


Kui haldate virtuaalset infrastruktuuri, mis põhineb VMware vSphere'il (või mõnel muul tehnoloogiastakil), kuulete kindlasti sageli kasutajatelt kaebusi: "Virtuaalmasin töötab aeglaselt!". Selles artiklite sarjas arutan jõudlusmeetmeid ja selgitan, mis ja miks "pidurdab", ning kuidas tagada, et see ei "pidurdaks".
Käsitlen järgmisi virtuaalmasinate jõudluse aspekte:
- CPU,
- RAM,
- DISK,
- Võrk.
Alustan CPU-st.
Jõudluse analüüsimiseks vajame:
- vCenter Performance Counters – jõudluse arvestid, mille graafikute vaatamiseks on vaja kasutada vSphere Clienti. Teave nende arvestite kohta on kergesti saadaval mis tahes versiooni kliendis (“paks” klient C#-is, veebiklient Flexil ja HTML5 veebiklient). Nendes artiklites kasutame ekraanipilte C#- klientidest, kuna need näevad väikese pildi vaates paremad välja :)
- ESXTOP – utiliit, mida käivitatakse käsurealt ESXi. Selle abil saab reaalajas jälgida jõudlusnäitajaid või eksportida neid teatud ajaperioodi jooksul .csv faili edasise analüüsi jaoks. Allpool tutvustan seda tööriista lähemalt ja jagan mitmeid kasulikke linke dokumentatsiooni ja artiklite kohta.
Natuke teooriat
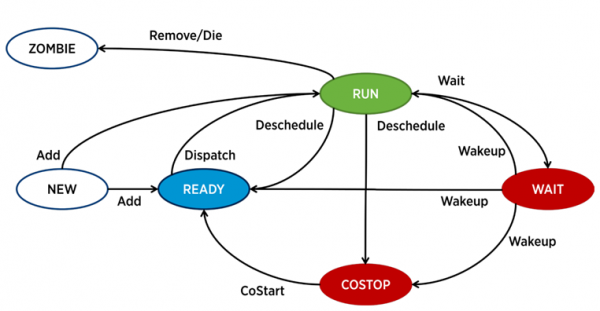
ESXi-s vastutab iga vCPU (virtuaalmasina tuum) eest eraldi protsess – world VMware terminoloogias. Samuti on olemas teenusprotsessid, kuid virtuaalmasina jõudluse analüüsi vaatepunktist on need vähem huvitavad.
Protsess võib ESXi-s olla ühes neljast olekust:
- Run – protsess täidab mingit kasulikku tööd.
- Oota – protsess ei tee mingit tööd (idle) või ootab sisend/väljundit.
- Costop – seisund, mis tekib mitme tuumaga virtuaalmasinates. See tekib, kui hüperviisira CPU planeerija (ESXi CPU Scheduler) ei suuda kavandada kõigi aktiivsete virtuaalmasina tuumade samaaegset täitmist füüsilistel serveri tuumadel. Füüsilises maailmas töötavad kõik protsessorituumad paralleelselt, mistõttu ootab virtuaalmasina sisene külalis-OS sarnast käitumist. Seetõttu peab hüperviir vähenema virtuaalmasina tuumadega, millel on võimalus tsüklit kiiremini lõpetada. Kaasaegsetes ESXi versioonides kasutab CPU planeerija mehhanismi, mida nimetatakse relaxed co-scheduling: hüperviir arvutab erinevust kõige „kiirema“ ja kõige „aeglasema“ virtuaalmasina tuuma vahel (skew). Kui erinevus ületab teatud läve, siirdub „kiire“ tuum costop olekusse. Kui virtuaalmasina tuumad spendivad palju aega selles olekus, võib see põhjustada jõudluse probleeme.
- Valmis – protsess siirdub sellesse olekusse, kui hüperviiral puuduvad ressursid selle täitmiseks. Suured väärtused ready võivad tekitada virtuaalmasina jõudlusprobleeme.
Virtuaalmasina CPU jõudluse põhistatis
CPU kasutus, % Näitab CPU kasutuse protsenti määratud ajavahemiku jooksul.
