


¿Cómo entiende un desarrollador back-end que una consulta SQL funcionará bien en un "prod"? En empresas grandes o de rápido crecimiento, no todos tienen acceso al "producto". Y con el acceso, no todas las solicitudes se pueden verificar sin problemas, y la creación de una copia de la base de datos a menudo lleva horas. Para resolver estos problemas, creamos un DBA artificial: Joe. Ya se ha implementado con éxito en varias empresas y ayuda a más de una docena de desarrolladores.
Vídeo:

¡Hola a todos! Mi nombre es Anatoly Stansler. Trabajo para una compañia . Estamos comprometidos a acelerar el proceso de desarrollo eliminando los retrasos asociados con el trabajo de Postgres por parte de los desarrolladores, DBA y QA.
Tenemos grandes clientes y hoy parte del reportaje estará dedicado a casos que conocimos mientras trabajábamos con ellos. Hablaré sobre cómo los ayudamos a resolver problemas bastante serios.

Cuando estamos desarrollando y realizando migraciones complejas de alta carga, nos hacemos la pregunta: "¿Despegará esta migración?". Usamos revisión, usamos el conocimiento de colegas más experimentados, expertos en DBA. Y pueden decir si volará o no.
Pero tal vez sería mejor si pudiéramos probarlo nosotros mismos en copias de tamaño completo. Y hoy solo hablaremos sobre cuáles son los enfoques de prueba ahora y cómo se puede hacer mejor y con qué herramientas. También hablaremos sobre los pros y los contras de tales enfoques y lo que podemos solucionar aquí.
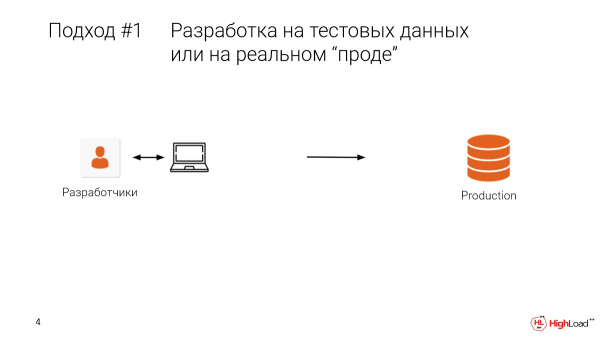
¿Quién ha hecho alguna vez índices directamente en prod o ha hecho algún cambio? Bastante. ¿Y para quién condujo esto al hecho de que se perdieron datos o hubo tiempo de inactividad? Entonces conoces este dolor. Gracias a Dios hay copias de seguridad.

El primer enfoque es probar en prod. O, cuando un desarrollador se sienta en una máquina local, tiene datos de prueba, hay algún tipo de selección limitada. Y salimos a presionar, y obtenemos esta situación.

Duele, es caro. Probablemente sea mejor no hacerlo.
¿Y cuál es la mejor manera de hacerlo?
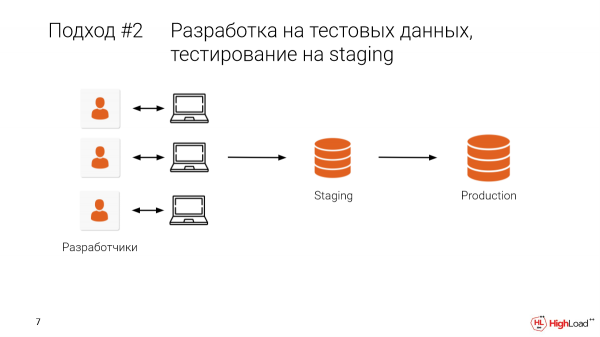
Tomemos la puesta en escena y seleccionemos alguna parte de la producción allí. O, en el mejor de los casos, hagamos un esfuerzo real, todos los datos. Y después de que lo hayamos desarrollado localmente, también verificaremos la puesta en escena.
Esto nos permitirá eliminar algunos de los errores, es decir, evitar que estén en producción.
¿Cuáles son los problemas?
- El problema es que compartimos esta puesta en escena con compañeros. Y muy a menudo sucede que haces algún tipo de cambio, bam, y no hay datos, el trabajo se va por el desagüe. La puesta en escena fue de varios terabytes. Y hay que esperar mucho tiempo para que vuelva a subir. Y decidimos finalizarlo mañana. Eso es todo, tenemos un desarrollo.
- Y, por supuesto, tenemos muchos compañeros trabajando allí, muchos equipos. Y tiene que hacerse manualmente. Y esto es inconveniente.

Y vale la pena decir que solo tenemos un intento, una oportunidad, si queremos hacer algunos cambios en la base de datos, tocar los datos, cambiar la estructura. Y si algo salió mal, si hubo un error en la migración, entonces no retrocederemos rápidamente.
Esto es mejor que el enfoque anterior, pero aún existe una alta probabilidad de que algún tipo de error pase a producción.
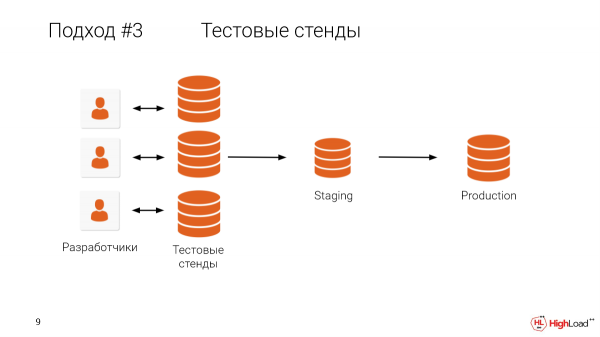
¿Qué nos impide dar a cada desarrollador un banco de pruebas, una copia a tamaño completo? Creo que está claro lo que se interpone en el camino.
¿Quién tiene una base de datos de más de un terabyte? Más de la mitad de la habitación.
Y está claro que mantener las máquinas para cada desarrollador, cuando hay una producción tan grande, es muy caro y, además, lleva mucho tiempo.
Tenemos clientes que se han dado cuenta de que es muy importante probar todos los cambios en copias de tamaño completo, pero su base de datos es inferior a un terabyte y no hay recursos para mantener un banco de pruebas para cada desarrollador. Por lo tanto, tienen que descargar los volcados localmente a su máquina y probarlos de esta manera. Se tarda mucho tiempo.

