

Lastatempe liberigita , kiu montras bonan tendencon en maŝinlernado en la lastaj jaroj. Resume: la nombro da maŝinlernado-komencoj falis en la lastaj du jaroj.
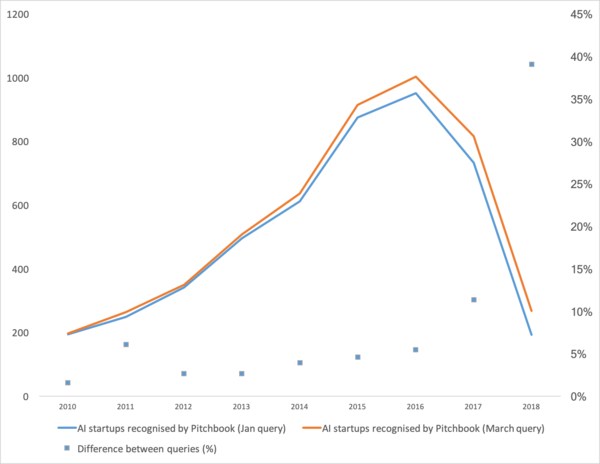
Nu. Ni rigardu "ĉu la veziko krevis", "kiel daŭre vivi" kaj parolu pri kie venas ĉi tiu squiggle en la unua loko.
Unue, ni parolu pri kio estis la akcelilo de ĉi tiu kurbo. De kie ŝi venis? Ili verŝajne memoros ĉion maŝinlernado en 2012 ĉe la ImageNet-konkurado. Post ĉio, ĉi tio estas la unua tutmonda evento! Sed fakte ĉi tio ne estas la kazo. Kaj la kresko de la kurbo komenciĝas iom pli frue. Mi dividus ĝin en plurajn punktojn.
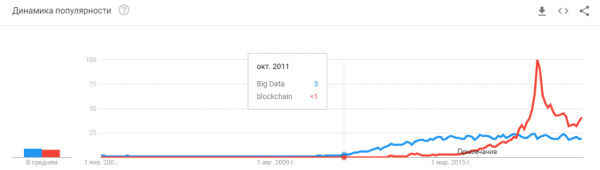
- 2008 vidis la aperon de la esprimo "grandaj datumoj". Veraj produktoj komenciĝis ekde 2010. Grandaj datumoj rekte rilatas al maŝinlernado. Sen grandaj datumoj, la stabila funkciado de la algoritmoj, kiuj ekzistis tiutempe, estas neebla. Kaj ĉi tiuj ne estas neŭralaj retoj. Ĝis 2012, neŭralaj retoj estis la konservaĵo de marĝena malplimulto. Sed tiam komencis funkcii tute malsamaj algoritmoj, kiuj ekzistis dum jaroj, aŭ eĉ jardekoj: (1963,1993), (1995), (2003),... Noventreprenoj de tiuj jaroj estas ĉefe rilataj al la aŭtomata prilaborado de strukturitaj datumoj: kasregistriloj, uzantoj, reklamado, multe pli.
Derivaĵo de ĉi tiu unua ondo estas aro de kadroj kiel XGBoost, CatBoost, LightGBM, ktp.
- En 2011-2012 gajnis kelkajn bildrekonkonkursojn. Ilia efektiva uzo estis iom prokrastita. Mi dirus, ke amase signifaj noventreprenoj kaj solvoj komencis aperi en 2014. Necesis du jaroj por digesti, ke neŭronoj ankoraŭ funkcias, por krei oportunajn kadrojn, kiuj povus esti instalitaj kaj lanĉitaj en racia tempo, por evoluigi metodojn, kiuj stabiligus kaj akcelos la konverĝan tempon.
Konvoluciaj retoj ebligis solvi problemojn pri komputila vidado: klasifiko de bildoj kaj objektoj en la bildo, detekto de objektoj, rekono de objektoj kaj homoj, plibonigo de bildo ktp., ktp.
- 2015-2017. La eksplodo de algoritmoj kaj projektoj bazitaj sur ripetiĝantaj retoj aŭ iliaj analogoj (LSTM, GRU, TransformerNet, ktp.). Aperis bonfunkciaj parol-al-tekstaj algoritmoj kaj maŝintradukaj sistemoj. Ili estas parte bazitaj sur konvoluciaj retoj por ĉerpi bazajn funkciojn. Parte pro tio, ke ni lernis kolekti vere grandajn kaj bonajn datumajn arojn.
