


En Badoo monitoreamos constantemente las nuevas tecnologías y evaluamos si vale la pena usarlas en nuestro sistema. Nos gustaría compartir uno de estos estudios con la comunidad. Está dedicado a Loki, un sistema de agregación de registros.
Loki es una solución para almacenar y ver registros, y esta pila también proporciona un sistema flexible para analizarlos y enviar datos a Prometheus. En mayo, se lanzó otra actualización, que los creadores promueven activamente. Estábamos interesados en lo que puede hacer Loki, qué capacidades ofrece y en qué medida puede actuar como una alternativa a ELK, la pila que utilizamos ahora.
¿Qué es Loki?
Grafana Loki es un conjunto de componentes para un sistema completo para trabajar con registros. A diferencia de otros sistemas similares, Loki se basa en la idea de indexar solo metadatos de registros: etiquetas (igual que en Prometheus) y comprimir los registros en fragmentos separados.
,
Antes de entrar en lo que puedes hacer con Loki, quiero aclarar lo que queremos decir con “la idea de indexar solo metadatos”. Comparemos el enfoque de Loki y el enfoque de indexación en soluciones tradicionales como Elasticsearch, usando el ejemplo de una línea del registro de nginx:
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"Los sistemas tradicionales analizan la fila completa, incluidos los campos con una gran cantidad de valores únicos de user_id y item_id, y almacenan todo en índices grandes. La ventaja de este enfoque es que puede ejecutar consultas complejas rápidamente, ya que casi todos los datos están en el índice. Pero esto tiene un costo, ya que el índice se vuelve grande, lo que se traduce en requisitos de memoria. Como resultado, el índice de registro de texto completo es comparable en tamaño a los propios registros. Para poder buscarlo rápidamente, el índice debe cargarse en la memoria. Y cuantos más registros, más rápido crece el índice y más memoria consume.
El enfoque de Loki requiere que solo se extraigan los datos necesarios de la cadena, cuyo número de valores es pequeño. De esta manera obtenemos un índice pequeño y podemos buscar los datos filtrándolos por tiempo y campos indexados, y luego escaneando el resto con expresiones regulares o búsquedas de subcadenas. El proceso no parece el más rápido, pero Loki divide la solicitud en varias partes y las ejecuta en paralelo, procesando una gran cantidad de datos en poco tiempo. La cantidad de fragmentos y solicitudes paralelas que contienen es configurable; así, la cantidad de datos que se pueden procesar por unidad de tiempo depende linealmente de la cantidad de recursos proporcionados.
Esta compensación entre un índice rápido grande y un índice pequeño de fuerza bruta paralelo le permite a Loki controlar el costo del sistema. Puede configurarse y ampliarse de forma flexible según sus necesidades.
La pila de Loki consta de tres componentes: Promtail, Loki, Grafana. Promtail recopila registros, los procesa y los envía a Loki. Loki se los queda. Y Grafana puede solicitar datos de Loki y mostrarlos. En general, Loki se puede utilizar no sólo para almacenar registros y buscar en ellos. Toda la pila proporciona grandes oportunidades para procesar y analizar datos entrantes utilizando el método Prometheus.
Puede encontrar una descripción del proceso de instalación. .
Búsqueda de registro
Puede buscar los registros en una interfaz especial de Grafana: Explorer. Las consultas utilizan el lenguaje LogQL, que es muy similar al PromQL utilizado en Prometheus. En principio, se puede considerar como un grep distribuido.
La interfaz de búsqueda se ve así:
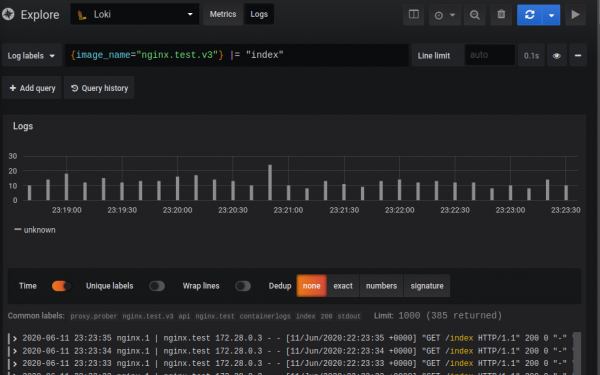
La solicitud en sí consta de dos partes: selector y filtro. El selector es una búsqueda que utiliza metadatos indexados (etiquetas) que se asignan a los registros, y el filtro es una cadena de búsqueda o expresión regular que filtra los registros definidos por el selector. En el ejemplo dado: entre llaves hay un selector, todo lo que sigue es un filtro.
