


VictoriaMetrics es un DBMS rápido y escalable para almacenar y procesar datos en forma de series temporales (un registro forma un tiempo y un conjunto de valores correspondientes a este tiempo, por ejemplo, obtenidos a través de un sondeo periódico del estado de los sensores o recopilar métricas).


Mi nombre es Pavel Kolobaev. DevOps, SRE, LeroyMerlin, todo es como un código: se trata de nosotros: de mí y de otros empleados de LeroyMerlin.
Hay una nube basada en OpenStack. Hay un pequeño enlace al radar técnico.

Está construido sobre la base del hierro de Kubernetes, así como sobre todos los servicios relacionados con OpenStack y registro.
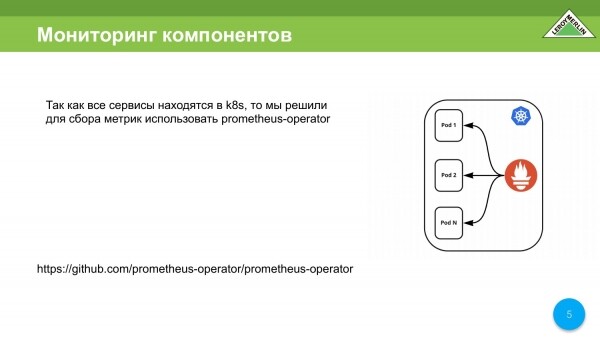
Este es el esquema que teníamos en desarrollo. Cuando desarrollamos todo esto, teníamos el operador Prometheus, que almacenaba datos dentro del propio clúster K8s. Automáticamente encuentra lo que necesita ser fregado y lo pone debajo de sus pies, en términos generales.

Tendremos que mover todos los datos fuera del clúster de Kubernetes, porque si algo sucede, debemos entender qué y dónde.
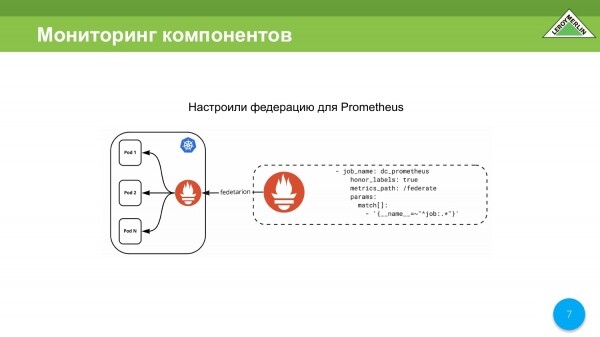
La primera solución es que usamos la federación cuando tenemos un Prometheus de terceros cuando vamos al clúster de Kubernetes a través del mecanismo de federación.