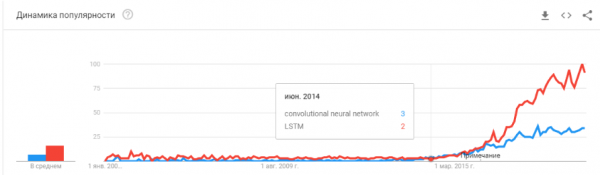
“Ĉu la veziko krevis? Ĉu la ekzaltiĝo estas trovarmigita? Ĉu ili mortis kiel blokĉeno?"
Alie! Morgaŭ Siri ĉesos labori en via telefono, kaj postmorgaŭ Tesla ne scios la diferencon inter turno kaj kanguruo.
Neŭralaj retoj jam funkcias. Ili estas en dekoj da aparatoj. Ili vere permesas vin gajni monon, ŝanĝi la merkaton kaj la mondon ĉirkaŭ vi. Hype aspektas iomete malsama:
Estas nur, ke neŭralaj retoj ne plu estas io nova. Jes, multaj homoj havas altajn atendojn. Sed granda nombro da kompanioj lernis uzi neŭronojn kaj fari produktojn bazitajn sur ili. Neŭronoj provizas novajn funkciojn, permesas vin tranĉi laborpostenojn kaj redukti la prezon de servoj:
- Produktaj kompanioj integras algoritmojn por analizi difektojn sur la produktserio.
- Brutaro-bienoj aĉetas sistemojn por kontroli bovinojn.
- Aŭtomataj kombinaĵoj.
- Aŭtomatigitaj Vokcentroj.
- Filtriloj en SnapChat. (nu, almenaŭ io utila!)
Sed la ĉefa afero, kaj ne la plej evidenta: "Ne plu ekzistas novaj ideoj, aŭ ili ne alportos tujan kapitalon." Neŭralaj retoj solvis dekojn da problemoj. Kaj ili decidos eĉ pli. Ĉiuj evidentaj ideoj, kiuj ekzistis, estigis multajn noventreprenojn. Sed ĉio, kio estis sur la surfaco, jam estis kolektita. Dum la lastaj du jaroj, mi ne trovis eĉ unu novan ideon por la uzo de neŭralaj retoj. Ne unu nova aliro (nu, bone, estas kelkaj problemoj kun GANoj).
Kaj ĉiu posta starto estas pli kaj pli kompleksa. Ĝi ne plu postulas du ulojn kiuj trejnas neŭronon uzante malfermajn datumojn. Ĝi postulas programistojn, servilon, teamon de markiloj, kompleksa subteno ktp.
Kiel rezulto, estas malpli da noventreprenoj. Sed estas pli da produktado. Ĉu vi bezonas aldoni numerplatan rekonon? Estas centoj da specialistoj kun grava sperto sur la merkato. Vi povas dungi iun kaj post kelkaj monatoj via dungito faros la sistemon. Aŭ aĉetu pretan. Sed farante novan ekentreprenon?.. Freneza!
Vi devas krei vizitantspuran sistemon - kial pagi por amaso da licencoj kiam vi povas fari vian propran en 3-4 monatoj, akrigi ĝin por via komerco.
Nun neŭralaj retoj trairas la saman vojon, kiun trairis dekoj da aliaj teknologioj.
Ĉu vi memoras, kiel la koncepto de "retejo-programisto" ŝanĝiĝis ekde 1995? La merkato ankoraŭ ne estas saturita de specialistoj. Estas tre malmultaj profesiuloj. Sed mi povas veti, ke post 5-10 jaroj ne estos multe da diferenco inter Java-programisto kaj neŭrala reto-programisto. Estos sufiĉe da ambaŭ specialistoj sur la merkato.
Simple estos klaso de problemoj, kiuj povas esti solvitaj per neŭronoj. Aperis tasko - dungi specialiston.
"Kio sekvas? Kie estas la promesita artefarita inteligenteco?"
Sed ĉi tie estas malgranda sed interesa miskompreno :)
La teknologia stako kiu ekzistas hodiaŭ, ŝajne, ne kondukos nin al artefarita inteligenteco. Ideoj kaj ilia noveco grandparte elĉerpigis sin. Ni parolu pri tio, kio tenas la nunan evolunivelon.
Restriktoj
Ni komencu per memveturaj aŭtoj. Ŝajnas klare, ke eblas fari plene aŭtonomajn aŭtojn kun la hodiaŭa teknologio. Sed post kiom da jaroj tio okazos ne estas klare. Tesla kredas, ke tio okazos post kelkaj jaroj -

Estas multaj aliaj , kiuj taksas ĝin esti 5-10 jaroj.