{image_name="nginx.promtail.test"} |= "index"Debido a la forma en que funciona Loki, no puedes realizar consultas sin un selector, pero las etiquetas se pueden hacer tan generales como quieras.
Un selector es un valor clave-valor entre llaves. Puede combinar selectores y especificar diferentes condiciones de búsqueda utilizando los operadores =, != o expresiones regulares:
{instance=~"kafka-[23]",name!="kafka-dev"}
// Найдёт логи с лейблом instance, имеющие значение kafka-2, kafka-3, и исключит dev Un filtro es texto o expresión regular que filtrará todos los datos recibidos por el selector.
Es posible obtener gráficos ad-hoc basados en los datos recibidos en modo métricas. Por ejemplo, puede averiguar con qué frecuencia aparece una entrada que contiene el índice de cadena en los registros de nginx:
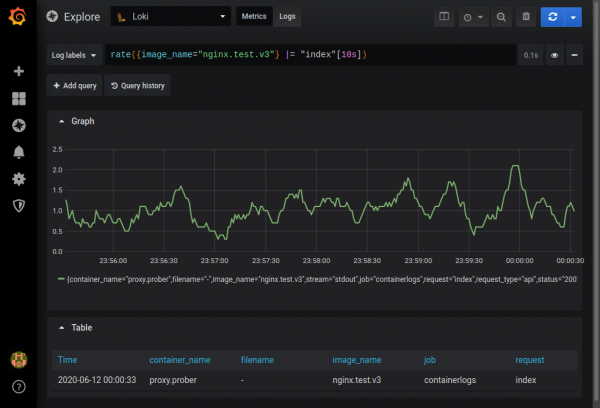
Puede encontrar una descripción completa de las capacidades en la documentación. .
análisis de registros
Hay varias formas de recopilar registros:
- Usando Promtail, un componente estándar de la pila para recopilar registros.
- Directamente desde el contenedor acoplable usando
- Utilice Fluentd o Fluent Bit, que pueden enviar datos a Loki. A diferencia de Promtail, tienen analizadores listos para usar para casi cualquier tipo de registro y también pueden manejar registros de varias líneas.
Por lo general, Promtail se utiliza para el análisis. Hace tres cosas:
- Encuentra fuentes de datos.
- Les adjunta etiquetas.
- Envía datos a Loki.
Actualmente, Promtail puede leer registros de archivos locales y del diario systemd. Debe instalarse en cada máquina desde la que se recopilan los registros.
Hay integración con Kubernetes: Promtail automáticamente, a través de la API REST de Kubernetes, reconoce el estado del clúster y recopila registros de un nodo, servicio o pod, publicando inmediatamente etiquetas basadas en metadatos de Kubernetes (nombre del pod, nombre del archivo, etc.) .
También puede colgar etiquetas basadas en datos del registro usando Pipeline. Pipeline Promtail puede constar de cuatro tipos de etapas. Más detalles en Inmediatamente notaré algunos matices.
- Etapas de análisis. Esta es la etapa RegEx y JSON. En esta etapa, extraemos datos de los registros en el llamado mapa extraído. Podemos extraer de JSON simplemente copiando los campos que necesitamos en el mapa extraído, o mediante expresiones regulares (RegEx), donde los grupos con nombre se "asignan" al mapa extraído. El mapa extraído es un almacén de valores-clave, donde clave es el nombre del campo y valor es su valor de los registros.
