

Se sabe que la competencia del CTO se pone a prueba sólo la segunda vez que desempeña este papel. Porque una cosa es trabajar en una empresa durante varios años, evolucionar con ella y, estando en el mismo contexto cultural, poco a poco ir adquiriendo más responsabilidades. Y otra muy distinta es llegar directamente al puesto de director técnico en una empresa con un legado heredado y un montón de problemas cuidadosamente escondidos debajo de la alfombra.
En este sentido, la experiencia de León Fuego, que compartió en , no precisamente único, pero multiplicado por su experiencia y la cantidad de roles diferentes que logró probar a lo largo de 20 años, resulta muy útil. Debajo del corte hay una cronología de eventos durante 90 días y muchas historias de las que es divertido reírse cuando le suceden a otra persona, pero que no son tan divertidas de enfrentar en persona.
Leon habla ruso de forma muy colorida, así que si tienes entre 35 y 40 minutos, te recomiendo que veas el vídeo. Versión de texto para ahorrar tiempo a continuación.

La primera versión del informe era una descripción bien estructurada del trabajo con personas y procesos, que contenía recomendaciones útiles. Pero no transmitió todas las sorpresas que se encontraron en el camino. Por lo tanto, cambié el formato y presenté los problemas que surgieron frente a mí como una caja sorpresa en la nueva empresa, y los métodos para resolverlos en orden cronológico.
Un mes antes
Como muchas buenas historias, ésta comenzó con el alcohol. Estábamos sentados con amigos en un bar y, como era de esperar entre los especialistas en TI, todos lloraban por sus problemas. Uno de ellos acababa de cambiar de trabajo y hablaba de sus problemas con la tecnología, con las personas y con el equipo. Cuanto más escuchaba, más me daba cuenta de que debería contratarme, porque estos son los tipos de problemas que he estado resolviendo durante los últimos 15 años. Se lo dije y al día siguiente nos encontramos en un ambiente de trabajo. La empresa se llamaba Estrategias de Enseñanza.
Teaching Strategies es líder del mercado en currículo para niños muy pequeños desde el nacimiento hasta los tres años de edad. La empresa tradicional “de papel” ya tiene 40 años y la versión digital SaaS de la plataforma, 10. Hace relativamente poco tiempo que se inició el proceso de adaptación de la tecnología digital a los estándares de la empresa. La “nueva” versión se lanzó en 2017 y era casi como la anterior, sólo que funcionaba peor.
Lo más interesante es que el tráfico de esta empresa es muy predecible: de día en día, de año en año, se puede predecir muy claramente cuántas personas vendrán y cuándo. Por ejemplo, entre las 13 y las 15 horas todos los niños de la guardería se van a dormir y los profesores empiezan a introducir información. Y esto sucede todos los días, excepto los fines de semana, porque los fines de semana casi nadie trabaja.
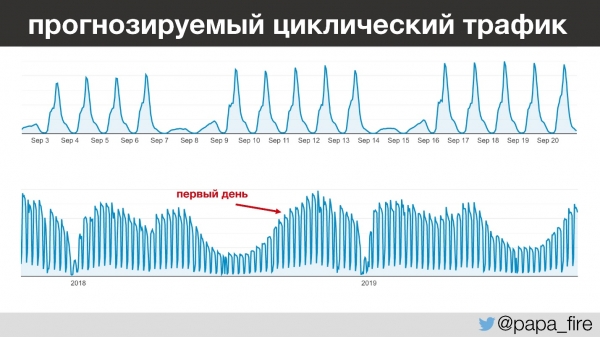
Mirando un poco hacia adelante, notaré que comencé a trabajar durante el período de mayor tráfico anual, lo cual es interesante por varias razones.
La plataforma, que parecía tener sólo 2 años, tenía un stack peculiar: ColdFusion & SQL Server de 2008. ColdFusion, si no lo sabes, y lo más probable es que no lo sepas, es un PHP empresarial que salió a mediados de los 90 y desde entonces ni siquiera he oído hablar de él. También estaban: Ruby, MySQL, PostgreSQL, Java, Go, Python. Pero el monolito principal funcionaba con ColdFusion y SQL Server.
Problemas
Cuanto más hablaba con los empleados de la empresa sobre el trabajo y los problemas encontrados, más me daba cuenta de que los problemas no eran sólo de naturaleza técnica. Bueno, la tecnología es antigua y no trabajaron en ella, pero hubo problemas con el equipo y con los procesos, y la empresa empezó a comprenderlo.
