

Ĉiuj parolas pri la procezoj de disvolviĝo kaj testado, trejnado de personaro, pliigo de motivado, sed ĉi tiuj procezoj ne sufiĉas kiam minuto da servo malfunkcio kostas grandegajn kvantojn da mono. Kion fari kiam vi faras financajn transakciojn sub strikta SLA? Kiel pliigi la fidindecon kaj toleremon al misfunkciadoj de viaj sistemoj, elprenante disvolviĝon kaj testadon el la ekvacio?

La sekva HighLoad++-konferenco okazos la 6-an kaj 7-an de aprilo 2020 en Sankt-Peterburgo. Detaloj kaj biletoj por . 9-a de novembro, 18:00. HighLoad++ Moskvo 2018, Delhio + Kolkata halo. Tezoj kaj .
Evgeniy Kuzovlev (ĉi-poste - EK): - Amikoj, saluton! Mia nomo estas Kuzovlev Evgeniy. Mi estas de la kompanio EcommPay, specifa divido estas EcommPay IT, la IT-dividado de la grupo de kompanioj. Kaj hodiaŭ ni parolos pri malfunkcioj - pri kiel eviti ilin, pri kiel minimumigi iliajn konsekvencojn, se ĝi ne povas esti evitita. La temo estas deklarita jene: "Kion fari kiam minuto da malfunkcio kostas $100"? Rigardante antaŭen, niaj nombroj estas kompareblaj.
Kion faras EcommPay IT?
Kiuj ni estas? Kial mi staras ĉi tie antaŭ vi? Kial mi havas la rajton diri ion al vi ĉi tie? Kaj pri kio ni parolos ĉi tie pli detale?
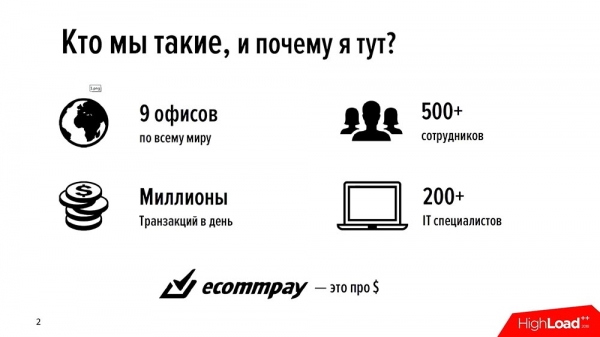
EcommPay-grupo de kompanioj estas internacia akiranto. Ni procesas pagojn tra la tuta mondo - en Rusio, Eŭropo, Sudorienta Azio (Ĉirkaŭ la Mondo). Ni havas 9 oficejojn, 500 dungitojn entute, kaj proksimume iom malpli ol duono de ili estas IT-specialistoj. Ĉion, kion ni faras, ĉion, kion ni gajnas monon, ni mem faris.
Ni mem skribis ĉiujn niajn produktojn (kaj ni havas sufiĉe multe da ili - en nia vico de grandaj IT-produktoj ni havas ĉirkaŭ 16 malsamajn komponantojn) mem; Ni mem skribas, ni evoluigas nin. Kaj nuntempe ni efektivigas ĉirkaŭ milionon da transakcioj tage (milionoj verŝajne estas la ĝusta maniero diri ĝin). Ni estas sufiĉe juna firmao - ni aĝas nur ĉirkaŭ ses jarojn.
Antaŭ 6 jaroj estis tia noventrepreno kiam la uloj venis kune kun la komerco. Ili estis kunigitaj per ideo (estis nenio alia ol ideo), kaj ni kuris. Kiel ĉiu starto, ni kuris pli rapide... Por ni, rapideco estis pli grava ol kvalito.
Iam ni haltis: ni rimarkis, ke ni ne plu iel povas vivi je tiu rapido kaj kun tiu kvalito kaj ni devis unue koncentriĝi pri kvalito. En ĉi tiu momento, ni decidis skribi novan platformon, kiu estus ĝusta, skalebla kaj fidinda. Ili komencis verki ĉi tiun platformon (ili komencis investi, disvolvi disvolviĝon, testadon), sed iam ili rimarkis, ke disvolviĝo kaj testado ne permesis al ni atingi novan nivelon de servokvalito.
Vi faras novan produkton, vi metas ĝin en produktadon, sed tamen io misfunkcios ie. Kaj hodiaŭ ni parolos pri kiel atingi novan kvalitan nivelon (kiel ni faris ĝin, pri nia sperto), elprenante evoluon kaj testadon el la ekvacio; ni parolos pri tio, kio estas disponebla por funkciado - kian operacion povas fari mem, kion ĝi povas proponi al testado por influi kvaliton.
Malfunkcioj. Ordonoj de operacio.
Ĉiam la ĉefa bazŝtono, pri kio ni vere parolos hodiaŭ estas malfunkcio. Terura vorto. Se ni havas malfunkcion, ĉio estas malbona por ni. Ni kuras por levi ĝin, la administrantoj tenas la servilon - Dio gardu, ke ĝi ne falu, kiel oni diras en tiu kanto. Jen pri kio ni parolos hodiaŭ.

Kiam ni komencis ŝanĝi niajn alirojn, ni formis 4 ordonojn. Mi havas ilin prezentitaj sur la lumbildoj:
Ĉi tiuj ordonoj estas sufiĉe simplaj:

- Rapide identigu la problemon.
- Forigu ĝin eĉ pli rapide.
- Helpu kompreni la kialon (poste, por programistoj).
- Kaj normigi alirojn.
Mi ŝatus atentigi vin pri la punkto n-ro 2. Ni forigas la problemon, ne solvas ĝin. Decidi estas malĉefa. Por ni, la ĉefa afero estas, ke la uzanto estas protektita kontraŭ ĉi tiu problemo. Ĝi ekzistos en iu izolita medio, sed ĉi tiu medio ne havos ajnan kontakton kun ĝi. Efektive, ni trairos ĉi tiujn kvar grupojn de problemoj (kelkaj pli detale, iuj malpli detale), mi rakontos al vi, kion ni uzas, kian koncernan sperton ni havas pri solvoj.
Solvado de problemoj: Kiam ili okazas kaj kion fari pri ili?
Sed ni komencos senorde, ni komencos per la punkto n-ro 2 - kiel rapide forigi la problemon? Estas problemo - ni devas ripari ĝin. "Kion ni faru pri ĉi tio?" - la ĉefa demando. Kaj kiam ni komencis pensi pri kiel ripari la problemon, ni mem ellaboris kelkajn postulojn, kiujn la solvo de problemoj devas sekvi.

Por formuli ĉi tiujn postulojn, ni decidis demandi al ni mem la demandon: "Kiam ni havas problemojn"? Kaj problemoj, kiel montriĝis, okazas en kvar kazoj:

- Fiasko de aparataro.
- Eksteraj servoj malsukcesis.
- Ŝanĝi la programversion (la sama disfaldas).
- Kresko de eksploda ŝarĝo.
Ni ne parolos pri la unuaj du. Malfunkcio de aparataro povas esti solvita tute simple: vi devas havi ĉion duobligita. Se ĉi tiuj estas diskoj, la diskoj devas esti kunmetitaj en RAID; se ĉi tio estas servilo, la servilo devas esti duobligita; se vi havas retan infrastrukturon, vi devas provizi duan kopion de la reto-infrastrukturo, tio estas, vi prenu ĝin kaj duobligu ĝin. Kaj se io malsukcesas, vi ŝanĝas al rezervi potencon. Estas malfacile diri ion pli ĉi tie.
