

Kubo-sur-kubo, metagrupoj, mielĉelaroj, resursdistribuo
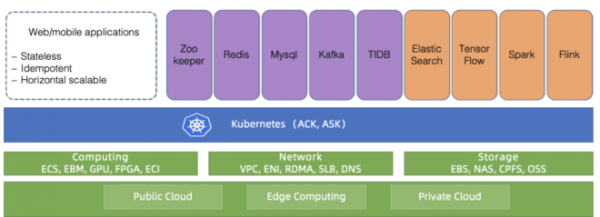
Rizo. 1. Kubernetes-ekosistemo sur Alibaba Cloud
Ekde 2015, Alibaba Cloud Container Service por Kubernetes (ACK) estas unu el la plej rapide kreskantaj nubaj servoj en Alibaba Cloud. Ĝi servas multajn klientojn kaj ankaŭ subtenas la internan infrastrukturon de Alibaba kaj la aliajn nubservojn de la kompanio.
Same kiel kun similaj ujservoj de mondklasaj nubaj provizantoj, niaj ĉefaj prioritatoj estas fidindeco kaj havebleco. Tial, skalebla kaj tutmonde alirebla platformo estis kreita por dekoj de miloj da Kubernetes-aretoj.
En ĉi tiu artikolo, ni dividos nian sperton pri administrado de granda nombro da Kubernetes-grupoj sur nuba infrastrukturo, same kiel la arkitekturon de la subesta platformo.
eniro
Kubernetes fariĝis la fakta normo por diversaj laborŝarĝoj en la nubo. Kiel montrite en Fig. 1 supre, pli kaj pli da Alibaba Cloud-aplikoj nun funkcias sur Kubernetes-aretoj: ŝtataj kaj sennaciaj aplikoj, same kiel aplikaĵadministrantoj. Kubernetes-administrado ĉiam estis interesa kaj serioza temo de diskuto por inĝenieroj, kiuj konstruas kaj prizorgas infrastrukturon. Kiam temas pri nubaj provizantoj kiel Alibaba Cloud, la temo de skalo venas al la unua loko. Kiel administri Kubernetes-aretojn ĉe ĉi tiu skalo? Ni jam kovris plej bonajn praktikojn por administri grandegajn 10-nodojn Kubernetes-grupojn. Kompreneble, ĉi tio estas interesa skampla problemo. Sed estas alia skalo: kvanto la aretoj mem.
Ni diskutis ĉi tiun temon kun multaj uzantoj de ACK. Plej multaj el ili elektas prizorgi dekduojn, se ne centojn, da malgrandaj aŭ mezgrandaj Kubernetes-aretoj. Estas bonaj kialoj por tio: limigi potencialan damaĝon, apartigi aretojn por malsamaj teamoj, krei virtualajn aretojn por testado. Se ACK celas servi tutmondan publikon per ĉi tiu uzmodelo, ĝi devas fidinde kaj efike administri grandan nombron da aretoj tra pli ol 20 regionoj.
Rizo. 2. Problemoj pri administrado de grandega nombro da Kubernetes-grupoj
Kio estas la ĉefaj defioj de administrado de aretoj je ĉi tiu skalo? Kiel montrite en la figuro, estas kvar aferoj por trakti:
- Heterogeneco
ACK devus subteni diversajn specojn de aretoj inkluzive de norma, senserva, Randa, Windows kaj kelkaj aliaj. Malsamaj aretoj postulas malsamajn parametrojn, komponantojn kaj gastigajn modelojn. Kelkaj klientoj bezonas helpon pri agordo por siaj specifaj bezonoj.
- Diversaj aretgrandoj
Aretoj varias en grandeco, de paro da nodoj kun kelkaj balgoj ĝis dekoj de miloj da nodoj kun miloj da balgoj. Rimedopostuloj ankaŭ multe varias. Nedeca resursa asigno povas influi efikecon aŭ eĉ kaŭzi fiaskon.
- Malsamaj versioj
Kubernetes evoluas tre rapide. Novaj versioj estas publikigitaj ĉiujn kelkajn monatojn. Klientoj ĉiam pretas provi novajn funkciojn. Do ili volas meti la testan ŝarĝon sur la novajn versiojn de Kubernetes kaj la produktan ŝarĝon sur la stabilaj. Por plenumi ĉi tiun postulon, ACK devas kontinue liveri novajn versiojn de Kubernetes al klientoj konservante stabilajn versiojn.