Tradicionalmente, sus técnicos se sentaban en un rincón y hacían algún tipo de trabajo. Pero cada vez más negocios empezaron a pasar por la versión digital. Por eso, en el último año antes de empezar a trabajar, aparecieron nuevos en la empresa: junta directiva, CTO, CPO y director de calidad. Es decir, la empresa comenzó a invertir en el sector tecnológico.
Las huellas de un legado pesado no se encontraban sólo en los sistemas. La empresa tenía procesos heredados, personas heredadas, cultura heredada. Todo esto había que cambiarlo. Pensé que definitivamente no sería aburrido y decidí intentarlo.
Dos dias antes
Dos días antes de comenzar un nuevo trabajo, llegué a la oficina, llené el último papeleo, conocí al equipo y descubrí que el equipo estaba luchando con un problema en ese momento. Fue que el tiempo promedio de carga de una página saltó a 4 segundos, es decir 2 veces.
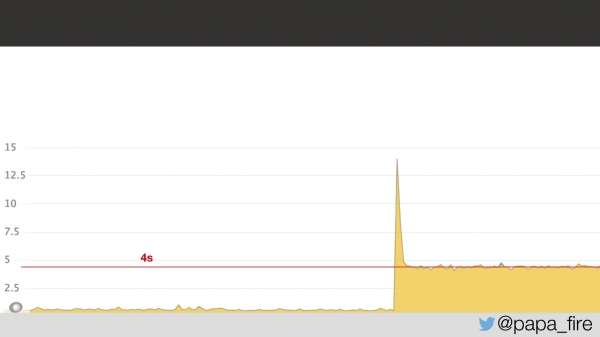
A juzgar por el gráfico, algo sucedió claramente y no está claro qué. Resultó que el problema era la latencia de la red en el centro de datos: la latencia de 5 ms en el centro de datos se convirtió en 2 s para los usuarios. No sabía por qué sucedió esto, pero de todos modos se supo que el problema estaba en el centro de datos.
Día uno
Pasaron dos días y en mi primer día de trabajo descubrí que el problema no había desaparecido.
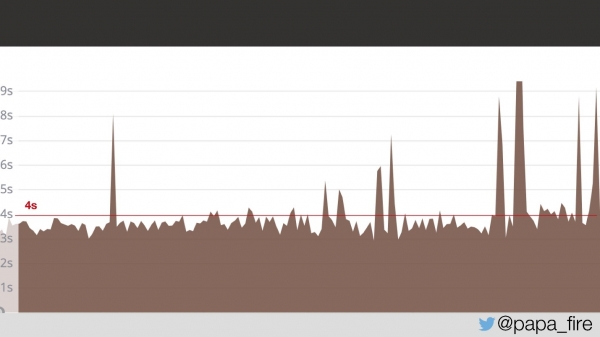
Durante dos días, las páginas de los usuarios se cargaron en promedio en 4 segundos. Pregunto si encontraron cuál es el problema.
- Sí, abrimos un ticket.
- y?
- Bueno, todavía no nos han respondido.
Entonces me di cuenta de que todo lo que me habían contado antes era sólo una pequeña punta del iceberg contra el que tenía que luchar.
Hay una buena cita que encaja muy bien con esto:
“A veces para cambiar la tecnología hay que cambiar la organización”.
Pero como comencé a trabajar en la época de mayor actividad del año, tuve que considerar ambas opciones para resolver el problema: tanto rápida como a largo plazo. Y comience con lo que es crítico en este momento.
El día tres
Así, la carga dura 4 segundos, y de 13 a 15 los picos más grandes.
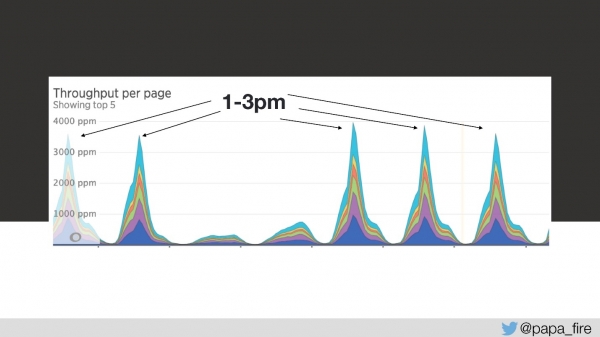
El tercer día durante este período de tiempo, la velocidad de descarga se veía así:
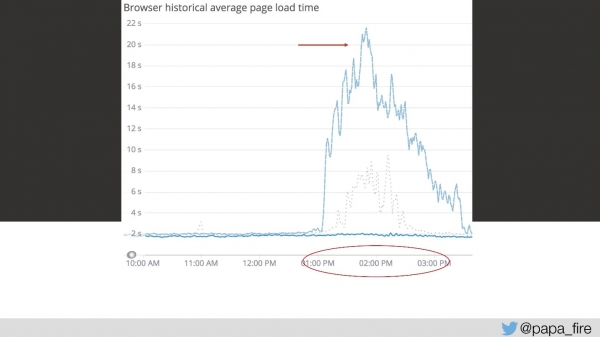
Desde mi punto de vista, nada funcionó en absoluto. Desde el punto de vista de todos los demás, iba un poco más lento de lo habitual. Pero simplemente no sucede así: es un problema grave.
