


Kiel backend-programisto komprenas, ke SQL-demando funkcios bone sur "prod"? En grandaj aŭ rapide kreskantaj kompanioj, ne ĉiuj havas aliron al la "produkto". Kaj kun aliro, ne ĉiuj petoj povas esti senpere kontrolitaj, kaj krei kopion de la datumbazo ofte prenas horojn. Por solvi ĉi tiujn problemojn, ni kreis artefaritan DBA - Joe. Ĝi jam estis sukcese efektivigita en pluraj kompanioj kaj helpas pli ol dekduon da programistoj.
Video:

Saluton al ĉiuj! Mia nomo estas Anatoly Stansler. Mi laboras por firmao . Ni kompromitas akceli la disvolvan procezon forigante la prokrastojn asociitajn kun la laboro de Postgres de programistoj, DBA-oj kaj QA-oj.
Ni havas bonegajn klientojn kaj hodiaŭ parto de la raporto estos dediĉita al kazoj, kiujn ni renkontis laborante kun ili. Mi parolos pri kiel ni helpis ilin solvi sufiĉe gravajn problemojn.

Kiam ni disvolvas kaj faras kompleksajn altŝarĝajn migradojn, ni demandas al ni mem la demandon: "Ĉu ĉi tiu migrado ekflugos?". Ni uzas revizion, ni uzas la scion de pli spertaj kolegoj, DBA-fakuloj. Kaj ili povas diri ĉu ĝi flugos aŭ ne.
Sed eble estus pli bone, se ni mem povus testi ĝin sur plengrandaj kopioj. Kaj hodiaŭ ni nur parolos pri kiaj aliroj al testado estas nun kaj kiel ĝi povas esti farita pli bone kaj per kiaj iloj. Ni ankaŭ parolos pri la avantaĝoj kaj malavantaĝoj de tiaj aliroj, kaj kion ni povas ripari ĉi tie.
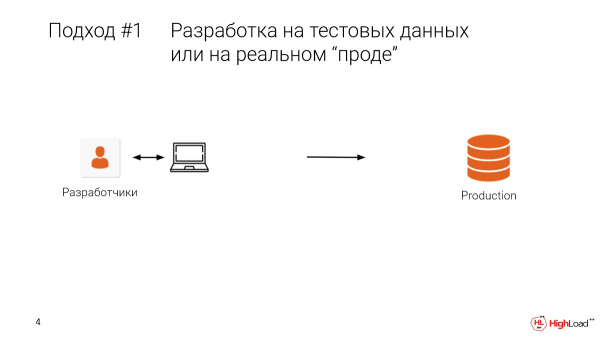
Kiu iam faris indeksojn rekte sur prod aŭ faris ajnajn ŝanĝojn? Sufiĉe da. Kaj por kiu tio kaŭzis, ke datumoj estis perditaj aŭ estis malfunkcio? Tiam vi konas ĉi tiun doloron. Dankon al Dio ekzistas sekurkopioj.

La unua aliro estas testado en prod. Aŭ, kiam programisto sidas sur loka maŝino, li havas testajn datumojn, ekzistas ia limigita elekto. Kaj ni eliras al prod, kaj ni ricevas ĉi tiun situacion.

Doloras, ĝi estas multekosta. Verŝajne estas plej bone ne.
Kaj kio estas la plej bona maniero fari ĝin?
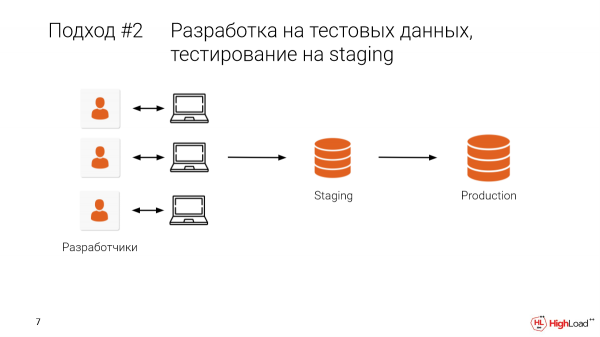
Ni prenu surscenigon kaj elektu iun parton de prod tie. Aŭ en la plej bona kazo, ni prenu veran prod, ĉiujn datumojn. Kaj post kiam ni disvolvis ĝin loke, ni aldone kontrolos pri enscenigo.
Ĉi tio permesos al ni forigi kelkajn el la eraroj, t.e. malhelpi ilin esti sur prod.
Kio estas la problemoj?
- La problemo estas, ke ni dividas ĉi tiun surscenigon kun kolegoj. Kaj tre ofte okazas, ke vi faras ian ŝanĝon, bam - kaj ne estas datumoj, la laboro estas en la drenilo. Enscenigo estis mult-terabajto. Kaj oni devas longe atendi, ke ĝi denove leviĝu. Kaj ni decidas fini ĝin morgaŭ. Jen, ni havas evoluon.
- Kaj, kompreneble, ni havas multajn kolegojn laborantajn tie, multajn teamojn. Kaj ĝi devas esti farita permane. Kaj ĉi tio estas maloportuna.

Kaj indas diri, ke ni havas nur unu provon, unu pafon, se ni volas fari iujn ŝanĝojn al la datumbazo, tuŝi la datumojn, ŝanĝi la strukturon. Kaj se io misfunkciis, se estis eraro en la migrado, tiam ni ne rapide retroiros.
Ĉi tio estas pli bona ol la antaŭa aliro, sed ankoraŭ estas alta probablo, ke ia eraro iros al produktado.
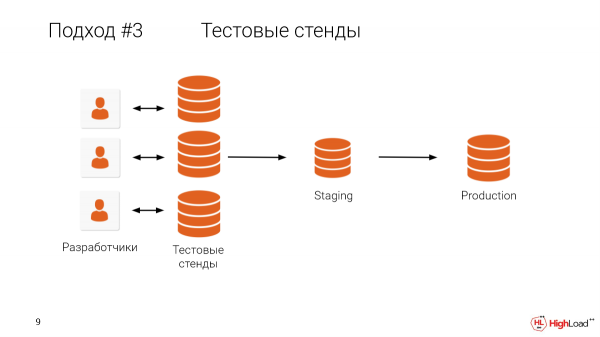
Kio malhelpas nin doni al ĉiu programisto testbenkon, plengrandan kopion? Mi pensas, ke estas klare kio malhelpas.
Kiu havas datumbazon pli grandan ol terabajto? Pli ol duono de la ĉambro.
Kaj estas klare, ke konservi maŝinojn por ĉiu programisto, kiam ekzistas tiom granda produktado, estas tre multekosta, kaj krome, ĝi prenas longan tempon.
Ni havas klientojn, kiuj rimarkis, ke estas tre grave testi ĉiujn ŝanĝojn sur plengrandaj kopioj, sed ilia datumbazo estas malpli ol terabajto, kaj ne ekzistas rimedoj por konservi testbenkon por ĉiu programisto. Tial ili devas elŝuti la rubejojn loke al sia maŝino kaj testi tiamaniere. Ĝi bezonas multan tempon.

