

Continuando con el tema de los concursos de aprendizaje automático en Habré, nos gustaría presentarles a los lectores dos plataformas más. Ciertamente no son tan grandes como Kaggle, pero definitivamente merecen atención.

Personalmente, no me gusta demasiado kaggle por varias razones:
- En primer lugar, las competiciones suelen durar varios meses y la participación activa requiere mucho esfuerzo;
- en segundo lugar, núcleos públicos (soluciones públicas). Los seguidores de Kaggle aconsejan tratarlos con la tranquilidad de los monjes tibetanos, pero en realidad es una lástima cuando algo en lo que has estado trabajando durante uno o dos meses de repente resulta ser servido en bandeja de plata para todos.
Afortunadamente, las competiciones de aprendizaje automático se llevan a cabo en otras plataformas y se analizarán algunas de estas competiciones.
| Idioma oficial: inglés, organizadores: Yandex, Sberbank, HSE | Idioma ruso oficial, organizadores: Grupo Mail.ru |
| Ronda en línea: del 15 de enero al 11 de febrero de 2019; Final presencial: 4 al 6 de abril de 2019 | en línea: del 7 de febrero al 15 de marzo; fuera de línea: del 30 de marzo al 1 de abril. |
| Utilizando un determinado conjunto de datos sobre una partícula en el Gran Colisionador de Hadrones (trayectoria, momento y otros parámetros físicos bastante complejos), determine si es un muón o no. A partir de esta declaración se identificaron 2 tareas: — en uno solo tenías que enviar tu predicción, - y en el otro - el código completo y el modelo para la predicción, y la ejecución estaba sujeta a restricciones bastante estrictas en cuanto al tiempo de ejecución y el uso de memoria. | Para la competencia SNA Hackathon, se recopilaron registros de visualización de contenido de grupos abiertos en las fuentes de noticias de los usuarios durante febrero-marzo de 2018. El conjunto de prueba contiene la última semana y media de marzo. Cada entrada en el registro contiene información sobre lo que se mostró y a quién, así como también cómo reaccionó el usuario a este contenido: lo calificó, comentó, lo ignoró o lo ocultó del feed. La esencia de las tareas del SNA Hackathon es clasificar a cada usuario de la red social Odnoklassniki en su feed, elevando lo más alto posible aquellas publicaciones que recibirán una "clase". En la etapa online, la tarea se dividió en 3 partes: 1. clasificar las publicaciones según diversas características de colaboración 2. Clasifica las publicaciones según las imágenes que contienen. 3. clasificar las publicaciones según el texto que contienen |
| Métrica personalizada compleja, algo así como ROC-AUC | ROC-AUC promedio por usuario |
| Premios de la primera etapa: camisetas para N plazas, pase a la segunda etapa, donde se pagará alojamiento y alimentación durante la competición. Segunda fase - ??? (Por determinadas razones, no estuve presente en la ceremonia de premiación y al final no pude saber cuáles eran los premios). Prometieron portátiles a todos los integrantes del equipo ganador | Los premios de la primera etapa fueron camisetas para los 100 mejores participantes, pasaje a la segunda etapa, donde se pagó el viaje a Moscú, el alojamiento y las comidas durante la competición. Además, hacia el final de la primera etapa, se anunciaron premios para los mejores en 3 tareas de la etapa 1: ¡todos ganaron una tarjeta de video RTX 2080 TI! La segunda etapa fue una etapa por equipos, los equipos estaban formados por 2 a 5 personas, premios: 1er lugar - 300 rublos 2er lugar - 200 rublos 3er lugar - 100 rublos premio del jurado - 100 rublos |
| Grupo oficial de Telegram, ~190 participantes, comunicación en inglés, las preguntas tuvieron que esperar varios días para obtener una respuesta. | Grupo oficial en Telegram, ~1500 participantes, discusión activa de tareas entre participantes y organizadores. |
| Los organizadores aportaron dos soluciones básicas, sencilla y avanzada. El simple requería menos de 16 GB de RAM y la memoria avanzada no cabía en 16. Al mismo tiempo, mirando un poco hacia el futuro, los participantes no pudieron superar significativamente la solución avanzada. No hubo dificultades para lanzar estas soluciones. Cabe señalar que en el ejemplo avanzado había un comentario con una pista sobre dónde empezar a mejorar la solución. | Para cada una de las tareas se proporcionaron soluciones básicas primitivas, que fueron fácilmente superadas por los participantes. En los primeros días del concurso, los participantes se enfrentaron a varias dificultades: en primer lugar, los datos se proporcionaban en formato Apache Parquet y no todas las combinaciones de Python y el paquete parquet funcionaban sin errores. La segunda dificultad fue descargar imágenes desde la nube de correo; por el momento no existe una manera fácil de descargar una gran cantidad de datos a la vez. Como resultado, estos problemas retrasaron a los participantes durante un par de días. |
IDAO. Primera etapa
La tarea consistía en clasificar partículas muónicas y no muónicas según sus características. La característica clave de esta tarea fue la presencia de una columna de peso en los datos del entrenamiento, que los propios organizadores interpretaron como confianza en la respuesta a esta línea. El problema era que bastantes filas contenían pesos negativos.
