

Atrás quedaron los días en los que no había que preocuparse por optimizar el rendimiento de la base de datos. El tiempo no se detiene. Todo nuevo emprendedor tecnológico quiere crear el próximo Facebook, mientras intenta recopilar todos los datos que pueda tener en sus manos. Las empresas necesitan estos datos para entrenar mejor modelos que les ayuden a ganar dinero. En tales condiciones, los programadores necesitan crear API que les permitan trabajar de manera rápida y confiable con grandes cantidades de información.
Si ha estado diseñando backends de aplicaciones o bases de datos durante algún tiempo, probablemente haya escrito código para ejecutar consultas paginadas. Por ejemplo, así:
SELECT * FROM table_name LIMIT 10 OFFSET 40
¿Cómo es?
Pero si así fue como hiciste tu paginación, lamento decirte que no lo hiciste de la manera más eficiente.
¿Quieres oponerte a mí? . , и Ya están utilizando las técnicas de las que quiero hablar hoy.
Nombra al menos un desarrollador backend que nunca haya usado OFFSET и LIMIT para realizar consultas paginadas. En MVP (Producto Mínimo Viable) y en proyectos donde se utilizan pequeñas cantidades de datos, este enfoque es bastante aplicable. "Simplemente funciona", por así decirlo.
Pero si necesita crear sistemas confiables y eficientes desde cero, debe preocuparse de antemano por la eficiencia de consultar las bases de datos utilizadas en dichos sistemas.
Hoy hablaremos sobre los problemas con las implementaciones comúnmente utilizadas (qué lástima) de motores de consultas paginadas y cómo lograr un alto rendimiento al ejecutar dichas consultas.
¿Qué hay de malo con OFFSET y LIMIT?
Como ya se mencionó, OFFSET и LIMIT Funcionan bien en proyectos que no necesitan trabajar con grandes cantidades de datos.
El problema surge cuando la base de datos crece hasta tal tamaño que ya no cabe en la memoria del servidor. Sin embargo, cuando trabaje con esta base de datos, deberá utilizar consultas paginadas.
Para que este problema se manifieste, debe haber una situación en la que el DBMS recurra a una operación ineficiente de escaneo completo de la tabla en cada consulta paginada (aunque pueden ocurrir operaciones de inserción y eliminación, ¡y no necesitamos datos desactualizados!).
¿Qué es un “escaneo de tabla completo” (o “escaneo de tabla secuencial”, Escaneo Secuencial)? Esta es una operación durante la cual el DBMS lee secuencialmente cada fila de la tabla, es decir, los datos contenidos en ella, y verifica que cumplan con una condición determinada. Se sabe que este tipo de escaneo de tablas es el más lento. El hecho es que cuando se ejecuta, se realizan muchas operaciones de entrada/salida que involucran al subsistema de disco del servidor. La situación empeora por la latencia asociada con el trabajo con datos almacenados en discos y el hecho de que transferir datos del disco a la memoria es una operación que consume muchos recursos.
Por ejemplo, tienes registros de 100000000 de usuarios y ejecutas una consulta con la construcción OFFSET 50000000. Esto significa que el DBMS tendrá que cargar todos estos registros (¡y ni siquiera los necesitamos!), ponerlos en la memoria y luego tomar, digamos, 20 resultados reportados en LIMIT.
Digamos que podría verse así: "seleccione filas de 50000 a 50020 de 100000". Es decir, el sistema primero deberá cargar 50000 filas para completar la consulta. ¿Ves cuánto trabajo innecesario tendrá que hacer?
Si no me cree, eche un vistazo al ejemplo que creé usando las funciones .
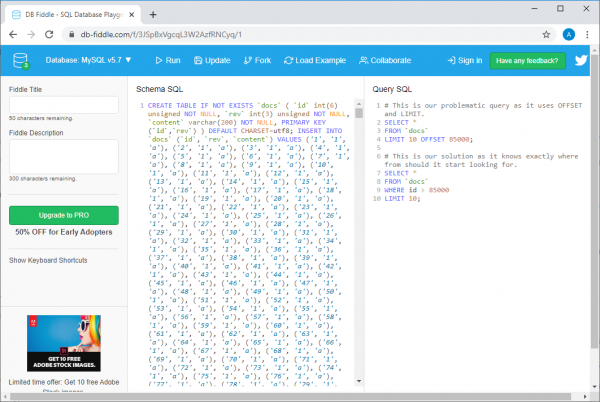
Ejemplo en db-fiddle.com
Allí, a la izquierda, en el campo. Schema SQL, hay un código que inserta 100000 filas en la base de datos, y a la derecha, en el campo Query SQL, se muestran dos consultas. El primero, lento, tiene este aspecto:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Y la segunda, que es una solución eficaz al mismo problema, es así:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Para cumplir con estas solicitudes, simplemente haga clic en el botón Run en la parte superior de la página. Una vez hecho esto, comparamos información sobre el tiempo de ejecución de la consulta. Resulta que ejecutar una consulta ineficaz tarda al menos 30 veces más que ejecutar la segunda (este tiempo varía de una ejecución a otra; por ejemplo, el sistema puede informar que la primera consulta tardó 37 ms en completarse, pero la ejecución de la segundo - 1 ms).
