

La artikolo diskutas plurajn manierojn determini la matematikan ekvacion de simpla (parigita) regresa linio.
Ĉiuj metodoj de solvado de la ekvacio diskutita ĉi tie estas bazitaj sur la metodo de malplej kvadrataj. Ni indiku la metodojn jene:
- Analiza solvo
- Gradienta Deveno
- Stokasta gradienta deveno
Por ĉiu metodo por solvi la ekvacion de rekto, la artikolo disponigas diversajn funkciojn, kiuj estas plejparte dividitaj en tiujn, kiuj estas skribitaj sen uzi la bibliotekon. numpy kaj tiuj, kiuj uzas por kalkuloj numpy. Oni kredas, ke lerta uzo numpy reduktos komputikkostojn.
Ĉiu kodo donita en la artikolo estas skribita en la lingvo pitono 2.7 uzante Kajero Jupyter. La fontkodo kaj dosiero kun specimenaj datumoj estas afiŝitaj
La artikolo pli celas kaj komencantojn kaj tiujn, kiuj jam iom post iom komencis majstri la studon de tre larĝa sekcio en artefarita inteligenteco - maŝinlernado.
Por ilustri la materialon, ni uzas tre simplan ekzemplon.
Ekzemplaj kondiĉoj
Ni havas kvin valorojn, kiuj karakterizas dependecon Y el X (Tabelo n-ro 1):
Tabelo n-ro 1 "Ekzemplaj kondiĉoj"

Ni supozos ke la valoroj  estas la monato de la jaro, kaj
estas la monato de la jaro, kaj  — enspezoj ĉi-monate. Alivorte, enspezo dependas de la monato de la jaro, kaj
— enspezoj ĉi-monate. Alivorte, enspezo dependas de la monato de la jaro, kaj  - la sola signo de kiu dependas enspezo.
- la sola signo de kiu dependas enspezo.
La ekzemplo estas tiel tiel, kaj el la vidpunkto de la kondiĉa dependeco de enspezo de la monato de la jaro, kaj el la vidpunkto de la nombro da valoroj - estas tre malmultaj el ili. Tamen tia simpligo ebligos, kiel oni diras, klarigi, ne ĉiam facile, la materialon, kiun asimilas komencantoj. Kaj ankaŭ la simpleco de la nombroj permesos al tiuj, kiuj volas solvi la ekzemplon surpapere sen gravaj laborkostoj.
Ni supozu, ke la dependeco donita en la ekzemplo povas esti sufiĉe bone proksimumata per la matematika ekvacio de simpla (parigita) regresa linio de la formo:

kie  estas la monato, en kiu la enspezo estis ricevita,
estas la monato, en kiu la enspezo estis ricevita,  — enspezo responda al la monato,
— enspezo responda al la monato,  и
и  estas la regresaj koeficientoj de la taksita linio.
estas la regresaj koeficientoj de la taksita linio.
Notu ke la koeficiento  ofte nomita la deklivo aŭ gradiento de la taksita linio; reprezentas la kvanton per kiu la
ofte nomita la deklivo aŭ gradiento de la taksita linio; reprezentas la kvanton per kiu la  kiam ĝi ŝanĝiĝas
kiam ĝi ŝanĝiĝas  .
.
Evidente, nia tasko en la ekzemplo estas elekti tiajn koeficientojn en la ekvacio  и
и  , ĉe kiu la devioj de niaj kalkulitaj enspezaj valoroj monate de la veraj respondoj, t.e. valoroj prezentitaj en la specimeno estos minimumaj.
, ĉe kiu la devioj de niaj kalkulitaj enspezaj valoroj monate de la veraj respondoj, t.e. valoroj prezentitaj en la specimeno estos minimumaj.
Malplej kvadrata metodo
Laŭ la metodo de malplej kvadrataj, la devio devas esti kalkulita per kvadrato. Ĉi tiu tekniko permesas eviti reciprokan nuligon de devioj se ili havas kontraŭajn signojn. Ekzemple, se en unu kazo, la devio estas +5 (plus kvin), kaj en la alia -5 (minus kvin), tiam la sumo de la devioj nuligos unu la alian kaj sumiĝos al 0 (nul). Eblas ne kvadrati la devion, sed uzi la posedaĵon de la modulo kaj tiam ĉiuj devioj estos pozitivaj kaj amasiĝos. Ni ne detale detalos pri ĉi tiu punkto, sed simple indikos, ke por komforto de kalkuloj, estas kutime kvadrati la devion.
Jen kiel aspektas la formulo, per kiu ni determinos la plej malgrandan sumon de kvadrataj devioj (eraroj):

kie  estas funkcio de aproksimado de veraj respondoj (tio estas la enspezo, kiun ni kalkulis),
estas funkcio de aproksimado de veraj respondoj (tio estas la enspezo, kiun ni kalkulis),
 estas la veraj respondoj (enspezo provizita en la specimeno),
estas la veraj respondoj (enspezo provizita en la specimeno),
 estas la specimena indekso (nombro de la monato en kiu la devio estas determinita)
estas la specimena indekso (nombro de la monato en kiu la devio estas determinita)
Ni diferencigu la funkcion, difinu la partajn diferencialajn ekvaciojn, kaj estu pretaj pluiri al la analiza solvo. Sed unue, ni faru mallongan ekskurson pri kio estas diferencigo kaj memoru la geometrian signifon de la derivaĵo.