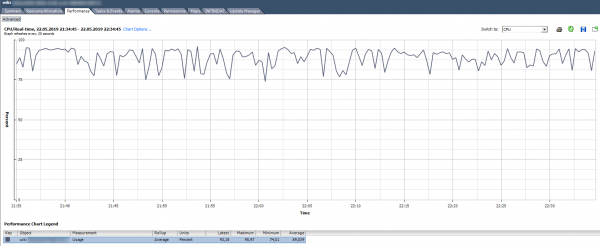
Kuidas analüüsida? Kui virtuaalmasin kasutab pidevalt CPU-d 90% või on tipud kuni 100%, siis on meil probleem. Probleemid võivad ilmneda mitte ainult virtuaalmasinas töötava rakenduse „aeglase“ toimimise kaudu, vaid ka virtuaalmasina võrgu kaudu puudumise kaudu. Kui jälgimissüsteem näitab, et virtuaalmasin perioodiliselt „langeb välja“, tasub tähelepanu pöörata CPU kasutuse graafiku tipudele.
On standardne alarm, mis näitab virtuaalmasina CPU koormust:

Mis teha? Kui virtuaalmasina CPU kasutus on pidevalt üle, siis võib mõelda vCPU arvu suurendamisele (kahjuks ei aita see alati) või virtuaalmasina viimisele serverisse, millel on võimsamad protsessorid.
CPU kasutus MHz-des
vCenteri graafikutes on %-kasutus näha ainult kogu virtuaalmasina kaupa, eraldi tuumade graafikuid ei ole (Esxtop hindamise puhul on väärtused % tuumade järgi olemas). Iga tuuma puhul on võimalik vaadata kasutust MHz-des.
Kuidas analüüsida? Juhtub, et rakendus ei ole optimeeritud mitme tuuma arhitektuuriks: see kasutab 100% ainult ühte tuuma ja teised jäävad koormamata. Näiteks MS SQL varukoopiate vaikevalikutes käivitab see protsessi ainult ühel tuumal. Selle tulemuseks on see, et varukoopiate tegemine viibib, mitte ebapiisava kettakiirusest (just sellele kasutaja alguses kaebas), vaid sellepärast, et protsessor ei jaksa. Probleem lahendati parameetrite muutmise kaudu: varukoopiad hakatakse käivitama paralleelselt mitmesse faili (seega mitmesse protsessi).
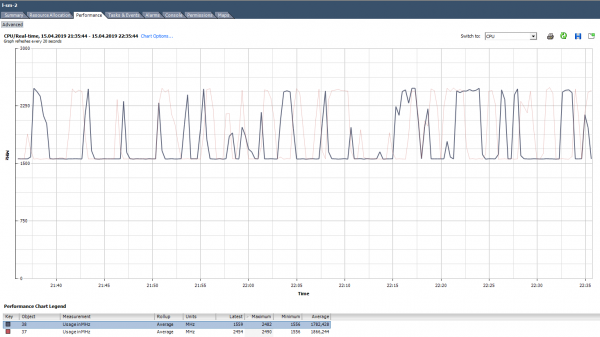
Ebaühtlase koormuse näide tuumadele.
Samuti esineb olukord (nagu ülaltoodud diagrammil), kus tuumad on ebavõrdse koormusega ja mõnel neist on 100% tipud. Nagu ühe tuuma koormuse korral, ei aktiveeru CPU kasutuse alarm (see on kogu VM ulatuses), kuid leidub jõudluse probleeme.
Mis teha? Kui tarkvara virtuaalses masinas koormab tuumasid ebaühtlaselt (kasutab ainult ühte tuuma või osalist tuumade hulka), pole mõtet nende arvu suurendada. Sellisel juhul on parem viia VM serverisse, kus on võimekamad protsessorid.
Samuti tasub proovida kontrollida serveri energiasäästu seadistusi BIOS-is. Paljud administraatorid aktiveerivad BIOS-is kõrge jõudluse režiimi, mis väljalülitab C-staatide ja P-staatide energiasäästetehnoloogiad. Kaasaegsetes Intel protsessorites kasutatakse Turbo Boost tehnoloogiat, mis suurendab üksikute protsessorituumade sagedust teiste tuumade arvelt. Kuid see töötab ainult energiasäästetehnoloogiate sisse lülitamisel. Kui me need välja lülitame, ei saa protsessor vähendada koormamata tuumade energiatarvet.
VMware soovitab mitte välja lülitada energiasäästetehnoloogiaid serverites, vaid valida režiimid, mis annavad energiasäästu juhtimise maksimaalselt hüperviisorile. Sel juhul tuleks hüperviisori energiasäästu seadistustes valida kõrge jõudluse režiim.
