

Pro mia laborlinio, mi devas trakti situaciojn, kiam programisto skribas peton kaj pensas "La bazo estas inteligenta, ĝi povas pritrakti ĉion mem!«
En iuj kazoj (parte pro nescio pri la kapabloj de la datumbazo, parte pro antaŭtempaj optimumigoj), ĉi tiu aliro kondukas al la apero de "Frankensteins".
Unue, mi donos ekzemplon de tia peto:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Por substantive taksi la kvaliton de peto, ni kreu iun arbitran datuman aron:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
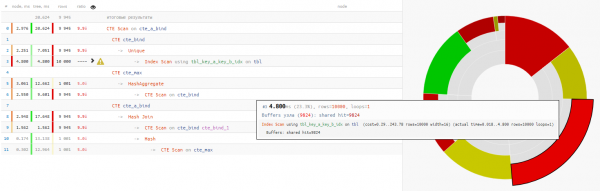
Rezultas ke legado de la datumoj prenis malpli ol kvaronon de la tempo demanda ekzekuto:
Forprenante ĝin peco post peco
Ni rigardu pli detale la peton kaj estu konfuzitaj:
- Kial estas WITH RECURSIVE ĉi tie se ne ekzistas rekursiemaj CTE-oj?
- Kial grupigi min/maksajn valorojn en aparta CTE, se ili tamen estas ligitaj al la origina specimeno?
+25% tempo - Kial uzi senkondiĉan 'SELECT * FROM' ĉe la fino por ripeti la antaŭan CTE?
+14% tempo
En ĉi tiu kazo, ni estis tre bonŝancaj, ke Hash Join estis elektita por la konekto, kaj ne Nested Loop, ĉar tiam ni ricevus ne nur unu CTE-Skanan enirpermesilon, sed 10K!
iom pri CTE ScanĈi tie ni devas memori tion CTE Scan estas simila al Seq Scan - tio estas neniu indeksado, sed nur kompleta serĉo, kio postulus 10K x 0.3ms = 3000ms por cikloj per cte_max aŭ 1K x 1.5ms = 1500ms kiam buklo per cte_bind!
Efektive, kion vi volis akiri kiel rezulto? Jes, kutime ĉi tiu estas la demando, kiu aperas ie en la 5-a minuto de analizado de "trietaĝaj" demandoj.
Ni volis eligi por ĉiu unika ŝlosilparo min/max de grupo per ŝlosilo_a.
Do ni uzu ĝin por ĉi tio :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 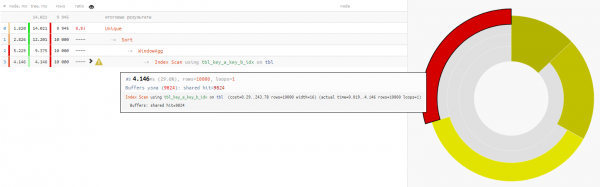
Ĉar legado de datumoj en ambaŭ opcioj prenas la saman proksimume 4-5ms, tiam nia tuta tempo gajnas -32% - ĉi tio estas en sia plej pura formo ŝarĝo forigita de baza CPU, se tia peto estas plenumita sufiĉe ofte.
Ĝenerale, vi ne devus devigi la bazon "porti la rondan, ruli la kvadratan."
fonto: www.habr.com
