

Nota. traducir: Nos complace compartir la traducción del maravilloso material del evangelista senior de tecnología de AWS, Adrian Hornsby. En términos sencillos, explica la importancia de la experimentación para mitigar los efectos de las fallas en los sistemas de TI. Probablemente ya hayas oído hablar de Chaos Monkey (o incluso hayas utilizado soluciones similares). Hoy en día, los enfoques para crear tales herramientas y su implementación en un contexto más amplio se llevan a cabo en el marco de una actividad llamada ingeniería del caos. Lea más sobre esto en este artículo.

"Pero detrás de toda esta belleza se esconde el caos y la locura". —Tanner Walling
Bomberos. Estos profesionales altamente capacitados arriesgan sus vidas todos los días combatiendo incendios. ¿Sabías que debes pasar al menos 600 horas de formación antes de convertirte en bombero? Y esto es sólo el principio. Según los informes, los bomberos entrenan hasta el 80% de su tiempo de trabajo.
¿Por qué?
Cuando un bombero está combatiendo un incendio real, necesita la adecuada intuición. Para poder desarrollarlo hay que entrenar hora tras hora, día tras día. Como dicen, la práctica hace maravillas.
“Parecen penetrar en la esencia misma del fuego; algo así como el Dr. Phil para las llamas”. —
Nota. traducir: Phillip Calvin "Phil" McGraw es un psicólogo, escritor y presentador estadounidense del popular programa de televisión Dr. Phil, en el que el presentador ofrece a sus participantes soluciones a sus problemas.
Érase una vez en Seattle
A principios de la década de 2000 , que ocupaba un puesto en Amazon con el título oficial Maestro del desastre, creó y dirigió el programa GameDay. Se basó en su experiencia como bombero. GameDay tenía como objetivo probar, capacitar y preparar los diversos sistemas, software y personas de Amazon para posibles situaciones de crisis.
Así como los bomberos desarrollan la intuición para combatir incendios, Jesse quería ayudar a su equipo a desarrollar la intuición para afrontar eventos catastróficos a gran escala.

"GameDay: Creando resiliencia a través de la destrucción" - Jesse Robbins
fue diseñado para aumentar la estabilidad del sitio minorista de Amazon al introducir deliberadamente errores en sistemas críticos.
GameDay comenzó con una serie de anuncios a toda la empresa de que se estaba planeando un simulacro, a veces a gran escala, por ejemplo, cerrando un centro de datos completo. Se proporcionaron detalles mínimos sobre la interrupción planificada y el equipo tuvo varios meses para prepararse. El objetivo principal del ejercicio era comprobar si el personal podía hacer frente a una crisis local y resolver rápidamente sus consecuencias.
Durante estos ejercicios se utilizaron herramientas y procesos específicos, como seguimiento, alertas y llamadas urgentes, para analizar e identificar errores en los procedimientos de respuesta a incidentes. Resulta que GameDay es excelente para identificar problemas arquitectónicos clásicos. A veces también fue posible detectar los llamados "defectos latentes", problemas que se manifiestan debido a las características específicas del incidente. Por ejemplo, los sistemas de gestión de incidentes críticos para el proceso de recuperación fallaron debido a efectos secundarios inesperados causados por un problema provocado por el hombre.
A medida que la empresa creció, el radio de explosión teórico de GameDay se expandió. Al final, estos ejercicios se abandonaron porque el daño potencial a la empresa si las cosas no salían según lo planeado se volvió demasiado grande. Desde entonces, el programa ha degenerado en una serie de experimentos dispares, sin impacto empresarial, para capacitar al personal en situaciones de crisis. No entraré en detalles sobre los experimentos en este artículo, pero lo haré en el futuro. Esta vez quiero discutir una idea importante que subyace a GameDay: la ingeniería de confiabilidad. (ingeniería de resiliencia), también conocida como ingeniería del caos. ().