Plej verŝajne, laŭ mi, post 15 jaroj la infrastrukturo de urboj mem ŝanĝiĝos tiel, ke la apero de aŭtonomaj aŭtomobiloj fariĝos neevitebla kaj fariĝos ĝia daŭrigo. Sed ĉi tio ne povas esti konsiderata inteligenteco. Moderna Tesla estas tre kompleksa dukto por datuma filtrado, serĉado kaj retrejnado. Ĉi tiuj estas reguloj-reguloj-reguloj, datumkolektado kaj filtriloj super ili (ĉi tie Mi skribis iom pli pri tio, aŭ rigardi de markoj).
La unua problemo
Kaj ĉi tie ni vidas unua fundamenta problemo. Grandaj datumoj. Ĝuste ĉi tio naskis la nunan ondon de neŭralaj retoj kaj maŝinlernado. Nuntempe, por fari ion kompleksan kaj aŭtomatan, vi bezonas multajn datumojn. Ne nur multe, sed tre, tre multe. Ni bezonas aŭtomatajn algoritmojn por ilia kolekto, markado kaj uzo. Ni volas igi la aŭton vidi la kamionojn al la suno - ni unue devas kolekti sufiĉan nombron da ili. Ni volas, ke la aŭto ne freneziĝu kun biciklo riglita al la kofro - pli da specimenoj.
Krome, unu ekzemplo ne sufiĉas. Centoj? Miloj?

Dua problemo
Dua problemo — bildigo de tio, kion nia neŭrala reto komprenis. Ĉi tio estas tre ne-triviala tasko. Ĝis nun, malmultaj homoj komprenas kiel bildigi ĉi tion. Ĉi tiuj artikoloj estas tre lastatempaj, ĉi tiuj estas nur kelkaj ekzemploj, eĉ se malproksimaj:
obsedo kun teksturoj. Ĝi bone montras, kion la neŭrono emas fiksi + kion ĝi perceptas kiel komencajn informojn.

Attention at . Fakte, altiro ofte povas esti uzata ĝuste por montri, kio kaŭzis tian retan reagon. Mi vidis tiajn aferojn kaj por senararigado kaj produktaj solvoj. Estas multaj artikoloj pri ĉi tiu temo. Sed ju pli kompleksaj la datumoj, des pli malfacile estas kompreni kiel atingi fortikan bildigon.

Nu, jes, la bona malnova aro de "rigardu kio estas ene de la maŝo en " Ĉi tiuj bildoj estis popularaj antaŭ 3-4 jaroj, sed ĉiuj rapide komprenis, ke la bildoj estas belaj, sed ili ne havis multe da signifo.
Mi ne menciis dekojn da aliaj aparatoj, metodoj, hakoj, esploroj pri kiel montri la internojn de la reto. Ĉu ĉi tiuj iloj funkcias? Ĉu ili helpas vin rapide kompreni, kio estas la problemo kaj sencimigi la reton?.. Akiri la lastan procenton? Nu, estas proksimume la sama:

Vi povas spekti ajnan konkurson ĉe Kaggle. Kaj priskribo de kiel homoj faras finajn decidojn. Ni stakigis 100-500-800 ekzemplerojn da modeloj kaj ĝi funkciis!
Mi troigas, kompreneble. Sed ĉi tiuj aliroj ne donas rapidajn kaj rektajn respondojn.
Havante sufiĉe da sperto, esplorinte malsamajn eblojn, vi povas doni verdikton pri kial via sistemo faris tian decidon. Sed estos malfacile korekti la konduton de la sistemo. Instalu lambastonon, movu la sojlon, aldonu datumaron, prenu alian backend-reton.
Tria problemo
Tria Fundamenta Problemo — kradoj instruas statistikon, ne logikon. Statistike ĉi tio :

Logike, ĝi ne estas tre simila. Neŭralaj retoj lernas nenion kompleksan krom se ili estas devigitaj. Ili ĉiam instruas la plej simplajn signojn eblaj. Ĉu vi havas okulojn, nazon, kapon? Do ĉi tiu estas la vizaĝo! Aŭ donu ekzemplon, kie okuloj ne signifas vizaĝon. Kaj denove - milionoj da ekzemploj.
Estas Multa Ĉambro ĉe la Malsupro
Mi dirus, ke ĉi tiuj tri tutmondaj problemoj nuntempe limigas la disvolviĝon de neŭralaj retoj kaj maŝinlernado. Kaj kie ĉi tiuj problemoj ne limigis ĝin, ĝi jam estas aktive uzata.