Incluso si lo hace dentro de la infraestructura, descargar un terabyte de datos por hora ya es muy bueno. Pero usan volcados lógicos, descargan localmente desde la nube. Para ellos, la velocidad es de unos 200 gigabytes por hora. Y todavía lleva tiempo dar la vuelta desde el volcado lógico, acumular los índices, etc.
Pero usan este enfoque porque les permite mantener el producto confiable.
¿Qué podemos hacer aquí? Hagamos que los bancos de pruebas sean baratos y demos a cada desarrollador su propio banco de pruebas.
Y esto es posible.
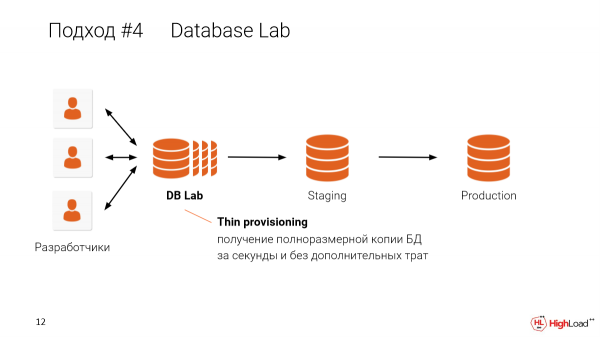
Y en este enfoque, cuando hacemos clones delgados para cada desarrollador, podemos compartirlo en una máquina. Por ejemplo, si tiene una base de datos de 10 TB y quiere dársela a 10 desarrolladores, no necesita tener XNUMX bases de datos de XNUMX TB. Solo necesita una máquina para hacer copias delgadas aisladas para cada desarrollador usando una máquina. Te diré cómo funciona un poco más tarde.

ejemplo real:
DB - 4,5 terabytes.
Podemos obtener copias independientes en 30 segundos.
No tiene que esperar a un banco de pruebas y depender de lo grande que sea. Puedes conseguirlo en segundos. Serán entornos completamente aislados, pero que comparten datos entre sí.
Esto es genial. Aquí estamos hablando de magia y un universo paralelo.

En nuestro caso, esto funciona usando el sistema OpenZFS.

OpenZFS es un sistema de archivos de copia en escritura que admite instantáneas y clones listos para usar. Es confiable y escalable. Ella es muy fácil de manejar. Literalmente se puede implementar en dos equipos.
Hay otras opciones:
lvm,
Almacenamiento (por ejemplo, Pure Storage).
El laboratorio de base de datos del que hablo es modular. Se puede implementar usando estas opciones. Pero por ahora, nos hemos enfocado en OpenZFS, porque hubo problemas específicamente con LVM.
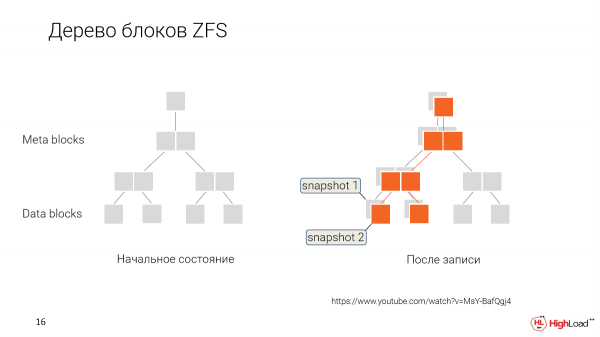
¿Cómo funciona? En lugar de sobrescribir los datos cada vez que los cambiamos, los guardamos simplemente marcando que estos nuevos datos son de un nuevo punto en el tiempo, una nueva instantánea.
Y en el futuro, cuando queramos retroceder o queramos hacer un nuevo clon de alguna versión anterior, simplemente decimos: "OK, danos estos bloques de datos que están marcados así".
Y este usuario trabajará con dicho conjunto de datos. Él los cambiará gradualmente, hará sus propias instantáneas.
Y nos ramificaremos. Cada desarrollador en nuestro caso tendrá la oportunidad de tener su propio clon que edite, y los datos que se compartan serán compartidos entre todos.
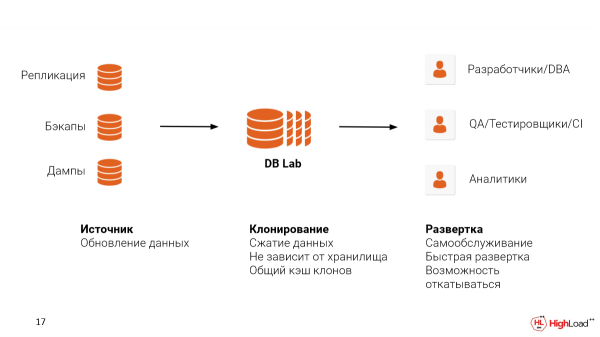
Para implementar un sistema de este tipo en casa, debe resolver dos problemas:
El primero es la fuente de los datos, de donde los tomará. Puede configurar la replicación con producción. Ya puedes usar las copias de seguridad que tienes configuradas, espero. WAL-E, WAL-G o Barman. E incluso si está utilizando algún tipo de solución en la nube como RDS o Cloud SQL, puede usar volcados lógicos. Pero aún le recomendamos que utilice copias de seguridad, porque con este enfoque también conservará la estructura física de los archivos, lo que le permitirá estar aún más cerca de las métricas que vería en producción para detectar los problemas que existen.
El segundo es donde desea alojar el laboratorio de base de datos. Podría ser Cloud, podría ser On-premise. Es importante decir aquí que ZFS admite la compresión de datos. Y lo hace bastante bien.
Imagina que por cada uno de esos clones, dependiendo de las operaciones que hagamos con la base, crecerá algún tipo de desarrollador. Para esto, el desarrollador también necesitará espacio. Pero debido al hecho de que tomamos una base de 4,5 terabytes, ZFS la comprimirá a 3,5 terabytes. Esto puede variar dependiendo de la configuración. Y todavía tenemos espacio para dev.
Tal sistema se puede utilizar para diferentes casos.
Estos son desarrolladores, DBA para validación de consultas, para optimización.
Esto se puede usar en las pruebas de control de calidad para probar una migración en particular antes de implementarla en la producción. Y también podemos plantear entornos especiales para QA con datos reales, donde puedan probar nuevas funcionalidades. Y tomará segundos en lugar de horas de espera, y tal vez días en algunos otros casos donde no se usan copias delgadas.
Y otro caso. Si la empresa no tiene un sistema de análisis configurado, podemos aislar un clon delgado de la base de productos y asignarlo a consultas largas o índices especiales que se pueden usar en análisis.

