

antaŭhistorio
Ekzistas vendmaŝinoj laŭ nia propra dezajno. Interne estas Raspberry Pi kaj iuj konektiloj sur aparta plato. Monerakceptilo, monbiletakceptilo, bankterminalo estas konektitaj... Ĉion kontrolas memskribita programo. La tuta laborhistorio estas skribita en taglibro sur USB-memorilo (MicroSD), kiu poste estas transdonita per la Interreto (uzante USB-modemon) al la servilo, kie ĝi estas konservita en datumbazo. Vendinformoj estas ŝarĝitaj en la 1C, estas ankaŭ simpla TTT-interfaco por monitorado, ktp.
Tio estas, la taglibro estas esence grava - por kontado (enspezoj, vendoj, ktp.), monitorado (ĉiaspecaj paneoj kaj aliaj fortmaĵoraj cirkonstancoj); tio, oni povus diri, estas ĉiuj informoj, kiujn ni havas pri ĉi tiu maŝino.
problemo
USB-memoriloj montriĝas tre nefidindaj aparatoj. Ili paneas kun enviinda reguleco. Tio kondukas kaj al maŝina paneo kaj (se pro iu kialo la protokolo ne povis esti translokigita al la interreto) al datenperdo.
Ĉi tio ne estas la unua sperto pri uzado de USB-memoriloj, antaŭ tio estis alia projekto kun pli ol cent aparatoj, kie la taglibro estis konservita sur USB-memoriloj, ankaŭ estis problemoj pri fidindeco, kelkfoje la nombro de paneintaj aparatoj monate estis dekoj. Ni provis diversajn memorilojn, inkluzive de markaj kun SLC-memoro, kaj iuj modeloj estas pli fidindaj ol aliaj, sed anstataŭigi la memorilojn ne solvis la problemon radikale.
Singardemo Legu longe! Se vi ne interesiĝas pri "kial", sed nur pri "kiel", vi povas iri rekte al artikoloj.
decido
La unua afero, kiu venas al la menso, estas forlasi la MicroSD-on, instali, ekzemple, SSD-on, kaj startigi de ĝi. Teorie ebla, eble, sed relative multekosta, kaj ne tiom fidinda (aldonas USB-SATA-adaptilon; la panestatistikoj por buĝetaj SSD-oj ankaŭ ne estas kuraĝigaj).
USB-disko ankaŭ ne aspektas kiel aparte alloga solvo.
Tial ni venis al ĉi tiu opcio: lasi la starton de MicroSD, sed uzi ilin en nurlegebla reĝimo, kaj konservi la laborprotokolon (kaj aliajn informojn unikajn al specifa aparataro - serian numeron, sensilajn kalibrojn, ktp.) ie alie.
La temo de nurlegebla FS por Raspberry Pi jam estis studita detale, mi ne restos pri la efektivigaj detaloj en ĉi tiu artikolo. (sed se estas intereso, eble mi skribos mini-artikolon pri ĉi tiu temo)La sola punkto, kiun mi ŝatus rimarkigi, estas ke kaj laŭ persona sperto kaj laŭ recenzoj de tiuj, kiuj jam efektivigis ĝin, ekzistas gajno en fidindeco. Jes, estas neeble tute seniĝi de paneoj, sed estas tute eble signife redukti ilian oftecon. Kaj la kartoj fariĝas unuigitaj, kio signife simpligas anstataŭigon por servistaro.
Aparataro
Ne estis aparta dubo pri la elekto de memortipo - NOR-Fulmo.
Argumentoj:
- simpla konekto (plej ofte la SPI-buso, kiun ni jam havas sperton pri uzado, do neniuj aparataraj problemoj estas atendataj);
- ridinda prezo;
- norma funkciiga protokolo (efektivigo jam estas en la kerno) Linux, se vi volas, vi povas preni triapartan, kiu ankaŭ ĉeestas, aŭ eĉ verki vian propran, feliĉe, ĉio estas simpla);
- fidindeco kaj rimedo:
el tipa datenfolio: datumoj estas konservitaj dum 20 jaroj, 100000 XNUMX forviŝcikloj por ĉiu bloko;
de triapartaj fontoj: ekstreme malalta BER, oni ne postulas erarkorektokodojn (kelkaj artikoloj konsideras ECC por NOR, sed kutime ili celas MLC NOR, tio ankaŭ okazas).
Ni taksu la postulojn por volumeno kaj rimedo.
Mi ŝatus esti certa, ke la datumoj estas konservitaj dum pluraj tagoj. Ĉi tio estas necesa por ke, okaze de iuj ajn konektaj problemoj, la vendhistorio ne perdiĝu. Ni koncentriĝos pri 5 tagoj por ĉi tiu periodo. (eĉ konsiderante semajnfinojn kaj feriojn) la problemo povas esti solvita.
Ni nuntempe havas ĉirkaŭ 100kb da protokolo ĉiutage (3-4 mil registroj), sed ĉi tiu nombro iom post iom kreskas - la detaloj pliiĝas, novaj eventoj aldoniĝas. Plie, kelkfoje okazas plialtiĝoj (iu sensilo komencas spami per falsaj pozitivoj, ekzemple). Ni kalkulos por 10 mil registroj de 100 bajtoj - megabajto ĉiutage.
Entute, estas 5MB da puraj (bone kunpremitaj) datumoj. Krome, (malglata takso) 1MB da servaj datumoj.
Tio estas, ni bezonas peceton por 8 MB se ni ne uzas kunpremon, aŭ 4 MB se ni faras tion. Sufiĉe realismaj ciferoj por ĉi tiu speco de memoro.
Koncerne la rimedon: se ni planas, ke la memoro estos tute reskribita ne pli ofte ol unufoje ĉiujn 5 tagojn, tiam dum 10 jaroj da servo ni ricevas malpli ol mil reskribajn ciklojn.
Permesu al mi memorigi vin, ke la fabrikanto promesas cent mil.
Iom pri NOR kontraŭ NAND
Hodiaŭ, kompreneble, NAND-memoro estas multe pli populara, sed mi ne uzus ĝin por ĉi tiu projekto: NAND, male al NOR, nepre postulas la uzon de erarkorektokodoj, tabelo de difektitaj blokoj, ktp., kaj NAND-blatoj kutime havas multe pli da pingloj.
La malavantaĝoj de NOR inkluzivas:
- malgranda volumeno (kaj, sekve, alta prezo por megabajto);
- malalta interŝanĝa rapido (plejparte pro la fakto, ke seria interfaco estas uzata, kutime SPI aŭ I2C);
- malrapida forviŝado (depende de la blokograndeco, ĝi daŭras de frakcioj de sekundo ĝis pluraj sekundoj).
Ŝajnas, ke nenio estas kritika por ni, do ni daŭrigas.
Se vi interesiĝas pri la detaloj, mikrocirkvito estis elektita (tamen, tio ne estas esenca, ekzistas multaj analogaĵoj sur la merkato, kiuj estas kongruaj laŭ pin-disigo kaj komandsistemo; eĉ se ni volas instali mikrocirkviton de alia fabrikanto kaj/aŭ alian volumon, ĉio funkcios sen ŝanĝi la kodon).
