

VictoriaMetrics, TimescaleDB and InfluxDB have been compared in over a dataset with a billion data points belonging to 40K unique time series.
A few years ago was the era of Zabbix. Each bare metal server had no more than a few metrics - CPU usage, RAM usage, disk usage, and network usage. Thus, metrics from thousands of servers can fit into 40 thousand unique time series, and Zabbix can use MySQL as a backend for time series data 🙂
Currently one with default configurations provides over 500 metrics on an average host. There are many for various databases, web servers, hardware systems, etc. All provide many useful metrics. All begin to exhibit various indicators on themselves. There is Kubernetes with clusters and pods that expose a lot of metrics. This causes servers to expose thousands of unique metrics per host. So the unique 40K time series is no longer high power. It's becoming mainstream, which should be easily handled by any modern TSDB on a single server.
What is a large number of unique time series at the moment? Probably 400K or 4M? Or 40m? Let's compare modern TSDBs with these numbers.
Benchmark installation
is a great benchmarking tool for TSDBs. It allows you to generate an arbitrary number of metrics by passing the required number of time series divided by 10 - flag (former -scale-var). 10 is the number of measurements (metrics) generated on each host, server. The following datasets were created using TSBS for benchmarking:
- 400K unique time series, 60 second interval between data points, data spans a full 3 days, ~1.7B total number of data points.
- 4M unique time series, 600 second interval, data spans a full 3 days, ~1.7B total data points.
- 40M unique time series, 1 hour interval, data spans a full 3 days, ~2.8B total number of data points.
The client and server were running on dedicated instances in the Google cloud. These instances had the following configurations:
- vCPUs: 16
- RAM: 60 GB
- Storage: Standard 1TB hard drive. It provides 120Mbps read/write throughput, 750 reads per second, and 1,5K writes per second.
The TSDBs have been pulled from the official docker images and run on docker with the following configurations:
VictoriaMetrics:
docker run -it --rm -v /mnt/disks/storage/vmetrics-data:/victoria-metrics-data -p 8080:8080 valyala/victoria-metricsInfluxDB (-e) values are required to support high cardinality. See details in ):
docker run -it --rm -p 8086:8086 -e INFLUXDB_DATA_MAX_VALUES_PER_TAG=4000000 -e INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=100g -e INFLUXDB_DATA_MAX_SERIES_PER_DATABASE=0 -v /mnt/disks/storage/influx-data:/var/lib/influxdb influxdbTimescaleDB (config was taken from file):
MEM=`free -m | grep "Mem" | awk ‘{print $7}’`
let "SHARED=$MEM/4"
let "CACHE=2*$MEM/3"
let "WORK=($MEM-$SHARED)/30"
let "MAINT=$MEM/16"
let "WAL=$MEM/16"
docker run -it — rm -p 5432:5432
--shm-size=${SHARED}MB
-v /mnt/disks/storage/timescaledb-data:/var/lib/postgresql/data
timescale/timescaledb:latest-pg10 postgres
-cmax_wal_size=${WAL}MB
-clog_line_prefix="%m [%p]: [%x] %u@%d"
-clogging_collector=off
-csynchronous_commit=off
-cshared_buffers=${SHARED}MB
-ceffective_cache_size=${CACHE}MB
-cwork_mem=${WORK}MB
-cmaintenance_work_mem=${MAINT}MB
-cmax_files_per_process=100The data loader was started with 16 parallel threads.
This article only contains results for insert benchmarks. The results of the selective benchmark will be published in a separate article.
400K unique time series
Let's start with simple elements - 400K. Benchmark results:
- VictoriaMetrics: 2,6M data points per second; RAM usage: 3 GB; final data size on disk: 965 MB
- InfluxDB: 1.2M data points per second; RAM usage: 8.5 GB; final data size on disk: 1.6 GB
- Timescale: 849K data points per second; RAM usage: 2,5 GB; final data size on disk: 50 GB
As you can see from the results above, VictoriaMetrics wins in insert performance and compression ratio. The timeline wins in RAM usage, but it uses a lot of disk space - 29 bytes per data point.