Con este enfoque:
Baja probabilidad de errores en el "prod", porque probamos todos los cambios en datos de tamaño completo.
Tenemos una cultura de prueba, porque ahora no tienes que esperar horas por tu propio stand.
Y no hay barrera, no hay espera entre pruebas. De hecho, puedes ir y verificar. Y será mejor así a medida que aceleremos el desarrollo.
Habrá menos refactorización. Menos errores terminarán en producción. Los refactorizaremos menos más adelante.
Podemos revertir cambios irreversibles. Este no es el enfoque estándar.
- Esto es beneficioso porque compartimos los recursos de los bancos de pruebas.
Ya está bien, pero ¿qué más se podría acelerar?

Gracias a dicho sistema, podemos reducir en gran medida el umbral para ingresar a dichas pruebas.
Ahora hay un círculo vicioso, cuando un desarrollador, para obtener acceso a datos reales de tamaño completo, debe convertirse en un experto. Se le debe confiar ese acceso.
Pero cómo crecer si no está allí. ¿Qué sucede si solo tiene un conjunto muy pequeño de datos de prueba disponibles? Entonces no obtendrás ninguna experiencia real.
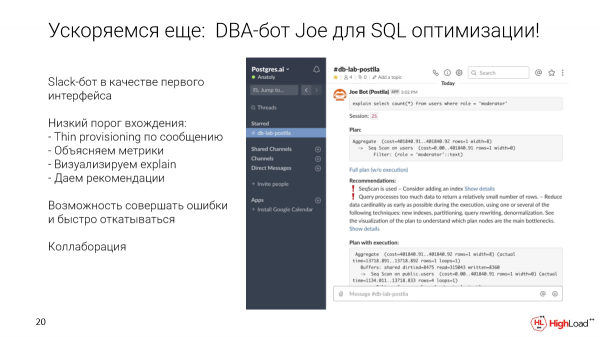
¿Cómo salir de este círculo? Como primera interfaz, conveniente para desarrolladores de cualquier nivel, elegimos el bot Slack. Pero puede ser cualquier otra interfaz.
¿Qué te permite hacer? Puede tomar una consulta específica y enviarla a un canal especial para la base de datos. Implementaremos automáticamente un clon delgado en segundos. Ejecutemos esta solicitud. Recopilamos métricas y recomendaciones. Vamos a mostrar una visualización. Y luego este clon permanecerá para que esta consulta pueda optimizarse de alguna manera, agregar índices, etc.
Y también Slack nos brinda oportunidades de colaboración listas para usar. Dado que este es solo un canal, puede comenzar a discutir esta solicitud allí mismo en el hilo para dicha solicitud, hacer ping a sus colegas, DBA que están dentro de la empresa.

