


Hola a todos. Este artículo fue escrito para aquellos que todavía están divididos entre elegir plataformas de virtualización y después de leer el artículo de la serie "Instalamos proxmox y en general todo está bien, 6 años de funcionamiento sin un solo descanso". Pero después de instalar una u otra solución lista para usar, surge la pregunta: ¿cómo puedo corregir esto aquí, para que el seguimiento sea más comprensible, y aquí, para controlar las copias de seguridad…? Y luego llega el momento y te das cuenta de que quieres algo más funcional, o quieres que todo dentro de tu sistema quede claro, y no esta caja negra, o quieres usar algo más que un hipervisor y un montón de máquinas virtuales. Este artículo contendrá algunas ideas y prácticas basadas en la plataforma Opennebula; la elegí porque. no exige recursos y la arquitectura no es tan compleja.
Y así, como vemos, muchos proveedores de la nube trabajan en kvm y realizan conexiones externas para controlar las máquinas. Está claro que los grandes proveedores de alojamiento escriben sus propios marcos para la infraestructura en la nube, el mismo YANDEX, por ejemplo. Alguien usa OpenStack y establece una conexión sobre esta base: SELECTEL, MAIL.RU. Pero si tiene su propio hardware y un pequeño equipo de especialistas, generalmente elige algo ya preparado: VMWARE, HYPER-V, hay licencias gratuitas y de pago, pero no estamos hablando de eso ahora. Hablemos de entusiastas: estos son aquellos que no tienen miedo de ofrecer y probar algo nuevo, a pesar de que la compañía dejó claramente claro: "¿Quién reparará esto después de usted?", "¿Vamos a implementar esto en producción más adelante?". ? Aterrador." Pero primero puede aplicar estas soluciones en un banco de pruebas y, si a todos les gusta, puede plantear la cuestión de un mayor desarrollo y uso en entornos más serios.
También aquí hay un enlace al informe. de un participante activo en el desarrollo de esta plataforma.
Quizás en este artículo algo resulte superfluo y ya sea comprensible para un especialista experimentado y, en algunos casos, no lo describiré todo porque comandos y descripciones similares están disponibles en Internet. Esta es solo mi experiencia con esta plataforma. Espero que los participantes activos agreguen en los comentarios qué se podría hacer mejor y qué errores cometí. Todas las acciones se desarrollaron en un stand de casa compuesto por 3 PC de diferentes características. Además, no indiqué específicamente cómo funciona este software ni cómo instalarlo. No, solo experiencia en administración y los problemas que encontré. Quizás esto le resulte útil a alguien en su elección.
Entonces empecemos. Como administrador del sistema, los siguientes puntos son importantes para mí, sin los cuales es poco probable que utilice esta solución.
1. Repetibilidad de la instalación
Hay muchas instrucciones para instalar opennebula, no debería haber ningún problema. De una versión a otra, aparecen nuevas funciones que no siempre funcionarán al pasar de una versión a otra.
2. Supervisión
Monitorearemos el nodo en sí, kvm y opennebula. Afortunadamente ya está listo. Hay muchas opciones para monitorear hosts Linux, el mismo Zabbix o exportador de nodos, a quien le guste qué más, por el momento lo defino como monitoreo de métricas del sistema (temperatura donde se puede medir, consistencia de la matriz de discos), a través de zabbix. , y en cuanto a solicitudes a través del exportador Prometheus. Para monitorear kvm, por ejemplo, puede tomar el proyecto y configúrelo para que se ejecute a través de systemd, funciona bastante bien y muestra métricas de kvm, también hay un panel listo para usar .
Por ejemplo, aquí está mi archivo:
/etc/systemd/system/libvirtd_exporter.service
[Unit]
Description=Node Exporter
[Service]
User=node_exporter
ExecStart=/usr/sbin/prometheus-libvirt-exporter --web.listen-address=":9101"
[Install]
WantedBy=multi-user.targetY entonces tenemos 1 exportador, necesitamos un segundo para monitorear la propia nebulosa abierta, usé este
Se puede agregar a lo normal para monitorear el sistema lo siguiente.
