


Tere, Habra lugejad! Eelmises artiklis rääkisime AERODISK ENGINE’i andmesalvestussüsteemide lihtsast katastroofikindluse vahendist - replikatsioonist. Selles artiklis sukeldume keerulisemasse ja huvitavasse teema - metroklaster, see tähendab kahte andmekeskust kaitsev automatiseeritud katastroofikindluse vahend, mis võimaldab andmekeskustel töötada aktiivselt-aktiivses režiimis. Räägime, näitame, purustame ja parandame.
Kuna tavaliselt, alustame teooriast
Metroklaster on klaster, mis on laiali pillutatud mitmele asukohale linna või piirkonna piires. Sõna „klaster“ vihjab selgelt, et kompleks on automatiseeritud, st klastrite sõlmede vahetus rikete korral (failover) toimub automaatselt.
Siin peitub peamine erinevus metrokliendi ja tavalise replikatsiooni vahel. Operatsioonide automatiseerimine. See tähendab, et juhtumite korral (andmekeskuse rike, kanali katkestamine jne) salvestussüsteem täidab iseseisvalt vajalikud toimingud andmete kättesaadavuse säilitamiseks. Tavaliste replikatsioonide korral teostab administraator need toimingud täielikult või osaliselt käsitsi.
Milleks seda vaja on?
Peamine eesmärk, mida tellijad püüavad saavutada metrokliendi erinevate lahenduste kasutamisega, on RTO (Recovery Time Objective) minimaalne vähendamine. See tähendab IT-teenuste taastamise aja vähendamist pärast riket. Kui kasutada tavalist replikatsiooni, on taastamisaeg alati pikem kui metrokliendi puhul. Miks? Väga lihtne. Administraator peab olema töökohal ja vahetama replikatsiooni käsitsi, mentre metrokliendi lahendus teeb seda automaatselt.
Kui teil ei ole pühendatud administraatorit, kes ei maga, ei söö, ei suitseta ja ei haigestu, vaid jälgib 24 tundi ööpäevas SAN-i seisukorda, siis ei ole ka võimalik tagada, et administraator oleks käsitsi vahetamiseks kergesti kätte saadav rikke korral.
Seetõttu RTO juhul, kui metroklastrit või igavest 99. taseme administratiivteenistust ei ole, on võrreldav süsteemide vahetamise aega ja maksimaalse ajavahega, mille jooksul administraator garantii alusel alustab SAN-i ja sellega seotud süsteemidega töötamist.
Nii jõuame ilmsele järeldusele, et metroklastrit tuleb kasutada juhul, kui RTO nõue on minutid, mitte tunnid või päevad. See tähendab, et kõige hullemate andmekeskuse kokkuvarisemisel peab IT-osakond tagama äri IT-teenustele juurdepääsu taastamise aja jooksul minutite või sekundite jooksul.
Kuidas see töötab?
Madalamal tasemel kasutab metroklaster sünkroonse andmete replikatsiooni mehhanismi, mida oleme kirjeldanud eelmises artiklis (vt. ). Kuna replikatsioon on sünkroonne, peavad ka nõuded sellele vastama, täpsemalt:
- kiudoptiline füüsika, 10 gigabitti Ethernet (või rohkem);
- andmekeskuste vahemaa mitte rohkem kui 40 kilomeetrit;
- optika kanalite viivitus andmekeskuste vahel (SKH-de vahel) kuni 5 millisekundi (optimaalselt 2).
Kõik need nõuded on soovituslikud, ehkki metroklaster töötab ka siis, kui neid nõudeid ei järgita, kuid tuleb mõista, et nende mittejärgimise tagajärjed võrduvad mõlema SKH aeglustumisega metroklastris.
Seega kasutatakse andmete edastamiseks SKH-de vahel sünkroonset replikatsiooni, kuid kuidas replikad automaatselt vahetuvad ja mis veelgi tähtsam, kuidas vältida split-brain'i? Selleks kasutatakse ülemisel tasemel lisasubit - arbitraari.
Kuidas arbitraaž töötab ja milline on tema ülesanne?
Arbitraaž on väike virtuaalmasin või riistvaraklass, mille tuleb käivitada kolmandas asukohas (nt kontoris) ning tagada juurdepääs SKH-dele ICMP ja SSH kaudu. Pärast käivitamist peab arbitraaž seadistama IP-aadressi ning seejärel SKH-st näitama oma aadressi, pluss kaugkontrollerite aadressid, mis osalevad metroklastris. Pärast seda on arbitraaž tööks valmis.
