

En este artículo, me gustaría hablar sobre las características de las matrices All Flash AccelStor que funcionan con una de las plataformas de virtualización más populares: VMware vSphere. En particular, concéntrese en aquellos parámetros que le ayudarán a obtener el máximo efecto al utilizar una herramienta tan poderosa como All Flash.

AccelStor NeoSapphire™ Todos los arreglos Flash son o dispositivos de nodo basados en unidades SSD con un enfoque fundamentalmente diferente para implementar el concepto de almacenamiento de datos y organizar el acceso a ellos utilizando tecnología patentada en lugar de los muy populares algoritmos RAID. Los arreglos brindan acceso en bloque a los hosts a través de interfaces Fibre Channel o iSCSI. Para ser justos, observamos que los modelos con interfaz ISCSI también tienen acceso a archivos como una buena ventaja. Pero en este artículo nos centraremos en el uso de protocolos de bloque como el más productivo para All Flash.
Todo el proceso de implementación y posterior configuración del funcionamiento conjunto del arreglo AccelStor y el sistema de virtualización VMware vSphere se puede dividir en varias etapas:
- Implementación de topología de conexión y configuración de red SAN;
- Configuración de matriz All Flash;
- Configuración de hosts ESXi;
- Configuración de máquinas virtuales.
Se utilizaron arreglos iSCSI y de canal de fibra AccelStor NeoSapphire™ como hardware de muestra. El software base es VMware vSphere 6.7U1.
Antes de implementar los sistemas descritos en este artículo, se recomienda encarecidamente que lea la documentación de VMware sobre problemas de rendimiento ( ) y configuración iSCSI ()
Topología de conexión y configuración de red SAN
Los componentes principales de una red SAN son los HBA en hosts ESXi, conmutadores SAN y nodos de matriz. Una topología típica para una red de este tipo sería la siguiente:
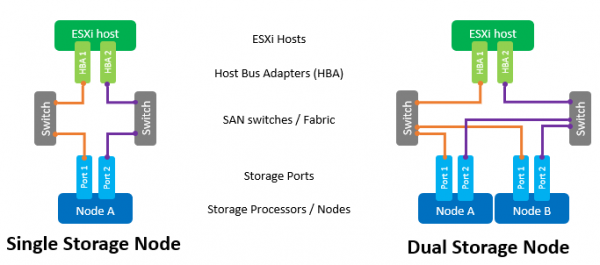
El término conmutador aquí se refiere tanto a un conmutador físico separado o un conjunto de conmutadores (Fabric) como a un dispositivo compartido entre diferentes servicios (VSAN en el caso de Fibre Channel y VLAN en el caso de iSCSI). El uso de dos interruptores/telas independientes eliminará un posible punto de falla.
Aunque es compatible, no se recomienda la conexión directa de hosts al arreglo. El rendimiento de las matrices All Flash es bastante alto. Y para obtener la máxima velocidad, se deben utilizar todos los puertos del conjunto. Por lo tanto, es obligatoria la presencia de al menos un conmutador entre los hosts y NeoSapphire™.
La presencia de dos puertos en el HBA host también es un requisito obligatorio para lograr el máximo rendimiento y garantizar la tolerancia a fallos.
Cuando se utiliza una interfaz Fibre Channel, se debe configurar la zonificación para eliminar posibles colisiones entre iniciadores y objetivos. Las zonas se basan en el principio de "un puerto iniciador, uno o más puertos de matriz".
Si utiliza una conexión a través de iSCSI en el caso de utilizar un conmutador compartido con otros servicios, entonces es imperativo aislar el tráfico iSCSI dentro de una VLAN separada. También se recomienda encarecidamente habilitar la compatibilidad con tramas gigantes (MTU = 9000) para aumentar el tamaño de los paquetes en la red y así reducir la cantidad de información general durante la transmisión. Sin embargo, vale la pena recordar que para un funcionamiento correcto es necesario cambiar el parámetro MTU en todos los componentes de la red a lo largo de la cadena "iniciador-interruptor-destino".
Configurar la matriz All Flash
La matriz se entrega a clientes con grupos ya formados. . Por lo tanto, no es necesario realizar ninguna acción para combinar unidades en una sola estructura. Solo necesita crear volúmenes del tamaño y cantidad requeridos.
