

Modernaj datumcentroj havas centojn da aktivaj aparatoj instalitaj, kovritaj de malsamaj specoj de monitorado. Sed eĉ ideala inĝeniero kun perfekta monitorado en la mano povos ĝuste respondi al reto fiasko en nur kelkaj minutoj. En raporto ĉe la konferenco Next Hop 2020, mi prezentis metodologion pri desegna reto de DC, kiu havas unikan funkcion - la datumcentro resanigas sin en milisekundoj. Pli precize, la inĝeniero trankvile riparas la problemon, dum la servoj simple ne rimarkas ĝin.
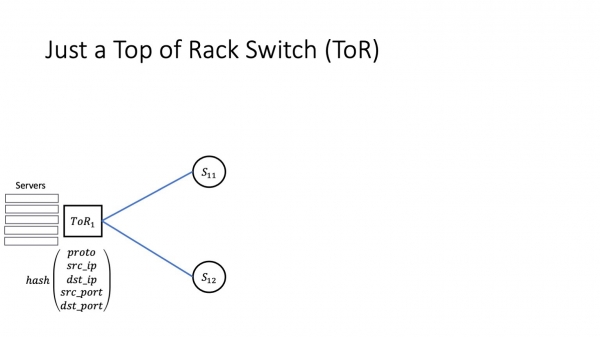
Por multaj retaj inĝenieroj, datumcentra reto komenciĝas, kompreneble, per ToR, kun ŝaltilo en la rako. ToR kutime havas du specojn de ligiloj. La malgrandaj iras al la serviloj, aliaj - estas N-oble pli da ili - iras al la spinoj de la unua nivelo, tio estas, al ĝiaj suprenligoj. Suprenaj ligiloj estas kutime konsiderataj egalaj, kaj trafiko inter suprenligiloj estas ekvilibra surbaze de hash de 5-opo, kiu inkluzivas proto, src_ip, dst_ip, src_port, dst_port. Neniuj surprizoj ĉi tie.
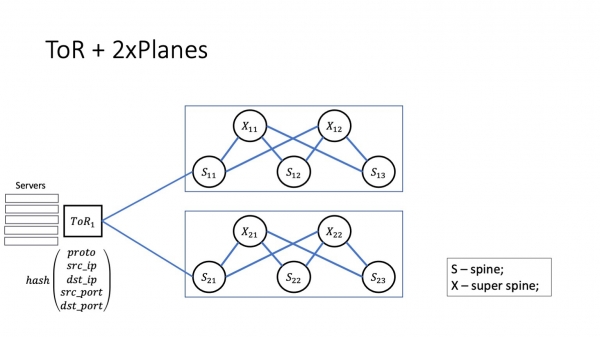
Poste, kiel aspektas la planarkitekturo? Spinoj de la unua nivelo ne estas ligitaj unu al la alia, sed estas ligitaj tra superspinoj. La litero X respondecos pri superspinoj; ĝi estas preskaŭ kiel kruckonekto.
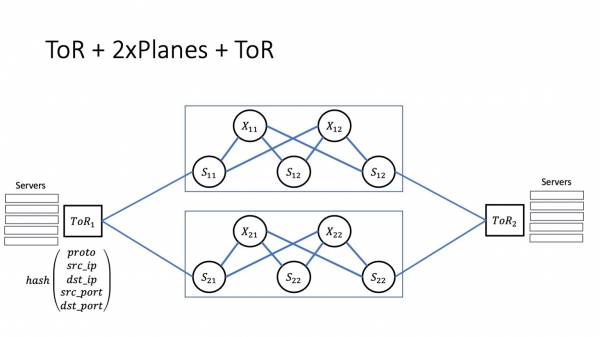
Kaj estas klare, ke, aliflanke, tori estas konektitaj al ĉiuj spinoj de la unua nivelo. Kio estas grava en ĉi tiu bildo? Se ni havas interagon ene de la rako, tiam la interago, kompreneble, trairas ToR. Se la interago okazas ene de la modulo, tiam la interago okazas tra la unuanivelaj spinoj. Se la interagado estas intermodula - kiel ĉi tie, ToR 1 kaj ToR 2 - tiam la interagado trairos spinojn de kaj la unua kaj dua niveloj.
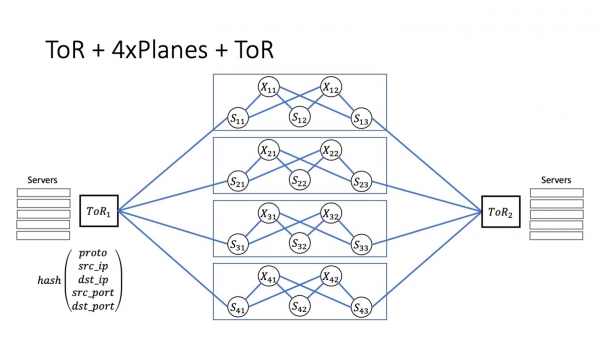
En teorio, tia arkitekturo estas facile skalebla. Se ni havas havenkapaciton, rezervan spacon en la datumcentro kaj antaŭmetitan fibron, tiam la nombro da lenoj ĉiam povas esti pliigita, tiel pliigante la totalan kapaciton de la sistemo. Ĉi tio estas tre facila por fari sur papero. Tiel estus en la vivo. Sed la hodiaŭa rakonto ne temas pri tio.

Mi volas, ke oni eltiru la ĝustajn konkludojn. Ni havas multajn vojojn ene de la datumcentro. Ili estas kondiĉe sendependaj. Unu vojo ene de la datumcentro nur eblas ene de ToR. Ene de la modulo, ni havas la nombron da vojoj egala al la nombro da vojoj. La nombro da vojoj inter moduloj estas egala al la produkto de la nombro da aviadiloj kaj la nombro da superspinoj en ĉiu aviadilo. Por pliklarigi ĝin, por kompreni la skalon, mi donos nombrojn, kiuj validas por unu el la Yandex-datumcentroj.