Pero hay algunos problemas menores aquí. En nuestro caso, los problemas empezaron cuando teníamos 250 métricas, y cuando llegamos a las 000 métricas, nos dimos cuenta de que no podíamos trabajar así. Hemos aumentado scrape_timeout a 400 segundos.
¿Por qué tuvimos que hacer esto? Prometheus comienza a contar el tiempo de espera desde el inicio del momento de recogida. No importa que los datos sigan llegando. Si durante este período de tiempo especificado los datos no se fusionaron y la sesión no se cerró a través de http, entonces se considera que la sesión ha fallado y los datos no llegan a Prometheus.
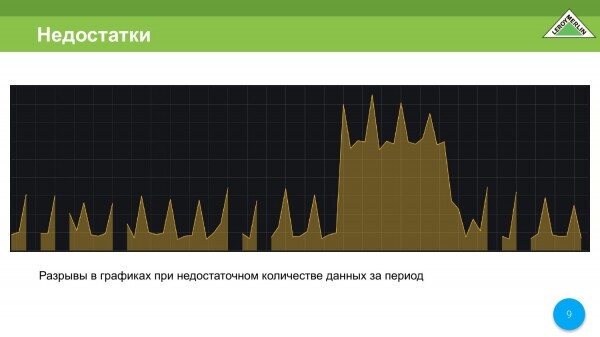
Todo el mundo conoce los gráficos que obtenemos cuando falta parte de los datos. Los gráficos están rotos y no estamos contentos con eso.
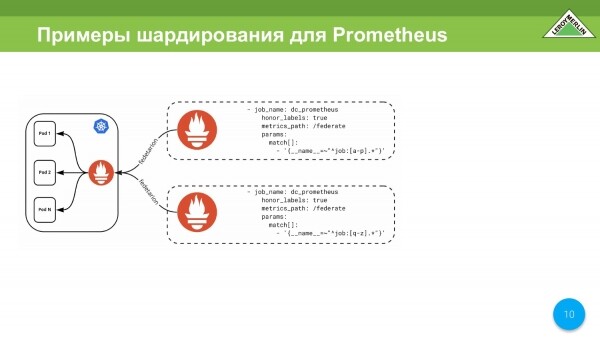
La siguiente opción es la fragmentación basada en dos Prometheus diferentes a través del mismo mecanismo de federación.
Por ejemplo, simplemente tómelos y fragmentelos por nombre. Esto también se puede usar, pero decidimos seguir adelante.
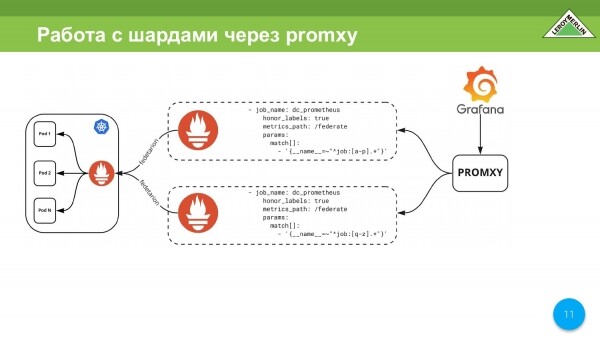
Ahora tendremos que procesar estos fragmentos de alguna manera. Puede tomar promxy, que desciende al área del fragmento, multiplica los datos. Funciona con dos fragmentos como un único punto de entrada. Esto se puede implementar a través de promxy, pero es demasiado complicado por ahora.
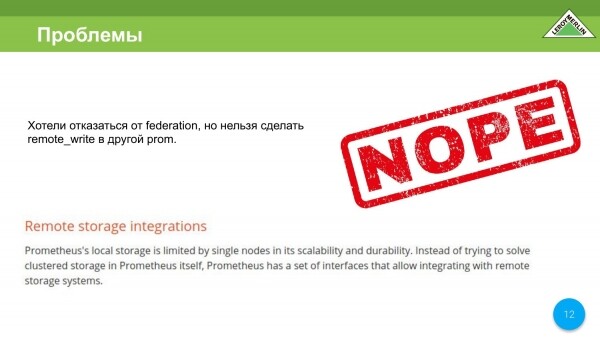
La primera opción: queremos abandonar el mecanismo de federación, porque es muy lento.
Los desarrolladores de Prometheus dicen explícitamente: "Chicos, usen otro TimescaleDB, porque no admitiremos el almacenamiento a largo plazo de métricas". Esta no es su tarea. 
Anotamos en un papel que aún debemos descargar afuera, para no almacenar todo en un solo lugar.
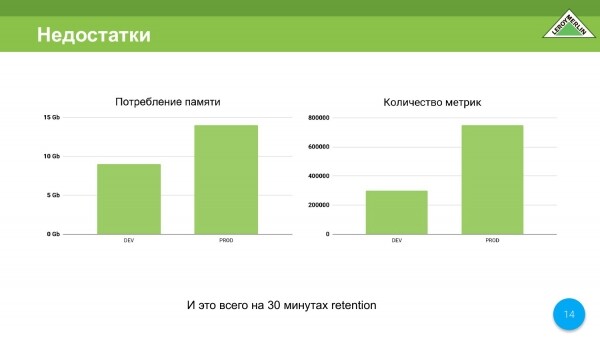
La segunda desventaja es el consumo de memoria. Sí, entiendo que muchos dirán que en 2020 un par de gigas de memoria valen un centavo, pero sin embargo.
Ahora tenemos un entorno de desarrollo y producción. En desarrollo, esto es alrededor de 9 gigabytes por 350 000 métricas. En producción, esto es 14 gigabytes con una pequeña métrica de 780. Al mismo tiempo, solo tenemos 000 minutos de tiempo de retención. Esto es malo. Y ahora explicaré por qué.
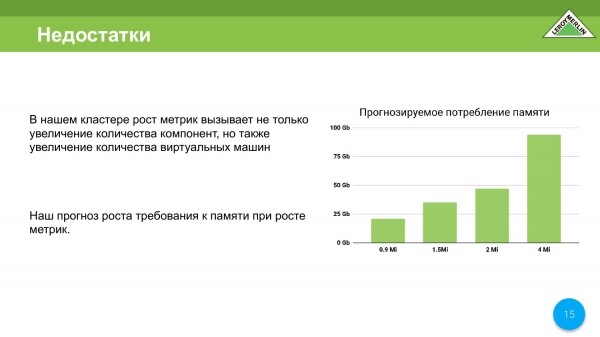
Hacemos un cálculo, es decir, con un millón y medio de métricas, y ya estamos cerca de ellas, en la etapa de diseño obtenemos 35-37 gigabytes de memoria. Pero ya por 4 millones de métricas, ya se requieren alrededor de 90 gigabytes de memoria. Es decir, se calculó según la fórmula proporcionada por los desarrolladores de Prometheus. Observamos la correlación y nos dimos cuenta de que no queremos pagar un par de millones por un servidor solo para monitorear.
No solo aumentaremos la cantidad de máquinas, también monitorearemos las propias máquinas virtuales. Por tanto, cuantas más máquinas virtuales, más métricas de diversa índole, etc. Tendremos un crecimiento especial de nuestro clúster en cuanto a métricas.
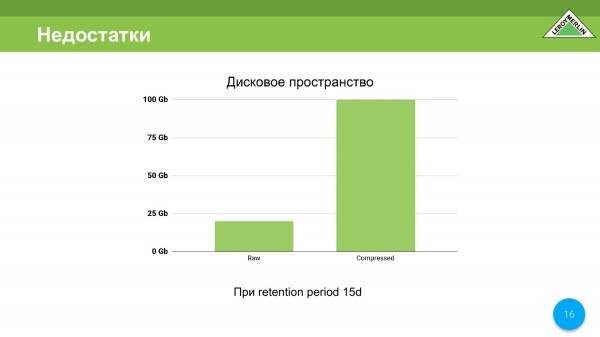
Con espacio en disco, no todo es tan triste aquí, pero me gustaría mejorarlo. Recibimos un total de 15 gigabytes en 120 días, de los cuales 100 son datos comprimidos, 20 son datos sin comprimir, pero siempre quieres menos.