Pero hay, por supuesto, problemas. Debido a que este es el mundo real, y estamos usando un servidor que aloja muchos clones a la vez, tenemos que comprimir la cantidad de memoria y potencia de CPU disponible para los clones.
Pero para que estas pruebas sean plausibles, debe resolver este problema de alguna manera.
Está claro que el punto importante es el mismo dato. Pero ya lo tenemos. Y queremos lograr la misma configuración. Y podemos dar una configuración casi idéntica.
Sería genial tener el mismo hardware que en producción, pero puede diferir.
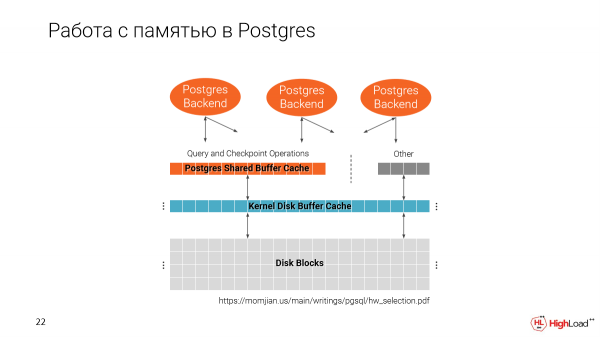
Recordemos cómo funciona Postgres con la memoria. Tenemos dos cachés. Uno del sistema de archivos y uno nativo de Postgres, es decir, Shared Buffer Cache.
Es importante tener en cuenta que el caché de búfer compartido se asigna cuando se inicia Postgres, según el tamaño que especifique en la configuración.
Y el segundo caché usa todo el espacio disponible.
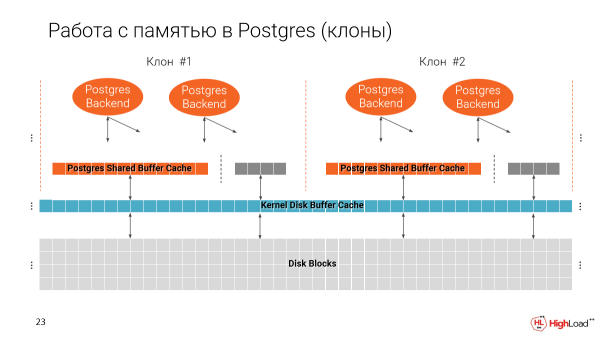
Y cuando hacemos varios clones en una máquina, resulta que gradualmente llenamos la memoria. Y en el buen sentido, Shared Buffer Cache es el 25% de la cantidad total de memoria disponible en la máquina.
Y resulta que si no cambiamos este parámetro, podremos ejecutar solo 4 instancias en una máquina, es decir, 4 de todos esos clones delgados. Y esto, por supuesto, es malo, porque queremos tener muchos más de ellos.
Pero por otro lado, Buffer Cache se usa para ejecutar consultas de índices, es decir, el plan depende de qué tan grandes sean nuestras cachés. Y si simplemente tomamos este parámetro y lo reducimos, nuestros planes pueden cambiar mucho.
Por ejemplo, si tenemos un gran caché en prod, entonces Postgres preferirá usar un índice. Y si no, habrá SeqScan. ¿Y cuál sería el punto si nuestros planes no coincidieran?
Pero aquí llegamos a la conclusión de que, de hecho, el plan en Postgres no depende del tamaño específico especificado en el búfer compartido en el plan, depende del tamaño_caché_efectivo.