Estas ok aviadiloj, ĉiu aviadilo havas 32 superspinojn. Kiel rezulto, rezultas, ke ekzistas ok vojoj ene de la modulo, kaj kun intermodula interago jam estas 256 el ili.

Tio estas, se ni disvolvas Kuirlibron, provante lerni kiel konstrui mistoleremajn datumcentrojn, kiuj resanigas sin, tiam ebena arkitekturo estas la ĝusta elekto. Ĝi solvas la skalproblemon, kaj en teorio ĝi estas facila. Estas multaj sendependaj vojoj. La demando restas: kiel tia arkitekturo postvivas fiaskojn? Estas diversaj malsukcesoj. Kaj ni diskutos ĉi tion nun.
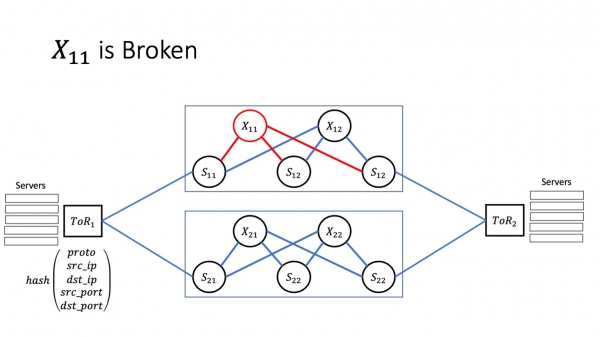
Lasu unu el niaj superspinoj "malsaniĝi". Ĉi tie mi revenis al la duebena arkitekturo. Ni restos kun ĉi tiuj kiel ekzemplo ĉar simple estos pli facile vidi kio okazas kun malpli da moviĝantaj partoj. Lasu X11 malsaniĝi. Kiel ĉi tio influos la servojn, kiuj loĝas en datumcentroj? Multe dependas de kia efektive aspektas la fiasko.
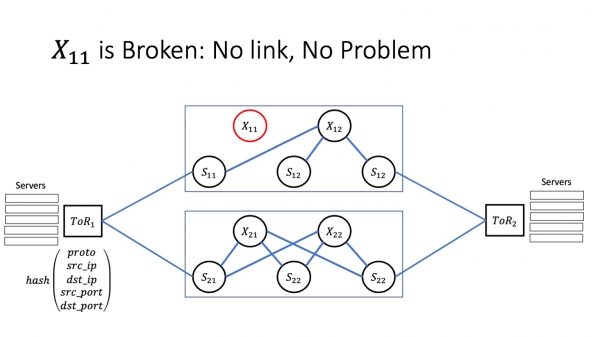
Se la fiasko estas bona, ĝi estas kaptita ĉe la aŭtomatiga nivelo de la sama BFD, la aŭtomatigo feliĉe metas la problemajn artikojn kaj izolas la problemon, tiam ĉio estas en ordo. Ni havas multajn vojojn, trafiko estas tuj redirektita al alternativaj itineroj, kaj servoj nenion rimarkos. Ĉi tio estas bona skripto.
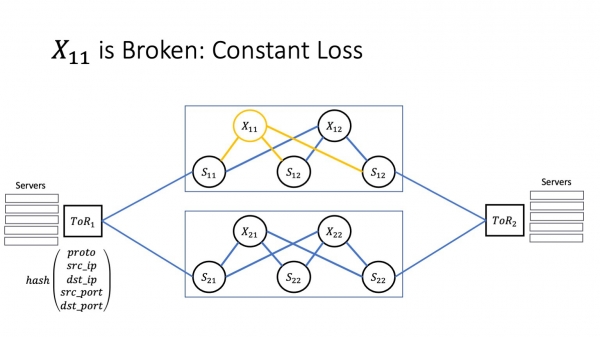
Malbona scenaro estas se ni havas konstantajn perdojn, kaj la aŭtomatigo ne rimarkas la problemon. Por kompreni kiel ĉi tio influas aplikaĵon, ni devos pasigi iom da tempo diskuti kiel funkcias TCP.
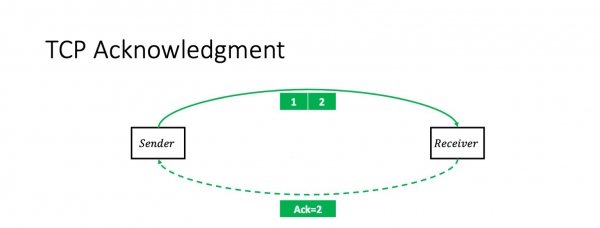
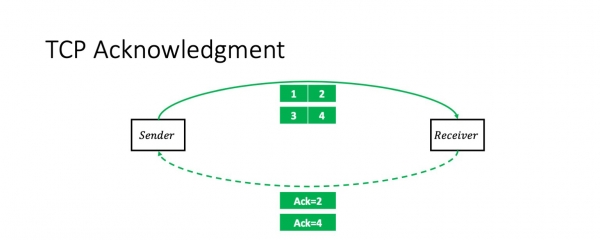
Mi esperas, ke mi ne ŝokas iun ajn per ĉi tiu informo: TCP estas transdona konfirma protokolo. Tio estas, en la plej simpla kazo, la sendinto sendas du pakaĵojn kaj ricevas akumulan akon sur ili: "Mi ricevis du pakaĵojn."
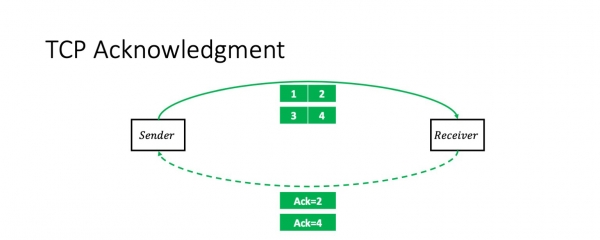
Post tio, li sendos du pliajn paketojn, kaj la situacio ripetiĝos. Mi anticipe pardonpetas pro iom da simpligo. Ĉi tiu scenaro estas ĝusta se la fenestro (la nombro da pakaĵoj dumfluge) estas du. Kompreneble, en la ĝenerala kazo tio ne estas nepre tiel. Sed la fenestra grandeco ne influas la pakaĵetan kuntekston.
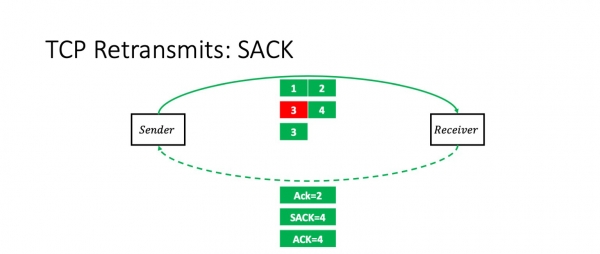
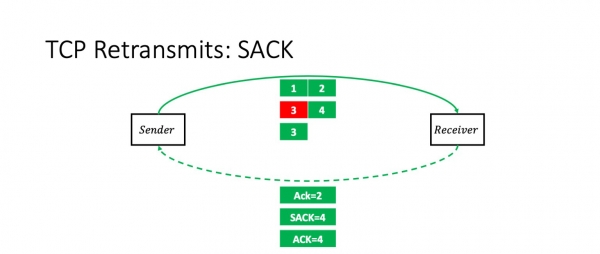
Kio okazas se ni perdas pakon 3? En ĉi tiu kazo, la ricevanto ricevos pakaĵojn 1, 2 kaj 4. Kaj li eksplicite diros al la sendinto uzante la opcion SAKO: "Vi scias, tri alvenis, sed la mezo estis perdita." Li diras, "Ack 2, SACK 4."
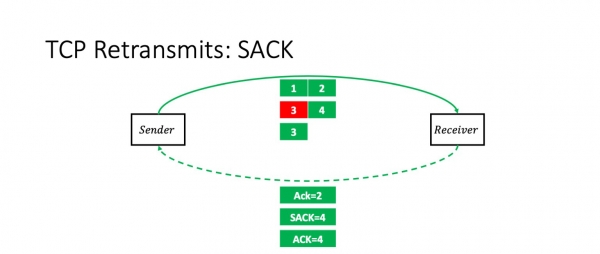
En ĉi tiu momento, la sendinto senprobleme ripetas ĝuste la pakaĵon perditan.