Intenté convencer al equipo, a lo que respondieron que simplemente necesitaban más servidores. Esto, por supuesto, es una solución al problema, pero no siempre es la única ni la más eficaz. Pregunté por qué no había suficientes servidores y cuál era el volumen de tráfico. Extrapolé los datos y descubrí que tenemos aproximadamente 150 solicitudes por segundo, lo que, en principio, está dentro de límites razonables.
Pero no debemos olvidar que antes de obtener la respuesta correcta, es necesario hacer la pregunta correcta. Mi siguiente pregunta fue: ¿cuántos servidores frontend tenemos? La respuesta “me desconcertó un poco”: ¡teníamos 17 servidores frontend!
— Me da vergüenza preguntar, pero ¿150 dividido entre 17 da aproximadamente 8? ¿Estás diciendo que cada servidor permite 8 solicitudes por segundo, y si mañana hay 160 solicitudes por segundo, necesitaremos 2 servidores más?
Por supuesto, no necesitábamos servidores adicionales. La solución estaba en el código mismo y en la superficie:
var currentClass = classes.getCurrentClass();
return currentClass; habia una funcion getCurrentClass(), porque todo en el sitio funciona en el contexto de una clase, así es. Y para esta función en cada página había Más de 200 solicitudes.
La solución de esta manera era muy sencilla, ni siquiera tenías que reescribir nada: simplemente no volver a pedir la misma información.
if ( !isDefined("REQUEST.currentClass") ) {
var classes = new api.private.classes.base();
REQUEST.currentClass = classes.getCurrentClass();
}
return REQUEST.currentClass;Me sentí muy feliz porque decidí que apenas al tercer día había encontrado el problema principal. Por muy ingenuo que fuera, éste era sólo uno de muchos problemas.
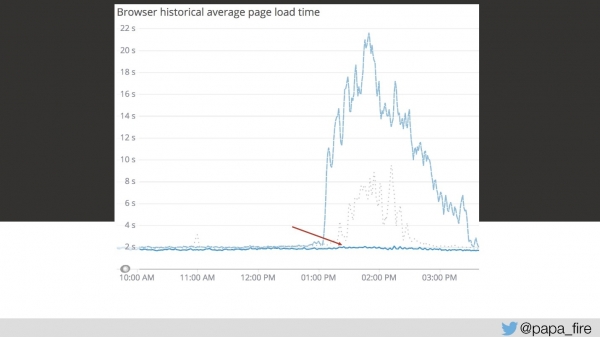
Pero al resolver este primer problema el gráfico cayó mucho más.
Al mismo tiempo, estábamos haciendo otras optimizaciones. Había muchas cosas a la vista que podían solucionarse. Por ejemplo, el mismo tercer día descubrí que, después de todo, había un caché en el sistema (al principio pensé que todas las solicitudes provenían directamente de la base de datos). Cuando pienso en caché, pienso en Redis o Memcached estándar. Pero yo era el único que pensaba eso, porque ese sistema usaba MongoDB y SQL Server para el almacenamiento en caché, el mismo desde donde se acaban de leer los datos.
Día diez
La primera semana me ocupé de problemas que debían resolverse ahora mismo. En algún momento de la segunda semana, vine por primera vez al stand-up para comunicarme con el equipo, ver qué estaba pasando y cómo iba todo el proceso.
Se volvió a descubrir algo interesante. El equipo estuvo formado por: 18 desarrolladores; 8 probadores; 3 gerentes; 2 arquitectos. Y todos participaban de rituales comunes, es decir, más de 30 personas acudían cada mañana al stand-up y contaban lo que hacían. Está claro que la reunión no duró ni 5 ni 15 minutos. Nadie escuchó a nadie porque todos trabajan en sistemas diferentes. De esta forma, 2-3 entradas por hora para una sesión de aseo ya era un buen resultado.