El tamaño_caché_efectivo es la cantidad estimada de caché que tenemos disponible, es decir, la suma de la caché del búfer y la caché del sistema de archivos. Esto lo establece la configuración. Y esta memoria no está asignada.
Y debido a este parámetro, podemos engañar a Postgres, diciendo que en realidad tenemos muchos datos disponibles, incluso si no tenemos estos datos. Y así, los planes coincidirán completamente con la producción.
Pero esto puede afectar el tiempo. Y optimizamos las consultas por tiempo, pero es importante que el tiempo dependa de muchos factores:
Depende de la carga que esté actualmente en producción.
Depende de las características de la propia máquina.
Y este es un parámetro indirecto, pero de hecho podemos optimizar exactamente por la cantidad de datos que leerá esta consulta para obtener el resultado.
Y si desea que el tiempo esté cerca de lo que veremos en producción, entonces debemos tomar el hardware más similar y, posiblemente, aún más para que todos los clones encajen. Pero esto es un compromiso, es decir, obtendrá los mismos planes, verá cuántos datos leerá una consulta en particular y podrá concluir si esta consulta es buena (o migración) o mala, aún necesita ser optimizada .
Echemos un vistazo a cómo Joe está específicamente optimizado.
Tomemos una solicitud de un sistema real. En este caso, la base de datos es de 1 terabyte. Y queremos contar la cantidad de publicaciones nuevas que tuvieron más de 10 Me gusta.
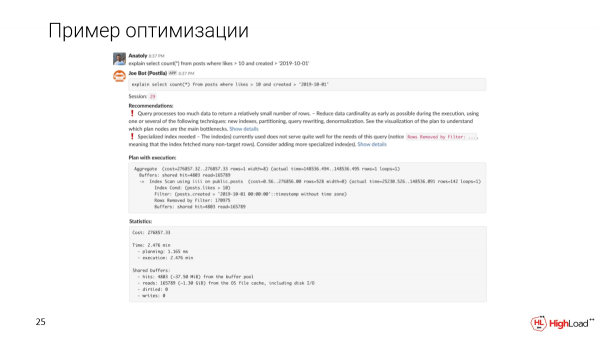
Estamos escribiendo un mensaje al canal, se ha implementado un clon para nosotros. Y veremos que dicha solicitud se completará en 2,5 minutos. Esto es lo primero que notamos.
B Joe te mostrará recomendaciones automáticas basadas en el plan y las métricas.
Veremos que la consulta procesa demasiados datos para obtener un número relativamente pequeño de filas. Y se necesita algún tipo de índice especializado, ya que notamos que hay demasiadas filas filtradas en la consulta.
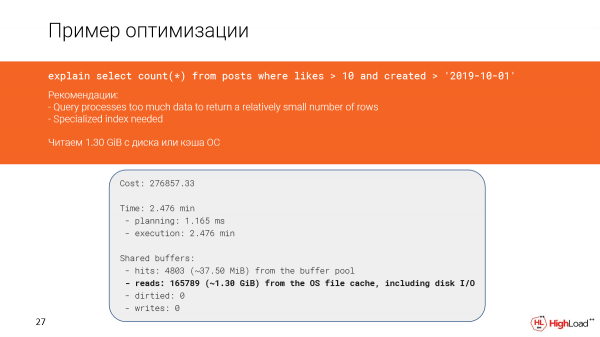
Echemos un vistazo más de cerca a lo que sucedió. Efectivamente, vemos que hemos leído casi un gigabyte y medio de datos del caché de archivos o incluso del disco. Y esto no es bueno, porque solo tenemos 142 líneas.
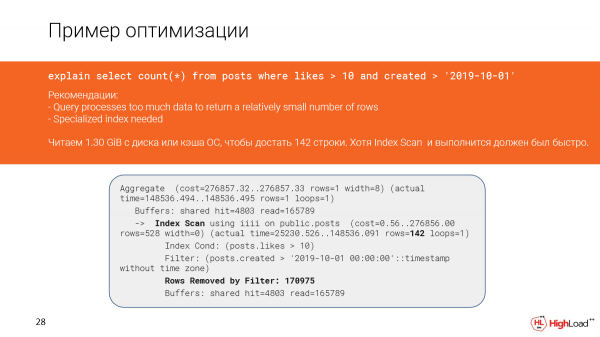
Y, al parecer, tenemos un escaneo de índice aquí y debería haber funcionado rápidamente, pero como filtramos demasiadas líneas (tuvimos que contarlas), la solicitud funcionó lentamente.