En consecuencia, anotamos un punto más: este es un gran consumo de recursos que aún queremos ahorrar, porque no queremos que nuestro clúster de monitoreo consuma más recursos que nuestro clúster que administra OpenStack.

Hay una desventaja más de Prometheus, que hemos identificado por nosotros mismos, esto es al menos algún tipo de limitación de memoria. Con Prometheus, todo es mucho peor aquí, porque no tiene esos giros en absoluto. Usar el límite de la ventana acoplable tampoco es una opción. Si de repente tu RAF ha caído y hay 20-30 gigabytes, entonces tardará mucho en subir.

Esta es otra razón por la que Prometheus no es adecuado para nosotros, es decir, no podemos limitar el consumo de memoria.
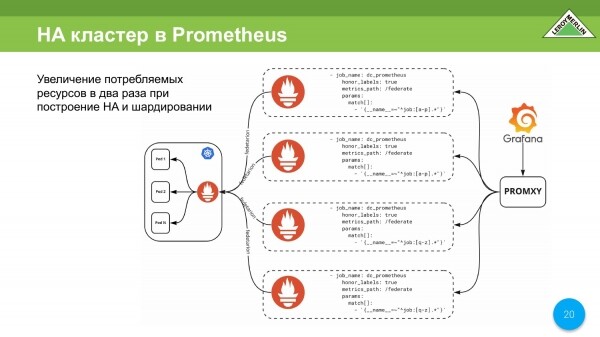
Sería posible llegar a tal esquema. Necesitamos este esquema para organizar un clúster HA. Queremos que nuestras métricas estén disponibles en cualquier momento y en cualquier lugar, incluso si el servidor que almacena estas métricas falla. Y por lo tanto tenemos que construir tal esquema.
Este esquema dice que tendremos duplicación de fragmentos y, en consecuencia, duplicación de los costos de los recursos consumidos. Se puede escalar casi horizontalmente, pero sin embargo el consumo de recursos será infernal.

Desventajas en orden, en la forma en que las escribimos nosotros mismos:
- Requiere subir métricas al exterior.
- Alto consumo de recursos.
- No puede limitar el consumo de memoria.
- Implementación complicada y que requiere muchos recursos de HA.

Por nuestra parte, decidimos que nos estamos alejando de Prometheus como repositorio.
Hemos identificado requisitos adicionales para nosotros mismos que necesitamos. Este:
- Este es el soporte de promql, porque ya se ha escrito mucho para Prometheus: consultas, alertas.
- Y luego tenemos Grafana, que ya está escrito de la misma manera bajo Prometheus como backend. No quiero volver a escribir los tableros.
- Queremos construir una arquitectura HA normal.
- Queremos reducir el consumo de cualquier recurso.
- Hay otro pequeño matiz. No podemos usar varios tipos de sistemas en la nube para recopilar métricas. No sabemos qué volará en estas métricas por ahora. Y como cualquier cosa puede volar allí, tenemos que limitarnos a la ubicación local.