Para mayor comodidad, existe una funcionalidad para la creación por lotes de varios volúmenes de un tamaño determinado a la vez. De forma predeterminada, se crean volúmenes delgados, ya que esto permite un uso más eficiente del espacio de almacenamiento disponible (incluida la compatibilidad con la recuperación de espacio). En términos de rendimiento, la diferencia entre volúmenes "finos" y "gruesos" no supera el 1%. Sin embargo, si desea “exprimir todo el jugo” de una matriz, siempre puede convertir cualquier volumen “delgado” en uno “grueso”. Pero conviene recordar que dicha operación es irreversible.
A continuación, queda "publicar" los volúmenes creados y establecer derechos de acceso a ellos desde los hosts mediante ACL (direcciones IP para iSCSI y WWPN para FC) y separación física por puertos de matriz. Para los modelos iSCSI, esto se hace creando un Destino.
Para los modelos FC, la publicación se produce mediante la creación de un LUN para cada puerto del arreglo.
Para acelerar el proceso de configuración, los hosts se pueden combinar en grupos. Además, si el host utiliza un HBA FC multipuerto (lo que en la práctica ocurre con mayor frecuencia), el sistema determina automáticamente que los puertos de dicho HBA pertenecen a un único host gracias a los WWPN que difieren en uno. La creación por lotes de Target/LUN también es compatible con ambas interfaces.
Una nota importante al utilizar la interfaz iSCSI es crear múltiples destinos para volúmenes a la vez para aumentar el rendimiento, ya que la cola en el destino no se puede cambiar y efectivamente será un cuello de botella.
Configuración de hosts ESXi
En el lado del host ESXi, la configuración básica se realiza de acuerdo con un escenario completamente esperado. Procedimiento para la conexión iSCSI:
- Agregar un adaptador iSCSI de software (no es necesario si ya se ha agregado o si está utilizando un adaptador iSCSI de hardware);
- Crear un vSwitch a través del cual pasará el tráfico iSCSI y agregarle un enlace ascendente físico y VMkernal;
- Agregar direcciones de matriz a Dynamic Discovery;
- Creación de almacén de datos
Algunas notas importantes:
- En el caso general, por supuesto, puede utilizar un vSwitch existente, pero en el caso de un vSwitch independiente, administrar la configuración del host será mucho más fácil.
- Es necesario separar el tráfico iSCSI y de administración en enlaces físicos y/o VLAN independientes para evitar problemas de rendimiento.
- Las direcciones IP de VMkernal y los puertos correspondientes de la matriz All Flash deben estar dentro de la misma subred, nuevamente debido a problemas de rendimiento.
- Para garantizar la tolerancia a fallos según las reglas de VMware, vSwitch debe tener al menos dos enlaces ascendentes físicos
- Si se utilizan Jumbo Frames, debe cambiar la MTU tanto de vSwitch como de VMkernal
- Sería útil recordarle que según las recomendaciones de VMware para los adaptadores físicos que se utilizarán para trabajar con tráfico iSCSI, es necesario configurar Teaming y Failover. En particular, cada VMkernal debe funcionar a través de un solo enlace ascendente, el segundo enlace ascendente debe cambiarse al modo no utilizado. Para lograr tolerancia a fallas, debe agregar dos VMkernals, cada uno de los cuales funcionará a través de su propio enlace ascendente.
Adaptador VMkernel (vmk#)
Adaptador de red física (vmnic#)
vmk1 (Almacenamiento01)
Adaptadores activos
vmnic2
Adaptadores no utilizados
vmnic3
vmk2 (Almacenamiento02)
Adaptadores activos
vmnic3
Adaptadores no utilizados
vmnic2
No se requieren pasos preliminares para conectarse a través de Fibre Channel. Puede crear inmediatamente un almacén de datos.
Después de crear el almacén de datos, debe asegurarse de que la política Round Robin para las rutas al destino/LUN se utilice como la de mayor rendimiento.
De forma predeterminada, la configuración de VMware prevé el uso de esta política de acuerdo con el esquema: 1000 solicitudes a través de la primera ruta, las siguientes 1000 solicitudes a través de la segunda ruta, etc. Dicha interacción entre el host y la matriz de dos controladores estará desequilibrada. Por lo tanto, recomendamos configurar la política Round Robin = 1 parámetro a través de Esxcli/PowerCLI.