Arbiter jälgib pidevalt kõiki salvestusseadmeid metroklastris ja juhul, kui mõni salvestussüsteem on saadaval, siis pärast teise klastriliikme (ühe elava salvestusseadmest) kinnitust saadavusele, teeb ta otsuse replikatsiooni reeglite vahetamise ja kaardistamise protseduuri käivitamiseks.
Väga oluline punkt. Arbiter peab alati olema platvormil, mis erineb neist, kus asuvad salvestusseadmed, seega ei tohi ta olla andmekeskuses 1, kus asub salvestusseade 1, ega andmekeskuses 2, kus on paigaldatud salvestusseade 2.
Miks? Sest ainult nii saab arbiter ühe elava salvestusseadmese abil üheselt ja eksimatult tuvastada kummagi kahest platvormist, kus asuvad salvestusseadmed, kokkuvarisemise. Igasugused muud viisid arbitri paigutamiseks võivad viia split-braini olukorrani.
Nüüd sukeldume arbitri töö detailidesse.
Arbiteris on käivitatud mitu teenust, mis pidevalt küsitlevad kõiki salvestusseadmeste juhtimisseade. Kui küsitluse tulemus erineb eelnevast (saadav/nähtav), salvestatakse see väikesesse andmebaasi, mis töötleb ka arbitris.
Vaadake arbitri töö loogikat lähemalt.
Samm 1. Saadavuse määramine. Sügavuse signaal, mis näitab, et SAN on ebaõnnestunud, on kahe SAN kontrolleri pinget puudumine viie sekundi jooksul.
Samm 2. Üleminekuprotseduuri käivitamine. Pärast seda, kui kohtunik on aru saanud, et üks SAN ei ole kasutatav, saadab ta päringu „elavale“ SAN-ile, et veenduda, et „surnud“ SAN on tõeliselt lõpetanud töö.
Pärast sellise käsu saamist kohtunikult kontrollib teine (elav) SAN täiendavalt, kas langenud esialgne SAN on endiselt kättesaadav, ning kui ei, saadab ta kohtuniku arvamuse kinnituse. SAN on tõepoolest kättesaamatuks osutunud.
Pärast sellise kinnituse saamist käivitab kohtunik kaugüleminekuprotseduuri ja tõstab mape nende koopiate peal, mis olid aktiivsed (primary) langenud SAN-is, ning saadab käsu teisele SAN-ile muuta need koopiad secondary-st primary-ks ja tõsta mapping. Ning teine SAN täidab vastavalt need protseduurid, pärast mida tagab juurdepääsu kadunud LUN-idele.
Miks on vajalik täiendav kontroll? Kvoorumi jaoks. See tähendab, et enamus üldisest võrdsetest (3) klastriosalistest peab kinnitama klastrisõlme rikke. Ainult siis on see otsus tõeliselt õige. See on vajalik vale vahetuse vältimiseks ja seega split-brain'i vältimiseks.
Samm 2 kestab umbes 5–10 sekundit, seega, arvestades aegade määramiseks vajalikke viiteid (5 sekundit), on LUN-id, millel nurjunud salvestus, automaatselt kättesaadavad elava salvestusega 10–15 sekundi jooksul pärast riket.
Mõistagi, et hostide ühenduse katkemise vältimiseks tuleb hoolitseda ka hostide ajutimeetmete nõuetekohase seadistamise eest. Soovitatav ajutimeetme pikkus on vähemalt 30 sekundit. See ei võimalda hostil katkestada ühendust salvestusega koormuse ülemineku ajal ja suudab tagada sisendi-väljundi katkestamise vältimise.
Oota, kui metroklaster on kõik nii hästi, siis miks on vajaliku tavalise replikatsiooni?
Tegelikult pole see nii lihtne.
Vaatame metroklastere eeliseid ja puudusi.
Niisiis, oleme aru saanud, et metroklaster pakub võrreldes tavalise replikatsiooniga järgmisi ilmselgeid eeliseid:
- Täielik automatiseeritus, mis tagab minimaalsete taastumisaegade katastroofide korral;
- Ja kõik :-).