La elección fue pequeña. Hemos recopilado todo sobre lo que teníamos experiencia. Miramos la página de Prometheus en la sección de integración, leímos un montón de artículos, miramos lo que está disponible en general. Y para nosotros, elegimos VictoriaMetrics como reemplazo de Prometheus.
¿Por qué? Porque:
- Capaz de Promql.
- Hay una arquitectura modular.
- No requiere cambios en Grafana.
- Y lo que es más importante, probablemente proporcionaremos un almacenamiento de métricas dentro de nuestra empresa como un servicio, por lo que estamos buscando de antemano varios tipos de restricciones para que los usuarios puedan usar todos los recursos del clúster de forma limitada, porque existe la posibilidad que será multiusuario.
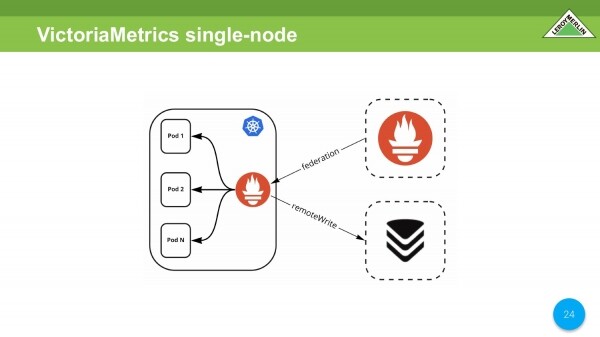
Hacemos la primera comparación. Tomamos el mismo Prometeo dentro del grupo, el Prometeo externo va hacia él. Agregamos a través de remoteWrite VictoriaMetrics.
Haré una reserva de inmediato de que aquí detectamos un ligero aumento en el consumo de CPU de VictoriaMetrics. El wiki de VictoriaMetrics dice qué parámetros son los más adecuados. Los revisamos. Redujeron muy bien el consumo de la CPU.
En nuestro caso, el consumo de memoria de Prometheus, que se encuentra en un clúster de Kubernetes, no aumentó significativamente.
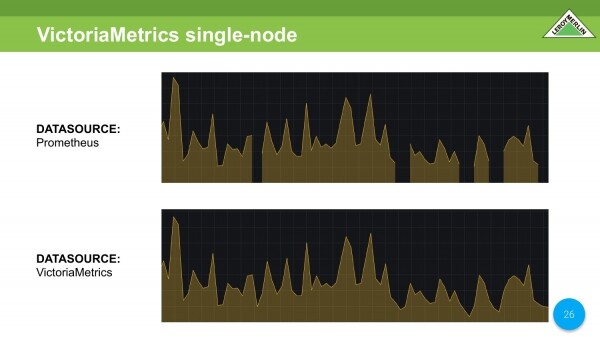
Comparamos dos fuentes de datos de los mismos datos. En Prometheus, vemos todos los mismos datos faltantes. Todo es bueno en VictoriaMetrics.

Resultados de pruebas con espacio en disco. En Prometheus obtuvimos 120 gigabytes en total. En VictoriaMetrics ya estamos recibiendo 4 gigabytes por día. Hay un mecanismo ligeramente diferente al que estás acostumbrado a ver en Prometheus. Es decir, los datos ya están bastante bien comprimidos para un día, para media hora. Ya están bien cosechados en un día, en media hora, a pesar de que luego se fusionarán los datos. Como resultado, ahorramos espacio en disco.
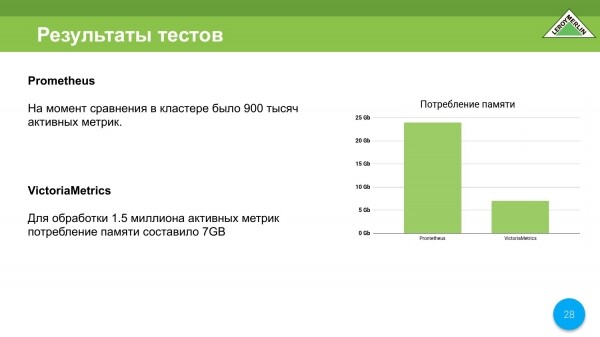
También ahorramos en el consumo de recursos de memoria. En el momento de las pruebas, implementamos Prometheus en una máquina virtual: 8 núcleos, 24 gigabytes. Prometeo come casi todo. Cayó sobre OOM Killer. Al mismo tiempo, solo se vertieron 900 métricas activas. Esto es alrededor de 000-25 métricas por segundo.
VictoriaMetrics se ejecutaba en una máquina virtual de doble núcleo con 8 gigabytes de RAM. Conseguimos que VictoriaMetrics funcionara bien ajustando algunas cosas en una máquina de 8 GB. Como resultado, nos mantuvimos dentro de los 7 gigabytes. Al mismo tiempo, obtuvimos la velocidad de entrega de contenido, es decir, métricas, incluso más altas que las de Prometheus.
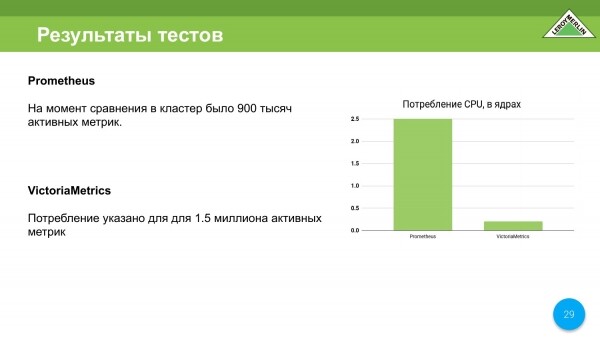
La CPU es mucho mejor que Prometheus. Aquí Prometheus consume 2,5 núcleos y VictoriaMetrics consume solo 0,25 núcleos. Al principio - 0,5 núcleos. A medida que se fusiona, alcanza un núcleo, pero esto es extremadamente, extremadamente raro.
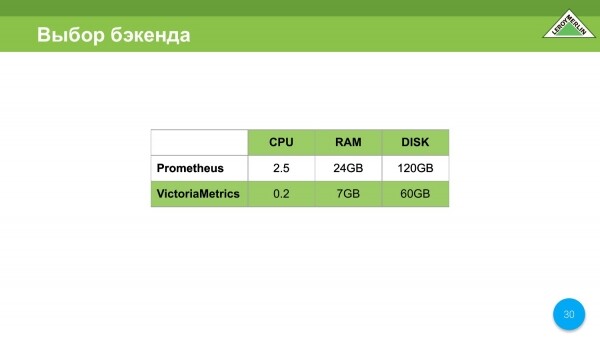
En nuestro caso, la elección recayó en VictoriaMetrics por razones obvias, queríamos ahorrar dinero y ahorramos.

