

Pavel Selivanov, Southbridge solution architect and Slurm teacher, gave a talk at DevOpsConf 2019. This talk is part of one of the topics of the Slurm Mega advanced Kubernetes course.
takes place in Moscow on November 18-20.
- Moscow, November 22-24.
always available.

Under the cut - transcript of the report.
Good afternoon, colleagues and sympathizers. Today I will talk about security.
I see that there are a lot of security people in the hall today. I apologize in advance to you if I use terms from the world of security not quite the way you usually do.
It so happened that about six months ago, one public Kubernetes cluster fell into my hands. Public - means that there are n-th number of namespaces, in these namespaces there are users isolated in their namespace. All these users belong to different companies. Well, it was assumed that this cluster should be used as a CDN. That is, they give you a cluster, give a user there, you go there in your namespace, deploy your fronts.
My previous company tried to sell such a service. And I was asked to poke the cluster on the subject - whether such a solution is suitable or not.
I came to this cluster. I was given limited rights, limited namespace. There, the guys understood what security is. They read what Role-based access control (RBAC) is in Kubernetes - and they twisted it so that I could not run pods separately from deployments. I don't remember the problem I was trying to solve by running a pod without deployment, but I really wanted to run just a pod. I decided for luck to see what rights I have in the cluster, what I can, what I can’t, what they screwed up there. At the same time, I'll tell you what they have configured incorrectly in RBAC.
It so happened that in two minutes I got an admin to their cluster, looked at all the neighboring namespaces, saw the production fronts of companies that had already bought the service and deployed there. I barely stopped myself so as not to come to someone in the front and put some swear words on the main page.
I will tell you with examples how I did it and how to defend against it.
But first, let me introduce myself. My name is Pavel Selivanov. I am an architect for Southbridge. I understand Kubernetes, DevOps and all sorts of fancy stuff. The Southbridge engineers and I are building it all, and I am consulting.
In addition to our main activities, we have recently launched projects called Slurms. We are trying to bring our ability to work with Kubernetes to the masses a little, to teach other people how to work with K8s too.
What will I talk about today. The topic of the report is obvious - about the security of the Kubernetes cluster. But I want to say right away that this topic is very large - and therefore I want to specify right away what I will definitely not talk about. I will not talk about hackneyed terms that have already been overused a hundred times on the Internet. Any RBAC and certificates.
I will talk about what hurts me and my colleagues from security in a Kubernetes cluster. We see these problems both with providers who provide Kubernetes clusters and with clients who come to us. And even for clients who come to us from other consulting admin companies. That is, the scale of the tragedy is very large in fact.
Literally three points that I will talk about today:
- User rights vs pod rights. User rights and pod rights are not the same thing.
- Collection of information about the cluster. I will show that you can collect all the information that you need from a cluster without having special rights in this cluster.
- DoS attack on the cluster. If we fail to collect information, we will be able to put the cluster in any case. I will talk about DoS attacks on cluster control elements.
Another general thing that I will mention is what I tested it all on, on which I can say for sure that it all works.
As a basis, we take the installation of a Kubernetes cluster using Kubespray. If someone does not know, this is actually a set of roles for Ansible. We use it all the time at work. The good thing is that you can roll anywhere - and you can roll on the pieces of iron, and somewhere in the cloud. One installation method is suitable in principle for everything.
In this cluster, I will have Kubernetes v1.14.5. The entire Cube cluster, which we will consider, is divided into namespaces, each namespace belongs to a separate team, members of this team have access to each namespace. They cannot go to different namespaces, only to their own. But there is a certain admin account that has rights to the entire cluster.
I promised that the first thing we will have is obtaining admin rights to the cluster. We need a specially prepared pod that will break the Kubernetes cluster. All we need to do is apply it to the Kubernetes cluster.
kubectl apply -f pod.yamlThis pod will come to one of the masters of the Kubernetes cluster. And the cluster will happily return a file called admin.conf after that. In Cuba, this file stores all admin certificates, and at the same time the cluster API is configured. This is how easy it is to get admin access, I think, to 98% of Kubernetes clusters.
Again, this pod was made by one developer in your cluster, who has access to deploy their proposals into one small namespace, he is all clamped by RBAC. He didn't have any rights. But nevertheless the certificate returned.