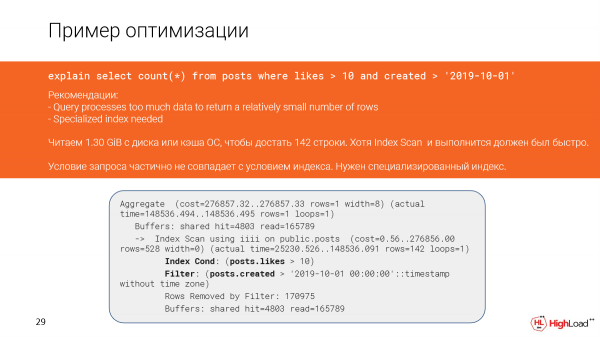
Y esto sucedió en el plan debido al hecho de que las condiciones en la consulta y las condiciones en el índice no coinciden parcialmente.
Intentemos hacer que el índice sea más preciso y veamos cómo cambia la ejecución de la consulta después de eso.
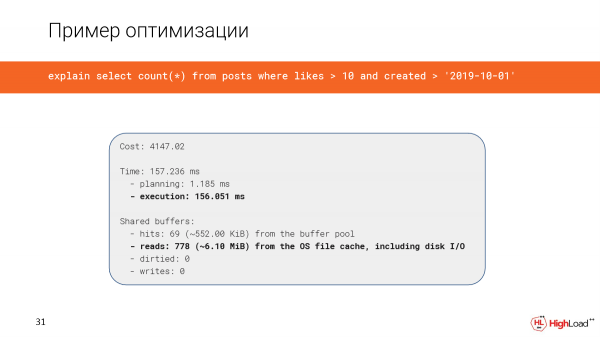
La creación del índice tomó mucho tiempo, pero ahora revisamos la consulta y vemos que el tiempo en lugar de 2,5 minutos es solo 156 milisegundos, lo cual es suficiente. Y leemos solo 6 megabytes de datos.
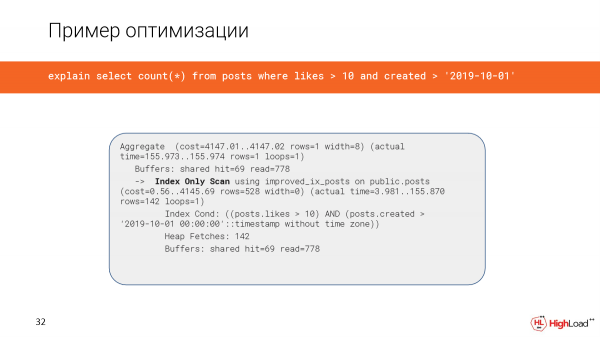
Y ahora usamos escaneo de solo índice.
Otra historia importante es que queremos presentar el plan de una manera más comprensible. Hemos implementado la visualización usando Flame Graphs.
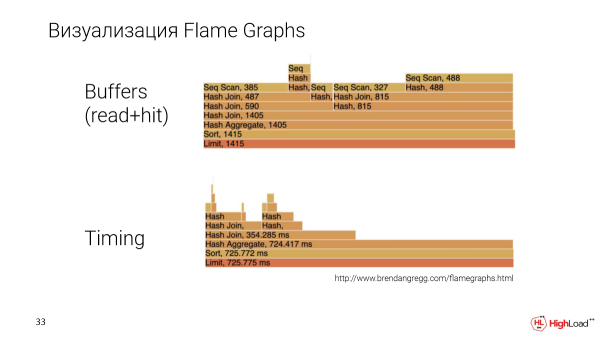
Esta es una petición diferente, más intensa. Y construimos Flame Graphs de acuerdo con dos parámetros: esta es la cantidad de datos que un nodo en particular contó en el plan y el tiempo, es decir, el tiempo de ejecución del nodo.
Aquí podemos comparar nodos específicos entre sí. Y quedará claro cuál de ellos lleva más o menos, lo que suele ser difícil de hacer en otros métodos de renderizado.
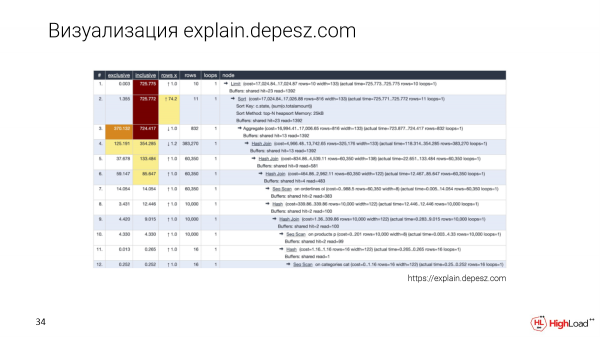
Por supuesto, todo el mundo conoce el sitio Explain.depesz.com. Una buena característica de esta visualización es que guardamos el plan de texto y también ponemos algunos parámetros básicos en una tabla para que podamos ordenar.
Y los desarrolladores que aún no han profundizado en este tema también usan Explain.depesz.com, porque les resulta más fácil darse cuenta de qué métricas son importantes y cuáles no.
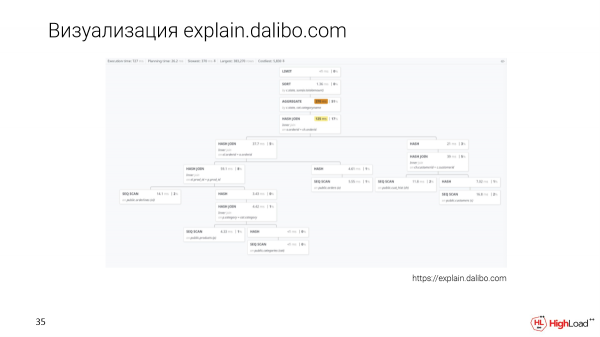
Hay un nuevo enfoque para la visualización: se trata de Explain.dalibo.com. Hacen una visualización de árbol, pero es muy difícil comparar nodos entre sí. Aquí puede comprender bien la estructura, sin embargo, si hay una solicitud grande, deberá desplazarse hacia adelante y hacia atrás, pero también una opción.
colaboración
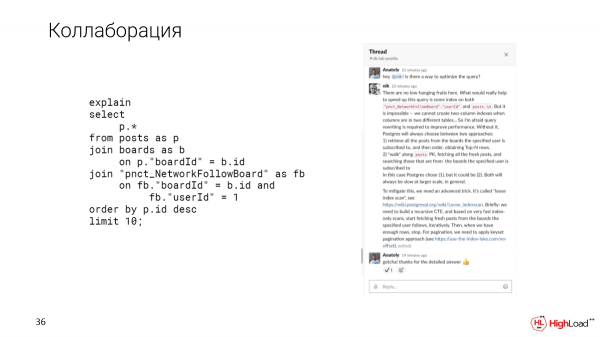
Y, como decía, Slack nos da la oportunidad de colaborar. Por ejemplo, si nos encontramos con una consulta compleja que no tiene claro cómo optimizar, podemos aclarar este problema con nuestros colegas en un hilo en Slack.