Ĉi tio estas la fino? Ĉu neŭralaj retoj funkcias?
Nekonata. Sed, kompreneble, ĉiuj esperas, ke ne.
Estas multaj aliroj kaj direktoj por solvi la fundamentajn problemojn, kiujn mi elstarigis supre. Sed ĝis nun neniu el tiuj aliroj ebligis fari ion fundamente novan, solvi ion, kio ankoraŭ ne estis solvita. Ĝis nun, ĉiuj fundamentaj projektoj estas faritaj surbaze de stabilaj aliroj (Tesla), aŭ restas provaj projektoj de institutoj aŭ korporacioj (Google Brain, OpenAI).
Malglate parolante, la ĉefa direkto estas krei iun altnivelan reprezenton de la eniga datumoj. Iasence, "memoro". La plej simpla ekzemplo de memoro estas diversaj "Enkonstruado" - bildaj prezentoj. Nu, ekzemple, ĉiuj vizaĝrekonosistemoj. La reto lernas akiri de vizaĝo iun stabilan reprezentadon kiu ne dependas de rotacio, lumigado aŭ rezolucio. Esence, la reto minimumigas la metrikon "malsamaj vizaĝoj estas malproksimaj" kaj "identaj vizaĝoj estas proksimaj".
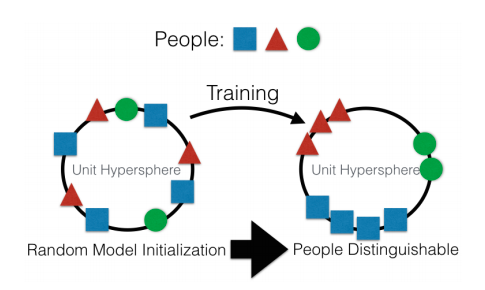
Por tia trejnado necesas dekoj kaj centoj da miloj da ekzemploj. Sed la rezulto portas kelkajn el la rudimentoj de "Unu-pafa Lernado". Nun ni ne bezonas centojn da vizaĝoj por memori homon. Nur unu vizaĝo kaj jen ĉio ni estas !
Estas nur unu problemo... La krado povas lerni nur sufiĉe simplajn objektojn. Kiam vi provas distingi ne vizaĝojn, sed, ekzemple, "homojn per vestaĵoj" (tasko ) - kvalito falas je multaj grandordoj. Kaj la reto ne plu povas lerni sufiĉe evidentajn ŝanĝojn en anguloj.
Kaj lerni de milionoj da ekzemploj ankaŭ estas iom amuza.
Estas laboro por signife redukti elektojn. Ekzemple, oni povas tuj rememori unu el la unuaj verkoj sur OneShot Lernado :
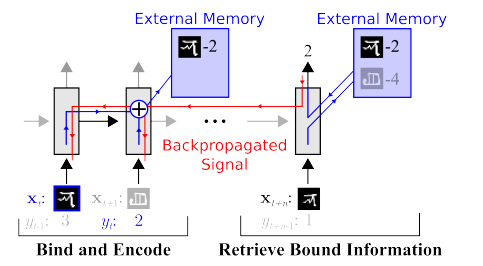
Estas multaj tiaj verkoj, ekzemple aŭ aŭ .
Estas unu minuso - kutime trejnado funkcias bone sur kelkaj simplaj, "MNIST" ekzemploj. Kaj kiam vi transiras al kompleksaj taskoj, vi bezonas grandan datumbazon, modelon de objektoj aŭ ian magion.
Ĝenerale, laboro pri One-Shot-trejnado estas tre interesa temo. Vi trovas multajn ideojn. Sed plejparte, la du problemoj, kiujn mi listigis (antaŭtrejnado sur grandega datumaro / malstabileco pri kompleksaj datumoj) multe malhelpas la lernadon.
Aliflanke, GANoj—generativaj kontraŭaj retoj—aliras la temon de Enkonstruado. Vi verŝajne legis amason da artikoloj pri Habré pri ĉi tiu temo. (, ,)
Karakterizaĵo de GAN estas la formado de iu interna ŝtatspaco (esence la sama Enkorpiĝo), kiu permesas vin desegni bildon. Ĝi povas esti , povas esti .