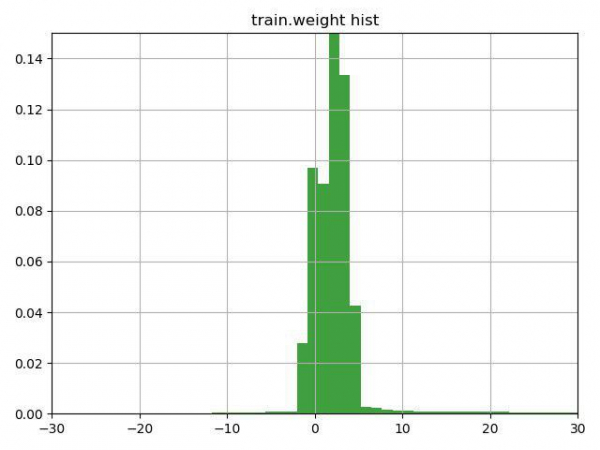
Después de pensar durante unos minutos en la línea con la pista (la pista simplemente llamó la atención sobre esta característica de la columna de peso) y construir este gráfico, decidimos verificar 3 opciones:
1) invertir el objetivo de las líneas con pesos negativos (y los pesos correspondientes)
2) cambie los pesos al valor mínimo para que comiencen desde 0
3) no uses pesas de cuerda
La tercera opción resultó ser la peor, pero las dos primeras mejoraron el resultado, la mejor fue la opción número 1, que inmediatamente nos llevó al actual segundo lugar en la primera prueba y al primero en la segunda.

Nuestro siguiente paso fue revisar los datos en busca de valores faltantes. Los organizadores nos dieron datos ya combinados, donde faltaban bastantes valores, y fueron reemplazados por -9999.
Encontramos valores faltantes en las columnas MatchedHit_{X,Y,Z}[N] y MatchedHit_D{X,Y,Z}[N], y solo cuando N=2 o 3. Como entendemos, algunas partículas no pase los 4 detectores y se detenga en la tercera o cuarta placa. Los datos también contenían columnas Lextra_{X,Y}[N], que aparentemente describen lo mismo que MatchedHit_{X,Y,Z}[N], pero usando algún tipo de extrapolación. Estas escasas conjeturas sugirieron que Lextra_{X,Y}[N] podría sustituirse por los valores faltantes en MatchedHit_{X,Y,Z}[N] (solo para las coordenadas X e Y). MatchedHit_Z[N] estaba bien lleno con la mediana. Estas manipulaciones nos permitieron alcanzar el 3er puesto intermedio en ambas tareas.

Teniendo en cuenta que no dieron nada por ganar la primera etapa, podríamos haber parado ahí, pero continuamos, hicimos algunos dibujos bonitos y se nos ocurrieron nuevas funciones.