Lo primero que hicimos fue dividir el equipo en varias líneas de productos. Para diferentes secciones y sistemas, asignamos equipos separados, que incluían desarrolladores, evaluadores, gerentes de productos y analistas de negocios.
Como resultado obtuvimos:
- Reducción de stand-ups y mítines.
- Conocimiento temático del producto.
- Un sentido de propiedad. Cuando la gente jugaba con los sistemas todo el tiempo, sabían que lo más probable era que alguien más tuviera que trabajar con sus errores, pero no ellos mismos.
- Colaboración entre grupos. No hace falta decir que el control de calidad no se comunicaba mucho con los programadores antes, el producto hacía lo suyo, etc. Ahora tienen un punto común de responsabilidad.
Nos centramos principalmente en la eficiencia, la productividad y la calidad: estos son los problemas que intentamos resolver con la transformación del equipo.
Día once
En el proceso de cambiar la estructura del equipo, descubrí cómo contar HistoriaPuntos. 1 SP equivalía a un día y cada ticket contenía SP tanto para desarrollo como para control de calidad, es decir, al menos 2 SP.
¿Cómo descubrí esto?
Encontramos un error: en uno de los informes, donde se ingresa la fecha de inicio y finalización del período para el cual se necesita el informe, no se tiene en cuenta el último día. Es decir, en algún lugar de la solicitud no estaba <=, sino simplemente <. Me dijeron que estos son tres puntos de historia, es decir 3 días.
Después de esto nosotros:
- Se ha revisado el sistema de clasificación de Story Points. Ahora las correcciones para errores menores que pueden pasar rápidamente a través del sistema llegan al usuario más rápidamente.
- Comenzamos a fusionar tickets relacionados para desarrollo y pruebas. Anteriormente, cada ticket, cada error era un ecosistema cerrado, no ligado a nada más. Cambiar tres botones en una página podría haber generado tres tickets diferentes con tres procesos de control de calidad diferentes en lugar de una prueba automatizada por página.
- Comenzamos a trabajar con desarrolladores en un enfoque para estimar los costos laborales. Tres días para cambiar un botón no tiene gracia.
día vigésimo
A mediados del primer mes, la situación se estabilizó un poco, descubrí lo que estaba sucediendo básicamente y comencé a mirar hacia el futuro y a pensar en soluciones a largo plazo.
Objetivos a largo plazo:
- Plataforma gestionada. Cientos de solicitudes en cada página no son serias.
- Tendencias predecibles. Hubo picos de tráfico periódicos que a primera vista no se correlacionaban con otras métricas; necesitábamos entender por qué sucedía esto y aprender a predecir.
- Ampliación de plataforma. El negocio crece constantemente, cada vez llegan más usuarios y el tráfico aumenta.
En el pasado se solía decir: “¡Reescribamos todo en [lenguaje/marco], todo funcionará mejor!”
En la mayoría de los casos esto no funciona, es bueno que la reescritura funcione. Por lo tanto, necesitábamos crear una hoja de ruta: una estrategia específica que ilustrara paso a paso cómo se lograrán los objetivos comerciales (qué haremos y por qué), que:
- refleja la misión y los objetivos del proyecto;
- prioriza los objetivos principales;
- contiene un cronograma para alcanzarlos.
Antes de esto, nadie había hablado con el equipo sobre el propósito de los cambios que se estaban realizando. Esto requiere las métricas de éxito correctas. Por primera vez en la historia de la empresa establecimos KPI para el grupo técnico, y estos indicadores se vincularon a los organizacionales.
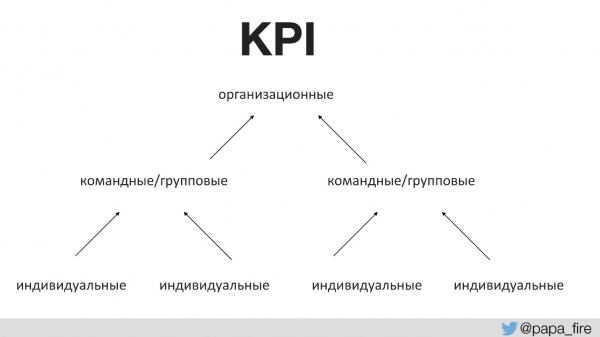
Es decir, los KPI organizacionales están respaldados por equipos y los KPI de equipo están respaldados por KPI individuales. De lo contrario, si los KPI tecnológicos no coinciden con los organizacionales, entonces todos se cubren con la manta.