Nos parece que es importante probar con datos de tamaño completo. Para hacer esto, creamos la herramienta Update Database Lab, que está disponible en código abierto. También puedes usar el bot Joe. Puede tomarlo ahora mismo e implementarlo en su lugar. Todas las guías están disponibles allí.
También es importante señalar que la solución en sí no es revolucionaria, porque existe Delphix, pero es una solución empresarial. Está completamente cerrado, es muy caro. Nos especializamos específicamente en Postgres. Todos estos son productos de código abierto. ¡Únete a nosotros!
Aquí es donde termino. ¡Gracias!
preguntas
¡Hola! ¡Gracias por el informe! Muy interesante, especialmente para mí, porque resolví el mismo problema hace algún tiempo. Y entonces tengo una serie de preguntas. Espero conseguir al menos una parte.
Me pregunto cómo calculas el lugar para este entorno. La tecnología significa que, bajo ciertas circunstancias, tus clones pueden crecer hasta el tamaño máximo. En términos generales, si tiene una base de datos de diez terabytes y 10 clones, entonces es fácil simular una situación en la que cada clon pesa 10 datos únicos. ¿Cómo calculas este lugar, es decir, ese delta del que hablas, en el que vivirán estos clones?
Buena pregunta. Es importante hacer un seguimiento de los clones específicos aquí. Y si un clon tiene un cambio demasiado grande, comienza a crecer, primero podemos emitir una advertencia al usuario sobre esto, o detener inmediatamente este clon para que no tengamos una situación de falla.
Sí, tengo una pregunta anidada. Es decir, ¿cómo se asegura el ciclo de vida de estos módulos? Tenemos este problema y toda una historia aparte. ¿Como sucedió esto?
Hay algo de ttl para cada clon. Básicamente, tenemos un ttl fijo.
¿Qué pasa si no es un secreto?
1 hora, es decir inactivo - 1 hora. Si no se usa, lo golpeamos. Pero aquí no hay sorpresa, ya que podemos levantar el clon en segundos. Y si lo necesita de nuevo, por favor.
También me interesa la elección de tecnologías, porque, por ejemplo, usamos varios métodos en paralelo por una u otra razón. ¿Por qué ZFS? ¿Por qué no usaste LVM? Mencionaste que hubo problemas con LVM. ¿Cuáles fueron los problemas? En mi opinión, la opción más óptima es con almacenamiento, en términos de rendimiento.
¿Cuál es el principal problema con ZFS? El hecho de que debe ejecutarse en el mismo host, es decir, todas las instancias vivirán dentro del mismo sistema operativo. Y en el caso del almacenamiento, puedes conectar diferentes equipos. Y el cuello de botella son solo aquellos bloques que están en el sistema de almacenamiento. Y la cuestión de la elección de tecnologías es interesante. ¿Por qué no LVM?
Podemos hablar de LVM específicamente en la reunión. En cuanto al almacenamiento, es simplemente caro. Podemos implementar ZFS en cualquier lugar. Puedes implementarlo en tu máquina. Simplemente puedes descargar el repositorio e implementarlo. ZFS se puede instalar en casi cualquier lugar, si estamos hablando de Linux Estamos hablando de ello. Así que estamos obteniendo una solución muy flexible. Y ZFS ofrece muchas funcionalidades listas para usar. Puedes cargar tantos datos como quieras, conectar una gran cantidad de discos y tiene instantáneas. Y, como ya dije, es fácil de administrar. Por lo tanto, parece muy agradable de usar. Está probado, lleva muchos años en el mercado. Tiene una comunidad muy grande y en constante crecimiento. ZFS es una solución muy fiable.
Nikolai Samokhvalov: ¿Puedo comentar más? Mi nombre es Nikolay, trabajamos junto con Anatoly. Estoy de acuerdo en que el almacenamiento es excelente. Y algunos de nuestros clientes tienen Pure Storage, etc.
Anatoly señaló correctamente que estamos enfocados en la modularidad. Y en el futuro, puede implementar una interfaz: tomar una instantánea, hacer un clon, destruir el clon. Todo es fácil. Y el almacenamiento es genial, si lo es.
Pero ZFS está disponible para todos. DelPhix ya es suficiente, tienen 300 clientes. De estos, fortune 100 tiene 50 clientes, es decir, están dirigidos a la NASA, etc. Es hora de que todos se hagan con esta tecnología. Y es por eso que tenemos un Core de código abierto. Tenemos una parte de la interfaz que no es de código abierto. Esta es la plataforma que mostraremos. Pero queremos que sea accesible para todos. Queremos hacer una revolución para que todos los evaluadores dejen de adivinar en las computadoras portátiles. Tenemos que escribir SELECT e inmediatamente vemos que va lento. Deje de esperar a que el DBA le informe al respecto. Aquí está el objetivo principal. Y creo que todos llegaremos a esto. Y hacemos esto para que todos lo tengan. Por lo tanto, ZFS, porque estará disponible en todas partes. Gracias a la comunidad por resolver problemas y por tener una licencia de código abierto, etc.*
¡Saludos! ¡Gracias por el informe! Mi nombre es Máximo. Nos hemos ocupado de los mismos problemas. Decidieron por su cuenta. ¿Cómo se comparten los recursos entre estos clones? Cada clon puede hacer lo suyo en un momento dado: uno prueba una cosa, otro otra, alguien construye un índice, alguien tiene un trabajo pesado. Y si aún puede dividir por CPU, luego por IO, ¿cómo se divide? Esta es la primera pregunta.
Y la segunda pregunta es sobre la disimilitud de las gradas. Digamos que tengo ZFS aquí y todo está bien, pero el cliente en producción no tiene ZFS, sino ext4, por ejemplo. ¿Cómo en este caso?
Las preguntas son muy buenas. Mencioné un poco este problema con el hecho de que compartimos recursos. Y la solución es esta. Imagina que estás probando en la puesta en escena. También puede tener una situación así al mismo tiempo que alguien da una carga, otra persona. Y como resultado, ves métricas incomprensibles. Incluso el mismo problema puede ser con prod. Cuando desea verificar alguna solicitud y ve que hay algún problema con ella, funciona lentamente, entonces, de hecho, el problema no estaba en la solicitud, sino en el hecho de que hay algún tipo de carga paralela.
Y por lo tanto, es importante aquí centrarse en cuál será el plan, qué pasos daremos en el plan y cuántos datos levantaremos para esto. El hecho de que nuestros discos, por ejemplo, estén cargados con algo, afectará específicamente el tiempo. Pero podemos estimar cuán cargada está esta solicitud por la cantidad de datos. No es tan importante que al mismo tiempo haya algún tipo de ejecución.
Tengo dos preguntas. Esto es algo muy bueno. ¿Ha habido casos en los que los datos de producción son críticos, como los números de tarjetas de crédito? ¿Ya hay algo listo o es una tarea aparte? Y la segunda pregunta: ¿hay algo así para MySQL?
