

La traducción del artículo fue preparada específicamente para estudiantes del curso. .

Durante las últimas semanas hemos añadido a formato de transmisión binaria, que complementa el formato de archivo de acceso aleatorio/IPC existente. Tenemos implementaciones de Java y C++ y enlaces de Python. En este artículo, explicaré cómo funciona el formato y mostraré cómo se puede lograr un rendimiento de datos muy alto para un DataFrame de pandas.
Transmisión de datos de columnas
Una pregunta común que recibo de los usuarios de Arrow es el alto costo de migrar grandes conjuntos de datos tabulares de un formato orientado a filas o registros a un formato orientado a columnas. Para conjuntos de datos de varios gigabytes, la transposición en la memoria o en el disco puede ser una tarea abrumadora.
Para transmitir datos, ya sea que los datos de origen sean filas o columnas, una opción es enviar pequeños lotes de filas, cada una de las cuales contiene un diseño de columnas en su interior.
En Apache Arrow, la colección de matrices de columnas en memoria que representan un fragmento de tabla se denomina lote de registros. Para representar una única estructura de datos de una tabla lógica, se pueden recopilar varios lotes de registros.
En el formato de archivo de "acceso aleatorio" existente, registramos metadatos que contienen el esquema de la tabla y las ubicaciones de los bloques al final del archivo, lo que le permite seleccionar de forma extremadamente económica cualquier lote de registros o cualquier columna de un conjunto de datos. En formato streaming enviamos una serie de mensajes: un esquema y luego uno o más lotes de registros.
Los diferentes formatos se parecen a esto:
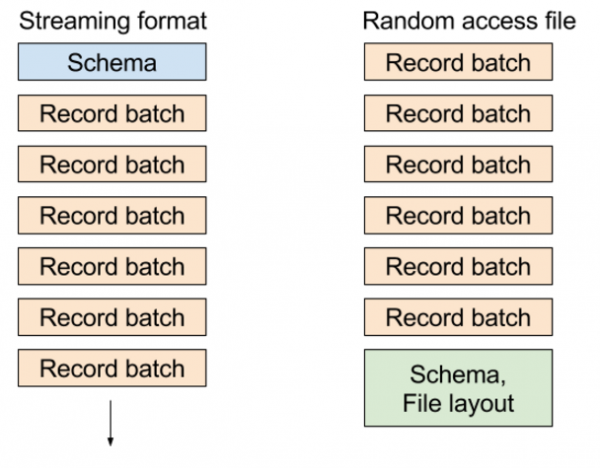
Transmisión de datos en PyArrow: aplicación
Para mostrarte cómo funciona esto, crearé un conjunto de datos de ejemplo que representa un único fragmento de flujo:
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = int(total_size / ncols / np.dtype('float64').itemsize)
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
}) Ahora, digamos que queremos escribir 1 GB de datos, que consta de fragmentos de 1 MB cada uno, para un total de 1024 fragmentos. Para comenzar, creemos el primer marco de datos de 1 MB con 16 columnas:
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
df = generate_data(MEGABYTE, NCOLS) Luego los convierto a pyarrow.RecordBatch:
batch = pa.RecordBatch.from_pandas(df) Ahora crearé un flujo de salida que escribirá en la RAM y creará StreamWriter:
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)Luego escribiremos 1024 fragmentos, que en última instancia equivaldrán a un conjunto de datos de 1 GB:
for i in range(DATA_SIZE // MEGABYTE):
stream_writer.write_batch(batch)Como escribimos en la RAM, podemos obtener la transmisión completa en un búfer:
In [13]: source = sink.get_result()
In [14]: source
Out[14]: <pyarrow.io.Buffer at 0x7f2df7118f80>
In [15]: source.size
Out[15]: 1074750744 Dado que estos datos están en la memoria, la lectura de lotes de registros de Arrow es una operación de copia cero. Abro StreamReader, leo datos en pyarrow.Tabley luego convertirlos a DataFrame pandas:
In [16]: reader = pa.StreamReader(source)
In [17]: table = reader.read_all()
In [18]: table
Out[18]: <pyarrow.table.Table at 0x7fae8281f6f0>
In [19]: df = table.to_pandas()
In [20]: df.memory_usage().sum()
Out[20]: 1073741904Todo esto es, por supuesto, bueno, pero es posible que tengas preguntas. ¿Qué tan rápido sucede esto? ¿Cómo afecta el tamaño del fragmento al rendimiento de recuperación de Pandas DataFrame?
Rendimiento de transmisión
A medida que disminuye el tamaño del fragmento de transmisión, el costo de reconstruir un DataFrame de columnas contiguo en pandas aumenta debido a patrones de acceso a la caché ineficientes. También hay algunos gastos generales al trabajar con estructuras y matrices de datos de C++ y sus buffers de memoria.
Para 1 MB, como se indica arriba, en mi computadora portátil (Quad-core Xeon E3-1505M) resulta:
In [20]: %timeit pa.StreamReader(source).read_all().to_pandas()
10 loops, best of 3: 129 ms per loopResulta que el rendimiento efectivo es de 7.75 GB/s para restaurar un DataFrame de 1 GB a partir de 1024 fragmentos de 1 MB. ¿Qué pasa si utilizamos trozos más grandes o más pequeños? Estos son los resultados:
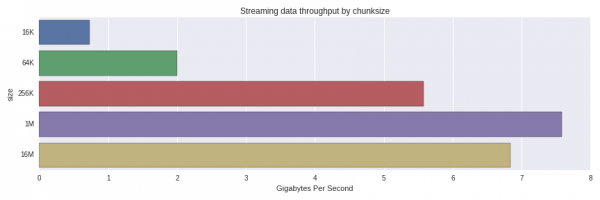
El rendimiento cae significativamente de 256K a 64K. Me sorprendió que los fragmentos de 1 MB se procesaran más rápido que los de 16 MB. Vale la pena realizar un estudio más exhaustivo y comprender si se trata de una distribución normal o si hay algo más en juego.
En la implementación actual del formato, los datos no están comprimidos en principio, por lo que el tamaño en la memoria y "en los cables" es aproximadamente el mismo. En el futuro, la compresión puede convertirse en una opción adicional.
Total
La transmisión de datos en columnas puede ser una forma eficaz de introducir grandes conjuntos de datos en herramientas de análisis en columnas como pandas en pequeños fragmentos. Los servicios de datos que utilizan almacenamiento orientado a filas pueden transferir y transponer pequeños fragmentos de datos que son más convenientes para las cachés L2 y L3 de su procesador.
código completo
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = total_size / ncols / np.dtype('float64').itemsize
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
})
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
def get_timing(f, niter):
start = time.clock_gettime(time.CLOCK_REALTIME)
for i in range(niter):
f()
return (time.clock_gettime(time.CLOCK_REALTIME) - start) / NITER
def read_as_dataframe(klass, source):
reader = klass(source)
table = reader.read_all()
return table.to_pandas()
NITER = 5
results = []
CHUNKSIZES = [16 * KILOBYTE, 64 * KILOBYTE, 256 * KILOBYTE, MEGABYTE, 16 * MEGABYTE]
for chunksize in CHUNKSIZES:
nchunks = DATA_SIZE // chunksize
batch = pa.RecordBatch.from_pandas(generate_data(chunksize, NCOLS))
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)
for i in range(nchunks):
stream_writer.write_batch(batch)
source = sink.get_result()
elapsed = get_timing(lambda: read_as_dataframe(pa.StreamReader, source), NITER)
result = (chunksize, elapsed)
print(result)
results.append(result)Fuente: habr.com