Sed se la lasta pako en la fenestro estas perdita, la situacio aspektos tute alia.
La ricevilo ricevas la unuajn tri pakaĵetojn kaj komencas atendi. Danke al kelkaj optimumigoj en la kerna TCP-stako, Linux Ĝi atendos kongruan pakaĵeton krom se ekzistas eksplicita flago indikanta, ke ĝi estas la lasta pakaĵeto aŭ io simila. Ĝi atendos ĝis la tempolimo por Malfrua Agnosko eksvalidiĝos kaj poste sendos agnoskon por la unuaj tri pakaĵetoj. Sed nun la sendinto devos atendi. Ĝi ne scias, ĉu la kvara pakaĵeto perdiĝis aŭ baldaŭ alvenos. Por eviti troŝarĝi la reton, ĝi provos atendi ĝis ekzistas eksplicita indiko, ke la pakaĵeto perdiĝis aŭ ĝis la tempolimo por RTO eksvalidiĝos.
Kio estas RTO-tempo? Ĉi tiu estas la maksimumo de la RTT kalkulita de la TCP-stako kaj iu konstanto. Kia konstanto ĉi tio estas, ni nun diskutos.
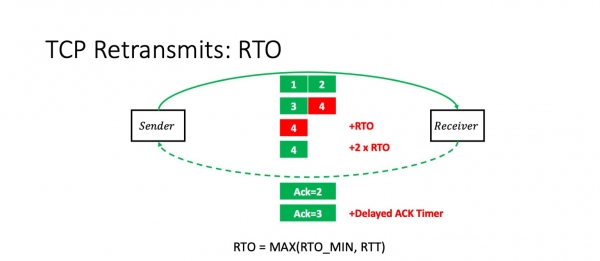
Sed la grava afero estas, ke se ni denove estas malbonŝancaj kaj la kvara pako denove estas perdita, tiam la RTO duobliĝas. Tio estas, ĉiu malsukcesa provo signifas duobligi la tempon.
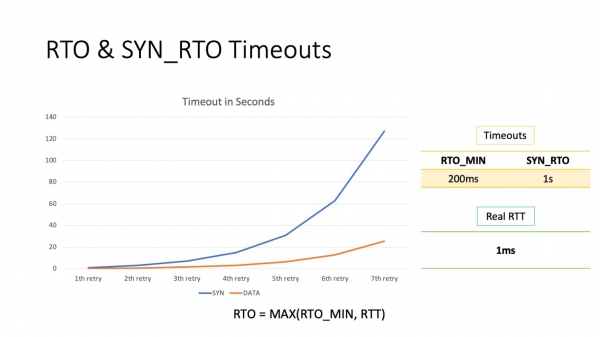
Nun ni vidu, al kio ĉi tiu bazo estas egala. Defaŭlte, la minimuma RTO estas 200 ms. Ĉi tiu estas la minimuma RTO por datumpakaĵoj. Por SYN-pakoj ĝi estas malsama, 1 sekundo. Kiel vi povas vidi, eĉ la unua provo resendi pakaĵojn daŭros 100 fojojn pli longe ol la RTT ene de la datumcentro.
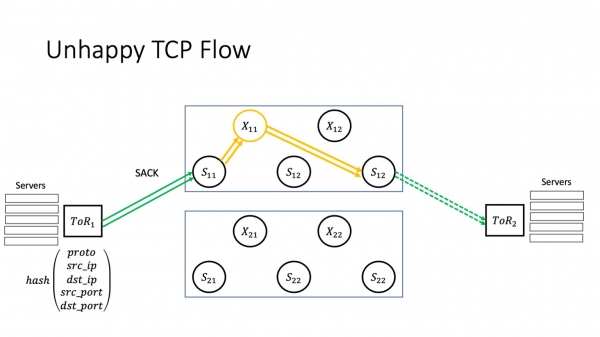
Nun ni revenu al nia scenaro. Kio okazas kun la servo? La servo komencas perdi pakojn. Lasu la servon esti kondiĉe bonŝanca komence kaj perdu ion meze de la fenestro, tiam ĝi ricevas SAKO kaj resendas la pakaĵetojn kiuj estis perditaj.
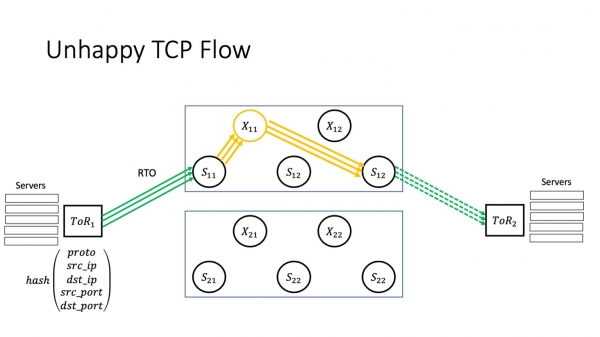
Sed se malbonŝanco ripetiĝas, tiam ni havas RTO. Kio gravas ĉi tie? Jes, ni havas multajn vojojn en nia reto. Sed la TCP-trafiko de unu aparta TCP-konekto daŭre trairos la saman rompitan stakon. Pakaj perdoj, kondiĉe ke ĉi tiu magia X11 nia ne eliras memstare, ne kondukas al trafiko fluanta en areojn kiuj ne estas problemaj. Ni provas liveri la pakaĵon per la sama rompita stako. Ĉi tio kondukas al kaskada fiasko: datumcentro estas aro de interagaj aplikoj, kaj kelkaj el la TCP-konektoj de ĉiuj ĉi tiuj aplikoj komencas degradi - ĉar superspine influas ĉiujn aplikojn kiuj ekzistas ene de la datumcentro. Kiel diras la diro: se vi ne ŝuis ĉevalon, la ĉevalo lamis; the horse went lame - la raporto ne estis transdonita; la raporto ne estis transdonita — ni perdis la militon. Nur ĉi tie la kalkulo estas en sekundoj de la momento kiam la problemo ekestas ĝis la stadio de degenero, kiun la servoj komencas senti. Ĉi tio signifas, ke uzantoj eble maltrafas ion ie.