Mi uzas tiun enkonstruitan en la kernon Linux Ŝoforo, ĉe Raspberry, danke al la subteno de la paŭzo de la aparatarbo, ĉio estas tre simpla - vi bezonas meti la kompilitan paŭzon en /boot/overlays kaj iomete modifi /boot/config.txt.
Ekzemplo de dts-dosiero
Honeste, mi ne certas, ke ĝi estas skribita sen eraroj, sed ĝi funkcias.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};Kaj alia linio en config.txt
dtoverlay=at25:spimaxfrequency=50000000Mi preterlasos la priskribon de la konekto de la mikrocirkvito al la Raspberry Pi. Unuflanke, mi ne estas fakulo pri elektroniko, aliflanke, ĉio estas banala eĉ por mi: la mikrocirkvito havas nur 8 stiftojn, el kiuj ni bezonas teron, potencon, SPI (CS, SI, SO, SCK); la niveloj koincidas kun tiuj de la Raspberry Pi, neniu plia konektado estas necesa - nur konektu la specifitajn 6 kontaktojn.
Formulado de la problemo
Kiel kutime, la problemdeklaro trairas plurajn ripetojn, kaj mi opinias, ke estas tempo por alia. Do ni haltu, kunmetu tion, kio jam estis skribita, kaj klarigu la detalojn, kiuj restas en la ombroj.
Do, ni decidis, ke la protokolo estos konservita en SPI NOR Flash-memoro.
Kio estas NOR-Fulmo por tiuj, kiuj ne scias?
Ĉi tiu estas nevolatila memoro, per kiu vi povas plenumi tri operaciojn:
- Legado:
La plej ofta legado: ni transdonas la adreson kaj legas tiom da bajtoj kiom ni bezonas; - Rekordo:
Skribi al NOR-fulmmemorilo aspektas kiel normala, sed ĝi havas unu apartecon: oni povas ŝanĝi nur 1 al 0, sed ne inverse. Ekzemple, se ni havus 0x55 en memorĉelo, tiam post skribo de 0x0f al ĝi, 0x05 jam estus konservita tie. (vidu tabelon sube); - Forviŝi:
Kompreneble, ni bezonas povi fari la malan operacion - ŝanĝi 0 al 1, por tio estas la forviŝa operacio. Male al la unuaj du, ĝi funkcias ne sur bajtoj, sed sur blokoj (la minimuma forviŝa bloko en la elektita ico estas 4 KB). Forviŝo detruas la tutan blokon kaj tio estas la sola maniero ŝanĝi 0 al 1. Tial, kiam oni laboras kun fulmmemoro, ofte necesas vicigi datenstrukturojn al la limo de la forviŝa bloko.
Skribante al NOR-Fulmomemorilo:
Binaraj datumoj
Estis
01010101
Registrita
00001111
Fariĝis
00000101
La protokolo mem estas sekvenco de variablolongaj registroj. Tipa registro longas ĉirkaŭ 30 bajtojn (kvankam kelkfoje registroj longas plurajn kilobajtojn). En ĉi tiu kazo ni simple laboras kun ili kiel aro da bajtoj, sed se tio vin interesas, CBOR estas uzata ene de la registroj.
Aldone al la protokolo, ni bezonas konservi iujn "agordajn" informojn, kaj ĝisdatigitajn kaj ne: iujn aparatajn identigilojn, sensilajn kalibrojn, flagon "aparato provizore malŝaltita", ktp.
Ĉi tiu informo estas aro de ŝlosil-valoraj rikordoj, ankaŭ konservitaj en CBOR. Ni ne havas multon da ĉi tiu informo (maksimume kelkajn kilobajtojn), kaj ĝi estas ĝisdatigata malofte.
Estontece ni nomos ĝin kunteksto.
Se vi memoras kiel ĉi tiu artikolo komenciĝis, estas tre grave certigi fidindan datumstokadon kaj, se eble, seninterrompan funkciadon eĉ en kazo de aparatara paneo/datenkorupto.
Kiujn fontojn de problemoj oni povas konsideri?
- Elektropaneo dum skribado/forigo de operacioj. Ĉi tio estas el la kategorio "neniu defendo kontraŭ levstango".
Informoj de ĉe stackexchange: kiam la potenco estas malŝaltita dum laborado kun fulmmemoro, kaj forviŝado (agordita al 1) kaj skribo (agordita al 0) kondukas al nedifinita konduto: datumoj povas esti skribitaj, parte skribitaj (ekzemple, ni transdonis 10 bajtojn/80 bitojn, sed sukcesis skribi nur 45 bitojn), eblas ankaŭ, ke iuj bitoj finos en "meza" stato (legado povas produkti aŭ 0 aŭ 1); - Eraroj en la fulmmemoro mem.
BER, kvankam tre malalta, ne povas esti egala al nulo; - Eraroj sur la buso
Datumoj transdonitaj per SPI neniel estas protektitaj; eraroj de unu bito kaj eraroj de sinkronigado - perdo aŭ enmeto de bitoj (kio kondukas al grandega datenmisprezento) povas okazi; - Aliaj eraroj/problemoj
Koderaroj, Raspaj paneoj, ekstertera interveno...
Mi formulis la postulojn, kiujn laŭ mia opinio oni devas plenumi por certigi fidindecon:
- registroj devas esti skribitaj al fulmmemoro tuj, prokrastita skribado ne estas konsiderata; - se eraro okazas, ĝi devas esti detektita kaj prilaborita kiel eble plej frue; - la sistemo devas, se eble, resaniĝi post eraroj.
(ekzemplo el la vivo de "kiel ĝi ne devus esti", kiun mi kredas, ke ĉiu renkontis: post kriza restartiĝo, la dosiersistemo estas "difektita" kaj la operaciumo ne startas)
Ideoj, aliroj, pensoj
Kiam mi komencis pripensi ĉi tiun problemon, amaso da ideoj ekbrilis en mia kapo, ekzemple:
- uzi datumkunpremon;
- uzu lertajn datenstrukturojn, kiel ekzemple konservadon de rekordkapoj aparte de la rekordoj mem, tiel ke se estas eraro en unu rekordo, la resto povas esti legata senprobleme;
- uzu bitkampojn por kontroli skribkompletigon kiam la potenco estas malŝaltita;
- konservi ĉeksumojn por ĉio kaj ĉiuj;
- uzi iun formon de erar-korekta kodado.
Kelkaj el ĉi tiuj ideoj estis uzitaj, kelkaj estis forlasitaj. Ni trairu ilin laŭorde.
Kunpremo de datumoj
La eventoj mem, kiujn ni registras en la protokolo, estas sufiĉe unuformaj kaj ripeteblaj ("ĵetis 5-rublan moneron", "premis la butonon por ŝanĝi monon", ...). Tial, kunpremo devus esti sufiĉe efika.
