


Tere kõigile. Olen OÜ peamine süsteemihaldur ja vastutan portaali stabiilse töö eest. Soovin rääkida, kuidas me oleme üles ehitanud automaatse ketaste vahetamise protsessi ning sellest, kuidas me selle protsessist administraatori välja tõime ja asendasime ta botiga.
See artikkel on omamoodi transliteratsioon HighLoad+ 2018-l
Ketaste vahetamise protsessi rajamine
Esmalt mõned numbrid
OÜ on hiigelsuur teenus, mida kasutavad miljonid inimesed. Seda teenindavad umbes 7000 serverit, mis asuvad 4 erinevas andmekeskuses. Serverites on üle 70 000 ketta. Kui need üksteise peale laduda, saame torni, mis on kõrgem kui 1 km.
Kõvakettad on serveri komponent, mis tõuseb kõige sagedamini välja. Selliste mahtude korral peame nädalas vahetama umbes 30 ketast ja see protseduur on muutunud ebameeldivaks rutiiniks.

Juhtumid
Meie ettevõttes on rakendatud täielik sündmuste haldamine. Iga sündmus salvestatakse Jira, seejärel lahendatakse ja analüüsitakse. Kui sündmus on mõjutanud kasutajaid, koguneme kindlasti ja arutame, kuidas sellistes olukordades kiiremini reageerida, kuidas vähendada mõju ja loomulikult, kuidas ennetada kordumist.
Kettad ei ole erand. Nende seisundit jälgib Zabbix. Jälgime Syslogi sõnumeid kirjutamis-/lugemisvihjete osas, analüüsime HW/SW raidide seisundit, jälgime SMART-i ning SSD-de puhul arvutame kulumist.
Kuidas on kettad varem muutunud
Kui Zabbixis süttib mõni käivitaja, luuakse Jira-s sündmus ja see määratakse automaatselt vastavatele inseneridele andmekeskustes. Teeme seda kõigi HW-sündmustega, st sellistega, mis nõuavad mingit füüsilist tööd seadmetega andmekeskuses.
Andme keskuse insener on inimene, kes lahendab riistvara probleeme, vastutab serverite paigaldamise, hooldamise ja demonteerimise eest. Pärast probleemi registreerimist alustab insener tööd. Ta vahetab ise kettaid ketaste riiulites. Kui tal ei ole juurdepääsu vajalikele seadmetele, pöördub insener valve süsteemiadministraatorite poole abi saamiseks. Esiteks tuleb ketas rotatsioonist välja võtta. Selleks tuleb serveris vajalikud muudatused teha, rakendused peatada ja kettast lahti monteerida.
Valve süsteemiadministraator vastutab oma töövahetuse jooksul kogu portaali toimimise eest. Ta uurib juhtumeid, tegeleb remontidega ning aitab arendajatel väiksemaid ülesandeid täita. Ta ei tegele aga kõvaketastega.
Varem suhtlesid andmekeskuse insenerid süsteemiadministraatoriga vestluses. Insenerid saatsid lingid Jira pileti juurde, administraator käis need läbi ja pidas logi mingis märkmikus. Kuid selliste ülesannete jaoks on vestlused ebamugavad: teave on seal struktureerimata ja kaob kiiresti. Ja administraator võis lihtsalt arvuti juurest eemale minna ning mõnda aega küsimustele ei vastata, samas kui insener seisis serveri juures diskide virnaga ja ootas.
Kuid kõige halvem oli see, et administraatorid ei näinud kogu pilti: milliseid kettaintsidente esineb, kus võib potentsiaalselt probleem tekkida. See on seotud sellega, et kõik HW-intsidendid suuname inseneridele. Jah, oleks saanud kuvada kõik intsidendid administraatori juhtpaneelil. Kuid neid on nii palju, et administraator kaasatakse vaid mõnele neist.
Lisaks ei saanud insener õigesti prioriteete seada, kuna ta ei tea midagi konkreetsete serverite määramisest ega andmete jaotamisest mäluseadmetele.
Uus asendamisprotseduur
Esimene asi, mida me tegime, oli kõik kettaga seotud intsidentide väljavõttmine eraldi tüüpi „HW-ketas“ ning sellele lisati väljad „blokeeringu nimi“, „suurus“ ja „ketta tüüp“, et see teave salvestataks piletisse ja et seda ei peaks pidevalt vestluses vahetama.
Oleme samuti kokku leppinud, et ühe intsidenti raames vahetame ainult ühe ketta. See lihtsustas oluliselt edasist automatiseerimise, statistika kogumise ja tööprotsessi.