Now let's talk about a specially prepared pod. We can run it on any image. Let's take this as an example. debian:jessie.
We have something like this:
tolerations:
- effect: NoSchedule
operator: Exists
nodeSelector:
node-role.kubernetes.io/master: "" What is tolerance? Masters in a Kubernetes cluster are usually labeled with a thing called taint. And the essence of this “infection” is that it says that pods cannot be assigned to master nodes. But no one bothers to indicate in any pod that it is tolerant of the “infection”. The Toleration section just says that if NoSchedule is installed on some node, then our pod is tolerant to such an infection - and there are no problems.
Further, we say that our pod is not only tolerant, but also wants to hit the master on purpose. Because the masters have the most delicious thing that we need - all the certificates. Therefore, we say nodeSelector - and we have a standard label on the masters, which allows you to select from all the nodes of the cluster exactly those nodes that are masters.
With these two sections, it will definitely come to the master. And he will be allowed to live there.
But just coming to the master is not enough for us. It won't give us anything. So next we have these two things:
hostNetwork: true
hostPID: true We specify that our pod we are running will live in the kernel namespace, the network namespace, and the PID namespace. Once a pod is running on the master, it will be able to see all the real, live interfaces of that node, listen to all traffic, and see the PIDs of all processes.
Then it's up to the little things. Take etcd and read what you want.
The most interesting thing is this Kubernetes feature, which is there by default.
volumeMounts:
- mountPath: /host
name: host
volumes:
- hostPath:
path: /
type: Directory
name: host And its essence is that we can, in the pod that we launch, even without rights to this cluster, say that we want to create a volume of the hostPath type. So take the path from the host on which we will start - and take it as volume. And then we call it name: host. We mount all this hostPath inside the pod. In this example, to the /host directory.
Once again I will repeat. We told the pod to come to the master, get hostNetwork and hostPID there - and mount the entire root of the master inside this pod.
You understand that in debian we have bash running, and this bash works for us as root. That is, we just got root on the master, while not having any rights in the Kubernetes cluster.
Then the whole task is to go into the directory / host / etc / kubernetes / pki, if I’m not mistaken, pick up all the cluster’s master certificates there and, accordingly, become the cluster admin.
When viewed this way, these are some of the most dangerous rights in pods, regardless of what rights the user has:
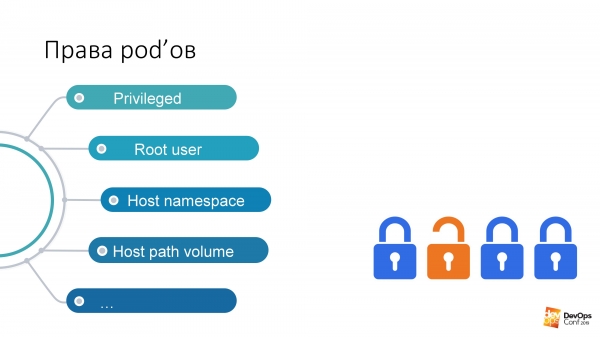
If I have rights to run a pod in some cluster namespace, then this pod has these rights by default. I can run privileged pods, which is generally all rights, practically rooting a node.
My favorite is Root user. And Kubernetes has this Run As Non-Root option. This is a type of protection against a hacker. Do you know what the “Moldovan virus” is? If you are suddenly a hacker and came to my Kubernetes cluster, then we, poor administrators, ask: “Please indicate in your pods with which you will hack my cluster, run as non-root. Otherwise, it will turn out that you start the process in your pod under the root, and it will be very easy for you to hack me. Protect yourself, please."
Host path volume - in my opinion, the fastest way to get the desired result from the Kubernetes cluster.
But what to do with all this?
Thoughts that should come to any normal administrator who encounters Kubernetes: “Yeah, I told you, Kubernetes does not work. It has holes in it. And the whole Cube is bullshit.” In fact, there is such a thing as documentation, and if you look there, then there is a section .
This is such a yaml object - we can create it in the Kubernetes cluster - which controls the security aspects in the description of the pods. That is, in fact, it controls the rights to use any hostNetwork, hostPID, certain volume types that are in the pods at startup. With the help of Pod Security Policy, all this can be described.