- Sekureca Konformeco
Aretoj estas distribuitaj tra malsamaj regionoj. Kiel tia, ili devas plenumi diversajn sekurecajn postulojn kaj oficialajn regularojn. Ekzemple, areto en Eŭropo devas esti konforma al GDPR, dum financa nubo en Ĉinio devas havi pliajn tavolojn de protekto. Ĉi tiuj postuloj estas devigaj kaj estas neakcepteble ignori ilin, ĉar tio kreas grandegajn riskojn por klientoj de la nuba platformo.
La ACK-platformo estas dizajnita por solvi la plej multajn el ĉi-supraj problemoj. Ĝi nuntempe fidinde kaj stabile administras pli ol 10 mil Kubernetes-grupojn tra la mondo. Ni rigardu kiel tio estis atingita, inkluzive per pluraj ŝlosilaj principoj pri dezajno/arkitekturo.
Dezajno
Kubo-sur-kubo kaj mielĉelaro
Male al alcentrigita hierarkio, ĉel-bazita arkitekturo kutimas tipe grimpi platformon preter ununura datencentro aŭ vastigi la amplekson de katastrofa reakiro.
Ĉiu regiono en la Alibaba Nubo konsistas el pluraj zonoj (AZ) kaj kutime respondas al specifa datumcentro. En granda regiono (ekz. Huangzhou), ofte estas miloj da Kubernetes-klientgrupoj, kiuj funkcias ACK.
ACK administras ĉi tiujn Kubernetes-aretojn uzante Kubernetes mem, tio signifas, ke ni havas Kubernetes-metagrupon funkciantan por administri la klientajn Kubernetes-aretojn. Ĉi tiu arkitekturo ankaŭ estas nomita "kube-on-kube" (KoK). La KoK-arkitekturo simpligas la administradon de klientgrupoj ĉar clusterdeplojo estas simpla kaj determinisma. Pli grave, ni povas reuzi denaskajn funkciojn de Kubernetes. Ekzemple, administri API-servilojn per deplojo, uzante la etcd-funkciigiston por administri plurajn etcd-ojn. Tia rekurso ĉiam alportas specialan plezuron.
Pluraj metagrupoj de Kubernetes estas deplojitaj ene de unu regiono, depende de la nombro da klientoj. Ni nomas ĉi tiujn metagrupojn ĉelojn. Por protekti kontraŭ la malsukceso de tuta zono, ACK subtenas mult-aktivajn deplojojn en ununura regiono: la metacluster distribuas Kubernetes-klient-grupo-majstrajn komponentojn tra pluraj zonoj kaj funkciigas ilin samtempe, tio estas, en mult-aktiva reĝimo. Por certigi la fidindecon kaj efikecon de la majstro, ACK optimumigas la lokigon de komponantoj kaj certigas, ke la API-servilo kaj ktpd estas proksimaj unu al la alia.
Ĉi tiu modelo permesas vin administri Kubernetes efike, flekseble kaj fidinde.
Metacluster planado de rimedoj
Kiel ni jam menciis, la nombro da metagrupoj en ĉiu regiono dependas de la nombro da klientoj. Sed je kiu punkto aldoni novan metagrupon? Ĉi tio estas tipa problemo pri planado de rimedoj. Kiel regulo, estas kutime krei novan kiam ekzistantaj metagrupoj elĉerpis ĉiujn siajn rimedojn.
Ni prenu retajn rimedojn, ekzemple. En la KoK-arkitekturo, Kubernetes-komponentoj de klientgrupoj estas deplojitaj kiel balgoj en metacluster. Ni uzas (Fig. 3) estas alt-efikeca kromaĵo evoluigita de Alibaba Cloud por kontenera retadministrado. Ĝi provizas riĉan aron da sekurecaj politikoj kaj permesas vin konekti al virtualaj privataj nuboj (VPC) de klientoj per la Alibaba Cloud Elastic Networking Interface (ENI). Por efike distribui retajn rimedojn tra nodoj, podoj kaj servoj en metacluster, ni devas zorge monitori ilian uzadon ene de la metacluster de virtualaj privataj nuboj. Kiam retaj rimedoj finiĝas, nova ĉelo estas kreita.
Por determini la optimuman nombron da klientgrupoj en ĉiu metacluster, ni ankaŭ konsideras niajn kostojn, densecpostulojn, rimedkvoton, fidindecpostulojn kaj statistikojn. La decido krei novan metagrupon estas farita surbaze de ĉiuj ĉi tiuj informoj. Bonvolu noti, ke malgrandaj aretoj povas multe vastiĝi en la estonteco, do la konsumo de rimedoj pliiĝas eĉ se la nombro da aretoj restas senŝanĝa. Ni kutime lasas sufiĉe da libera spaco por ke ĉiu areto kresku.