- Transformar etapas. Esta etapa tiene dos opciones: transformar, donde establecemos las reglas de transformación, y fuente, la fuente de datos para la transformación del mapa extraído. Si no existe tal campo en el mapa extraído, se creará. De esta forma es posible crear etiquetas que no estén basadas en el mapa extraído. En esta etapa podemos manipular los datos en el mapa extraído usando un bastante poderoso . Además, debemos recordar que el mapa extraído se carga por completo durante el análisis, lo que permite, por ejemplo, comprobar el valor que contiene: "{{if .tag}el valor de la etiqueta existe{end}}". La plantilla admite condiciones, bucles y algunas funciones de cadena como Reemplazar y Recortar.
- Etapas de acción. En esta etapa, puedes hacer algo con lo extraído:
- Cree una etiqueta a partir de los datos extraídos, que Loki indexará.
- Cambie o establezca la hora del evento desde el registro.
- Cambia los datos (texto de registro) que irán a Loki.
- Crea métricas.
- Etapas de filtrado. La etapa de coincidencia, donde podemos enviar entradas que no necesitamos a /dev/null o reenviarlas para su posterior procesamiento.
Utilizando un ejemplo de procesamiento de registros nginx normales, mostraré cómo se pueden analizar registros utilizando Promtail.
Para la prueba, tomemos una imagen nginx jwilder/nginx-proxy:alpine modificada y un pequeño demonio que puede consultarse a sí mismo a través de HTTP como nginx-proxy. El demonio tiene varios puntos finales, a los que puede dar respuestas de diferentes tamaños, con diferentes estados HTTP y con diferentes retrasos.
Recopilaremos registros de los contenedores acoplables, que se pueden encontrar en la ruta /var/lib/docker/containers/ / -json.log
En docker-compose.yml configuramos Promtail y especificamos la ruta a la configuración:
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
Agregue la ruta a los registros a promtail.yml (hay una opción "docker" en la configuración, que hace lo mismo en una línea, pero no sería tan claro):
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # for linux onlyCuando esta configuración esté habilitada, los registros de todos los contenedores se enviarán a Loki. Para evitar esto, cambiamos la configuración del nginx de prueba en docker-compose.yml; agregamos un campo de etiqueta de registro:
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"Editando promtail.yml y configurando Pipeline. La entrada incluye registros del siguiente tipo:
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /api/index HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.096"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /200 HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.000"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}Etapa de canalización:
- json:
expressions:
stream: stream
attrs: attrs
tag: attrs.tagExtraemos los campos stream, attrs, attrs.tag (si existen) del JSON entrante y los colocamos en el mapa extraído.
- regex:
expression: ^(?P<image_name>([^|]+))|(?P<container_name>([^|]+))$
source: "tag"Si fuera posible colocar el campo de etiqueta en el mapa extraído, entonces usando la expresión regular extraemos los nombres de la imagen y el contenedor.
- labels:
image_name:
container_name:Asignamos etiquetas. Si las claves image_name y container_name se encuentran en los datos extraídos, sus valores se asignarán a las etiquetas correspondientes.
- match:
selector: '{job="docker",container_name="",image_name=""}'
action: dropDescartamos todos los registros que no tengan etiquetas instaladas nombre_imagen y nombre_contenedor.
- match:
selector: '{image_name="nginx.promtail.test"}'
stages:
- json:
expressions:
row: logPara todos los registros cuyo nombre_imagen sea nginx.promtail.test, extraiga el campo de registro del registro de origen y colóquelo en el mapa extraído con la clave de fila.
- regex:
# suppress forego colors
expression: .+nginx.+|.+[0m(?P<virtual_host>[a-z_.-]+) +(?P<nginxlog>.+)
source: logrowLimpiamos la línea de entrada con expresiones regulares y extraemos el host virtual nginx y la línea de registro de nginx.
- regex:
source: nginxlog
expression: ^(?P<ip>[w.]+) - (?P<user>[^ ]*) [(?P<timestamp>[^ ]+).*] "(?P<method>[^ ]*) (?P<request_url>[^ ]*) (?P<request_http_protocol>[^ ]*)" (?P<status>[d]+) (?P<bytes_out>[d]+) "(?P<http_referer>[^"]*)" "(?P<user_agent>[^"]*)"( "(?P<response_time>[d.]+)")?Analiza el registro de nginx usando expresiones regulares.
