

In the previous article, I talked about the basics of DATA VAULT, described the main elements of DATA VAULT and their purpose. At this point, the topic of DATA VAULT cannot be considered exhausted, it is necessary to talk about the next steps in the evolution of DATA VAULT.
And in this article, I will focus on the development of DATA VAULT and the transition to BUSINESS DATA VAULT or simply BUSINESS VAULT.
Reasons for the emergence of BUSINESS DATA VAULT
It should be noted that DATA VAULT, having certain strengths, is not without its shortcomings. One of these drawbacks is the difficulty in writing analytical queries. Queries have a significant number of JOINs, the code is long and cumbersome. Also, the data that enters the DATA VAULT is not subject to any transformations, therefore, from a business point of view, DATA VAULT in its pure form has no unconditional value.
It is to eliminate these shortcomings that the DATA VAULT methodology was expanded with such elements as:
- PIT (point in time) tables;
- BRIDGE tables;
- PREDEFINED DERIVATIONS.
Let's take a closer look at the purpose of these elements.
PIT tables
As a rule, one business object (HUB) can contain data with different update rates, for example, if we are talking about data characterizing a person, we can say that information about a phone number, address or email has a higher update rate than say, full name, passport details, marital status or gender.
Therefore, when determining satellites, one should keep in mind the frequency of their renewal. Why is it important?
If you store attributes with different update rates in the same table, you will have to add a row to the table every time the most frequently changed attribute is updated. As a result, there is an increase in the amount of disk space, an increase in the execution time of queries.
Now that we have separated the satellites by update rate, and we can load data into them independently, we need to ensure that we can get up-to-date data. Better without using unnecessary JOINs.
Let me explain, for example, you need to get up-to-date (by the date of the last update) information from satellites with different update rates. To do this, you will need not only to make a JOIN, but also to create several nested queries (for each satellite containing information) with a choice of the maximum update date MAX (Update date). With each new JOIN, such code grows, and very quickly becomes difficult to understand.
The PIT table is designed to simplify such queries, PIT tables are filled simultaneously with writing new data to the DATA VAULT. PIT table:
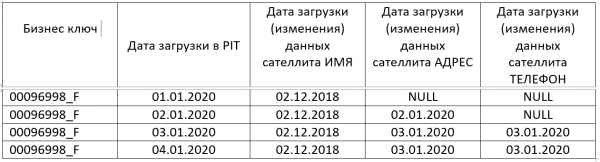
Thus, we have information about the relevance of data for all satellites at each point in time. Using JOINs on the PIT table, we can completely eliminate nested queries, of course with the condition that the PIT is filled every day and without gaps. Even if there are gaps in the PIT, you can only get up-to-date data using one nested query to the PIT itself. One nested query will work faster than nested queries for each satellite.
BRIDGE
BRIDGE tables are also used to simplify analytical queries. However, the difference from PIT is a means of simplifying and speeding up requests between various hubs, links and their satellites.
The table contains all the necessary keys for all satellites that are often used in queries. In addition, if necessary, hashed business keys can be supplemented with keys in text form, if the names of the keys are needed for analysis.
The fact is that without using BRIDGE, in the process of obtaining data located in satellites belonging to different hubs, it will be necessary to JOIN not only the satellites themselves, but also the links connecting the hubs.
The presence or absence of BRIDGE is determined by the storage configuration, the need to optimize the speed of query execution. It is difficult to come up with a universal example of BRIGE.
PREDEFINED DERIVATIONS
Another type of objects that brings us closer to BUSINESS DATA VAULT are tables containing pre-calculated indicators. Such tables are really important for business, they contain information aggregated according to given rules and make it relatively easy to access.
Architecturally, PREDEFINED DERIVATIONS are nothing more than another satellite of a certain hub. It, like a regular satellite, contains a business key and the date the record was created in the satellite. This, however, is where the similarities end. The further composition of the attributes of such a "specialized" satellite is determined by business users based on the most popular, pre-calculated indicators.
For example, a hub containing information about an employee may include a satellite with indicators such as:
- Minimum wage;
- Maximum salary;
- Average salary;
- Cumulative total of accrued wages, etc.
It is logical to include PREDEFINED DERIVATIONS in the PIT table of the same hub, then you can easily get employee data slices for a specific date.
CONCLUSIONS
As practice shows, the use of DATA VAULT by business users is somewhat difficult for several reasons:
- The query code is complex and cumbersome;
- The abundance of JOINs affects query performance;
- Writing analytical queries requires an outstanding knowledge of the warehouse structure.
To simplify data access, DATA VAULT is extended with additional objects:
- PIT (point in time) tables;
- BRIDGE tables;
- PREDEFINED DERIVATIONS.
Next I plan to tell, in my opinion, the most interesting for those who work with BI. I will present ways to create tables - facts and tables - dimensions based on DATA VAULT.
The materials of the article are based on:
- For Kenta Graziano, which, in addition to a detailed description, contains model diagrams;
- Book: "Building a Scalable Data Warehouse with DATA VAULT 2.0";
- Article .
Source: habr.com