Kui teie infrastruktuuris nõuavad eraldi virtuaalmasinad (või virtuaalmasinate tuumad) suurenenud CPU sagedust, võib õige energiasäästu seadistus oluliselt parandada nende jõudlust.
CPU Ready (Valmidus)
Kui virtuaalmasina (vCPU) tuum on olekus Ready, ei täida see mingit kasulikku tööd. See olek tekib siis, kui hüperviisor ei leia vabade füüsiliste tuumade seas ühtegi, kuhu virtuaalmasina vCPU protsessi määrata.
Kuidas analüüsida? Tavaliselt, kui virtuaalmasina tuumad on olekus Ready rohkem kui 10% ajast, märkate soorituse probleeme. Lihtsamalt öeldes, rohkem kui 10% ajast ootab virtuaalmasin füüsiliste ressursside kättesaadavust.
vCenteris saab vaadata kahte CPU Ready-ga seotud mõõdikut:
- Readiness,
- Ready.
Mõlema mõõdiku väärtusi saab vaadata nii kogu virtuaalmasina kohta kui ka eraldi tuumade kaupa.
Readiness näitab väärtust protsentides, kuid ainult reaalajas (andmed viimase tunni jooksul, mõõtmisintervall 20 sekundit). Seda mõõdikut on parem kasutada ainult probleemide kiireks leidmiseks.
Ready loendurite väärtusi saab vaadata ka ajalises perspektiivis. See on kasulik mustrite määratlemiseks ja probleemide sügavamaks analüüsimiseks. Näiteks, kui virtuaalmasinal tekivad jõudlusprobleemid kindlal ajal, saab võrrelda suurenenud CPU Ready väärtuste ajavahemikke serveri üldise koormusega, kus antud virtuaalmasin töötab, ning võtta meetmeid koormuse vähendamiseks (kui DRS ei ole sellega toime tulnud).
Ready, erinevalt Readinessist, ei näidata protsentides, vaid millisekundites. See on summatsioonitüüp, mis näitab, kui kaua oli VM südamik mõõtmise ajal Ready olekus. Selle väärtuse protsentideks muutmiseks saab kasutada lihtsat valemit:
(CPU ready summation value / (chart default update interval in seconds * 1000)) * 100 = CPU ready %
Näiteks, alloleval graafikul on virtuaalmasina kogu ready oleku tippväärtus järgmine:

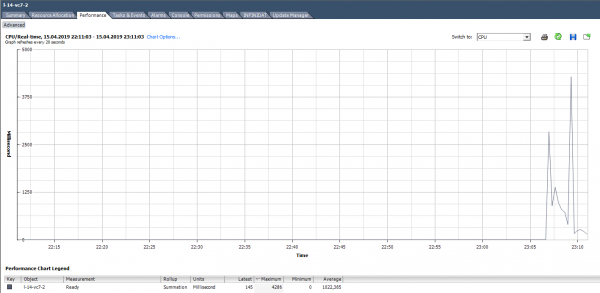
Ready väärtuse protsentides arvutamisel tasub pöörata tähelepanu kahele punktile:
- Terve VM ready väärtus on südamike Ready väärtuste summa.
- Mõõtmise intervall. Reaalajas – 20 sekundit, aga näiteks päevagrafikute puhul – 300 sekundit.
Aktiivse tõrkeotsingu käigus võivad need lihtsad punktid kergesti ununeda, raisates väärtuslikku aega mittetekkivate probleemide lahendamisele.
Arvutame Ready, tuginedes allolevalt graafikult saadud andmetele. (324474/(20*1000))*100 = 1622% tervele VM-ile. Kui vaadata tuumade kaupa, ei tundu see enam nii hirmutav: 1622/64 = 25% tuuma kohta. Antud juhul on petmine suhteliselt lihtne: Ready väärtus ei ole realistlik. Kuid kui jutt käib 10–20% terve VM-i kohta mitme tuumaga, võivad olla tuuma kaupa väärtused täiesti normi piires.
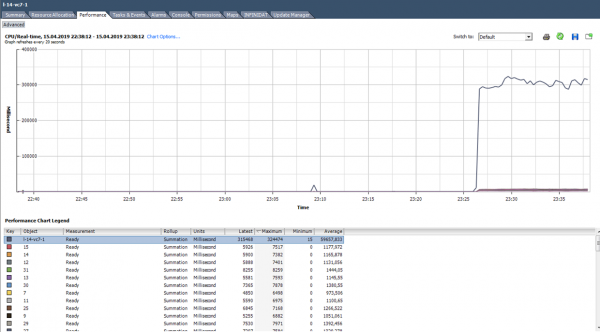
Mis teha? Kõrge Ready väärtus näitab, et serveril napib protsessorivõimsust virtuaalmasinate normaalseks toimimiseks. Sellises olukorras tuleb vähendada protsessori liialdust (vCPU:pCPU). Seda saab ilmselgelt teha, vähendades olemasolevate VM-ide parameetreid või migreerides osa VM-e teistele serveritele.