La kosto de kunpremo estas sensignifa (nia procesoro estas sufiĉe potenca, eĉ la unua Pi havis unu kernon kun frekvenco de 700 MHz, nunaj modeloj havas plurajn kernojn kun frekvenco de pli ol gigaherco), la rapido de interŝanĝo kun la memoro estas malalta (kelkaj megabajtoj por sekundo), la grandeco de la registroj estas malgranda. Ĝenerale, se kunpremo havas efikon sur la rendimenton, ĝi estos nur pozitiva. (absolute senkritika, nur konstatante)Plie, ni ne havas veran enigitan, sed ordinaran. Linux — do la efektivigo ne devus postuli multan penon (sufiĉas nur ligi la bibliotekon kaj uzi kelkajn funkciojn el ĝi).
Peco de protokolo de funkcianta aparato (1.7 MB, 70 mil registroj) estis prenita kaj unue kontrolita por kunpremebleco uzante gzip, lz4, lzop, bzip2, xz, zstd haveblajn sur la komputilo.
- gzip, xz, zstd montris similajn rezultojn (40Kb).
Mi surpriziĝis, ke la moda xz montris sin ĉi tie je la nivelo de gzip aŭ zstd; - lzip kun defaŭltaj agordoj donis iom pli malbonajn rezultojn;
- lz4 kaj lzop ne montris tre bonajn rezultojn (150Kb);
- bzip2 montris surprize bonajn rezultojn (18Kb).
Do la datumoj kunpremiĝas tre bone.
Do (se ni ne trovos mortigajn difektojn) kunpremo estos tie! Simple ĉar pli da datumoj konvenos sur la sama USB-memorilo.
Ni pripensu la malavantaĝojn.
La unua problemo: ni jam konsentis, ke ĉiu registro tuj iru al la fulmmemoro. Kutime, la arkivilo kolektas datumojn el la eniga fluo ĝis ĝi decidas, ke estas tempo skribi al la eligo. Ni bezonas tuj akiri kunpremitan datenblokon kaj konservi ĝin en nevolatila memoro.
Mi vidas tri manierojn:
- Kunpremu ĉiun rikordon uzante vortaran kunpremon anstataŭ la supre diskutitajn algoritmojn.
Ĝi estas tute funkcianta opcio, sed mi ne ŝatas ĝin. Por certigi pli-malpli bonan kunpremnivelon, la vortaro devas esti "adaptita" al specifaj datumoj; ĉiu ŝanĝo rezultigos katastrofe malaltiĝon de la kunpremnivelo. Jes, la problemo solveblas per kreado de nova versio de la vortaro, sed tio estas kapdoloro - ni devos konservi ĉiujn versiojn de la vortaro; en ĉiu eniro, ni devos indiki per kiu versio de la vortaro ĝi estis kunpremita... - Kunpremu ĉiun rekordon uzante "klasikajn" algoritmojn, sed sendepende de aliaj.
La konsiderataj kunpremaj algoritmoj ne estas desegnitaj por funkcii kun registroj de ĉi tiu grandeco (dekoj da bajtoj), la kunprema proporcio estos klare malpli ol 1 (tio estas, pliiĝo de la volumeno de datumoj anstataŭ kunpremo); - Faru FLUSH post ĉiu eniro.
Multaj kunpremaj bibliotekoj subtenas FLUSH. Ĉi tio estas komando (aŭ parametro al la kunprema proceduro), ricevinte kiun la arkivilo formas kunpremitan fluon tiel ke surbaze de ĝi eblas restarigi ĉiuj nekunpremitaj datumoj, kiuj jam estis ricevitaj. Ĉi tiu analogaĵosyncen dosiersistemoj aŭcommiten sql.
Gravas, ke postaj kunpremaj operacioj povos uzi la akumulitan vortaron kaj la kunprema proporcio ne suferos tiom, kiom en la antaŭa versio.
Mi opinias, ke estas evidente, ke mi elektis la trian opcion, ni rigardu ĝin pli detale.
Trovita pri FLUSH en zlib.
Mi faris genuoteston bazitan sur la artikolo, prenis 70 mil protokolajn enskribojn de reala aparato, kun paĝograndeco de 60 KB. (ni revenos al paĝograndeco poste) ricevis:
Fontaj datumoj
Kunpremo gzip -9 (sen FLUSH)
zlib kun Z_PARTIAL_FLUSH
zlib kun Z_SYNC_FLUSH
Volumeno, Kb
1692
40
352
604
Unuavide, la kosto de FLUSH estas troe alta, sed fakte ni havas malbonan elekton - aŭ tute ne kunpremi, aŭ kunpremi (kaj sufiĉe efike) per FLUSH. Ni ne devas forgesi, ke ni havas 70 mil rikordojn, la redundo enkondukita de Z_PARTIAL_FLUSH estas nur 4-5 bajtoj por rikordo. Kaj la kunprema proporcio montriĝis preskaŭ 5:1, kio estas pli ol bonega rezulto.
Ĝi eble ŝajnas surpriza, sed Z_SYNC_FLUSH estas fakte pli efika maniero fari FLUSH.
Kaze de uzado de Z_SYNC_FLUSH la lastaj 4 bajtoj de ĉiu rikordo ĉiam estos 0x00, 0x00, 0xff, 0xff. Kaj se ni konas ilin, ni ne povas konservi ilin, do la fina grandeco estas nur 324 KB.
La artikolo, al kiu mi ligis, havas klarigon:
Nova bloko de tipo 0 kun malplena enhavo estas aldonita.
Bloko de tipo 0 kun malplena enhavo konsistas el:
- la tri-bita bloka kaplinio;
- 0 ĝis 7 bitoj egalaj al nulo, por atingi bajtan vicigon;
- la kvar-bajta sekvenco 00 00 FF FF.
Kiel vi facile vidas, en la lasta bloko antaŭ ĉi tiuj 4 bajtoj estas de 3 ĝis 10 nulaj bitoj. Tamen, praktiko montris, ke fakte estas almenaŭ 10 nulaj bitoj.
Montriĝas, ke tiaj mallongaj blokoj de datumoj estas kutime (ĉiam?) ĉifritaj per bloko de tipo 1 (fiksa bloko), kiu nepre finiĝas per 7 nulaj bitoj, do ni ricevas 10-17 garantiitajn nulajn bitojn (kaj la resto estos nula kun probableco de ĉirkaŭ 50%).
Do, en la testaj datumoj en 100% de kazoj antaŭ 0x00, 0x00, 0xff, 0xff estas unu nula bajto, kaj en pli ol triono de kazoj estas du nulaj bajtoj. (eble la afero estas, ke mi uzas binaran CBOR, kaj se mi uzus tekstan JSON, mi pli ofte renkontus blokojn de tipo 2 - dinamika bloko, respektive, mi renkontus blokojn sen aldonaj nulaj bajtoj antaŭ 0x00, 0x00, 0xff, 0xff).
Entute, uzante la disponeblajn testdatumojn, eblas enhavi malpli ol 250 KB da kunpremitaj datumoj.
Ni povas ŝpari iom pli per ĵonglado de bitoj: nun ni ignoras la ĉeeston de kelkaj nulaj bitoj ĉe la fino de bloko, kaj kelkaj bitoj ĉe la komenco de bloko ankaŭ ne ŝanĝiĝas...
Sed ĉi tie mi faris fortan decidon ĉesi, alie je ĉi tiu rapideco mi povus fini disvolvante mian propran arkivilon.