Y si hay más datos, entonces todo se verá aún peor (para convencerte de ello, echa un vistazo a mi con 10 millones de filas).
Lo que acabamos de comentar debería darle una idea de cómo se procesan realmente las consultas a la base de datos.
Tenga en cuenta que cuanto mayor sea el valor OFFSET — más tardará en completarse la solicitud.
¿Qué debo usar en lugar de la combinación de OFFSET y LIMIT?
En lugar de una combinación OFFSET и LIMIT Vale la pena utilizar una estructura construida según el siguiente esquema:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Esta es la ejecución de consultas con paginación basada en cursor.
En lugar de almacenar los actuales localmente OFFSET и LIMIT y transmitirlos con cada solicitud, debe almacenar la última clave primaria recibida (generalmente esto es ID) Y LIMIT, como resultado se obtendrán consultas similares a las anteriores.
¿Por qué? El punto es que al especificar explícitamente el identificador de la última fila leída, le indica a su DBMS dónde debe comenzar a buscar los datos necesarios. Además, la búsqueda, gracias al uso de la clave, se realizará de manera eficiente, el sistema no tendrá que distraerse con líneas fuera del rango especificado.
Echemos un vistazo a la siguiente comparación de rendimiento de varias consultas. Aquí hay una consulta ineficaz.
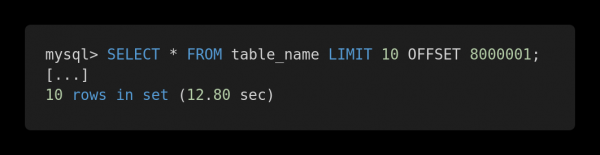
Solicitud lenta
Y aquí hay una versión optimizada de esta solicitud.
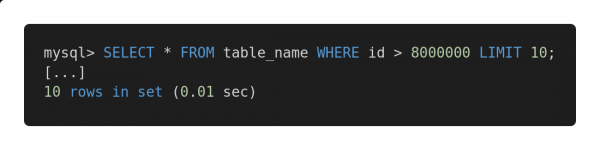
Solicitud rápida
Ambas consultas devuelven exactamente la misma cantidad de datos. Pero el primero tarda 12,80 segundos en completarse y el segundo 0,01 segundos. ¿Sientes la diferencia?
Posibles problemas
Para que el método de consulta propuesto funcione eficazmente, la tabla debe tener una columna (o columnas) que contengan índices secuenciales únicos, como un identificador entero. En algunos casos específicos, esto puede determinar el éxito del uso de dichas consultas para aumentar la velocidad de trabajo con la base de datos.
Naturalmente, al crear consultas, es necesario tener en cuenta la arquitectura específica de las tablas y elegir los mecanismos que funcionarán mejor en las tablas existentes. Por ejemplo, si necesitas trabajar en consultas con grandes volúmenes de datos relacionados, puede que te resulte interesante artículo.
Si nos enfrentamos al problema de que falta una clave primaria, por ejemplo, si tenemos una tabla con una relación de muchos a muchos, entonces el enfoque tradicional de usar OFFSET и LIMIT, está garantizado que nos conviene. Pero su uso puede resultar en consultas potencialmente lentas. En tales casos, recomendaría usar una clave primaria de incremento automático, incluso si solo es necesaria para manejar consultas paginadas.
Si está interesado en este tema - , и - varios materiales útiles.
resultados
La principal conclusión que podemos sacar es que, da igual el tamaño de bases de datos del que hablemos, siempre es necesario analizar la velocidad de ejecución de las consultas. Hoy en día, la escalabilidad de las soluciones es extremadamente importante, y si todo está diseñado correctamente desde el principio de trabajar en un determinado sistema, esto, en el futuro, puede salvar al desarrollador de muchos problemas.
¿Cómo se analizan y optimizan las consultas de bases de datos?
Fuente: habr.com
