


Ya hemos hablado de , que le permite desarrollar aplicaciones distribuidas y empaquetarlas. Todo lo que queda es aprender a implementar y administrar estas aplicaciones. ¡No te preocupes, hemos pensado en todo! Hemos reunido todas las mejores prácticas para trabajar con el cartucho Tarantool y escribimos , que descompondrá el paquete en servidores, iniciará las instancias, las combinará en un clúster, configurará la autorización, arrancará vshard, habilitará la conmutación por error automática y parcheará la configuración del clúster.
¿Interesante? Luego pregunto debajo del corte, le diremos y mostraremos todo.
Empecemos con un ejemplo
Cubriremos solo una parte de la funcionalidad de nuestro rol. Siempre puede encontrar una descripción completa de todas sus características y parámetros de entrada en . Pero es mejor intentarlo una vez que ver cien veces, así que implementemos una pequeña aplicación.
El cartucho Tarantool tiene para crear una pequeña aplicación de cartucho que almacena información sobre los clientes del banco y sus cuentas, y también proporciona una API para administrar datos a través de HTTP. Para ello, la aplicación describe dos posibles roles: api и storageque se pueden asignar a las instancias.
El cartucho en sí no dice nada sobre cómo iniciar los procesos, solo brinda la capacidad de configurar instancias que ya se están ejecutando. El usuario debe hacer el resto por sí mismo: descomponer los archivos de configuración, iniciar los servicios y configurar la topología. Pero no haremos todo esto, Ansible lo hará por nosotros.
De las palabras a los hechos.
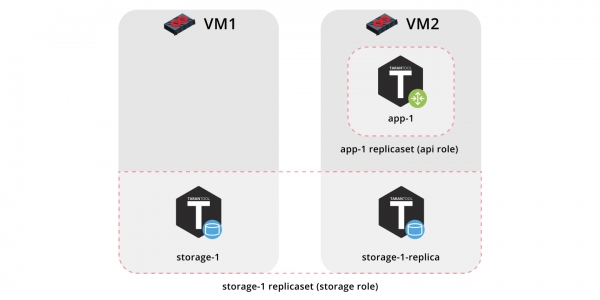
Entonces, implementemos nuestra aplicación en dos máquinas virtuales y configuremos una topología simple:
- conjunto de réplicas
app-1jugará el papelapique incluye el papelvshard-router. Solo habrá una instancia aquí. - conjunto de réplicas
storage-1implementa el rolstorage(y al mismo tiempovshard-storage), aquí agregamos dos instancias de diferentes máquinas.
Para ejecutar el ejemplo, necesitamos и (versión 2.8 o posterior).
El papel en sí es . Este es un repositorio que le permite compartir su trabajo y usar roles ya preparados.
Clona el repositorio con un ejemplo:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git
$ cd deploy-tarantool-cartridge-app && git checkout 1.0.0Levantamos máquinas virtuales:
$ vagrant upInstale la función ansible del cartucho de Tarantool:
$ ansible-galaxy install tarantool.cartridge,1.0.1Ejecute el rol instalado:
$ ansible-playbook -i hosts.yml playbook.ymlEstamos esperando el final de la ejecución del libro de jugadas, vaya a y disfruta del resultado:
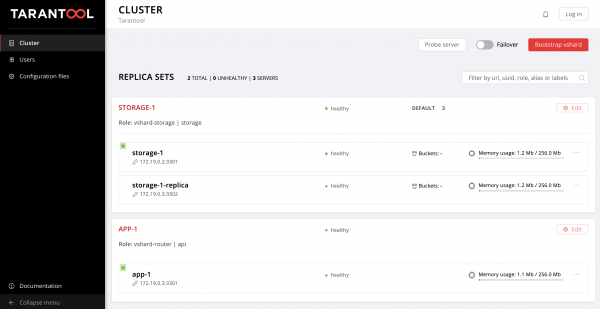
Puede verter datos. ¿Guay, verdad?
Ahora averigüemos cómo trabajar con esto y, al mismo tiempo, agreguemos otro conjunto de réplicas a la topología.
empezamos a entender
¿Entonces qué pasó?
Tenemos dos máquinas virtuales en funcionamiento y ejecutando un libro de jugadas ansible que configuró nuestro clúster. Veamos el contenido del archivo. playbook.yml:
---
- name: Deploy my Tarantool Cartridge app
hosts: all
become: true
become_user: root
tasks:
- name: Import Tarantool Cartridge role
import_role:
name: tarantool.cartridgeAquí no pasa nada interesante, empezamos el ansible-role, que se llama tarantool.cartridge.