Eĉ se vi faras ĝin ene de la infrastrukturo, tiam elŝuti unu terabajton da datumoj por horo jam estas tre bona. Sed ili uzas logikajn rubejojn, ili elŝutas loke el la nubo. Por ili, la rapido estas ĉirkaŭ 200 gigabajtoj hore. Kaj necesas ankoraŭ tempo por turni sin de la logika rubejo, ruliĝi la indeksojn, ktp.
Sed ili uzas ĉi tiun aliron ĉar ĝi permesas al ili konservi la produkton fidinda.
Kion ni povas fari ĉi tie? Ni faru testbenkojn malmultekostajn kaj donu al ĉiu programisto sian propran testbenkon.
Kaj ĉi tio eblas.
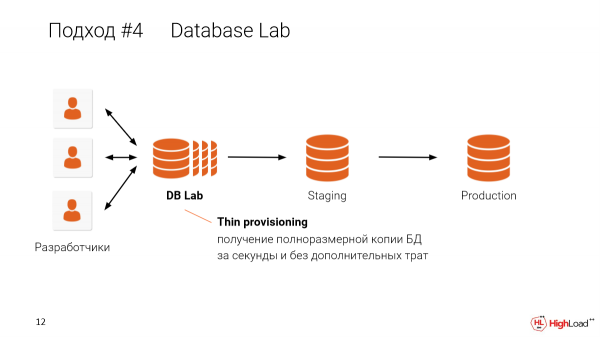
Kaj en ĉi tiu aliro, kiam ni faras maldikajn klonojn por ĉiu programisto, ni povas dividi ĝin sur unu maŝino. Ekzemple, se vi havas 10TB datumbazon kaj volas doni ĝin al 10 programistoj, vi ne bezonas havi XNUMX x XNUMXTB datumbazoj. Vi nur bezonas unu maŝinon por fari maldikajn izolitajn kopiojn por ĉiu programisto uzante unu maŝinon. Mi rakontos al vi kiel ĝi funkcias iom poste.

Reala ekzemplo:
DB - 4,5 terabajtoj.
Ni povas akiri sendependajn kopiojn en 30 sekundoj.
Vi ne devas atendi teststandon kaj dependi de kiom granda ĝi estas. Vi povas akiri ĝin en sekundoj. Estos tute izolitaj medioj, sed kiuj kunhavas datumojn inter si.
Ĉi tio estas bonega. Ĉi tie ni parolas pri magio kaj paralela universo.

En nia kazo, ĉi tio funkcias uzante la OpenZFS-sistemon.

OpenZFS estas kopio-sur-skriba dosiersistemo kiu subtenas momentfotojn kaj klonojn el la skatolo. Ĝi estas fidinda kaj skalebla. Ŝi estas tre facile administrebla. Ĝi laŭvorte povas esti deplojita en du teamoj.
Estas aliaj ebloj:
lvm,
Stokado (ekzemple, Pura Stokado).
La Database Lab, pri kiu mi parolas, estas modula. Povas esti efektivigita uzante ĉi tiujn eblojn. Sed nuntempe, ni koncentriĝis pri OpenZFS, ĉar estis problemoj specife kun LVM.
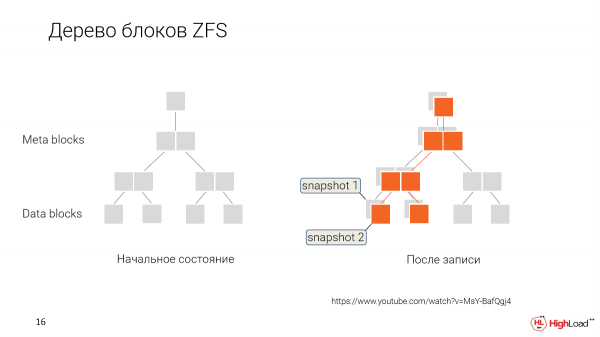
Kiel ĝi funkcias? Anstataŭ anstataŭi la datumojn ĉiufoje kiam ni ŝanĝas ĝin, ni konservas ĝin simple markante, ke ĉi tiuj novaj datumoj estas de nova punkto en tempo, nova momentfoto.
Kaj en la estonteco, kiam ni volas restarigi aŭ ni volas fari novan klonon de iu pli malnova versio, ni nur diras: "Bone, donu al ni ĉi tiujn blokojn de datumoj kiuj estas markitaj tiel."
Kaj ĉi tiu uzanto laboros kun tia datuma aro. Li iom post iom ŝanĝos ilin, faros siajn proprajn momentfotojn.
Kaj ni disbranĉiĝos. Ĉiu programisto en nia kazo havos la ŝancon havi sian propran klonon, kiun li redaktas, kaj la datumoj kiuj estas kunhavataj estos dividitaj inter ĉiuj.
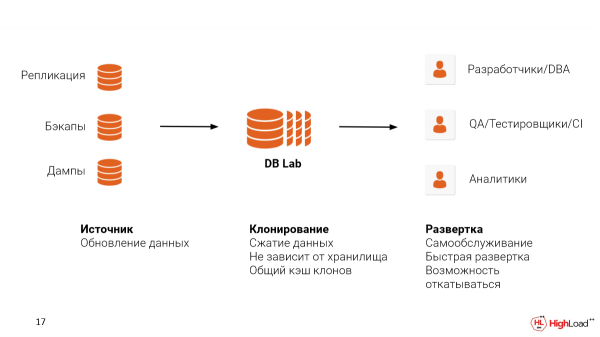
Por disfaldi tian sistemon hejme, vi devas solvi du problemojn:
La unua estas la fonto de la datumoj, de kie vi prenos ĝin. Vi povas agordi reproduktadon kun produktado. Vi jam povas uzi la sekurkopiojn, kiujn vi agordis, mi esperas. WAL-E, WAL-G aŭ Barman. Kaj eĉ se vi uzas iun specon de Cloud-solvo kiel RDS aŭ Cloud SQL, tiam vi povas uzi logikan rubejojn. Sed ni ankoraŭ konsilas vin uzi sekurkopiojn, ĉar kun ĉi tiu aliro vi ankaŭ konservos la fizikan strukturon de la dosieroj, kio permesos al vi esti eĉ pli proksima al la metrikoj, kiujn vi vidus en produktado por kapti tiujn problemojn kiuj ekzistas.
La dua estas kie vi volas gastigi la Datumbazan Laboratorion. Ĝi povus esti Nubo, ĝi povus esti Surloka. Gravas diri ĉi tie, ke ZFS subtenas kunpremadon de datumoj. Kaj ĝi faras ĝin sufiĉe bone.
Imagu, ke por ĉiu tia klono, depende de la operacioj, kiujn ni faras kun la bazo, kreskos ia dev. Por ĉi tio, dev ankaŭ bezonos spacon. Sed pro la fakto, ke ni prenis bazon de 4,5 terabajtoj, ZFS kunpremos ĝin al 3,5 terabajtoj. Ĉi tio povas varii laŭ la agordoj. Kaj ni ankoraŭ havas lokon por dev.
Tia sistemo povas esti uzata por malsamaj kazoj.
Ĉi tiuj estas programistoj, DBAoj por konsultvalidigo, por optimumigo.
Ĉi tio povas esti uzata en QA-testado por testi apartan migradon antaŭ ol ni ruliĝas ĝin por produkti. Kaj ni ankaŭ povas levi specialajn mediojn por QA kun realaj datumoj, kie ili povas testi novajn funkciojn. Kaj ĝi prenos sekundojn anstataŭ atendi horojn, kaj eble tagojn en iuj aliaj kazoj kie maldikaj kopioj ne estas uzataj.
Kaj alia kazo. Se la kompanio ne havas analitikan sistemon starigita, tiam ni povas izoli maldikan klonon de la produktobazo kaj doni ĝin al longaj demandoj aŭ specialaj indeksoj, kiuj povas esti uzataj en analitiko.