Entute, mi ricevis 3-4 bajtojn por ĉiu registro el miaj testaj datumoj, la kunprema proporcio estis pli ol 6:1. Honeste, mi ne atendis tian rezulton, laŭ mia opinio, io ajn pli bona ol 2:1 jam estas rezulto, kiu pravigas la uzon de kunpremo.
Ĉio estas bonega, sed zlib (deflate) estas ankoraŭ arkaika, bone meritita kaj iom malmoderna kunprema algoritmo. La fakto, ke la lastaj 32K de la nekunpremita datumfluo estas uzataj kiel vortaro, aspektas strange hodiaŭ (tio estas, se iu datumbloko estas tre simila al tio, kio estis en la eniga fluo antaŭ 40K, ĝi rekomencos arkivadon, kaj ne rilatos al la antaŭa eniro). En modaj modernaj arkiviloj, la vortara grandeco ofte mezuriĝas en megabajtoj, ne kilobajtoj.
Do, ni daŭrigu nian mini-esploradon pri arkivistoj.
Poste, oni provis bzip2 (memoru, sen FLUSH ĝi montris bonegan kunpreman proporcion, preskaŭ 100:1). Bedaŭrinde, kun FLUSH ĝi montris sin tre malbone, la grandeco de la kunpremitaj datumoj estis pli granda ol tiu de la nekunpremitaj.
Miaj divenoj pri la kialoj de la malsukceso
Libbz2 proponas nur unu opcion por forigi la vortaron, kiu ŝajne forigas ĝin (analoge al Z_FULL_FLUSH en zlib), do ne utilas paroli pri iu ajn efika kunpremo post tio.
Kaj la lasta testita estis zstd. Depende de la parametroj, ĝi kunpremas aŭ je la nivelo de gzip, sed multe pli rapide, aŭ pli bone ol gzip.
Bedaŭrinde, kun FLUSH ĝi ankaŭ montriĝis "ne tre bona": la grandeco de la kunpremitaj datumoj estis ĉirkaŭ 700 KB.
Я sur la projekta paĝo en github, mi ricevis la respondon, ke valoras kalkuli je ĝis 10 bajtoj da servaj datumoj por ĉiu bloko de kunpremitaj datumoj, kio estas proksima al la akiritaj rezultoj, ne eblos atingi malŝveligon.
Je ĉi tiu punkto mi decidis ĉesi eksperimenti kun arkiviloj (permesu al mi memorigi vin, ke xz, lzip, lzo, lz4 ankoraŭ ne montris sin en la testa stadio sen FLUSH, kaj mi ne konsideris pli ekzotikajn kunpremajn algoritmojn).
Ni revenu al la problemoj de arkivado.
La dua (kiel oni diras laŭorde, ne laŭ graveco) problemo estas, ke kunpremitaj datumoj estas ununura fluo, en kiu konstante oni faras referencojn al antaŭaj sekcioj. Tiel, se iu sekcio de kunpremitaj datumoj estas difektita, ni perdas ne nur la nekunpremitan datenblokon asociitan kun ĝi, sed ankaŭ ĉiujn postajn.
Ekzistas manieroj solvi ĉi tiun problemon:
- Malhelpi la problemon okazi - aldonu redundon al la kunpremitaj datumoj por permesi la detekton kaj korekton de eraroj; ni parolos pri tio poste;
- Minimumigu la sekvojn se problemo okazas
Ni jam diris antaŭe, ke eblas kunpremi ĉiun datenblokon sendepende, kaj la problemo malaperos per si mem (datuma korupto de unu bloko kondukos al la perdo de datumoj nur de tiu bloko). Tamen, ĉi tio estas ekstrema kazo, en kiu datumkunpremo estos senefika. La mala ekstremo: uzi ĉiujn 4 MB de nia ico kiel unuopan arkivon, kio donos al ni bonegan kunpremon, sed katastrofajn sekvojn en kazo de datumkorupto.
Jes, kompromiso necesas rilate al fidindeco. Sed ni devas memori, ke ni disvolvas datumstokan formaton por nevolatila memoro kun ekstreme malalta BER kaj deklarita datumstoka vivo de 20 jaroj.
Dum la eksperimentoj mi malkovris, ke pli-malpli rimarkeblaj perdoj en la kunprema nivelo komenciĝas ĉe blokoj de kunpremitaj datumoj malpli ol 10 KB grandaj.
Estis menciite antaŭe, ke la uzata memoro estas paĝiga, mi ne vidas ian ajn kialon, kial vi ne uzu la mapadon "unu paĝo - unu bloko de kunpremitaj datumoj".
Tio estas, la minimuma racia paĝgrandeco estas 16Kb (kun rezervo por servaj informoj). Tamen, tia malgranda paĝgrandeco trudas signifajn limigojn al la maksimuma rekordgrandeco.
Kvankam mi ne atendas havi rikordojn pli grandajn ol kelkaj kilobajtoj en kunpremita formo, mi decidis uzi 32K paĝojn (kio donas al mi 128 paĝojn por ĉiu ico).
Resumo:
- Ni stokas datumojn kunpremitajn per zlib (deflate);
- Por ĉiu eniro ni agordas Z_SYNC_FLUSH;
- Por ĉiu kunpremita rikordo, ni forigas la postajn bajtojn (ekz. 0x00, 0x00, 0xff, 0xff); en la kaplinio ni indikas kiom da bajtoj ni fortranĉas;
- Ni stokas datumojn en 32Kb-aj paĝoj; ene de ĉiu paĝo estas ununura fluo de kunpremitaj datumoj; sur ĉiu paĝo ni rekomencas la kunpremon.
Kaj, antaŭ ol fini kun kunpremo, mi ŝatus atentigi pri la fakto, ke ni ricevas nur kelkajn bajtojn da kunpremitaj datumoj por ĉiu rikordo, do estas ekstreme grave ne ŝveligi la servinformojn, ĉiu bajto gravas ĉi tie.
Stokado de datumaj kaplinioj
Ĉar ni havas variajn longajn rikordojn, ni bezonas iel determini la lokigon/limojn de la rikordoj.
Mi konas tri alirojn:
- Ĉiuj rikordoj estas konservitaj en kontinua fluo, unue la rikorda kaplinio enhavanta la longon, kaj poste la rikordo mem.
En ĉi tiu variaĵo, kaj titoloj kaj datumoj povas esti de varia longo.
Esence, ni ricevas unuope ligitan liston, kiu estas uzata ĉiam; - Titoloj kaj rikordoj mem estas konservitaj en apartaj fluoj.
Per uzado de konstant-longaj titoloj, ni certigas, ke korupto de unu titolo ne influas la aliajn.
Simila aliro estas uzata, ekzemple, en multaj dosiersistemoj; - Rikordoj estas konservitaj en kontinua fluo, la limo de la rikordo estas determinita per iu markilo (simbolo/sekvenco de simboloj malpermesita ene de datenblokoj). Se markilo troviĝas ene de rikordo, ni anstataŭigas ĝin per iu sekvenco (ni uzas ĝin kiel eskapon).
Simila aliro estas uzata, ekzemple, en la PPP-protokolo.
Permesu al mi ilustri.