- regex:
source: request_url
expression: ^.+.(?P<static_type>jpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
source: request_url
expression: ^/photo/(?P<photo>[^/?.]+).*$
- regex:
source: request_url
expression: ^/api/(?P<api_request>[^/?.]+).*$Analizar request_url. Con la ayuda de expresiones regulares, determinamos el propósito de la solicitud: estática, fotos, API y configuramos la clave correspondiente en el mapa extraído.
- template:
source: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"Usando operadores condicionales en Plantilla, verificamos los campos instalados en el mapa extraído y configuramos los valores requeridos para el campo request_type: foto, estático, API. Asigne otro si falla. request_type ahora contiene el tipo de solicitud.
- labels:
api_request:
virtual_host:
request_type:
status:Configuramos las etiquetas api_request, virtual_host, request_type y status (estado HTTP) en función de lo que logramos poner en el mapa extraído.
- output:
source: nginx_log_rowCambiar salida. Ahora el registro nginx limpio del mapa extraído va a Loki.
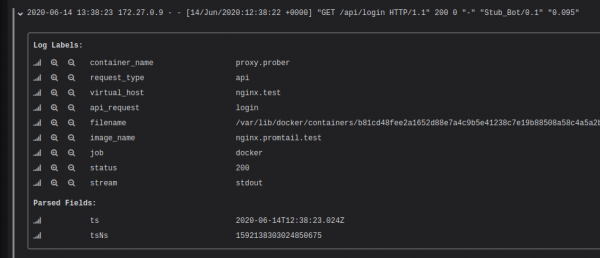
Después de ejecutar la configuración anterior, puede ver que a cada entrada se le asignan etiquetas según los datos del registro.
Una cosa a tener en cuenta es que recuperar etiquetas con una gran cantidad de valores (cardinalidad) puede ralentizar significativamente a Loki. Es decir, no debes poner, por ejemplo, user_id en el índice. Lea más sobre esto en el artículo “" Pero esto no significa que no se pueda buscar por user_id sin índices. Debe utilizar filtros al realizar la búsqueda (“captar” los datos), y el índice aquí actúa como un identificador de flujo.
Visualización de registros
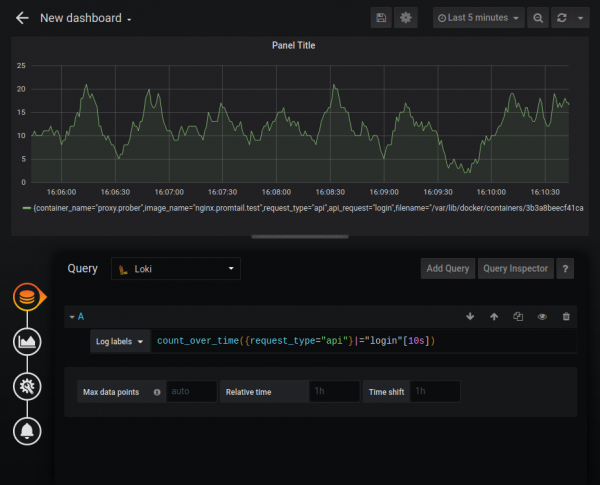
Loki puede actuar como fuente de datos para gráficos de Grafana utilizando LogQL. Se admiten las siguientes funciones:
- tasa: número de registros por segundo;
- contar a lo largo del tiempo: el número de registros en el rango especificado.