Nüüd aga tähelepanu, puudused:
- Lahenduse hind. Kuigi metroklaster Airodiski süsteemides ei vaja täiendavat litsentseeringut (kasutatakse sama litsentsi kui replikal), on lahenduse hind siiski kõrgem kui sünkroonne replikatsioon. Nõutakse kõigi nõuete rakendamist sünkroonsesse replika, pluss metroklastriga seotud nõuded, mis on seotud täiendava lülitamise ja täiendava saidiga (vt metroklastrite planeerimine);
- Lahenduse keerukus. Metroklaster on märgatavalt keerulisem kui tavaline replikatsioon ja nõuab palju rohkem tähelepanu ja tööjõudu planeerimise, seadistamise ja dokumenteerimise osas.
Kokkuvõtteks. Metroklaster on kindlasti väga tehnoloogiliselt arenenud ja hea lahendus, kui on tõeliselt vajalik tagada RTO sekundite või minutite jooksul. Kuid kui selline ülesanne puudub ja RTO tundides on ettevõtte jaoks aktsepteeritav, pole mõtet tulistada linnukeste pihta. Tavaline töö- ja talureplikatsioon on piisav, kuna metroklastri kasutuselevõtt tooks kaasa lisakulud ja keerukama IT-infrastruktuuri.
Metroklastri planeerimine
See jaotis ei pretendeeri olema põhjalik juhend metroklastri projekteerimiseks, vaid näitab vaid põhisuundi, mida tuleks arvesse võtta, kui olete otsustanud sarnase süsteemi üles ehitada. Seetõttu kaasake metroklastri tõelise rakendamise puhul kindlasti nõustamiseks andmeid salvestava seadme tootja (ehk meid) ja teiste seotud süsteemide esindajad.
Asukohad
Nagu eelnevalt mainitud, vajab metroklastr vähemalt kolme asukohta. Kaks andmekeskust, kus töötavad andmeid salvestavad seadmed ja seotud süsteemid, ning kolmas asukoht, kus töötab vahemees.
Soovitatav kaugus andmekeskuste vahel on mitte rohkem kui 40 kilomeetrit. Suurem kaugus tõenäoliselt põhjustab täiendavaid viivitusi, mis on metroklastri puhul äärmiselt ebasoovitavad. Tuletame meelde, et viivitused peaksid olema kuni 5 millisekundit, kuigi soovitav on jääda 2 piiresse.
Viivitusi soovitatakse kontrollida ka planeerimise käigus. Iga suurem või vähegi arvestatav teenusepakkuja, kes pakub andmed ühendada keskuste vahel, suudab kvaliteedi kontrolli korraldada üsna kiiresti.
Mis puudutab viivitusi arbitraži juures (st kolmanda osapoole ja kahe esimese vahel), siis soovitatav viivituse piir on kuni 200 millisekundit, mis tähendab, et tavapärane ettevõtte VPN-ühendus üle interneti sobib selleks.
Vahetus ja võrk
Erinevalt replikatsiooni skeemist, kus piisab, kui ühendada omavahel erinevate asukohtade andmesalvestusseadmed, nõuab metroklaster hostide ühendamist mõlema andmesalvestusseadmest eri kohtades. Kergemaks arusaamiseks, mis vahe on, on allpool toodud mõlemad skeemid.
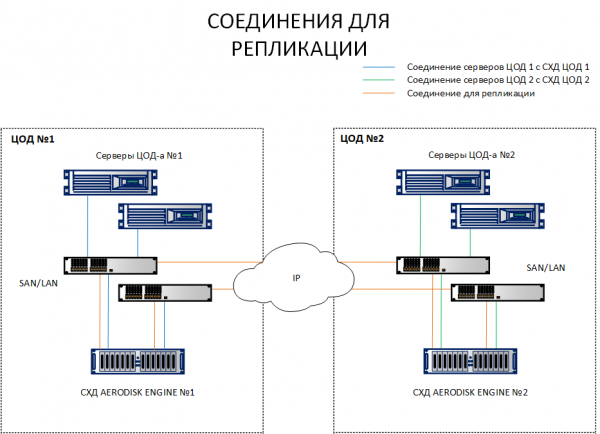
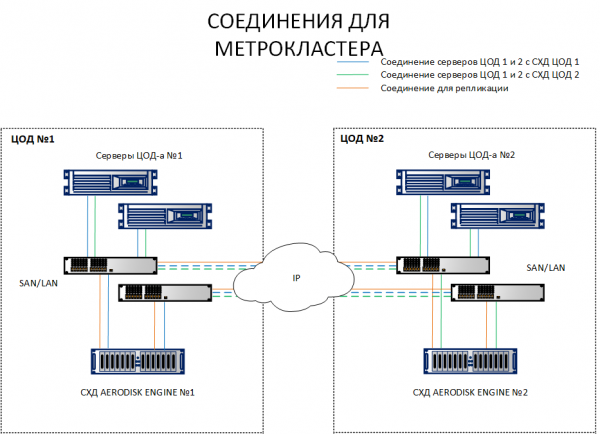
Kuna skeemist on näha, vaadatakse esimese asukoha hostide poolt nii Andmesalvestusseade 1 kui ka Andmesalvestusseade 2. Samuti vaatavad teise asukoha hostid nii Andmesalvestusseade 2 kui ka Andmesalvestusseade 1. See tähendab, et iga host näeb mõlemat andmesalvestusseadet. See on metroklastri töö kohustuslik tingimus.