La dua estas la fiasko de eksteraj servoj. Por la plimulto, la sistemo tute ne estas problemo, sed ne por ni. Ĉar ni procesas pagojn, ni estas agreganto, kiu staras inter la uzanto (kiu enigas siajn kartajn datumojn) kaj bankoj, pagsistemoj (Visa, MasterCard, Mira, ktp.). Niaj eksteraj servoj (pagsistemoj, bankoj) tendencas malsukcesi. Nek ni nek vi (se vi havas tiajn servojn) povas influi tion.
Kion fari do? Estas du ebloj ĉi tie. Unue, se vi povas, vi devus iel duobligi ĉi tiun servon. Ekzemple, se ni povas, ni translokigas trafikon de unu servo al alia: ekzemple, kartoj estis prilaboritaj per Sberbank, Sberbank havas problemojn - ni transdonas trafikon [kondiĉe] al Raiffeisen. La dua afero, kiun ni povas fari, estas rimarki la fiaskon de eksteraj servoj tre rapide, kaj tial ni parolos pri respondrapideco en la sekva parto de la raporto.
Fakte, el ĉi tiuj kvar, ni povas specife influi la ŝanĝon de programaraj versioj - fari agojn, kiuj kondukos al plibonigo de la situacio en la kunteksto de deplojoj kaj en la kunteksto de eksploda kresko de ŝarĝo. Efektive, tion ni faris. Jen, denove, eta noto...
El ĉi tiuj kvar problemoj, pluraj estas solvitaj tuj se vi havas nubon. Se vi estas en la Microsoft Azhur, Ozonaj nuboj, aŭ uzas niajn nubojn, de Yandex aŭ Mail, tiam almenaŭ aparatara misfunkcio fariĝas ilia problemo kaj ĉio tuj fariĝas bona por vi en la kunteksto de aparatara misfunkcio.
Ni estas iomete nekonvencia firmao. Ĉi tie ĉiuj parolas pri "Kubernets", pri nuboj - ni havas nek "Kubernets" nek nubojn. Sed ni havas rakojn da aparataro en multaj datumcentroj, kaj ni estas devigitaj vivi per ĉi tiu aparataro, ni estas devigitaj respondeci pri ĉio. Tial ni parolos en ĉi tiu kunteksto. Do, pri la problemoj. La unuaj du estis elprenitaj el krampoj.
Ŝanĝi la programversion. Bazoj
Niaj programistoj ne havas aliron al produktado. Kial estas tio? Estas nur, ke ni estas atestitaj PCI DSS, kaj niaj programistoj simple ne rajtas eniri la "produkton". Jen ĝi, punkto. Entute. Tial, evolurespondeco finiĝas ĝuste en la momento, kiam evoluo sendas la konstruon por liberigo.

Nia dua bazo kiun ni havas, kiu ankaŭ helpas nin multe, estas la foresto de unika nedokumentita scio. Mi esperas, ke estas same por vi. Ĉar se ĉi tio ne estas la kazo, vi havos problemojn. Problemoj aperos kiam ĉi tiu unika, nedokumentita scio ne ĉeestas en la ĝusta tempo en la ĝusta loko. Ni diru, ke vi havas unu personon, kiu scias kiel disfaldi specifan komponanton - la persono ne estas tie, li estas ferianta aŭ malsana - jen ĝi, vi havas problemojn.
Kaj la tria bazo al kiu ni venis. Ni venis al ĝi per doloro, sango, larmoj - ni alvenis al la konkludo, ke iu ajn el niaj konstruaĵoj enhavas erarojn, eĉ se ĝi estas senerara. Ni decidis ĉi tion por ni mem: kiam ni deplojas ion, kiam ni ruliĝas ion en produktadon, ni havas konstruaĵon kun eraroj. Ni formis la postulojn, kiujn nia sistemo devas kontentigi.
Postuloj por ŝanĝi la programversion
Estas tri postuloj:

- Ni devas rapide retiriĝi la deplojon.
- Ni devas minimumigi la efikon de malsukcesa deplojo.
- Kaj ni devas povi rapide deploji paralele.
Ĝuste en tiu ordo! Kial? Ĉar, antaŭ ĉio, kiam oni disvastigas novan version, rapideco ne gravas, sed gravas por vi, se io misfunkcias, rapide reveni kaj havi minimuman efikon. Sed se vi havas aron da versioj en produktado, por kiuj rezultas, ke estas eraro (ekstere, ne estis disvastiĝo, sed estas eraro) - la rapideco de posta disvastigo estas grava por vi. Kion ni faris por plenumi ĉi tiujn postulojn? Ni uzis la jenan metodaron:
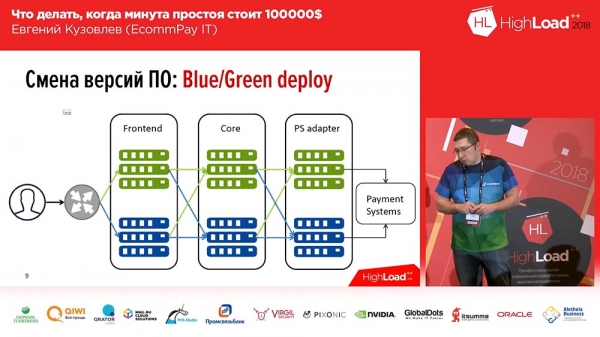
Ĝi estas sufiĉe konata, ni neniam inventis ĝin - ĉi tio estas Blua/Verda deplojo. Kio ĝi estas? Vi devas havi kopion por ĉiu grupo de serviloj sur kiuj viaj aplikaĵoj estas instalitaj. La kopio estas "varma": ne estas trafiko sur ĝi, sed ĉiumomente ĉi tiu trafiko povas esti sendita al ĉi tiu kopio. Ĉi tiu kopio enhavas la antaŭan version. Kaj en la momento de deplojo, vi ruliĝas la kodon al neaktiva kopio. Tiam vi ŝanĝas parton de la trafiko (aŭ ĉion) al la nova versio. Tiel, por ŝanĝi la trafikfluon de la malnova versio al la nova, vi devas fari nur unu agon: vi devas ŝanĝi la ekvilibron en la kontraŭfluo, ŝanĝi la direkton - de unu kontraŭflue al alia. Ĉi tio estas tre oportuna kaj solvas la problemon de rapida ŝanĝado kaj rapida retroiro.Ĉi tie la solvo de la dua demando estas minimumigo: vi povas sendi nur parton de via trafiko al nova linio, al linio kun nova kodo (estu, ekzemple, 2%). Kaj ĉi tiuj 2% ne estas 100%! Se vi perdis 100% de via trafiko pro malsukcesa deplojo, tio estas timiga; se vi perdis 2% de via trafiko, tio estas malagrabla, sed ne timigas. Cetere, uzantoj plej verŝajne eĉ ne rimarkos tion, ĉar en iuj kazoj (ne en ĉiuj) la sama uzanto, premante F5, estos prenita al alia, funkcianta versio.
Blua/Verda deplojo. Envojigo
Tamen, ne ĉio estas tiel simpla "Blua/Verda deplojo"... Ĉiuj niaj komponantoj povas esti dividitaj en tri grupojn:
- ĉi tio estas la fasado (paĝaj paĝoj, kiujn vidas niaj klientoj);
- pretiga kerno;
- adaptilo por labori kun pagsistemoj (bankoj, MasterCard, Visa...).
Kaj ĉi tie estas nuanco - la nuanco kuŝas en la vojigo inter la linioj. Se vi nur ŝanĝas 100% de la trafiko, vi ne havas ĉi tiujn problemojn. Sed se vi volas ŝanĝi 2%, vi komencas demandi demandojn: "Kiel fari tion?" La plej simpla afero estas rekta: vi povas agordi Round Robin en nginx per hazarda elekto, kaj vi havas 2% maldekstren, 98% dekstren. Sed ĉi tio ne ĉiam taŭgas.
