

Debido a mi línea de trabajo, tengo que lidiar con situaciones en las que un desarrollador escribe una solicitud y piensa "La base es inteligente, ¡puede manejar todo por sí sola!«
En algunos casos (en parte por desconocimiento de las capacidades de la base de datos, en parte por optimizaciones prematuras), este enfoque conduce a la aparición de "Frankensteins".
Primero, daré un ejemplo de dicha solicitud:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Para evaluar sustancialmente la calidad de una solicitud, creemos un conjunto de datos arbitrario:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
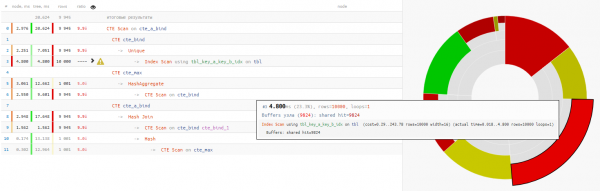
Resulta que leer los datos tomó menos de una cuarta parte del tiempo ejecución de consulta:
Desmontándolo pieza por pieza
Echemos un vistazo más de cerca a la solicitud y estemos desconcertados:
- ¿Por qué está CON RECURSIVO aquí si no hay CTE recursivos?
- ¿Por qué agrupar los valores mínimos y máximos en un CTE separado si luego están vinculados a la muestra original de todos modos?
+25% de tiempo - ¿Por qué utilizar un 'SELECT * FROM' incondicional al final para repetir el CTE anterior?
+14% de tiempo
En este caso, tuvimos mucha suerte de que se eligiera Hash Join para la conexión, y no Nested Loop, porque entonces habríamos recibido no solo un pase de CTE Scan, ¡sino 10K!
un poco sobre CTE ScanAquí debemos recordar que CTE Scan es similar a Seq Scan - es decir, no hay indexación, sino sólo una búsqueda completa, que requeriría 10K x 0.3ms = 3000ms para ciclos por cte_max o 1K x 1.5ms = 1500ms al realizar un bucle por cte_bind!
En realidad, ¿qué querías obtener como resultado? Sí, normalmente esta es la pregunta que surge en algún momento del quinto minuto del análisis de consultas de "tres pisos".
Queríamos generar resultados para cada par de claves único. min/max del grupo por key_a.
Así que usémoslo para esto. :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 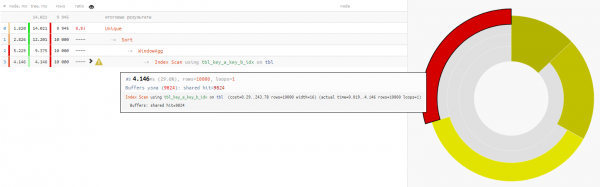
Dado que leer datos en ambas opciones toma aproximadamente 4-5 ms, entonces todo nuestro tiempo gana -32% - esto está en su forma más pura carga eliminada de la CPU base, si dicha solicitud se ejecuta con suficiente frecuencia.
En general, no debes forzar la base a “llevar la redonda, rodar la cuadrada”.
Fuente: habr.com