Below are graphs of CPU usage for each of the TSDBs during the benchmark:
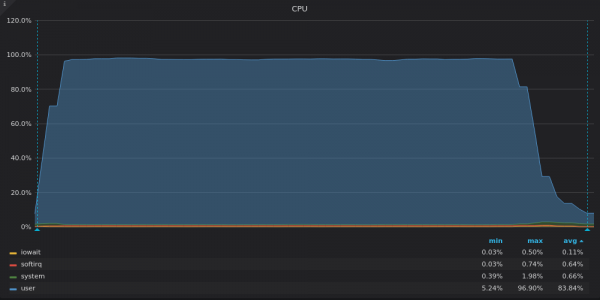
Above screenshot: VictoriaMetrics - Insert test CPU usage for 400K unique metric.
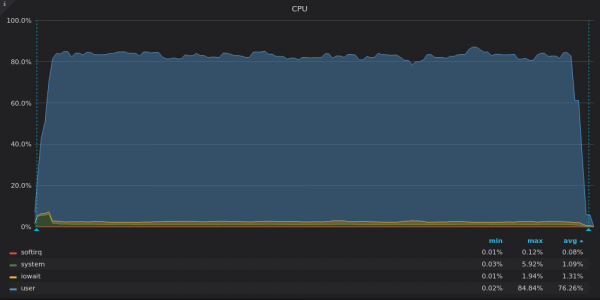
Above screenshot: InfluxDB - CPU usage on insert test for 400K unique metric.
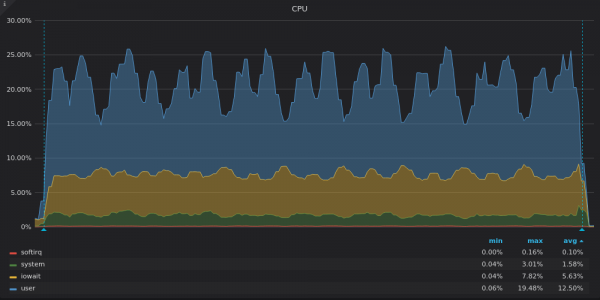
Above screenshot: TimescaleDB - CPU usage on insert test for 400K unique metric.
VictoriaMetrics uses all available vCPUs while InfluxDB underutilizes ~2 out of 16 vCPUs.
Timescale only uses 3-4 out of 16 vCPUs. The high proportions of iowait and system in the TimescaleDB timescale graph indicate a bottleneck in the input/output (I/O) subsystem. Let's look at the disk bandwidth usage graphs:
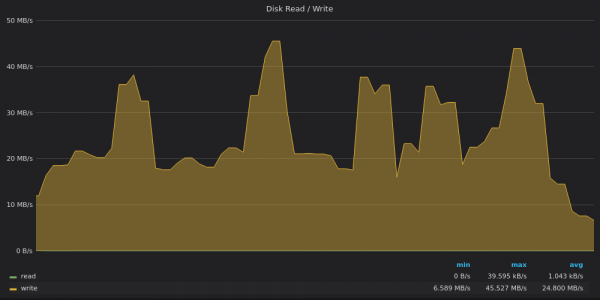
Above screenshot: VictoriaMetrics - Insert Test Disk Bandwidth Usage for 400K unique metrics.
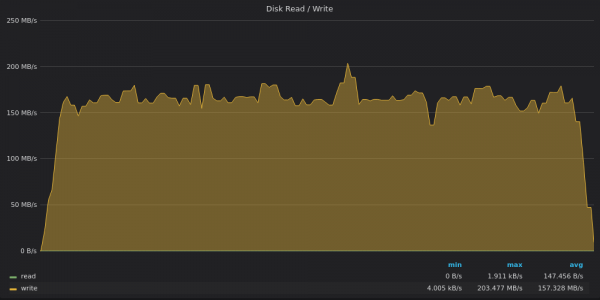
Above screenshot: InfluxDB - Insert Test Disk Bandwidth Usage for 400K unique metrics.
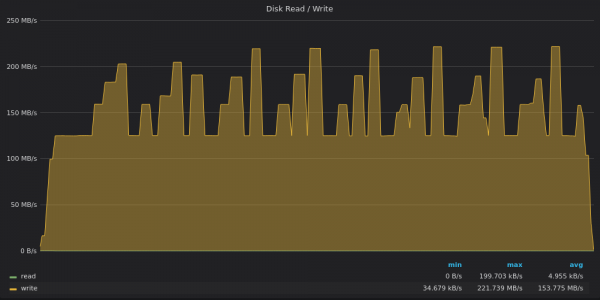
Above screenshot: TimescaleDB - Insert Test Disk Bandwidth Usage for 400K unique metrics.