Estas du klasikaj solvoj, kiuj kompletigas unu la alian. La unua estas servoj, kiuj provas enmeti pajlojn kaj solvi la problemon tiel: "Ni ĝustigu ion en la TCP-stako. Ni faru paŭzojn ĉe la aplikaĵa nivelo aŭ longdaŭrajn TCP-sesiojn kun internaj sankontroloj." La problemo estas, ke tiaj solvoj: a) tute ne skalas; b) estas tre malbone kontrolitaj. Tio estas, eĉ se la servo hazarde agordas la TCP-stakon tiel, ke ĝi plibonigas, unue, ĝi verŝajne ne aplikeblas por ĉiuj aplikoj kaj ĉiuj datumcentroj, kaj due, plej verŝajne, ĝi ne komprenos, ke ĝi estis farita. ĝuste, kaj kio ne. Tio estas, ĝi funkcias, sed ĝi funkcias malbone kaj ne skalas. Kaj se estas problemo pri reto, kiu kulpas? Kompreneble, NOC. Kion faras NOC?

Multaj servoj kredas, ke en NOC-laboro okazas io tia. Sed honeste, ne nur tio.

NOC en la klasika skemo okupiĝas pri la evoluo de multaj monitoraj sistemoj. Ĉi tiuj estas ambaŭ nigra skatolo kaj blanka skatolo monitorado. Pri ekzemplo de nigra skatolo spino monitorado Alexander Klimenko ĉe la lasta Next Hop. Cetere, ĉi tiu monitorado funkcias. Sed eĉ ideala monitorado havos tempomalfruon. Kutime ĉi tio estas kelkaj minutoj. Post kiam ĝi eksplodas, la deĵorantaj inĝenieroj bezonas tempon por kontroli ĝian funkciadon, lokalizi la problemon kaj poste estingi la problemon. Tio estas, en la plej bona kazo, trakti la problemon daŭras 5 minutojn, en la plej malbona kazo, 20 minutojn, se ne tuj evidentiĝas kie okazas la perdoj. Estas klare, ke dum ĉi tiu tuta tempo - 5 aŭ 20 minutoj - niaj servoj daŭre suferos, kio verŝajne ne estas bona.
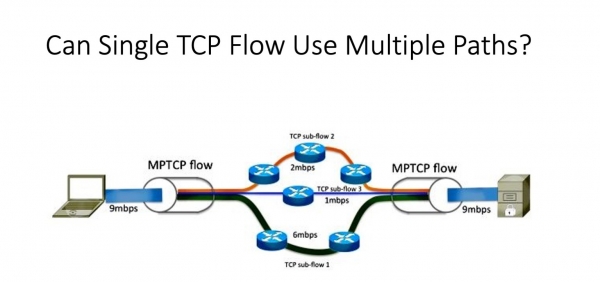
Kion vi vere ŝatus ricevi? Ni havas tiom da manieroj. Kaj problemoj ekestas ĝuste ĉar TCP-fluoj, kiuj estas malbonŝancaj, daŭre uzas la saman vojon. Ni bezonas ion, kio permesos al ni uzi plurajn itinerojn ene de ununura TCP-konekto. Ŝajnus, ke ni havas solvon. Estas TCP, kiu nomiĝas plurvoja TCP, tio estas, TCP por multoblaj vojoj. Vere, ĝi estis evoluigita por tute malsama tasko - por saĝtelefonoj, kiuj havas plurajn retajn aparatojn. Por maksimumigi translokigon aŭ fari ĉefan/rezervan reĝimon, mekanismo estis evoluigita, kiu kreas plurajn fadenojn (sesiojn) travideble al la aplikaĵo kaj ebligas al vi ŝanĝi inter ili en la okazo de malsukceso. Aŭ, kiel mi diris, maksimumigi la sinsekvon.
Sed estas nuanco ĉi tie. Por kompreni kio ĝi estas, ni devos rigardi kiel fadenoj estas establitaj.
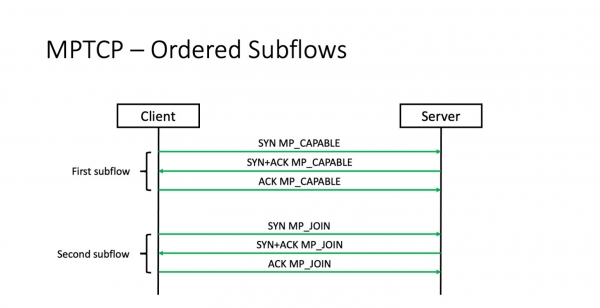
Fadenoj estas instalitaj sinsekve. La unua fadeno unue estas instalita. Postaj fadenoj tiam estas fiksitaj uzante la kuketon, kiu jam estis interkonsentita ene de tiu fadeno. Kaj jen la problemo.

