


Tere, Habr! Selles artiklis soovin rääkida ühest suurepärasest tööriistast andmete töötlemise batch-protsesside arendamiseks, näiteks ettevõtte DWH või teie DataLake infrastruktuuris. Räägime Apache Airflow'st (edaspidi Airflow). Ta on Habr'is ebaõiglaselt tähelepanuta jäetud ja peamises osas püüan ma veenda teid, et vähemalt Airflow'le tasub tähelepanu pöörata, kui valite ETL/ELT-protsesside ajakava.
Varem olen kirjutanud seeria artikleid DWH teemal, kui töötasin Tinkoff Pangas. Nüüd olen osa Mail.Ru Group'ist ja tegelen andmete analüüsiplatvormi arendamisega mänguvaldkonnas. Tegelikult, uudiste ja huvitavate lahenduste ilmumise korral räägime me oma meeskonnaga siin meie andmete analüütika platvormist.
Proloog
Nii, alustame. Mis on Airflow? See on teek (või ) töövoogude arendamiseks, planeerimiseks ja jälgimiseks. Airflow peamine omadus: protsesside kirjeldamiseks (arendamiseks) kasutatakse Python'i keelt. Sealt tulenevad palju eeliseid oma projekti ja arenduse korraldamiseks: sisuliselt on teie (näiteks) ETL-projekt lihtsalt Python-projekt, mida saate korraldada vastavalt oma vajadustele, arvestades infrastruktuuri eripära, meeskonna suurust ja muid nõudeid. Tööriistad on lihtsad. Kasutage näiteks PyCharm'i + Git'i. See on suurepärane ja väga mugav!
Nüüd vaatame Airflow'i põhielemente. Mõistes nende olemust ja eesmärki, korraldate protsesside arhitektuuri optimaalselt. Peamine element on suunatud tsükliline graaf (edaspidi DAG).
DAG
DAG on teie ülesannete mõtteline kogum, mida soovite teatavas järjekorras teatud ajakava järgi täita. Airflow pakub mugavat veebiliidest DAG'ide ja teiste elementide haldamiseks:
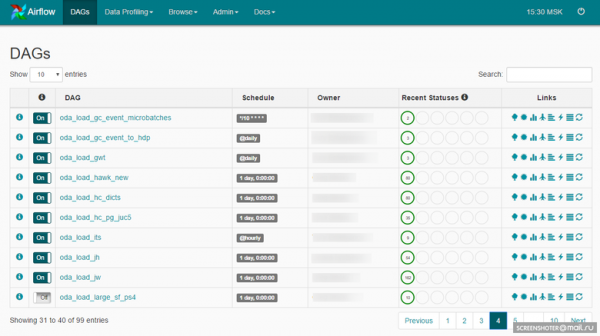
DAG võib välja näha selline:
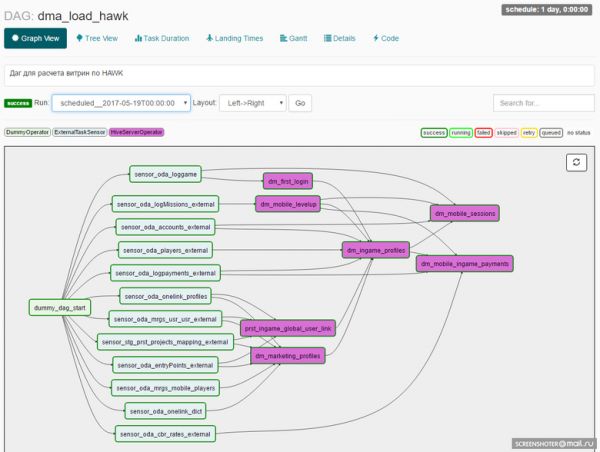
Arendaja, kavandades DAG-i, sisestab operaatorite komplekti, mille põhjal ülesanded DAG-is üles ehitatakse. Siit jõuame veel ühe olulise kontseptsioonini: Airflow Operaator.
Operaatorid
Operaator on üksus, mille alusel luuakse tööülesannete eksemplarid, kus kirjeldatakse, mis toimub tööülesande eksemplari täitmise ajal. kannavad juba endas komplekti valmis kasutamiseks mõeldud operaatoritest. Näited:
- BashOperator — operaator bash-käskude täitmiseks.
- PythonOperator — operaator Python-koodi kutsumiseks.