Kun ĉi tiu aliro:
Malalta probablo de eraroj sur la "prod", ĉar ni testis ĉiujn ŝanĝojn sur plengrandaj datumoj.
Ni havas kulturon de testado, ĉar nun vi ne devas atendi horojn por via propra stando.
Kaj ne ekzistas baro, neniu atendado inter provoj. Vi povas efektive iri kontroli. Kaj estos pli bone tiel, kiam ni akcelos la evoluon.
Estos malpli refaktorado. Malpli da cimoj finiĝos en prod. Ni refaktorigos ilin malpli poste.
Ni povas inversigi nemaligeblajn ŝanĝojn. Ĉi tio ne estas la norma aliro.
- Ĉi tio estas utila ĉar ni dividas la rimedojn de la testbenkoj.
Jam bone, sed kion alian oni povus akceli?

Danke al tia sistemo, ni povas multe redukti la sojlon por eniri tian testadon.
Nun ekzistas malvirta cirklo, kiam programisto, por akiri aliron al realaj plengrandaj datumoj, devas fariĝi spertulo. Oni devas konfidi al li tia aliro.
Sed kiel kreski se ĝi ne estas tie. Sed kio se vi havas nur tre malgrandan aron da testaj datumoj disponeblaj al vi? Tiam vi ne ricevos realan sperton.
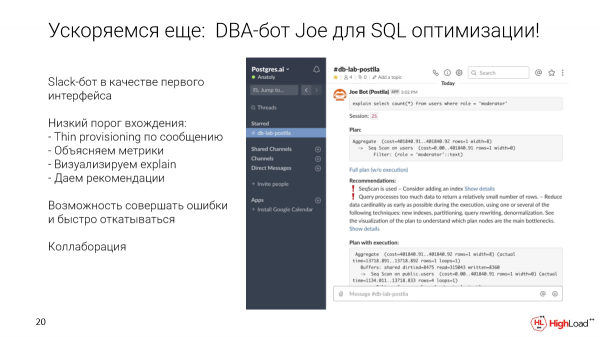
Kiel eliri el ĉi tiu rondo? Kiel la unua interfaco, oportuna por programistoj de ajna nivelo, ni elektis la Slack-bot. Sed ĝi povas esti ajna alia interfaco.
Kion ĝi permesas al vi fari? Vi povas preni specifan demandon kaj sendi ĝin al speciala kanalo por la datumbazo. Ni aŭtomate deplojos maldikan klonon en sekundoj. Ni plenumu ĉi tiun peton. Ni kolektas metrikojn kaj rekomendojn. Ni montru bildigon. Kaj tiam ĉi tiu klono restos por ke ĉi tiu demando estu iel optimumigita, aldoni indeksojn ktp.
Kaj ankaŭ Slack donas al ni ŝancojn por kunlaboro el la skatolo. Ĉar ĉi tio estas nur kanalo, vi povas komenci diskuti ĉi tiun peton ĝuste tie en la fadeno por tia peto, ping viajn kolegojn, DBAs kiuj estas ene de la firmao.