Ekzemple, en nia kazo, uzanto interagas kun la sistemo kun pli ol unu peto. Ĉi tio estas normala: 2, 3, 4, 5 petoj - viaj sistemoj eble estas la samaj. Kaj se gravas por vi, ke ĉiuj uzantpetoj venu al la sama linio, sur kiu venis la unua peto, aŭ (dua punkto) ĉiuj uzantpetoj venu al nova linio post ŝanĝado (li povus esti komencinta labori pli frue kun la sistemo, antaŭ ol ŝaltilo), - tiam ĉi tiu hazarda distribuo ne taŭgas por vi. Tiam estas la sekvaj opcioj:
La unua opcio, la plej simpla, baziĝas sur la bazaj parametroj de la kliento (IP Hash). Vi havas IP-on, kaj vi dividas ĝin de dekstre al maldekstre per IP-adreso. Tiam la dua kazo, kiun mi priskribis, funkcios por vi, kiam la disfaldiĝo okazis, la uzanto jam povus eklabori kun via sistemo, kaj ekde la momento de la disvastigo ĉiuj petoj iros al nova linio (al la sama, ekzemple).Se ial ĉi tio ne konvenas al vi kaj vi devas sendi petojn al la linio kie venis la komenca, komenca peto de la uzanto, tiam vi havas du eblojn...
Unua opcio: vi povas aĉeti pagitan nginx+. Estas mekanismo de Sticky-sesioj, kiu, laŭ la komenca peto de la uzanto, asignas sesion al la uzanto kaj ligas ĝin al unu aŭ alia kontraŭflue. Ĉiuj postaj uzantpetoj ene de la sesiovivdaŭro estos senditaj al la sama kontraŭflue kie la sesio estis afiŝita.Ĉi tio ne konvenis al ni ĉar ni jam havis regulan nginx. Ŝanĝi al nginx+ ne estas ke ĝi estas multekosta, nur ke ĝi estis iom dolora por ni kaj ne tre ĝusta. "Sticks Sessions", ekzemple, ne funkciis por ni pro la simpla kialo, ke "Sticks Sessions" ne permesas vojigon bazitan sur "Either-or". Tie vi povas specifi kion ni "Sticks Sessions" faras, ekzemple, per IP-adreso aŭ per IP-adreso kaj kuketoj aŭ per postparametro, sed "Aŭ-aŭ" estas pli komplika tie.
Tial ni venis al la kvara opcio. Ni prenis nginx per steroidoj (ĉi tio estas openresty) - ĉi tio estas la sama nginx, kiu aldone subtenas la inkludon de lastaj skriptoj. Vi povas skribi lastan skripton, doni al ĝi "malfermitan ripozon", kaj ĉi tiu lasta skripto estos plenumita kiam venos la peto de la uzanto.
Kaj ni verkis, fakte, tian skripton, starigis nin "openresti" kaj en ĉi tiu skripto ni ordigas 6 malsamajn parametrojn per kunligado "Aŭ". Depende de la ĉeesto de unu aŭ alia parametro, ni scias, ke la uzanto venis al unu aŭ alia paĝo, unu aŭ alia linio.
Blua/Verda deplojo. Avantaĝoj kaj malavantaĝoj
Kompreneble, verŝajne eblis iom pli simpla (uzu la samajn "Glosiĝajn Sesiojn"), sed ni ankaŭ havas tian nuancon, ke ne nur la uzanto interagas kun ni kadre de unu prilaborado de unu transakcio... Sed pagsistemoj ankaŭ interagas kun ni: Post kiam ni prilaboras la transakcion (sendante peton al la pagsistemo), ni ricevas coolback.
Kaj ni diru, se ene de nia cirkvito ni povas plusendi la IP-adreson de la uzanto en ĉiuj petoj kaj dividi uzantojn surbaze de la IP-adreso, tiam ni ne diros la saman "Vizon": "Ho, ni estas tia retrofirmao, ni ŝajnas. esti internacia (en la retejo kaj en Rusio)... Bonvolu provizi al ni la IP-adreson de la uzanto en plia kampo, via protokolo estas normigita”! Estas klare, ke ili ne konsentos.
Tial ĉi tio ne funkciis por ni - ni faris malferman reskonton. Sekve, kun vojigo ni ricevis ion tian:Blua/Verda Deplojo havas sekve la avantaĝojn, kiujn mi menciis, kaj malavantaĝojn.
Du malavantaĝoj:
- vi devas ĝeni vin per vojigo;
- la dua ĉefa malavantaĝo estas la elspezo.
Vi bezonas duoble pli da serviloj, vi bezonas duoble pli da operaciaj rimedoj, vi devas elspezi duoble pli da penado por konservi ĉi tiun tutan zoon.
Cetere, inter la avantaĝoj estas ankoraŭ unu afero, kiun mi antaŭe ne menciis: vi havas rezervon en kazo de kresko de ŝarĝo. Se vi havas eksplodeman kreskon de ŝarĝo, vi havas grandan nombron da uzantoj, tiam vi simple inkluzivas la duan linion en la 50 ĝis 50-distribuo - kaj vi tuj havas x2-servilojn en via areto ĝis vi solvas la problemon havi pli da serviloj.
Kiel fari rapidan deplojon?
Ni parolis pri kiel solvi la problemon de minimumigo kaj rapida retroigo, sed la demando restas: "Kiel disfaldi rapide?"
Ĝi estas mallonga kaj simpla ĉi tie.- Vi devas havi KD-sistemon (Kontinua Livero) - vi ne povas vivi sen ĝi. Se vi havas unu servilon, vi povas deploji permane. Ni havas ĉirkaŭ unu kaj duonon mil servilojn kaj unu kaj duonon mil tenilojn, kompreneble - ni povas planti fakon de la grandeco de ĉi tiu ĉambro nur por deploji.
- Deplojo devas esti paralela. Se via deplojo estas sinsekva, tiam ĉio estas malbona. Unu servilo estas normala, vi deplojos unu kaj duonon mil servilojn la tutan tagon.
- Denove, por akcelo, ĉi tio verŝajne ne plu necesas. Dum deplojo, la projekto estas kutime konstruita. Vi havas TTT-projekton, ekzistas fronta parto (vi faras tie retpakon, vi kompilas npm - ion tian), kaj ĉi tiu procezo principe estas mallongdaŭra - 5 minutoj, sed ĉi tiuj 5 minutoj povas estu kritika. Tial, ekzemple, ni ne faras tion: ni forigis ĉi tiujn 5 minutojn, ni deplojas artefaktojn.
Kio estas artefakto? Artefakto estas kunmetita konstruo en kiu ĉiuj kunigpartoj jam estis finitaj. Ni stokas ĉi tiun artefakton en la artefakto-stokado. Siatempe ni uzis du tiajn konservaĵojn - ĝi estis Nexus kaj nun jFrog Artifactory).Ni komence uzis "Nexus" ĉar ni komencis praktiki ĉi tiun aliron en java-aplikoj (ĝi taŭgis al ĝi). Tiam ili enmetis kelkajn el la aplikaĵoj skribitaj en PHP tien; kaj "Nexus" ne plu estis taŭga, kaj tial ni elektis jFrog Artefactory, kiu povas artefari preskaŭ ĉion. Ni eĉ venis al la punkto, ke en ĉi tiu artefakto-deponejo ni stokas niajn proprajn binarajn pakaĵojn, kiujn ni kolektas por serviloj.
Kresko de eksploda ŝarĝo
Ni parolis pri ŝanĝado de la programara versio. La sekva afero, kiun ni havas, estas eksploda pliigo de ŝarĝo. Ĉi tie, mi verŝajne volas diri per eksploda kresko de la ŝarĝo ne tute ĝustan aferon...
