

 The InterSystems IRIS DBMS supports interesting structures for storing data - globals. In fact, these are multi-level keys with various additional goodies in the form of transactions, quick functions for bypassing data trees, locks, and their own ObjectScript language.
The InterSystems IRIS DBMS supports interesting structures for storing data - globals. In fact, these are multi-level keys with various additional goodies in the form of transactions, quick functions for bypassing data trees, locks, and their own ObjectScript language.
Read more about globals in the series of articles "Globals - Swords-Treasurers for Data Storage":
It became interesting to me how transactions are implemented in globals, what features there are. After all, this is a completely different structure for storing data than the usual tables. Much lower level.
As is known from the theory of relational databases, a good implementation of transactions must satisfy the requirements :
A - Atomic (atomicity). All changes made in the transaction or none at all are recorded.
C - Consistency (consistency). After the transaction is completed, the logical state of the database must be internally consistent. In many ways, this requirement applies to the programmer, but in the case of SQL databases, it also applies to foreign keys.
I - Isolate (isolation). Transactions running in parallel should not affect each other.
D - Durable (durability). After the successful completion of the transaction, problems at the lower levels (power failure, for example) should not affect the data modified by the transaction.
Globals are non-relational data structures. They were designed to run super fast on very limited hardware. Let's understand the implementation of transactions in globals using .
To support transactions in IRIS, the following commands are used: , , .
1. Atomicity
The easiest way to check atomicity. We check from the database console.
Kill ^a
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TCOMMITThen we conclude:
Write ^a(1), “ ”, ^a(2), “ ”, ^a(3)We get:
1 2 3Everything is fine. Atomicity is observed: all changes are recorded.
Let's complicate the task, introduce an error and see how the transaction is saved, partially or not at all.
Let's check the atomicity again:
Kill ^A
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3After that, we forcibly stop the container, run it and see.
docker kill my-irisThis command is almost equivalent to forcibly shutting down the power, as it sends a SIGKILL signal to stop the process immediately.
Maybe the transaction was saved partially?
WRITE ^a(1), ^a(2), ^a(3)
^
<UNDEFINED> ^a(1)- No, it hasn't survived.
Let's test the rollback command:
Kill ^A
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TROLLBACK
WRITE ^a(1), ^a(2), ^a(3)
^
<UNDEFINED> ^a(1)Nothing has survived either.
2. Consistency
Since in databases on globals, keys are also made on globals (let me remind you that a global is a lower-level structure for storing data than a relational table), to fulfill the consistency requirement, you need to include a key change in the same transaction as changing the global.
For example, we have a ^person global in which we store personalities and we use the TIN as a key.
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
...In order to have a quick search by last name and first name, we made the ^index key.
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1In order for the base to be consistent, we must add personalities like this:
TSTART
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1
TCOMMITAccordingly, when deleting, we must also use a transaction:
TSTART
Kill ^person(1234567)
ZKill ^index(‘Kamenev’, ‘Sergey’, 1234567)
TCOMMITIn other words, the implementation of the requirement of consistency lies entirely on the shoulders of the programmer. But when it comes to globals, this is normal, due to their low-level nature.
3. Isolation
This is where the mess starts. Many users simultaneously work on the same database, change the same data.
The situation is comparable to when many users simultaneously work with the same repository with code and try to commit changes to it in many files at the same time.
The database should sort it all out in real time. Considering that in serious companies there is even a special person who is responsible for version control (for merging branches, resolving conflicts, etc.), and the database must do all this in real time, the complexity of the task and the correct design of the database become obvious and the code that serves it.
The database cannot understand the meaning of the actions performed by users in order to avoid conflicts if they work on the same data. It can only reverse one transaction that conflicts with another, or execute them sequentially.
Another problem is that during the execution of a transaction (before the commit), the state of the database may be inconsistent, so it is desirable that other transactions do not have access to the inconsistent state of the database, which is achieved in relational databases in many ways: creating snapshots, multi-version rows, and etc.
When transactions are executed in parallel, it is important for us that they do not interfere with each other. This is the property of isolation.
SQL defines 4 levels of isolation:
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
Let's consider each level separately. The cost of implementing each level grows almost exponentially.
READ UNCOMMITTED - this is the lowest level of isolation, but at the same time the fastest. Transactions can read changes made by each other.
READ COMMITTED is the next level of isolation, which is a compromise. Transactions cannot read each other's changes before the commit, but they can read any changes made after the commit.
If we have a long transaction T1, during which there were commits in transactions T2, T3 ... Tn, which worked with the same data as T1, then when we request data in T1, we will receive a different result each time. This phenomenon is called non-repeatable reading.
REPEATABLE READ - in this isolation level, we do not have the phenomenon of non-repeatable reading, due to the fact that for each request to read data, a snapshot of the result data is created and, when reused in the same transaction, data from the snapshot is used. However, it is possible to read phantom data in this isolation level. This refers to reading new rows that have been added by concurrent committed transactions.
SERIALIZABLE - the highest level of isolation. It is characterized by the fact that data in any way used in a transaction (reading or changing) becomes available to other transactions only after the completion of the first transaction.
To begin with, let's figure out whether there is isolation of operations in a transaction from the main thread. Let's open 2 terminal windows.
Kill ^t
Write ^t(1)
2
TSTART
Set ^t(1)=2There is no isolation. One thread sees what the second one who opened the transaction is doing.