Sobre los datos. Haremos ofuscación hasta que lo hagamos. Pero si implementa exactamente Joe, si no da acceso a los desarrolladores, entonces no hay acceso a los datos. ¿Por qué? Porque Joe no muestra datos. Solo muestra métricas, planes y listo. Esto se hizo a propósito, porque este es uno de los requisitos de nuestro cliente. Querían poder optimizar sin dar acceso a todos.
Acerca de MySQL. Este sistema se puede usar para cualquier cosa que almacene estado en el disco. Y dado que estamos haciendo Postgres, ahora estamos haciendo toda la automatización para Postgres primero. Queremos automatizar la obtención de datos de una copia de seguridad. Estamos configurando Postgres correctamente. Sabemos cómo hacer coincidir los planes, etc.
Pero como el sistema es extensible, también se puede utilizar para MySQL. Y hay tales ejemplos. Yandex tiene algo similar, pero no lo publican en ninguna parte. Lo usan dentro de Yandex.Metrica. Y solo hay una historia sobre MySQL. Pero las tecnologías son las mismas, ZFS.
¡Gracias por el informe! También tengo un par de preguntas. Mencionó que la clonación se puede usar para análisis, por ejemplo, para crear índices adicionales allí. ¿Puedes contarnos un poco más sobre cómo funciona?
E inmediatamente haré la segunda pregunta sobre la similitud de las gradas, la similitud de los planos. El plan también depende de las estadísticas recopiladas por Postgres. ¿Cómo resuelves este problema?
Según los análisis, no hay casos específicos, porque aún no lo hemos usado, pero existe esa oportunidad. Si estamos hablando de índices, imagine que una consulta persigue una tabla con cientos de millones de registros y una columna que generalmente no está indexada en prod. Y queremos calcular algunos datos allí. Si esta solicitud se envía a prod, existe la posibilidad de que sea simple en prod, porque la solicitud se procesará allí durante un minuto.
Ok, hagamos un clon delgado que no sea terrible detenerse por unos minutos. Y para que sea más cómoda la lectura de las analíticas, añadiremos índices para aquellas columnas en las que nos interesen los datos.
¿El índice se creará cada vez?
Puede hacer que toquemos los datos, hagamos instantáneas, luego nos recuperaremos de esta instantánea y generaremos nuevas solicitudes. Es decir, puede hacerlo para que pueda generar nuevos clones con índices ya fijados.
En cuanto a la pregunta sobre las estadísticas, si restauramos desde una copia de seguridad, si hacemos una replicación, nuestras estadísticas serán exactamente las mismas. Porque tenemos toda la estructura de datos físicos, es decir, traeremos los datos tal como están con todas las métricas estadísticas también.
Aquí hay otro problema. Si usa una solución en la nube, solo hay volcados lógicos disponibles allí, porque Google, Amazon no le permiten tomar una copia física. Habrá un problema.
Gracias por la presentación. Se plantearon dos buenas preguntas sobre MySQL y la compartición de recursos. Pero, en esencia, todo se reduce a que este no es un tema para sistemas de gestión de bases de datos específicos, sino para el sistema de archivos en su conjunto. Por lo tanto, los problemas de compartición de recursos también deberían abordarse desde allí, no solo en Postgres, sino en el propio sistema de archivos. servidor, por ejemplo.
Mi pregunta es un poco diferente. Está más cerca de la base de datos de varias capas, donde hay varias capas. Por ejemplo, configuramos una actualización de imagen de diez terabytes, estamos replicando. Y usamos específicamente esta solución para bases de datos. La replicación está en curso, los datos se están actualizando. Aquí hay 100 empleados trabajando en paralelo, que constantemente están lanzando estos diferentes tiros. ¿Qué hacer? ¿Cómo asegurarse de que no haya conflicto, que lanzaron uno, y luego el sistema de archivos cambió, y todas estas imágenes se fueron?
No irán porque así es como funciona ZFS. Podemos mantener por separado en un hilo los cambios en el sistema de archivos que se producen debido a la replicación. Y conserve los clones que los desarrolladores usan en versiones anteriores de los datos. Y funciona para nosotros, todo está en orden con esto.
Resulta que la actualización se llevará a cabo como una capa adicional, y todas las imágenes nuevas ya estarán basadas en esta capa, ¿verdad?
De capas anteriores que eran de réplicas anteriores.
Las capas anteriores se caerán, pero se referirán a la capa anterior y ¿tomarán nuevas imágenes de la última capa que se recibió en la actualización?
En general sí.
Entonces como consecuencia tendremos hasta un higo de capas. ¿Y con el tiempo tendrán que ser comprimidos?
Sí, todo es correcto. Hay alguna ventana. Mantenemos instantáneas semanales. Depende del recurso que tengas. Si tiene la capacidad de almacenar una gran cantidad de datos, puede almacenar instantáneas durante mucho tiempo. No se irán solos. No habrá corrupción de datos. Si las instantáneas están desactualizadas, como nos parece, es decir, depende de la política de la empresa, simplemente podemos eliminarlas y liberar espacio.
Hola, gracias por el informe! Pregunta sobre Joe. Usted dijo que el cliente no quería dar acceso a todos a los datos. Estrictamente hablando, si una persona tiene el resultado de Explicar Analizar, entonces puede mirar los datos.
Es así. Por ejemplo, podemos escribir: "SELECCIONE DESDE DONDE correo electrónico = a eso". Es decir, no veremos los datos en sí, pero podemos ver algunas señales indirectas. Esto debe entenderse. Pero por otro lado, todo está ahí. Tenemos una auditoría de registro, tenemos control de otros colegas que también ven lo que están haciendo los desarrolladores. Y si alguien intenta hacer esto, entonces el servicio de seguridad acudirá a ellos y trabajará en este problema.
Buenas tardes ¡Gracias por el informe! Tengo una pregunta corta. Si la empresa no usa Slack, ¿hay alguna vinculación ahora o es posible que los desarrolladores implementen instancias para conectar una aplicación de prueba a las bases de datos?
Ahora hay un enlace a Slack, es decir, no hay otro mensajero, pero realmente quiero hacer soporte para otros mensajeros también. ¿Qué puedes hacer? Puede implementar DB Lab sin Joe, ir con la ayuda de la API REST o con la ayuda de nuestra plataforma y crear clones y conectarse con PSQL. Pero esto se puede hacer si está listo para dar a sus desarrolladores acceso a los datos, porque ya no habrá ninguna pantalla.
No necesito esta capa, pero necesito esa oportunidad.
Entonces sí, se puede hacer.
Fuente: habr.com