Eblo 1:

Ĉi tie ĉio estas tre simpla: sciante la longon de la rikordo ni povas kalkuli la adreson de la sekva kaplinio. Do ni moviĝas tra la kaplinioj ĝis ni renkontas areon plenan de 0xff (libera areo) aŭ la finon de la paĝo.
Eblo 2:

Pro la varia longo de la rikordo, ni ne povas anticipe diri kiom da rikordoj (kaj tial titoloj) ni bezonos por paĝo. Ni povas distribui la titolojn kaj la datumojn mem tra malsamaj paĝoj, sed mi preferas alian aliron: ni metas kaj la titolojn kaj la datumojn sur unu paĝon, sed la titoloj (de konstanta grandeco) komenciĝas de la komenco de la paĝo, kaj la datumoj (de varia longo) komenciĝas de la fino. Tuj kiam ili "renkontiĝas" (ne estas sufiĉe da libera spaco por nova rikordo), ni konsideras ĉi tiun paĝon plena.
Eblo 3:

Ne necesas konservi la longon aŭ aliajn informojn pri la loko de la datumoj en la kaplinio, sufiĉas markiloj indikantaj la limojn de la rikordoj. Tamen, la datumoj devas esti prilaboritaj dum skribado/legado.
Mi uzus 0xff (per kio la paĝo pleniĝas post forviŝo) kiel markilon, do la libera areo certe ne estos traktata kiel datumoj.
Kompara tabelo:
Eblo 1
Eblo 2
Eblo 3
Erartoleremo
-
+
+
Komplikeco
+
-
+
Komplekseco de efektivigo
*
**
**
Opcio 1 havas mortigan difekton: se unu el la kaplinioj estas difektita, la tuta posta ĉeno estas detruita. La aliaj opcioj permesas al vi restarigi parton de la datumoj eĉ en kazo de grandega difekto.
Sed ĉi tie estas konvene memori, ke ni decidis konservi datumojn en kunpremita formo, kaj ĉiuokaze ni perdas ĉiujn datumojn sur la paĝo post "rompita" registro, do kvankam estas minuso en la tabelo, ni ne konsideras ĝin.
Kompakteco:
- en la unua opcio ni nur bezonas konservi la longon en la kaplinio, se ni uzas variablo-longajn entjerojn, tiam en plej multaj kazoj ni povas eluzi unu bajton;
- en la dua opcio ni bezonas konservi la komencan adreson kaj la longon; la rikordo devas esti de konstanta grandeco, mi taksas 4 bajtojn por rikordo (du bajtoj por la ofseto, kaj du bajtoj por la longo);
- la tria opcio postulas nur unu signon por indiki la komencon de la registrado, kaj plie la registrado mem kreskos je 1-2% pro la rastrumo. Ĝenerale, ĝi estas proksimume samnivela kun la unua opcio.
Komence, mi konsideris la duan opcion kiel la ĉefan (kaj eĉ skribis efektivigon). Mi forlasis ĝin nur kiam mi fine decidis uzi kunpremon.
Eble iam mi uzos tian opcion. Ekzemple, se mi devos trakti datumstokadon por ŝipo vojaĝanta inter la Tero kaj Marso - tute malsamaj postuloj pri fidindeco, kosma radiado, ...
Pri la tria opcio: mi donis al ĝi du stelojn pro la komplekseco de efektivigo simple ĉar mi ne ŝatas ludi kun eskapado, ŝanĝado de la longo en la procezo, ktp. Jes, eble mi estas partia, sed mi devos skribi la kodon - kial devigi min fari ion, kion mi ne ŝatas.
Resumo: Ni elektas la stokad-opcion en la formo de ĉenoj "kaplinio kun longo - variablolongaj datumoj" pro ĝia efikeco kaj facileco de efektivigo.
Uzante peckampojn por monitori la sukceson de skriboperacioj
Mi ne memoras nun de kie mi prenis la ideon, sed ĝi aspektas pli-malpli jene:
Por ĉiu eniro, ni asignas plurajn bitojn por konservi flagojn.
Kiel ni diris antaŭe, post forviŝo ĉiuj bitoj pleniĝas per 1, kaj ni povas ŝanĝi 1 al 0, sed ne inverse. Do por "flago ne agordita" ni uzas 1, por "flago agordita" - 0.
Jen kiel povus aspekti meti variablolongan rekordon en fulmmemoron:
- Agordu la flagon "daŭro-registrado komencita";
- Ni skribas la longon;
- Agordu la flagon "datenregistrado komenciĝis";
- Ni skribas datumojn;
- Ni agordis la flagon "registrado finiĝis".
Krome, ni havos flagon "eraro okazis", por entute 4-bitaj flagoj.
En ĉi tiu kazo ni havas du stabilajn statojn "1111" - la registrado ne komenciĝis kaj "1000" - la registrado sukcesis; kaze de neatendita interrompo de la registra procezo ni ricevos mezajn statojn, kiujn ni povos detekti kaj prilabori poste.
La aliro estas interesa, sed ĝi nur protektas kontraŭ subitaj elektropaneoj kaj similaj paneoj, kio kompreneble gravas, sed ĉi tio estas malproksima de la sola (kaj eĉ ne la ĉefa) kialo de eblaj paneoj.
Resumo: Ni pluiru serĉante bonan solvon.
Kontrolsumoj
Kontrolsumoj ankaŭ provizas manieron kontroli (kun racia probableco) ke ni legas precize tion, kio devus esti skribita. Kaj, male al la bitkampoj diskutitaj supre, ili ĉiam funkcias.
Se ni konsideras la liston de eblaj fontoj de problemoj, kiujn ni diskutis supre, tiam la ĉeksumo kapablas rekoni eraron sendepende de ĝia origino. (escepte, eble, de malbonaj eksterteruloj - ili ankaŭ povas falsi la kontrolsumon).
Do se nia celo estas kontroli, ke la datumoj estas sendifektaj, kontrolsumoj estas bonega ideo.
La elekto de la algoritmo por kalkuli la ĉeksumon ne levis demandojn - CRC. Unuflanke, la matematikaj ecoj permesas 100% kapton de eraroj de iuj tipoj, aliflanke - sur hazardaj datumoj ĉi tiu algoritmo kutime montras la probablecon de kolizioj ne multe pli altan ol la teoria limo.  Eble ĝi ne estas la plej rapida algoritmo, kaj eble ĝi ne ĉiam havas la plej malgrandan nombron da kolizioj, sed ĝi havas tre gravan kvaliton: en la testoj, kiujn mi renkontis, ne estis ŝablonoj, laŭ kiuj ĝi klare malsukcesus. Stabileco estas la ĉefa kvalito en ĉi tiu kazo.
Eble ĝi ne estas la plej rapida algoritmo, kaj eble ĝi ne ĉiam havas la plej malgrandan nombron da kolizioj, sed ĝi havas tre gravan kvaliton: en la testoj, kiujn mi renkontis, ne estis ŝablonoj, laŭ kiuj ĝi klare malsukcesus. Stabileco estas la ĉefa kvalito en ĉi tiu kazo.
Ekzemplo de volumetra studo: , (ligiloj al narod.ru, pardonu).