Por ejemplo, uno de los KPI organizacionales es aumentar la participación de mercado a través de nuevos productos.
¿Cómo pueden apoyar el objetivo de tener más productos nuevos?
- En primer lugar, queremos dedicar más tiempo a desarrollar nuevos productos en lugar de corregir defectos. Esta es una solución lógica y fácil de medir.
- En segundo lugar, queremos apoyar un aumento en el volumen de transacciones, porque cuanto mayor sea la cuota de mercado, más usuarios y, en consecuencia, más tráfico.
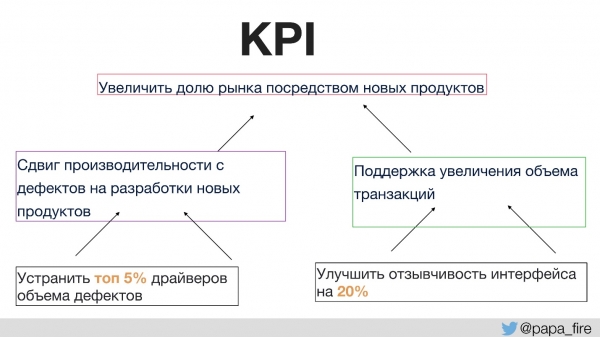
Entonces, los KPI individuales que se pueden ejecutar dentro del grupo estarán, por ejemplo, en el lugar de donde provienen los defectos principales. Si se concentra específicamente en esta sección, puede asegurarse de que haya muchos menos defectos y luego aumentará el tiempo para desarrollar nuevos productos y nuevamente para respaldar los KPI organizacionales.
Por lo tanto, cada decisión, incluida la reescritura de código, debe respaldar los objetivos específicos que la empresa nos ha fijado (crecimiento organizacional, nuevas funciones, contratación).
Durante este proceso salió a la luz algo interesante, que se convirtió en noticia no solo para los techies, sino en general en la empresa: todos los tickets deben estar enfocados en al menos un KPI. Es decir, si un producto dice que quiere crear una nueva característica, la primera pregunta debe hacerse: "¿Qué KPI admite esta característica?" Si no, lo siento, parece una característica innecesaria.
Día treinta
A finales de mes, descubrí otro matiz: nadie en mi equipo de Operaciones ha visto nunca los contratos que celebramos con los clientes. Quizás te preguntes por qué necesitas ver los contactos.
- En primer lugar, porque los SLA se especifican en los contratos.
- En segundo lugar, los SLA son todos diferentes. Cada cliente llegó con sus propios requisitos y el departamento comercial firmó sin mirar.
Otro matiz interesante es que el contrato con uno de los clientes más importantes establece que todas las versiones de software admitidas por la plataforma deben ser n-1, es decir, no la última versión, sino la penúltima.
Está claro lo lejos que estábamos del n-1 si la plataforma se basara en ColdFusion y SQL Server 2008, que ya no era compatible en julio.
Día cuarenta y cinco
A mediados del segundo mes tuve tiempo suficiente para sentarme y hacer valorstreamcartografía completamente durante todo el proceso. Estos son los pasos necesarios que se deben seguir, desde la creación de un producto hasta su entrega al consumidor, y deben describirse con el mayor detalle posible.
Divides el proceso en pequeños pedazos y ves qué está llevando demasiado tiempo, qué se puede optimizar, mejorar, etc. Por ejemplo, cuánto tiempo tarda una solicitud de producto en pasar por el proceso de preparación, cuándo llega a un ticket que un desarrollador puede aceptar, control de calidad, etc. Así que analiza cada paso individualmente en detalle y piensa en lo que se puede optimizar.
Cuando hice esto, dos cosas me llamaron la atención:
- alto porcentaje de tickets devueltos por el control de calidad a los desarrolladores;
- Las revisiones de las solicitudes de extracción tardaron demasiado.
El problema era que se trataba de conclusiones como: Parece que lleva mucho tiempo, pero no estamos seguros de cuánto tiempo.
"No se puede mejorar lo que no se puede medir".
¿Cómo justificar la gravedad del problema? ¿Se pierden días u horas?
Para medir esto, agregamos un par de pasos al proceso de Jira: "listo para desarrollo" y "listo para control de calidad" para medir cuánto tiempo espera cada ticket y cuántas veces regresa a un determinado paso.