La problemo estas, ke se la unua fadeno ne stariĝas, la dua kaj tria fadenoj neniam aperos. Tio estas, plurvoja TCP ne solvas la perdon de SYN-pako en la unua fluo. Kaj se la SYN estas perdita, plurvoja TCP iĝas regula TCP. Ĉi tio signifas, ke en datumcentra medio ĝi ne helpos nin solvi la problemon de perdoj en la fabriko kaj lerni uzi plurajn vojojn en kazo de fiasko.
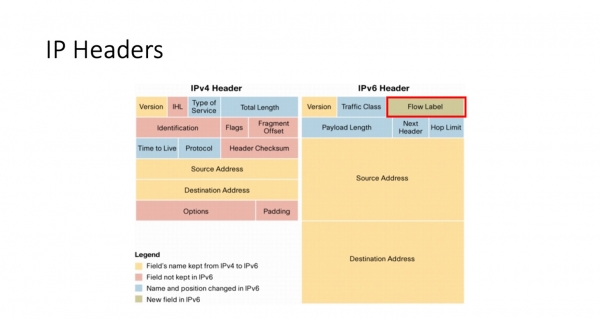
Kio povas helpi nin? Kelkaj el vi jam divenis el la titolo, ke grava kampo en nia plia diskuto estos la kampo de la IPv6-fluetikeda kaplinio. Efektive, ĉi tiu kampo, kiu aperas en versio 6 kaj forestas de versio 4, okupas 20 bitojn, kaj ĝia uzo estis la temo de multe da debato. Ĉi tio estas tre interesa - estis debato, kelkaj aferoj estis riparitaj en RFC-oj, kaj en Linux- samtempe, en la kerno aperis efektivigo, kiu neniam estis dokumentita ie ajn.

Mi invitas vin kuniĝi kun mi en malgranda esploro. Ni vidu, kio okazis en la kerno. Linux dum la pasintaj kelkaj jaroj.

2014. Inĝeniero de granda kaj respektata kompanio aldonas funkciojn al la kerno Linux La dependeco de la fluetikeda valoro de la ingohaŝo. Kion ili provis ripari ĉi tie? Ĉi tio rilatas al RFC 6438, kiu diskutis la jenan problemon. Ene de datumcentro, IPv4 ofte estas enkapsuligita en IPv6-pakaĵetoj ĉar la ŝtofo mem estas IPv6, sed IPv4 devas esti liverita ekstere. Dum longa tempo, estis problemoj kun ŝaltiloj, kiuj ne povis rigardi sub du IP-kaplinioj por atingi TCP aŭ UDP kaj trovi src_ports kaj dst_ports. Ĉi tio signifis, ke la haŝo, rigardante la unuajn du IP-kapliniojn, estis preskaŭ fiksita. Por eviti ĉi tion, kaj por certigi ĝustan ekvilibron de ĉi tiu enkapsuligita trafiko, oni proponis aldoni la haŝon de la 5-tupla enkapsuligita pakaĵeto al la fluetikeda kampo. Proksimume la sama estis farita por aliaj enkapsuligaj skemoj, por UDP kaj por GRE, ĉi-lasta uzante la GRE-ŝlosilan kampon. Ĉiukaze, la celoj ĉi tie estas klaraj. Kaj almenaŭ tiutempe ili estis utilaj.
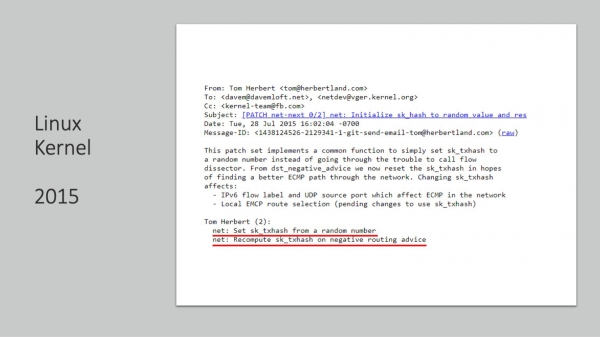
En 2015, nova flikaĵo venas de la sama respektata inĝeniero. Li estas tre interesa. Ĝi diras la jenon - ni randomigos la haŝon en kazo de negativa enrutiga evento. Kio estas negativa envoja evento? Ĉi tiu estas la RTO, kiun ni diskutis antaŭe, tio estas, la perdo de la vosto de la fenestro estas evento vere negativa. Vere, estas relative malfacile konjekti, ke tio estas.