En el archivo node_exporter cambiamos el inicio así:
ExecStart=/usr/sbin/node_exporter --web.listen-address=":9102" --collector.textfile.directory=/var/lib/opennebula_exporter/textfile_collectorCree un directorio mkdir -p /var/lib/opennebula_exporter
script bash presentado anteriormente, primero verificamos el trabajo a través de la consola, si muestra lo que necesitamos (si da un error, instale xmlstarlet), lo copiamos a /usr/local/bin/opennebula_exporter.sh
Agregue una tarea cron por cada minuto:
*/1 * * * * (/usr/local/bin/opennebula_exporter.sh > /var/lib/opennebula_exporter/textfile_collector/opennebula.prom)Empezaron a aparecer métricas, puedes tomarlas como un prometeo y construir gráficos y hacer alertas. En Grafana puedes dibujar, por ejemplo, un panel de control tan simple.
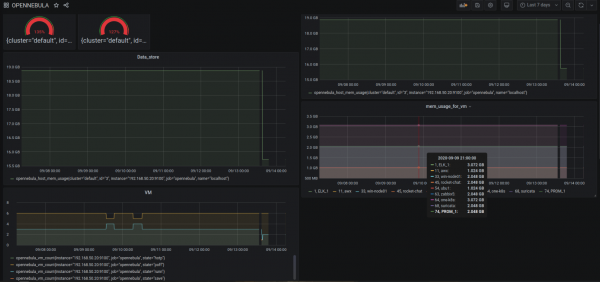
(está claro que aquí comprometo demasiado la CPU y la RAM)
Para aquellos que aman y usan Zabbix, existe
En cuanto al seguimiento, lo principal es que esté ahí. Por supuesto, también puede utilizar las herramientas integradas de monitoreo de máquinas virtuales y cargar datos en la facturación, aquí cada uno tiene su propia visión, todavía no he comenzado a trabajar en esto más de cerca.
Realmente todavía no he empezado a registrarme. La opción más sencilla es agregar td-agent para analizar el directorio /var/lib/one con expresiones regulares. Por ejemplo, el archivo sunstone.log coincide con la expresión regular de nginx y otros archivos que muestran el historial de acceso a la plataforma. ¿Cuál es la ventaja de esto? Bueno, por ejemplo, podemos rastrear explícitamente el número de "Error, error" y rastrear rápidamente dónde y en qué nivel hay un mal funcionamiento.
3. Copias de seguridad
También hay proyectos completados pagados, por ejemplo septiembre. :OpenNebula_Backup. Aquí debemos entender que simplemente hacer una copia de seguridad de la imagen de una máquina no es lo mismo en este caso, porque nuestras máquinas virtuales deben funcionar con integración total (el mismo archivo de contexto que describe la configuración de red, el nombre de la máquina virtual y la configuración personalizada de sus aplicaciones). . Por lo tanto, aquí decidimos qué y cómo realizaremos la copia de seguridad. En algunos casos es mejor hacer copias de lo que hay en la propia máquina virtual. Y quizás sólo necesites hacer una copia de seguridad de un disco de una máquina determinada.
Por ejemplo, determinamos que todas las máquinas comienzan con imágenes persistentes, por lo tanto, después de leer
Esto significa que primero podemos cargar la imagen desde nuestra máquina virtual:
onevm disk-saveas 74 3 prom.qcow2
Image ID: 77
Смотрим, под каким именем он сохранился
oneimage show 77
/var/lib/one//datastores/100/f9503161fe180658125a9b32433bf6e8
И далее копируем куда нам необходимо. Конечно, так себе способ. Просто хотел показать, что используя инструменты opennebula можно строить подобные решения.También encontré en Internet. y hay mas , pero sólo hay almacenamiento para qcow2.