The most interesting thing about the Pod Security Policy is that in the Kubernetes cluster, all PSP installers are not just not described in any way, they are simply turned off by default. Pod Security Policy is enabled using the admission plugin.
Okay, let's deploy Pod Security Policy to the cluster, let's say that we have some service pods in the namespace, to which only admins have access. Let's say, in all the rest, pods have limited rights. Because most likely developers don't need to run privileged pods on your cluster.
And we seem to be fine. And our Kubernetes cluster cannot be hacked in two minutes.
There is a problem. Most likely, if you have a Kubernetes cluster, then monitoring is installed in your cluster. I even undertake to predict that if your cluster has monitoring, then it is called Prometheus.
What I am going to tell you now will be valid both for the Prometheus operator and for Prometheus delivered in its pure form. The question is, if I can’t get an admin to the cluster so quickly, then this means that I need to search more. And I can search using your monitoring.
Probably, everyone read the same articles on Habré, and monitoring is located in the namespace monitoring. Helm chart is called approximately the same for everyone. My guess is that if you do helm install stable/prometheus you should end up with roughly the same names. And even most likely I won’t have to guess the DNS name in your cluster. Because it's standard.
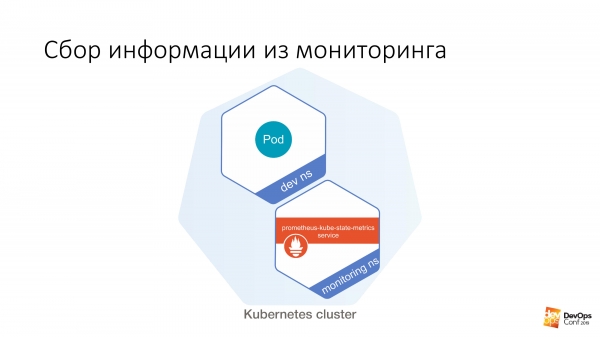
Next, we have a certain dev ns, in which you can run a certain pod. And then from this pod it is very easy to do like this:
$ curl http://prometheus-kube-state-metrics.monitoring prometheus-kube-state-metrics is one of the prometheus exporters that collects metrics from the Kubernetes API itself. There is a lot of data there, what is running in your cluster, what it is, what problems you have with it.
As a simple example:
kube_pod_container_info{namespace="kube-system",pod="kube-apiserver-k8s-1",container="kube-apiserver",image=
"gcr.io/google-containers/kube-apserver:v1.14.5"
,image_id=»docker-pullable://gcr.io/google-containers/kube- apiserver@sha256:e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989″,container_id=»docker://7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b»} 1
By making a simple curl request from an unprivileged pod, you can get information like this. If you don't know what version of Kubernetes you are running, it will easily tell you.
And the most interesting thing is that in addition to the fact that you are accessing kube-state-metrics, you can just as well access Prometheus itself directly. You can collect metrics from there. You can even build metrics from there. Even theoretically, you can build such a query from a cluster in Prometheus, which will simply turn it off. And your monitoring will generally stop working from the cluster.
And here the question already arises whether any external monitoring monitors your monitoring. I just got the opportunity to operate in a Kubernetes cluster with no consequences for myself at all. You won't even know that I'm working there, since monitoring is no longer there.
Just like with the PSP, it feels like the problem is that all these fancy technologies - Kubernetes, Prometheus - they just don't work and are full of holes. Not really.
There is such a thing - .
If you are a normal admin, then most likely you know about Network Policy that this is another yaml, of which there are already dofiga in the cluster. And Network Policies are definitely not needed. And even if you read what Network Policy is, what is a Kubernetes yaml firewall, it allows you to restrict access rights between namespaces, between pods, then you definitely decided that the yaml firewall in Kubernetes is based on the next abstractions ... No-no . It's definitely not necessary.
Even if your security specialists were not told that with the help of your Kubernetes, you can build a very easy and simple firewall, and very granular. If they don’t know this yet and don’t pull you: “Well, give it, give it ...” Then in any case, you need Network Policy to block access to some service places that you can pull from your cluster without any authorization.