2016, alia bonfama kompanio, ankaŭ granda. Ĝi malmuntas la lastajn lambastonojn kaj faras ĝin tiel ke la hash, kiun ni antaŭe faris hazarda, nun ŝanĝiĝas por ĉiu SYN-retranssendo kaj post ĉiu RTO-tempo. Kaj en ĉi tiu letero, por la unua kaj lasta fojo, la finfina celo estas deklarita - certigi ke trafiko en la okazo de perdoj aŭ kanalkongesto havas la kapablon esti mallaŭte redirektita kaj uzi plurajn vojojn. Kompreneble, post tio estis multaj eldonaĵoj, vi povas facile trovi ilin.
Kvankam ne, vi ne povas, ĉar ne estis unu eldonaĵo pri ĉi tiu temo. Sed ni scias!

Kaj se vi ne plene komprenas, kio estis farita, mi diros al vi nun.

Kio estis farita, kiaj funkcioj estis aldonitaj al la kerno? LinuxLa haketo ŝanĝiĝas al hazarda valoro post ĉiu RTO-evento. Ĉi tio estas la sama negativa vojiga rezulto. La haketo dependas de ĉi tiu haketo, kaj la fluetikedo dependas de la skb-haketo. Estas kelkaj funkciaj klarigoj ĉi tie, sed unu lumbildo ne kovros ĉiujn detalojn. Se iu scivolas, vi povas paŝi tra la kernan kodon kaj kontroli.
Kio gravas ĉi tie? La valoro de la fluo-etikedo kampo ŝanĝiĝas al hazarda nombro post ĉiu RTO. Kiel ĉi tio influas nian malfeliĉan TCP-rivereton?
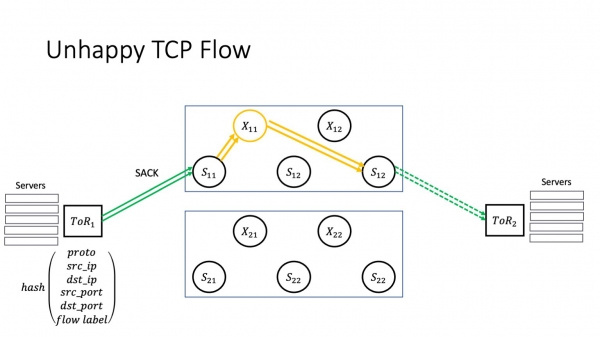
Se SAKO okazas, nenio ŝanĝiĝas ĉar ni provas resendi konatan perditan pakaĵon. Ĝis nun tiel bone.
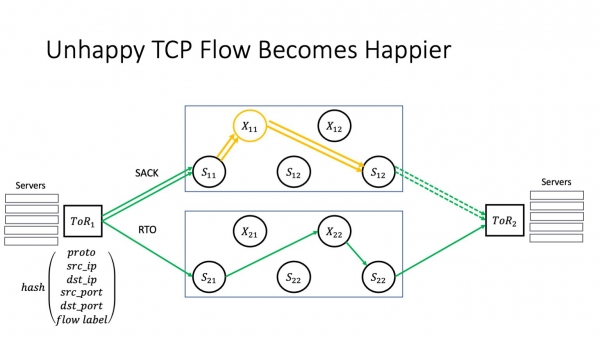
Sed en la kazo de RTO, kondiĉe ke ni aldonis fluo-etikedon al la hash-funkcio sur ToR, la trafiko povas preni alian vojon. Kaj ju pli da vojoj, des pli granda estas la ŝanco, ke ĝi trovos vojon, kiu ne estas tuŝita de misfunkciado de aparta aparato.
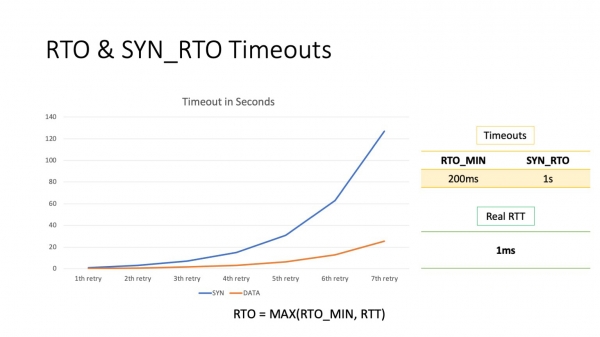
Unu problemo restas - RTO. Kompreneble, ekzistas alia vojo, sed multe da tempo estas malŝparita pri tio. 200 ms estas multe. Sekundo estas absolute sovaĝa. Antaŭe, mi parolis pri tempodaŭroj, ke servoj estas agorditaj. Do, sekundo estas tempodaŭro, kiu estas kutime agordita de la servo ĉe la aplika nivelo, kaj en ĉi tio la servo eĉ estos relative ĝusta. Krome, mi ripetas, la vera RTT ene de moderna datumcentro estas ĉirkaŭ 1 milisekundo.

Kion vi povas fari kun RTO-tempo? La timeout, kiu respondecas pri RTO en kazo de perdo de datumpakaĵoj, povas esti agordita relative facile de uzantspaco: ekzistas IP-utilo, kaj unu el ĝiaj parametroj enhavas la saman rto_min. Konsiderante ke RTO, kompreneble, devas esti ĝustigita ne tutmonde, sed por donitaj prefiksoj, tia mekanismo aspektas sufiĉe realigebla.