Todo lo más importante (es decir, la configuración del clúster) se encuentra en -archivo hosts.yml:
---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:Todo lo que necesitamos es aprender a administrar instancias y conjuntos de réplicas cambiando el contenido de este archivo. A continuación, le añadiremos nuevas secciones. Para no confundirse sobre dónde agregarlos, puede echar un vistazo a la versión final de este archivo, hosts.updated.yml, que se encuentra en el repositorio de ejemplo.
Gestión de instancias
En términos de Ansible, cada instancia es un host (que no debe confundirse con un servidor de hierro), es decir, el nodo de infraestructura que administrará Ansible. Para cada host, podemos especificar parámetros de conexión (como ansible_host и ansible_user), así como la configuración de la instancia. La descripción de las instancias se encuentra en la sección hosts.
Considere la configuración de la instancia storage-1:
all:
vars:
...
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
...en una variable config especificamos los parámetros de la instancia - advertise URI и HTTP port.
A continuación se muestran los parámetros de la instancia. app-1 и storage-1-replica.
Necesitamos decirle a Ansible los parámetros de conexión para cada instancia. Parece lógico agrupar instancias en grupos de máquinas virtuales. Para hacer esto, las instancias se combinan en grupos. host1 и host2, y en cada grupo en la sección vars valores ansible_host и ansible_user para una máquina virtual. Y en la sección hosts - hosts (son instancias) que se incluyen en este grupo:
all:
vars:
...
hosts:
...
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:empezamos a cambiar hosts.yml. Agreguemos dos instancias más, storage-2-replica en la primera máquina virtual y storage-2 En el segundo:
all:
vars:
...
# INSTANCES
hosts:
...
storage-2: # <==
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica: # <==
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
...
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica: # <==
host2:
vars:
...
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2: # <==
...Ejecute el libro de jugadas ansible:
$ ansible-playbook -i hosts.yml
--limit storage-2,storage-2-replica
playbook.ymlPresta atención a la opción. --limit. Dado que cada instancia de clúster es un host en términos de Ansible, podemos especificar explícitamente qué instancias deben configurarse al ejecutar el libro de jugadas.
Volver a la interfaz de usuario web y observa nuestras nuevas instancias:
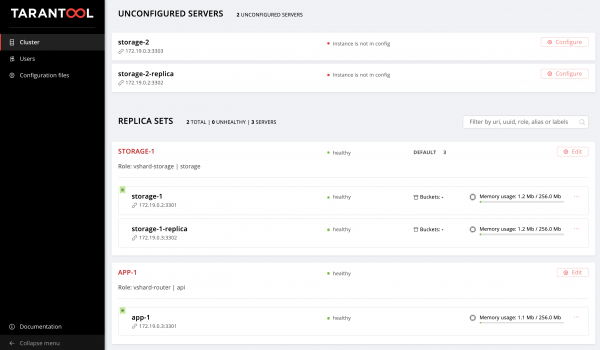
No nos dormiremos en los laureles y dominaremos el control de la topología.
Gestión de topología
Fusionemos nuestras nuevas instancias en un conjunto de réplicas storage-2. Agreguemos un nuevo grupo replicaset_storage_2 y describir en sus variables los parámetros del conjunto de réplicas por analogía con replicaset_storage_1. En la sección hosts especifique qué instancias se incluirán en este grupo (es decir, nuestro conjunto de réplicas):
---
all:
vars:
...
hosts:
...
children:
...
# GROUP INSTANCES BY REPLICA SETS
...
replicaset_storage_2: # <==
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replicaset instances
storage-2:
storage-2-replica:Comencemos el libro de jugadas de nuevo:
$ ansible-playbook -i hosts.yml
--limit replicaset_storage_2
--tags cartridge-replicasets
playbook.ymlPor opción --limit esta vez le pasamos el nombre del grupo que corresponde a nuestro replicaset.
Considere la opción tags.
Nuestro rol realiza secuencialmente varias tareas, que están marcadas con las siguientes etiquetas:
cartridge-instances: gestión de instancias (configuración, conexión a membresía);cartridge-replicasets: gestión de topología (gestión de replicaset y eliminación permanente (expulsión) de instancias del clúster);cartridge-config: administrar otros parámetros del clúster (arranque vshard, modo de conmutación por error automático, parámetros de autorización y configuración de la aplicación).
Podemos especificar explícitamente qué parte del trabajo queremos hacer, luego el rol se saltará el resto de las tareas. En nuestro caso, queremos trabajar solo con la topología, por lo que especificamos cartridge-replicasets.
