

De vez en cuando, el desarrollador necesita pasar un conjunto de parámetros o incluso una selección completa a la solicitud "en la entrada". A veces hay soluciones muy extrañas a este problema.
Vayamos "desde lo contrario" y veamos cómo no hacerlo, por qué y cómo puedes hacerlo mejor.
"Inserción" directa de valores en el cuerpo de la solicitud
Por lo general, se ve algo como esto:
query = "SELECT * FROM tbl WHERE id = " + value... o así:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Sobre este método se dice, se escribe y suficiente:

casi siempre lo es ruta directa a la inyección de SQL y una carga adicional en la lógica empresarial, que se ve obligada a "pegar" su cadena de consulta.
Este enfoque puede justificarse parcialmente solo si es necesario. usar particionamiento en PostgreSQL versiones 10 y anteriores para un plan más eficiente. En estas versiones, la lista de secciones escaneadas se determina sin tener en cuenta los parámetros transmitidos, solo sobre la base del cuerpo de la solicitud.
$n argumentos
el uso de los parámetros son buenos, te permite usar , lo que reduce la carga tanto en la lógica empresarial (la cadena de consulta se forma y se transmite solo una vez) como en el servidor de la base de datos (no es necesario volver a analizar ni planificar cada instancia de la solicitud).
Número variable de argumentos
Nos aguardarán problemas cuando queramos pasar un número desconocido de argumentos por adelantado:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Si deja la solicitud en este formulario, aunque nos salvará de posibles inyecciones, seguirá siendo necesario pegar/analizar la solicitud. para cada opción del número de argumentos. Ya es mejor que hacerlo cada vez, pero puedes prescindir de él.
Es suficiente pasar solo un parámetro que contenga representación serializada de una matriz:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'La única diferencia es la necesidad de convertir explícitamente el argumento al tipo de matriz deseado. Pero esto no da problemas, ya que sabemos de antemano hacia dónde nos dirigimos.
Transferencia de muestra (matriz)
Por lo general, estas son todo tipo de opciones para transferir conjuntos de datos para insertarlos en la base de datos "en una sola solicitud":
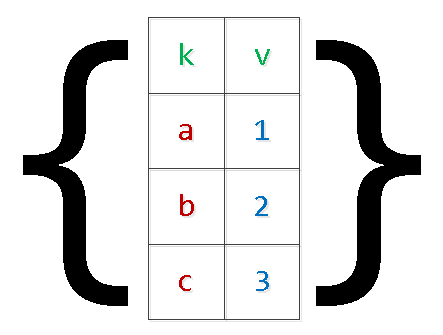
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Además de los problemas descritos anteriormente con el "re-pegado" de la solicitud, esto también puede llevarnos a sin memoria y caída del servidor. La razón es simple: PG reserva memoria adicional para los argumentos, y la cantidad de entradas en el conjunto está limitada solo por la lista de deseos de la aplicación de lógica de negocios. En casos especialmente clínicos era necesario ver argumentos "numerados" superiores a $ 9000 - No lo hagas de esta manera.
Reescribamos la consulta, aplicando ya serialización de "dos niveles":
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Sí, en el caso de valores "complejos" dentro de una matriz, deben enmarcarse entre comillas.
Está claro que de esta manera puede "expandir" la selección con un número arbitrario de campos.
desquiciado, desquiciado,…
De vez en cuando hay opciones para pasar en lugar de una "matriz de matrices" varias "matrices de columnas" que mencioné :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Con este método, si comete un error al generar listas de valores para diferentes columnas, es muy fácil obtener completamente resultados inesperados, que también dependen de la versión del servidor:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
A partir de la versión 9.3, PostgreSQL tiene funciones completas para trabajar con el tipo json. Por lo tanto, si sus parámetros de entrada están definidos en el navegador, puede allí mismo y formar objeto json para consulta SQL:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Para versiones anteriores, se puede utilizar el mismo método para cada (hstore), pero el "plegado" correcto con objetos complejos que se escapan en hstore puede causar problemas.
json_populate_recordset
Si sabe de antemano que los datos de la matriz json de "entrada" se utilizarán para completar alguna tabla, puede ahorrar mucho en los campos de "eliminación de referencias" y conversión a los tipos deseados utilizando la función json_populate_recordset:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
Y esta función simplemente "expandirá" la matriz de objetos pasada en una selección, sin depender del formato de la tabla:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2MESA TEMPORAL
Pero si la cantidad de datos en la muestra transmitida es muy grande, entonces incluirlos en un parámetro serializado es difícil y, a veces, imposible, ya que requiere una sola vez. gran asignación de memoria. Por ejemplo, necesita recopilar un gran lote de datos de eventos de un sistema externo durante mucho, mucho tiempo y luego desea procesarlo una sola vez en el lado de la base de datos.
En este caso, la mejor solución sería utilizar :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
el metodo es bueno para transmisión poco frecuente de grandes volúmenes datos.
Desde el punto de vista de la descripción de la estructura de sus datos, una tabla temporal se diferencia de una tabla "regular" en una sola característica. en la tabla del sistema pg_class, Y en pg_type, pg_depend, pg_attribute, pg_attrdef, ... - y nada en absoluto.
Por lo tanto, en sistemas web con una gran cantidad de conexiones de corta duración para cada una de ellas, dicha tabla generará cada vez nuevos registros del sistema, que se eliminan cuando se cierra la conexión con la base de datos. Eventualmente, el uso descontrolado de TEMP TABLE conduce a la "hinchazón" de las tablas en pg_catalog y ralentizando muchas operaciones que los utilizan.
Por supuesto, esto se puede combatir con paso periódico VACÍO LLENO según las tablas del catálogo del sistema.
Variables de sesión
Suponga que el procesamiento de los datos del caso anterior es bastante complejo para una sola consulta SQL, pero desea hacerlo con bastante frecuencia. Es decir, queremos utilizar el procesamiento procesal en , pero usar la transferencia de datos a través de tablas temporales será demasiado costoso.
Tampoco podemos usar $n-parámetros para pasar a un bloque anónimo. Las variables de sesión y la función nos ayudarán a salir de la situación. configuración actual.
Antes de la versión 9.2, tenía que preconfigurar clases_de_variables_personalizadas para "sus" variables de sesión. En las versiones actuales, puede escribir algo como esto:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3Hay otras soluciones disponibles en otros lenguajes de procedimiento admitidos.
¿Conoces más formas? ¡Comparte en los comentarios!
Fuente: habr.com