Küll, pole mõtet iga hosti tõmmata optilise kaabli abil teise andmekeskusesse, ports ja kaablid ei piisa. Kõik need ühendused tuleb teha Ethernet 10G+ või FibreChannel 8G+ (FC ainult hostide ja SAN-i ühendamiseks IO jaoks, replikeerimise kanal on hetkel saadaval ainult IP (Ethernet 10G+) kaudu.
Nüüd paar sõna võrgutopoloogiast. Oluline punkt on alamside korrektne konfigureerimine. Tuleb kohe määrata mitu alamsidet järgmiste liikide liikluseks:
- Replikeerimise alamside, mille kaudu sünhroniseeritakse andmed SAN-i vahel. Neid võib olla mitu, selle puhul ei oma tähtsust, kõik sõltub praegusest (juba rakendatud) võrgutopoloogiast. Kui neid on kaks, peab ilmselt olema nende vahel seadistatud marsruutimine;
- Andmete salvestamise alamsidemed, mille kaudu hostid saavad pääseda SAN-i ressurssidele (kui see on iSCSI). Selliseid alamsidemeid peaks olema igas andmekeskuses üks;
- Haldus alamsidemed, ehk kolm marsruutitavat alamsidet kolmes asukohas, kust juhitakse SAN-i ning kus asub ka määrav koht.
Hostide ressursside juurde pääsemiseks alalisi võrke me siin ei käsitle, kuna need sõltuvad tugevalt ülesannetest.
Erineva liikluse jagamine erinevatesse alalistesse võrkudesse on äärmiselt oluline (eriti on tähtis eraldada replikatsioon sisend-väljundist), kuna kui kogu liiklus segatakse ühte "paksu" võrku, siis ei ole võimalik seda liiklust hallata. Kaks andmekeskust võivad selle olukorra tõttu veelgi erinevaid võrgu kokkupõrke variante põhjustada. Me ei sukelduda selle küsimuse sügavale, kuna jagatud võrgu planeerimist andmekeskuste vahel tutvustavad võrgu seadmete tootjate ressursid, kus seda on väga detailselt kirjeldatud.
Arbitraari konfiguratsioon
Arbiter peab tagama juurdepääsu kõigile salvestuslahenduse halduskeskustele ICMP ja SSH protokollide kaudu. Samuti tuleks mõelda arbitraari tõrgeteta toimimisele. Siin on üks nüanss.
Arbitraari tõrgeteta toimimine on väga soovitav, kuid mitte kohustuslik. Mis juhtub, kui arbitraar kukub ootamatult kokku?
- Metroklaasteri töö normaalses režiimis ei muutu, kuna arbitraar metroklaasteri töö normaalses režiimis ei mõjuta absoluutselt üldse (tema ülesanne on koormuse õigel ajal vahetamine andmekeskuste vahel).
- Siiski, kui arbitraar mingil põhjusel kokku kukub ja ei märka andmekeskuses toimuvat õnnetust, siis ei toimu ühtegi vahetust, sest ei ole kedagi, kes annaks vajalikud käsud vahetamiseks ja korraldaks kvoorumi. Sel juhul muutub metroklaaster tavaliseks replikatsiooniskeemiks, mida tuleb katastroofi ajal käsitsi vahetada, mis mõjutab RTO-d.