Ni verkis novan sistemon - ĝi estas servo-orientita, moda, bela, laboristoj ĉie, vicoj ĉie, malsinkronio ĉie. Kaj en tiaj sistemoj, datumoj povas flui tra malsamaj fluoj. Por la unua transakcio, la 1-a, 3-a, 10-a laboristo povas esti uzata, por la dua transakcio - la 2-a, 4-a, 5-a. Kaj hodiaŭ, ni diru, matene vi havas datumfluon, kiu uzas la tri unuajn laboristojn, kaj vespere ĝi draste ŝanĝiĝas, kaj ĉio uzas la aliajn tri laboristojn.
Kaj ĉi tie rezultas, ke vi devas iel grimpi la laboristojn, vi devas iel grimpi viajn servojn, sed samtempe malhelpi rimedŝveladon.
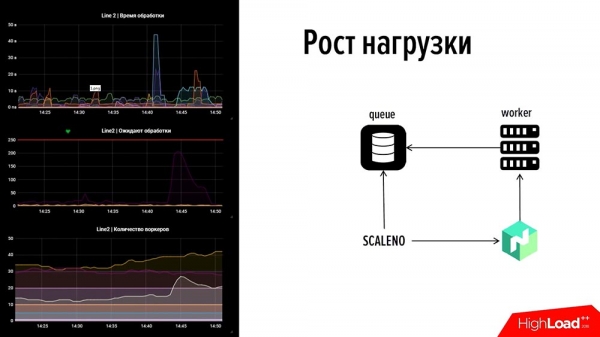
Ni difinis niajn postulojn. Ĉi tiuj postuloj estas sufiĉe simplaj: ke estu Servo-malkovro, parametrigo - ĉio estas norma por konstrui tiajn skaleblajn sistemojn, krom unu punkto - resursa depreco. Ni diris, ke ni ne pretas amortizi rimedojn, por ke la serviloj varmigu la aeron. Ni prenis "Konsulon", ni prenis "Nomadon", kiu administras niajn laboristojn.Kial ĉi tio estas problemo por ni? Ni iomete retroiru. Ni nun havas ĉirkaŭ 70 pagsistemojn malantaŭ ni. Matene, trafiko iras tra Sberbank, tiam Sberbank falis, ekzemple, kaj ni ŝanĝas ĝin al alia pagsistemo. Ni havis 100 laboristojn antaŭ Sberbank, kaj post tio ni devas akre pliigi 100 laboristojn por alia pagsistemo. Kaj estas dezirinde, ke ĉio ĉi okazu sen homa partopreno. Ĉar se estas homa partopreno, tie sidu 24/7 inĝeniero, kiu nur faru tion, ĉar tiaj misfunkciadoj, kiam 70 sistemoj estas malantaŭ vi, okazas regule.
Sekve, ni rigardis Nomad, kiu havas malfermitan IP, kaj skribis nian propran aferon, Scale-Nomad - ScaleNo, kiu faras proksimume la jenon: ĝi kontrolas la kreskon de la atendovico kaj reduktas aŭ pliigas la nombron da laboristoj depende de la dinamiko. de la vico. Kiam ni faris ĝin, ni pensis: "Eble ni povas malfermi ĝin?" Tiam ili rigardis ŝin — ŝi estis simpla kiel du kopekoj.
Ĝis nun ni ne malfermis ĝin, sed se subite post la raporto, post konstato, ke vi bezonas tian aferon, vi bezonas ĝin, miaj kontaktoj estas en la lasta diapozitivo - bonvolu skribi al mi. Se estas almenaŭ 3-5 homoj, ni sponsoros ĝin.
Kiel ĝi funkcias? Ni rigardu! Rigardante antaŭen: sur la maldekstra flanko estas peco de nia monitorado: ĉi tio estas unu linio, supre estas la tempo de evento-prilaborado, en la mezo estas la nombro da transakcioj, malsupre estas la nombro da laboristoj.Se vi rigardas, estas eraro en ĉi tiu bildo. Sur la supra diagramo, unu el la leteroj kraŝis en 45 sekundoj - unu el la pagsistemoj falis. Tuj, trafiko estis alportita en 2 minutoj kaj la vico komencis kreski sur alia pagsistemo, kie mankis laboristoj (ni ne uzis rimedojn - male, ni forigis la rimedon ĝuste). Ni ne volis varmigi - estis minimuma nombro, ĉirkaŭ 5-10 laboristoj, sed ili ne povis elteni.
La lasta grafikaĵo montras "ĝibon", kio nur signifas, ke "Skaleno" duobligis ĉi tiun kvanton. Kaj tiam, kiam la grafiko iomete malleviĝis, li iomete reduktis ĝin - la nombro de laboristoj estis aŭtomate ŝanĝita. Tiel funkcias ĉi tiu afero. Ni parolis pri punkto numero 2 - "Kiel rapide forigi kialojn."
Monitorado. Kiel rapide identigi la problemon?
Nun la unua punkto estas "Kiel rapide identigi la problemon?" Monitorado! Ni devas kompreni iujn aferojn rapide. Kiajn aferojn ni komprenu rapide?
Tri aferoj!- Ni devas kompreni kaj kompreni rapide la agadon de niaj propraj rimedoj.
- Ni devas rapide kompreni misfunkciadojn kaj kontroli la agadon de sistemoj eksteraj al ni.
- La tria punkto estas identigado de logikaj eraroj. Jen kiam la sistemo funkcias por vi, ĉio estas normala laŭ ĉiuj indikiloj, sed io misfunkcias.
Mi verŝajne ne diros al vi ion ajn bonegan ĉi tie. Mi estos Kapitano Obvious. Ni serĉis kio estis sur la merkato. Ni havas "amuzan zoon". Jen la speco de zoo, kiun ni havas nun:
Ni uzas Zabbix por monitori aparataron, por monitori la ĉefajn indikilojn de serviloj. Ni uzas Okmeter por datumbazoj. Ni uzas "Grafana" kaj "Prometheus" por ĉiuj aliaj indikiloj, kiuj ne konvenas al la unuaj du, iuj kun "Grafana" kaj "Prometheus", kaj iuj kun "Grafana" kun "Influx" kaj Telegraf.Antaŭ unu jaro ni volis uzi New Relic. Mirinda afero, ĝi povas fari ĉion. Sed kiom ŝi povas ĉion fari, ŝi estas tiom multekosta. Kiam ni kreskis al volumo de 1,5 mil serviloj, vendisto venis al ni kaj diris: "Ni konkludu interkonsenton por la venonta jaro." Ni rigardis la prezon kaj diris ne, ni ne faros tion. Nun ni forlasas Novan Relikon, ni restas ĉirkaŭ 15 serviloj sub la viglado de New Relic. La prezo montriĝis absolute sovaĝa.
Kaj estas unu ilo, kiun ni mem efektivigis - ĉi tiu estas Senĉimilo. Komence ni nomis ĝin "Bagger", sed poste preterpasis angla instruisto, sovaĝe ridis kaj renomis ĝin "Debagger". Kio ĝi estas? Ĉi tio estas ilo, kiu fakte en 15-30 sekundoj sur ĉiu komponanto, kiel "nigra skatolo" de la sistemo, faras provojn pri la ĝenerala rendimento de la komponanto.
Ekzemple, se ekzistas ekstera paĝo (pagpaĝo), li simple malfermas ĝin kaj rigardas kiel ĝi devus aspekti. Se ĉi tio estas prilaborado, li sendas teston "transakcio" kaj certigas, ke ĉi tiu "transakcio" alvenas. Se ĉi tio estas konekto kun pagsistemoj, ni laŭe lanĉas testan peton, kie ni povas, kaj vidas, ke ĉio estas en ordo ĉe ni.
Kiuj indikiloj estas gravaj por monitorado?
Kion ni ĉefe kontrolas? Kiuj indikiloj estas gravaj por ni?
- Respondtempo / RPS ĉe frontoj estas tre grava indikilo. Li tuj respondas, ke io misas ĉe vi.