Tachamos dos puntos desde el principio: esta es la descarga de métricas y un gran consumo de recursos. Y nos queda por decidir dos puntos que aún nos dejamos para nosotros.

Aquí haré una reserva enseguida, consideramos a VictoriaMetrics como un repositorio de métricas. Pero dado que lo más probable es que proporcionemos VictoriaMetrics como almacenamiento para todos los Leroy, debemos limitar a los que usarán este clúster para que no nos lo pongan.
Hay un parámetro maravilloso que te permite limitar por tiempo, por la cantidad de datos y por el tiempo de ejecución.
Y también existe una excelente opción que permite limitar el consumo de memoria, por lo que podemos encontrar el equilibrio justo que nos permitirá obtener una velocidad normal y un consumo de recursos adecuado.

Menos un punto más, es decir, tachamos el punto: no puede limitar el consumo de memoria.
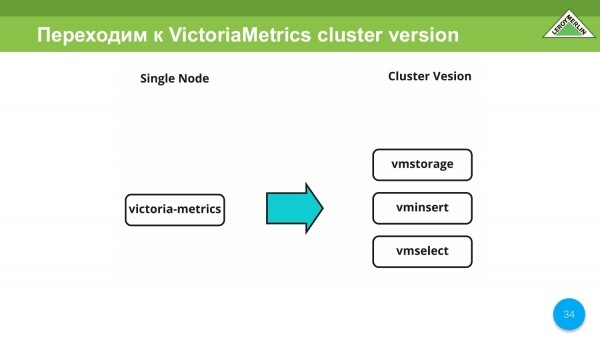
En las primeras iteraciones, probamos el nodo único de VictoriaMetrics. A continuación pasamos a la versión de clúster de VictoriaMetrics.
Aquí tenemos las manos libres sobre el tema de la separación de diferentes servicios en VictoriaMetrics, dependiendo de qué girarán y qué recursos consumirán. Esta es una solución muy flexible y conveniente. Lo hemos usado nosotros mismos.
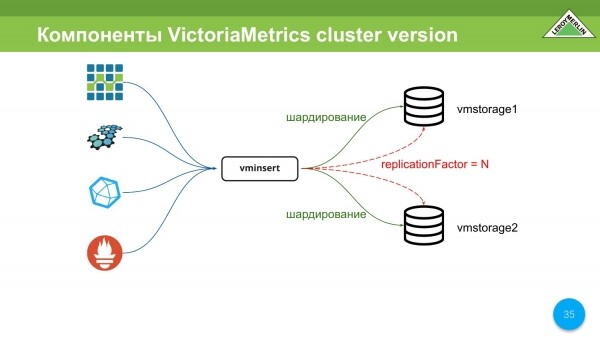
Los componentes principales de la versión de clúster de VictoriaMetrics son vmstsorage. Puede haber un número N. En nuestro caso, hay 2 de ellos.
Y hay vminsert. Este es un servidor proxy que nos permite: organizar la fragmentación entre todos los almacenamientos de los que le hablamos, y permite otra réplica, es decir, tendrá fragmentación y una réplica.
Vminsert es compatible con los protocolos OpenTSDB, Graphite, InfluxDB y remoteWrite de Prometheus.
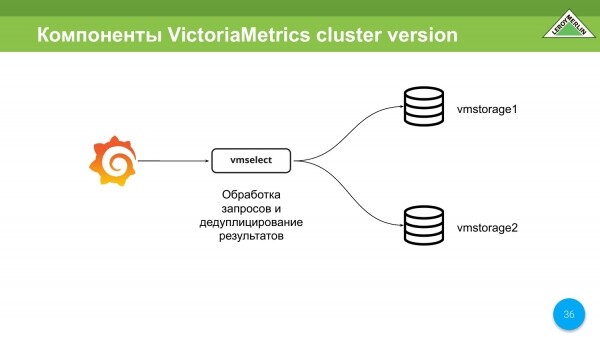