Diferencigo
Diferencigo estas la operacio de trovado de la derivaĵo de funkcio.
Por kio estas uzata la derivaĵo? La derivaĵo de funkcio karakterizas la rapidecon de ŝanĝo de la funkcio kaj rakontas al ni ĝian direkton. Se la derivaĵo ĉe donita punkto estas pozitiva, tiam la funkcio pliiĝas; alie, la funkcio malpliiĝas. Kaj ju pli granda la valoro de la absoluta derivaĵo, des pli alta la indico de ŝanĝo de la funkciovaloroj, same kiel des pli kruta la deklivo de la funkciografiko.
Ekzemple, sub la kondiĉoj de kartezia koordinatsistemo, la valoro de la derivaĵo ĉe la punkto M(0,0) estas egala al + 25 signifas ke ĉe donita punkto, kiam la valoro estas ŝovita  dekstren per konvencia unuo, valoro
dekstren per konvencia unuo, valoro  pliiĝas je 25 konvenciaj ekzempleroj. Sur la grafiko ĝi aspektas kiel sufiĉe kruta altiĝo de valoroj
pliiĝas je 25 konvenciaj ekzempleroj. Sur la grafiko ĝi aspektas kiel sufiĉe kruta altiĝo de valoroj  de donita punkto.
de donita punkto.
Alia ekzemplo. La deriva valoro estas egala -0,1 signifas ke kiam delokita  po unu konvencia unuo, valoro
po unu konvencia unuo, valoro  malpliiĝas je nur 0,1 konvencia unuo. Samtempe, sur la grafikaĵo de la funkcio, ni povas observi apenaŭ rimarkeblan malsuprenan deklivon. Desegnante analogion kun monto, estas kvazaŭ ni tre malrapide malsuprenirus mildan deklivon de monto, male al la antaŭa ekzemplo, kie ni devis grimpi tre krutajn pintojn :)
malpliiĝas je nur 0,1 konvencia unuo. Samtempe, sur la grafikaĵo de la funkcio, ni povas observi apenaŭ rimarkeblan malsuprenan deklivon. Desegnante analogion kun monto, estas kvazaŭ ni tre malrapide malsuprenirus mildan deklivon de monto, male al la antaŭa ekzemplo, kie ni devis grimpi tre krutajn pintojn :)
Tiel, post diferencigo de la funkcio  per probableco
per probableco  и
и  , ni difinas 1-an ordaj partaj diferencialaj ekvacioj. Post determini la ekvaciojn, ni ricevos sistemon de du ekvacioj, solvante, kiujn ni povos elekti tiajn valorojn de la koeficientoj.
, ni difinas 1-an ordaj partaj diferencialaj ekvacioj. Post determini la ekvaciojn, ni ricevos sistemon de du ekvacioj, solvante, kiujn ni povos elekti tiajn valorojn de la koeficientoj.  и
и  , por kiu la valoroj de la respondaj derivaĵoj ĉe donitaj punktoj ŝanĝiĝas je tre, tre malgranda kvanto, kaj en la kazo de analiza solvo tute ne ŝanĝiĝas. Alivorte, la erara funkcio ĉe la trovitaj koeficientoj atingos minimumon, ĉar la valoroj de la partaj derivaĵoj ĉe ĉi tiuj punktoj estos egalaj al nulo.
, por kiu la valoroj de la respondaj derivaĵoj ĉe donitaj punktoj ŝanĝiĝas je tre, tre malgranda kvanto, kaj en la kazo de analiza solvo tute ne ŝanĝiĝas. Alivorte, la erara funkcio ĉe la trovitaj koeficientoj atingos minimumon, ĉar la valoroj de la partaj derivaĵoj ĉe ĉi tiuj punktoj estos egalaj al nulo.
Do, laŭ la reguloj de diferencigo, la parta deriva ekvacio de la 1-a ordo kun respekto al la koeficiento  prenos la formon:
prenos la formon:

1-a orda parta deriva ekvacio kun respekto al  prenos la formon:
prenos la formon:

Kiel rezulto, ni ricevis sistemon de ekvacioj, kiu havas sufiĉe simplan analizan solvon:
komenci{ekvacion*}
komenci{ kazoj}
na + bsumlims_{i=1}^nx_i — sumlimoj_{i=1}^ny_i = 0
sumlimoj_{i=1}^nx_i(a +bsumlimoj_{i=1}^nx_i — sumlimoj_{i=1}^ny_i) = 0
fini{ kazoj}
fino {ekvacio.*}
Antaŭ ol solvi la ekvacion, ni antaŭŝargu, kontrolu, ke la ŝarĝo estas ĝusta, kaj formatu la datumojn.