Sed estas, kompreneble, problemoj. Ĉar ĉi tio estas la reala mondo, kaj ni uzas servilon gastigantan multajn klonojn samtempe, ni devas kunpremi la kvanton de memoro kaj CPU-potenco disponeblaj por la klonoj.
Sed por ke ĉi tiuj provoj estu kredindaj, vi devas iel solvi ĉi tiun problemon.
Estas klare, ke la grava punkto estas la samaj datumoj. Sed ni jam havas ĝin. Kaj ni volas atingi la saman agordon. Kaj ni povas doni tian preskaŭ identan agordon.
Estus bone havi la saman aparataron kiel en produktado, sed ĝi povas malsami.
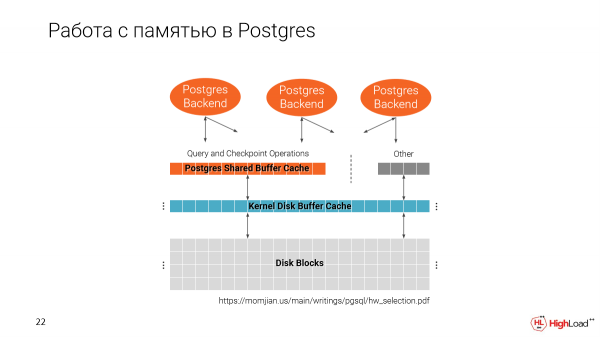
Ni memoru kiel Postgres funkcias kun memoro. Ni havas du kaŝmemorojn. Unu el la dosiersistemo kaj unu indiĝena Postgres, t.e. Shared Buffer Cache.
Gravas noti, ke la Dividita Buffer Cache estas asignita kiam Postgres komenciĝas, depende de kia grandeco vi specifas en la agordo.
Kaj la dua kaŝmemoro uzas la tutan disponeblan spacon.
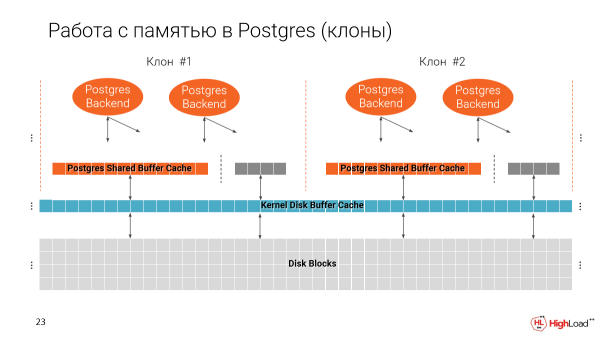
Kaj kiam ni faras plurajn klonojn sur unu maŝino, rezultas, ke ni iom post iom plenigas la memoron. Kaj en bona maniero, Shared Buffer Cache estas 25% de la tuta kvanto de memoro disponebla en la maŝino.
Kaj rezultas, ke se ni ne ŝanĝas ĉi tiun parametron, tiam ni povos ruli nur 4 petskribojn sur unu maŝino, tio estas, 4 el ĉi tiuj maldikaj klonoj entute. Kaj ĉi tio, kompreneble, estas malbona, ĉar ni volas havi multe pli da ili.
Sed aliflanke, Buffer Cache estas uzata por ekzekuti demandojn por indeksoj, tio estas, la plano dependas de kiom grandaj estas niaj kaŝmemoroj. Kaj se ni nur prenas ĉi tiun parametron kaj reduktas ĝin, tiam niaj planoj povas multe ŝanĝiĝi.
Ekzemple, se ni havas grandan kaŝmemoron sur prod, tiam Postgres preferos uzi indekson. Kaj se ne, tiam estos SeqScan. Kaj kio havus se niaj planoj ne koincidus?
Sed ĉi tie ni venas al la konkludo, ke fakte la plano en Postgres ne dependas de la specifa grandeco specifita en la Dividita Buffer en la plano, ĝi dependas de la efektiva_cache_size.