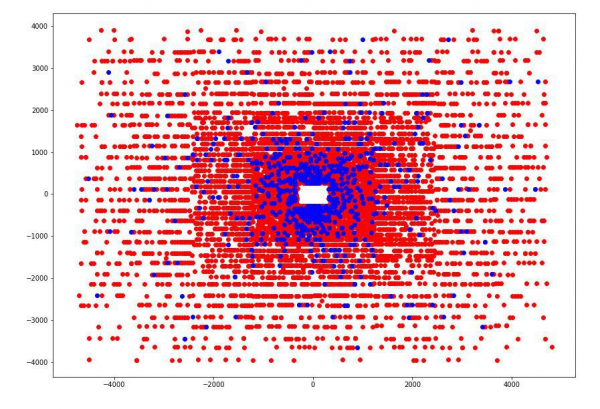
Por ejemplo, encontramos que si trazamos los puntos de intersección de una partícula con cada una de las cuatro placas detectoras, podemos ver que los puntos en cada una de las placas están agrupados en 5 rectángulos con una relación de aspecto de 4 a 5 y centrados en el punto (0,0), y en No hay puntos en el primer rectángulo.
| Número de placa/dimensiones del rectángulo | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Plato 1 | 500h625 | 1000h1250 | 2000h2500 | 4000h5000 | 8000h10000 |
| Plato 2 | 520h650 | 1040h1300 | 2080h2600 | 4160h5200 | 8320h10400 |
| Plato 3 | 560h700 | 1120h1400 | 2240h2800 | 4480h5600 | 8960h11200 |
| Plato 4 | 600h750 | 1200h1500 | 2400h3000 | 4800h6000 | 9600h12000 |
Una vez determinadas estas dimensiones, agregamos 4 nuevas características categóricas para cada partícula: el número del rectángulo en el que intersecta cada placa.
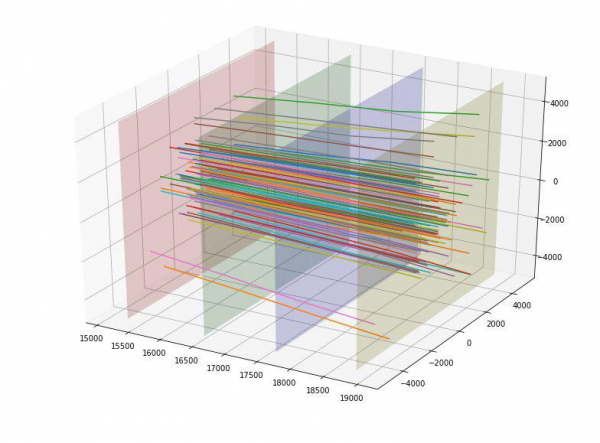
También notamos que las partículas parecían dispersarse hacia los lados desde el centro y surgió la idea de evaluar de alguna manera la "calidad" de esta dispersión. Idealmente, probablemente sería posible encontrar algún tipo de parábola "ideal" dependiendo del punto de despegue y estimar la desviación de él, pero nos limitamos a la línea recta "ideal". Habiendo construido líneas rectas ideales para cada punto de entrada, pudimos calcular la desviación estándar de la trayectoria de cada partícula desde esta línea recta. Dado que la desviación promedio para el objetivo = 1 fue 152 y para el objetivo = 0 fue 390, evaluamos tentativamente esta característica como buena. Y, de hecho, esta característica inmediatamente llegó a la cima de las más útiles.
Estuvimos encantados y agregamos la desviación de los 4 puntos de intersección para cada partícula de la línea recta ideal como 4 características adicionales (y también funcionaron bien).
Los enlaces a artículos científicos sobre el tema del concurso que nos facilitaron los organizadores nos hicieron pensar que no somos los primeros en resolver este problema y que tal vez exista algún tipo de software especializado. Habiendo descubierto un repositorio en github donde se implementaron los métodos IsMuonSimple, IsMuon, IsMuonLoose, los transferimos a nuestro sitio con modificaciones menores. Los métodos en sí eran muy simples: por ejemplo, si la energía es inferior a un cierto umbral, entonces no es un muón; en caso contrario, es un muón. Obviamente, características tan simples no podrían dar un aumento en el caso de utilizar el aumento de gradiente, por lo que agregamos otra "distancia" significativa al umbral. Estas características también se han mejorado ligeramente. Quizás, analizando más a fondo los métodos existentes, fuera posible encontrar métodos más potentes y añadirlos a los signos.