Co-stop
Kuidas analüüsida? Sellel loenduril on samuti tüüp Summation ja seda tõlgitakse protsentideks nagu Ready:
(CPU co-stop summation value / (chart default update interval in seconds * 1000)) * 100 = CPU co-stop %
Siin tuleb samuti tähele panna, kui palju tuumasid on VM-is ja mõõtmise intervalli.
Co-stop olekus ei tee kasulikku tööd. Õige VM suuruse ja serveri normaalse koormuse korral peaks co-stop number olema lähedane nullile.
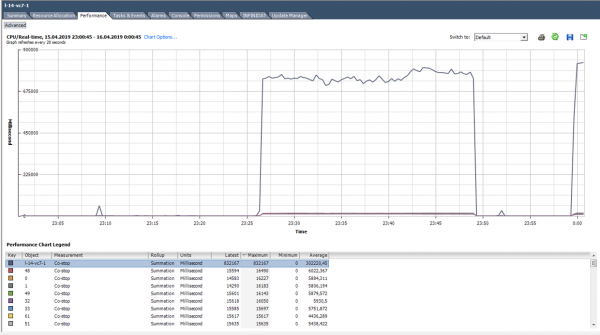
Antud juhul on koormus selgelt ebanormaalne :)
Mis teha? Kui ühel hüpervahendajal töötab mitu VM-i, millel on palju tuumikke ja on olemas CPU ülediviseerimine, võib co-stop number suureneda, mis toob kaasa probleemid nende VM-ide jõudluses.
Samuti kasvab co-stop, kui aktiivsete tuumade jaoks kasutatakse ühe VM-i lõime ühel füüsilisel tuumal serveris koos aktiveeritud hyper-threading'uga. Selline olukord võib tekkida näiteks siis, kui VM-il on rohkem tuumikke, kui füüsiliselt on serveris, kus see töötas, või kui VM-i jaoks on aktiveeritud seade 'preferHT'. Selle seade kohta saab rohkem lugeda .
Et vältida VM-i jõudlusprobleeme kõrge co-stop tõttu, valige VM suurus vastavalt tarkvara tootja soovitustele, mis töötab sellel VM-il, ja füüsilise serveri võimalustele, kus VM töötab.
Ärge lisage tuumikke reservidena, see võib tekitada jõudlusprobleeme mitte ainult VM-is endas, vaid ka tema naabrite seas serveris.
Teised kasulikud CPU metoodikad
Run – kui palju aega (ms) vCPU mõõtmise perioodi jooksul oli RUN olekus, st täitis tõeliselt tööd.
Idle – kui palju aega (ms) vCPU mõõtmise perioodi jooksul oli inaktiivses olekus. Kõrged Idle väärtused ei ole probleem, lihtsalt vCPU-l ei olnud "midagi teha".
Oota – kui palju aega (ms) vCPU mõõtmise perioodi jooksul oli Wait olekus. Kuna see arvestab ka IDLE, siis kõrged Wait väärtused ei tähenda samuti probleemi. Kui aga kõrge Wait ajal on IDLE madal, siis tähendab see, et VM ootas sisendi/väljundi operatsioonide lõpuleviimist, mis võib viidata probleemile kõvaketta või mõne virtuaalse seadme jõudlusega.
Max limited – kui palju aega (ms) vCPU mõõtmise perioodi jooksul oli Ready olekus seetõttu, et ressursside limiit oli seadistatud. Kui jõudlus on seletamatult madal, siis on kasulik kontrollida selle arvesti väärtust ja CPU limiiti VM seadetes. VM võib tõepoolest olla seatud limiidid, millest te ei tea. Näiteks juhtub see, kui VM on kloonitud mallist, millel oli CPU limiit.
Swap wait – kui kaua vCPU mõõtmise perioodi jooksul ootas operatsiooni VMkernel Swap. Kui selle loenduri väärtused on üle nulli, on VM-il kindlasti jõudlusprobleeme. Rohkem SWAP-ist räägime mälulugemist loenduri artiklis.