- EmailOperator — operaator e-kirjade saatmiseks.
- HTTPOperator — operaator HTTP-päringute tegemiseks.
- SqlOperator — operaator SQL-koodi täitmiseks.
- Sensor — operaator, mis ootab sündmust (nagu vajaliku aja saabumine, nõutava faili ilmumine, rida andmebaasis, API-st saadud vastus jne).
On ka spetsiifilisemaid operaatoreid: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
Samuti saate arendada operaatorite, lähtudes oma eripäradest, ja kasutada neid projektis. Näiteks lõime MongoDBToHiveViaHdfsTransfer, operaatori dokumentide eksportimiseks MongoDB-st Hive'i, ja mitu operaatorit tööks koos. : CHLoadFromHiveOperator ja CHTableLoaderOperator. Tegelikult, kui projektis tekib sageli kasutatav kood, mis on üles ehitatud põhioperatoritele, siis tasub kaaluda selle kokkupanekut uueks operaatoriks. See lihtsustab edasist arendust ning täidate oma projekti operaatorite raamatukogu.
Seejärel tuleb need ülesande eksemplarid täita ning nüüd räägime ajastamisest.
Ajakava
Airflow ülesannete ajastaja põhineb . Celery on Python'i teek, mis võimaldab korraldada järjekorvi ning asünkroonset ja jaotatud ülesannete täitmist. Airflow'i poolelt jagunevad kõik ülesanded basseinideks. Basseinid luuakse käsitsi. Reeglina on nende eesmärgiks piirata koormust allikaga töötamisel või tüüpeerida ülesandeid DWH sees. Basseine saab hallata veebiliidese kaudu:
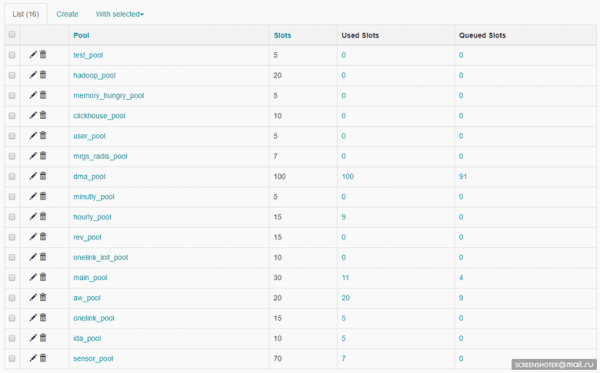
Igal basseinil on piirang salveslotide arvu osas. DAG'i loomisel määratakse sellele bassein:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh")
DAG_NAME = 'dma_load'
OWNER = 'Vasya Pupkin'
DEPENDS_ON_PAST = True
EMAIL_ON_FAILURE = True
EMAIL_ON_RETRY = True
RETRIES = int(Variable.get('gv_dag_retries'))
POOL = 'dma_pool'
PRIORITY_WEIGHT = 10
start_dt = datetime.today() - timedelta(1)
start_dt = datetime(start_dt.year, start_dt.month, start_dt.day)
default_args = {
'owner': OWNER,
'depends_on_past': DEPENDS_ON_PAST,
'start_date': start_dt,
'email': ALERT_MAILS,
'email_on_failure': EMAIL_ON_FAILURE,
'email_on_retry': EMAIL_ON_RETRY,
'retries': RETRIES,
'pool': POOL,
'priority_weight': PRIORITY_WEIGHT
}
dag = DAG(DAG_NAME, default_args=default_args)
dag.doc_md = __doc__DAG tasemel määratud bassein saab ülesande tasemel üle kirjutada.
Airflowis vastutab kõigi ülesannete ajastamise eest eraldi protsess — Scheduler. Scheduler tegeleb ülesannete täitmise mehaanika kõigega, mis on seotud ülesannete tegemisega. Ülesanne peab enne täitmist läbima mitu etappi:
- DAG-is on eelnevad ülesanded lõpetatud, uue saab järjekorda panna.
- Järjekord sorteeritakse vastavalt ülesannete prioriteetidele (prioriteetidega saab samuti hallata) ning kui basseinil on vaba koht, saab ülesande tööle võtta.
- Kui vaba celery worker on olemas, suunatakse ülesanne sellesse; algab töö, mille te olete ülesandes määratlenud, kasutades seda või seda operaatorit.
Lihtne.
Scheduler töötab mitmete DAG-ide ja DAG-ides asuvate ülesannete peal.