Tamen, la tasko elekti ĉeksumon ne estas kompleta, CRC estas tuta familio de ĉeksumoj. Vi devas decidi pri la longo, kaj poste elekti polinomon.
Elekti la longon de la ĉeksumo ne estas tiel simpla demando, kiel ĝi ŝajnas unuarigarde.
Permesu al mi ilustri:
Ni havu la probablecon de eraro en ĉiu bajto  kaj la ideala ĉeksumo, ni kalkulas la averaĝan nombron de eraroj por miliono da registroj:
kaj la ideala ĉeksumo, ni kalkulas la averaĝan nombron de eraroj por miliono da registroj:
Datumoj, bajto
Kontrolsumo, bajto
Nerimarkitaj eraroj
Falspozitivaj erardetektoj
Tuta nombro de malĝustaj respondoj
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
Ŝajnus, ke ĉio estas simpla - elektu la longon de la ĉeksumo kun minimumo de falsaj pozitivoj depende de la longo de la protektitaj datumoj - kaj vi finis.
Tamen, ekzistas problemo kun mallongaj kontrolsumoj: kvankam ili bone detektas erarojn je unuopa bito, ili povas, kun sufiĉe alta probableco, akcepti tute hazardajn datumojn kiel ĝustajn. Jam ekzistis artikolo pri Habr priskribanta .
Tial, por igi hazardan ĉeksumakordigon preskaŭ maleblan, oni devus uzi ĉeksumojn de 32 bitoj aŭ pli. (por longoj pli grandaj ol 64 bitoj, kutime oni uzas kriptografiajn haŝfunkciojn).
Malgraŭ la fakto, ke mi skribis pli frue, ke ni bezonas ŝpari spacon je ĉia kosto, ni tamen uzos 32-bitan kontrolsumon (16 bitoj ne sufiĉas, la probableco de kolizio estas pli ol 0.01%; kaj 24 bitoj, kiel oni diras, estas nek ĉi tie nek tie).
Obĵeto povas ekesti ĉi tie: ĉu ni konservis ĉiun bajton elektante kunpremon por nun doni 4 bajtojn samtempe? Ĉu ne estus pli bone ne kunpremi kaj ne aldoni kontrolsumon? Kompreneble ne, la manko de kunpremo ne signifas, ke ni ne bezonas integreckontrolon.
Ni ne reinventos la radon elektante polinomon, sed ni prenos la nun popularan CRC-32C.
Ĉi tiu kodo detektas 6-bitajn erarojn sur pakaĵetoj ĝis 22 bajtoj (verŝajne la plej ofta kazo por ni), 4-bitajn erarojn sur pakaĵetoj ĝis 655 bajtoj (ankaŭ ofta kazo por ni), 2 aŭ ajnan neparan nombron da bitaj eraroj sur pakaĵetoj de ajna akceptebla longo.
Se iu interesiĝas pri la detaloj
pri CRC.
sur — eble la ĉefa CRC-specialisto sur la planedo.
В estas , kiu provizas iomete pli bonajn parametrojn por la pakaĵlongoj, kiuj estas gravaj por ni, sed mi ne konsideris la diferencon signifa, kaj mi ne konsideris min sufiĉe kompetenta por elekti kutiman kodon anstataŭ la norman kaj bone esploritan.
Ankaŭ, ĉar niaj datumoj estas kunpremitaj, la demando ekestas: ĉu ni kalkulu la kontrolsumon de kunpremitaj aŭ nekunpremitaj datumoj?
Argumentoj favore al kalkulado de la ĉeksumo de nekunpremitaj datumoj:
- ni finfine bezonas kontroli la sekurecon de datumstokado - do ni kontrolas ĝin rekte (samtempe, eblaj eraroj en la efektivigo de kunpremo/malkunpremo, damaĝo kaŭzita de malbona memoro, ktp. estos kontrolitaj);
- la malŝveligi algoritmon en zlib havas sufiĉe maturan efektivigon kaj ne devus fali kun "kurbaj" enigaj datumoj, krome, ĝi ofte kapablas sendepende detekti erarojn en la eniga fluo, reduktante la ĝeneralan probablecon de nerimarko de eraro (mi faris teston kun la inversigo de ununura bito en mallonga registro, zlib detektis eraron en ĉirkaŭ triono de la kazoj).
Argumentoj kontraŭ kalkulado de la ĉeksumo de nekunpremitaj datumoj:
- CRC estas "adaptita" specife por la malmultaj biteraroj tipaj por fulmmemoro (biteraro en kunpremita fluo povas kaŭzi grandegan ŝanĝon en la elira fluo, sur kiu, pure teorie, ni povas "kapti" kolizion);
- Mi ne vere ŝatas la ideon provizi eble rompitajn datumojn al la malkunpremilo, , kiel li reagos.
En ĉi tiu projekto mi decidis forlasi la komunan praktikon konservi kontrolsumon de nekunpremitaj datumoj.
Resumo: Ni uzas CRC-32C, ni kalkulas la ĉeksumon el la datumoj en la formo, en kiu ili estas skribitaj al la fulmmemoro (post kunpremo).
Redundo
La uzo de redunda kodado kompreneble ne forigas datenperdon; tamen, ĝi povas signife (ofte je multaj grandordoj) redukti la probablecon de neriparebla datenperdo.
Ni povas uzi diversajn tipojn de redundanco por korekti erarojn.
Hamming-kodoj povas korekti unuopulajn bitajn erarojn, Reed-Solomon-kodoj estas simbolaj, pluraj kopioj de datumoj kune kun ĉeksumoj, aŭ kodado kiel RAID-6 povas helpi reakiri datumojn eĉ en kazo de amasa korupto.
Komence, mi celis la vastan uzon de erar-korekta kodado, sed poste mi komprenis, ke unue ni bezonas havi ideon pri kiaj eraroj ni volas protekti nin, kaj poste elekti la kodadon.
Ni diris pli frue, ke eraroj devas esti identigitaj kiel eble plej rapide. Je kiuj punktoj ni povus renkonti erarojn?
- Nefinita registrado (pro iu kialo, la elektro estingiĝis dum la registrado, la Raspberry frostiĝis, ...)
Bedaŭrinde, okaze de tia eraro, la sola eblo estas ignori malvalidajn rikordojn kaj konsideri la datumojn perditaj; - Skriberaroj (pro iu kialo, io alia ol tio, kio estis skribita, estis skribita al la fulmmemoro)
Ni povas tuj detekti tiajn erarojn se ni faras kontrollegadon tuj post la registrado; - Datumkorupto en memoro dum stokado;
- Legaj eraroj
Por korekti la eraron, se la ĉeksumo ne kongruas, sufiĉas ripeti la legadon plurfoje.
Tio estas, nur eraroj de la tria tipo (spontanea korupto de datumoj dum stokado) ne povas esti korektitaj sen erar-korekta kodado. Ŝajnas, ke tiaj eraroj estas ankoraŭ ekstreme neverŝajnaj.
Resumo: oni decidis forlasi redundan kodadon, sed se la operacio montros la erarecon de tiu decido, tiam oni revenu al la konsidero de la problemo (kun jam akumulitaj statistikoj pri malsukcesoj, kiuj ebligos elekti la optimuman tipon de kodado).