Mis sellest järeldub? Kui tõeliselt on vaja tagada minimaalne RTO näitaja, tuleb tagada arbitraari rikke kindelus. Selleks on kaks varianti:
- Käivitada virtuaalmasin arbitraariga rikkealti hüperviseerijas, õnneks toetavad kõik küpsed hüperviseerijad rikkealti.
- Kui kolmandal platvormil (tinglikus kontoris) ei viitsita korralikku klastrit seadistada ja olemasolevat hüperviisori klastrit pole, siis oleme ette näinud riistvaralise arbitr põhivormis 2U kasti, kus töötavad kaks tavalist x86 serverit ja mis suudab taluda kohalikku riket.
Soovitame tungivalt tagada arbitri korraliku töökindluse, hoolimata sellest, et normaalses režiimis pole see metroklastrile vajalik. Kuid nagu näitab nii teooria kui ka praktika, on tõelise usaldusväärse katastroofi vastupidava infrastruktuuri ehitamisel parem end üle kindlustada. On parem kaitsta end ja oma äri "alati halva seaduse" eest, see tähendab, et nii arbitr kui ka üks plats, kus on paigaldatud andmesalvestus, võivad samaaegselt välja kukkuda.
Lahenduse arhitektuur
Arvestades ülaltoodud nõudeid, saame järgmise lahenduse üldise arhitektuuri.
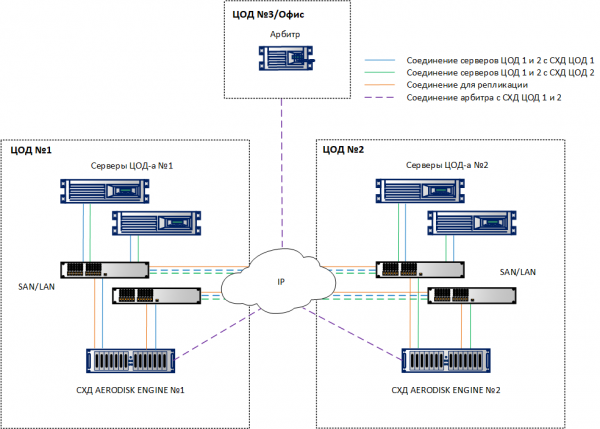
LUN-id tuleks ühtlaselt jaotada kahe andmekeskuse vahel, et vältida tugevat ülekoormust. Samuti tuleb mõlema andmekeskuse suuruse seadmisel arvestada mitte ainult kahekordse mahu vajadusega (mis on vajalik andmete samaaegseks salvestamiseks kahes SAN-is), vaid ka kahekordse jõudlusega IOPS ja MB/s, et vältida rakenduste degradeerumist ühe andmekeskuse tõrke korral.
Erakordselt tahame rõhutada, et kui suuruse seadmine toimub õigesti (st juhul, kui oleme ette näinud vajalikud IOPS ja MB/s ülemised piirid, samuti vajalikud CPU ja RAM ressursid), siis ei esine metroklastri ühes SAN-is rikke korral tõsiseid jõudluspause ajutiste toimingute käigus ühel SAN-il.
See on tingitud sellest, et kahe platvormi samaaegse töö korral töötav sünkroonne replikatsioon "neelab" poole tootlikkusest kirjutamise ajal, kuna iga tehing tuleb salvestada kahele andmesalvestusele (sarnaselt RAID-1/10). Seega, kui üks andmesalvestus ebaõnnestub, kaob replikatsiooni mõju ajutiselt (kuni rikki läinud andmesalvestus uuesti tööle hakkab) ja me saame kahekordse tootlikkuse tõusu kirjutamisel. Pärast seda, kui rikki läinud andmesalvestuse LUN-id on taaskäivitatud töötavas andmesalvestuses, kaob see kahekordne tõus, kuna koormus teisest andmesalvestusest hakkab mõjutama, ja me naaseme tagasi sama tootlikkuse tasemele, mis meil oli enne "langemist", kuid juba ainult ühe platvormi raames.
Korraliku suuruse määramise abil on võimalik tagada tingimused, mille korral kasutajad ei tunne üldse, et terve andmesalvestus on tagasi lükatud. Kuid kordame veel kord, et see nõuab väga hoolikat suuruse määramist, mille osas saab meilt tasuta abi küsida :-).