La problemo kun GAN estas ke ju pli kompleksa la generita objekto, des pli malfacile estas priskribi ĝin en "generator-diskriminacia" logiko. Kiel rezulto, la nuraj realaj aplikoj de GAN, kiujn oni aŭdas, estas DeepFake, kiu, denove, manipulas vizaĝajn reprezentadojn (por kiuj ekzistas grandega bazo).
Mi vidis tre malmultajn aliajn utilajn uzojn. Kutime ia trompo implikanta finajn desegnaĵojn de bildoj.
Kaj denove. Neniu havas ideon, kiel ĉi tio permesos al ni moviĝi en pli brilan estontecon. Reprezenti logikon/spacon en neŭrala reto estas bona. Sed ni bezonas grandegan nombron da ekzemploj, ni ne komprenas kiel la neŭrono reprezentas ĉi tion en si mem, ni ne komprenas kiel igi la neŭronon memori iun vere kompleksan ideon.
Plifortiga lernado — jen aliro el tute alia direkto. Verŝajne vi memoras kiel Guglo venkis ĉiujn en Go. Lastatempaj venkoj en Starcraft kaj Dota. Sed ĉi tie ĉio estas malproksime de tiel roza kaj promesplena. Li plej bone parolas pri RL kaj ĝiaj kompleksecoj .
Por mallonge resumi tion, kion skribis la aŭtoro:
- Modeloj el la skatolo ne taŭgas / funkcias malbone en la plej multaj kazoj
- Praktikaj problemoj estas pli facile solvi alimaniere. Boston Dynamics ne uzas RL pro sia komplekseco/neantaŭvidebleco/komputika komplekseco
- Por ke RL funkciu, vi bezonas kompleksan funkcion. Estas ofte malfacile krei/skribi
- Malfacile trejni modelojn. Vi devas pasigi multan tempon por pumpi kaj eliri el lokaj optimumoj
- Kiel rezulto, estas malfacile ripeti la modelon, la modelo estas malstabila kun la plej etaj ŝanĝoj
- Ofte tro konvenas kelkajn hazardajn ŝablonojn, eĉ hazardan nombrogeneratoron
La ŝlosila punkto estas, ke RL ankoraŭ ne funkcias en produktado. Guglo havas kelkajn eksperimentojn ( , ). Sed mi ne vidis ununuran produktan sistemon.
memoro. La malavantaĝo de ĉio priskribita supre estas manko de strukturo. Unu el la aliroj por provi ordigi ĉion ĉi estas provizi la neŭralan reton per aliro al aparta memoro. Por ke ŝi povu registri kaj reverki la rezultojn de siaj paŝoj tie. Tiam la neŭrala reto povas esti determinita per la nuna memorstato. Ĉi tio tre similas al klasikaj procesoroj kaj komputiloj.
La plej fama kaj populara - de DeepMind:
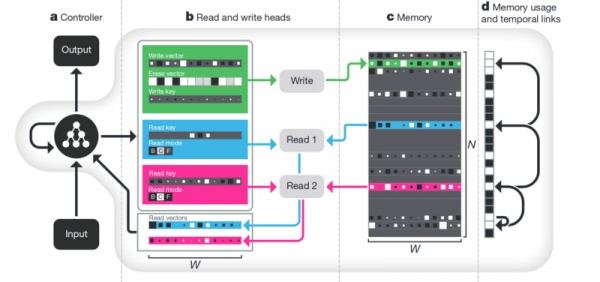
Ŝajnas, ke ĉi tio estas la ŝlosilo por kompreni inteligentecon? Sed verŝajne ne. La sistemo ankoraŭ postulas grandegan kvanton da datumoj por trejnado. Kaj ĝi funkcias ĉefe kun strukturitaj tabelaj datumoj. Cetere, kiam Facebook similan problemon, tiam ili prenis la vojon "ŝraŭba memoro, simple pli kompliki la neŭronon, kaj havu pli da ekzemploj - kaj ĝi lernos memstare."
Elirado. Alia maniero krei signifan memoron estas preni la samajn enkonstruojn, sed dum trejnado, enkonduku pliajn kriteriojn, kiuj permesus al vi reliefigi "signifoj" en ili. Ekzemple, ni volas trejni neŭralan reton por distingi inter homa konduto en vendejo. Se ni sekvus la norman vojon, ni devus fari dekduon da retoj. Unu serĉas homon, la dua estas determini kion li faras, la tria estas lia aĝo, la kvara estas lia sekso. Aparta logiko rigardas la parton de la vendejo kie ĝi faras/estas trejnita por fari tion. La tria determinas ĝian trajektorion, ktp.