Kuna Scheduler peab hakkama töötama DAG-iga, peab DAG-il olema ajakava:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')On olemas hulk valmispreset'e: @once, @hourly, teeb põhiosa tööst, aga mitte nüüd. Hetkel lihtsalt väljastame meie konteksti logisse., @weekly, @monthly, @yearly.
Samuti on võimalik kasutada cron-väljendeid:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')Täideviimise kuupäev
Airflow'i toimimise mõistmiseks on oluline mõista, mis on DAG-i jaoks Täideviimise kuupäev. Airflow's on DAG-il Täideviimise kuupäeva mõõde, st sõltuvalt DAG-i töö ajakavast luuakse iga Täideviimise kuupäeva jaoks ülesande eksemplarid. Ja iga Täideviimise kuupäeva jaoks saab ülesandeid uuesti täita — või näiteks võib DAG töötada samaaegselt mitmel Täideviimise kuupäeval. See on selgelt näidatud siin:
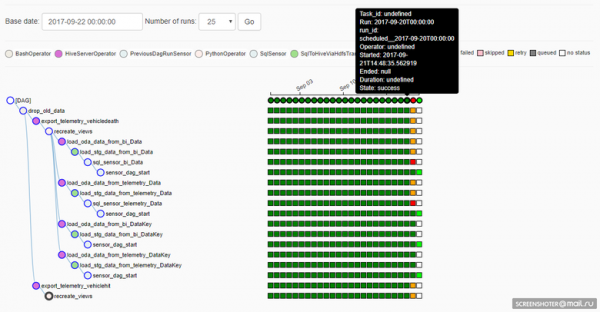
Kahjuks (või võib-olla ka õnneks, sõltub olukorrast) on, kui DAG'i ülesande elluviimist muudetakse, siis eelnevate täitmise kuupäevade tulemused arvestavad juba parandusi. See on hea, kui on vaja andmeid varasemate perioodide jooksul uuesti arvutada uue algoritmiga, kuid halb, kuna tulemuse korduvus kaob (loomulikult ei takista miski tagasi minna Git'i ja saada vajalik lähtekood ning ühekordselt arvutada, kuidas vaja).
Ülesannete genereerimine
DAG'i elluviimine — kood Pythonis, seega on meil väga mugav võimalus koodi mahtu vähendada, töötades näiteks sharditud allikatega. Oletame, et teil on kolm MySQL shard'i allikana, peate minema igasse ja võtma mingid andmed. Samas sõltumatult ja paralleelselt. Pythonis DAG'is võib kood välja näha selline:
connection_list = lv.get('connection_list')
export_profiles_sql = '''
SELECT
id,
user_id,
nickname,
gender,
{{params.shard_id}} as shard_id
FROM profiles
'''
for conn_id in connection_list:
export_profiles = SqlToHiveViaHdfsTransfer(
task_id='export_profiles_from_' + conn_id,
sql=export_profiles_sql,
hive_table='stg.profiles',
overwrite=False,
tmpdir='/data/tmp',
conn_id=conn_id,
params={'shard_id': conn_id[-1:], },
compress=None,
dag=dag
)
export_profiles.set_upstream(exec_truncate_stg)
export_profiles.set_downstream(load_profiles)DAG on selline:
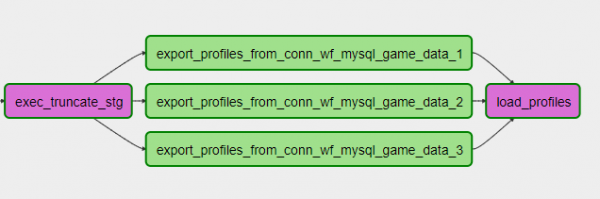
Selle käigus saab shardi lisada või eemaldada, lihtsalt seadistust kohandades ja DAG-i värskendades. Mugav!
Saate kasutada ka keerukamat koodigeneratsiooni, näiteks töötades andmebaasi allikatest või kirjeldades tabelistruktuuri, tabelite töötlemise algoritmi ning laenguprotsessi genereerimist, arvestades DWH infrastruktuuri eripärasid. Või näiteks, kui API ei toeta loendina parametri töötlemist, saate selle loendi põhjal DAG-is genereerida N ülesannet, piirata API-päringute paralleelsust ja koguda vajalikud andmed API-st. Paindlik!
