound there. There we have bash scripts, with their help we launch, configure ...
Artyom: This happens through the AWS API, there are many other side technical services. We divided our duties so that I deliver on , and front-end and back-end developers take it from there. We have a number of our own bindings to simplify the laying out of content, which we then make in 4K, etc. Since the deadlines were very tight, we almost completely did it on the basis of AWS.
- Then all this gets into the player using the backend system. We have TypeScript, React, Next.JS in the player. And on the backend we have several services in C#, Java, Spring Boot and Node.js. All this is deployed using Kubernetes using the Yandex.Cloud infrastructure.
I also want to note that when I needed to get acquainted with the platform, it turned out to be easy: all repositories are on GitLab, everything is well named, tests are written, there is documentation. That is, even in emergency mode, they took care of such things.
Business Constraints and Analytics
— We targeted business requirements for 10 users. It's time to talk about the business restrictions that we had. We had to provide a high workload, ensure the implementation of the law on the preservation of personal data. And what else?
Nikolai: Initially, we started from the requirements for the video. The most important thing is the distributed storage of video around the world for fast delivery to the client. Of the others - 1080p resolution, as well as rewind, which many others do not implement in live mode. Later, we added the ability to enable 2x speed, with its help you can “catch up” with live and continue watching the conference in real time. And along the way, the timeline markup functionality appeared. Plus, we had to be fault-tolerant and withstand a load of 10 connections. From a backend perspective, that's roughly 000 connections times 10 requests per page refresh. And this is already 000 RPS / sec. Quite a bit of.
- Were there any requirements for a "virtual exhibition" with online stands of partners?
Nikolai: Yes, it had to be done quite quickly and universally. We had up to 10 partner companies for each conference, and the pages of all of them had to be completed in a week or two. At the same time, their content is slightly different in format. But a certain templating engine was made that collects these pages on the fly, with little or no further development involvement.
— There were also requirements for real-time view analytics and statistics. I know that we use Prometheus for this, but tell us in more detail: what requirements do we fulfill in terms of analytics, and how is this implemented?
Nikolai: Initially, we have marketing requirements to collect for A/B testing and to collect information in order to understand how to properly deliver the best content to the client in the future. There are also requirements for some analytics on partner activities and the analytics that you see (visit counter). All information is collected in real time.
We can give out this information in an aggregated form even to speakers: how many people watched you at a certain point in time. At the same time, in order to comply with Federal Law 152, the personal account and personal data are not tracked in any way.
The platform already has both marketing tools and our metrics for measuring user activity in real time (who watched which second of the report) in order to build report attendance graphs. Based on this data, research is being done that will make the next conferences better.
Fraud
— Do we have anti-fraud mechanisms?
Nikolai: Due to the tight time frame from the point of view of the business, the task was not initially set to immediately block unnecessary connections. If two users logged in under the same account, they could view the content. But we know how many simultaneous views were from one account. And we banned several especially malicious violators.
Vladimir: We must pay tribute, one of the banned users understood why this happened. He came, apologized and promised to buy a ticket.
- For this to happen, you must completely trace all users from entry to exit, always know what they are doing. How is this system arranged?
Vladimir: I would like to talk about analytics and statistics, which we then analyze for the success of the report, or we can then provide to partners. All clients are websocket-attached to a specific backend cluster. It stands there . Each client in each period of time sends what he is doing and what track he is watching. Further, this information is aggregated by fast Hazelcast jobs and sent back to everyone who watches these tracks. We see in the corner how many people are with us now.

The same information is stored in and leaves for our data lake, on which we have the opportunity to build a more interesting graph. The question comes up: how many unique users have watched this report? We go to , there are pings of all people who came by the id of this report. We collected, aggregated unique ones, and now we can understand.
Nikolai: But at the same time, we also get real-time data from Prometheus. It is set on all Kubernetes services, on Kubernetes itself. It collects absolutely everything, and with Grafana we can build any graphs in real time.
Vladimir: On the one hand, we download it for further processing of the OLAP type. And for OLTP, the application uploads the whole thing to Prometheus, Grafana, and the graphs even converge!
- The very case when the graphs converge.
Dynamic changes
- Tell us how dynamic changes roll out: if the report was canceled 6 minutes before the start, what is the chain of actions? What pipeline works?
Vladimir: The pipeline is very conditional. There are several possibilities. First, the scheduling program worked and changed the schedule. The modified schedule is uploaded to Contentful. After that, the backend understands that there are changes for this conference in Contentful, takes it and rebuilds it. Everything is collected and sent via websocket.
The second possibility, when everything happens at a frantic pace: the editor manually changes the information in Contentful (link to Telegram, presentation of the speaker, etc.) and the same logic works as the first time.
Nikolai: Everything happens without refreshing the page. All changes occur absolutely seamlessly for the client. Also with switching reports. When the time comes, the report and the interface change.