El ascenso de los monos
Probablemente hayas oído hablar de Netflix, un proveedor de contenidos de vídeo online. Netflix comenzó a trasladarse de su propio centro de datos a la nube de AWS en agosto de 2008. La medida fue motivada por una grave corrupción en la base de datos que retrasó los envíos de DVD tres días (sí, Netflix comenzó enviando películas por correo postal). La migración a la nube fue impulsada por la necesidad de manejar cargas de transmisión mucho mayores, así como por el deseo de alejarse de una arquitectura monolítica y adoptar microservicios que puedan escalarse fácilmente según la cantidad de usuarios y el tamaño del equipo de ingeniería. El lado del consumidor del servicio de streaming se trasladó primero a AWS, entre 2010 y 2011, seguido por la TI empresarial y todas las demás estructuras. El propio centro de datos de Netflix cerró en 2016. La empresa mide la disponibilidad como una relación entre el número de intentos exitosos de estrenar una película y el número total, en lugar de una simple comparación entre el tiempo de actividad y el tiempo de inactividad, y se esfuerza por alcanzar una cifra de 0,9999 en cada región trimestralmente (es decir, a menudo tiene éxito). La arquitectura global de Netflix abarca tres regiones de AWS. Así, si surgen problemas en una de las regiones, la empresa tiene la capacidad de redirigir a los usuarios a otras.
Repetiré una de mis citas favoritas:
“Las interrupciones son inevitables; Al final, cualquier sistema colapsará con el tiempo”. —Werner Vogels
De hecho, los fallos en los sistemas distribuidos, especialmente los de gran escala, son inevitables, incluso en la nube. Sin embargo, la nube de AWS y sus primitivas de redundancia, en particular , sobre el que se basa, permite a cualquiera diseñar servicios altamente confiables.
Usando principios de redundancia (redundancia) y disminución gradual de la funcionalidad (Degradación agraciada)Netflix sin afectar a los usuarios finales.
Desde el principio, Netflix se ha adherido a los principios arquitectónicos más estrictos. Una de las primeras aplicaciones que implementaron en AWS fue su – para admitir microservicios sin estado de escalamiento automático. En otras palabras, cualquier instancia puede detenerse y reemplazarse automáticamente sin pérdida de estado. Chaos Monkey se asegura de que nadie viole este principio.
Nota. traducir: Por cierto, para Kubernetes existe un análogo llamado , cuyo desarrollo parece haberse detenido en marzo de este año.
Netflix tiene otra regla que distribuye cada servicio en tres zonas de disponibilidad. Debería seguir funcionando si sólo dos de ellos están disponibles. Para garantizar que se cumpla esta regla, deshabilita las zonas de disponibilidad. A una escala más global es capaz de cerrar una región completa de AWS para confirmar que todos los usuarios de Netflix pueden recibir servicios desde cualquiera de las tres regiones. Y realizan estas pruebas exhaustivas cada pocas semanas en producción para asegurarse de que nada se haya escapado.
Finalmente, Netflix también ha desarrollado estrategias más enfocadas. para ayudar a identificar problemas con los microservicios y la arquitectura de almacenamiento. Puedes aprender más sobre estas técnicas en el libro Chaos Engineering, que recomiendo a cualquiera interesado en este tema.
"Al realizar experimentos regulares que simulan cortes regionales, pudimos identificar varias deficiencias del sistema desde el principio y corregirlas". —
Hoy los principios de la ingeniería del caos. ; se les da la siguiente definición:
"La ingeniería del caos es un enfoque que implica realizar experimentos en un sistema de producción para garantizar su capacidad de resistir diversas perturbaciones que surgen durante la operación". —
Sin embargo, en su dedicado a la ingeniería del caos, , el ex creador de la arquitectura en la nube de Netflix que ayudó a la empresa a pasar a una infraestructura totalmente en la nube, presentó una definición alternativa de ingeniería del caos. En mi opinión, es más preciso y establecido:
"La ingeniería del caos es un experimento diseñado para mitigar los efectos del fracaso".
De hecho, sabemos que los fracasos ocurren todo el tiempo. Cuando se responden adecuadamente, no deberían afectar a los usuarios finales. El objetivo principal de la ingeniería del caos es descubrir problemas que no se abordan adecuadamente.
Condiciones necesarias para crear caos
Antes de comenzar la ingeniería del caos, asegúrese de haber realizado todo el trabajo necesario para garantizar la sostenibilidad en todos los niveles de la organización. La creación de sistemas tolerantes a fallos no se trata sólo de software. comienza en el nivel infraestructura, se propaga red y datos, afecta la estructura aplicaciones, y en última instancia cubre gente y cultura. He escrito extensamente en el pasado sobre modelos de resiliencia y fracasos (, , и ) y no me centraré en esto ahora, pero no puedo prescindir de un pequeño recordatorio.
