

Hemos diseñado con éxito la estructura de nuestra base de datos PostgreSQL para almacenar correspondencia, ha pasado un año, los usuarios la están llenando activamente y ahora contiene millones de registros, y... algo empezó a ralentizarse.
- Parte 2: seccionamiento “con fines de lucro”

El hecho es que A medida que crece el tamaño de la tabla, también crece la "profundidad" de los índices. - aunque sea logarítmicamente. Pero con el tiempo esto obliga al servidor a realizar las mismas tareas de lectura/escritura. procesar muchas veces más páginas de datosque al principio.
Aquí es donde viene al rescate. seccionamiento.
Permítanme señalar que no estamos hablando de fragmentación, es decir, distribuir datos entre diferentes bases de datos o servidores. Porque incluso dividiendo los datos en varios servidores, no podrá deshacerse del problema de que los índices se "hinchen" con el tiempo. Está claro que si puede permitirse el lujo de poner en funcionamiento un nuevo servidor todos los días, sus problemas ya no residirán en el plano de una base de datos específica.
No consideraremos scripts específicos para implementar la partición "en hardware", sino el enfoque en sí: qué y cómo se debe "cortar en rodajas" y a qué conduce ese deseo.
Concepto
Definamos nuestro objetivo una vez más: queremos asegurarnos de que hoy, mañana y dentro de un año, la cantidad de datos leídos por PostgreSQL durante cualquier operación de lectura/escritura siga siendo aproximadamente la misma.
Para cualquier datos acumulados cronológicamente (mensajes, documentos, registros, archivos, ...) la elección natural como clave de partición es fecha/hora del evento. En nuestro caso, tal evento es momento de enviar el mensaje.
Tenga en cuenta que los usuarios casi siempre trabajar sólo con los “últimos” esos datos: leen los mensajes más recientes, analizan los registros más recientes... No, por supuesto, pueden retroceder en el tiempo, pero lo hacen muy raramente.
A partir de estas restricciones queda claro que la solución de mensaje óptima sería secciones "diarias" - después de todo, nuestro usuario casi siempre leerá lo que le llegó "hoy" o "ayer".
Si escribimos y leemos casi sólo en una sección durante el día, esto también nos da uso más eficiente de la memoria y el disco - Dado que todos los índices de las secciones caben fácilmente en la RAM, a diferencia de los "grandes y gruesos" que aparecen en toda la tabla.
paso a paso
En general, todo lo dicho anteriormente suena como un beneficio continuo. Y es posible, pero para ello tendremos que esforzarnos mucho, porque la decisión de dividir una de las entidades conduce a la necesidad de “cortar” las entidades asociadas.
Mensaje, sus propiedades y proyecciones.
Dado que decidimos cortar los mensajes por fechas, tiene sentido dividir también las entidades-propiedades que dependen de ellos (archivos adjuntos, lista de destinatarios), y también por fecha del mensaje.
Dado que una de nuestras tareas típicas es precisamente ver los registros de mensajes (no leídos, entrantes, todos), también es lógico "dibujarlos" en particiones por fechas de mensajes.
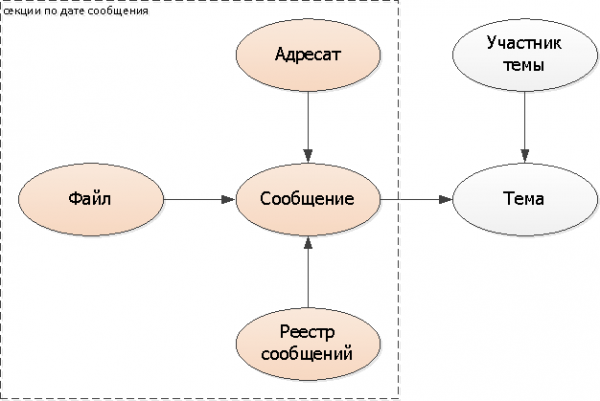
Agregamos la clave de partición (fecha del mensaje) a todas las tablas: destinatarios, archivo, registros. No es necesario agregarlo al mensaje en sí, pero use el DateTime existente.
hilos
Como hay un solo tema para varios mensajes, no hay forma de “cortarlo” en el mismo modelo, hay que apoyarse en otra cosa. En nuestro caso es ideal. fecha del primer mensaje en correspondencia — es decir, el momento de creación, de hecho, del tema.