Vladimir: Also, the time cut-offs of the beginning of reports in the timeline. There is nothing at the very beginning. And if you move the mouse over the red bar, then at some point, thanks to the broadcast director, cut-offs will appear. The director sets the correct beginning of the broadcast, the backend captures this change, calculates the start and end times of the reports of the entire track according to the conference schedule, sends it to our clients, the player draws cutoffs. Now the user can easily navigate to the beginning and end of the report. It was a tough business requirement, very convenient and useful. You don't waste time finding the present start time of the report. And when we do a preview, it will be generally wonderful.
Deployment
— I would like to ask about the deployment. Kolya and the team at the beginning killed a lot of time to set up the entire infrastructure in which everything is deployed for us. Tell me, what is it all from?
Nikolai: From a technical point of view, we initially had a requirement for the product to abstract as much as possible from any vendor. Come to AWS to make Terraform scripts specifically AWS, or specifically Yandex, or Azure, etc. didn't fit very well. We had to go somewhere at the right time.
For the first three weeks, we were constantly looking for a way to do it better. As a result, we came to the conclusion that Kubernetes in this case is our everything, because it allows you to do auto-scalable services, auto-rollout and get almost all services out of the box. Naturally, it was necessary to train all services to work with Kubernetes, Docker, and to learn the team too.
We have two clusters. Test and prodovsky. They are absolutely identical in terms of hardware, settings. We implement the infrastructure as code. All services are automatically rolled out into three environments from feature branches, from master branches, from test branches, from GitLab. This is maximally integrated into GitLab, maximally integrated with Elastic, Prometheus.
We get the opportunity to quickly (for the backend within 10 minutes, for the frontend within 5 minutes) roll out changes to any environment with all tests, integrations, running functional tests, integration tests on the environment, and also test with load tests on a test environment about the same thing that we want to get in production.
About tests
- You test almost everything, it's hard to believe how you wrote everything. Can you tell us about the backend for tests: how much is everything covered, what tests?
Vladimir: Two types of tests have been written. The first are component tests. Lift level tests of the entire spring application and base in . This is a test of the highest level business scenarios. I don't test features. We only test some big things. For example, right in the test, the user's login process is emulated, the user's request for tickets, where he can go, the request for access to watch the stream. Very clear user scripts.
Approximately the same thing is implemented in the so-called integration tests that actually run on the environment. In fact, when the next deployment to the production rolls out, the real base scenarios also run on the production. The same login, requesting tickets, requesting access to CloudFront, checking that the stream really clings to my permissions, checking the director's interface.
At the moment I have about 70 component tests and about 40 integration tests on board. The coverage is very close to 95%. This is for component, for integration is smaller, there is simply not so much needed. Given that the project has all sorts of code generation, this is a very good indicator. There was no other way to do what we did in three months. Because if we tested manually, giving features to our tester, and she would find bugs and return them to us for fixes, then this round trip to debug the code would be very long, and we would not fit into any deadlines.
Nikolai: Conventionally, in order to carry out a regression on the entire platform when a function is changed, you need to sit for two days and poke everywhere.
Vladimir: Therefore, it is a great success that when I estimate a feature, I say that I need 4 days for two simple pens and 1 websocket, Kolya allows. He is already used to the fact that 4 types of tests are included in these 2 days, and then, most likely, it will work.
Nikolai: I also have 140 tests written: component + functional, which do the same. All the same scenarios are tested in production, on test and on dev. Also recently we have functional basic UI tests. So we cover the most basic functionality that can fall apart.
Vladimir: Of course, it is worth talking about load tests. It was necessary to check the platform under a load close to the real one in order to understand how everything is, what happens with Rabbit, what happens with JVMs, how much memory is really needed.
— I don’t know for sure if we are testing anything on the side of the streams, but I remember that there were problems with transcoders when we did meetups. Have we tested streams?
Artyom: Tested iteratively. Organizing meetups. In the process of organizing meetups, there were approximately 2300 JIRA tickets. These are just formulaic things that people did to make meetups. We took parts of the platform to a separate page for meetups, which was handled by Kirill Tolkachev ().
To be honest, there were no big problems. Literally a couple of times we caught caching bugs on CloudFront, we solved it pretty quickly - we just reconfigured the policies. There were much more bugs in people, in streaming systems on the site.
During the conferences, I had to write a few more exporters in order to cover more equipment and services. In some places I had to make my bikes just for the sake of metrics. The world of AV (audio video) hardware is not very rosy - you have some kind of “API” of equipment that you simply cannot influence. And it’s far from a fact that it will be possible to pick up the information that you need. Hardware vendors are really slow and almost impossible to get what you want out of them. There are more than 100 pieces of hardware in total, they don’t give what you need, and you write strange and redundant exporters, thanks to which you can at least somehow debug the system.
Equipment
— I remember how, before the start of the conferences, we partially purchased additional equipment.