Metroklastri seadistamine
Metroklastri seadistamine on väga sarnane tavalise replikatsiooni seadistamisega, millest oleme rääkinud . Seetõttu keskendume ainult erinevustele. Oleme laboris seadistanud katsejaama, mis põhineb eespool kirjeldatud arhitektuuril, ainult minimaalsetes tingimustes: kaks andmesalvestusseadet, ühendatud omavahel 10G Etherneti kaudu, kaks 10G lülitit ja üks host, mis vaatab lülitite kaudu mõlemasse andmesalvestusseadmesse 10G portidega. Arbitrator töötab virtuaalses masinas.
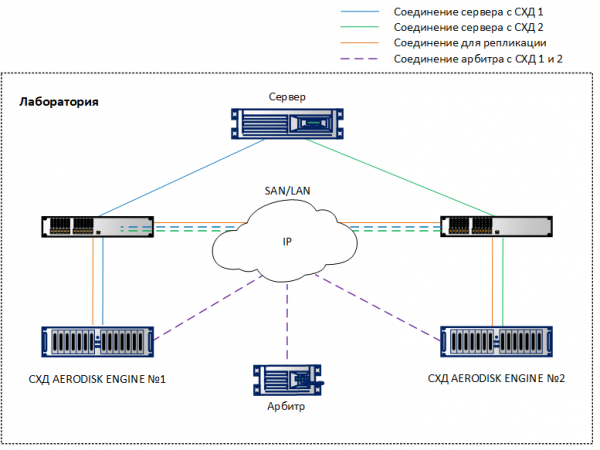
Virtuaalsete IP-de (VIP) seadistamisel replikale tuleks valida VIP tüüp – metrokluster.
Oleme loonud kaks replikatsiooniühendust kahe LUN-i jaoks ja jaotanud need kahe andmesalvestusseadmest: LUN TEST Primary andmesalvestusseadmest 1 (ühendus METRO), LUN TEST2 Primary andmesalvestusseadmest 2 (ühendus METRO2).
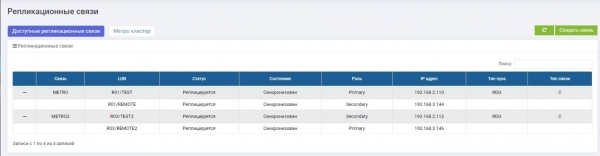
Nende jaoks seadistasime kaks identset sihtpunkti (meie juhul iSCSI, kuid toetatakse ka FC-d, seadistamise loogika on sama).
Andmesalvestusseade 1:

Andmesalvestusseade 2:
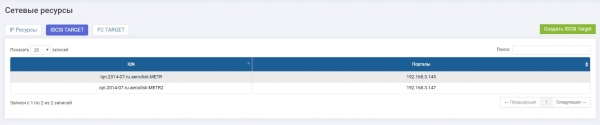
Replikatsiooniühenduste jaoks tegime igas andmesalvestusseadmest mappimised.
Andmesalvestusseade 1:
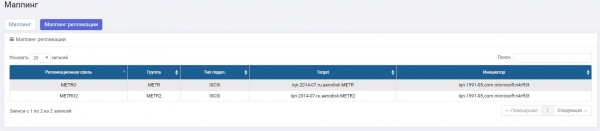
Andmesalvestusseade 2:
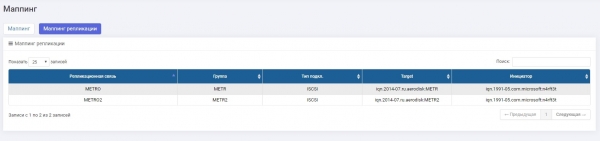
Seadistasime multipath'i ja esitleme hostis.
Seadistame arbitratori.
Arbiitra ise ei pea tegelikult midagi tegema; tuleb lihtsalt see kolmandal platvormil sisse lülitada, määrata IP ja seadistada sellele juurdepääs ICMP ja SSH kaudu. Ise seadistamine toimub otse RAID-jõudlustel. Seejuures piisab, kui seadistada arbiiter üks kord mõnes tehnikasüsteemi kontrolleris metroklusteris; need seadistused levitatakse automaatselt kõigile kontrolleritele.
Sektsioonis Kaug-replikatsioon >> Metrokluster (iga kontrolleris) >> nupp „Konfigureerida“.
Sisestame arbiitri IP-aadressi ning kaugete RAID-jõudluste kahe kontrolleri juhtimisliidese.