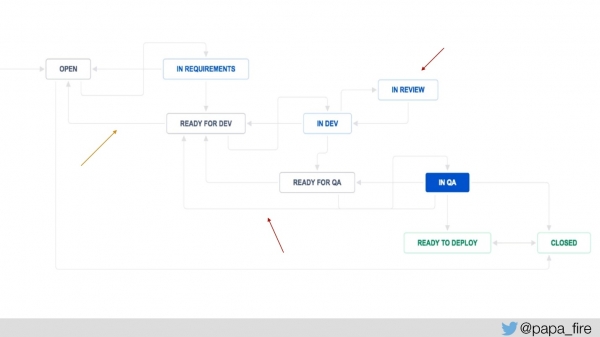
También agregamos “en revisión” para saber cuántas entradas hay en promedio para revisión, y a partir de esto ya puedes empezar a bailar. Teníamos métricas del sistema, ahora agregamos nuevas métricas y comenzamos a medir:
- Eficiencia del proceso: desempeño y planificado/entregado.
- Calidad del proceso: número de defectos, defectos de control de calidad.
Realmente ayuda entender qué va bien y qué no.
día quincuagésimo
Todo esto, por supuesto, es bueno e interesante, pero hacia finales del segundo mes sucedió algo que, en principio, era predecible, aunque no esperaba tal magnitud. La gente empezó a irse porque la alta dirección había cambiado. Nuevas personas llegaron a la dirección y empezaron a cambiarlo todo, y los viejos renunciaron. Y normalmente en una empresa que tiene varios años, todos son amigos y todos se conocen.
Esto era de esperarse, pero la magnitud de los despidos fue inesperada. Por ejemplo, en una semana dos jefes de equipo presentaron simultáneamente sus dimisiones por voluntad propia. Por lo tanto, no sólo tuve que olvidarme de otros problemas, sino también concentrarme en creando un equipo. Este es un problema largo y difícil de resolver, pero había que abordarlo porque quería salvar a las personas que quedaron (o a la mayoría de ellas). Era necesario reaccionar de alguna manera ante el hecho de que la gente se fuera para mantener la moral en el equipo.
En teoría, esto es bueno: llega una nueva persona que tiene total carta blanca, que puede evaluar las habilidades del equipo y reemplazar al personal. De hecho, no se puede simplemente incorporar gente nueva por muchas razones. Siempre se necesita equilibrio.
- Viejo y nuevo. Necesitamos conservar a personas mayores que puedan cambiar y apoyar la misión. Pero al mismo tiempo, necesitamos traer sangre nueva, hablaremos de eso un poco más adelante.
- Experiencia. Hablé mucho con buenos jóvenes que estaban ansiosos y querían trabajar con nosotros. Pero no pude encargarme de ellos porque no había suficientes personas mayores para apoyar a los jóvenes y actuar como mentores para ellos. Era necesario reclutar primero a los mejores y solo después a los jóvenes.
- Zanahoria y palo.
No tengo una buena respuesta a la pregunta de cuál es el equilibrio correcto, cómo mantenerlo, cuántas personas conservar y cuánto presionar. Este es un proceso puramente individual.
día cincuenta y uno
Comencé a mirar de cerca al equipo para entender quién tenía y una vez más recordé:
"La mayoría de los problemas son problemas de personas".
Descubrí que el equipo como tal, tanto de desarrollo como de operaciones, tiene tres grandes problemas:
- Satisfacción con el estado actual de las cosas.
- Falta de responsabilidad - porque nunca nadie ha aprovechado los resultados del trabajo de los artistas para influir en el negocio.
- Miedo al cambio.

El cambio siempre te saca de tu zona de confort, y cuanto más jóvenes son, más les disgusta el cambio porque no entienden por qué ni cómo. La respuesta más común que he escuchado es: "Nunca hemos hecho eso". Además, llegó al punto de ser completamente absurdo: el más mínimo cambio no podía producirse sin que alguien se indignara. Y por mucho que los cambios afectaran su trabajo, la gente decía: “No, ¿por qué? Esto no funcionará."
Pero no se puede mejorar sin cambiar nada.
Tuve una conversación absolutamente absurda con un empleado, le conté mis ideas de optimización, a lo que me dijo:
- ¡Oh, no viste lo que tuvimos el año pasado!
- ¿Y qué?
"Ahora es mucho mejor de lo que era".
- Entonces, ¿no se puede mejorar?