También hay vmselect. Su tarea principal es ir a vmstorage, obtener datos de ellos, desduplicar estos datos y dárselos al cliente.
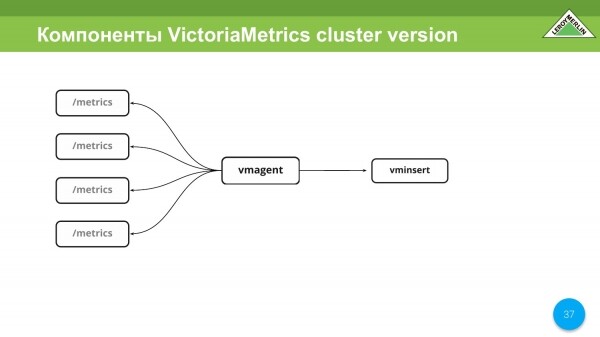
Hay una cosa maravillosa como vmagent. Realmente nos gusta ella. Le permite configurar como Prometheus y aún hacer todo como Prometheus. Es decir, recopila métricas de diferentes entidades y servicios y las envía a vminsert. Entonces todo depende de ti.
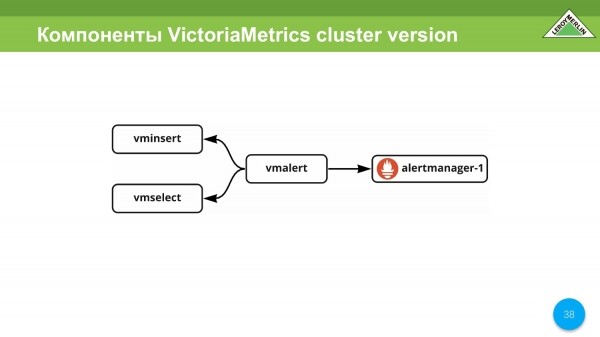
Otro gran servicio es vmalert, que le permite usar VictoriaMetrics como back-end, recibir datos procesados de vminsert y enviar datos procesados a vmselect. Procesa las propias alertas, así como las reglas. En el caso de las alertas, recibimos una alerta a través de alertmanager.
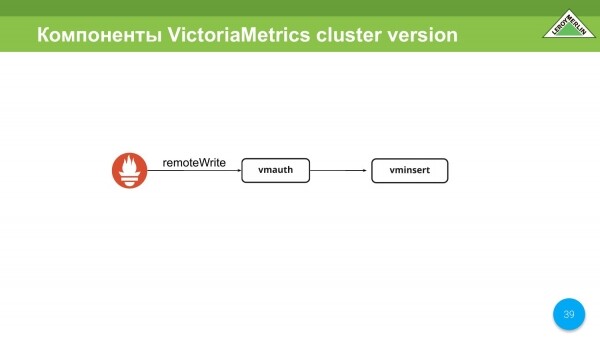
Hay un componente wmauth. Probablemente lo usemos, y quizás no (todavía no lo hemos decidido) como un sistema de autorización para versiones multiusuario de clústeres. Es compatible con remoteWrite para Prometheus y puede autorizar en función de la url, o más bien de la segunda parte de la misma, donde puede o no puede escribir.
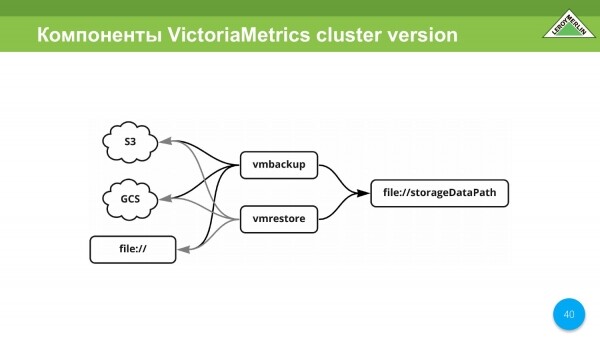
También hay vmbackup, vmrestore. Esto es, de hecho, la restauración y copia de seguridad de todos los datos. Capaz de S3, GCS, archivo.
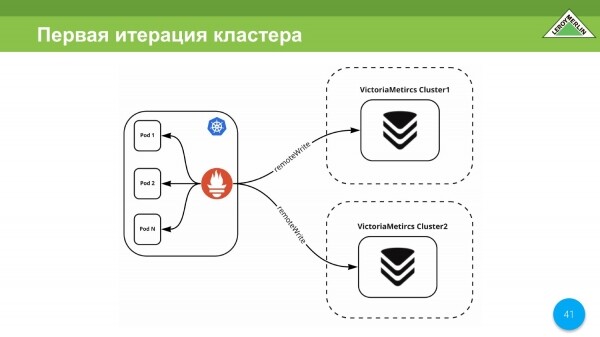
La primera iteración de nuestro clúster se realizó durante la cuarentena. En ese momento, no había una réplica, por lo que nuestra iteración constaba de dos clústeres diferentes e independientes, en los que recibimos datos a través de remoteWrite.
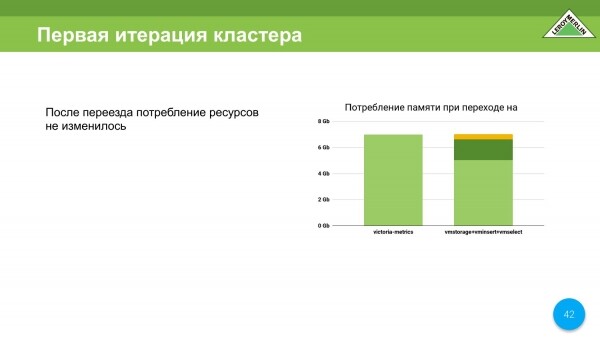
Aquí haré una reserva de que cuando cambiamos de VictoriaMetrics Single Node a VictoriaMetrics Cluster Version, seguimos con los mismos recursos consumidos, es decir, el principal es la memoria. Aproximadamente de esta manera se distribuyeron nuestros datos, es decir, el consumo de recursos.
