

Buenas tardes Mi nombre es Danil Lipovoy, nuestro equipo en Sbertech comenzó a utilizar HBase como almacenamiento de datos operativos. En el transcurso de su estudio se ha acumulado una experiencia que quise sistematizar y describir (esperamos que sea de utilidad para muchos). Todos los experimentos siguientes se realizaron con las versiones de HBase 1.2.0-cdh5.14.2 y 2.0.0-cdh6.0.0-beta1.
- Arquitectura general
- Escribir datos en HBASE
- Lectura de datos de HBASE
- Almacenamiento en caché de datos
- Procesamiento de datos por lotes MultiGet/MultiPut
- Estrategia para dividir tablas en regiones (división)
- Tolerancia a fallos, compactación y localidad de datos.
- Configuración y rendimiento
- Pruebas de estrés
- Hallazgos
1. Arquitectura general
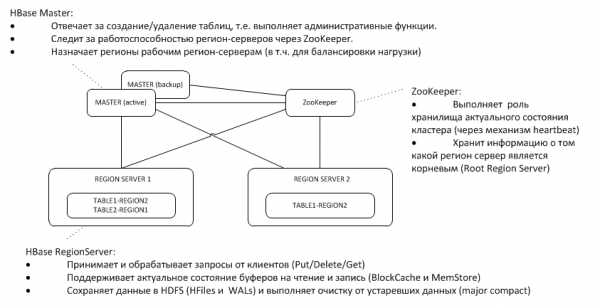
El Maestro de respaldo escucha los latidos del activo en el nodo ZooKeeper y, en caso de desaparición, asume las funciones del maestro.
2. Escribir datos en HBASE
Primero, veamos el caso más simple: escribir un objeto clave-valor en una tabla usando put(rowkey). El cliente primero debe averiguar dónde está ubicado el servidor de región raíz (RRS), que almacena la tabla hbase:meta. Recibe esta información de ZooKeeper. Después de lo cual accede a RRS y lee la tabla hbase:meta, de la cual extrae información sobre qué RegionServer (RS) es responsable de almacenar datos para una clave de fila determinada en la tabla de interés. Para uso futuro, el cliente almacena en caché la metatabla y, por lo tanto, las llamadas posteriores son más rápidas, directamente a RS.
A continuación, RS, al recibir una solicitud, primero la escribe en WriteAheadLog (WAL), que es necesario para la recuperación en caso de falla. Luego guarda los datos en MemStore. Este es un búfer en la memoria que contiene un conjunto ordenado de claves para una región determinada. Una tabla se puede dividir en regiones (particiones), cada una de las cuales contiene un conjunto de claves disjunto. Esto le permite colocar regiones en diferentes servidores para lograr un mayor rendimiento. Sin embargo, a pesar de la obviedad de esta afirmación, veremos más adelante que esto no funciona en todos los casos.
Después de colocar una entrada en MemStore, se devuelve una respuesta al cliente de que la entrada se guardó correctamente. Sin embargo, en realidad se almacena sólo en un búfer y llega al disco sólo después de un cierto período de tiempo o cuando se llena con nuevos datos.
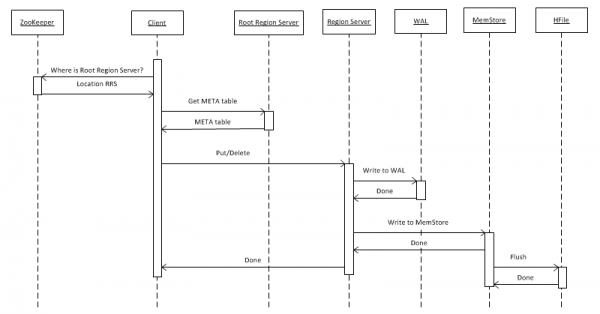
Al realizar la operación "Eliminar", los datos no se eliminan físicamente. Simplemente se marcan como eliminados y la destrucción misma se produce en el momento de llamar a la función compacta principal, que se describe con más detalle en el párrafo 7.