Ŝargado kaj formatado de datumoj
Oni devas rimarki, ke pro la fakto, ke por la analiza solvo, kaj poste por gradienta kaj stokastika gradienta deveno, ni uzos la kodon en du variaĵoj: uzante la bibliotekon. numpy kaj sen uzi ĝin, tiam ni bezonos taŭgan formatadon de datumoj (vidu kodon).
Kodo pri ŝarĝo kaj prilaborado de datumoj
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Bildigo
Nun, post kiam ni unue ŝarĝis la datumojn, due kontrolis la ĝustecon de la ŝarĝo kaj fine formatis la datumojn, ni faros la unuan bildigon. La metodo ofte uzata por ĉi tio estas parploto bibliotekoj Marnaskita. En nia ekzemplo, pro la limigitaj nombroj, ne utilas uzi la bibliotekon Marnaskita. Ni uzos la kutiman bibliotekon matplotlib kaj nur rigardu la disvastigon.
Diskaŝtrama kodo
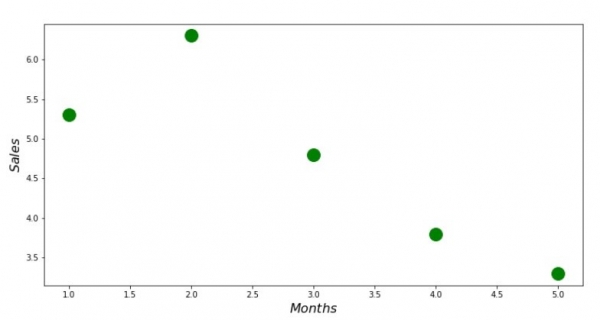
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Grafiko n-ro 1 "Dependeco de enspezo sur la monato de la jaro"
Analiza solvo
Ni uzu la plej oftajn ilojn en python kaj solvu la sistemon de ekvacioj:
komenci{ekvacion*}
komenci{ kazoj}
na + bsumlims_{i=1}^nx_i — sumlimoj_{i=1}^ny_i = 0
sumlimoj_{i=1}^nx_i(a +bsumlimoj_{i=1}^nx_i — sumlimoj_{i=1}^ny_i) = 0
fini{ kazoj}
fino {ekvacio.*}
Laŭ la regulo de Cramer ni trovos la ĝeneralan determinanton, same kiel determinantojn per  kaj per
kaj per  , post kio, dividante la determinanton per
, post kio, dividante la determinanton per  al la ĝenerala determinanto - trovi la koeficienton
al la ĝenerala determinanto - trovi la koeficienton  , simile ni trovas la koeficienton
, simile ni trovas la koeficienton  .
.
Analiza solvkodo
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Jen kion ni ricevis:

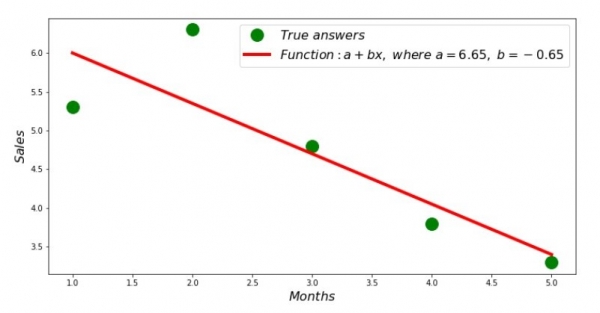
Do, la valoroj de la koeficientoj estis trovitaj, la sumo de la kvadrataj devioj estis establita. Ni desegnu rektan linion sur la disiga histogramo laŭ la trovitaj koeficientoj.
Regreslinia kodo
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Diagramo n-ro 2 "Ĝusta kaj kalkulita respondoj"
Vi povas rigardi la devian grafikon por ĉiu monato. En nia kazo, ni ne ricevos signifan praktikan valoron el ĝi, sed ni kontentigos nian scivolemon pri kiom bone la simpla lineara regresa ekvacio karakterizas la dependecon de enspezo sur la monato de la jaro.
Devio-diagramkodo
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Diagramo n-ro 3 "Devojoj, %"
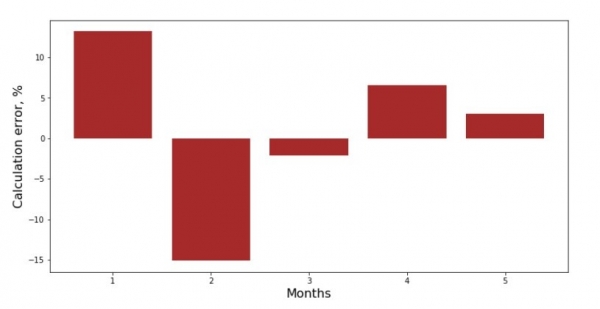
Ne perfektaj, sed ni plenumis nian taskon.
Ni skribu funkcion kiu, por determini la koeficientojn  и
и  uzas la bibliotekon numpy, pli precize, ni skribos du funkciojn: unu uzante pseŭdoinversan matricon (ne rekomendita en la praktiko, ĉar la procezo estas kompute kompleksa kaj malstabila), la alia uzante matrican ekvacion.
uzas la bibliotekon numpy, pli precize, ni skribos du funkciojn: unu uzante pseŭdoinversan matricon (ne rekomendita en la praktiko, ĉar la procezo estas kompute kompleksa kaj malstabila), la alia uzante matrican ekvacion.