Parámetros
Para Esxcli:
- Listar LUN disponibles
Lista de dispositivos nmp de almacenamiento esxcli
- Copiar nombre del dispositivo
- Cambiar la política de round robin
esxcli almacenamiento nmp psp roundrobin dispositivoconfig conjunto —tipo=iops —iops=1 —dispositivo=“ID_dispositivo”
La mayoría de las aplicaciones modernas están diseñadas para intercambiar grandes paquetes de datos con el fin de maximizar la utilización del ancho de banda y reducir la carga de la CPU. Por lo tanto, ESXi emite de forma predeterminada solicitudes de E/S al dispositivo de almacenamiento en fragmentos de hasta 32767 KB. Sin embargo, en algunos escenarios, el intercambio de porciones más pequeñas será más productivo. Para los arreglos AccelStor, estos son los siguientes escenarios:
- La máquina virtual usa UEFI en lugar de Legacy BIOS
- Utiliza replicación de vSphere
Para tales escenarios, se recomienda cambiar el valor del parámetro Disk.DiskMaxIOSize a 4096.
Para conexiones iSCSI, se recomienda cambiar el parámetro Tiempo de espera de inicio de sesión a 30 (5 predeterminado) para aumentar la estabilidad de la conexión y deshabilitar el retraso DelayedAck para confirmaciones de paquetes reenviados. Ambas opciones están en vSphere Client: Host → Configurar → Almacenamiento → Adaptadores de almacenamiento → Opciones avanzadas para el adaptador iSCSI
Un punto bastante sutil es la cantidad de volúmenes utilizados para el almacén de datos. Está claro que para facilitar la gestión, existe el deseo de crear un volumen grande para todo el volumen de la matriz. Sin embargo, la presencia de varios volúmenes y, en consecuencia, un almacén de datos tiene un efecto beneficioso en el rendimiento general (más información sobre las colas a continuación). Por ello, recomendamos crear al menos dos volúmenes.
Hasta hace relativamente poco, VMware aconsejaba limitar el número de máquinas virtuales en un almacén de datos, nuevamente para obtener el mayor rendimiento posible. Sin embargo, ahora, especialmente con la expansión del VDI, este problema ya no es tan grave. Pero esto no cancela la regla de larga data: distribuir máquinas virtuales que requieren IO intensiva en diferentes almacenes de datos. Para determinar el número óptimo de máquinas virtuales por volumen, nada mejor que dentro de su infraestructura.
Configurar máquinas virtuales
No existen requisitos especiales a la hora de configurar máquinas virtuales, o más bien, son bastante comunes:
- Usar la versión de VM más alta posible (compatibilidad)
- Es más cuidadoso configurar el tamaño de la RAM cuando se colocan máquinas virtuales densamente, por ejemplo, en VDI (ya que de forma predeterminada, al inicio, se crea un archivo de paginación de un tamaño acorde con la RAM, lo que consume capacidad útil y tiene un efecto en la actuación final)
- Utilice las versiones de adaptadores más productivas en términos de IO: tipo de red VMXNET 3 y SCSI tipo PVSCSI
- Utilice el tipo de disco Thick Provision Eager Zeroed para obtener el máximo rendimiento y Thin Provisioning para una máxima utilización del espacio de almacenamiento.
- Si es posible, limite el funcionamiento de máquinas críticas que no sean de E/S mediante el límite de disco virtual
- Asegúrese de instalar VMware Tools
Notas sobre colas
La cola (o E/S pendientes) es la cantidad de solicitudes de entrada/salida (comandos SCSI) que están esperando ser procesadas en un momento dado para un dispositivo/aplicación específico. En caso de desbordamiento de la cola, se emiten errores QFULL, lo que finalmente resulta en un aumento en el parámetro de latencia. Cuando se utilizan sistemas de almacenamiento en disco (eje), en teoría, cuanto mayor sea la cola, mayor será su rendimiento. Sin embargo, no debes abusar de él, ya que es fácil toparte con QFULL. En el caso de los sistemas All Flash, por un lado, todo es algo más sencillo: después de todo, la matriz tiene latencias en órdenes de magnitud menores y, por lo tanto, la mayoría de las veces no es necesario regular por separado el tamaño de las colas. Pero, por otro lado, en algunos escenarios de uso (fuerte sesgo en los requisitos de IO para máquinas virtuales específicas, pruebas de rendimiento máximo, etc.) es necesario, si no cambiar los parámetros de las colas, al menos comprender qué indicadores se puede lograr y lo principal es de qué manera.
En la matriz AccelStor All Flash no hay límites en relación con los volúmenes o los puertos de E/S. Si es necesario, incluso un solo volumen puede recibir todos los recursos de la matriz. La única limitación de la cola es para los destinos iSCSI. Es por esta razón que anteriormente se indicó la necesidad de crear varios objetivos (idealmente hasta 8 piezas) para cada volumen para superar este límite. Repitamos también que los arreglos AccelStor son soluciones muy productivas. Por lo tanto, debe utilizar todos los puertos de interfaz del sistema para lograr la máxima velocidad.