- La nombro da prilaboritaj mesaĝoj en ĉiuj atendovicoj.
- Nombro de laboristoj.
- Bazaj korektecaj metrikoj.
La lasta punkto estas "komerco", "komerco" metriko. Se vi volas kontroli la samon, vi devas difini unu aŭ du metrikojn, kiuj estas la ĉefaj indikiloj por vi. Nia metriko estas trafluo (ĉi tio estas la rilatumo de la nombro da sukcesaj transakcioj al la totala transakcia fluo). Se io ŝanĝiĝas en ĝi je intervalo de 5-10-15 minutoj, tio signifas, ke ni havas problemojn (se ĝi ŝanĝiĝas radikale).
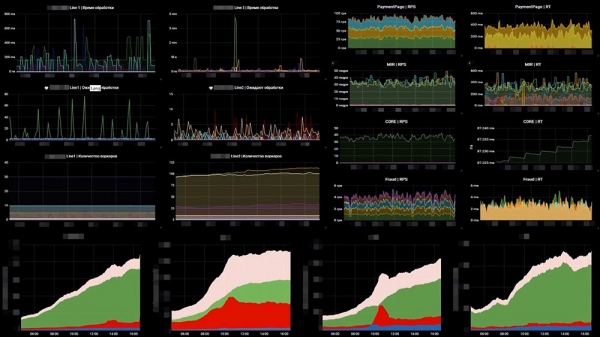
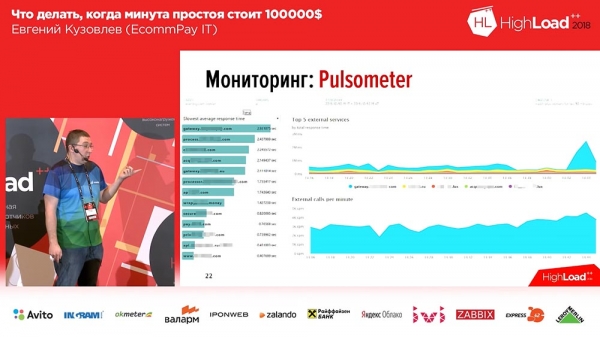
Kia ĝi aspektas por ni estas ekzemplo de unu el niaj tabuloj:
Sur la maldekstra flanko estas 6 grafikaĵoj, tio estas laŭ la linioj - la nombro da laboristoj kaj la nombro da mesaĝoj en la atendovicoj. Sur la dekstra flanko - RPS, RTS. Malsupre estas la sama "komerca" metriko. Kaj en la "komerca" metriko ni tuj povas vidi, ke io misfunkciis en la du mezaj grafikaĵoj... Ĉi tio estas nur alia sistemo, kiu staras malantaŭ ni, kiu falis.La dua afero, kiun ni devis fari, estis kontroli la falon de eksteraj pagsistemoj. Ĉi tie ni prenis OpenTracing - mekanismon, normo, paradigmon, kiu ebligas al vi spuri distribuitajn sistemojn; kaj ĝi estis iom ŝanĝita. La norma OpenTracing-paradigmo diras, ke ni konstruas spuron por ĉiu individua peto. Ni ne bezonis ĉi tion, kaj ni envolvis ĝin en resuman, agregan spuron. Ni faris ilon, kiu ebligas al ni spuri la rapidecon de la sistemoj malantaŭ ni.
La grafikaĵo montras al ni, ke unu el la pagsistemoj komencis respondi en 3 sekundoj - ni havas problemojn. Krome, ĉi tiu afero reagos kiam problemoj komenciĝos, je intervalo de 20-30 sekundoj.Kaj la tria klaso de monitoraj eraroj, kiuj ekzistas, estas logika monitorado.
Verdire, mi ne sciis, kion desegni sur ĉi tiu glito, ĉar ni delonge serĉis sur la merkato ion, kio konvenus al ni. Ni trovis nenion, do ni mem devis fari ĝin.
Kion mi volas diri per logika monitorado? Nu, imagu: vi faras al vi sistemon (ekzemple Tinder-klono); vi faris ĝin, lanĉis ĝin. Sukcesa administranto Vasja Pupkin metis ĝin sur sian telefonon, vidas knabinon tie, ŝatas ŝin... kaj similaĵo ne iras al la knabino - simila iras al la sekureca gardisto Miĥaliĉ el la sama komerca centro. La direktisto malsupreniras, kaj tiam demandas sin: "Kial ĉi tiu sekuristo Miĥaliĉ tiel agrable ridetas al li?"En tiaj situacioj... Por ni, ĉi tiu situacio sonas iom alie, ĉar (mi skribis) tio estas reputacia perdo, kiu nerekte kondukas al financaj perdoj. Nia situacio estas la malo: ni povas suferi rektajn financajn perdojn - ekzemple, se ni faris transakcion kiel sukcesa, sed ĝi estis malsukcesa (aŭ inverse). Mi devis skribi mian propran ilon, kiu spuras la nombron da sukcesaj transakcioj laŭlonge de la tempo uzante komercajn indikilojn. Trovis nenion sur la merkato! Ĝuste ĉi tio estas la ideo, kiun mi volis transdoni. Estas nenio sur la merkato por solvi tian problemon.
Ĉi tio temis pri kiel rapide identigi la problemon.
Kiel determini la kialojn de deplojo
La tria grupo de problemoj, kiujn ni solvas, estas post kiam ni identigis la problemon, post kiam ni forigis ĝin, estus bone kompreni la kialon de evoluo, por testado, kaj fari ion pri ĝi. Sekve, ni devas esplori, ni devas levi la ŝtipojn.
Se ni parolas pri protokoloj (la ĉefa kialo estas protokoloj), la plej granda parto de niaj protokoloj estas en ELK-Stako - preskaŭ ĉiuj havas la samon. Por iuj, ĝi eble ne estas en ELK, sed se vi skribas protokolojn en gigabajtoj, tiam pli aŭ malpli frue vi venos al ELK. Ni skribas ilin en terabajtoj.
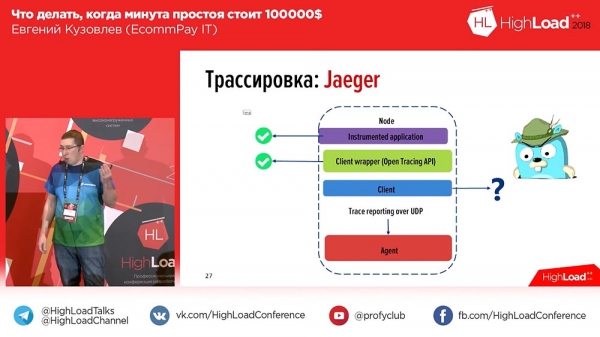
Estas problemo ĉi tie. Ni riparis ĝin, korektis la eraron por la uzanto, komencis elfosi kio estis tie, grimpis en Kibana, enmetis la transakcian identigilon tie kaj akiris piedtukon kiel ĉi tio (montras multon). Kaj absolute nenio estas klara en ĉi tiu piedtuko. Kial? Jes, ĉar ne estas klare, kiu parto apartenas al kiu laboristo, kiu parto apartenas al kiu komponanto. Kaj en tiu momento ni konstatis, ke ni bezonas spuradon - la saman OpenTracing, pri kiu mi parolis.Ni pensis ĉi tion antaŭ unu jaro, turnis nian atenton al la merkato, kaj tie estis du iloj - "Zipkin" kaj "Jaeger". "Jager" estas fakte tia ideologia heredanto, ideologia posteulo de "Zipkin". Ĉio estas bona en Zipkin, krom ke ĝi ne scias kiel kunigi, ĝi ne scias kiel enmeti protokolojn en la spuron, nur tempospuron. Kaj "Jager" subtenis ĉi tion.