Effective_cache_size estas la laŭtaksa kvanto de kaŝmemoro kiu estas disponebla por ni, t.e. la sumo de Buffer Cache kaj dosiersistemo kaŝmemoro. Ĉi tio estas agordita de la agordo. Kaj ĉi tiu memoro ne estas asignita.
Kaj pro ĉi tiu parametro, ni povas iom trompi Postgres, dirante, ke ni efektive havas multajn datumojn disponeblajn, eĉ se ni ne havas ĉi tiujn datumojn. Kaj tiel, la planoj tute koincidos kun produktado.
Sed ĉi tio povas influi la tempon. Kaj ni optimumigas demandojn per tempo, sed gravas, ke tempo dependas de multaj faktoroj:
Ĝi dependas de la ŝarĝo kiu estas nuntempe sur prod.
Ĝi dependas de la karakterizaĵoj de la maŝino mem.
Kaj ĉi tio estas nerekta parametro, sed fakte ni povas optimumigi ĝuste per la kvanto de datumoj, kiujn ĉi tiu demando legos por ricevi la rezulton.
Kaj se vi volas, ke la tempo estu proksima al tio, kion ni vidos en prod, tiam ni devas preni la plej similan aparataron kaj, eble, eĉ pli por ke ĉiuj klonoj taŭgu. Sed ĉi tio estas kompromiso, t.e. vi ricevos la samajn planojn, vi vidos kiom da datumoj legos aparta demando kaj vi povos konkludi ĉu ĉi tiu demando estas bona (aŭ migrado) aŭ malbona, ĝi ankoraŭ bezonas esti optimumigita. .
Ni rigardu kiel Joe estas specife optimumigita.
Ni prenu peton de reala sistemo. En ĉi tiu kazo, la datumbazo estas 1 terabajto. Kaj ni volas kalkuli la nombron da freŝaj afiŝoj, kiuj havis pli ol 10 ŝatojn.
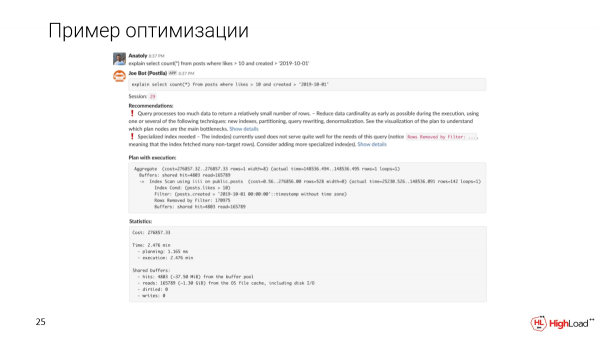
Ni skribas mesaĝon al la kanalo, klono estis deplojita por ni. Kaj ni vidos, ke tia peto finiĝos en 2,5 minutoj. Ĉi tio estas la unua afero, kiun ni rimarkas.
B Joe montros al vi aŭtomatajn rekomendojn bazitajn sur la plano kaj metriko.
Ni vidos, ke la demando prilaboras tro da datumoj por akiri relative malgrandan nombron da vicoj. Kaj necesas ia speciala indekso, ĉar ni rimarkis, ke estas tro da filtritaj vicoj en la konsulto.
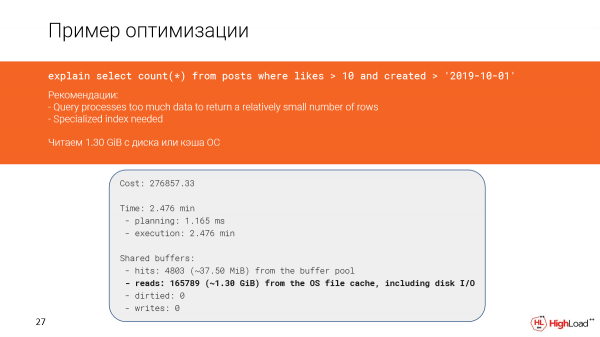
Ni rigardu pli detale kio okazis. Efektive, ni vidas, ke ni legis preskaŭ unu kaj duonon da gigabajtoj da datumoj el la dosierkaŝmemoro aŭ eĉ el disko. Kaj ĉi tio ne estas bona, ĉar ni ricevis nur 142 liniojn.
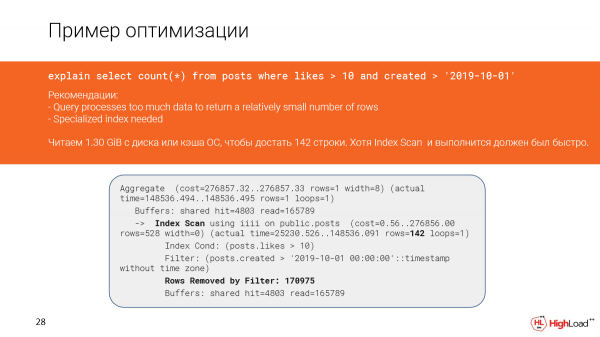