VictoriaMetrics records data at 20Mbps with peaks up to 45Mbps. Peaks correspond to large partial merges in the tree .
InfluxDB writes data at 160MB/s while a 1TB disk write bandwidth of 120 MB/s.
TimescaleDB is limited to 120Mbps write throughput, but sometimes it breaks that limit and peaks at 220Mbps. These peaks correspond to the underutilization dips in the previous graph.
Let's look at the I/O usage graphs:
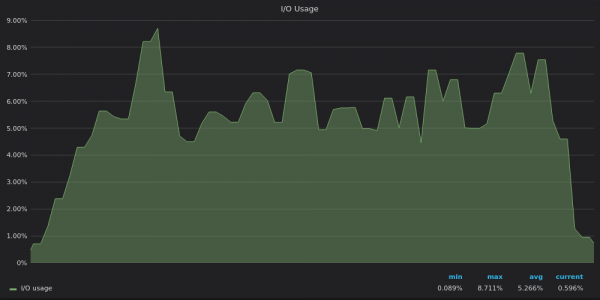
Above screenshot: VictoriaMetrics - Insert test I/O usage for 400K unique metrics.
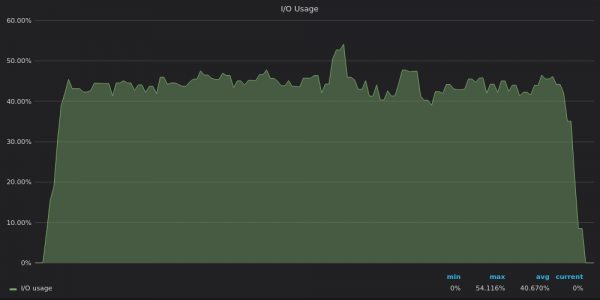
Above screenshot: InfluxDB - Insert test I/O usage for 400K unique metrics.
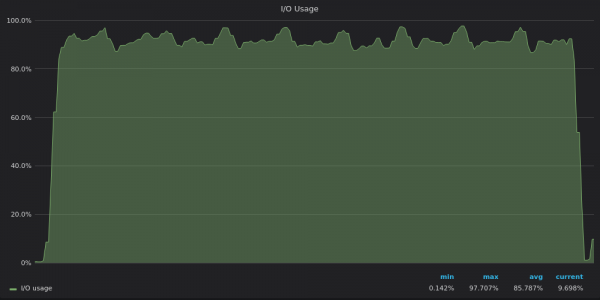
Above screenshot: TimescaleDB - Insert test I/O usage for 400K unique metrics.
Now it's clear that TimescaleDB is hitting the I/O limit so it can't use the remaining 12 vCPUs.
4M unique time series
4M time series look a bit defiant. But our competitors successfully pass this exam. Benchmark results:
- VictoriaMetrics: 2,2M data points per second; RAM usage: 6 GB; final data size on disk: 3 GB.
- InfluxDB: 330K data points per second; RAM usage: 20,5 GB; final data size on disk: 18,4 GB.
- TimescaleDB: 480K data points per second; RAM usage: 2,5 GB; final data size on disk: 52 GB.
InfluxDB performance dropped from 1,2M data points per second for a 400K time series to 330K data points per second for a 4M time series. This is a significant performance loss compared to other competitors. Let's look at the CPU usage graphs to understand the root cause of this loss:
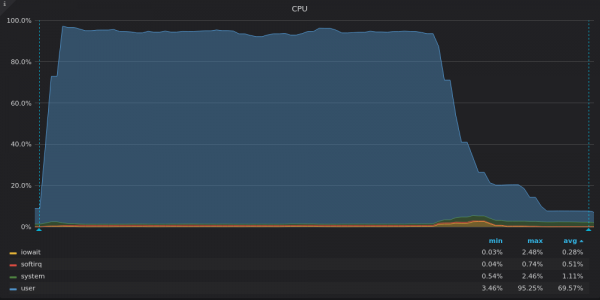
Above screenshot: VictoriaMetrics - Insert Test CPU Usage for Unique 4M Time Series.