Artyom: Purchased computers, laptops, battery packs. At the moment we can live without electricity for 40 minutes. In June, there were severe thunderstorms in St. Petersburg - so we had such a shutdown. At the same time, several providers come to us with optical links from different points. This is really 40 minutes of downtime of the building, during which we will have lights on, sound, cameras, etc. will work.
We have a similar story with the Internet. In the office where our studios are located, we dragged a fierce net between floors.
Artyom: We have 20 Gbit of optics between floors. Further down the floors, somewhere there is optics, somewhere there is none, but still there are no channels less than gigabit channels - we drive video between them between the tracks of the conference. In general, it is very convenient to work on your own infrastructure, it is rarely possible to do so at offline conferences on sites.
- Before I worked at JUG Ru Group, I saw how the control rooms at offline conferences are set up overnight, where there is a large monitor with all the metrics that you build in Grafana. Now there is also a headquarters room in which the development team sits, which fixes some bugs and develops features during the conference. At the same time, there is a monitoring system that is displayed on a large screen. Artyom, Kolya and other guys are sitting and watching so that everything does not fall and works beautifully.
Curiosities and problems
— You spoke well about the fact that we have streaming with Amazon, we have a web player, everything is written in different programming languages, fault tolerance and other business requirements are provided, including a personal account that is supported for legal entities and individuals, and we can integrate with someone via OAuth 2.0, there is antifraud, user blocking. We can roll out changes dynamically because we did it well, and it's all being tested.
I'm interested to know what were the curiosities in order for something to start. Were there any strange situations when you developed the backend, frontend, some kind of game turned out and you did not understand what to do with it?
Vladimir: I think it's only been like this for the last three months. Every day. As you can see, all my hair has been pulled out.

Vladimir Krasilshchik after 3 months, when some kind of game turned out and no one understood what to do with it
Every day there was something like that, when there was such a moment when you take and tear your hair, or you realize that there is no one else, and only you can do it. Our first big event was TechTrain. On June 6 at 2 am, we had not yet rolled out the production environment, it was rolled out by Kolya. And the personal account did not work as an authorization server for OAuth2.0. We've turned it into an OAuth2.0 provider to connect the platform to. I worked for probably 18 hours in a row, looked at the computer and didn’t see anything, didn’t understand why it wasn’t working, and remotely Kolya looked at my code, looked for a bug in the Spring configuration, found it, and the LC worked, and in production too.
Nikolai: And an hour before TechTrain the release took place.
There are a lot of stars here. We were extremely lucky, because we had just a super team, and everyone was driven by the idea of doing it online. All these three months we were driven by the fact that we were "doing YouTube". I did not allow myself to tear my hair, but I told everyone that everything would work out, because in fact everything had been calculated long ago.
About performance
— Can you tell us the maximum number of people on the site on one track? Were there performance issues?
Nikolai: There were no performance problems, as we have already said. The maximum number of people who were at one report is 1300 people, this is on Heisenbug.
— Were there any problems with local viewing? And is it possible to have a technical description with diagrams of how it all works?
Nikolai: We will make an article about this later.
Locally, you can even debug streams. As soon as the conferences started, it became even easier because there were production streams that we can watch all the time.
Vladimir: As I understand it, front-end developers worked locally with mocks, and then, since the time to roll out to the devs in the front is also short (5 minutes), there are no problems to see what's going on with the certificates.
— Everything is tested, debugged, even locally. So, we will write an article with all the technical features, show, tell everything with diagrams, as it was.
Vladimir: You can take and repeat.
- For 3 months.
Сonclusion
— Everything described together sounds cool, given that it was done by a small team in three months.
Nikolai: A big team wouldn't do that. But a small group of people who communicate quite closely and well with each other and can come to an agreement could. They do not have any contradictions, the architecture was invented in two days, was finalized and has not actually changed. There is a very tough facilitation of incoming business requirements in terms of heaping feature requests and changes.
- What was on your list of further tasks when the summer conferences were already held?
Nikolai: For example, titles. Scrolling lines on the video, pop-ups in some places of the video, depending on the display of content. For example, a speaker wants to ask a question to the audience, and a voting box pops up on the screen, which goes back to the back according to the voting results to the speaker himself. Some kind of social activity in the form of likes, hearts, ratings of the report during the presentation itself, so that you can, without being distracted later by feedback forms, fill in the feedback at the right second. Initially like this.
And adding the entire platform, except for streaming and conference, is also a post-conference state. These are playlists (including those compiled by users), possibly content from other past conferences, integrated, marked, available to the user, and also available for viewing on our website ().
Guys, thank you very much for your answers!
If there are those among the readers who were at our summer conferences, please share your impressions of the player and the broadcast. What was convenient, what annoyed you, what do you want to see in the future?
If the platform is of interest and you want to see it "in battle" - we use it again on our . There are a number of them, so there is almost certainly one for you.
Source: habr.com