Los archivos en formato HFile se acumulan en HDFS y de vez en cuando se lanza el proceso compacto menor, que simplemente fusiona archivos pequeños en otros más grandes sin eliminar nada. Con el tiempo, esto se convierte en un problema que sólo aparece al leer datos (volveremos a esto un poco más adelante).
Además del proceso de carga descrito anteriormente, existe un procedimiento mucho más eficaz, que es quizás el lado más fuerte de esta base de datos: BulkLoad. Se basa en el hecho de que formamos HFiles de forma independiente y los guardamos en el disco, lo que nos permite escalar perfectamente y alcanzar velocidades muy decentes. De hecho, la limitación aquí no es HBase, sino las capacidades del hardware. A continuación se muestran los resultados de arranque en un clúster que consta de 16 RegionServers y 16 NodeManager YARN (CPU Xeon E5-2680 v4 a 2.40 GHz * 64 subprocesos), versión HBase 1.2.0-cdh5.14.2.
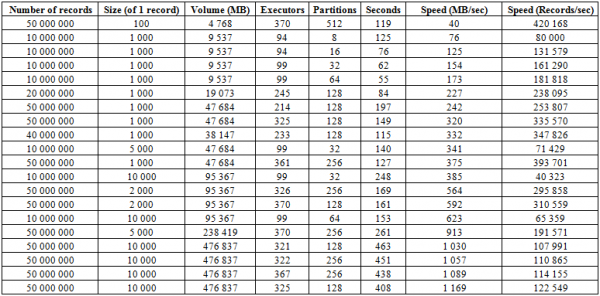
Aquí puede ver que al aumentar la cantidad de particiones (regiones) en la tabla, así como los ejecutores de Spark, obtenemos un aumento en la velocidad de descarga. Además, la velocidad depende del volumen de grabación. Los bloques grandes dan un aumento en MB/seg, los bloques pequeños en el número de registros insertados por unidad de tiempo, en igualdad de condiciones.
También puedes empezar a cargar en dos mesas al mismo tiempo y obtener el doble de velocidad. A continuación puede ver que escribir bloques de 10 KB en dos tablas a la vez se produce a una velocidad de aproximadamente 600 MB/s en cada una (total 1275 MB/s), lo que coincide con la velocidad de escritura en una tabla de 623 MB/s (ver No. 11 arriba)

Pero la segunda ejecución con registros de 50 KB muestra que la velocidad de descarga está aumentando ligeramente, lo que indica que se está acercando a los valores límite. Al mismo tiempo, debe tener en cuenta que prácticamente no se crea ninguna carga en HBASE, todo lo que se requiere de él es primero proporcionar datos de hbase:meta y, después de forrar HFiles, restablecer los datos de BlockCache y guardar el Búfer MemStore al disco, si no está vacío.
3. Leer datos de HBASE
Si asumimos que el cliente ya tiene toda la información de hbase:meta (ver punto 2), entonces la solicitud va directamente al RS donde se almacena la clave requerida. Primero, la búsqueda se realiza en MemCache. Independientemente de si hay datos o no, la búsqueda también se realiza en el búfer BlockCache y, si es necesario, en HFiles. Si se encontraron datos en el archivo, se colocan en BlockCache y se devolverán más rápido en la siguiente solicitud. La búsqueda en HFile es relativamente rápida gracias al uso del filtro Bloom, es decir. después de leer una pequeña cantidad de datos, determina inmediatamente si este archivo contiene la clave requerida y, en caso contrario, pasa al siguiente.
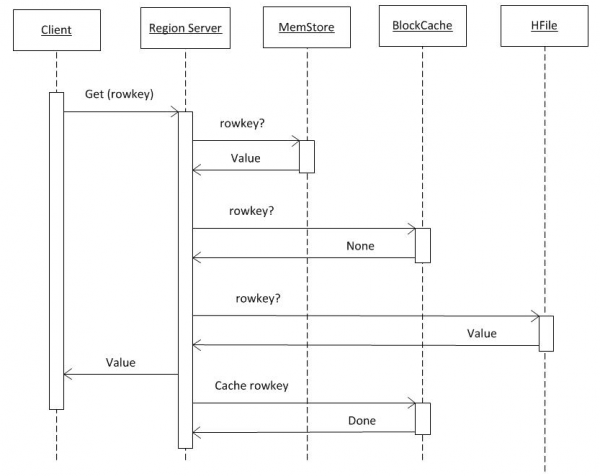
Habiendo recibido datos de estas tres fuentes, RS genera una respuesta. En particular, puede transferir varias versiones encontradas de un objeto a la vez si el cliente solicitó el control de versiones.