Analiza Solva Kodo (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npNi komparu la tempon pasigitan por determini la koeficientojn  и
и  , konforme al la 3 prezentitaj metodoj.
, konforme al la 3 prezentitaj metodoj.
Kodo por kalkuli kalkultempon
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Kun malgranda kvanto da datumoj, "mem-skribita" funkcio aperas antaŭen, kiu trovas la koeficientojn uzante la metodon de Cramer.
Nun vi povas pluiri al aliaj manieroj trovi koeficientojn  и
и  .
.
Gradienta Deveno
Unue, ni difinu kio estas gradiento. Simple dirite, la gradiento estas segmento kiu indikas la direkton de maksimuma kresko de funkcio. Analogie kun grimpado de monto, kie la gradientvizaĝoj estas kie la plej kruta grimpado al la pinto de la monto estas. Disvolvante la ekzemplon kun la monto, ni memoras, ke fakte ni bezonas la plej krutan malsupreniron por atingi la malaltebenon kiel eble plej rapide, tio estas, la minimumon - la lokon, kie la funkcio ne pliiĝas aŭ malpliiĝas. Je ĉi tiu punkto la derivaĵo estos egala al nulo. Tial ni ne bezonas gradienton, sed kontraŭgradienton. Por trovi la kontraŭgradienton vi nur bezonas multobligi la gradienton per -1 (minus unu).
Ni atentu, ke funkcio povas havi plurajn minimumojn, kaj descendinte en unu el ili uzante la algoritmon proponitan sube, ni ne povos trovi alian minimumon, kiu eble estas pli malalta ol tiu trovita. Ni malstreĉu, ĉi tio ne estas minaco por ni! En nia kazo ni traktas ununuran minimumon, ekde nia funkcio  sur la grafeo estas regula parabolo. Kaj kiel ni ĉiuj devus tre bone scii el nia lerneja kurso pri matematiko, parabolo havas nur unu minimumon.
sur la grafeo estas regula parabolo. Kaj kiel ni ĉiuj devus tre bone scii el nia lerneja kurso pri matematiko, parabolo havas nur unu minimumon.
Post kiam ni eksciis, kial ni bezonas gradienton, kaj ankaŭ ke la gradiento estas segmento, tio estas, vektoro kun donitaj koordinatoj, kiuj estas ĝuste la samaj koeficientoj.  и
и  ni povas efektivigi gradienta descendo.
ni povas efektivigi gradienta descendo.
Antaŭ ol komenci, mi sugestas legi nur kelkajn frazojn pri la descenda algoritmo:
- Ni determinas en pseŭdo-hazarda maniero la koordinatojn de la koeficientoj
 и . En nia ekzemplo, ni difinos koeficientojn proksime de nulo. Ĉi tio estas ofta praktiko, sed ĉiu kazo povas havi sian propran praktikon.
и . En nia ekzemplo, ni difinos koeficientojn proksime de nulo. Ĉi tio estas ofta praktiko, sed ĉiu kazo povas havi sian propran praktikon. - De koordinato subtrahi la valoron de la 1-a orda parta derivaĵo ĉe la punkto . Do, se la derivaĵo estas pozitiva, tiam la funkcio pliiĝas. Tial, subtrahante la valoron de la derivaĵo, ni moviĝos en la kontraŭa direkto de kresko, tio estas, en la direkto de deveno. Se la derivaĵo estas negativa, tiam la funkcio ĉe ĉi tiu punkto malpliiĝas kaj subtrahante la valoron de la derivaĵo ni moviĝas en la direkto de deveno.
- Ni faras similan operacion kun la koordinato : subtrahi la valoron de la parta derivaĵo ĉe la punkto .
- Por ne transsalti la minimumon kaj flugi en profundan spacon, necesas agordi la paŝon en la direkto de malsupreniro. Ĝenerale, vi povus skribi tutan artikolon pri kiel ĝuste agordi la paŝon kaj kiel ŝanĝi ĝin dum la descenda procezo por redukti komputajn kostojn. Sed nun ni havas iomete alian taskon antaŭ ni, kaj ni establos la paŝograndecon uzante la sciencan metodon de "poke" aŭ, kiel oni diras en komuna lingvaĵo, empirie.
- Unufoje ni estas de la donitaj koordinatoj и subtrahi la valorojn de la derivaĵoj, ni ricevas novajn koordinatojn и . Ni faras la sekvan paŝon (subtraho), jam de la kalkulitaj koordinatoj. Kaj tiel la ciklo komenciĝas denove kaj denove, ĝis la bezonata konverĝo estas atingita.
 и
и  . En nia ekzemplo, ni difinos koeficientojn proksime de nulo. Ĉi tio estas ofta praktiko, sed ĉiu kazo povas havi sian propran praktikon.