Rizo. 3. Terway reto-arkitekturo
Skali sorĉistkomponentojn tra klientgrupoj
Sorĉistkomponentoj havas malsamajn rimedbezonojn. Ili dependas de la nombro da nodoj kaj balgoj en la areto, la nombro da ne-normaj regiloj/funkciigistoj interagante kun APIServer.
En ACK, ĉiu Kubernetes-klientgrupo malsamas laŭ grandeco kaj rultempa postuloj. Ne ekzistas universala agordo por meti sorĉistkomponentojn. Se ni erare fiksas malaltan rimedlimon por granda kliento, tiam ĝia areto ne povos elteni la ŝarĝon. Se vi fiksas konservative altan limon por ĉiuj aretoj, rimedoj estos malŝparitaj.
Por trovi subtilan interŝanĝon inter fidindeco kaj kosto, ACK uzas tipsistemon. Nome, ni difinas tri specojn de aretoj: malgrandaj, mezaj kaj grandaj. Ĉiu tipo havas apartan rimedan asignoprofilon. La tipo estas determinita surbaze de la ŝarĝo de sorĉistkomponentoj, la nombro da nodoj, kaj aliaj faktoroj. La grupo tipo povas ŝanĝiĝi kun la tempo. ACK ade kontrolas ĉi tiujn faktorojn kaj povas supren/malsupren tajpi laŭe. Post kiam la aretspeco estas ŝanĝita, resursa asigno estas ĝisdatigita aŭtomate kun minimuma uzantinterveno.
Ni laboras por plibonigi ĉi tiun sistemon per pli fajna skalo kaj pli preciza tipa ĝisdatigo por ke ĉi tiuj ŝanĝoj okazas pli glate kaj havu pli ekonomian sencon.
Rizo. 4. Inteligenta plurstadia tipo-ŝanĝo
Evoluo de klientgrupoj je skalo
La antaŭaj sekcioj kovris kelkajn aspektojn de administrado de grandaj nombroj da Kubernetes-aretoj. Tamen estas alia problemo, kiu devas esti solvita: la evoluo de aretoj.
Kubernetes estas "Linux"en la nuba mondo. Ĝi konstante ĝisdatigiĝas kaj fariĝas pli modula. Ni devas konstante liveri novajn versiojn al niaj klientoj, ripari vundeblecojn kaj ĝisdatigi ekzistantajn aretojn, kaj ankaŭ administri grandan nombron da rilataj komponantoj (CSI, CNI, Aparata Kromaĵo, Horplana Kromaĵo kaj multaj aliaj)."
Ni prenu Kubernetes-komponan administradon kiel ekzemplon. Komence, ni evoluigis centralizitan sistemon por registri kaj administri ĉiujn ĉi tiujn konektitajn komponantojn.
Rizo. 5. Flekseblaj kaj ŝtopeblaj komponantoj
Antaŭ ol antaŭeniri, vi devas certigi, ke la ĝisdatigo sukcesis. Por fari tion, ni evoluigis sistemon por kontroli la funkciojn de komponantoj. La kontrolo estas farita antaŭ kaj post la ĝisdatigo.
Rizo. 6. Antaŭa kontrolo de aretkomponentoj
Por rapide kaj fidinde ĝisdatigi ĉi tiujn komponentojn, kontinua deplojsistemo funkcias kun subteno por parta antaŭeniĝo (grizskalo), paŭzoj kaj aliaj funkcioj. Normaj Kubernetes-regiloj ne taŭgas por ĉi tiu uzokazo. Tial, por administri grapolkomponentojn, ni evoluigis aron da specialigitaj regiloj, inkluzive de kromaĵo kaj helpa kontrolmodulo (flanka administrado).
Ekzemple, la BroadcastJob-regilo estas dizajnita por ĝisdatigi komponentojn sur ĉiu laborista maŝino aŭ kontroli nodojn sur ĉiu maŝino. La Broadcast-laboro funkcias pod sur ĉiu nodo en la areto, kiel DaemonSet. Tamen, DaemonSet ĉiam tenas la balgon funkcii dum longa tempo, dum BroadcastJob kolapsas ĝin. La Broadcast-regilo ankaŭ lanĉas podojn sur lastatempe kunigitaj nodoj kaj pravigas la nodojn kun la necesaj komponantoj. En junio 2019, ni malfermis la fontkodon de la aŭtomatiga motoro OpenKruise, kiun ni mem uzas en la kompanio.