4. Almacenamiento en caché de datos
Los buffers MemStore y BlockCache ocupan hasta el 80% de la memoria RS en el montón asignada (el resto está reservado para tareas de servicio RS). Si el modo de uso típico es tal que los procesos escriben y leen inmediatamente los mismos datos, entonces tiene sentido reducir BlockCache y aumentar MemStore, porque Cuando los datos escritos no ingresan al caché para su lectura, BlockCache se usará con menos frecuencia. El búfer BlockCache consta de dos partes: LruBlockCache (siempre en el montón) y BucketCache (normalmente fuera del montón o en un SSD). BucketCache debe usarse cuando hay muchas solicitudes de lectura y no encajan en LruBlockCache, lo que conduce al trabajo activo de Garbage Collector. Al mismo tiempo, no debe esperar un aumento radical en el rendimiento al usar el caché de lectura, pero volveremos a esto en el párrafo 8.
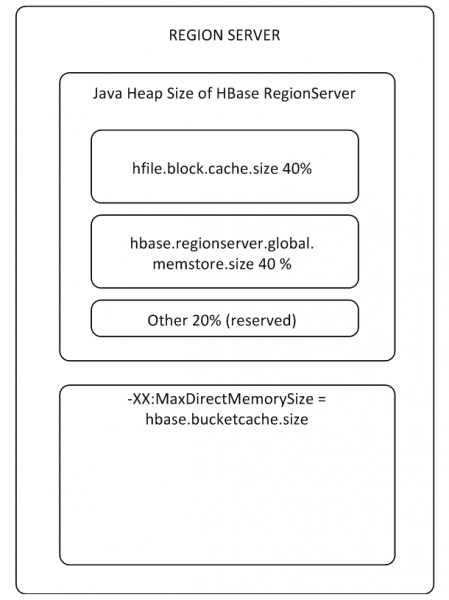
Hay un BlockCache para todo el RS y hay un MemStore para cada tabla (uno para cada familia de columnas).
cómo en teoría, al escribir, los datos no van a la caché y, de hecho, los parámetros CACHE_DATA_ON_WRITE para la tabla y "Caché de datos en escritura" para RS se establecen en falso. Sin embargo, en la práctica, si escribimos datos en MemStore, luego los descargamos en el disco (borrándolos así), luego eliminamos el archivo resultante y luego, al ejecutar una solicitud de obtención, recibiremos los datos con éxito. Además, incluso si desactiva completamente BlockCache y llena la tabla con datos nuevos, luego reinicia MemStore en el disco, los elimina y los solicita desde otra sesión, aún así se recuperarán de algún lugar. Entonces HBase almacena no solo datos, sino también misterios misteriosos.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
El parámetro "Caché de DATOS al leer" está establecido en falso. Si tiene alguna idea, bienvenido a discutirla en los comentarios.
5. Procesamiento de datos por lotes MultiGet/MultiPut
Procesar solicitudes individuales (Obtener/Pujar/Eliminar) es una operación bastante costosa, por lo que, si es posible, debe combinarlas en una Lista o Lista, lo que le permitirá obtener un aumento significativo en el rendimiento. Esto es especialmente cierto para la operación de escritura, pero al leer existe el siguiente problema. El siguiente gráfico muestra el tiempo necesario para leer 50 registros de MemStore. La lectura se realizó en un hilo y el eje horizontal muestra el número de claves en la solicitud. Aquí puede ver que cuando se aumenta a mil claves en una solicitud, el tiempo de ejecución disminuye, es decir. aumenta la velocidad. Sin embargo, con el modo MSLAB habilitado de forma predeterminada, después de este umbral comienza una caída radical en el rendimiento y cuanto mayor sea la cantidad de datos en el registro, mayor será el tiempo de funcionamiento.