. En nia ekzemplo, ni difinos koeficientojn proksime de nulo. Ĉi tio estas ofta praktiko, sed ĉiu kazo povas havi sian propran praktikon. subtrahi la valoron de la 1-a orda parta derivaĵo ĉe la punkto
subtrahi la valoron de la 1-a orda parta derivaĵo ĉe la punkto  . Do, se la derivaĵo estas pozitiva, tiam la funkcio pliiĝas. Tial, subtrahante la valoron de la derivaĵo, ni moviĝos en la kontraŭa direkto de kresko, tio estas, en la direkto de deveno. Se la derivaĵo estas negativa, tiam la funkcio ĉe ĉi tiu punkto malpliiĝas kaj subtrahante la valoron de la derivaĵo ni moviĝas en la direkto de deveno.
. Do, se la derivaĵo estas pozitiva, tiam la funkcio pliiĝas. Tial, subtrahante la valoron de la derivaĵo, ni moviĝos en la kontraŭa direkto de kresko, tio estas, en la direkto de deveno. Se la derivaĵo estas negativa, tiam la funkcio ĉe ĉi tiu punkto malpliiĝas kaj subtrahante la valoron de la derivaĵo ni moviĝas en la direkto de deveno.  : subtrahi la valoron de la parta derivaĵo ĉe la punkto
: subtrahi la valoron de la parta derivaĵo ĉe la punkto  .
. и
и  subtrahi la valorojn de la derivaĵoj, ni ricevas novajn koordinatojn
subtrahi la valorojn de la derivaĵoj, ni ricevas novajn koordinatojn  и
и  . Ni faras la sekvan paŝon (subtraho), jam de la kalkulitaj koordinatoj. Kaj tiel la ciklo komenciĝas denove kaj denove, ĝis la bezonata konverĝo estas atingita.
. Ni faras la sekvan paŝon (subtraho), jam de la kalkulitaj koordinatoj. Kaj tiel la ciklo komenciĝas denove kaj denove, ĝis la bezonata konverĝo estas atingita.Ĉiuj! Nun ni pretas iri serĉi la plej profundan gorĝon de la Mariana Tranĉeo. Ni komencu.
Kodo por gradienta deveno
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Ni plonĝis ĝis la fundo de la Mariana Tranĉeo kaj tie ni trovis ĉiujn samajn koeficientajn valorojn  и
и  , kio estas ĝuste kio estis atendata.
, kio estas ĝuste kio estis atendata.
Ni plu plonĝu, nur ĉi-foje, nia altamara veturilo pleniĝos per aliaj teknologioj, nome biblioteko. numpy.
Kodo por gradienta deveno (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Koeficientaj valoroj  и
и  neŝanĝebla.
neŝanĝebla.
Ni rigardu kiel la eraro ŝanĝiĝis dum gradienta malsupreniro, tio estas, kiel la sumo de kvadrataj devioj ŝanĝiĝis kun ĉiu paŝo.
Kodo por desegnado de sumoj de kvadrataj devioj
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Grafiko n-ro 4 "Sumo de kvadrataj devioj dum gradienta malsupreniro"
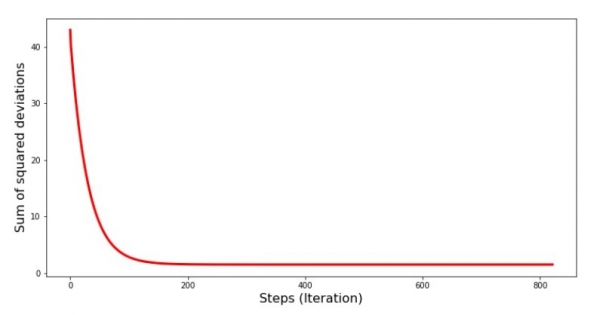
Sur la grafeo ni vidas, ke kun ĉiu paŝo la eraro malpliiĝas, kaj post certa nombro da ripetoj ni observas preskaŭ horizontalan linion.
Fine, ni taksu la diferencon en la tempo de ekzekuto de kodo:
Kodo por determini gradienta descendo kalkultempo
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Eble ni faras ion malĝustan, sed denove ĝi estas simpla "hejmskribita" funkcio, kiu ne uzas la bibliotekon. numpy superas la kalkultempon de funkcio uzante la bibliotekon numpy.
Sed ni ne staras senmove, sed iras al studado de alia ekscita maniero solvi la simplan linearan regresan ekvacion. Renkontu!
Stokasta gradienta deveno
Por rapide kompreni la principon de funkciado de stokasta gradienta deveno, estas pli bone determini ĝiajn diferencojn de ordinara gradienta deveno. Ni, en la kazo de gradienta deveno, en la ekvacioj de derivaĵoj de  и
и  uzis la sumojn de la valoroj de ĉiuj trajtoj kaj verajn respondojn disponeblajn en la specimeno (tio estas, la sumoj de ĉiuj
uzis la sumojn de la valoroj de ĉiuj trajtoj kaj verajn respondojn disponeblajn en la specimeno (tio estas, la sumoj de ĉiuj  и
и  ). En stokasta gradienta deveno, ni ne uzos ĉiujn valorojn ĉeestantajn en la specimeno, sed anstataŭe, pseŭdo-hazarde elektas la tiel nomatan specimenindekson kaj uzos ĝiajn valorojn.