Kaj, ŝajnus, ni havas indeksan skanadon ĉi tie kaj devus esti funkciinta rapide, sed ĉar ni filtris tro da linioj (ni devis nombri ilin), la demando malrapide funkciis.
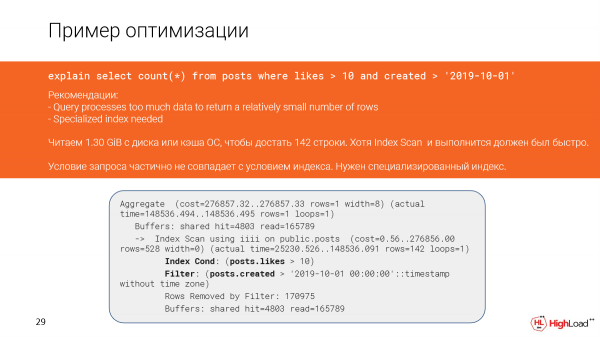
Kaj ĉi tio okazis en la plano pro la fakto, ke la kondiĉoj en la konsulto kaj la kondiĉoj en la indekso parte ne kongruas.
Ni provu fari la indekson pli preciza kaj vidu kiel la demanda ekzekuto ŝanĝiĝas post tio.
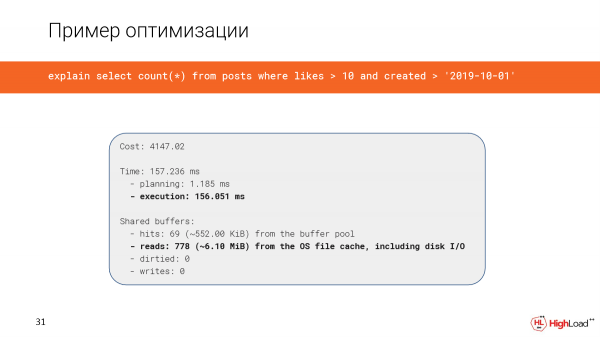
La kreado de la indekso daŭris sufiĉe longan tempon, sed nun ni kontrolas la demandon kaj vidas, ke la tempo anstataŭ 2,5 minutoj estas nur 156 milisekundoj, kio estas sufiĉe bona. Kaj ni legas nur 6 megabajtojn da datumoj.
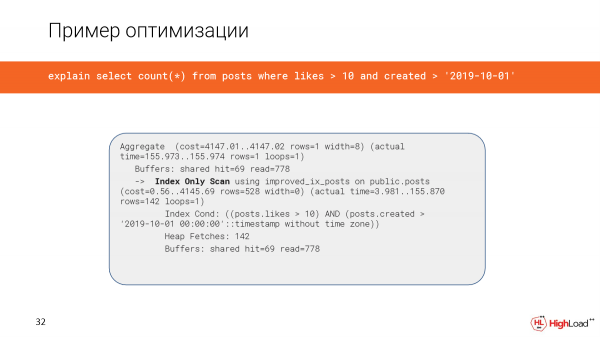
Kaj nun ni uzas nur indeksan skanadon.
Alia grava rakonto estas, ke ni volas prezenti la planon en iu pli komprenebla maniero. Ni efektivigis bildigon uzante Flamajn Grafikojn.
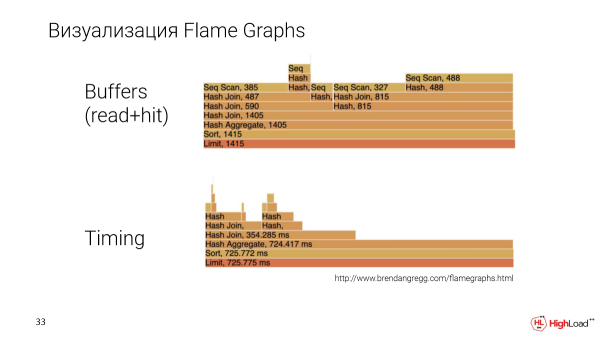
Jen alia peto, pli intensa. Kaj ni konstruas Flame Graphs laŭ du parametroj: ĉi tiu estas la kvanto de datumoj kiujn aparta nodo nombris en la plano kaj tempo, t.e. la ekzekuttempo de la nodo.
Ĉi tie ni povas kompari specifajn nodojn unu kun la alia. Kaj estos klare, kiu el ili prenas pli aŭ malpli, kio estas kutime malfacile fari en aliaj bildigaj metodoj.
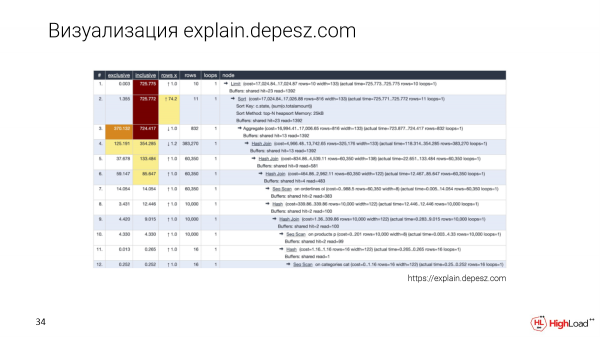
Kompreneble, ĉiuj konas explic.depesz.com. Bona trajto de ĉi tiu bildigo estas, ke ni konservas la tekstplanon kaj ankaŭ metas kelkajn bazajn parametrojn en tabelon por ke ni povu ordigi.
Kaj programistoj, kiuj ankoraŭ ne enprofundiĝis en ĉi tiun temon, ankaŭ uzas explic.depesz.com, ĉar estas pli facile por ili eltrovi, kiuj metrikoj estas gravaj kaj kiuj ne.
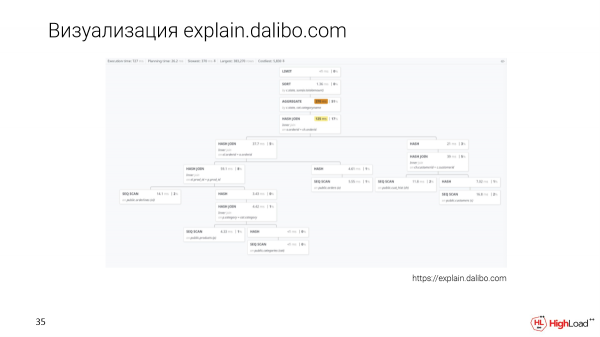
Estas nova aliro al bildigo - ĉi tio estas klarigi.dalibo.com. Ili faras arbobildigon, sed estas tre malfacile kompari nodojn unu kun la alia. Ĉi tie vi povas bone kompreni la strukturon, tamen, se estas granda peto, tiam vi devos rulumi tien kaj reen, sed ankaŭ opcion.
kunlaboro
Kaj, kiel mi diris, Slack donas al ni la ŝancon kunlabori. Ekzemple, se ni renkontas kompleksan demandon, kiu ne klaras kiel optimumigi, ni povas klarigi ĉi tiun problemon kun niaj kolegoj en fadeno en Slack.