También existen funciones de agregación Sum, Avg y otras. Puede crear gráficos bastante complejos, por ejemplo, un gráfico del número de errores HTTP:
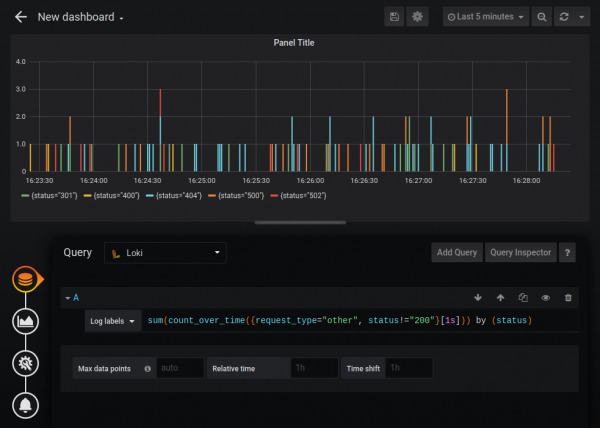
La fuente de datos estándar Loki tiene una funcionalidad algo reducida en comparación con la fuente de datos Prometheus (por ejemplo, no se puede cambiar la leyenda), pero Loki se puede conectar como fuente con el tipo Prometheus. No estoy seguro de si se trata de un comportamiento documentado, pero a juzgar por la respuesta de los desarrolladores "”, por ejemplo, es completamente legal y Loki es totalmente compatible con PromQL.
Agregue Loki como fuente de datos con el tipo Prometheus y agregue la URL /loki:

Y puedes hacer gráficos, como si trabajáramos con métricas de Prometheus:
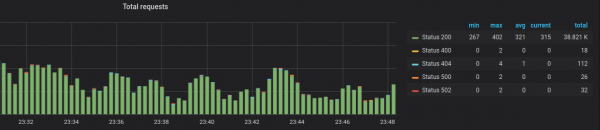
Creo que la discrepancia en la funcionalidad es temporal y los desarrolladores la solucionarán en el futuro.
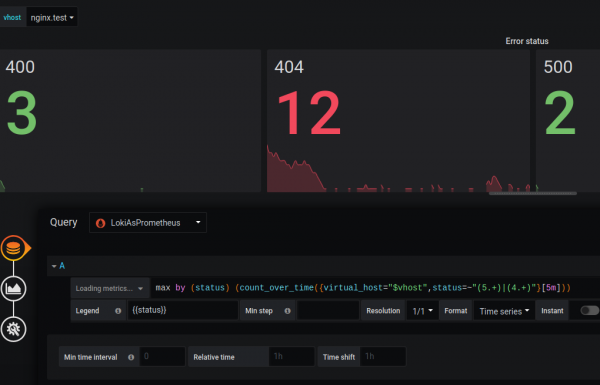
Métrica
Loki ofrece la posibilidad de extraer métricas numéricas de los registros y enviarlas a Prometheus. Por ejemplo, el registro nginx contiene la cantidad de bytes por respuesta, así como, con cierta modificación del formato de registro estándar, el tiempo en segundos que tardó en responder. Estos datos se pueden extraer y enviar a Prometheus.
Agregue otra sección a promtail.yml:
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "response time ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "response bytes sum"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "response bytes count"
source: bytes_out
config:
action: incLa opción le permite definir y actualizar métricas basadas en datos del mapa extraído. Estas métricas no se envían a Loki; aparecen en el punto final Promtail/metrics. Prometheus debe configurarse para recibir los datos recibidos en esta etapa. En el ejemplo anterior, para request_type=“api” recopilamos una métrica de histograma. Con este tipo de métricas conviene obtener percentiles. Para estática y fotografía, recopilamos la suma de bytes y el número de filas en las que recibimos bytes para calcular el promedio.
Leer más sobre métricas .
Abra un puerto en Promtail:
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"Asegúrese de que aparezcan métricas con el prefijo promtail_custom:
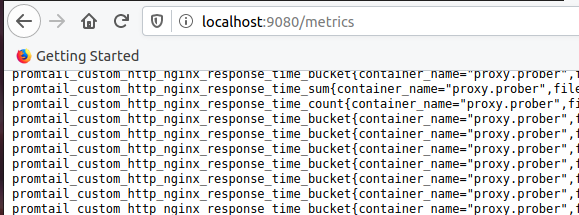
Configurando Prometeo. Agregar oferta de empleo:
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']Y dibujamos un gráfico:
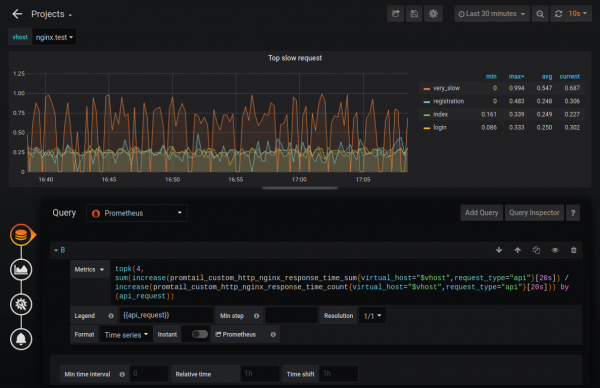
De esta forma podrá conocer, por ejemplo, las cuatro solicitudes más lentas. También puede configurar la supervisión de estas métricas.