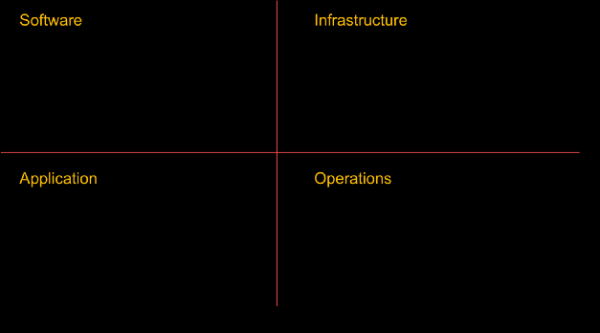
Algunos elementos necesarios antes de introducir el caos en el sistema (la lista no es exhaustiva)
Etapas de la ingeniería del caos
Es importante entender que la esencia de la ingeniería del caos NO es liberar a los monos en la naturaleza y dejar que destruyan todo, sin ningún propósito. El objetivo de esta disciplina es alterar algunos elementos de un sistema en un entorno controlado mediante experimentos bien diseñados para ver si su aplicación puede soportar condiciones turbulentas.
Para hacer esto, debe seguir un proceso formalizado y claramente definido que se describe en la siguiente figura. Puede ayudarle a pasar de comprender el estado estable de su sistema a formular una hipótesis, probarla y, finalmente, analizar la experiencia obtenida del experimento y mejorar la estabilidad del sistema en sí.
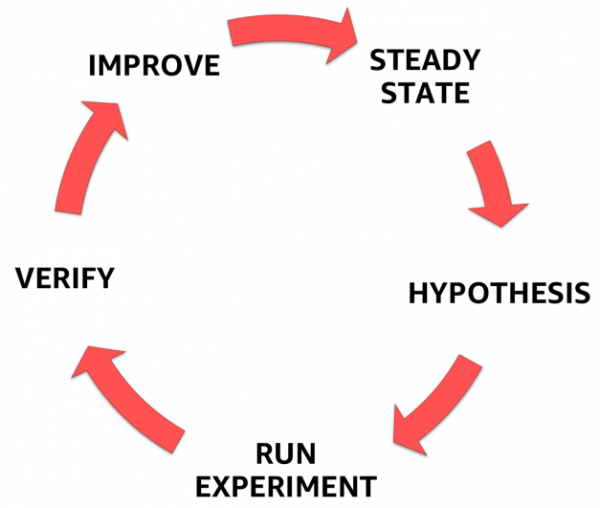
Etapas de la ingeniería del caos
1. Estado estable
Uno de los elementos más importantes de la ingeniería del caos es comprender el comportamiento del sistema en condiciones normales.
¿Por qué? Es simple: después de introducir una falla artificial, debe asegurarse de que el sistema haya regresado a un estado estable bien estudiado y que el experimento ya no interfiera con su comportamiento normal.
La clave aquí es centrarse no en los atributos internos del sistema (procesador, memoria, etc.) sino en resultados mensurables que vinculen el rendimiento con la experiencia del usuario. Para que estas salidas estén en un estado estable, el comportamiento observado del sistema debe tener un patrón predecible, pero cambiar significativamente cuando ocurre una falla en el sistema.
Teniendo en cuenta , propuesto anteriormente por Adrian Cockcroft, este estado estable cambia cuando una falla fuera de control causa un problema inesperado y señala que el experimento del caos debe ser abortado.
Como ejemplo de estados estables, tomemos la experiencia de Amazon. La empresa utiliza el volumen de pedidos como una de sus métricas de estado estable, y con razón. En 2007, Greg Linden, ex empleado de Amazon, describió cómo un experimento utilizando el método Intenté reducir el tiempo de carga de las páginas del sitio web en incrementos de 100 ms y descubrí que incluso los retrasos menores provocan una caída importante en los ingresos. Con un aumento del tiempo de carga de 100 ms, el número de pedidos (y por tanto de ventas) disminuyó un 1%. Es por eso que el número de pedidos es un excelente candidato para las métricas de estado estacionario.