Por que
Buena pregunta: ¿por qué? Es como si ahora fuera mejor de lo que era, entonces todo está suficientemente bien. Esto conduce a una falta de responsabilidad, lo que en principio es absolutamente normal. Como dije, el grupo técnico estuvo un poco al margen. La empresa creía que deberían existir, pero nadie nunca estableció los estándares. El soporte técnico nunca vio el SLA, por lo que fue bastante "aceptable" para el grupo (y esto fue lo que más me llamó la atención):
- 12 segundos de carga;
- 5 a 10 minutos de tiempo de inactividad en cada lanzamiento;
- La resolución de problemas críticos lleva días y semanas;
- Falta de personal de guardia 24x7 / de guardia.
Nadie ha intentado nunca preguntar por qué no lo hacemos mejor y nadie se ha dado cuenta de que no tiene por qué ser así.
Como beneficio adicional, hubo un problema más: falta de experiencia. Los mayores se fueron y el equipo joven restante creció bajo el régimen anterior y fue envenenado por él.
Además de todo esto, la gente también tenía miedo de fracasar y parecer incompetente. Esto se expresa en el hecho de que, en primer lugar, bajo ninguna circunstancia pidió ayuda. Cuántas veces hemos hablado en grupo e individualmente y he dicho: “Haz una pregunta si no sabes hacer algo”. Tengo confianza en mí mismo y sé que puedo solucionar cualquier problema, pero llevará tiempo. Por lo tanto, si puedo preguntarle a alguien que sepa solucionarlo en 10 minutos, se lo preguntaré. Cuanta menos experiencia tengas, más miedo tendrás de preguntar porque crees que te considerarán un incompetente.
Este miedo a hacer preguntas se manifiesta de maneras interesantes. Por ejemplo, preguntas: "¿Cómo te va con esta tarea?" - “Faltan un par de horas, ya estoy terminando”. Al día siguiente vuelves a preguntar y obtienes la respuesta de que todo está bien, pero hubo un problema, definitivamente estará listo al final del día. Pasa otro día, y hasta que te clavan contra la pared y te obligan a hablar con alguien, esto continúa. Una persona quiere resolver un problema por sí misma; cree que si no lo resuelve por sí misma, será un gran fracaso.
Es precisamente eso los desarrolladores inflaron las estimaciones. Fue esa misma anécdota, cuando estaban discutiendo una determinada tarea, me dieron tal cifra que me sorprendió mucho. A lo que me dijeron que en las estimaciones del desarrollador, el desarrollador incluye el tiempo que tardará el control de calidad en devolver el ticket, porque allí encontrarán errores, y el tiempo que tardará el PR, y el tiempo que tardarán las personas que deben revisar. estará ocupado, es decir, todo lo que sea posible.
En segundo lugar, las personas que temen parecer incompetentes analizar demasiado. Cuando dices qué es exactamente lo que hay que hacer, comienza: "No, ¿y si lo pensamos aquí?" En este sentido, nuestra empresa no es única, es un problema común entre los jóvenes.
En respuesta, introduje las siguientes prácticas:
- Regla 30 minutos. Si no puedes resolver el problema en media hora, pídele ayuda a alguien. Esto funciona con distintos grados de éxito, porque la gente todavía no pregunta, pero al menos el proceso ha comenzado.
- Eliminar todo menos la esencia., al estimar la fecha límite para completar una tarea, es decir, considere solo cuánto tiempo llevará escribir el código.
- El aprendizaje permanente para aquellos que analizan demasiado. Es simplemente un trabajo constante con la gente.
Día sexagésimo
Mientras hacía todo esto, llegó el momento de calcular el presupuesto. Por supuesto, encontré muchas cosas interesantes sobre dónde gastamos nuestro dinero. Por ejemplo, teníamos un rack completo en un centro de datos separado con un servidor FTP, que era utilizado por un cliente. Resultó que “…nos mudamos, pero él se quedó así, no lo cambiamos”. Fue hace 2 años.
De particular interés fue la factura por los servicios en la nube. Creo que la razón principal de la elevada factura de la nube son los desarrolladores que tienen acceso ilimitado a los servidores por primera vez en sus vidas. No necesitan preguntar: "Por favor, dame un servidor de prueba", pueden realizarlo ellos mismos. Además, los desarrolladores siempre quieren construir un sistema tan genial que Facebook y Netflix estarán celosos.
Pero los desarrolladores no tienen experiencia en la compra de servidores ni la habilidad para determinar el tamaño requerido de servidores, porque antes no lo necesitaban. Y normalmente no entienden bien la diferencia entre escalabilidad y rendimiento.