Let's see if transactions of different threads see what is happening inside them.
Let's open 2 terminal windows and open 2 transactions in parallel.
kill ^t
TSTART
Write ^t(1)
3
TSTART
Set ^t(1)=3
Parallel transactions see each other's data. So, we got the simplest, but also the fastest READ UNCOMMITED isolation level.
In principle, this could be expected for globals, for which speed has always been at the forefront.
What if we need a higher level of isolation in operations on globals?
Here you need to think about why isolation levels are needed at all and how they work.
The highest isolation level SERIALIZE means that the result of transactions executed in parallel is equivalent to their serial execution, which guarantees the absence of collisions.
We can do this with the help of smart locks in ObjectScript, which have a lot of different uses: you can do regular, incremental, multiple locks with the command .
Lower isolation levels are trade-offs designed to increase the speed of the database.
Let's see how we can achieve different levels of isolation using locks.
This operator allows you to take not only exclusive locks needed to change data, but the so-called shared locks, which can be taken in parallel by several threads at once when they need to read data that should not be changed by other processes in the process of reading.
More about the two-phase blocking method in Russian and English:
→
→
The difficulty is that during a transaction, the state of the database can be inconsistent, but this inconsistent data is visible to other processes. How to avoid it?
With the help of locks, we will make such windows of visibility in which the state of the base will be consistent. And all accesses to such consistent state visibility windows will be controlled by locks.
Shared locks on the same data are reusable - they can be taken by several processes. These locks prevent other processes from modifying the data, i.e. they are used to form windows of the consistent state of the database.
Exclusive locks are used to modify data - only one process can take such a lock. An exclusive lock can be taken by:
- Any process as long as the data is free
- Only the process that has a shared lock on this data and was the first to request an exclusive lock.
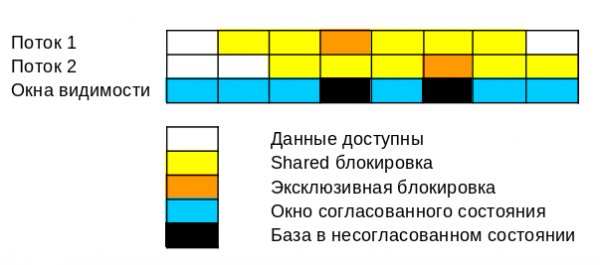
The narrower the visibility window, the longer other processes have to wait for it, but the more consistent the state of the database in it can be.
READ_COMMITTED - the essence of this level is that we see only committed data from other threads. If the data in another transaction is not yet committed, then we see their old version.
This allows us to parallelize work instead of waiting for a lock to be released.
Without special tricks, we will not be able to see the old version of the data in IRIS, so we will have to make do with locks.
Accordingly, we will have to use shared locks to allow data to be read only at moments of consistency.
Let's say we have a user base ^person who transfer money to each other.
Moment of transfer from person 123 to person 242:
LOCK +^person(123), +^person(242)
Set ^person(123, amount) = ^person(123, amount) - amount
Set ^person(242, amount) = ^person(242, amount) + amount
LOCK -^person(123), -^person(242)The moment of requesting the amount of money from person 123 before debiting must be accompanied by an exclusive lock (by default):
LOCK +^person(123)
Write ^person(123)And if you need to show the account status in your personal account, then you can use a shared lock or not use it at all:
LOCK +^person(123)#”S”
Write ^person(123)However, if we assume that database operations are performed almost instantly (let me remind you that globals are a much lower-level structure than a relational table), then the need for this level drops.
REPEATABLE READ - in this isolation level it is allowed that there can be several readings of data that can be changed by parallel transactions.
Accordingly, we will have to set a shared lock on reading the data that we are changing and exclusive locks on the data that we are changing.
Fortunately, the LOCK operator allows you to list in detail all the necessary locks in one operator, of which there can be a lot.
LOCK +^person(123, amount)#”S”
чтение ^person(123, amount)other operations (during this time parallel threads try to change ^person(123, amount) but cannot)
LOCK +^person(123, amount)
изменение ^person(123, amount)
LOCK -^person(123, amount)
чтение ^person(123, amount)
LOCK -^person(123, amount)#”S”When listing locks separated by commas, they are taken sequentially, and if you do this:
LOCK +(^person(123),^person(242))then they are taken atomically all at once.
SERIALIZE - we will have to set locks so that eventually all transactions that have common data are performed sequentially. For this approach, most locks should be exclusive and taken on the smallest areas of the global for performance.
If we talk about write-offs in the ^person global, then only the SERIALIZE isolation level is acceptable for it, since money must be spent strictly sequentially, otherwise it is possible to spend the same amount several times.
4. Durability
I've been testing hard punching the container with
docker kill my-irisThe base tolerated them well. No problems were identified.
Conclusion
For globals, InterSystems IRIS has transaction support. They are really atomic, reliable. To ensure the consistency of the database on globals, the efforts of the programmer and the use of transactions are necessary, since it does not have complex built-in structures such as foreign keys.
The isolation level for globals without using locks is READ UNCOMMITED, and when using locks, it can be provided up to the SERIALIZE level.
The correctness and speed of transactions on globals very much depends on the skill of the programmer: the more widely shared locks are used when reading, the higher the isolation level, and the more narrowly exclusive locks are taken, the faster the performance.
Source: habr.com