Pero como todos sabemos, tarde o temprano llega un momento en el que quieres copias de seguridad incrementales, aquí es más difícil y tal vez la gerencia asigne dinero para una solución paga, o vaya por el otro lado y comprenda que aquí solo estamos recortando recursos. y hacer copias de seguridad a nivel de aplicación y agregar una serie de nuevos nodos y máquinas virtuales; sí, aquí estoy diciendo que usar la nube únicamente para iniciar grupos de aplicaciones y ejecutar la base de datos en otra plataforma o tomar una ya preparada del proveedor, si es posible.
4. Facilidad de uso
En este párrafo describiré los problemas que encontré. Por ejemplo, según las imágenes, como sabemos, existe la persistencia: cuando esta imagen se monta en una máquina virtual, todos los datos se escriben en esta imagen. Y si no es persistente, la imagen se copia al almacenamiento y los datos se escriben en lo que se copió de la imagen de origen; así es como funcionan las plantillas. Me causé problemas repetidamente al olvidarme de especificar persistente y se copió la imagen de 200 GB, el problema es que este procedimiento ciertamente no se puede cancelar, hay que ir al nodo y finalizar el proceso "cp" actual.
Una de las desventajas importantes es que no puedes cancelar acciones simplemente usando la interfaz gráfica de usuario. O mejor dicho los cancelarás y verás que no pasa nada y los iniciarás nuevamente, los cancelarás y de hecho ya habrá 2 procesos cp que copian la imagen.
Y luego se trata de entender por qué opennebula numera cada nueva instancia con una nueva identificación, por ejemplo, en el mismo proxmox creó una máquina virtual con identificación 101, la eliminó, luego la crea nuevamente y la identificación 101. En opennebula esto no sucederá, Cada nueva instancia se creará con una nueva identificación y esto tiene su propia lógica, por ejemplo, borrar datos antiguos o instalaciones fallidas.
Lo mismo ocurre con el almacenamiento; sobre todo, esta plataforma está orientada al almacenamiento centralizado. Hay complementos para usar local, pero no estamos hablando de eso en este caso. Creo que en el futuro alguien escribirá un artículo sobre cómo lograron utilizar el almacenamiento local en nodos y utilizarlo con éxito en producción.
5. Máxima sencillez
Por supuesto, cuanto más avanzas, menos personas te entenderán.
En las condiciones de mi stand (3 nodos con almacenamiento nfs), todo funciona bien. Pero si realizamos experimentos que involucran un corte de energía, por ejemplo, cuando ejecutamos una instantánea y apagamos la energía del nodo, guardamos la configuración en la base de datos de que hay una instantánea, pero en realidad no hay ninguna (bueno, todos entendemos que Inicialmente escribió la base de datos sobre esta acción en sql, pero la operación en sí no fue exitosa). La ventaja es que al crear una instantánea, se forma un archivo separado y hay un "padre", por lo tanto, en caso de problemas e incluso si no funciona a través de la interfaz gráfica de usuario, podemos tomar el archivo qcow2 y restaurarlo por separado.
En las redes, lamentablemente, no todo es tan sencillo. Bueno, al menos es más fácil que en OpenStack, usé solo VLAN (802.1Q); funciona bastante bien, pero si realiza cambios en la configuración desde la red de plantilla, estas configuraciones no se aplicarán a las máquinas que ya están en ejecución, es decir. debe eliminar y agregar una tarjeta de red, luego se aplicará la nueva configuración.
Si también desea compararlo con OpenStack, entonces puede decir esto: en Opennebula no existe una definición clara de qué tecnologías usar para almacenar datos, administrar la red y los recursos; cada administrador decide por sí mismo qué es más conveniente para él.
6. Complementos e instalaciones adicionales
Después de todo, según lo entendemos, la plataforma en la nube puede administrar no solo kvm, sino también vmware esxi. Desafortunadamente, no tenía un grupo con Vcenter, si alguien lo ha probado, por favor escriba.
Se declara soporte para otros proveedores de nube.
AWS, AZUL.
También intenté conectar Vmware Cloud desde Selectel, pero nada funcionó; en general, se bloqueó porque hay muchos factores y no tiene sentido escribir al soporte técnico del proveedor de hosting.