Resultados del inventario:
- Salimos del mismo centro de datos.
- Rescindió el contrato con 3 servicios de registro. Porque teníamos 5 de ellos: cada desarrollador que comenzaba a jugar con algo tomaba uno nuevo.
- Se cerraron 7 sistemas AWS. Una vez más, nadie detuvo los proyectos muertos; todos continuaron trabajando.
- Reducción de los costos de software en 6 veces.
Día setenta y cinco
Pasó el tiempo y en dos meses y medio me tocó reunirme con la junta directiva. Nuestra junta directiva no es mejor ni peor que otras; como todas las juntas directivas, quiere saberlo todo. La gente invierte dinero y quiere entender hasta qué punto lo que hacemos encaja en los KPI establecidos.
La junta directiva recibe mucha información cada mes: el número de usuarios, su crecimiento, qué servicios utilizan y cómo, rendimiento y productividad y, finalmente, velocidad media de carga de las páginas.
El único problema es que creo que el promedio es pura maldad. Pero es muy difícil explicarle esto a la junta directiva. Están acostumbrados a operar con números agregados y no, por ejemplo, con la dispersión de los tiempos de carga por segundo.
Hubo algunos puntos interesantes a este respecto. Por ejemplo, dije que necesitamos dividir el tráfico entre servidores web separados según el tipo de contenido.

Es decir, ColdFusion pasa por Jetty y nginx y lanza las páginas. Y las imágenes, JS y CSS pasan por un nginx separado con sus propias configuraciones. Esta es una práctica bastante estándar de la que estoy hablando. un par de años atras. Como resultado, las imágenes se cargan mucho más rápido y... la velocidad de carga promedio ha aumentado en 200 ms.
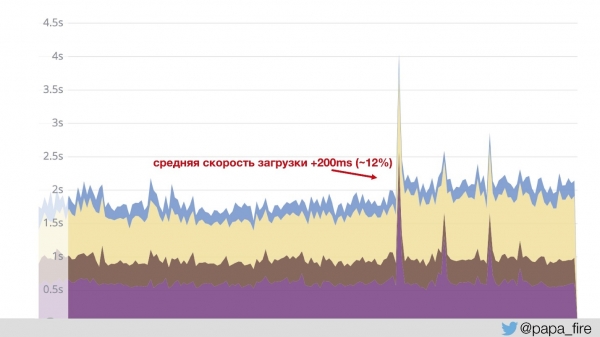
Esto sucedió porque el gráfico se construye en base a los datos que vienen con Jetty. Es decir, el contenido rápido no se incluye en el cálculo: el valor medio ha aumentado. Esto lo teníamos claro, nos reímos, pero ¿cómo podemos explicarle a la junta directiva por qué hicimos algo y las cosas empeoraron un 12%?
Día ochenta y cinco
Al final del tercer mes, me di cuenta de que había una cosa con la que no había contado en absoluto: el tiempo. Todo lo que hablé lleva tiempo.

Este es mi verdadero calendario semanal: solo una semana laboral, no muy ocupada. No hay tiempo suficiente para todo. Por lo tanto, nuevamente es necesario reclutar personas que lo ayuden a enfrentar los problemas.
Conclusión
Eso no es todo. En esta historia, ni siquiera he llegado a cómo trabajamos con el producto y tratamos de sintonizarnos con la ola general, o cómo integramos el soporte técnico, o cómo resolvimos otros problemas técnicos. Por ejemplo, aprendí por casualidad que en las tablas más grandes de la base de datos no utilizamos SEQUENCE. Tenemos una función autoescrita. nextIDy no se utiliza en una transacción.
Había un millón de cosas más similares de las que podríamos hablar durante mucho tiempo. Pero lo más importante que aún queda por decir es la cultura.

Es la cultura o la falta de ella lo que conduce a todos los demás problemas. Estamos tratando de construir una cultura donde las personas:
- no temen los fracasos;
- aprender de los errores;
- colaborar con otros equipos;
- toma la iniciativa;
- asumir la responsabilidad;
- acoger el resultado como objetivo;
- celebrando el éxito.
Con esto vendrá todo lo demás.
fuego leon , y .
Hay dos estrategias con respecto al legado: evitar trabajar con él a toda costa o superar con valentía las dificultades asociadas. Nosotros C Estamos tomando el segundo camino, cambiando procesos y enfoques. Únete a nosotros , и , y juntos implementaremos una cultura DevOps.
Fuente: habr.com