Vere, kun SYN_RTO ĉio estas iom pli malbona. Ĝi estas nature najlita malsupren. La kerno havas fiksan valoron de 1 sekundo, kaj jen ĝi. Vi ne povas atingi tien de uzantspaco. Estas nur unu maniero.
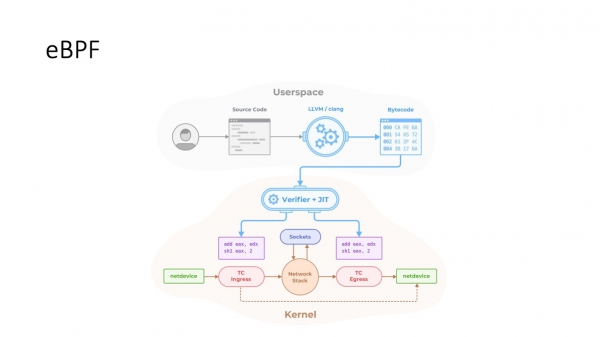
eBPF venas al la savo. Por diri simple, ĉi tiuj estas malgrandaj programoj C. Ili povas esti enmetitaj en hokojn en malsamaj lokoj en la ekzekuto de la kernstako kaj la TCP-stako, per kiuj vi povas ŝanĝi tre grandan nombron da agordoj. Ĝenerale, eBPF estas longtempa tendenco. Anstataŭ tranĉi dekduojn da novaj sysctl-parametroj kaj vastigi la IP-servaĵon, la movado moviĝas al eBPF kaj vastigas sian funkciecon. Uzante eBPF, vi povas dinamike ŝanĝi obstrukcajn kontrolojn kaj diversajn aliajn TCP-agordojn.
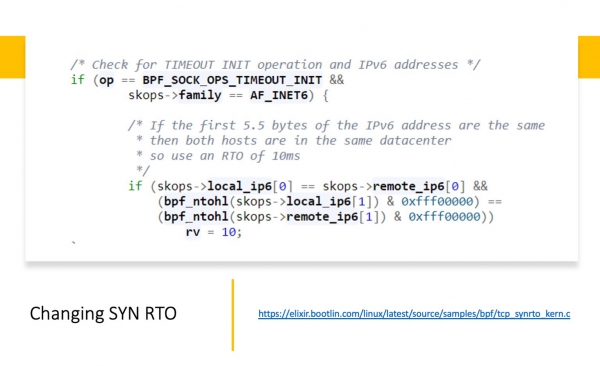
Sed gravas por ni, ke ĝi povas esti uzata por ŝanĝi la SYN_RTO-valorojn. Krome, estas publike afiŝita ekzemplo: . Kion oni faris ĉi tie? La ekzemplo funkcias, sed en si mem estas tre malglata. Ĉi tie oni supozas, ke ene de la datumcentro ni komparas la unuajn 44 bitojn; se ili kongruas, tiam ni estas ene de la datumcentro. Kaj ĉi-kaze ni ŝanĝas la SYN_RTO-tempovaloron al 4ms. La sama tasko povas esti farita multe pli elegante. Sed ĉi tiu simpla ekzemplo montras, ke tio estas a) ebla; b) relative simpla.