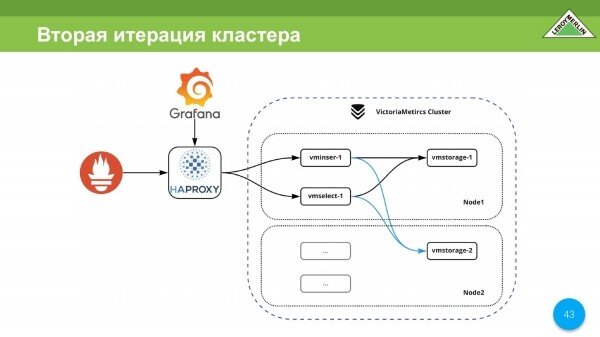
Ya se ha agregado una réplica aquí. Hemos combinado todo esto en un grupo relativamente grande. Todos los datos se fragmentan y replican.
Todo el clúster tiene N puntos de entrada, es decir, Prometheus puede agregar datos a través de HAPROXY. Aquí está nuestro punto de entrada. Y a través de este punto de entrada, puede iniciar sesión con Grafana.
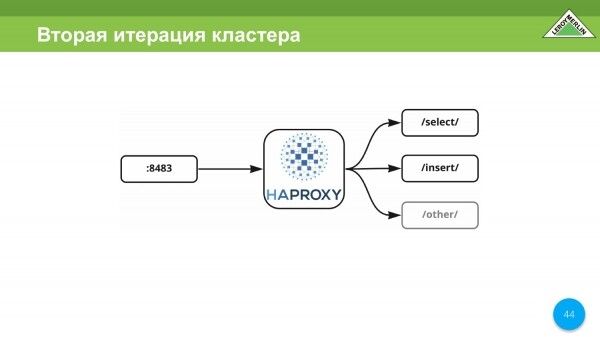
En nuestro caso, HAPROXY es el único puerto que los proxies seleccionan, insertan y otros servicios en este clúster. En nuestro caso, era imposible hacer una dirección, tuvimos que hacer varios puntos de entrada, porque las propias máquinas virtuales, en las que se ejecuta el clúster de VictoriaMetrics, están ubicadas en diferentes zonas del mismo proveedor de nube, es decir, no dentro de nuestra nube. , pero afuera.
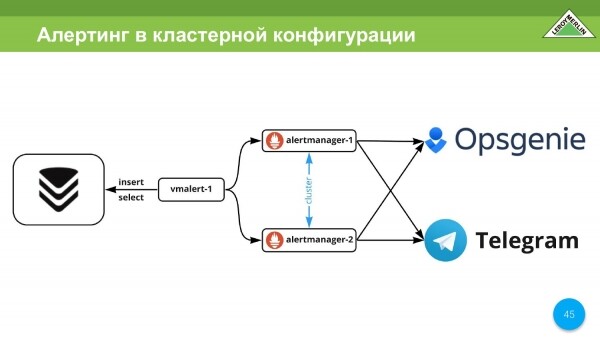
Tenemos una alerta. lo usamos Usamos alertmanager de Prometheus. Usamos Opsgenie y Telegram como canal de envío de alertas. En Telegram, están saliendo de desarrollo, tal vez algo de producción, pero más como algo estadístico que necesitan los ingenieros. Y Opsgenie es fundamental. Son llamadas, gestión de incidencias.
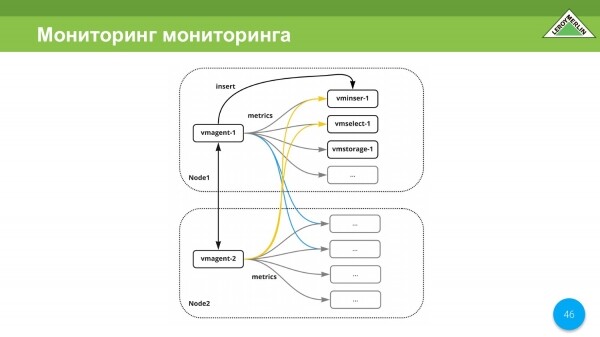
La vieja pregunta: "¿Quién supervisa el seguimiento?". En nuestro caso, el monitoreo monitorea el monitoreo mismo, porque usamos vmagent en cada nodo. Y dado que nuestros nodos están ubicados en diferentes centros de datos del mismo proveedor, cada centro de datos tiene su propio canal, son independientes y, aunque venga un cerebro dividido, seguiremos recibiendo alertas. Sí, habrá más, pero es mejor recibir más alertas que ninguna.