Netflix utiliza una métrica del lado del servidor asociada con el inicio de la reproducción: la cantidad de clics en el botón "reproducir". Notaron un patrón en el comportamiento del indicador SPS (inicios por segundo) y sus fluctuaciones significativas cuando ocurrían fallas del sistema. La métrica se llama "El pulso de Netflix" ().
Las cifras de pedidos de Amazon y Pulse de Netflix son excelentes barómetros del estado estable porque combinan la experiencia del usuario y las métricas operativas en una métrica única, mensurable y altamente predecible.
Mide, mide y vuelve a medir
No hace falta decir que si no puede capturar adecuadamente las métricas del sistema, no podrá monitorear (ni siquiera detectar) cambios en el estado estable. Preste especial atención a la lectura de todos los parámetros/indicadores, desde la red, el hardware hasta la aplicación y las personas. Dibuja gráficas de estas medidas, incluso si no cambian con el tiempo. Te sorprenderá descubrir correlaciones que no sabías que existían.
"Haga que a los ingenieros les resulte lo más fácil posible acceder a datos que puedan calcular o representar gráficamente". —
2. Hipótesis
Una vez que nos hemos ocupado del estado estable, podemos pasar a formular una hipótesis.

- ¿Qué pasa si el motor de recomendaciones se detiene?
- ¿Qué pasa si el balanceador de carga deja de funcionar?
- ¿Qué pasa si falla el almacenamiento en caché?
- ¿Qué pasa si la latencia aumenta en 300 ms?
- ¿Qué pasa si la base de datos maestra falla?
Por supuesto, sólo se debe elegir una hipótesis y no complicarla innecesariamente. Empieza pequeño. Me gusta empezar con la hipótesis del personal. ¿Has oído hablar de factor de bus ()? El factor bus es una medida del riesgo asociado con la distribución desigual del conocimiento entre los miembros del equipo. Permite calcular el número mínimo de sus participantes, tras cuya pérdida repentina el proyecto se detendrá por falta de conocimiento o experiencia.
Muchas empresas cuentan con expertos técnicos cuya desaparición repentina (“ser atropellada por un autobús”) tendría un impacto devastador tanto en el proyecto como en el equipo. Identifique a estas personas y realice experimentos de caos con ellas: por ejemplo, quíteles sus computadoras y envíelas a casa por el día, luego observe los resultados (a menudo caóticos).
¡Haz que el problema sea común para todos!
Atraer todo el equipo para desarrollar una hipótesis. Deje que todos participen en la lluvia de ideas: propietario del producto, director técnico, desarrolladores backend y frontend, diseñadores, arquitectos, etc. Todo aquel que de una forma u otra esté relacionado con el producto.
Primero, pida a todos que escriban su propia respuesta a la pregunta "¿Qué pasaría si...?" en un trozo de papel. Verás que en la mayoría de los casos cada uno tendrá una respuesta diferente, y te darás cuenta de que algunos miembros del equipo no han pensado en absoluto en este problema hasta ahora.
Haga una pausa en este punto y analice por qué los miembros del equipo tienen ideas diferentes sobre cómo se comportará el producto en un "¿Qué pasaría si...?" Vuelva a sus especificaciones y asegúrese de que todos tengan una buena idea de lo que sucederá a continuación.
Tomemos, por ejemplo, el sitio minorista de Amazon antes mencionado. ¿Qué pasa si Comprar por categoría deja de cargarse en la página de inicio?
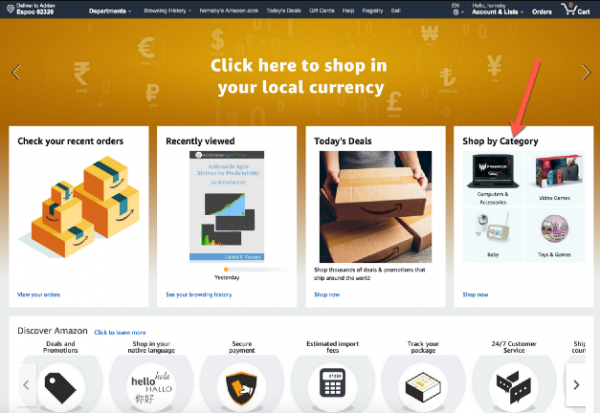
¿Debo devolver un error 404? ¿Vale la pena cargar la página y dejar un espacio vacío como en la captura de pantalla siguiente?