ESXTOP
Kui vCenter'i jõudlusloendurid sobivad ajalooliste andmete analüüsiks, siis on probleemi operatiivseks analüüsiks parem kasutada ESXTOP'i. Siin esitatakse kõik väärtused valmis kujul (midagi ei pea tõlkima) ning minimaalne mõõtmise periood on 2 sekundit.
CPU ESXTOP ekraan avatakse klahviga «c» ja see näeb välja järgnev.

Mugavuse huvides saab jätta alles ainult virtuaalmasinate protsessid, vajutades Shift-V.
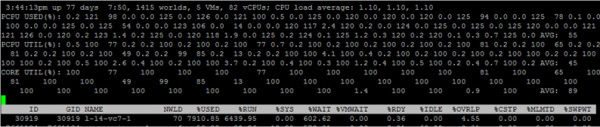
Selleks, et näha individuaalseid tuumade metrikaid, vajutage «e» ja sisestage huvi pakkuva VM-i GID (30919 alloleval ekraanipildil):
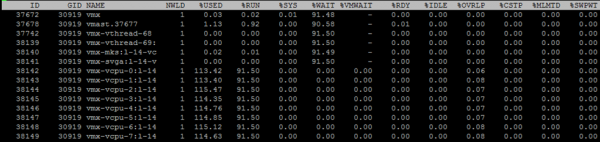
Käin kiiresti üle vaikimisi esitatud veergude. Täiendavaid veerge saab lisada, vajutades «f».
NWLD (Number of Worlds) – protsesside arv grupis. Grupi avamiseks ja iga protsessi (nt iga tuuma mitme tuumaga VM) metrikate nägemiseks vajutage "e". Kui grupis on rohkem kui üks protsess, siis grupi metrikate väärtused on võrdsed üksikute protsesside metrikate summaga.
%KASUTATUD – kui palju CPU tsükleid server kasutab protsess või protsesside grupp.
%JOOKSUS – kui kaua protsess oli mõõtmisperioodi jooksul RUN seisundis, st tegi kasulikku tööd. Erineb %KASUTATUD-st, kuna ei arvesta hyper-threading'ut, sageduse skaleerimist ja aega, mida kulutatakse süsteemitöödele (%SYS).
%SYS – aeg, mis kulub süsteemitöödele, näiteks katkestuste, sisendi/väljundi töötlemisele, võrgu tööle jms. Väärtus võib olla kõrge, kui VM-is on suur sisend/väljund.
%ÜLEVIK – kui kaua füüsiline tuum, millel VM-protsess töötab, on teisi protsesside ülesannete täitmisele kulutanud.
Need metrikad seonduvad üksteisega järgmiselt:
%KASUTATUD = %JOOKSUS + %SYS — %ÜLEVIK.
Tavaliselt on %KASUTATUD metrika informatiivsem.
%OOTEL – kui kaua protsess oli mõõtmisperioodi jooksul OOTEL seisundis. Sisaldab IDLE.
%IDLE – kui kaua protsess oli mõõtmisperioodi jooksul IDLE olekus.
%SWPWT – kui kaua kõik mõõtmisperioodi jooksul vCPU ootas VMkernel Swap'i operatsiooni.
%VMWAIT – kui kaua kõik mõõtmisperioodi jooksul vCPU oli sündmuse ootamise olekus (tavaliselt sisse-/väljaandmine). Vastavat loenduri vCenter'is ei ole. Suured väärtused viitavad sisendi/väljundi probleemidele VM-is.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Kui VM ei kasuta VMkernel Swap'i, siis on probleemide analüüsimisel mõistlik vaadata %VMWAIT'i, kuna see näitaja ei arvesta aega, mil VM ei teinud midagi (%IDLE).
%RDY – kui kaua mõõtmisperioodi jooksul protsess oli Ready olekus.
%CSTP – kui kaua mõõtmisperioodi jooksul protsess oli kostop olekus.
%MLMTD – kui kaua mõõtmisperioodi jooksul vCPU oli Ready olekus, kuna ressursi piirang oli seatud.
%WAIT + %RDY + %CSTP + %RUN = 100% – VM-i südamik on pidevalt mõnes neist neljast olekust.
CPU hüpervisoril
vCenter'is on samuti hüpervisori CPU tõhususe loendurid, kuid need ei ole midagi huvitavat – need on lihtsalt kõigi serveris olevate VM-ide loendurite summa.
