

Un buen juego tradicional de escondite puede ser una gran prueba para que los robots de inteligencia artificial (IA) demuestren cómo toman decisiones e interactúan entre sí y con varios objetos a su alrededor.
en su , publicado por investigadores de OpenAI, una organización de investigación de inteligencia artificial sin fines de lucro que se ha hecho famosa En el juego de ordenador Dota 2, los científicos describen cómo se entrenó a agentes controlados por inteligencia artificial para que fueran más sofisticados a la hora de buscarse y esconderse unos de otros en un entorno virtual. Los resultados del estudio demostraron que un equipo de dos robots aprende de forma más eficaz y rápida que cualquier agente sin aliados.

Los científicos han utilizado un método que se ha ganado fama durante mucho tiempo. , en el que la inteligencia artificial se coloca en un entorno desconocido para ella, teniendo determinadas formas de interactuar con ella, así como un sistema de recompensas y multas por tal o cual resultado de sus acciones. Este método es bastante eficaz gracias a la capacidad de la IA para realizar diversas acciones en un entorno virtual a una velocidad enorme, millones de veces más rápida de lo que una persona puede imaginar. Esto permite que la prueba y el error encuentren las estrategias más efectivas para resolver un problema determinado. Pero este enfoque también tiene algunas limitaciones: por ejemplo, crear un entorno y realizar numerosos ciclos de formación requiere enormes recursos informáticos, y el proceso en sí requiere un sistema preciso para comparar los resultados de las acciones de la IA con su objetivo. Además, las habilidades adquiridas por el agente de esta forma se limitan a la tarea descrita y, una vez que la IA aprenda a afrontarla, no habrá más mejoras.
Para entrenar a la IA para que juegue al escondite, los científicos utilizaron un enfoque llamado "exploración no dirigida", en el que los agentes tienen total libertad para desarrollar su comprensión del mundo del juego y desarrollar estrategias ganadoras. Esto es similar al enfoque de aprendizaje de múltiples agentes que utilizaron los investigadores de DeepMind cuando se utilizaron múltiples sistemas de inteligencia artificial. . Como en este caso, los agentes de IA no fueron entrenados previamente en las reglas del juego, pero con el tiempo aprendieron estrategias básicas e incluso fueron capaces de sorprender a los investigadores con soluciones no triviales.
En un juego de escondite, varios agentes cuyo trabajo era esconderse debían evitar la línea de visión de sus oponentes después de una ligera ventaja mientras el equipo de agentes de búsqueda estaba inmovilizado. Además, la “línea de visión” en este contexto es un cono de 135 grados frente a un robot individual. Los agentes no podían aventurarse demasiado fuera del área de juego y se vieron obligados a navegar por salas generadas aleatoriamente con la capacidad de usar algunos objetos externos (cajas, paredes móviles, rampas especiales) dispersos por todas partes que podían usarse tanto para crear cobertura como para infiltrarse en ellas. .
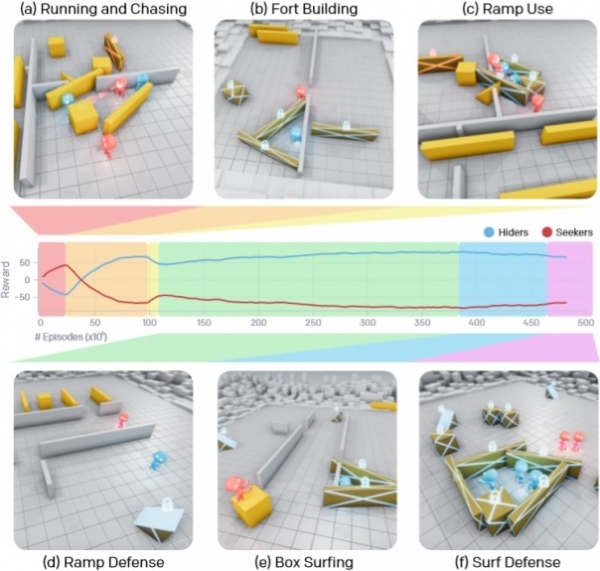
A través de un largo proceso de aprendizaje, los agentes de IA aprendieron seis estrategias únicas, cada una de las cuales los ayudó a pasar a la siguiente etapa del juego. Al principio, los equipos que buscaban y escondían simplemente huían y se perseguían entre sí, pero después de unos 25 millones de partidos, el equipo que se escondía aprendió a bloquear los pasillos con cajas y a construir refugios con ellas. Después de otros 75 millones de partidas, el equipo descubrió formas de utilizar rampas para acceder a estos escondites. Después de otros 10 millones de rondas, los escondidos aprendieron a arrastrar rampas hasta el borde del área de juego y bloquearlas en su lugar para evitar que los oponentes las usaran.