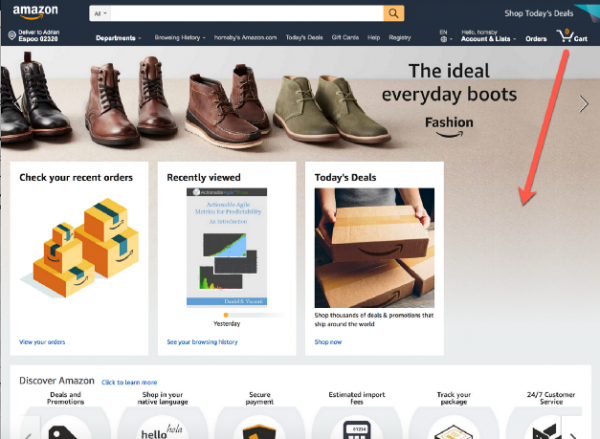
¿Vale la pena sacrificar alguna funcionalidad y, por ejemplo, permitir que la página se expanda y oculte el error?
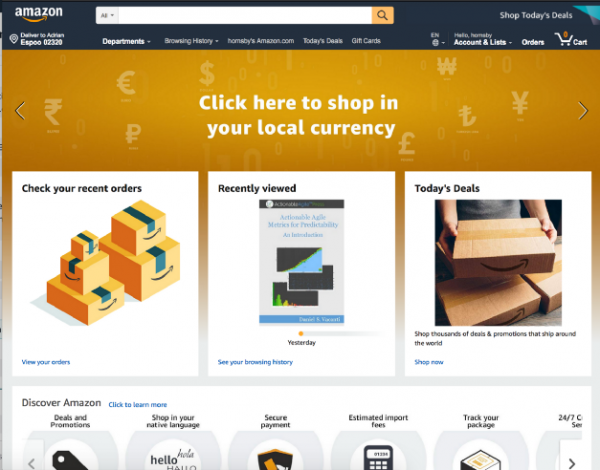
Y eso es sólo en el lado de la interfaz de usuario. ¿Qué debería pasar en el backend? ¿Se deben enviar alertas? ¿El servicio que falla debería continuar recibiendo solicitudes cada vez que el usuario carga la página de inicio, o el backend debería cortarla por completo?
Y una última cosa. ¡No formule una hipótesis que sepa de antemano que causará problemas! Experimente con partes del sistema que crea que son estables; después de todo, ese es el objetivo de la experimentación.
3. Diseñar y realizar un experimento.
- Elija una hipótesis;
- Definir el alcance del experimento;
- Identificar los indicadores relacionados que serán medidos;
- Notificar a la organización.
Hoy en día muchas personas, así como el sitio. , promover la idea de la ingeniería del caos en la producción. Si bien este debería ser el objetivo final, la mayoría de las organizaciones se sienten intimidadas por este enfoque, por lo que no es un buen punto de partida.
Para mí, la ingeniería del caos no es sólo la destrucción de diversos elementos de los sistemas de producción. Este es un viaje. Un viaje al mundo del conocimiento, indisolublemente ligado a una actividad como la destrucción de sistemas en un entorno controlado, cualquier entorno, ya sea un entorno de desarrollo local, beta, staging o prod. Interrumpa mediante experimentos bien diseñados para generar confianza en la capacidad de su aplicación para soportar condiciones turbulentas. "Construyendo confianza"Es un punto clave aquí porque es un precursor de los cambios culturales necesarios para implementar con éxito prácticas de confiabilidad e ingeniería del caos en su empresa.
Honestamente, la mayoría de los equipos aprenden mucho rompiendo cosas, incluso en un entorno que no es de producción. Sólo intenta hacer docker stop database en su entorno local y vea si puede manejar este problema sin consecuencias. Hay muchas posibilidades de que no sea así.
