

Cuanto más complejo es el sistema, más se llena de todo tipo de alertas. Y es necesario reaccionar ante esas mismas alertas, agregarlas y visualizarlas. Creo que esta es una situación que a muchos les resulta familiar hasta el punto del nerviosismo.
La solución que se discutirá no es la más inesperada, pero la búsqueda no arroja un artículo completo sobre este tema.
Por eso, decidí compartir la experiencia de FunCorp y hablar sobre cómo se estructura el proceso de turno, quién llama, por qué y cómo se puede ver todo.

¿Qué es PagerDuty?
Entonces, para resolver todos estos problemas, comenzamos a buscar una herramienta conveniente. Después de buscar un poco, elegimos PagerDuty. PD nos pareció una solución bastante completa y concisa con una gran cantidad de integraciones y configuraciones. ¿Cómo es ella?
En resumen, PagerDuty es una plataforma de procesamiento de incidentes que puede procesar incidentes entrantes a través de varias integraciones, configurar órdenes de servicio y luego alertar al ingeniero de turno según el nivel del incidente (en un nivel alto, una llamada, en un nivel bajo, un empujón desde la aplicación/SMS).
¿Quién es el oficial de turno?
Este es probablemente el primer lugar para empezar a configurar PD.
En FunCorp, al igual que en otras empresas, existe un puesto honorario de funcionario de turno. Se transmite de ingeniero a ingeniero una vez al día. Existe una llamada primera y segunda línea de respuesta a una alerta de PagerDuty. Supongamos que llega una alerta de alta prioridad y si 10 minutos después de la llamada al oficial de guardia desde la primera línea no hay reacción (es decir, no se transfiere al estado de reconocimiento o resolución), la llamada pasa a la segunda. ingeniero de turno. Esto se configura en el propio PagerDuty a través de Políticas de escalamiento.
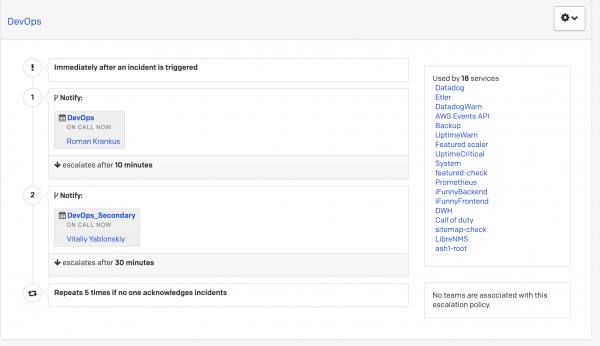
Si el segundo oficial de servicio no responde, la notificación regresa a el principal al oficial de turno.
Por lo tanto, cualquier alerta entrante de alta prioridad no puede quedar sin procesar.
Ahora veamos de dónde pueden venir los incidentes.
¿Qué integraciones utilizamos?
PD recibe muchas incidencias diferentes de varios servicios. Actualmente tenemos alrededor de 25 servicios de este tipo y para procesarlos utilizamos algunas integraciones ya preparadas.
- Prometheus
El principal sistema de recopilación de métricas es Prometheus. Ya se ha escrito mucho al respecto en Habré, solo diré que tenemos varios para diferentes entornos: uno recopila métricas de máquinas virtuales y acopladores, otro de los servicios de Amazon, el tercero de máquinas de hardware. Telegraf se utiliza principalmente como exportador de métricas.
- Correo electrónico
Creo que también aquí todo queda claro en el título. Esta integración se utiliza para enviar notificaciones desde algunos scripts ejecutados por cron. PD le proporciona una dirección determinada a la que envía cartas. Al crear un servicio con dicha integración, puede establecer prioridades, en qué orden se procesarán los incidentes entrantes, cómo crear exactamente una alerta (para cada carta entrante, para una carta entrante + una regla determinada, etc.).