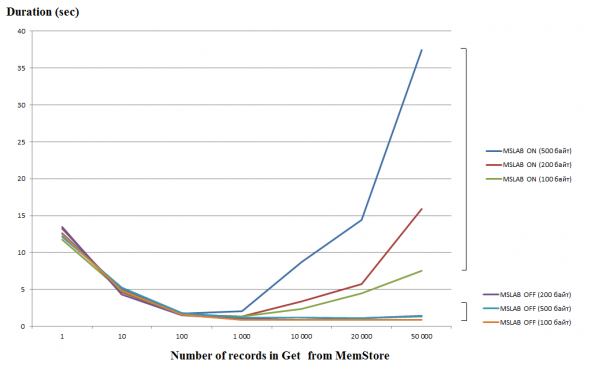
Las pruebas se realizaron en una máquina virtual de 8 núcleos, versión HBase 2.0.0-cdh6.0.0-beta1.
El modo MSLAB está diseñado para reducir la fragmentación del montón, que se produce debido a la mezcla de datos de generación nueva y antigua. Como solución alternativa, cuando MSLAB está habilitado, los datos se colocan en celdas relativamente pequeñas (fragmentos) y se procesan en fragmentos. Como resultado, cuando el volumen del paquete de datos solicitado excede el tamaño asignado, el rendimiento cae drásticamente. Por otro lado, desactivar este modo tampoco es aconsejable, ya que provocará paradas debido a la GC en momentos de procesamiento intensivo de datos. Una buena solución es aumentar el volumen de la celda en el caso de escritura activa vía put al mismo tiempo que se lee. Vale la pena señalar que el problema no ocurre si, después de grabar, ejecuta el comando de descarga, que restablece MemStore al disco, o si carga usando BulkLoad. La siguiente tabla muestra que las consultas desde MemStore para datos más grandes (y de la misma cantidad) provocan ralentizaciones. Sin embargo, al aumentar el tamaño del fragmento, el tiempo de procesamiento vuelve a la normalidad.
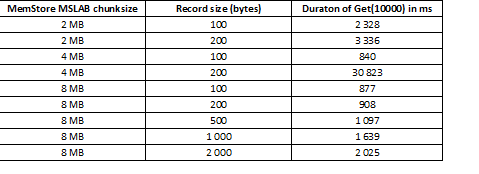
Además de aumentar el tamaño del fragmento, ayuda dividir los datos por región, es decir, división de mesa. Esto da como resultado que lleguen menos solicitudes a cada región y, si caben en una celda, la respuesta sigue siendo buena.
6. Estrategia para dividir tablas en regiones (división)
Dado que HBase es un almacenamiento clave-valor y la partición se realiza por clave, es extremadamente importante dividir los datos de manera uniforme en todas las regiones. Por ejemplo, dividir una tabla de este tipo en tres partes dará como resultado que los datos se dividan en tres regiones:
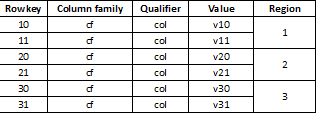
Sucede que esto conduce a una fuerte desaceleración si los datos cargados más tarde parecen, por ejemplo, valores largos, la mayoría de ellos comenzando con el mismo dígito, por ejemplo:
1000001
1000002
...
1100003
Dado que las claves se almacenan como una matriz de bytes, todas comenzarán igual y pertenecerán a la misma región n.° 1 que almacena este rango de claves. Existen varias estrategias de partición:
HexStringSplit: convierte la clave en una cadena codificada hexadecimal en el rango "00000000" => "FFFFFFFF" y rellena a la izquierda con ceros.
UniformSplit: convierte la clave en una matriz de bytes con codificación hexadecimal en el rango "00" => "FF" y rellena a la derecha con ceros.
Además, puede especificar cualquier rango o conjunto de claves para dividir y configurar la división automática. Sin embargo, uno de los enfoques más simples y efectivos es UniformSplit y el uso de concatenación hash, por ejemplo, el par de bytes más significativo al ejecutar la clave a través de la función CRC32(rowkey) y la propia clave de fila:
hash + clave de fila
Entonces todos los datos se distribuirán uniformemente entre las regiones. Al leer, los primeros dos bytes simplemente se descartan y la clave original permanece. RS también controla la cantidad de datos y claves en la región y, si se exceden los límites, los divide automáticamente en partes.