). En stokasta gradienta deveno, ni ne uzos ĉiujn valorojn ĉeestantajn en la specimeno, sed anstataŭe, pseŭdo-hazarde elektas la tiel nomatan specimenindekson kaj uzos ĝiajn valorojn.
Ekzemple, se la indekso estas determinita esti numero 3 (tri), tiam ni prenas la valorojn  и
и  , tiam ni anstataŭigas la valorojn en la derivajn ekvaciojn kaj determinas novajn koordinatojn. Tiam, determininte la koordinatojn, ni denove pseŭdo-hazarde determinas la specimenan indekson, anstataŭigas la valorojn respondajn al la indekso en la partajn diferencialajn ekvaciojn kaj determinas la koordinatojn en nova maniero.
, tiam ni anstataŭigas la valorojn en la derivajn ekvaciojn kaj determinas novajn koordinatojn. Tiam, determininte la koordinatojn, ni denove pseŭdo-hazarde determinas la specimenan indekson, anstataŭigas la valorojn respondajn al la indekso en la partajn diferencialajn ekvaciojn kaj determinas la koordinatojn en nova maniero.  и
и  ktp. ĝis la konverĝo fariĝas verda. Unuavide, eble ŝajnas, ke ĉi tio tute ne povus funkcii, sed jes. Estas vere, ke indas rimarki, ke la eraro ne malpliiĝas kun ĉiu paŝo, sed certe estas tendenco.
ktp. ĝis la konverĝo fariĝas verda. Unuavide, eble ŝajnas, ke ĉi tio tute ne povus funkcii, sed jes. Estas vere, ke indas rimarki, ke la eraro ne malpliiĝas kun ĉiu paŝo, sed certe estas tendenco.
Kio estas la avantaĝoj de stokasta gradienta deveno super konvencia? Se nia specimena grandeco estas tre granda kaj mezurita en dekoj da miloj da valoroj, tiam estas multe pli facile prilabori, ekzemple, hazardan milon da ili, prefere ol la tuta specimeno. Jen kie stokastika gradienta deveno eniras. En nia kazo, kompreneble, ni ne rimarkos multe da diferenco.
Ni rigardu la kodon.
Kodo por stokasta gradienta deveno
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Ni zorge rigardas la koeficientojn kaj kaptas nin demandanta la demandon "Kiel tio povas esti?" Ni ricevis aliajn koeficientajn valorojn  и
и  . Eble stokasta gradienta deveno trovis pli optimumajn parametrojn por la ekvacio? Bedaŭrinde ne. Sufiĉas rigardi la sumon de kvadrataj devioj kaj vidi, ke kun novaj valoroj de la koeficientoj, la eraro estas pli granda. Ni ne rapidas malesperi. Ni konstruu grafeon de la erara ŝanĝo.
. Eble stokasta gradienta deveno trovis pli optimumajn parametrojn por la ekvacio? Bedaŭrinde ne. Sufiĉas rigardi la sumon de kvadrataj devioj kaj vidi, ke kun novaj valoroj de la koeficientoj, la eraro estas pli granda. Ni ne rapidas malesperi. Ni konstruu grafeon de la erara ŝanĝo.
Kodo por bildi la sumon de kvadrataj devioj en stokasta gradienta deveno
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Grafiko n-ro 5 "Sumo de kvadrataj devioj dum stokasta gradienta descendo"
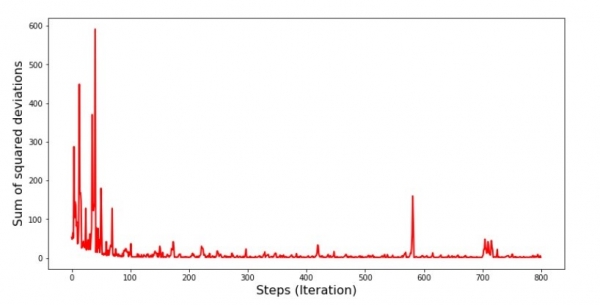
Rigardante la horaron, ĉio falas en lokon kaj nun ni riparos ĉion.
Kio do okazis? La sekvanta okazis. Kiam ni hazarde elektas monaton, tiam estas por la elektita monato, ke nia algoritmo serĉas redukti la eraron en kalkulado de enspezoj. Tiam ni elektas alian monaton kaj ripetas la kalkulon, sed ni reduktas la eraron por la dua elektita monato. Nun memoru, ke la unuaj du monatoj signife devias de la linio de la simpla lineara regresa ekvacio. Ĉi tio signifas, ke kiam iu el ĉi tiuj du monatoj estas elektita, reduktante la eraron de ĉiu el ili, nia algoritmo grave pliigas la eraron por la tuta specimeno. Kion do fari? La respondo estas simpla: vi devas redukti la malsuprenpaŝon. Post ĉio, reduktante la descendan paŝon, la eraro ankaŭ ĉesos "salti" supren kaj malsupren. Aŭ pli ĝuste, la eraro de "saltado" ne ĉesos, sed ĝi ne faros ĝin tiel rapide :) Ni kontrolu.