- Flojo
En mi opinión, una integración muy interesante. Hay ocasiones en las que sucede algo pero no está cubierto por incidentes. Por eso, agregamos integración desde Slack para crear un incidente. Es decir, puedes escribir al Slack corporativo. /callofduty todo es lento y se romperá pronto y el PD lo procesará y enviará el incidente al ingeniero de turno.
Hacemos:

Vemos:

- API
Integración HTTP. De hecho, aquí no hay nada particularmente interesante, solo una solicitud POST con un cuerpo en formato JSON. Por ejemplo, algo interesante: lo usamos para monitoreo externo usando . Este servicio comprueba la accesibilidad de nuestros sitios desde diferentes partes del mundo. En el caso de que recibamos un código de respuesta inaceptable (por ejemplo, 502), se crea un incidente y luego todo sigue la cadena descrita anteriormente. El propio StatusCake tiene la capacidad de monitorear las URL internas, el certificado SSL o la caducidad del dominio.
- LibreNMS
Este es otro sistema de seguimiento, puedes leer más sobre él en su sitio web. . Con su ayuda, monitoreamos las interfaces de red y el iDRAC desde los servidores.
También hubo integraciones como Datadog, CloudWatch. Puedes ver más sobre lo que les pasó. .
Visualización
El principal sistema de notificación de incidencias es Slack. Todos los incidentes que llegan a PD se escriben en un chat especial y, si su estado cambia, también se muestra en el chat.
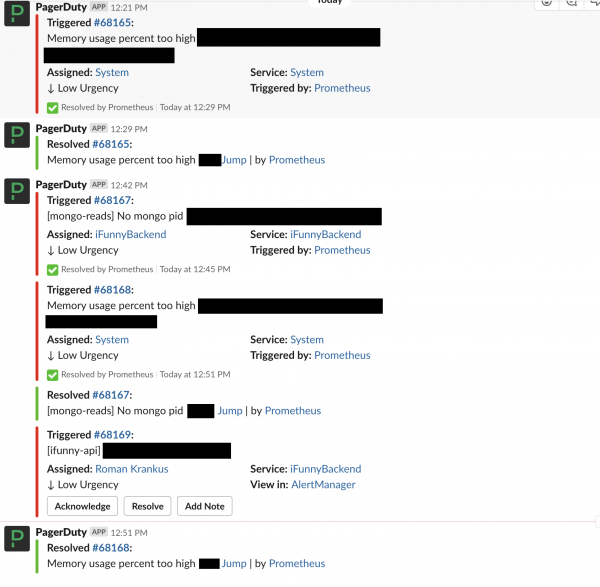
Cuando surgió la oportunidad de mostrar datos útiles en las pantallas de los monitores que colgaban del techo, de repente nos dimos cuenta de que nosotros (en el departamento de Devops) no teníamos nada que mostrar en ellos. Existe un Grafana maravilloso, pero no lo cubre todo y los empleados reaccionan a las alertas, no a los gráficos.
Después de una búsqueda exhaustiva pero infructuosa en GitHub de un "tablero" conciso e informativo para PD, decidimos escribir el nuestro, solo con lo que necesitábamos. Aunque al principio surgió la idea de mostrar la interfaz PD en sí, parecía aún más inconveniente.
Para escribirlo, todo lo que necesita hacer es obtener una clave de un PD con derechos de solo lectura.
Y esto es lo que obtuvimos:
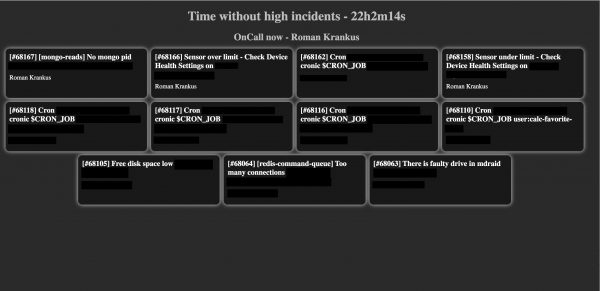
La pantalla muestra los incidentes abiertos actuales, el nombre del ingeniero actual en servicio del cronograma seleccionado y el tiempo sin un incidente de alta prioridad (el panel con un incidente de alta prioridad se resaltará en rojo).
.
Como resultado, recibimos un panel conveniente para ver todos nuestros incidentes. Me alegraré si algunos de ustedes encuentran útil nuestra experiencia.
Fuente: habr.com