7. Tolerancia a fallos y localidad de datos.
Dado que solo una región es responsable de cada conjunto de claves, la solución a los problemas asociados con fallas o desmantelamiento de RS es almacenar todos los datos necesarios en HDFS. Cuando RS cae, el maestro lo detecta mediante la ausencia de un latido en el nodo ZooKeeper. Luego asigna la región servida a otro RS y dado que los HFiles se almacenan en un sistema de archivos distribuido, el nuevo propietario los lee y continúa entregando los datos. Sin embargo, dado que algunos de los datos pueden estar en MemStore y no tuvieron tiempo de ingresar a HFiles, para restaurar el historial de operaciones se utiliza WAL, que también se almacena en HDFS. Una vez aplicados los cambios, RS puede responder a las solicitudes, pero el movimiento lleva al hecho de que algunos de los datos y los procesos que los atienden terminan en nodos diferentes, es decir, La localidad está disminuyendo.
La solución al problema es la compactación importante: este procedimiento mueve los archivos a los nodos que son responsables de ellos (donde se encuentran sus regiones), como resultado de lo cual, durante este procedimiento, la carga en la red y los discos aumenta considerablemente. Sin embargo, en el futuro el acceso a los datos se acelerará notablemente. Además, major_compaction fusiona todos los HFiles en un solo archivo dentro de una región y también limpia los datos según la configuración de la tabla. Por ejemplo, puede especificar el número de versiones de un objeto que se deben conservar o el tiempo de vida después del cual el objeto se elimina físicamente.
Este procedimiento puede tener un efecto muy positivo en el funcionamiento de HBase. La siguiente imagen muestra cómo el rendimiento se degradó como resultado de la grabación de datos activa. Aquí puede ver cómo 40 subprocesos escribieron en una tabla y 40 subprocesos leyeron datos simultáneamente. Los hilos de escritura generan cada vez más archivos H, que son leídos por otros hilos. Como resultado, es necesario eliminar cada vez más datos de la memoria y, finalmente, el GC comienza a funcionar, lo que prácticamente paraliza todo el trabajo. El inicio de una compactación importante condujo a la limpieza de los escombros resultantes y al restablecimiento de la productividad.
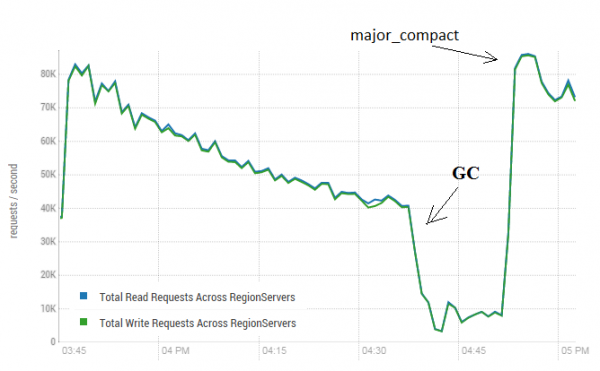
La prueba se realizó en 3 DataNodes y 4 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 subprocesos). HBase versión 1.2.0-cdh5.14.2
Vale la pena señalar que se lanzó una compactación importante en una tabla "en vivo", en la que se escribían y leían datos activamente. En Internet se decía que esto podría provocar una respuesta incorrecta al leer los datos. Para comprobarlo, se lanzó un proceso que generó nuevos datos y los escribió en una tabla. Después de lo cual inmediatamente leí y verifiqué si el valor resultante coincidía con lo escrito. Mientras se ejecutaba este proceso, se realizó una compactación importante unas 200 veces y no se registró ni una sola falla. Quizás el problema aparece rara vez y solo durante una carga alta, por lo que es más seguro detener los procesos de escritura y lectura según lo planeado y realizar una limpieza para evitar tales caídas del GC.