Aliaj
Kompreneble, la formato de la artikolo ne permesas pravigi ĉiun peceton en la formato. (kaj mi jam elĉerpis mian forton), do mi nelonge trairos kelkajn punktojn, kiuj ne estis tuŝitaj antaŭe.
- Oni decidis igi ĉiujn paĝojn "egalaj"
Tio estas, ne estos specialaj paĝoj kun metadatenoj, apartaj fluoj, ktp., anstataŭe estos ununura fluo kiu laŭvice reskribas ĉiujn paĝojn.
Tio certigas egalan eluziĝon de la paĝoj, neniun ununuran punkton de difekto, kaj simple belan; - Estas esence provizi versiigadon de la formato.
Formato sen versinumero en la kaplinio estas malbona!
Sufiĉas aldoni kampon kun certa Magia Numero (subskribo) al la paĝkapo, kiu indikos la version de la uzata formato. (Mi ne kredas, ke estos eĉ dekduo da ili en la praktiko); - Uzu varian longan kaplinion por rikordoj (kiuj estas multaj), provante fari ĝin 1 bajton longa en la plej multaj kazoj;
- Por ĉifri la longon de la kaplinio kaj la longon de la stumpigita parto de la kunpremita rikordo, uzu variablo-longajn binarajn kodojn.
Ĝi estis tre helpema Huffman-kodoj. Post nur kelkaj minutoj, ni povis elekti la bezonatajn variablolongajn kodojn.
Priskribo de datumstoka formato
Bajta ordo
Kampoj pli grandaj ol unu bajto estas konservitaj en grand-endiana formato (reta bajtordo), tio estas, 0x1234 estas skribita kiel 0x12, 0x34.
Divido en paĝojn
Ĉiu fulmmemoro estas dividita en paĝojn de egala grandeco.
La defaŭlta paĝograndeco estas 32Kb, sed ne pli ol 1/4 de la tuta grandeco de la memor-ĉipo (por 4MB-ĉipo, tio estas 128 paĝoj).
Ĉiu paĝo stokas datumojn sendepende de la aliaj (tio estas, datumoj de unu paĝo ne referencas datumojn de alia paĝo).
Ĉiuj paĝoj estas numeritaj laŭ natura ordo (laŭ kreskanta ordo de adresoj), komencante per numero 0 (la nula paĝo komenciĝas per adreso 0, la unua - kun 32Kb, la dua - kun 64Kb, ktp.)
La memor-ico estas uzata kiel ringa bufro, tio estas, unue la registrado iras al paĝo numero 0, poste al paĝo numero 1, ..., kiam ni plenigas la lastan paĝon, nova ciklo komenciĝas kaj la registrado daŭras de paĝo nulo.
Ene de la paĝo

Komence de la paĝo, 4-bajta paĝkapo estas konservita, poste kapa ĉeksumo (CRC-32C), kaj poste la rikordoj estas konservitaj en la formato "kapo, datumoj, ĉeksumo".
La paĝkapo (malpurverda en la diagramo) konsistas el:
- du-bajta kampo Magia Numero (ankaŭ konata kiel la indikilo de formatversio)
por la nuna versio de la formato ĝi estas konsiderata kiel0xed00 ⊕ номер страницы; - du-bajta nombrilo "Paĝa Versio" (memora reverka ciklonombro).
La rikordoj sur la paĝo estas konservitaj en kunpremita formo (uzante la algoritmon deflate). Ĉiuj rikordoj sur unu paĝo estas kunpremitaj en unu fluo (uzante komunan vortaron), kaj kunpremo rekomenciĝas sur ĉiu nova paĝo. Tio estas, por malkunpremi iun ajn rikordon, ĉiuj antaŭaj rikordoj de tiu paĝo (kaj nur de tiu paĝo) estas necesaj.
Ĉiu rikordo estas kunpremita per la flago Z_SYNC_FLUSH, rezultante en tio, ke la kunpremita fluo finiĝas per 4 bajtoj 0x00, 0x00, 0xff, 0xff, eble antaŭitaj de unu aŭ du pliaj nulaj bajtoj.
Ni forĵetas ĉi tiun sekvencon (4, 5 aŭ 6 bajtojn longan) dum skribo al fulmmemoro.
La rekorda kaplinio estas 1, 2 aŭ 3 bajtoj, stokante:
- unu bito (T) indikanta la tipon de registro: 0 - kunteksto, 1 - protokolo;
- varia longokampo (S) de 1 ĝis 7 bitoj, difinante la longon de la kaplinio kaj la "voston", kiuj devas esti aldonitaj al la rikordo por malpakado;
- rekordlongo (L).
Tabelo de S-valoroj:
S
Longo de la titolo, bajtoj
Forĵetita dum skribado, bajto
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Mi provis ilustri, mi ne scias kiom klare ĝi montriĝis:
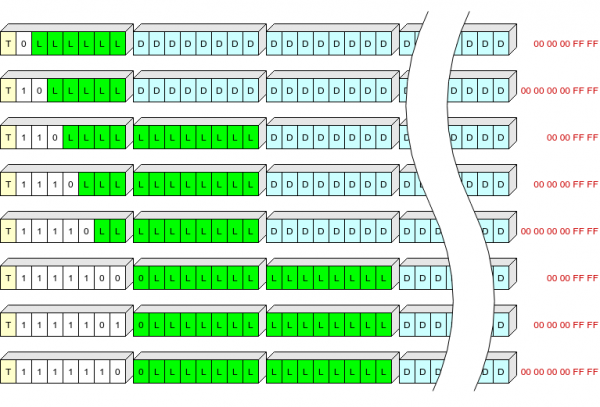
La flava koloro ĉi tie indikas la kampon T, la blanka koloro indikas la kampon S, la verda koloro indikas la L (longon de la kunpremitaj datumoj en bajtoj), la blua koloro indikas la kunpremitajn datumojn, kaj la ruĝa koloro indikas la finajn bajtojn de la kunpremitaj datumoj, kiuj ne estas skribitaj al la fulmmemoro.
Tiel, ni povas skribi la kapliniojn de rikordoj de la plej ofta longo (ĝis 63+5 bajtoj en kunpremita formo) en unu bajto.
Post ĉiu skribo, CRC-32C-ĉeksumo estas konservita, kiu uzas la inversigitan valoron de la antaŭa ĉeksumo kiel la komencan valoron (init).
CRC havas la proprecon de "daŭro", la jena formulo validas (plus aŭ minus bitinversio en la procezo):  .
.
Tio estas, ni fakte kalkulas la CRC de ĉiuj antaŭaj kapbajtoj kaj datumoj sur ĉi tiu paĝo.
Tuj post la kontrolsumo estas la kaplinio de la sekva rikordo.
La kaplinio estas desegnita tiel, ke ĝia unua bajto ĉiam diferencas de 0x00 kaj 0xff (se anstataŭ la unua bajto de la kaplinio ni renkontas 0xff, tiam tio signifas, ke temas pri neuzata areo; 0x00 signalas eraron).