Rizo. 7. OpenKurise organizas la plenumon de la Broadcast-tasko sur ĉiuj nodoj
Por helpi klientojn elekti la ĝustajn agordojn de la areto, ni ankaŭ provizas aron da antaŭdifinitaj profiloj, inkluzive de Servila Senserva, Randa, Windows kaj Nuda Metalo. Dum la pejzaĝo vastiĝas kaj la bezonoj de niaj klientoj evoluas, ni aldonos pliajn profilojn por simpligi la tedan agordan procezon.
Rizo. 8. Altnivelaj kaj flekseblaj aretoprofiloj por diversaj scenaroj
Tutmonda observeblo tra datumcentroj
Kiel montrite en malsupre fig. 9, Alibaba Cloud Container nuba servo estis deplojita en dudek regionoj ĉirkaŭ la mondo. Konsiderante ĉi tiun skalon, unu el la ĉefaj celoj de ACK estas facile monitori la staton de kurantaj aretoj tiel ke se klienta areto renkontas problemon, ni povas rapide respondi al la situacio. Alivorte, vi devas elpensi solvon, kiu permesos al vi efike kaj sekure kolekti statistikojn en reala tempo de klientgrupoj en ĉiuj regionoj - kaj vide prezenti la rezultojn.
Rizo. 9. Tutmonda deplojo de Alibaba Cloud Container-servo en dudek regionoj
Kiel multaj sistemoj de monitorado de Kubernetes, ni uzas Prometheus kiel nian ĉefan ilon. Por ĉiu metagrupo, Prometheus-agentoj kolektas la sekvajn metrikojn:
- OS-metrikoj kiel mastro-resursoj (CPU, memoro, disko, ktp.) kaj retbendolarĝo.
- Metrikoj por la metacluster kaj klienta cluster-administradsistemo, kiel ekzemple kube-apiserver, kube-controller-manager kaj kube-scheduler.
- Metriko de kubernetes-state-metrics kaj cadvisor.
- etcd-metrikoj kiel ekzemple disko-skriba tempo, datumbazograndeco, trairo de ligoj inter nodoj, ktp.
Tutmondaj statistikoj estas kolektitaj uzante tipan plurtavolan agregmodelon. Monitoraj datumoj de ĉiu metagrupo unue estas kunigitaj en ĉiu regiono kaj poste senditaj al centra servilo, kiu montras la ĝeneralan bildon. Ĉio funkcias per la federacia mekanismo. Prometheus-servilo en ĉiu datumcentro kolektas metrikojn de tiu datumcentro, kaj la centra Prometheus-servilo respondecas pri agregado de monitoraj datumoj. AlertManager konektas al centra Prometheus kaj, se necese, sendas atentigojn per DingTalk, retpoŝto, SMS, ktp. Vidigo - uzante Grafana.
En Figuro 10, la monitora sistemo povas esti dividita en tri nivelojn:
- Limnivelo
La tavolo plej malproksima de la centro. La Prometheus Edge Server funkcias en ĉiu metacluster, kolektante metrikojn de meta kaj klientgrupoj ene de la sama retdomajno.
- Kaskada nivelo
La funkcio de la kaskada tavolo de Prometeo estas kolekti monitoradajn datumojn el pluraj regionoj. Ĉi tiuj serviloj Ili funkcias je la nivelo de pli grandaj geografiaj unuoj, kiel ekzemple Ĉinio, Azio, Eŭropo kaj Ameriko. Dum kreskas aretoj, regiono povas esti dividita, kaj kaskada Prometheus-servilo tiam estos deplojita en ĉiu nova granda regiono. Ĉi tiu strategio permesas glatan skaladon laŭbezone.
- Centra nivelo
La centra Prometheus-servilo konektas al ĉiuj kaskadaj serviloj kaj plenumas la finan datuman agregadon. Por fidindeco, du centraj Prometheus-instancoj estis levitaj en malsamaj zonoj, konektitaj al la samaj kaskadaj serviloj.
Rizo. 10. Tutmonda plurnivela monitora arkitekturo bazita sur la Prometheus-federacia mekanismo
Resumo
Nubaj solvoj bazitaj en Kubernetes daŭre transformas nian industrion. Alibaba Cloud-ujo-servo provizas sekuran, fidindan kaj alt-efikecan gastigadon - ĝi estas unu el la plej bonaj nuba gastigado de Kubernetes. La Alibaba Cloud-teamo forte kredas je la principoj de Malferma Fonto kaj la malfermfonta komunumo. Ni certe daŭre dividos nian scion en la kampo de funkciigado kaj administrado de nubaj teknologioj.
fonto: www.habr.com