Ni rigardis "Jager": oni povas instrumentigi aplikaĵojn, oni povas skribi en Api (la Api-normo por PHP tiam ne estis aprobita - tio estis antaŭ unu jaro, sed nun ĝi jam estis aprobita), sed tie estis absolute neniu kliento. "Bone," ni pensis, kaj skribis nian propran klienton. Kion ni ricevis? Ĉi tio estas proksimume kiel ĝi aspektas:
En Jaeger, interspacoj estas kreitaj por ĉiu mesaĝo. Tio estas, kiam uzanto malfermas la sistemon, li vidas unu aŭ du blokojn por ĉiu envenanta peto (1-2-3 - la nombro da envenantaj petoj de la uzanto, la nombro da blokoj). Por plifaciligi ĝin por uzantoj, ni aldonis etikedojn al la protokoloj kaj tempospuroj. Sekve, en kazo de eraro, nia aplikaĵo markos la protokolon kun la taŭga Erara etikedo. Vi povas filtri per Erara etikedo kaj nur ampleksoj kiuj enhavas ĉi tiun blokon kun eraro estos montrataj. Jen kiel ĝi aspektas se ni vastigas la interspacon:
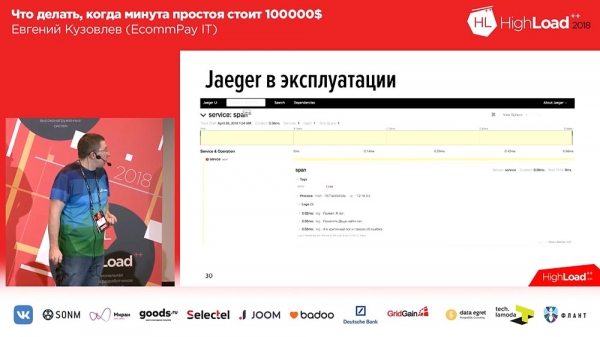
Ene de la interspaco estas aro da spuroj. En ĉi tiu kazo, ĉi tiuj estas tri testspuroj, kaj la tria spuro diras al ni, ke eraro okazis. Samtempe, ĉi tie ni vidas tempspuron: ni havas tempskalon ĉe la supro, kaj ni vidas, en kiu tempointervalo tiu aŭ alia protokolo estis registrita.Sekve, aferoj iris bone por ni. Ni skribis nian propran etendon kaj ni malfermis ĝin. Se vi volas labori kun spurado, se vi volas labori kun "Jager" en PHP, ekzistas nia etendo, bonvena uzi, kiel oni diras:
Ni havas ĉi tiun etendon - ĝi estas kliento por la OpenTracing Api, ĝi estas farita kiel php-extension, tio estas, vi devos kunmeti ĝin kaj instali ĝin en la sistemo. Antaŭ unu jaro estis nenio alia. Nun estas aliaj klientoj, kiuj estas kiel komponantoj. Ĉi tie dependas de vi: aŭ vi pumpas la komponantojn per komponisto, aŭ vi uzas etendaĵon laŭ vi.Korporaciaj normoj
Ni parolis pri la tri ordonoj. La kvara ordono estas normigi alirojn. Pri kio ĉi tio temas? Temas pri ĉi tio:
Kial la vorto "kompania" estas ĉi tie? Ne ĉar ni estas granda aŭ burokratia firmao, ne! Mi volis uzi la vorton "kompania" ĉi tie en la kunteksto, ke ĉiu kompanio, ĉiu produkto devus havi siajn proprajn normojn, inkluzive de vi. Kiajn normojn ni havas?- Ni havas regulojn pri deplojo. Ni ne moviĝas ien sen li, ni ne povas. Ni deplojiĝas ĉirkaŭ 60 fojojn semajne, tio estas, ni deplojas preskaŭ konstante. Samtempe ni havas, ekzemple, en la deplojregularoj tabuon pri deplojoj vendrede - principe, ni ne deplojas.
- Ni postulas dokumentadon. Eĉ ne unu nova komponanto eniras en produktadon se ne ekzistas dokumentado por ĝi, eĉ se ĝi naskiĝis sub la plumo de niaj RnD-specialistoj. Ni postulas de ili instrukciojn pri deplojo, monitoradmapon kaj malglatan priskribon (nu, kiel programistoj povas skribi) pri kiel funkcias ĉi tiu ero, kiel solvi ĝin.
- Ni solvas ne la kaŭzon de la problemo, sed la problemon – kion mi jam diris. Gravas por ni protekti la uzanton de problemoj.
- Ni havas permesojn. Ekzemple, ni ne konsideras ĝin malfunkcio se ni perdis 2% de trafiko ene de du minutoj. Ĉi tio esence ne estas inkluzivita en niaj statistikoj. Se ĝi estas pli procenta aŭ provizora, ni jam kalkulas.
- Kaj ni ĉiam skribas postmortems. Ne gravas kio okazas al ni, ajna situacio kie iu kondutis nenormale en produktado estos reflektita en la postmortem. Postmorto estas dokumento en kiu vi skribas tion, kio okazis al vi, detalan tempon, kion vi faris por korekti ĝin kaj (ĉi tio estas deviga bloko!) kion vi faros por eviti ke tio okazu estonte. Ĉi tio estas deviga kaj necesa por posta analizo.
Kio estas konsiderata malfunkcio?
Al kio ĉio ĉi kondukis?Ĉi tio kondukis al la fakto, ke (ni havis iujn problemojn kun stabileco, ĉi tio ne konvenis nek klientoj nek al ni) dum la pasintaj 6 monatoj nia stabileca indikilo estis 99,97. Ni povas diri, ke tio ne estas tre multe. Jes, ni havas ion por strebi. De ĉi tiu indikilo, proksimume duono estas la stabileco, kvazaŭ, ne de nia, sed de nia retaplikaĵo fajroŝirmilo, kiu staras antaŭ ni kaj estas uzata kiel servo, sed klientoj ne zorgas pri tio.
Ni lernis dormi nokte. Fine! Antaŭ ses monatoj ni ne povis. Kaj pri ĉi tiu noto kun la rezultoj, mi ŝatus fari unu noton. Hieraŭ vespere estis mirinda raporto pri la rega sistemo por nuklea reaktoro. Se la homoj, kiuj skribis ĉi tiun sistemon, povas aŭdi min, bonvolu forgesi pri tio, kion mi diris pri "2% ne estas malfunkcio." Por vi, 2% estas malfunkcio, eĉ se dum du minutoj!
Tio estas ĉio! Viaj demandoj.
Pri balanciloj kaj datumbaza migrado
Demando de la ĉeestantaro (ĉi-poste – B): – Bonan vesperon. Koran dankon pro tia administra raporto! Mallonga demando pri viaj ekvilibristoj. Vi menciis, ke vi havas WAF, tio estas, kiel mi komprenas ĝin, vi uzas ian eksteran balancilon...
EK: – Ne, ni uzas niajn servojn kiel ekvilibranton. En ĉi tiu kazo, WAF estas ekskluzive DDoS-protekta ilo por ni.
En: – Ĉu vi povas diri kelkajn vortojn pri ekvilibristoj?
EK: – Kiel mi jam diris, ĉi tio estas grupo de serviloj en openresty. Ni nun havas 5 rezervajn grupojn kiuj respondas ekskluzive... tio estas, servilo kiu funkcias ekskluzive openresty, ĝi nur prokuras trafikon. Sekve, por kompreni kiom ni tenas: ni nun havas regulan trafikfluon de kelkcent megabitoj. Ili eltenas, ili sentas sin bone, ili eĉ ne streĉas sin.
En: – Ankaŭ simpla demando. Jen Blua/Verda deplojo. Kion vi faras, ekzemple, kun datumbazaj migradoj?