Kion ni jam scias? La fakto, ke la ebena arkitekturo permesas grimpi, ĝi rezultas esti ekstreme utila por ni kiam ni ebligas la fluo-etikedon sur ToR kaj ricevas la kapablon flui ĉirkaŭ problemaj areoj. La plej bona maniero redukti RTO kaj SYN-RTO-valoroj estas uzi eBPF-programojn. La demando restas: ĉu estas sekure uzi fluo-etikedon por ekvilibrigi? Kaj ĉi tie estas nuanco.
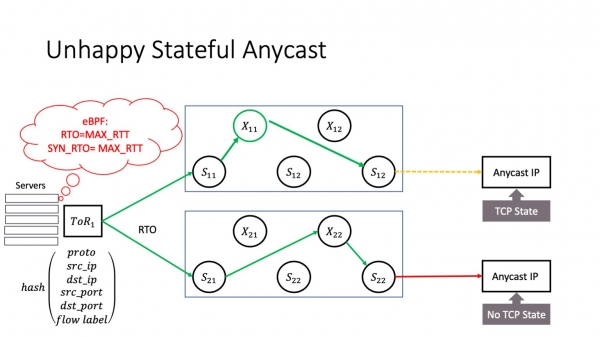
Supozu, ke vi havas servon en via reto, kiu loĝas en anycast. Bedaŭrinde, mi ne havas tempon por detaligi kio estas anycast, sed ĝi estas distribuita servo kun malsamaj fizikaj serviloj alireblaj per la sama IP-adreso. Kaj jen ebla problemo: la evento RTO povas okazi ne nur kiam trafiko pasas tra la ŝtofo. Ĝi ankaŭ povas okazi ĉe la ToR-bufrnivelo: kiam okazas enkasiga okazaĵo, ĝi eĉ povas okazi sur la gastiganto kiam la gastiganto verŝas ion. Kiam RTO-okazaĵo okazas kaj ĝi ŝanĝas la fluetikedon. En ĉi tiu kazo, trafiko povas iri al alia anycast-instanco. Ni supozu, ke ĉi tio estas ŝtata anycast, ĝi enhavas konektan staton - ĝi povus esti L3 Balancer aŭ iu alia servo. Tiam ekestas problemo, ĉar post RTO la TCP-konekto alvenas al la servilo, kiu scias nenion pri ĉi tiu TCP-konekto. Kaj se ni ne havas ŝtatan kundividon inter anycast-serviloj, tiam tia trafiko estos forigita kaj la TCP-konekto estos rompita.
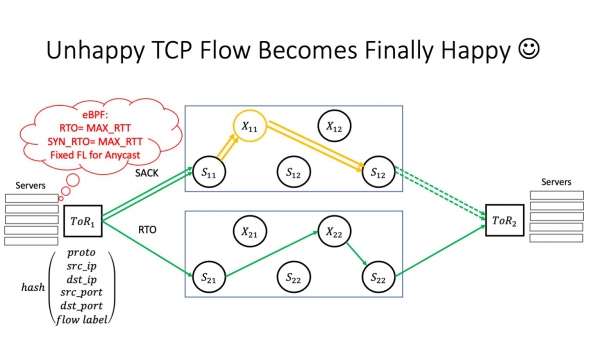
Kion vi povas fari ĉi tie? Ene de via kontrolita medio, kie vi ebligas fluetikedbalancadon, vi devas registri la valoron de la fluetikedo kiam vi aliras anycast-servilojn. La plej facila maniero estas fari tion per la sama programo eBPF. Sed ĉi tie estas tre grava punkto - kion fari se vi ne funkciigas datumcentran reton, sed estas telekomunika operatoro? Ankaŭ ĉi tio estas via problemo: komencante de certaj versioj de Juniper kaj Arista, ili inkluzivas fluetikedon en siaj haŝfunkcioj defaŭlte - sincere, pro kialo, kiu estas al mi neklara. Ĉi tio povas kaŭzi vin faligi TCP-konektojn de uzantoj pasantaj tra via reto. Do mi tre rekomendas kontroli viajn enkursigilojn ĉi tie.
Iel aŭ alimaniere, ŝajnas al mi, ke ni pretas pluiri al eksperimentoj.
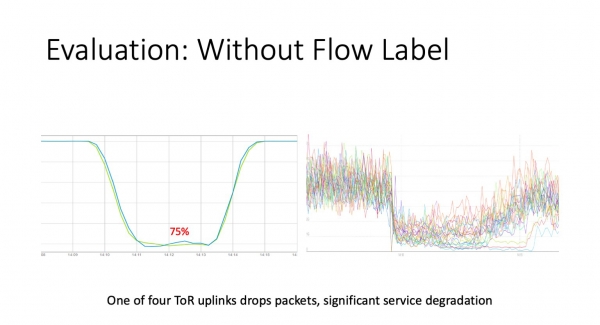
Kiam ni ebligis la fluo-etikedon sur ToR, preparis la eBPF-agenton, kiu nun vivas sur la gastigantoj, ni decidis ne atendi la sekvan grandan fiaskon, sed fari kontrolitajn eksplodojn. Ni prenis ToR, kiu havas kvar suprenligilojn, kaj starigis gutojn sur unu el ili. Ili desegnis regulon kaj diris - nun vi perdas ĉiujn paketojn. Kiel vi povas vidi maldekstre, ni havas per-paka monitorado, kiu falis al 75%, tio estas, 25% de pakoj estas perditaj. Dekstre estas grafikaĵoj de servoj vivantaj malantaŭ ĉi tiu ToR. Esence, ĉi tiuj estas trafikaj grafikaĵoj de la interfacoj kun serviloj ene de la rako. Kiel vi povas vidi, ili malleviĝis eĉ pli malalte. Kial ili malpliiĝis - ne je 25%, sed en iuj kazoj je 3-4 fojojn? Se la TCP-konekto estas malbonŝanca, ĝi daŭre provas atingi tra la rompita krucvojo. Ĉi tio estas plimalbonigita de la tipa konduto de la servo ene de la DC - por unu uzantpeto, N petoj al internaj servoj estas generitaj, kaj la respondo iros al la uzanto aŭ kiam ĉiuj datumfontoj respondas, aŭ kiam tempoforigo okazas ĉe la aplikaĵo. nivelo, kiu ankoraŭ devas esti agordita. Tio estas, ĉio estas tre, tre malbona.
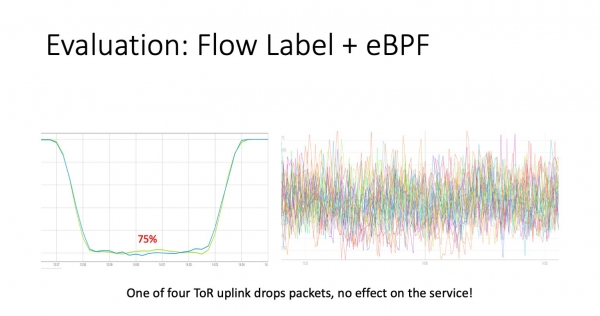
Nun la sama eksperimento, sed kun la fluo-etikedo valoro ebligita. Kiel vi povas vidi, maldekstre nia bata monitorado malpliiĝis je la sama 25%. Ĉi tio estas absolute ĝusta, ĉar ĝi scias nenion pri retranssendadoj, ĝi sendas pakaĵetojn kaj simple kalkulas la rilatumon de la nombro de liveritaj kaj perditaj pakoj.
Kaj dekstre estas la servohoraro. Vi ne trovos la efikon de problema artiko ĉi tie. En tiuj samaj milisekundoj, trafiko fluis de la problema areo al la tri ceteraj suprenligoj, kiuj ne estis tuŝitaj de la problemo. Ni havas reton, kiu resanigas sin.

Jen mia lasta lumbildo; tempo por fini. Nun, mi esperas, ke vi scias kiel konstrui mem-riparigan datumcentran reton. Vi ne bezonos plonĝi en la kerna arkivon. Linux Kaj serĉu tie specialajn flikaĵojn. Vi scias, ke Flow Label solvas la problemon en ĉi tiu kazo, sed vi devas alproksimiĝi al ĉi tiu mekanismo kun singardemo. Kaj mi denove emfazas, ke se vi estas telekomunika funkciigisto, vi ne uzu Flow Label kiel haŝfunkcion, alie vi interrompos la sesiojn de viaj uzantoj.
Retaj inĝenieroj devas sperti koncipan ŝanĝon: la reto komenciĝas ne per la ToR, ne per la reta aparato, sed kun la gastiganto. Sufiĉe okulfrapa ekzemplo estas kiel ni uzas eBPF kaj por ŝanĝi la RTO kaj por fiksi la fluetikedon al anycast-servoj.
La mekaniko de fluo-etikedo certe taŭgas por aliaj aplikoj ene de la kontrolita administra segmento. Ĉi tio povas esti trafiko inter datumcentroj, aŭ vi povas uzi tiajn mekanikojn en speciala maniero por administri elirantan trafikon. Sed mi rakontos al vi pri ĉi tio, mi esperas, venontfoje. Koran dankon pro via atento.
fonto: www.habr.com