Al final de la competición, modificamos ligeramente la solución "rápida" para el segundo problema; al final, se diferenciaba de la solución básica en los siguientes puntos:
- En filas con peso negativo se invirtió el objetivo.
- Complete los valores faltantes en MatchedHit_{X,Y,Z}[N]
- Profundidad reducida a 7.
- Tasa de aprendizaje reducida a 0.1 (antes 0.19)
Como resultado, probamos más funciones (sin mucho éxito), seleccionamos parámetros y entrenamos catboost, lightgbm y xgboost, probamos diferentes combinaciones de predicciones y antes de abrir el privado ganamos con confianza en la segunda tarea, y en la primera estábamos entre los líderes.
Después de abrir la privada quedamos en el décimo lugar en la primera manga y en el tercero en la segunda. Todos los líderes se mezclaron y la velocidad en privado fue mayor que en el libboard. Parece que los datos estaban mal estratificados (o por ejemplo no había filas con ponderaciones negativas en el privado) y esto fue un poco frustrante.
SNA Hackathon 2019 - Textos. Primera etapa
La tarea consistía en clasificar las publicaciones de los usuarios en la red social Odnoklassniki según el texto que contenían; además del texto, había algunas características más de la publicación (idioma, propietario, fecha y hora de creación, fecha y hora de visualización). ).
Como enfoques clásicos para trabajar con texto, destacaría dos opciones:
- Mapear cada palabra en un espacio vectorial de n dimensiones de modo que palabras similares tengan vectores similares (lea más en ), luego encontrar la palabra promedio para el texto o usar mecanismos que tengan en cuenta la posición relativa de las palabras (CNN, LSTM/GRU).
- Usar modelos que puedan funcionar inmediatamente con oraciones completas. Por ejemplo, Berto. En teoría, este enfoque debería funcionar mejor.
Dado que esta fue mi primera experiencia con los textos, estaría mal enseñarle a alguien, así que lo haré por mí mismo. Estos son los consejos que me daría al inicio de la competición:
- Antes de correr a enseñar algo, ¡mira los datos! Además del texto en sí, los datos tenían varias columnas y de ellas era posible extraer mucho más que yo. Lo más sencillo es utilizar una codificación de destino media para algunas de las columnas.
- ¡No aprendas de todos los datos! Había muchos datos (alrededor de 17 millones de filas) y no era absolutamente necesario utilizarlos todos para probar hipótesis. El entrenamiento y el preprocesamiento fueron bastante lentos y obviamente habría tenido tiempo de probar hipótesis más interesantes.
- <Consejos controvertidos> No es necesario buscar un modelo espectacular. Pasé mucho tiempo descubriendo a Elmo y Bert, con la esperanza de que me llevaran inmediatamente a un lugar alto y, como resultado, utilicé incrustaciones previamente entrenadas de FastText para el idioma ruso. No pude lograr mejor velocidad con Elmo y todavía no tuve tiempo de resolverlo con Bert.
- <Consejos controvertidos> No es necesario buscar una característica excelente. Al observar los datos, noté que alrededor del 1 por ciento de los textos en realidad no contienen texto. Pero había enlaces a algunos recursos y escribí un analizador simple que abrió el sitio y sacó el título y la descripción. Me pareció una buena idea, pero luego me dejé llevar y decidí analizar todos los enlaces de todos los textos y nuevamente perdí mucho tiempo. Todo esto no supuso una mejora significativa en el resultado final (aunque me di cuenta de cómo derivar, por ejemplo).
- Las características clásicas funcionan. Buscamos en Google, por ejemplo, "funciones de texto kaggle", leemos y agregamos todo. TF-IDF proporcionó una mejora, al igual que características estadísticas como la longitud del texto, las palabras y la cantidad de puntuación.
- Si hay columnas DateTime, vale la pena analizarlas en varias funciones separadas (horas, días de la semana, etc.). Las características que deben destacarse deben analizarse mediante gráficos/algunas métricas. Aquí, por capricho, hice todo correctamente y resalté las características necesarias, pero un análisis normal no estaría de más (por ejemplo, como lo hicimos en la final).