EK: - Bona demando! Rigardu, en Blua/Verda deplojo ni havas apartajn atendovicojn por ĉiu linio. Tio estas, se ni parolas pri eventovicoj, kiuj estas transdonitaj de laboristo al laboristo, estas apartaj vicoj por la blua linio kaj por la verda linio. Se ni parolas pri la datumbazo mem, tiam ni intence malvastigis ĝin kiom ni povis, movis ĉion praktike en atendovicojn; en la datumbazo ni stokas nur stakon da transakcioj. Kaj nia transakcia stako estas la sama por ĉiuj linioj. Kun la datumbazo en ĉi tiu kunteksto: ni ne dividas ĝin en blua kaj verda, ĉar ambaŭ versioj de la kodo devas scii kio okazas kun la transakcio.
Amikoj, mi ankaŭ havas premieton por sproni vin - libron. Kaj mi devus esti premiita ĝin por la plej bona demando.
En: - Saluton. Dankon pro la raporto. La demando estas ĉi tio. Vi kontrolas pagojn, vi kontrolas la servojn, per kiuj vi komunikas... Sed kiel vi kontrolas, por ke iu iel venis al via pagopaĝo, pagis, kaj la projekto kreditis lin per mono? Tio estas, kiel vi kontrolas, ke la komercisto estas disponebla kaj akceptis vian revokon?
EK: – "Komercisto" por ni ĉi-kaze estas ĝuste la sama ekstera servo kiel la pagsistemo. Ni kontrolas la respondrapidecon de la komercisto.
Pri datumbaza ĉifrado
En: - Saluton. Mi havas iomete rilatan demandon. Vi havas PCI DSS-sentemajn datumojn. Mi volis scii, kiel vi stokas PAN-ojn en vostoj, kiujn vi devas translokigi? Ĉu vi uzas ĉifradon? Kaj tio kondukas al la dua demando: laŭ PCI DSS, necesas periode reĉifri la datumbazon en kazo de ŝanĝoj (maldungo de administrantoj, ktp.) - kio okazas al alirebleco en ĉi tiu kazo?
EK: - Mirinda demando! Unue, ni ne stokas PAN-ojn en atendovicoj. Ni ne rajtas konservi PAN ie ajn en klara formo, principe, do ni uzas specialan servon (ni nomas ĝin "Kademon") - ĉi tio estas servo kiu faras nur unu aferon: ĝi ricevas mesaĝon kiel enigo kaj sendas. elĉifritan mesaĝon. Kaj ni stokas ĉion kun ĉi tiu ĉifrita mesaĝo. Sekve, nia ŝlosillongo estas sub kilobajto, tiel ke ĉi tio estas serioza kaj fidinda.En: – Ĉu vi bezonas nun 2 kilobajtojn?
EK: – Ŝajnas, ke ĝuste hieraŭ estis 256... Nu, kie alie?!
Sekve, ĉi tiu estas la unua. Kaj due, la solvo kiu ekzistas, ĝi subtenas la re-ĉifradan proceduron - estas du paroj de "keks" (ŝlosiloj), kiuj donas "ferdekojn" kiuj ĉifras (ŝlosilo estas la ŝlosiloj, dek estas derivaĵoj de la ŝlosiloj kiuj ĉifras) . Kaj se la proceduro estas komencita (ĝi okazas regule, de 3 monatoj ĝis ± kelkaj), ni elŝutas novan paron da "kukoj", kaj ni reĉifras la datumojn. Ni havas apartajn servojn, kiuj elŝiras ĉiujn datumojn kaj ĉifras ĝin en nova maniero; La datumoj estas konservitaj apud la identigilo de la ŝlosilo per kiu ĝi estas ĉifrita. Sekve, tuj kiam ni ĉifras la datumojn per novaj ŝlosiloj, ni forigas la malnovan ŝlosilon.
Foje pagoj devas esti faritaj permane...
En: – Tio estas, se alvenis repago por iu operacio, ĉu vi ankoraŭ deĉifri ĝin per la malnova ŝlosilo?
EK: - Jes.
En: – Tiam ankoraŭ unu malgranda demando. Kiam ia fiasko, falo aŭ okazaĵo okazas, necesas puŝi la transakcion permane. Estas tia situacio.
EK: - Jes, foje.
En: – De kie vi ricevas ĉi tiujn datumojn? Aŭ ĉu vi mem iras al ĉi tiu stokejo?
EK: – Ne, nu, kompreneble, ni havas ian administran sistemon, kiu enhavas interfacon por nia subteno. Se ni ne scias, en kia statuso estas la transakcio (ekzemple, ĝis la pagsistemo respondis per tempodaŭro), ni ne scias apriore, tio estas, ni atribuas la finan statuson nur kun plena konfido. En ĉi tiu kazo, ni atribuas la transakcion al speciala statuso por mana prilaborado. Matene, la sekvan tagon, tuj kiam subteno ricevas informojn, ke tiaj kaj tiaj transakcioj restas en la pagsistemo, ili permane prilaboras ilin en ĉi tiu interfaco.
En: – Mi havas kelkajn demandojn. Unu el ili estas la daŭrigo de la PCI DSS-zono: kiel vi ensalutas ilian cirkviton? Ĉi tiu demando estas ĉar la programisto povis meti ion ajn en la protokolojn! Dua demando: kiel vi disvolvas varmkorektojn? Uzado de teniloj en la datumbazo estas unu opcio, sed povas esti senpagaj varmaj korektoj - kia estas la proceduro tie? Kaj la tria demando verŝajne rilatas al RTO, RPO. Via havebleco estis 99,97, preskaŭ kvar naŭoj, sed kiel mi komprenas, vi havas duan datumcentron, trian datumcentron, kaj kvinan datumcentron... Kiel vi sinkronigas ilin, reproduktas ilin, kaj ĉion alian?EK: - Ni komencu per la unua. Ĉu la unua demando estis pri ŝtipoj? Kiam ni skribas protokolojn, ni havas tavolon, kiu maskas ĉiujn sentivajn datumojn. Ŝi rigardas la maskon kaj la kromajn kampojn. Sekve, niaj protokoloj aperas kun jam maskitaj datumoj kaj PCI DSS-cirkvito. Ĉi tiu estas unu el la regulaj taskoj asignitaj al la testa fako. Ili devas kontroli ĉiun taskon, inkluzive de la protokoloj, kiujn ili skribas, kaj ĉi tiu estas unu el la regulaj taskoj dum kodaj recenzoj, por kontroli, ke la programisto ne skribis ion. Postaj kontroloj pri tio estas aranĝitaj regule fare de la informsekureca departemento proksimume unufoje semajne: protokoloj por la lasta tago estas selekteme prenitaj kaj ili estas prizorgataj per speciala skanilo-analizilo de testaj serviloj por kontroli ĉion.
Pri varmaj korektoj. Ĉi tio estas inkluzivita en niaj deplojregularoj. Ni havas apartan klaŭzon pri korektoj. Ni kredas, ke ni disvastigas varmarkojn ĉirkaŭ la horloĝo kiam ni bezonas ĝin. Tuj kiam la versio estas kunvenita, tuj kiam ĝi estas rulita, tuj kiam ni havas artefakton, ni havas sistemadministranton deĵoranta sur voko de subteno, kaj li deplojas ĝin en la momento kiam ĝi estas necesa.Pri "kvar naŭoj". La cifero, kiun ni nun havas, estas vere atingita, kaj ni strebis al ĝi en alia datumcentro. Nun ni havas duan datumcentron, kaj ni komencas iri inter ili, kaj la temo de trans-datumcentro-reproduktado estas vere ne-triviala demando. Ni provis solvi ĝin samtempe per malsamaj rimedoj: ni provis uzi la saman "Tarantulo" - ĝi ne funkciis por ni, mi tuj diros al vi. Tial ni finis mendi la "sens" permane. Fakte, ĉiu aplikaĵo en nia sistemo funkcias la necesan "ŝanĝon - faritan" sinkronigon inter datumcentroj nesinkrone.