Kodo por ruli SGD kun pli malgrandaj pliigoj
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Grafiko n-ro 6 "Sumo de kvadrataj devioj dum stokasta gradienta malsupreniro (80 mil paŝoj)"
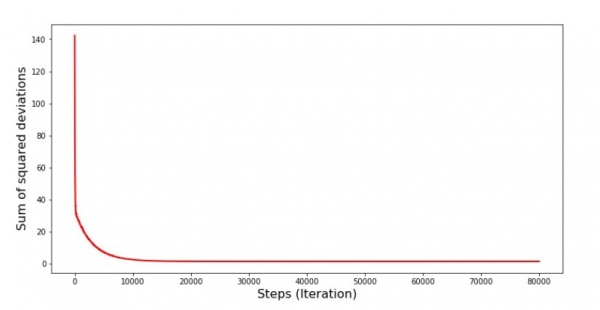
La koeficientoj pliboniĝis, sed ankoraŭ ne estas idealaj. Hipoteze, ĉi tio povas esti korektita tiel. Ni elektas, ekzemple, en la lastaj 1000 ripetoj la valorojn de la koeficientoj kun kiuj la minimuma eraro estis farita. Vere, por tio ni ankaŭ devos skribi la valorojn de la koeficientoj mem. Ni ne faros tion, sed prefere atentos la horaron. Ĝi aspektas glata kaj la eraro ŝajnas malpliiĝi egale. Fakte ĉi tio ne estas vera. Ni rigardu la unuajn 1000 ripetojn kaj komparu ilin kun la lasta.
Kodo por SGD-diagramo (unuaj 1000 paŝoj)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
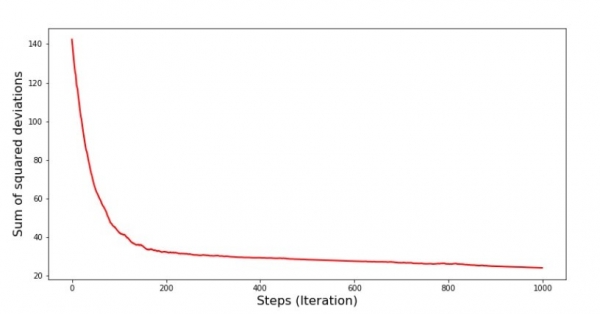
plt.show()Grafiko n-ro 7 "Sumo de kvadrataj devioj SGD (unuaj 1000 paŝoj)"
Grafiko n-ro 8 "Sumo de kvadrataj devioj SGD (lastaj 1000 paŝoj)"
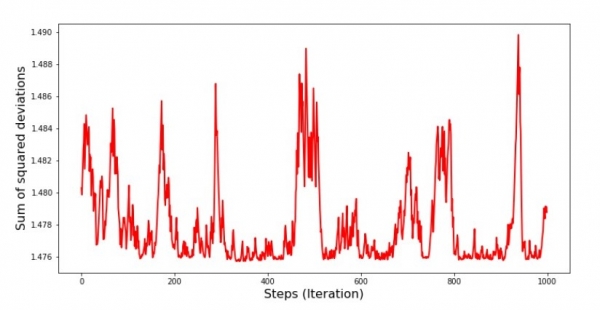
Je la komenco mem de la malsupreniro, ni observas sufiĉe unuforman kaj krutan malkreskon de eraro. En la lastaj ripetoj, ni vidas, ke la eraro iras ĉirkaŭ kaj ĉirkaŭ la valoro de 1,475 kaj en iuj momentoj eĉ egalas ĉi tiun optimuman valoron, sed tiam ĝi ankoraŭ pliiĝas... Mi ripetas, vi povas noti la valorojn de la koeficientoj  и
и  , kaj tiam elektu tiujn por kiuj la eraro estas minimuma. Tamen ni havis pli gravan problemon: ni devis fari 80 mil paŝojn (vidu kodon) por atingi valorojn proksime al optimumaj. Kaj ĉi tio jam kontraŭdiras la ideon ŝpari komputadtempon kun stokasta gradienta deveno relative al gradienta deveno. Kion oni povas korekti kaj plibonigi? Ne estas malfacile rimarki, ke en la unuaj ripetoj ni memfide malsupreniras kaj, tial, ni devus lasi grandan paŝon en la unuaj ripetoj kaj redukti la paŝon dum ni antaŭeniras. Ni ne faros tion en ĉi tiu artikolo - ĝi jam estas tro longa. Tiuj, kiuj deziras, povas pensi mem kiel fari tion, ne estas malfacile :)
, kaj tiam elektu tiujn por kiuj la eraro estas minimuma. Tamen ni havis pli gravan problemon: ni devis fari 80 mil paŝojn (vidu kodon) por atingi valorojn proksime al optimumaj. Kaj ĉi tio jam kontraŭdiras la ideon ŝpari komputadtempon kun stokasta gradienta deveno relative al gradienta deveno. Kion oni povas korekti kaj plibonigi? Ne estas malfacile rimarki, ke en la unuaj ripetoj ni memfide malsupreniras kaj, tial, ni devus lasi grandan paŝon en la unuaj ripetoj kaj redukti la paŝon dum ni antaŭeniras. Ni ne faros tion en ĉi tiu artikolo - ĝi jam estas tro longa. Tiuj, kiuj deziras, povas pensi mem kiel fari tion, ne estas malfacile :)
Nun ni faru stokastikan gradientdevenon uzante la bibliotekon numpy (kaj ni ne stumblos pri la ŝtonoj, kiujn ni antaŭe identigis)
Kodo por Stokasta Gradienta Deveno (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
La valoroj montriĝis preskaŭ la samaj kiel kiam malsupreniris sen uzi numpy. Tamen ĉi tio estas logika.