Ŝajnas al ni, ke gravas testi plengrandajn datumojn. Por fari tion, ni faris la ilon Ĝisdatigi Database Lab, kiu estas disponebla en malferma fonto. Vi ankaŭ povas uzi la Joe-bot. Vi povas preni ĝin ĝuste nun kaj efektivigi ĝin ĉe via loko. Ĉiuj gvidiloj estas haveblaj tie.
Ankaŭ gravas rimarki, ke la solvo mem ne estas revolucia, ĉar ekzistas Delphix, sed ĝi estas entreprena solvo. Ĝi estas tute fermita, ĝi estas tre multekosta. Ni specife specialiĝas pri Postgres. Ĉi tiuj estas ĉiuj malfermkodaj produktoj. Aliĝu al ni!
Jen kie mi finas. Dankon!
Viaj demandoj
Saluton! Dankon pro la raporto! Tre interesa, precipe al mi, ĉar mi solvis proksimume la saman problemon antaŭ iom da tempo. Kaj do mi havas kelkajn demandojn. Espereble mi ricevos almenaŭ parton de ĝi.
Mi scivolas kiel vi kalkulas la lokon por ĉi tiu medio? La teknologio signifas, ke en certaj cirkonstancoj, viaj klonoj povas kreski al la maksimuma grandeco. Malglate parolante, se vi havas dek terabajtan datumbazon kaj 10 klonojn, tiam estas facile simuli situacion kie ĉiu klono pezas 10 unikajn datumojn. Kiel vi kalkulas ĉi tiun lokon, tio estas, tiun delton, pri kiu vi parolis, en kiu ĉi tiuj klonoj loĝos?
Bona demando. Gravas konservi trakon de specifaj klonoj ĉi tie. Kaj se klono havas tro grandan ŝanĝon, ĝi komencas kreski, tiam ni unue povas doni averton al la uzanto pri tio, aŭ tuj ĉesigi ĉi tiun klonon por ke ni ne havu malsukcesan situacion.
Jes, mi havas nestitan demandon. Tio estas, kiel vi certigas la vivociklon de ĉi tiuj moduloj? Ni havas ĉi tiun problemon kaj tute apartan rakonton. Kiel tio okazas?
Estas iom da ttl por ĉiu klono. Esence, ni havas fiksan ttl.
Kio, se ne sekreto?
1 horo, t.e. senlabore - 1 horo. Se ĝi ne estas uzata, tiam ni batas ĝin. Sed ne estas surprizo ĉi tie, ĉar ni povas levi la klonon en sekundoj. Kaj se vi bezonas ĝin denove, do bonvolu.
Mi interesiĝas ankaŭ pri la elekto de teknologioj, ĉar ekzemple ni uzas plurajn metodojn paralele pro unu aŭ alia kialo. Kial ZFS? Kial vi ne uzis LVM? Vi menciis, ke estis problemoj kun LVM. Kio estis la problemoj? Laŭ mi, la plej optimuma eblo estas kun stokado, laŭ rendimento.
Kio estas la ĉefa problemo kun ZFS? La fakto, ke vi devas funkcii sur la sama gastiganto, t.e. ĉiuj okazoj vivos ene de la sama OS. Kaj en la kazo de stokado, vi povas konekti malsamajn ekipaĵojn. Kaj la botelkolo estas nur tiuj blokoj, kiuj estas sur la stokadsistemo. Kaj la demando pri la elekto de teknologioj estas interesa. Kial ne LVM?
Ni povas diskuti LVM specife ĉe la kunveno. Koncerne stokadon, ĝi estas nur multekosta. Ni povas instali ZFS ie ajn. Vi povas instali ĝin sur via maŝino. Vi povas simple elŝuti la deponejon kaj instali ĝin. ZFS povas esti instalita preskaŭ ie ajn, se ni parolas pri... Linux Ni parolas pri ĝi. Do, ni ricevas tre flekseblan solvon. Kaj ZFS mem ofertas multon tuj post uzo. Vi povas ŝargi tiom da datumoj en ĝin kiom vi volas, konekti grandan nombron da diskoj, kaj ĝi havas momentfotojn. Kaj, kiel mi jam diris, ĝi estas facile administrebla. Do, ĝi ŝajnas tre agrabla uzi. Ĝi estas pruvita, ĝi ekzistas jam de multaj jaroj. Ĝi havas tre grandan komunumon, kiu kreskas. ZFS estas tre fidinda solvo.
Nikolao Samoĥvalov: Ĉu mi rajtas komenti plu? Mi nomiĝas Nikolay, ni kunlaboras kun Anatoly. Mi konsentas, ke stokado estas bonega. Kaj kelkaj el niaj klientoj havas Puran Stokadon ktp.
Anatoly ĝuste rimarkis, ke ni koncentriĝas pri modulareco. Kaj estonte vi povas efektivigi unu interfacon - prenu momentfoton, faru klonon, detruu la klonon. Ĉio estas facila. Kaj konservado estas malvarmeta, se ĝi estas.
Sed ZFS disponeblas por ĉiuj. DelPhix jam sufiĉas, ili havas 300 klientojn. El tiuj, fortuno 100 havas 50 klientojn, t.e. ili celas NASA, ktp. Estas tempo por ĉiuj akiri ĉi tiun teknologion. Kaj tial ni havas malfermfontan Kernon. Ni havas interfacan parton, kiu ne estas malferma fonto. Ĉi tiu estas la platformo, kiun ni montros. Sed ni volas, ke ĝi estu alirebla por ĉiuj. Ni volas fari revolucion por ke ĉiuj testantoj ĉesu diveni sur tekkomputiloj. Ni devas skribi SELECT kaj tuj vidi ke ĝi estas malrapida. Ĉesu atendi ke la DBA informos vin pri ĝi. Jen la ĉefa celo. Kaj mi pensas, ke ni ĉiuj venos al ĉi tio. Kaj ni faras ĉi tiun aferon por ke ĉiuj havu. Tial ZFS, ĉar ĝi estos disponebla ĉie. Dankon al la komunumo pro solvado de problemoj kaj pro posedo de liberkoda permesilo, ktp.*
Saluton! Dankon pro la raporto! Mia nomo estas Maxim. Ni traktis la samajn aferojn. Ili decidis memstare. Kiel vi dividas rimedojn inter ĉi tiuj klonoj? Ĉiu klono povas fari sian propran aferon en ajna momento: unu elprovas unu aferon, alian alian, iu konstruas indekson, iu havas pezan laboron. Kaj se vi ankoraŭ povas dividi per CPU, tiam per IO, kiel vi dividas? Jen la unua demando.
Kaj la dua demando temas pri la malsimileco de la standoj. Ni diru, ke mi havas ZFS ĉi tie kaj ĉio estas bonega, sed la kliento sur prod ne havas ZFS, sed ext4, ekzemple. Kiel en ĉi tiu kazo?
La demandoj estas tre bonaj. Mi iom menciis ĉi tiun problemon kun la fakto, ke ni dividas rimedojn. Kaj la solvo estas ĉi tio. Imagu, ke vi testas pri surscenigo. Vi ankaŭ povas havi tian situacion samtempe, ke iu donas unu ŝarĝon, iu alia. Kaj kiel rezulto, vi vidas nekompreneblajn metrikojn. Eĉ la sama problemo povas esti kun prod. Kiam vi volas kontroli iun peton kaj vi vidas ke estas ia problemo kun ĝi - ĝi funkcias malrapide, tiam fakte la problemo estis ne en la peto, sed en la fakto ke ekzistas ia paralela ŝarĝo.
Kaj tial gravas ĉi tie koncentriĝi pri kio estos la plano, kiajn paŝojn ni faros en la plano kaj kiom da datumoj ni levos por ĉi tio. La fakto, ke niaj diskoj, ekzemple, estos ŝarĝitaj per io, ĝi specife influos la tempigon. Sed ni povas taksi kiom ŝarĝita ĉi tiu peto estas laŭ la kvanto da datumoj. Ne tiom gravas, ke samtempe okazos ia ekzekuto.
Mi havas du demandojn. Ĉi tio estas tre bonega aĵo. Ĉu estis kazoj kie produktaddatenoj estas kritikaj, kiel ekzemple kreditkartaj nombroj? Ĉu jam estas io preta aŭ ĉu ĝi estas aparta tasko? Kaj la dua demando - ĉu ekzistas io tia por MySQL?