Además, la compactación importante no afecta el estado de MemStore; para vaciarlo en el disco y compactarlo, necesita usar flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Configuración y rendimiento
Como ya se mencionó, HBase muestra su mayor éxito cuando no necesita hacer nada al ejecutar BulkLoad. Sin embargo, esto se aplica a la mayoría de los sistemas y personas. Sin embargo, esta herramienta es más adecuada para almacenar datos de forma masiva en bloques grandes, mientras que si el proceso requiere múltiples solicitudes de lectura y escritura competitivas, se utilizan los comandos Get y Put descritos anteriormente. Para determinar los parámetros óptimos, se realizaron lanzamientos con varias combinaciones de parámetros y configuraciones de la tabla:
- Se lanzaron 10 subprocesos simultáneamente 3 veces seguidas (llamémoslo bloque de subprocesos).
- El tiempo de operación de todos los subprocesos en un bloque se promedió y fue el resultado final de la operación del bloque.
- Todos los hilos trabajaron con la misma mesa.
- Antes de cada inicio del bloque de hilo, se realizó una compactación importante.
- Cada bloque realizó solo una de las siguientes operaciones:
-Poner
-Conseguir
—Obtener+Poner
- Cada bloque realizó 50 iteraciones de su operación.
- El tamaño de bloque de un registro es 100 bytes, 1000 bytes o 10000 bytes (aleatorio).
- Se lanzaron bloques con diferente número de claves solicitadas (ya sea una clave o 10).
- Los bloques se ejecutaron bajo diferentes configuraciones de tabla. Parámetros cambiados:
— BlockCache = activado o desactivado
— Tamaño de bloque = 65 KB o 16 KB
— Particiones = 1, 5 o 30
— MSLAB = habilitado o deshabilitado
Entonces el bloque se ve así:
a. El modo MSLAB se activó o desactivó.
b. Se creó una tabla para la cual se configuraron los siguientes parámetros: BlockCache = true/none, BlockSize = 65/16 Kb, Partition = 1/5/30.
C. La compresión se estableció en GZ.
d. Se lanzaron 10 subprocesos simultáneamente realizando 1/10 operaciones put/get/get+put en esta tabla con registros de 100/1000/10000 bytes, realizando 50 consultas seguidas (claves aleatorias).
mi. El punto d se repitió tres veces.
F. Se promedió el tiempo de funcionamiento de todos los hilos.
Se probaron todas las combinaciones posibles. Es predecible que la velocidad disminuirá a medida que aumente el tamaño del registro, o que deshabilitar el almacenamiento en caché provocará una desaceleración. Sin embargo, el objetivo era comprender el grado y la importancia de la influencia de cada parámetro, por lo que los datos recopilados se introdujeron en la entrada de una función de regresión lineal, que permite evaluar la importancia mediante la estadística t. A continuación se muestran los resultados de los bloques que realizan operaciones Put. Conjunto completo de combinaciones 2*2*3*2*3 = 144 opciones + 72 tk. algunos se hicieron dos veces. Por tanto, hay 216 carreras en total:
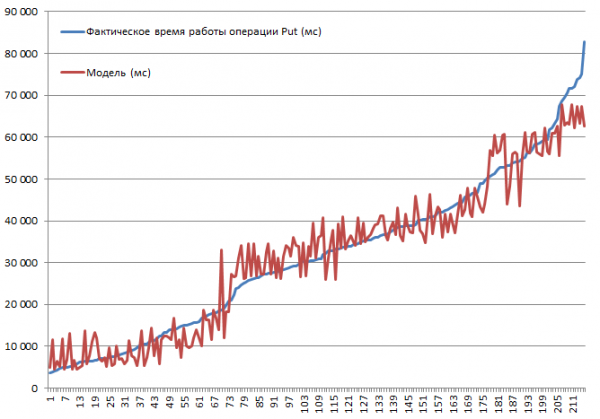
Las pruebas se llevaron a cabo en un miniclúster que consta de 3 DataNodes y 4 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 subprocesos). HBase versión 1.2.0-cdh5.14.2.