Ni eksciu kiom longe daris al ni stokastikaj gradientaj descendoj.
Kodo por determini SGD-kalkultempon (80 mil paŝoj)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Ju pli en la arbaron, des pli malhelaj la nuboj: denove, la "memskribita" formulo montras la plej bonan rezulton. Ĉio ĉi sugestas, ke devas ekzisti eĉ pli subtilaj manieroj uzi la bibliotekon numpy, kiu vere akcelas komputadoperaciojn. En ĉi tiu artikolo ni ne lernos pri ili. Estos io por pensi en via libertempo :)
Ni resumas
Antaŭ ol resumi, mi ŝatus respondi demandon, kiu plej verŝajne ekestis de nia kara leganto. Kial, fakte, tia "torturo" kun devenoj, kial ni bezonas marŝi supren kaj malsupren sur la monto (plejparte malsupren) por trovi la trezoran malaltan teron, se ni havas en niaj manoj tiel potencan kaj simplan aparaton, en la formo de analiza solvo, kiu tuj teletransportas nin al Ĝusta loko?
La respondo al ĉi tiu demando kuŝas sur la surfaco. Nun ni rigardis tre simplan ekzemplon, en kiu la vera respondo estas  dependas de unu signo
dependas de unu signo  . Vi ne ofte vidas ĉi tion en la vivo, do ni imagu, ke ni havas 2, 30, 50 aŭ pli da signoj. Ni aldonu al ĉi tio milojn, aŭ eĉ dekojn da miloj da valoroj por ĉiu atributo. En ĉi tiu kazo, la analiza solvo eble ne eltenas la teston kaj malsukcesas. Siavice, gradienta deveno kaj ĝiaj variadoj malrapide sed certe proksimigos nin al la celo - la minimumo de la funkcio. Kaj ne zorgu pri rapideco - ni verŝajne rigardos manierojn, kiuj permesos al ni agordi kaj reguligi paŝolongon (tio estas rapideco).
. Vi ne ofte vidas ĉi tion en la vivo, do ni imagu, ke ni havas 2, 30, 50 aŭ pli da signoj. Ni aldonu al ĉi tio milojn, aŭ eĉ dekojn da miloj da valoroj por ĉiu atributo. En ĉi tiu kazo, la analiza solvo eble ne eltenas la teston kaj malsukcesas. Siavice, gradienta deveno kaj ĝiaj variadoj malrapide sed certe proksimigos nin al la celo - la minimumo de la funkcio. Kaj ne zorgu pri rapideco - ni verŝajne rigardos manierojn, kiuj permesos al ni agordi kaj reguligi paŝolongon (tio estas rapideco).
Kaj nun la efektiva mallonga resumo.
Unue, mi esperas, ke la materialo prezentita en la artikolo helpos komenci "datumsciencistojn" kompreni kiel solvi simplajn (kaj ne nur) linearajn regresajn ekvaciojn.
Due, ni rigardis plurajn manierojn solvi la ekvacion. Nun, depende de la situacio, ni povas elekti tiun, kiu plej taŭgas por solvi la problemon.
Trie, ni vidis la potencon de pliaj agordoj, nome la gradienta descenda paŝolongo. Ĉi tiu parametro ne povas esti neglektita. Kiel notite supre, por redukti la koston de kalkuloj, la paŝolongo devus esti ŝanĝita dum la malsupreniro.
Kvare, en nia kazo, "hejm-skribitaj" funkcioj montris la plej bonajn temporezultojn por kalkuloj. Ĉi tio verŝajne estas pro ne la plej profesia uzo de la kapabloj de la biblioteko numpy. Sed estu kiel ajn, la sekva konkludo sugestas sin. Unuflanke, foje indas pridubi establitajn opiniojn, kaj aliflanke, ne ĉiam indas kompliki ĉion - male, foje pli simpla maniero solvi problemon estas pli efika. Kaj ĉar nia celo estis analizi tri alirojn por solvi simplan linearan regresan ekvacion, la uzo de "memskribitaj" funkcioj estis sufiĉe sufiĉa por ni.
Literaturo (aŭ io simila)
1. Lineara regreso
2. Malplej kvadrataj metodo
3. Derivaĵo
4. Gradiento
5. Gradienta deveno
6. Biblioteko NumPy
fonto: www.habr.com