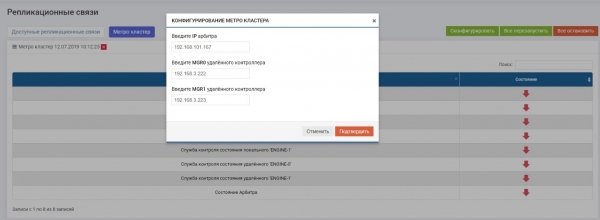
Pärast seda tuleb aktiveerida kõik teenused (nupp „Käivita kõik uuesti“). Juhul kui seadistust tulevikus muudetakse, tuleb teenused kindlasti uuesti käivitada, et muudatused jõustuksid.
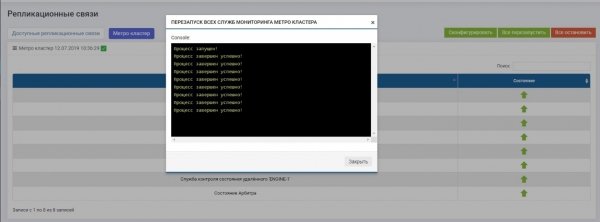
Kontrollime, et kõik teenused on käivitunud.
Sellega on metrokluster seadistamine lõpetatud.
Krahh-test
Krahh-test on meie juhul piisavalt lihtne ja kiire, kuna replikatsiooni funktsionaalsus (vahetus, järjepidevus jne) on juba varem käsitletud. . Seetõttu, et testida metroklaastrite usaldusväärsust, piisab meile hädaolukorra tuvastamise, lülitumise ja andmete kaotuse vältimise automatiseerimise kontrollimisest (sisend-väljund peatamine).
Selleks emuleerime ühe salvestusseadmestiku täieliku rikkumise, lülitades välja mõlemad selle kontrollerid, alustades eelnevalt suure faili kopeerimist LUN-ile, mis peab aktiveeruma teises salvestusseadmestikus.
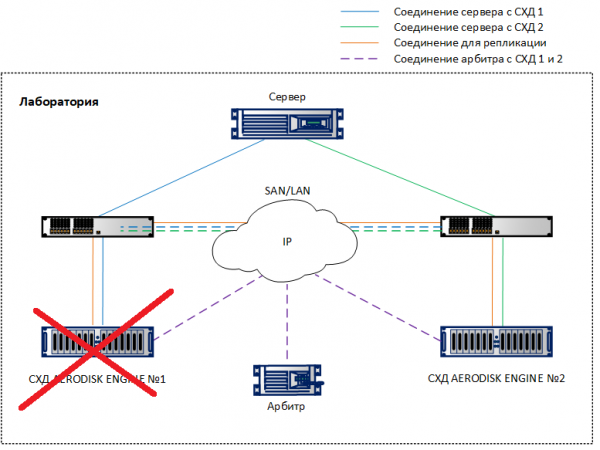
Oleme lülitanud välja ühe salvestusseadmestiku. Teises salvestusseadmestikus näeme häireid ja logisid teateid, et ühendus naaber süsteemiga on kadunud. Kui SMTP või SNMP jälgimine on seadistatud, saadab administraatorile vastavad teated.
Just 10 sekundi pärast (nagu on näha mõlemalt ekraanipildilt) muutus METRO replikatsiooniühendus (see, mis oli Primary kukkunud salvestusseadmestikus) automaatselt Primary töötavas salvestusseadmestikus. Kasutades olemasolevat kaardistust, jäi LUN TEST hostile kergesti kätte saadavaks, kirjutamine vähenes pisut (lubatud 10 protsendi piires), kuid ei katkenud.

Test lõpetati edukalt.
Kokkuvõte
AERODISK Engine N-seeria metrokliusterite praegune teostus võimaldab täielikult lahendada ülesandeid, kus on vajalik IT-teenuste katkestuste vältimine või nende aega minimeerimine ning tagada nende töö 24/7/365 režiimis väikeste tööjõukuludega.
Võime mõelda, et see kõik on teooria, ideaalsed laboratoorsed tingimused jne... KUID meil on mitmeid rakendatud projekte, kus oleme realiseerinud katastroofikindluse funktsiooni, ning süsteemid töötavad suurepäraselt. Üks meie tuntud klientidest, kus kasutatakse just kahte andmesalvestuslahendust katastroofikindlas konfiguratsioonis, on juba andnud nõusoleku projekti teabe avaldamiseks, seega järgmises osas räägime rakendamisest.
Aitäh, ootame produktiivset arutelu.
Allikas: habr.com