As in the example I gave, you can pull kube state metrics from any namespace in the Kubernetes cluster without having any rights to do so. Network policies have closed access from all other namespaces to the monitoring namespace and, as it were, everything: no access, no problems. In all the charts that exist, both the standard prometheus and the prometheus that is in the operator, there is simply an option in the values of the helm to simply enable network policies for them. You just need to turn it on and they will work.
There is really one problem here. Being a normal bearded administrator, you most likely decided that network policies are not needed. And after reading all sorts of articles on resources like Habr, you decided that flannel, especially with the host-gateway mode, is the best thing you can choose.
What to do?
You can try to redeploy the network solution that you have in your Kubernetes cluster, try to replace it with something more functional. On the same Calico, for example. But right away I want to say that the task of changing the network solution in the working Kubernetes cluster is quite non-trivial. I solved it twice (both times, however, theoretically), but we even showed how to do it at Slurms. For our students, we showed how to change the network solution in a Kubernetes cluster. In principle, you can try to make sure that there is no downtime on the production cluster. But you probably won't succeed.
And the problem is actually solved very simply. There are certificates in the cluster, and you know that your certificates will go bad in a year. Well, and usually a normal solution with certificates in the cluster - why are we going to take a steam bath, we will raise a new cluster next to it, let it go rotten in the old one, and redeploy everything. True, when it rots, everything will lie down for a day, but then a new cluster.
When you raise a new cluster, at the same time insert Calico instead of flannel.
What to do if you have certificates issued for a hundred years and you are not going to redeploy the cluster? There is such a thing Kube-RBAC-Proxy. This is a very cool development, it allows you to embed itself as a sidecar container to any pod in a Kubernetes cluster. And it actually adds authorization through the RBAC of Kubernetes itself to this pod.
There is one problem. Previously, this Kube-RBAC-Proxy solution was built into the operator's prometheus. But then he was gone. Now modern versions rely on the fact that you have network policies and close them with them. And so you have to rewrite the chart a bit. In fact, if you go to , there are examples of how to use it as sidecars, and the charts will have to be rewritten minimally.
There is one more small problem. Not only Prometheus gives away its metrics to anyone. In our case, all components of the Kubernetes cluster are also able to give their metrics.
But as I said, if you cannot access the cluster and collect information, then you can at least do harm.
So I'll quickly show you two ways that a Kubernetes cluster can get sick.
You will laugh when I tell you, these are two real life cases.
Method one. Resource exhaustion.
We are launching another special pod. It will have this section.
resources:
requests:
cpu: 4
memory: 4Gi As you know, requests is the amount of CPU and memory that is reserved on the host for specific request pods. If we have a four-core host in the Kubernetes cluster, and four CPU pods arrive there with requests, then no more pods with requests can come to this host.
If I run such a pod, then I issue the command:
$ kubectl scale special-pod --replicas=...Then no one else will be able to deploy to the Kubernetes cluster. Because all nodes will run out of requests. And so I will stop your Kubernetes cluster. If I do this in the evening, then the deployments can be stopped for quite a long time.
If we look again at the Kubernetes documentation, we will see such a thing called Limit Range. It sets the resources for the cluster objects. You can write a Limit Range object in yaml, apply it to certain namespaces - and further in this namespace you can say that you have resources for default, maximum and minimum pods.
With the help of such a thing, we can restrict users in specific team product namespaces from the ability to indicate all sorts of nasty things on their pods. But unfortunately, even if you tell the user that you cannot run pods with requests for more than one CPU, there is such a wonderful scale command, well, or through the dashboard they can do scale.
And this is where number two comes in. Run 11 111 111 111 111 pods. It's eleven billion. This is not because I came up with such a number, but because I saw it myself.
Real story. Late in the evening I was about to leave the office. I look, a group of developers is sitting in the corner and frantically doing something with laptops. I go up to the guys and ask: “What happened to you?”
A little earlier, at nine o'clock in the evening, one of the developers was going home. And I decided: “Now I will scale my application to one.” I pressed one, and the Internet got a little dull. He pressed the one again, he pressed the one, hit Enter. He poked everything he could. Then the Internet came to life - and everything began to scale up to this date.