Detener una base de datos: ejemplo
Comience poco a poco y gradualmente desarrolle confianza dentro de su equipo y organización. La gente le dirá que "el tráfico de producción real es la única forma de capturar de manera confiable el comportamiento del sistema". Escuche, sonría y continúe haciendo lentamente lo que está haciendo. Lo peor que se puede hacer es aplicar la ingeniería del caos a la producción y fracasar estrepitosamente. Después de esto, nadie confiará en ti y te verás obligado a olvidarte de los "monos del caos" para siempre.
Primero, gánese la confianza. Demuestre a la organización y a sus colegas que sabe lo que está haciendo. Conviértete en bombero y aprende todo lo que puedas sobre las llamas antes de pasar al entrenamiento con fuego real. Gana tu credibilidad. Recordar la historia de la tortuga y la liebre? Lento y paciente siempre gana la carrera.
Uno de los puntos más importantes durante un experimento es comprender el potencial radio de daño del fallo que introduces y su minimización. Pregúntate a ti mismo las siguientes preguntas:
- ¿Cuántos clientes se verán afectados por el experimento?
- ¿Qué funcionalidad se verá afectada?
- ¿Qué lugares se verán afectados?
Piense en un "botón de interrupción" o en una forma de cancelar inmediatamente el experimento y volver a un estado estable lo más rápido posible. Me gusta realizar experimentos utilizando el llamado. Lanzamientos “canarios”. Esta técnica le permite reducir el riesgo de fallas al iniciar nuevas versiones de una aplicación en producción al implementar gradualmente cambios en un pequeño subconjunto de usuarios y luego propagarlos lentamente a toda la infraestructura y a todos los usuarios. Me encantan los lanzamientos canarios simplemente porque cumplen el principio , y el experimento en sí es bastante fácil de detener.
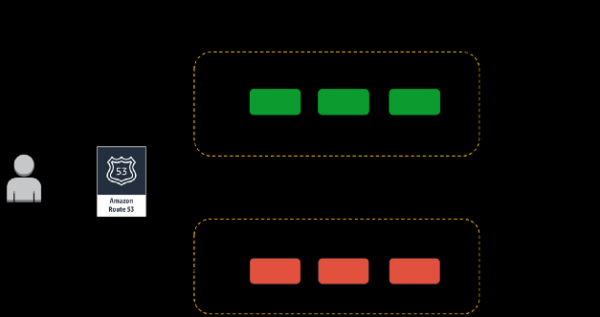
Ejemplo de implementación canary basada en DNS para experimentos de caos
Tenga cuidado con los experimentos que cambian el estado de la aplicación (caché o base de datos) o aquellos que no se pueden revertir (fácilmente o en absoluto).
Curiosamente, Adrian Cockcroft me dijo que una de las razones por las que Netflix comenzó a usar bases de datos NoSQL fue porque no tenían un esquema para cambios o reversiones, por lo que era mucho más fácil actualizar o corregir incrementalmente registros de datos individuales (es decir, eran más amigables con la ingeniería del caos). .
4. Observa y aprende
Para aprender algo nuevo y monitorear el progreso de un experimento, debe poder monitorear el rendimiento del sistema. Como se mencionó anteriormente, ¡preste la máxima atención a todo tipo de métricas y parámetros! Luego cuantifica los resultados y siempre - ¡siempre! — observe el tiempo antes de que aparezcan los primeros signos de un problema. Ha sucedido muchas veces en mi historia que los sistemas de alerta fallaron y los clientes tuitearon sobre el problema primero... créame, no querrá terminar en esa situación, así que use experimentos de caos para probar sus sistemas de monitoreo y alerta como sea posible. Bueno.
- ¿Tiempo hasta la detección?
- ¿Tiempo previo a la notificación y al inicio de acciones activas?
- ¿Tiempo hasta el aviso público?
- ¿Tiempo hasta la pérdida parcial de funcionalidad?
- ¿Cuánto dura el período de autocuración?
- ¿Tiempo hasta la recuperación total o parcial?
- ¿Tiempo hasta el fin de la crisis y el regreso a un estado estable?
Recuerde que no existe una única causa aislada de fallo. Los accidentes importantes son siempre el resultado de varios pequeños fallos que se acumulan y conducen a una crisis a gran escala.
¡Realice un análisis post mortem detallado de cada experimento!