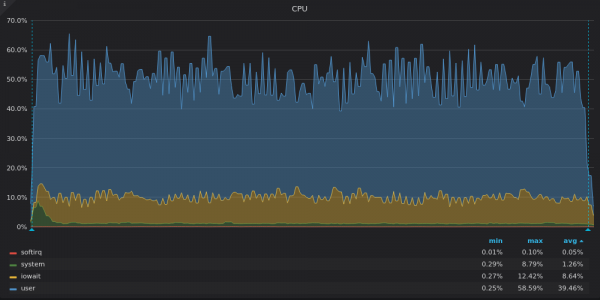
Above screenshot: InfluxDB - Insert Test CPU Usage for 4M Unique Time Series.
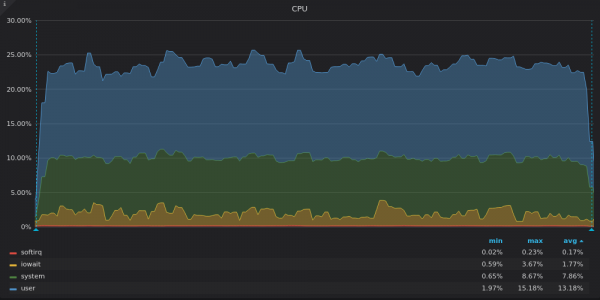
Above screenshot: TimescaleDB - Insert Test CPU Usage for Unique 4M Time Series.
VictoriaMetrics uses almost all of the processing power (CPU). The drop at the end corresponds to the remaining LSM merges after inserting all the data.
InfluxDB only uses 8 out of 16 vCPUs while TimsecaleDB uses 4 out of 16 vCPUs. What do their charts have in common? high share iowait, which again indicates an I/O bottleneck.
TimescaleDB has a high share system. We believe that high power has led to many system calls or to many .
Let's look at the disk bandwidth graphs:
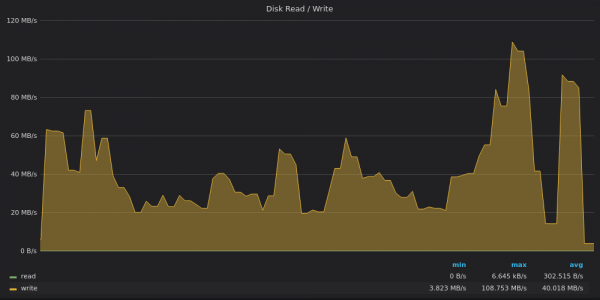
Above screenshot: VictoriaMetrics - Disk bandwidth usage to insert 4M unique metrics.
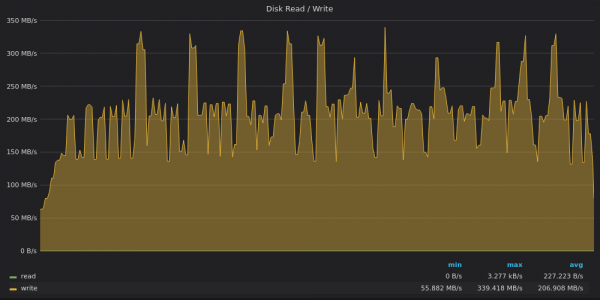
Above screenshot: InfluxDB - Disk bandwidth usage to insert 4M unique metrics.
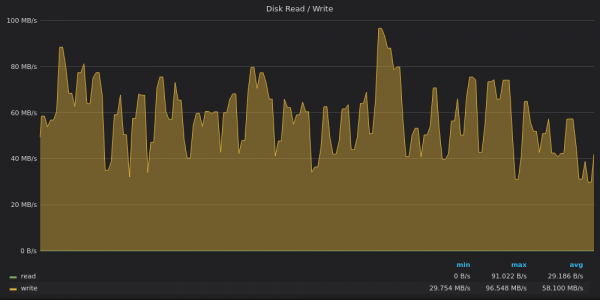
Above screenshot: TimescaleDB - Disk bandwidth usage to insert 4M unique metrics.