La velocidad de inserción más alta de 3.7 segundos se obtuvo con el modo MSLAB desactivado, en una tabla con una partición, con BlockCache habilitado, BlockSize = 16, registros de 100 bytes, 10 piezas por paquete.
La velocidad de inserción más baja de 82.8 segundos se obtuvo con el modo MSLAB habilitado, en una tabla con una partición, con BlockCache habilitado, BlockSize = 16, registros de 10000 bytes, 1 cada uno.
Ahora veamos el modelo. Vemos la buena calidad del modelo basado en R2, pero está absolutamente claro que la extrapolación aquí está contraindicada. El comportamiento real del sistema cuando cambian los parámetros no será lineal; este modelo no es necesario para hacer predicciones, sino para comprender lo que sucedió dentro de los parámetros dados. Por ejemplo, aquí vemos por el criterio del Estudiante que los parámetros BlockSize y BlockCache no importan para la operación Put (que generalmente es bastante predecible):

Pero el hecho de que aumentar el número de particiones conduzca a una disminución del rendimiento es algo inesperado (ya hemos visto el impacto positivo de aumentar el número de particiones con BulkLoad), aunque es comprensible. En primer lugar, para el procesamiento es necesario generar solicitudes para 30 regiones en lugar de una, y el volumen de datos no es tal que esto genere ganancias. En segundo lugar, el tiempo total de funcionamiento está determinado por el RS más lento y, dado que el número de DataNodes es menor que el número de RS, algunas regiones tienen localidad cero. Bueno, veamos los cinco primeros:

Ahora evaluemos los resultados de la ejecución de bloques Get:

El número de particiones ha perdido importancia, lo que probablemente se explique por el hecho de que los datos se almacenan bien en caché y la caché de lectura es el parámetro más significativo (estadísticamente). Naturalmente, aumentar la cantidad de mensajes en una solicitud también es muy útil para el rendimiento. Puntajes máximos:

Bueno, finalmente, veamos el modelo del bloque que primero realizó get y luego put:

Todos los parámetros son importantes aquí. Y los resultados de los dirigentes:

9. Pruebas de carga
Bueno, finalmente lanzaremos una carga más o menos decente, pero siempre es más interesante cuando tienes algo con qué comparar. En el sitio web de DataStax, el desarrollador clave de Cassandra, hay NT de varios almacenamientos NoSQL, incluida la versión HBase 0.98.6-1. La carga se realizó mediante 40 subprocesos, tamaño de datos de 100 bytes, discos SSD. El resultado de probar las operaciones de lectura, modificación y escritura mostró los siguientes resultados.
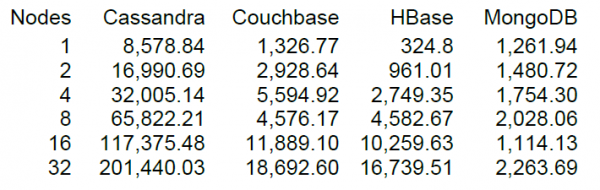
Según tengo entendido, la lectura se realizó en bloques de 100 registros y para 16 nodos HBase, la prueba DataStax mostró un rendimiento de 10 mil operaciones por segundo.
Es una suerte que nuestro clúster también tenga 16 nodos, pero no es muy “afortunado” que cada uno tenga 64 núcleos (hilos), mientras que en la prueba DataStax solo hay 4. Por otro lado, ellos tienen unidades SSD, mientras que nosotros tenemos HDD o más la nueva versión de HBase y la utilización de la CPU durante la carga prácticamente no aumentó significativamente (visualmente entre un 5 y un 10 por ciento). Sin embargo, intentemos empezar a utilizar esta configuración. Configuración de tabla predeterminada, la lectura se realiza en el rango de claves de 0 a 50 millones de forma aleatoria (es decir, esencialmente nueva cada vez). La tabla contiene 50 millones de registros, divididos en 64 particiones. Las claves se codifican mediante crc32. La configuración de la tabla es predeterminada, MSLAB está habilitado. Al iniciar 40 subprocesos, cada subproceso lee un conjunto de 100 claves aleatorias e inmediatamente escribe los 100 bytes generados en estas claves.
Stand: 16 DataNode y 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 hilos). HBase versión 1.2.0-cdh5.14.2.