Aŭ, se ekzistus senfina kvanto da datumoj, tiam eblus trejni unu reton por ĉiuj eblaj rezultoj (evidente, tia aro da datumoj ne povas esti kolektita).
La aliro de malimplikado diras al ni - ni trejnu la reton por ke ĝi mem povu distingi inter konceptoj. Tiel ke ĝi formus enkonstruadon bazitan sur la video, kie unu areo determinus la agon, oni determinus la pozicion sur la planko ĝustatempe, oni determinus la altecon de la persono, kaj oni determinus la sekson de la persono. Samtempe, dum trejnado, mi ŝatus preskaŭ ne instigi la reton per tiaj ŝlosilaj konceptoj, sed prefere ke ĝi reliefigu kaj grupigu areojn. Estas sufiĉe multaj tiaj artikoloj (kelkaj el ili , , ) kaj ĝenerale ili estas sufiĉe teoriaj.
Sed ĉi tiu direkto, almenaŭ teorie, devus kovri la problemojn listigitajn komence.
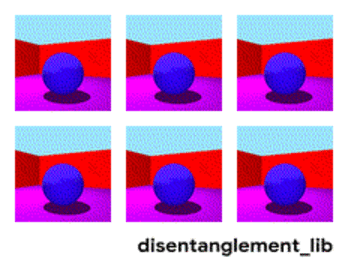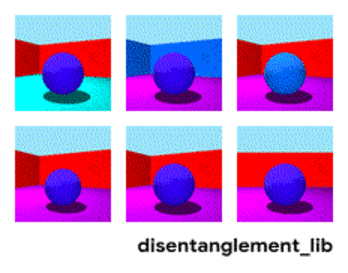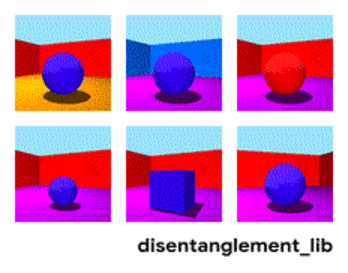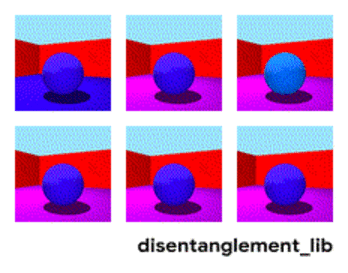
Bildmalkomponiĝo laŭ la parametroj "mura koloro/planka koloro/objekta formo/objekta koloro/ktp."

Malkomponiĝo de vizaĝo laŭ la parametroj "grandeco, brovoj, orientiĝo, haŭtkoloro, ktp."
Aliaj
Estas multaj aliaj, ne tiom tutmondaj, areoj, kiuj permesas vin iel redukti la datumbazon, labori kun pli heterogenaj datumoj ktp.
atenton. Verŝajne ne havas sencon apartigi ĉi tion kiel apartan metodon. Nur aliro kiu plibonigas aliajn. Multaj artikoloj estas dediĉitaj al li (,,). La atentiga punkto estas plibonigi la respondon de la reto specife al signifaj objektoj dum trejnado. Ofte per ia ekstera celnomo, aŭ malgranda ekstera reto.
3D simulado. Se vi faras bonan 3D-motoron, vi ofte povas kovri 90% de la trejnaj datumoj per ĝi (mi eĉ vidis ekzemplon kie preskaŭ 99% de la datumoj estis kovritaj de bona motoro). Estas multaj ideoj kaj hakoj pri kiel igi reton trejnitan sur 3D-motoro funkcii uzante realajn datumojn (Fin-agordado, stila translokigo, ktp.). Sed ofte fari bonan motoron estas pluraj ordoj de grandeco pli malfacila ol kolekti datumojn. Ekzemploj kiam motoroj estis faritaj:
Robota trejnado (, )
Trejnadoj varojn en la vendejo (sed en la du projektoj, kiujn ni faris, ni facile povus malhavi ĝin).
Trejnado ĉe Tesla (denove, la video supre).
trovoj
La tuta artikolo estas, iusence, konkludoj. Verŝajne la ĉefa mesaĝo, kiun mi volis fari, estis "la senpagaj donacoj finiĝis, neŭronoj ne plu provizas simplajn solvojn." Nun ni devas labori forte por fari kompleksajn decidojn. Aŭ laboru malfacile farante kompleksajn sciencajn esplorojn.
Ĝenerale, la temo estas diskutebla. Eble legantoj havas pli interesajn ekzemplojn?
fonto: www.habr.com