VictoriaMetrics peaked at 120MB/s while average write speed was 40MB/s. There were probably several heavy LSM merges performed during the peak.
InfluxDB is again squeezing out an average write throughput of 200MB/s with peaks up to 340MB/s on a disk with a 120MB/s write limit :)
TimescaleDB is no longer disk-limited. It looks like it's limited by something else related to the high proportion системной CPU load.
Let's look at the IO usage graphs:
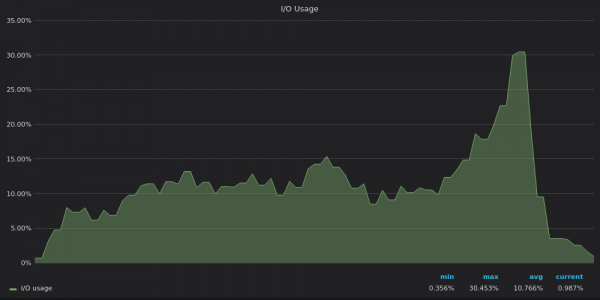
Above screenshot: VictoriaMetrics - Using I/O during insertion test for 4M unique time series.
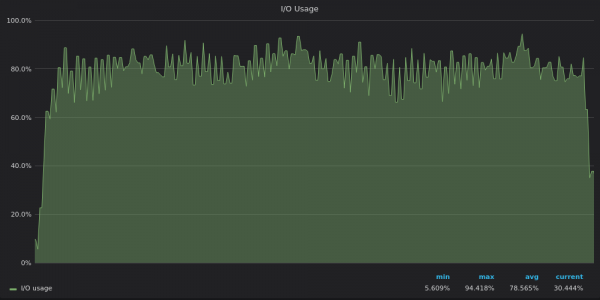
Above screenshot: InfluxDB - I/O usage during insert test for 4M unique time series.
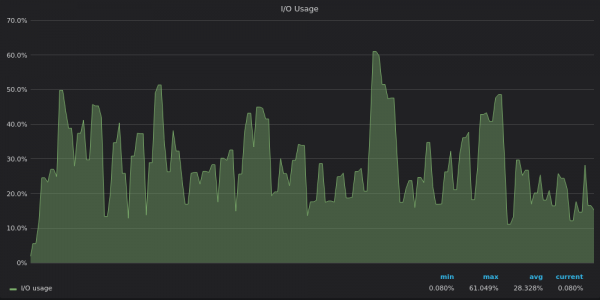
Above screenshot: TimescaleDB - I/O usage during insert test for 4M unique time series.
The IO usage graphs mirror the disk bandwidth usage graphs - InfluxDB is IO limited, while VictoriaMetrics and TimescaleDB have spare IO IO resources.
40M unique time series
40M unique time series was too big for InfluxDB 🙁
Benchmark results:
- VictoriaMetrics: 1,7M data points per second; RAM usage: 29 GB; disk space usage: 17 GB.
- InfluxDB: Didn't finish because it required over 60GB of RAM.
- TimescaleDB: 330K data points per second, RAM usage: 2,5 GB; disk space usage: 84GB.
TimescaleDB shows exceptionally low and stable RAM usage of 2,5GB, the same as for the unique 4M and 400K metrics.
VictoriaMetrics slowly increased at a rate of 100k data points per second until all 40M labeled metric names were processed. It then achieved a steady insertion rate of 1,5-2,0M data points per second, so that the end result was 1,7M data points per second.
The plots for 40M unique time series are similar to those for 4M unique time series, so let's skip those.
Conclusions
- Modern TSDBs are capable of handling inserts for millions of unique time series on a single server. In the next article, we will test how well TSDBs perform selection over millions of unique time series.
- Insufficient CPU utilization usually indicates an I/O bottleneck. In addition, it may indicate too rough blocking, when only a few threads can work at the same time.
- The I/O bottleneck does exist, especially in non-SSD storage such as cloud providers' virtualized block devices.
- VictoriaMetrics provides the best optimization for slow, low I/O storage. It provides the best speed and the best compression ratio.
Download and try it on your data. The corresponding static binary is available at .
Read more about VictoriaMetrics in this .
Update: published with reproducible results.
Update #2: Read also .
Update #3: !
Telegram chat:
Source: habr.com