Además, ahora la nueva versión tiene un petardo: se trata del lanzamiento de microvm, un tipo de arnés kvm sobre Docker, que brinda aún más versatilidad, seguridad y mayor productividad porque no hay necesidad de desperdiciar recursos en emular equipos. La única ventaja que le veo respecto a Docker es que no ocupa un número adicional de procesos y no hay sockets ocupados al utilizar esta emulación, es decir. Es muy posible usarlo como balanceador de carga (pero probablemente valga la pena escribir un artículo aparte sobre esto hasta que haya ejecutado todas las pruebas por completo).
7. Experiencia positiva de uso y depuración de errores.
Quería compartir mis observaciones sobre el trabajo, describí algunas de ellas arriba, me gustaría escribir más. De hecho, probablemente no sea el único que al principio piensa que este no es el sistema correcto y, en general, todo aquí es una muleta: ¿cómo funcionan con esto? Pero luego llega la comprensión de que todo es bastante lógico. Por supuesto, no se puede complacer a todo el mundo y algunos aspectos requieren mejora.
Por ejemplo, una operación simple de copiar una imagen de disco de un almacén de datos a otro. En mi caso, hay 2 nodos con nfs, envío la imagen; la copia se realiza a través del frontend opennebula, aunque todos estamos acostumbrados al hecho de que los datos deben copiarse directamente entre hosts; en el mismo vmware, somos hyper-v. Acostumbrado a esto, pero aquí a otro. Hay un enfoque diferente y una ideología diferente, y en la versión 5.12 eliminaron el botón "migrar al almacén de datos": solo se transfiere la máquina en sí, pero no el almacenamiento porque significa almacenamiento centralizado.
El siguiente es un error popular con varios motivos: "Error al implementar la máquina virtual: no se pudo crear el dominio desde /var/lib/one//datastores/103/10/deployment.5". A continuación se muestra lo más importante a tener en cuenta.
- Derechos de imagen para el usuario oneadmin;
- Permisos para que el usuario oneadmin ejecute libvirtd;
- ¿Está el almacén de datos montado correctamente? Vaya y verifique la ruta en el nodo, tal vez algo se haya caído;
- Red configurada incorrectamente, o más bien en la interfaz, está en la configuración de red donde la interfaz principal para vlan es br0, pero en el nodo está escrito como bridge0; debe ser el mismo.
El almacén de datos del sistema almacena metadatos para su máquina virtual; si ejecuta la máquina virtual con una imagen persistente, entonces la máquina virtual debe tener acceso a la configuración creada inicialmente en el almacenamiento donde creó la máquina virtual; esto es muy importante. Por lo tanto, al transferir una máquina virtual a otro almacén de datos, debe volver a verificar todo.
8. Documentación, comunidad. Mayor desarrollo
Y el resto, buena documentación, comunidad y lo principal es que el proyecto siga vivo en el futuro.
En general, todo está bastante bien documentado e incluso utilizando una fuente oficial no será un problema instalarlo y encontrar respuestas a dudas.
Comunidad, activa. Publica muchas soluciones listas para usar que puede utilizar en sus instalaciones.
Por el momento, algunas políticas en la empresa han cambiado desde el 5.12. Será interesante ver cómo se desarrolla el proyecto. Al principio, señalé específicamente algunos de los proveedores que utilizan sus soluciones y lo que ofrece la industria. Por supuesto, no hay una respuesta clara sobre qué utilizar. Pero para las organizaciones más pequeñas, mantener su pequeña nube privada puede no ser tan costoso como parece. Lo principal es saber exactamente lo que necesitas.
Como resultado, independientemente de lo que elija como sistema en la nube, no debe limitarse a un solo producto. Si tienes tiempo, merece la pena echar un vistazo a otras soluciones más abiertas.
Hay una buena charla Ayudan activamente y no te envían a buscar una solución al problema en Google. Únete a nosotros.
Fuente: habr.com