Pri la datumoj. Ni faros malklariĝon ĝis ni faros. Sed se vi deplojas ĝuste Joe, se vi ne donas aliron al programistoj, tiam ne estas aliro al la datumoj. Kial? Ĉar Joe ne montras datumojn. Ĝi nur montras metrikojn, planojn kaj jen ĝi. Ĉi tio estis farita intence, ĉar ĉi tio estas unu el la postuloj de nia kliento. Ili volis povi optimumigi sen doni al ĉiuj aliron.
Pri MySQL. Ĉi tiu sistemo povas esti uzata por ĉio, kio stokas staton sur disko. Kaj ĉar ni faras Postgres, ni nun faras la tutan aŭtomatigon por Postgres unue. Ni volas aŭtomatigi ricevi datumojn de sekurkopio. Ni agordas Postgres ĝuste. Ni scias kiel fari planojn kongrui ktp.
Sed ĉar la sistemo estas etendebla, ĝi ankaŭ povas esti uzata por MySQL. Kaj estas tiaj ekzemploj. Yandex havas similan aferon, sed ili ne publikigas ĝin ie ajn. Ili uzas ĝin ene de Yandex.Metrica. Kaj estas nur rakonto pri MySQL. Sed la teknologioj estas la samaj, ZFS.
Dankon pro la raporto! Mi ankaŭ havas kelkajn demandojn. Vi menciis, ke klonado povas esti uzata por analizo, ekzemple por konstrui pliajn indeksojn tie. Ĉu vi povas rakonti iom pli pri kiel ĝi funkcias?
Kaj mi tuj faros la duan demandon pri la simileco de la standoj, la simileco de la planoj. La plano dependas ankaŭ de la statistikoj kolektitaj de Postgres. Kiel vi solvas ĉi tiun problemon?
Laŭ la analizo, ne ekzistas specifaj kazoj, ĉar ni ankoraŭ ne uzis ĝin, sed ekzistas tia ŝanco. Se ni parolas pri indeksoj, tiam imagu, ke demando postkuras tabelon kun centoj da milionoj da registroj kaj kolumno, kiu kutime ne estas indeksita en prod. Kaj ni volas kalkuli iujn datumojn tie. Se ĉi tiu peto estas sendita al prod, tiam estas ebleco, ke ĝi estos simpla sur prod, ĉar la peto estos procesita tie dum minuto.
Bone, ni faru maldikan klonon, kiu ne estas terura halti dum kelkaj minutoj. Kaj por pli komfortigi legi la analizojn, ni aldonos indeksojn por tiuj kolumnoj, en kiuj ni interesiĝas pri datumoj.
La indekso estos kreita ĉiufoje?
Vi povas fari ĝin por ke ni tuŝu la datumojn, faru momentfotojn, tiam ni resaniĝos de ĉi tiu momentfoto kaj kondukos novajn petojn. Tio estas, vi povas fari ĝin tiel ke vi povas levi novajn klonojn kun jam fiksitaj indeksoj.
Koncerne la demandon pri statistiko, se ni restarigas de sekurkopio, se ni faras reproduktadon, tiam niaj statistikoj estos ĝuste la samaj. Ĉar ni havas la tutan fizikan datuman strukturon, tio estas, ni ankaŭ alportos la datumojn kiel ĝi estas kun ĉiuj statistikaj metrikoj.
Jen alia problemo. Se vi uzas nuban solvon, tiam nur logikaj rubejoj estas disponeblaj tie, ĉar Google, Amazon ne permesas al vi preni fizikan kopion. Estos problemo.
Dankon pro la prezento. Du bonaj demandoj estis levitaj ĉi tie pri MySQL kaj rimeda kunhavigo. Sed, esence, ĉio reduktiĝas al la fakto, ke ĉi tio ne estas temo por specifaj DBMS-oj, sed por la dosiersistemo kiel tuto. Kaj, sekve, rimedaj kunhavigaj problemoj ankaŭ devus esti traktataj de tie, ne nur en Postgres, sed en la dosiersistemo mem. servilo, ekzemple.
Mia demando estas iom malsama. Ĝi estas pli proksima al la plurtavola datumbazo, kie estas pluraj tavoloj. Ekzemple, ni starigas dek-terabajtan bildan ĝisdatigon, ni reproduktas. Kaj ni specife uzas ĉi tiun solvon por datumbazoj. Reproduktado estas en progreso, datumoj estas ĝisdatigitaj. Ĉi tie laboras paralele 100 dungitoj, kiuj konstante lanĉas ĉi tiujn malsamajn pafojn. Kion fari? Kiel certigi, ke ne ekzistas konflikto, ke ili lanĉis unu, kaj tiam la dosiersistemo ŝanĝiĝis, kaj ĉi tiuj bildoj ĉiuj iris?
Ili ne iros ĉar tiel funkcias ZFS. Ni povas konservi aparte en unu fadeno la dosiersistemojn ŝanĝojn kiuj venas pro reproduktado. Kaj konservu la klonojn, kiujn programistoj uzas en pli malnovaj versioj de la datumoj. Kaj ĝi funkcias por ni, ĉio estas en ordo kun ĉi tio.
Rezultas, ke la ĝisdatigo okazos kiel plia tavolo, kaj ĉiuj novaj bildoj jam iros, surbaze de ĉi tiu tavolo, ĉu ne?
De antaŭaj tavoloj kiuj estis de antaŭaj reproduktaĵoj.
La antaŭaj tavoloj defalos, sed ili referencos al la malnova tavolo, kaj ĉu ili prenos novajn bildojn de la lasta tavolo, kiu estis ricevita en la ĝisdatigo?
Ĝenerale, jes.
Tiam kiel konsekvenco ni havos ĝis figo da tavoloj. Kaj kun la tempo ili devos esti kunpremitaj?
Jes ĉio estas ĝusta. Estas iu fenestro. Ni konservas semajnajn momentfotojn. Ĝi dependas de kia rimedo vi havas. Se vi havas la kapablon stoki multajn datumojn, vi povas konservi momentfotojn dum longa tempo. Ili ne foriros memstare. Ne estos korupto de datumoj. Se la momentfotoj estas malmodernaj, kiel ŝajnas al ni, tio dependas de la politiko en la kompanio, tiam ni povas simple forigi ilin kaj liberigi spacon.
Saluton, dankon pro la raporto! Demando pri Joe. Vi diris, ke la kliento ne volis doni al ĉiuj aliron al la datumoj. Strikte parolante, se persono havas la rezulton de Klarigi Analizon, tiam li povas rigardi la datumojn.
Estas tiel. Ekzemple, ni povas skribi: "SELECT FROM WHERE retpoŝto = al tio". Tio estas, ni ne vidos la datumojn mem, sed ni povas vidi iujn nerektajn signojn. Ĉi tio devas esti komprenita. Sed aliflanke, ĉio estas tie. Ni havas protokolan revizion, ni havas kontrolon de aliaj kolegoj, kiuj ankaŭ vidas, kion faras la programistoj. Kaj se iu provas fari tion, tiam la sekureca servo venos al ili kaj laboros pri ĉi tiu afero.
Bonan posttagmezon Dankon pro la raporto! Mi havas mallongan demandon. Se la firmao ne uzas Slack, ĉu ekzistas ia ligo al ĝi nun, aŭ ĉu eblas por programistoj deploji petskribojn por konekti testan aplikaĵon al la datumbazoj?
Nun estas ligilo al Slack, t.e. ne ekzistas alia mesaĝisto, sed mi vere volas fari subtenon ankaŭ por aliaj mesaĝistoj. Kion vi povas fari? Vi povas disfaldi DB Lab sen Joe, iri kun la helpo de la REST API aŭ kun la helpo de nia platformo kaj krei klonojn kaj konekti kun PSQL. Sed ĉi tio povas esti farita se vi pretas doni al viaj programistoj aliron al la datumoj, ĉar ne plu estos ekrano.
Mi ne bezonas ĉi tiun tavolon, sed mi bezonas tian ŝancon.
Tiam jes, ĝi povas esti farita.
fonto: www.habr.com