Como resultado de la competencia, entrené un modelo de keras con convolución de palabras y otro basado en LSTM y GRU. Ambos utilizaron incrustaciones FastText previamente entrenadas para el idioma ruso (probé varias otras incrustaciones, pero estas fueron las que funcionaron mejor). Después de promediar los pronósticos, obtuve el séptimo lugar entre 7 participantes.
Después de la primera etapa se publicó , que ocupó el segundo lugar (participó fuera de competencia), y su solución hasta cierto punto repitió la mía, pero fue más allá gracias al mecanismo de atención de consulta-valor-clave.
Segunda etapa OK e IDAO
Las segundas etapas de las competiciones se desarrollaron casi consecutivamente, así que decidí verlas juntas.
Primero, el equipo recién adquirido y yo terminamos en la impresionante oficina de la empresa Mail.ru, donde nuestra tarea era combinar los modelos de tres pistas de la primera etapa: texto, imágenes y colaboración. Para ello se destinaron poco más de 2 días, lo que resultó ser muy poco. De hecho, sólo pudimos repetir los resultados de la primera etapa sin recibir ninguna ganancia de la fusión. Al final quedamos en quinto lugar, pero no pudimos utilizar el modelo de texto. Después de observar las soluciones de otros participantes, parece que valió la pena intentar agrupar los textos y agregarlos al modelo de colaboración. Un efecto secundario de esta etapa fueron las nuevas impresiones, el encuentro y la comunicación con participantes y organizadores geniales, así como una grave falta de sueño, lo que pudo haber afectado el resultado de la etapa final de IDAO.
La tarea en la etapa final de IDAO 2019 fue predecir el tiempo de espera de un pedido para los taxistas de Yandex en el aeropuerto. En la etapa 2, se identificaron 3 tareas = 3 aeropuertos. Para cada aeropuerto se proporcionan datos minuto a minuto sobre el número de pedidos de taxis durante seis meses. Y como datos de prueba, se dieron los datos del mes siguiente y minuto a minuto de los pedidos de las últimas 2 semanas. Hubo poco tiempo (1,5 días), la tarea era bastante específica, solo una persona del equipo vino a la competencia y, como resultado, el final fue un lugar triste. Ideas interesantes incluyeron intentos de utilizar datos externos: clima, atascos y estadísticas de pedidos de taxis de Yandex. Aunque los organizadores no dijeron cuáles eran estos aeropuertos, muchos participantes supusieron que eran Sheremetyevo, Domodedovo y Vnukovo. Aunque esta suposición fue refutada después del concurso, las características, por ejemplo, de los datos meteorológicos de Moscú mejoraron los resultados tanto en la validación como en la clasificación.
Conclusión
- ¡Las competiciones de ML son geniales e interesantes! Aquí encontrará el uso de habilidades en análisis de datos y modelos y técnicas astutos, y simplemente el sentido común es bienvenido.
- El aprendizaje automático ya es un enorme conjunto de conocimientos que parece estar creciendo exponencialmente. Me propuse el objetivo de familiarizarme con diferentes áreas (señales, imágenes, tablas, texto) y ya me di cuenta de cuánto queda por estudiar. Por ejemplo, después de estas competiciones decidí estudiar: algoritmos de agrupamiento, técnicas avanzadas para trabajar con bibliotecas de aumento de gradiente (en particular, trabajar con CatBoost en la GPU), redes de cápsulas, el mecanismo de atención de valor clave de consulta.
- ¡No solo por Kaggle! Hay muchos otros concursos en los que es más fácil conseguir al menos una camiseta y hay más posibilidades de conseguir otros premios.
- ¡Comunicar! Ya existe una gran comunidad en el campo del aprendizaje automático y el análisis de datos, hay grupos temáticos en Telegram, Slack y personas serias de Mail.ru, Yandex y otras empresas responden preguntas y ayudan a los principiantes y a quienes continúan su camino en este campo. del conocimiento.
- Aconsejo a todos los que se inspiraron en el punto anterior que visiten — una importante conferencia gratuita en Moscú, que tendrá lugar los días 10 y 11 de mayo.
Fuente: habr.com