En: – Se vi ricevis duan, kial vi ne ricevis trian? Ĉar neniu ankoraŭ havas fenditan cerbon...
EK: – Sed ni ne havas Split Brain. Pro la fakto, ke ĉiu aplikaĵo estas gvidata de plurmajstro, ne gravas al ni, al kiu centro venis la peto. Ni estas pretaj por tio, ke se unu el niaj datumcentroj malsukcesas (ni fidas je tio) kaj meze de uzantpeto ŝanĝas al la dua datumcentro, ni estas pretaj perdi ĉi tiun uzanton, ja; sed ĉi tiuj estos unuoj, absolutaj unuoj.
En: - Bonan vesperon. Dankon pro la raporto. Vi parolis pri via erarserĉilo, kiu funkciigas kelkajn testajn transakciojn en produktado. Sed diru al ni pri testaj transakcioj! Kiom profunde ĝi iras?
EK: – Ĝi trairas la plenan ciklon de la tuta komponanto. Por komponento, ne ekzistas diferenco inter testa transakcio kaj produktado. Sed de logika vidpunkto, ĉi tio estas simple aparta projekto en la sistemo, sur kiu nur testaj transakcioj funkcias.
En: -Kie vi detranĉas ĝin? Jen Kerno sendis...
EK: – Ni estas malantaŭ “Kor” ĉi-kaze por testaj transakcioj... Ni havas tian vojigon: “Kor” scias al kiu pagsistemo sendi - ni sendas al falsa pagsistemo, kiu simple donas http-signalon kaj tio estas ĉio.
En: – Diru, mi petas, ĉu via aplikaĵo estis skribita en unu grandega monolito, aŭ ĉu vi tranĉis ĝin en iujn servojn aŭ eĉ mikroservojn?
EK: – Ni ne havas monoliton, kompreneble, ni havas servo-orientitan aplikaĵon. Ni ŝercas, ke nia servo estas farita el monolitoj - ili estas vere sufiĉe grandaj. Estas malfacile nomi ĝin mikroservoj, sed ĉi tiuj estas servoj en kiuj funkcias laboristoj de distribuitaj maŝinoj.
Se la servo sur la servilo estas endanĝerigita...
En: – Tiam mi havas la sekvan demandon. Eĉ se ĝi estus monolito, vi ankoraŭ diris, ke vi havas multajn el ĉi tiuj tujaj serviloj, ili ĉiuj esence prilaboras datumojn, kaj la demando estas: "En la okazo de kompromiso de unu el la tujaj serviloj aŭ aplikaĵo, ajna individua ligo. , ĉu ili havas ian alirkontrolon? Kiu el ili povas fari kion? Kiun mi kontaktu por kiaj informoj?
EK: - Jes, nepre. La sekurecaj postuloj estas sufiĉe seriozaj. Unue, ni havas malfermajn datumajn movadojn, kaj la havenoj estas nur tiuj, tra kiuj ni anticipas trafikan movadon. Se komponanto komunikas kun la datumbazo (diru, kun Muskul) per 5-4-3-2, nur 5-4-3-2 estos malfermita al ĝi, kaj aliaj havenoj kaj aliaj trafikaj direktoj ne estos disponeblaj. Krome, vi devas kompreni, ke en nia produktado estas ĉirkaŭ 10 malsamaj sekurecaj bukloj. Kaj eĉ se la aplikaĵo estis iel kompromitita, Dio gardu, la atakanto ne povos aliri la servilan administradkonzolon, ĉar ĉi tio estas malsama reto sekureca zono.En: – Kaj en ĉi tiu kunteksto, kio pli interesas al mi estas, ke vi havas certajn kontraktojn kun servoj - kion ili povas fari, per kiaj "agoj" ili povas kontakti unu la alian... Kaj en normala fluo, iuj specifaj servoj petas kelkajn vico, listo de "agoj" aliflanke. Ili ne ŝajnas turni sin al aliaj en normala situacio, kaj ili havas aliajn respondecojn. Se unu el ili estas kompromitita, ĉu ĝi povos interrompi la "agojn" de tiu servo?...
EK: - Mi komprenas. Se en normala situacio kun alia servilo komunikado estis entute permesita, tiam jes. Laŭ la SLA-kontrakto, ni ne kontrolas, ke vi rajtas nur la unuaj 3 "agoj", kaj vi ne rajtas la 4 "agojn". Ĉi tio verŝajne estas superflua por ni, ĉar ni jam havas 4-nivelan protektan sistemon, principe, por cirkvitoj. Ni preferas defendi nin per la konturoj, prefere ol je la nivelo de la internoj.
Kiel funkcias Visa, MasterCard kaj Sberbank
En: – Mi volas klarigi punkton pri ŝanĝado de uzanto de unu datumcentro al alia. Kiom mi scias, Visa kaj MasterCard funkcias per la 8583 binara sinkrona protokolo, kaj estas miksaĵoj tie. Kaj mi volis scii, nun ni celas ŝanĝi - ĉu rekte "Visa" kaj "MasterCard" aŭ antaŭ pagsistemoj, antaŭ prilaborado?
EK: - Ĉi tio estas antaŭ la miksaĵoj. Niaj miksaĵoj situas en la sama datumcentro.
En: – Proksimume, ĉu vi havas unu konekton?
EK: – “Visa” kaj “MasterCard” - jes. Simple ĉar Visa kaj MasterCard postulas sufiĉe seriozajn investojn en infrastrukturo por fini apartajn kontraktojn por akiri duan paron da miksaĵoj, ekzemple. Ili estas rezervitaj ene de unu datumcentro, sed se, Dio gardu, nia datumcentro, kie estas miksaĵoj por konektiĝi al Visa kaj MasterCard, mortos, tiam ni havos konekton kun Visa kaj MasterCard perdita...
En: – Kiel oni povas ilin rezervi? Mi scias, ke Visa principe permesas nur unu konekton!
EK: – Ili mem provizas la ekipaĵon. Ĉiukaze, ni ricevis ekipaĵon kiu estas plene redunda interne.
En: – Do la stando estas de ilia Connects Orange?...
EK: - Jes.
En: – Sed kio pri ĉi tiu kazo: se via datumcentro malaperas, kiel vi povas daŭre uzi ĝin? Aŭ ĉu la trafiko simple ĉesas?
EK: - Ne. En ĉi tiu kazo, ni simple ŝanĝos la trafikon al alia kanalo, kiu, nature, estos pli multekosta por ni kaj pli multekosta por niaj klientoj. Sed la trafiko ne trairos nian rektan konekton al Visa, MasterCard, sed tra la kondiĉa Sberbank (tre troigita).
Mi pardonpetas sovaĝe, se mi ofendis dungitojn de Sberbank. Sed laŭ niaj statistikoj, inter la rusaj bankoj, Sberbank falas plej ofte. Ne pasas monato sen io defali ĉe Sberbank.

Kelkaj reklamoj 🙂
Dankon pro restado ĉe ni. Ĉu vi ŝatas niajn artikolojn? Ĉu vi volas vidi pli interesan enhavon? Subtenu nin farante mendon aŭ rekomendante al amikoj, , unika analogo de enirnivelaj serviloj, kiu estis inventita de ni por vi: (havebla kun RAID1 kaj RAID10, ĝis 24 kernoj kaj ĝis 40GB DDR4).
Dell R730xd 2 fojojn pli malmultekosta en Equinix Tier IV datumcentro en Amsterdamo? Nur ĉi tie en Nederlando! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ekde $99! Legu pri



















fonto: www.habr.com