True, this story did not take place on Kubernetes, at that time it was Nomad. It ended with the fact that after an hour of our attempts to stop Nomad from stubborn attempts to scale, Nomad replied that he would not stop scaling and would not do anything else. "I'm tired, I'm leaving." And turned around.
I naturally tried to do the same on Kubernetes. Eleven billion pods Kubernetes did not please, he said: “I can’t. Exceeds internal caps. But 1 pods could.
In response to one billion, the Cube did not withdraw into itself. He really started to scale. The further the process went, the more time it took to create new pods. But still the process went on. The only problem is that if I can run pods in my namespace indefinitely, then even without requests and limits, I can run such a number of pods with some tasks that with the help of these tasks the nodes will start to add up from memory, on the CPU. When I run so many pods, the information from them must get into the storage, that is, etcd. And when too much information comes in, the storage starts to give back too slowly - and Kubernetes starts to become blunt.
And one more problem ... As you know, Kubernetes controls are not some kind of central thing, but several components. There, in particular, there is a controller manager, scheduler and so on. All these guys will start doing unnecessary stupid work at the same time, which over time will start to take more and more time. The controller manager will create new pods. Scheduler will try to find a new node for them. New nodes in your cluster will most likely run out soon. The Kubernetes cluster will start to run slower and slower.
But I decided to go even further. As you know, Kubernetes has a thing called a service. Well, by default in your clusters, most likely, the service works using IP tables.
If you run one billion pods, for example, and then use a script to force Kubernetis to create new services:
for i in {1..1111111}; do
kubectl expose deployment test --port 80
--overrides="{"apiVersion": "v1",
"metadata": {"name": "nginx$i"}}";
done On all nodes of the cluster, more and more new iptables rules will be generated approximately simultaneously. Moreover, one billion iptables rules will be generated for each service.
I checked this whole thing on several thousand, up to a dozen. And the problem is that already at this threshold it is quite problematic to make ssh to the node. Because packets, passing through so many chains, begin to feel not very good.
And this is also all solved with the help of Kubernetes. There is such an object Resource quota. Sets the number of available resources and objects for the namespace in the cluster. We can create a yaml object in each Kubernetes cluster namespace. With the help of this object, we can say that we have a certain number of requests, limits allocated for this namespace, and further we can say that it is possible to create 10 services and 10 pods in this namespace. And a single developer can even crush himself in the evenings. Kubernetes will tell him: “You can’t scale your pods to such an amount, because it exceeds the resource quota.” That's it, problem solved. .
One problem arises in connection with this. You feel how difficult it becomes to create a namespace in Kubernetes. To create it, we need to take into account a bunch of things.
Resource quota + Limit Range + RBAC
• Create a namespace
• Create inside limitrange
• Create inside resourcequota
• Create a serviceaccount for CI
• Create rolebinding for CI and users
• Optionally launch the necessary service pods
Therefore, taking this opportunity, I would like to share my developments. There is such a thing called the SDK operator. This is the way in the Kubernetes cluster to write statements for it. You can write statements with Ansible.
At first, we wrote in Ansible, and then I looked at what the SDK operator was and rewrote the Ansible role into an operator. This statement allows you to create an object in the Kubernetes cluster called a command. Inside the command, it allows you to describe in yaml the environment for this command. And inside the team environment, it allows us to describe that we allocate so many resources.
Petite .
And in conclusion. What to do with all this?
First. Pod Security Policy is good. And despite the fact that none of the Kubernetes installers use them to this day, you still need to use them in your clusters.
Network Policy is not some other unnecessary feature. This is what is really needed in the cluster.
LimitRange / ResourceQuota - it's time to use. We started using it a long time ago, and for a long time I was sure that everyone without exception uses it. It turned out that this is rare.
In addition to what I mentioned during the report, there are undocumented features that allow you to attack the cluster. Released recently .
Some things are so sad and hurtful. For example, under certain conditions, cubelets in a Kubernetes cluster can give the contents of the warlocks directory, and to an unauthorized user.
there are instructions on how to reproduce everything that I said. There are files with production examples, how ResourceQuota, Pod Security Policy look like. And all this can be touched.
Thank you all.
Source: habr.com