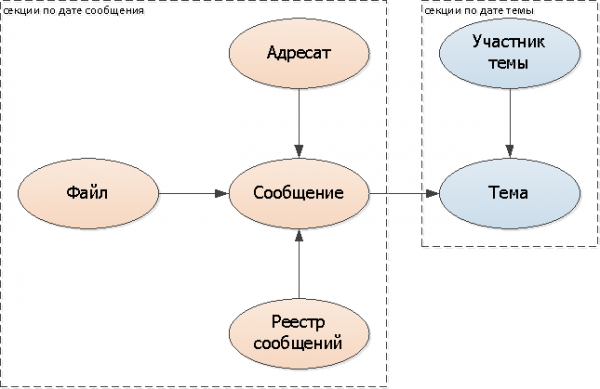
Agregue la clave de partición (fecha del tema) a todas las tablas: tema, participante.
Pero ahora tenemos dos problemas a la vez:
- ¿En qué sección debo buscar mensajes sobre el tema?
- ¿En qué sección debo buscar el tema del mensaje?
Por supuesto, podemos seguir buscando en todas las secciones, pero esto será muy triste y anulará todas nuestras ganancias. Por lo tanto, para saber dónde buscar exactamente, haremos enlaces/indicadores lógicos a las secciones:
- agregaremos en el mensaje campo de fecha del tema
- agreguemos al tema fecha del mensaje establecida esta correspondencia (puede ser una tabla separada o una serie de fechas)
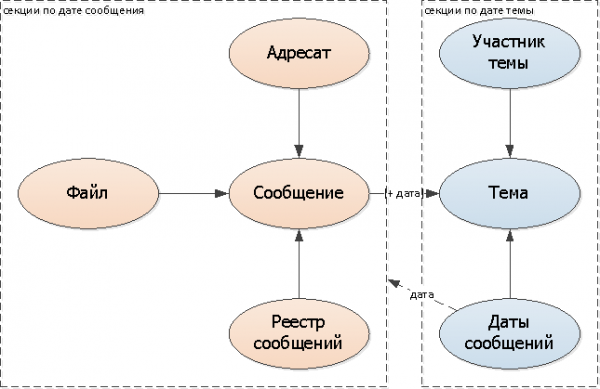
Dado que habrá pocas modificaciones en la lista de fechas de mensajes para cada correspondencia individual (después de todo, casi todos los mensajes caen en 1 o 2 días consecutivos), me centraré en esta opción.
En total, la estructura de nuestra base de datos tomó la siguiente forma, teniendo en cuenta la partición:
Tablas: RU, si tienes aversión al alfabeto cirílico en los nombres de tablas/campos, es mejor no buscar
-- секции по дате сообщения
CREATE TABLE "Сообщение_YYYYMMDD"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "ДатаТемы"
date
, "Автор"
uuid
, "ДатаВремя" -- используем как дату
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат_YYYYMMDD"(
"ДатаСообщения"
date
, "Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл_YYYYMMDD"(
"ДатаСообщения"
date
, "Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);
CREATE TABLE "РеестрСообщений_YYYYMMDD"(
"ДатаСообщения"
date
, "Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений_YYYYMMDD"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
-- секции по дате темы
CREATE TABLE "Тема_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "УчастникТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);
CREATE TABLE "ДатыСообщенийТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Дата"
date
);
Ahorra un centavo
Bueno, ¿y si usamos no? Según la distribución de los valores de los campos (a través de activadores y herencia o PARTICIÓN POR), y “manualmente” a nivel de aplicación, notará que el valor de la clave de partición ya está almacenado en el nombre de la propia tabla.
Así que si eres así ¿Estás muy preocupado por la cantidad de datos almacenados?, entonces podrá deshacerse de estos campos "adicionales" y abordar tablas específicas. Es cierto que en este caso todas las selecciones de varias secciones deberán transferirse al lado de la aplicación.
Fuente: habr.com