CPU seisundi vaatamine serveris on kõige mugavam vahekaardil Summary:

Serveril, nagu ka virtuaalmasinal, on standardne Alarm:
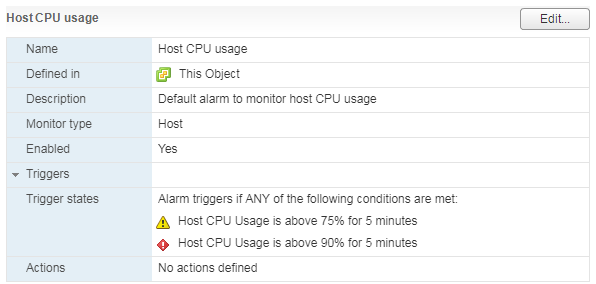
Kui serveri CPU on tugevalt koormatud, algavad probleemid jõudlusega VM-idega, mis sellel töötavad.
ESXTOP-is esitatakse serveri CPU koormuse andmed ekraani ülaservas. Peale tavalise CPU koormuse, mis on hüperviisorite jaoks vähe informatiivne, on veel kolm näitajat:
CORE UTIL(%) – füüsilise serveri tuuma koormus. See mõõdik näitab, kui kaua tuum mõõtmisperioodi jooksul tööd tegi.
PCPU UTIL(%) – kui hyper-threading on sisse lülitatud, siis iga füüsilise tuuma kohta on kaks võrguühendust (PCPU). See näitaja näitab, kui kaua iga voog tööd tegi.
PCPU USED(%) – sama mis PCPU UTIL(%), kuid arvestab sageduse reguleerimist (kas tuuma sageduse langetamine energiasäästu eesmärgil või tuuma sageduse tõstmine Turbo Boost tehnoloogia abil) ja hyper-threadingut.
PCPU_USED% = PCPU_UTIL% * tõhus sagedus / nimisagedus.
Sellel ekraanipildil on mõnede tuumade puhul Turbo Boost'iga töötamise tõttu väärtus USED üle 100%, kuna tuuma sagedus on kõrgem kui nimisagedus.
Mõned sõnad, kuidas arvesse võetakse hyper-threading'u. Kui protsessid töötavad 100% aega serveri füüsilise tuuma mõlemal lõngal ja tuum töötab nominaalvõimete sagedusel, siis:
- CORE UTIL tuuma jaoks on 100%,
- PCPU UTIL mõlemale lõngale on 100%,
- PCPU USED mõlemale lõngale on 50%.
Kui mõlemad lõngad ei töötanud 100% perioodi jooksul, siis nendel perioodidel, mil lõngad töötasid paralleelselt, jagatakse PCPU USED tuumade jaoks pooleks.
ESXTOP-is on ka ekraan, mis kuvab serveri CPU energiatarbimise parameetreid. Siit saate vaadata, kas server kasutab energiasäästutehnoloogiaid: C-states ja P-states. Avatakse klahviga „p“:

Standardprobleemid CPU jõudluses
Viimaks käsitlen tüüpilisi põhjuseid, miks VM-i CPU jõudlusprobleeme tekib, ja annan lühikesed nõuanded nende lahendamiseks:
Puudub tuuma taktsagedus. Kui ei ole võimalik VM-i viia tõhusamatele tuumadele, siis võib proovida muuta energiasäästurežiime, et Turbo Boost töötaks efektiivsemalt.
Vale VM-i suurus (liialt palju/vähe tuumi). Kui tuumi on liiga vähe, siis on VM-i CPU koormus kõrge. Kui liiga palju, kuuletub kõrge co-stop.
Suured CPU ülekohustused serveris. Kui VM-i valmisolek on kõrge, alandage CPU ülekohustust.
Vale NUMA-topoloogia suurtes VM-ides. VM-i (vNUMA) nähtav NUMA-topoloogia peab vastama serveri (pNUMA) NUMA-topoloogiale. Probleemi diagnoosi ja võimalike lahenduste kohta on kirjutatud näiteks raamatus . Kui te ei soovi süvitsi minna ja teil ei ole operatsioonisüsteemiga, mis on installitud VM-ile, litsentsipiiranguid, looge VM-is palju virtuaalseid sokette igaühe tuumaga. Palju ei kaota 🙂
Sellega CPU teemadest mul kõik. Esitage küsimusi. Järgmises osas räägin operatiivmälu kohta.
Kasulikud lingid
Allikas: habr.com