Escalado
Loki puede estar en modo binario único o en modo fragmentado (modo escalable horizontalmente). En el segundo caso, puede guardar datos en la nube y los fragmentos y el índice se almacenan por separado. La versión 1.5 introduce la capacidad de almacenar en un solo lugar, pero aún no se recomienda utilizarlo en producción.
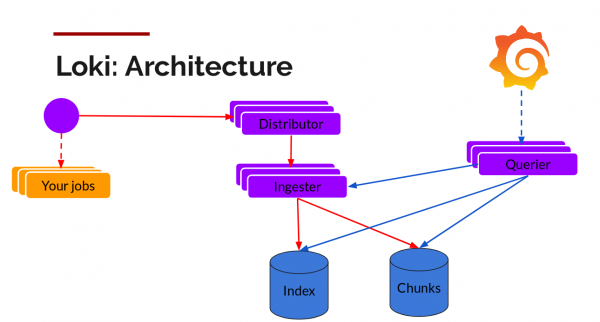
Los fragmentos se pueden almacenar en un almacenamiento compatible con S3 y se pueden usar bases de datos escalables horizontalmente para almacenar índices: Cassandra, BigTable o DynamoDB. Otras partes de Loki (distribuidores (para escritura) y consulta (para consultas)) no tienen estado y también escalan horizontalmente.
En la conferencia DevOpsDays Vancouver 2019, uno de los participantes, Callum Styan, anunció que con Loki su proyecto tiene petabytes de registros con un índice de menos del 1% del tamaño total: “.
Comparación de Loki y ELK
Tamaño del índice
Para probar el tamaño del índice resultante, tomé registros del contenedor nginx para el cual se configuró el Pipeline anterior. El archivo de registro contenía 406 líneas con un volumen total de 624 MB. Los registros se generaron en una hora, aproximadamente 109 entradas por segundo.
Ejemplo de dos líneas del registro:

Cuando ELK lo indexó, esto dio un tamaño de índice de 30,3 MB:
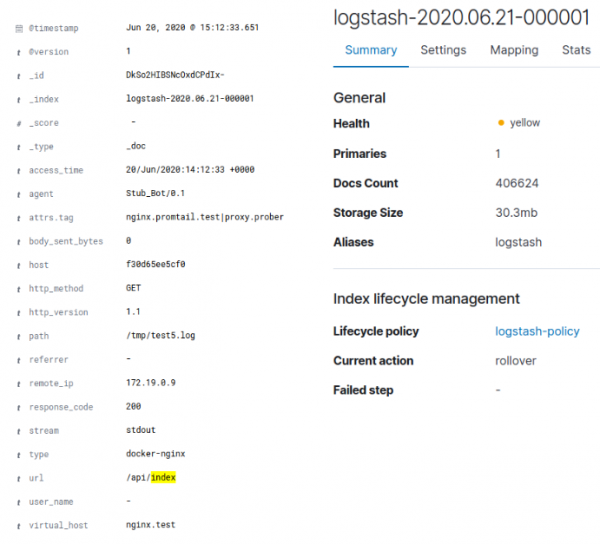
En el caso de Loki, esto resultó en aproximadamente 128 KB de índice y aproximadamente 3,8 MB de datos en fragmentos. Vale la pena señalar que el registro fue generado artificialmente y no contenía una gran variedad de datos. Un simple gzip en el registro JSON de Docker original con datos proporcionó una compresión del 95,4% y, teniendo en cuenta el hecho de que solo se envió el registro nginx limpio a Loki, es comprensible una compresión de hasta 4 MB. El número total de valores únicos para las etiquetas de Loki fue 35, lo que explica el pequeño tamaño del índice. Para ELK también se borró el registro. Así, Loki comprimió los datos originales en un 96% y ELK en un 70%.