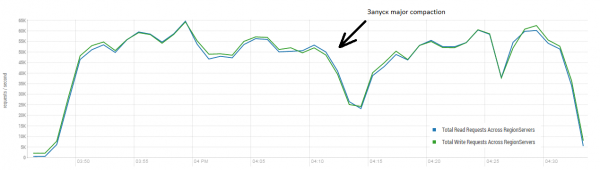
El resultado medio se acerca a las 40 operaciones por segundo, lo que es significativamente mejor que en la prueba DataStax. Sin embargo, con fines experimentales, puedes cambiar ligeramente las condiciones. Es muy poco probable que todo el trabajo se realice exclusivamente en una mesa y también sólo en claves únicas. Supongamos que hay un determinado conjunto de claves "calientes" que genera la carga principal. Por lo tanto, intentemos crear una carga con registros más grandes (10 KB), también en lotes de 100, en 4 tablas diferentes y limitando el rango de claves solicitadas a 50 mil. El siguiente gráfico muestra el lanzamiento de 40 hilos, cada hilo dice un conjunto de 100 claves e inmediatamente escribe 10 KB aleatorios en estas claves.
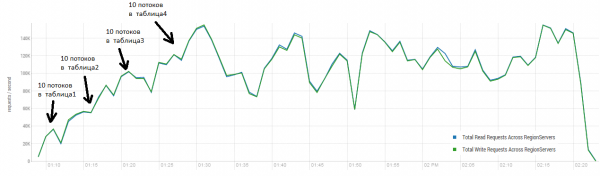
Stand: 16 DataNode y 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 hilos). HBase versión 1.2.0-cdh5.14.2.
Durante la carga, se inició una compactación importante varias veces, como se muestra arriba, sin este procedimiento, el rendimiento se degradará gradualmente, sin embargo, también surge una carga adicional durante la ejecución. Las reducciones se deben a varias razones. A veces los subprocesos terminaban de funcionar y había una pausa mientras se reiniciaban, a veces aplicaciones de terceros creaban una carga en el clúster.
Leer y escribir inmediatamente es uno de los escenarios de trabajo más difíciles para HBase. Si solo realiza solicitudes de transferencia pequeñas, por ejemplo de 100 bytes, combinándolas en paquetes de 10 a 50 mil piezas, puede obtener cientos de miles de operaciones por segundo, y la situación es similar con las solicitudes de solo lectura. Vale la pena señalar que los resultados son radicalmente mejores que los obtenidos por DataStax, sobre todo debido a las solicitudes en bloques de 50 mil.
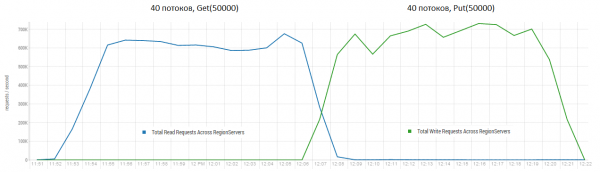
Stand: 16 DataNode y 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 hilos). HBase versión 1.2.0-cdh5.14.2.
10. Conclusiones
Este sistema está configurado de forma bastante flexible, pero aún se desconoce la influencia de un gran número de parámetros. Algunos de ellos fueron probados, pero no se incluyeron en el conjunto de pruebas resultante. Por ejemplo, los experimentos preliminares mostraron una importancia insignificante de un parámetro como DATA_BLOCK_ENCODING, que codifica información utilizando valores de celdas vecinas, lo cual es comprensible para datos generados aleatoriamente. Si utiliza una gran cantidad de objetos duplicados, la ganancia puede ser significativa. En general, podemos decir que HBase da la impresión de ser una base de datos bastante seria y bien pensada, que puede resultar bastante productiva a la hora de realizar operaciones con grandes bloques de datos. Sobre todo si es posible separar en el tiempo los procesos de lectura y escritura.
Si hay algo en su opinión que no se ha revelado lo suficiente, estoy dispuesto a contárselo con más detalle. Te invitamos a compartir tu experiencia o discutir si no estás de acuerdo con algo.
Fuente: habr.com