Del lado del host ESXi, la situación es completamente diferente. El propio anfitrión aplica la práctica de igualdad de acceso a los recursos para todos los participantes. Por lo tanto, existen colas de E/S independientes para el sistema operativo invitado y el HBA. Las colas hacia el sistema operativo invitado se combinan desde las colas hacia el adaptador SCSI virtual y el disco virtual:
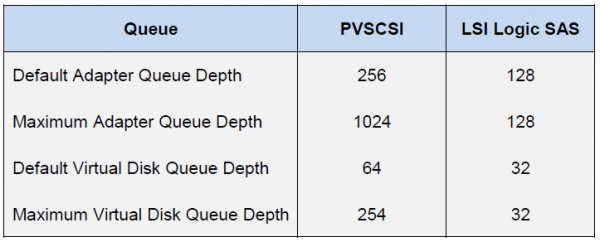
La cola al HBA depende del tipo/proveedor específico:
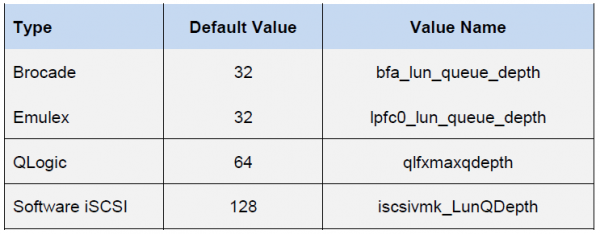
El rendimiento final de la máquina virtual estará determinado por el límite de profundidad de cola más bajo entre los componentes del host.
Gracias a estos valores podemos evaluar los indicadores de rendimiento que podemos obtener en una configuración particular. Por ejemplo, queremos saber el rendimiento teórico de una máquina virtual (sin enlace de bloques) con una latencia de 0.5 ms. Entonces sus IOPS = (1,000/latencia) * E/S pendientes (límite de profundidad de la cola)
Примеры
ejemplo 1
- Adaptador FC Emulex HBA
- Una máquina virtual por almacén de datos
- Adaptador SCSI paravirtual de VMware
Aquí el límite de profundidad de la cola lo determina Emulex HBA. Por lo tanto IOPS = (1000/0.5)*32 = 64K
ejemplo 2
- Adaptador de software VMware iSCSI
- Una máquina virtual por almacén de datos
- Adaptador SCSI paravirtual de VMware
Aquí el límite de profundidad de la cola ya está determinado por el adaptador SCSI paravirtual. Por lo tanto IOPS = (1000/0.5)*64 = 128K
Los mejores modelos de matrices All Flash AccelStor (por ejemplo, ) son capaces de ofrecer un rendimiento de escritura de 700 4 IOPS en bloques de 11 K. Con tal tamaño de bloque, es bastante obvio que una sola máquina virtual no es capaz de cargar dicha matriz. Para hacer esto, necesitará 1 (por ejemplo 6) o 2 (por ejemplo XNUMX) máquinas virtuales.
Como resultado, con la configuración correcta de todos los componentes descritos de un centro de datos virtual, se pueden obtener resultados impresionantes en términos de rendimiento.
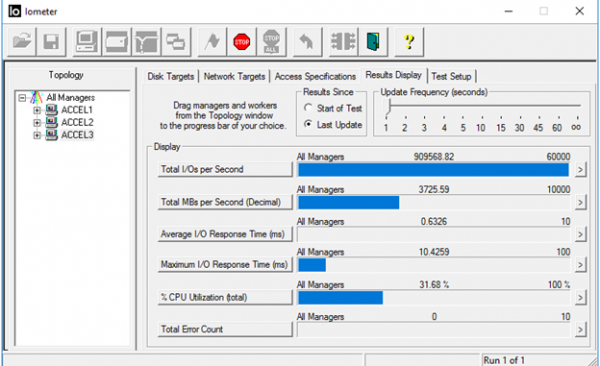
4K aleatorio, 70% lectura/30% escritura
De hecho, el mundo real es mucho más complejo de lo que puede describirse con una fórmula sencilla. Un host siempre aloja varias máquinas virtuales con diferentes configuraciones y requisitos de E/S. Y el procesamiento de E/S lo maneja el procesador anfitrión, cuya potencia no es infinita. Entonces, para desbloquear todo el potencial del mismo en realidad, necesitarás tres hosts. Además, las aplicaciones que se ejecutan dentro de máquinas virtuales realizan sus propios ajustes. Por lo tanto, para un tamaño preciso ofrecemos Todas las matrices Flash dentro de la infraestructura del cliente en tareas actuales reales.
Fuente: habr.com