En AWS, ponemos gran énfasis en analizar las fallas detectadas y comprender qué las causó para poder prevenir problemas similares en el futuro. Todas las conclusiones y resultados del experimento se resumen en un documento llamado Corrección de errores (COE). COE nos permite aprender de nuestros errores, ya sean fallas en una tecnología, un proceso o incluso una organización. Utilizamos este mecanismo para eliminar las causas subyacentes de las averías y mejorar continuamente.
La clave del éxito en este proceso es la apertura y la transparencia sobre lo que salió mal. Uno de los principios más importantes a la hora de redactar un buen COE es ser imparcial y evitar mencionar a personas específicas. Esto suele resultar difícil en un entorno que desalienta ese comportamiento y no permite la posibilidad de fracasar. Amazon utiliza una colección de "principios de liderazgo" () para fomentar dicho comportamiento - p.e. Autocrítica, enfoque analítico, compromiso con los más altos estándares y responsabilidad. son componentes clave del proceso COE y de la excelencia operativa en general.
El informe del COE tiene cinco secciones principales:
- ¿Qué pasó (orden cronológico)?
- ¿Cuál fue el impacto en los clientes?
- ¿Por qué ocurrió el error? ()
- ¿Qué hemos aprendido?
- ¿Cómo prevenir esto en el futuro?
Estas preguntas son más difíciles de responder de lo que parecen a primera vista, ya que es necesario asegurarse de que cada punto poco claro o desconocido se estudie cuidadosamente.
Para convertir el mecanismo COE en un proceso completo, realizamos revisiones constantemente en forma de reuniones semanales con análisis obligatorio de métricas operativas. Además, los líderes técnicos realizan revisiones de métricas semanales con todo el personal de AWS.
5. ¡Corrige y mejora!
La lección principal aquí es solucionar primero los problemas identificados durante los experimentos de caos, dándoles una mayor prioridad que el desarrollo de nuevas funciones. Involucrar a la alta dirección en este proceso e inculcarles la idea de que solucionar los problemas actuales es más importante que desarrollar nuevas funciones.
Una vez ayudé a un cliente a identificar problemas críticos de estabilidad mediante un experimento de caos, pero debido a la presión del equipo de ventas, las correcciones perdieron prioridad y todos los esfuerzos se centraron en introducir algo nuevo que fuera "críticamente importante" para los clientes. Dos semanas después, una inactividad de 16 horas obligó a la empresa a abordar los mismos problemas que identificamos durante el experimento del caos. Sólo las pérdidas resultaron ser mucho mayores.
Beneficios de la ingeniería del caos
Hay muchas ventajas. Destacaré dos, en mi opinión, los más importantes:
En primer lugar, la ingeniería del caos ayuda a descubrir problemas desconocidos en un sistema y solucionarlos antes de que provoquen un bloqueo de la producción, digamos, a las 3 a.m. de un domingo. Es decir, el aumenta la resistencia a los fallos y, de hecho, la calidad del sueño..
En segundo lugar, los experimentos de caos realizados eficazmente siempre provocan cambios más amplios (principalmente culturales) de lo esperado. Quizás el más importante de ellos sea la evolución natural hacia "inocente" (sin culpar) cultura, cuando la pregunta "¿Por qué hiciste eso?" se convierte en “¿Cómo podemos evitar esto en el futuro?” El resultado es un equipo más feliz, más eficiente, más comprometido y más exitoso. ¡Y es hermoso!
Con esto concluye la primera parte. Espero que les haya gustado. Por favor escriba reseñas, comparta opiniones o simplemente aplauda . En la siguiente parte, analizaré herramientas y técnicas para introducir fallas en los sistemas. ¡Hasta!
Para aquellos que estén ansiosos por leer la segunda parte, ofrezco mi discurso sobre el tema de la ingeniería del caos en NDC en Oslo. En él hablo de muchas de mis herramientas favoritas:

PD del traductor
La segunda parte del artículo en inglés. y también lo traduciremos si vemos suficiente interés por parte de los lectores de Habr en este material. ¡Los comentarios apropiados sobre el artículo son bienvenidos!
Lea también en nuestro blog:
- «";
- «";
- «".
Fuente: habr.com