Specimenaj algoritmoj
Legado el fulmmemoro
Ĉiu legado estas akompanata de kontrolo de la sumo.
Se la ĉeksumo ne kongruas, la legado estas ripetata plurfoje kun la espero legi la ĝustajn datumojn.
(tio havas sencon, Linux Ne konservas en kaŝmemoro legaĵoj de NOR-Fulmo, kontrolita)
Skribado al fulmmemoro
Ni skribas la datumojn.
Ni legu ilin.
Se la legitaj datumoj ne kongruas kun la skribitaj datumoj, ni plenigas la areon per nuloj kaj signalas eraron.
Preparante novan mikrocirkviton por funkciado
Por inicialigo, kaplinio kun versio 1 estas skribita al la unua (aŭ pli precize, nula) paĝo.
Post tio, la komenca kunteksto estas skribita al ĉi tiu paĝo (ĝi enhavas la UUID-on de la maŝino kaj defaŭltajn agordojn).
Jen tio, la fulmmemoro estas preta funkcii.
Ŝarĝante la maŝinon
Dum ŝargado, la unuaj 8 bajtoj de ĉiu paĝo (kaplinio + CRC) estas legitaj, paĝoj kun nekonata Magia Numero aŭ malĝusta CRC estas ignorataj.
El la "ĝustaj" paĝoj, paĝoj kun la maksimuma versio estas elektitaj, kaj el ili, la paĝo kun la plej alta numero estas prenita.
La unua registro estas legita, la CRC estas kontrolita por korekteco, kaj la flago "kunteksto" estas kontrolita. Se ĉio estas en ordo, ĉi tiu paĝo estas konsiderata aktuala. Se ne, ni reiras al la antaŭa ĝis ni trovas "vivan" paĝon.
kaj sur la trovita paĝo ni legas ĉiujn rikordojn, tiujn, kiujn ni uzas kun la flago "kunteksto".
Konservu la zlib-vortaron (ĝi estos bezonata por aldoni al ĉi tiu paĝo).
Jen ĉio, la ŝarĝado finiĝis, la kunteksto estas restarigita, vi povas labori.
Aldonante Protokolan Eniron
Ni kunpremas la rikordon per la ĝusta vortaro, specifante Z_SYNC_FLUSH. Ni vidas ĉu la kunpremita rikordo taŭgas sur la nuna paĝo.
Se ĝi ne taŭgas (aŭ estis CRC-eraroj sur la paĝo), komencu novan paĝon (vidu sube).
Ni skribas la rikordon kaj la CRC-kodon. Se eraro okazas, ni komencas novan paĝon.
Nova paĝo
Ni elektas liberan paĝon kun minimuma nombro (ni konsideras paĝon kun malĝusta kontrolsumo en la kaplinio aŭ kun versio pli malalta ol la nuna kiel libera). Se ne ekzistas tiaj paĝoj, ni elektas paĝon kun minimuma nombro el tiuj, kiuj havas version egalan al la nuna.
Ni forviŝas la elektitan paĝon. Ni komparas la enhavon per 0xff. Se io estas malĝusta, ni prenas la sekvan liberan paĝon, ktp.
Ni skribas la kaplinion al la forigita paĝo, la unua eniro estas la nuna stato de la kunteksto, la sekva estas la neskribita protokola eniro (se ekzistas unu).
Aplikebleco de la formato
Laŭ mia opinio, ĉi tiu estas bona formato por konservi iujn ajn pli-malpli kunpremeblajn informfluojn (simpla teksto, JSON, MessagePack, CBOR, eble protobuf) en NOR-Flash.
Kompreneble, la formato estas "akrigita" por SLC NOR Flash.
Ĝi ne devus esti uzata kun alt-BER-medioj kiel NAND aŭ MLC NOR. (ĉu tia memoro eĉ haveblas por vendo? Mi nur vidis menciojn pri ĝi en verkoj pri korektaj kodoj).
Krome, ĝi ne devus esti uzata kun aparatoj, kiuj havas propran FTL: USB-memorilon, SD, MicroSD, ktp. (por tia memoro mi kreis formaton kun paĝograndeco de 512 bajtoj, subskribo komence de ĉiu paĝo kaj unikaj registraĵnumeroj - kelkfoje eblis reakiri ĉiujn datumojn de "difektita" USB-memorilo per simple sinsekva legado).
Depende de la taskoj, la formato uzeblas sen ŝanĝoj sur USB-memoriloj de 128Kbit (16Kb) ĝis 1Gbit (128Mb). Se dezirite, ĝi uzeblas sur pli grandkapacitaj blatoj, sed verŝajne necesas adapti la paĝograndecon. (Sed ĉi tie aperas la demando pri ekonomia farebleco, la prezo de grandvolumena NOR-Fulmo ne estas kuraĝiga).
Se iu ajn trovas la formaton interesa kaj volas uzi ĝin en malfermitkoda projekto, skribu al mi, mi provos trovi tempon, poluri la kodon kaj afiŝos ĝin ĉe github.
konkludo
Kiel ni vidas, fine la formato montriĝis simpla kaj eĉ teda.
Malfacilas reflekti la evoluon de mia vidpunkto en artikolo, sed kredu min: komence mi volis krei ion sofistikan, nedetrueblan, kapablan postvivi eĉ post nuklea eksplodo en proksima proksimeco. Tamen, la racio (mi esperas) ankoraŭ venkis kaj iom post iom la prioritatoj ŝanĝiĝis al simpleco kaj kompakteco.
Ĉu eblas, ke mi faris eraron? Jes, kompreneble. Eble ni aĉetis aron da malaltkvalitaj mikrocirkvitoj. Aŭ pro iu alia kialo la ekipaĵo ne plenumos atendojn rilate fidindecon.
Ĉu mi havas planon por tio? Mi pensas, ke post legado de la artikolo vi ne dubas, ke ekzistas plano. Kaj eĉ ne unu.
Iom pli serioze, la formato estis evoluigita kaj kiel funkcia opcio kaj kiel "prova balono".
Nuntempe, ĉio funkcias bone sur la tablo, la solvo estos deplojita laŭvorte post kelkaj tagoj. (proksimume) sur cent aparatoj, ni vidu kio okazos en "batala" operacio (feliĉe, mi esperas, la formato permesas fidindan detekton de paneoj; do eblos kolekti plenajn statistikojn). Post kelkaj monatoj eblos tiri konkludojn (kaj se vi malbonŝancas, eĉ pli frue).
Se, post ĝia uzado, oni malkovros iujn ajn gravajn problemojn kaj plibonigojn necesos, mi certe skribos pri tio.
Literaturo
Mi ne volis fari longan, enuigan liston de referencoj; finfine, ĉiu havas Guglon.
Jen mi decidis lasi liston de trovaĵoj, kiuj ŝajnis aparte interesaj al mi, sed iom post iom ili migris rekte en la tekston de la artikolo, kaj nur unu ero restis en la listo:
- Utileco de la aŭtoro de zlib. Ĝi povas montri la enhavon de deflate/zlib/gzip arkivoj klare. Se vi devas trakti la internan strukturon de la deflate (aŭ gzip) formato, mi tre rekomendas ĝin.
fonto: www.habr.com