Consumo de memoria
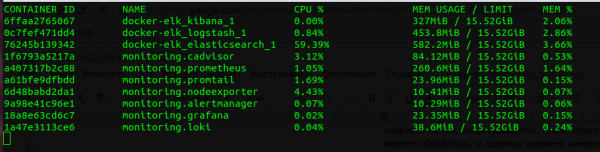
Si comparamos toda la pila de Prometheus y ELK, entonces Loki "come" varias veces menos. Está claro que un servicio Go consume menos que un servicio Java, y comparar el tamaño de JVM Heap Elasticsearch y la memoria asignada para Loki es incorrecto, pero vale la pena señalar que Loki usa mucha menos memoria. La ventaja de su CPU no es tan obvia, pero también está presente.
velocidad
Loki “devora” registros más rápido. La velocidad depende de muchos factores (qué tipo de registros son, qué tan sofisticados somos para analizarlos, red, disco, etc.), pero definitivamente es más alta que ELK (en mi prueba, aproximadamente el doble). Esto se explica por el hecho de que Loki introduce muchos menos datos en el índice y, en consecuencia, dedica menos tiempo a la indexación. Con la velocidad de búsqueda, la situación es la contraria: Loki se ralentiza notablemente con datos de más de varios gigabytes, mientras que la velocidad de búsqueda de ELK no depende del tamaño de los datos.
Búsqueda de registro
Loki es significativamente inferior a ELK en términos de capacidades de búsqueda de registros. Grep con expresiones regulares es algo fuerte, pero es inferior a una base de datos para adultos. La falta de consultas de rango, la agregación solo por etiquetas, la imposibilidad de buscar sin etiquetas: todo esto nos limita a la hora de buscar información de interés en Loki. Esto no implica que no se pueda encontrar nada usando Loki, pero define el flujo de trabajo con registros, cuando se encuentra por primera vez un problema en los gráficos de Prometheus y luego se busca lo que sucedió en los registros usando estas etiquetas.
Interfaz
En primer lugar, es hermoso (lo siento, no pude resistirme). Grafana tiene una interfaz atractiva, pero Kibana tiene muchas más funciones.
Pros y contras de Loki
Una de las ventajas es que Loki se integra con Prometheus, por lo que obtenemos métricas y alertas listas para usar. Es conveniente para recopilar registros y almacenarlos desde Kubernetes Pods, ya que tiene descubrimiento de servicios heredado de Prometheus y adjunta etiquetas automáticamente.
De las desventajas: mala documentación. Algunas cosas, como las características y capacidades de Promtail, las descubrí solo en el proceso de estudiar el código, los beneficios del código abierto. Otra desventaja son las débiles capacidades de análisis. Por ejemplo, Loki no puede analizar registros de varias líneas. Además, las desventajas incluyen el hecho de que Loki es una tecnología relativamente joven (la versión 1.0 fue en noviembre de 2019).
Conclusión
Loki es una tecnología 100% interesante que es adecuada para proyectos pequeños y medianos, lo que le permite resolver muchos problemas de agregación de registros, búsqueda de registros, monitoreo y análisis de registros.
No usamos Loki en Badoo porque tenemos una pila ELK que nos conviene y que ha ido creciendo con varias soluciones personalizadas a lo largo de los años. Para nosotros, el obstáculo es buscar entre los registros. Con casi 100 GB de registros por día, para nosotros es importante poder encontrar todo y un poco más y hacerlo rápidamente. Para los gráficos y el seguimiento utilizamos otras soluciones que se adaptan a nuestras necesidades y se integran entre sí. La pila de Loki tiene beneficios tangibles, pero no nos brindará más de lo que ya tenemos y sus beneficios ciertamente no superarán el costo de la migración.
Y aunque después de la investigación quedó claro que no podemos utilizar Loki, esperamos que este post te ayude en tu elección.
Se encuentra el repositorio con el código utilizado en el artículo. .
Fuente: habr.com