Terminamos nuestra lista con la implementación de HA.

Y además, me gustaría destacar la experiencia de comunicarme con la comunidad de VictoriaMetrics. Resultó ser muy positivo. Los chicos son receptivos. Intentan profundizar en cada caso que se ofrece.
Hice problemas en GitHub. Se resolvieron muy rápido. Hay un par de problemas más que no están completamente cerrados, pero ya puedo ver en el código que se está trabajando en esta dirección.
El principal problema durante las iteraciones para mí fue que si cortaba el nodo, durante los primeros 30 segundos, vminsert no podía entender que no había backend. Ahora ya está decidido. Y, literalmente, en uno o dos segundos, los datos se toman de todos los nodos restantes y la solicitud deja de esperar por ese nodo que falta.

Queríamos en algún momento de VictoriaMetrics ser el operador de VictoriaMetrics. Lo esperamos. Ahora estamos construyendo activamente un enlace sobre el operador VictoriaMetrics para tomar todas las reglas de cálculo previo, etc. Prometheus, porque estamos usando bastante activamente las reglas que vienen con el operador Prometheus.
Hay sugerencias para mejorar la implementación del clúster. Los he esbozado arriba.
Y también realmente quiero reducir la resolución. En nuestro caso, la reducción de resolución es necesaria exclusivamente para ver tendencias. En términos generales, una métrica es suficiente para mí durante el día. Estas tendencias son necesarias para un año, tres, cinco, diez años. Y un valor métrico es suficiente.
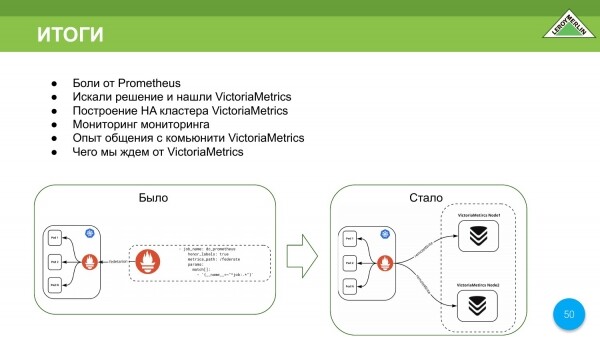
- Hemos conocido el dolor, al igual que algunos de nuestros colegas, mientras usamos Prometheus.
- Elegimos VictoriaMetrics por nosotros mismos.
- Escala bastante bien tanto en vertical como en horizontal.
- Podemos distribuir diferentes componentes a un número diferente de nodos en el clúster, limitarlos en términos de memoria, agregar memoria, etc.
Usaremos VictoriaMetrics en casa, porque nos gustó mucho. Esto es lo que pasó y lo que pasó.

Un par de códigos qr del chat de VictoriaMetrics, mis contactos, radar técnico de LeroyMerlin.
Fuente: habr.com