Evaluemos el resultado de nuestros esfuerzos. Encontrar un nuevo conjunto de réplicas .
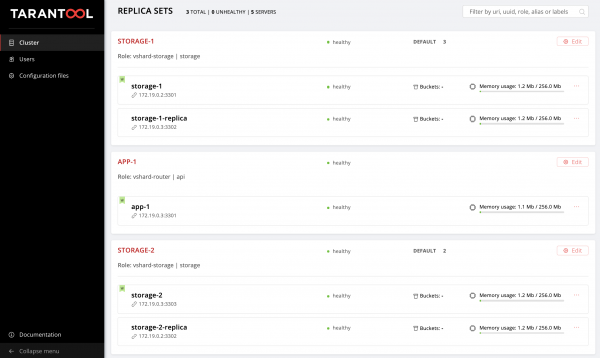
Hooray!
Experimente con la reconfiguración de instancias y conjuntos de réplicas y vea cómo cambia la topología del clúster. Puede probar diferentes escenarios operativos, por ejemplo, o aumentar memtx_memory. El rol intentará hacer esto sin reiniciar la instancia para reducir el posible tiempo de inactividad de su aplicación.
no olvides correr vagrant haltpara detener las máquinas virtuales cuando haya terminado con ellas.
¿Y qué hay debajo del capó?
Aquí hablaré más sobre lo que sucedió bajo el capó del papel ansible durante nuestros experimentos.
Echemos un vistazo a la implementación de una aplicación de cartucho paso a paso.
Instalación del paquete e inicio de instancias
Primero debe entregar el paquete al servidor e instalarlo. Ahora el rol puede funcionar con paquetes RPM y DEB.
A continuación, lanzamos las instancias. Todo es muy simple aquí: cada instancia es una systemd-servicio. Estoy hablando de un ejemplo:
$ systemctl start myapp@storage-1Este comando lanzará la instancia. storage-1 приложения myapp. La instancia lanzada buscará su в /etc/tarantool/conf.d/. Los registros de instancia se pueden ver usando journald.
archivo de la unidad /etc/systemd/system/myapp@.sevice para un servicio systemd se entregará con el paquete.
Ansible tiene módulos incorporados para instalar paquetes y administrar servicios systemd, no hemos inventado nada nuevo aquí.
Configuración de la topología del clúster
Y aquí empieza lo más interesante. De acuerdo, sería extraño molestarse con un rol especial de ansible para instalar paquetes y ejecutar systemd-servicios.
Puede configurar el clúster manualmente:
- La primera opción: abra la interfaz de usuario web y haga clic en los botones. Para un inicio único de varias instancias, es bastante adecuado.
- Segunda opción: puedes usar la API de GraphQl. Aquí ya puedes automatizar algo, por ejemplo, escribir un script en Python.
- La tercera opción (para los fuertes de espíritu): ve al servidor, conéctate a una de las instancias usando
tarantoolctl connecty realiza todas las manipulaciones necesarias con el módulo Luacartridge.
La tarea principal de nuestra invención es hacer esto, la parte más difícil del trabajo para usted.
Ansible le permite escribir su propio módulo y usarlo en un rol. Nuestro rol utiliza estos módulos para administrar los diversos componentes del clúster.
¿Cómo funciona? Describe el estado deseado del clúster en una configuración declarativa, y el rol le da a cada módulo su sección de configuración como entrada. El módulo recibe el estado actual del clúster y lo compara con la entrada. A continuación, se ejecuta un código a través del socket de una de las instancias, lo que lleva al clúster al estado deseado.
resultados
Hoy contamos y mostramos cómo implementar su aplicación en el cartucho Tarantool y configurar una topología simple. Para ello, utilizamos Ansible, una poderosa herramienta que es fácil de usar y le permite configurar simultáneamente muchos nodos de infraestructura (en nuestro caso, se trata de instancias de clúster).
Arriba, tratamos una de las muchas formas de describir la configuración del clúster usando Ansible. Una vez que sepa que está listo para continuar, aprenda para escribir libros de jugadas. Puede que le resulte más conveniente administrar la topología con group_vars и host_vars.
Muy pronto le diremos cómo eliminar (expulsar) instancias de forma permanente de la topología, arrancar vshard, administrar el modo de conmutación por error automático, configurar la autorización y parchear la configuración del clúster. Mientras tanto, puedes estudiar por tu cuenta. y experimente cambiando los parámetros del clúster.
Si algo no funciona, asegúrese nosotros sobre el problema. ¡Lo desglosaremos rápidamente!
Fuente: habr.com