Después de 388 millones de partidas, los buscadores han aprendido a usar rampas bloqueadas para subir a las cajas que les traen y luego, moviéndose directamente hacia ellas, penetran en los escondites enemigos creados a partir de paredes portátiles. Y finalmente, después de 458 millones de partidas, el equipo escondido llegó a la conclusión de que necesitaban bloquear todos los objetos y luego construir un refugio, lo que aparentemente les llevó a la victoria final.
Lo que es particularmente impresionante es que después de 22 millones de coincidencias, los agentes aprendieron a coordinar sus acciones y la eficiencia de su colaboración solo aumentó en el futuro; por ejemplo, cada uno trajo su propia caja o pared para crear un refugio y eligió su parte de objetos para bloquear, para complicar el juego de dificultad a los oponentes.

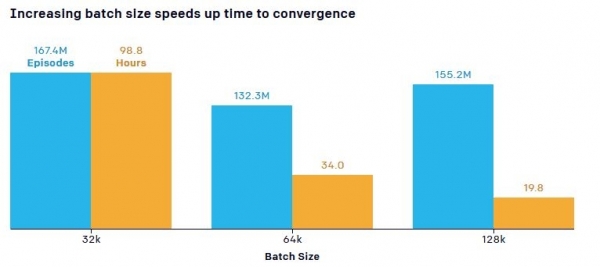
Los científicos también notaron un punto importante relacionado con la influencia del número de objetos de entrenamiento (la cantidad de datos pasados a través de la red neuronal - "Tamaño del lote") en la velocidad de aprendizaje. El modelo predeterminado requirió 132,3 millones de partidos durante 34 horas de entrenamiento para llegar al punto en el que el equipo escondido aprendió a bloquear rampas, mientras que más datos dieron como resultado una reducción notable en el tiempo de entrenamiento. Por ejemplo, aumentar el número de parámetros (parte de los datos obtenidos durante todo el proceso de entrenamiento) de 0,5 millones a 5,8 millones aumentó la eficiencia del muestreo en 2,2 veces, y aumentar el tamaño de los datos de entrada de 64 KB a 128 KB redujo el entrenamiento. tiempo casi una vez y media.
Al final de su trabajo, los investigadores decidieron probar en qué medida el entrenamiento dentro del juego podría ayudar a los agentes a afrontar tareas similares fuera del juego. Hubo cinco pruebas en total: conciencia del número de objetos (comprender que un objeto sigue existiendo incluso si está fuera de la vista y no se utiliza); “bloquear y regresar”: la capacidad de recordar la posición original y regresar a ella después de completar alguna tarea adicional; “bloqueo secuencial”: 4 cajas estaban ubicadas aleatoriamente en tres habitaciones sin puertas, pero con rampas para ingresar, los agentes necesitaban encontrarlas y bloquearlas todas; colocación de cajas en sitios predeterminados; creando un refugio alrededor de un objeto en forma de cilindro.
Como resultado, en tres de cada cinco tareas, los robots que habían recibido un entrenamiento preliminar en el juego aprendieron más rápido y mostraron mejores resultados que la IA que fue entrenada para resolver problemas desde cero. Se desempeñaron ligeramente mejor al completar la tarea y regresar a la posición inicial, bloqueando secuencialmente cajas en habitaciones cerradas y colocando cajas en áreas determinadas, pero se desempeñaron un poco más débilmente al reconocer la cantidad de objetos y crear cobertura alrededor de otro objeto.
Los investigadores atribuyen resultados mixtos a la forma en que la IA aprende y recuerda ciertas habilidades. “Creemos que las tareas en las que el entrenamiento previo en el juego funcionó mejor implicaron reutilizar habilidades previamente aprendidas de una manera familiar, mientras que realizar las tareas restantes mejor que la IA entrenada desde cero requeriría usarlas de una manera diferente, lo que mucho más difícil”, escriben los coautores del trabajo. "Este resultado pone de relieve la necesidad de desarrollar métodos para reutilizar eficazmente las habilidades adquiridas mediante la formación al transferirlas de un entorno a otro".
El trabajo realizado es realmente impresionante, ya que la posibilidad de utilizar este método de enseñanza va mucho más allá de los límites de cualquier juego. Los investigadores dicen que su trabajo es un paso importante hacia la creación de IA con un comportamiento "basado en la física" y "similar al humano" que pueda diagnosticar enfermedades, predecir las estructuras de moléculas proteicas complejas y analizar tomografías computarizadas.
En el vídeo a continuación se puede ver claramente cómo se desarrolló todo el proceso de aprendizaje, cómo la IA aprendió a trabajar en equipo y sus estrategias se volvieron cada vez más astutas y complejas.

Fuente: 3dnews.ru