Repo
Airflow'il on oma tagavarala, andmebaas (see võib olla MySQL või Postgres, meil on Postgres), kus hoitakse ülesannete, DAG'ide, ühenduste seadete, globaalsete muutujate jne olekuid. Siinkohal tahaksin öelda, et Airflow'i tagavara on väga lihtne (umbes 20 tabelit) ja mugav, kui soovite selle üle oma protsessi luua. Tuleb meelde 100500 tabelit Informatica tagavaras, mis nõudsid pikaajalist tutvumist, enne kui sain aru, kuidas päringut koostada.
Jälgimine
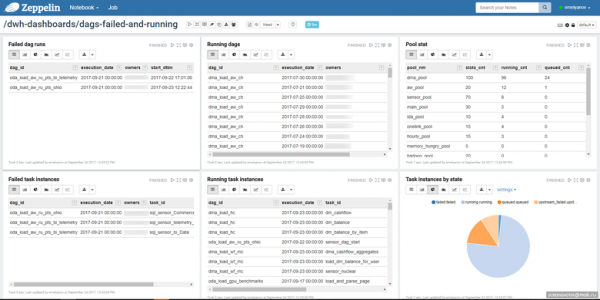
Arvestades tagavara lihtsust, saate ise luua endale sobiva ülesannete jälgimise protsessi. Me kasutame Zeppelin'is märkmikku, kus vaatame ülesannete olekut:
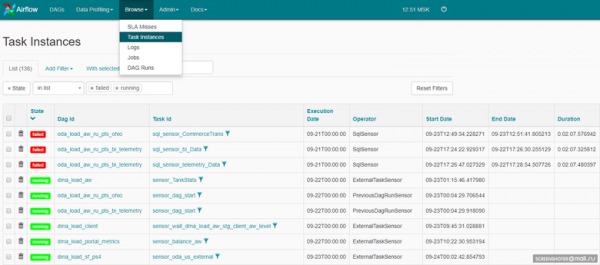
See võib olla ka Airflow'i veebiliides:
Airflow'i kood on avatud, seega lisasime me teavituse Telegram'i. Iga ülesande aktiivne instants, kui toimub viga, spammib Telegram'i gruppi, kus on kogu arendus- ja tugimeeskond.
Saame Telegram'i kaudu kiire reageerimise (kui see on vajalik), Zeppelin'i kaudu — üldise ülevaate Airflow'i ülesannetest.
Kokku
Airflow on avatud lähtekoodiga ja ei tasu oodata, et see imepäraselt töötaks. Olge valmis investeerima aega ja vaeva, et luua toimiv lahendus. Eesmärk on saavutatav ja uskuge, see on seda väärt. Arenduse kiirus, paindlikkus, uute protsesside lihtne lisamine — teile meeldib see. Loomulikult tuleb palju tähelepanu pöörata projekti korraldamisele ja Airflow enda tööstabiilsusele: imesid ei juhtu.
Praegu töötleb meie Airflow igapäevaselt umbes 6,5 tuhat ülesannet. Need ülesanded on iseloomult üsna erinevad. On ülesandeid andmete laadimiseks peamisse DWH-st paljusid erinevaid ja väga spetsiifilisi allikaid, on ülesandeid vitriinide arvutamiseks peamise DWH sees, on ülesandeid andmete avaldamiseks kiiremas DWH-s, ja palju, palju erinevaid ülesandeid — ja Airflow töötleb kõiki neid päevast päeva. Kui rääkida numbritest, siis see on 2,3 tuhat ELT erineva keerukusega ülesannet DWH-s (Hadoop), umbes 250 erinevat andmebaasi allikat, see on meeskond neljast ETL arendajast, kes jagunevad ETL andmete töötlemise ja ELT andmete töötlemise vahel DWH-s ja muidugi veel üks administraator, kes tegeleb teenuse infrastruktuuriga.
Tulevikuplaanid
Protsesside arv kasvab üha enam ning meie peamine tegevusala Airflow infrastruktuuris on skaleerimine. Tahame luua Airflow klastrit, eraldada mõned jalad Celery töötajatele ja teha dubleeriva pea, mis haldab ülesannete planeerimise protsesse ja hoidlat.
Epilog
See ei ole muidugi kõik, mida Airflow kohta rääkida tahaks, kuid olen püüdnud peamised punktid esile tuua. Isu tuleb söögi ajal, proovi — ja sulle meeldib 🙂
Allikas: habr.com