Lisaks lisasime välja „vastutav administraator“. Sellele kantakse automaatselt asendajana inimese nimi. See on väga mugav, sest nüüd näeb insener alati, kes on vastutav. Ei ole vaja minna kalendrisse ja otsida. Just see väli võimaldas administraatori armatuurlauda välja tuua pileteid, kus võib tekkida vajadus tema abi järele.
Kuna kõik osalised saaksid maksimaalset kasu uuendustest, oleme loonud filtrid ja armatuurlaud ning tutvustanud neid meeskonnale. Kui inimesed mõistavad muudatusi, ei hoia nad neist eemale nagu millestki tarbetust. Insenerile on oluline teada, milline on serveri rack'i number, ketta suurus ja tüüp. Administraatorile on oluline esmajoones mõista, milline on see serverite gruppe ja milline võib olla efekt ketta vahetamisel.
Väljade olemasolu ja nende kuvamine on mugav, kuid see ei vabasta meid vajadusest kasutada vestlusi. Selleks pidime muutma töövoogu.
Varem oli see selline:
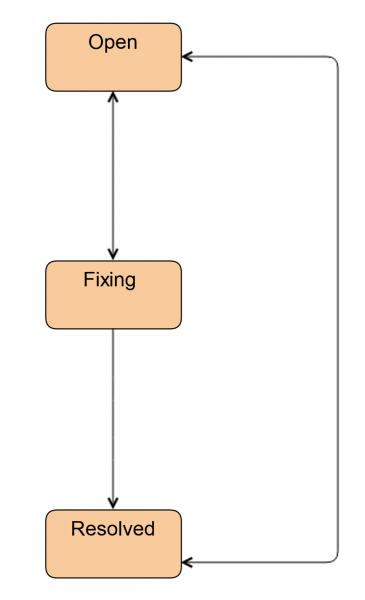
Täna töötavad insenerid nii, kui neile ei ole enam vaja administraatori abi.
Esimene asi, mida me tegime, oli uus staatuse sisseviimine Uuri. Sellel staatustas on pilet, kui insener pole veel otsustanud, kas tal on administraatori abi vajalik või mitte. Selle staatuse kaudu saab insener edastada piletit administraatorile. Lisaks kasutame seda staatust piletite märkimiseks, kui ketas vajab vahetamist, kuid kohapeal ei ole kassetti. See juhtub CDN ja eemal asuvate kohtade korral.
Samuti oleme lisanud staatuse Valmis. Pilet muudetakse pärast ketta vahetamist. See tähendab, et kõik on juba tehtud, kuid serveris sünkroniseeritakse HW/SW RAID. Sellel võib kuluda üsna palju aega.
Kui töö tegemiseks kaasatakse administraator, muutub skeem veidi keerulisemaks.
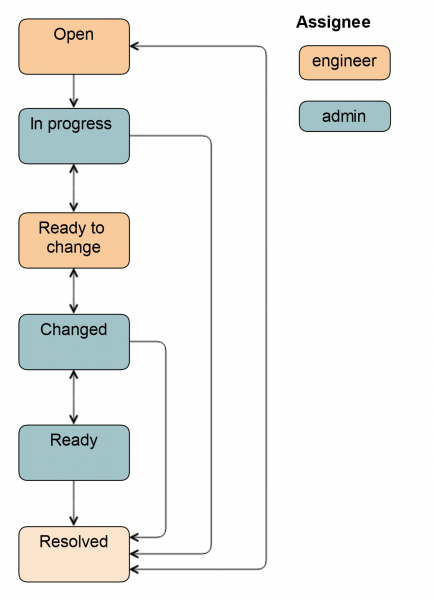
Olekust Open võib pileti muuta nii süsteemiadministraator kui ka insener. Olekus Töös administraator eemaldab ketta rotatsioonist, et insener saaks selle lihtsalt välja võtta: lülitab sisse LED-valgustuse, monteerib ketta lahti, peatab rakendused, sõltuvalt konkreetsetest serverigruppidest.
Seejärel muudetakse pilet olekusse Valmis vahetamiseks: see on märk insenerile, et ketas võib välja võtta. Kõik väljad Jira-s on juba täidetud, insener teab, milline tüüp ja suurus on kettal. Need andmed sisestatakse kas automaatselt eelmises olekus või administraatori poolt.
Pärast ketta vahetamist muudetakse pilet olekusse Vahetatud. Kontrollitakse, et õige ketas on paigaldatud, tehakse jaotus, käivitatakse rakendus ja mõned andmete taastamise ülesanded. Samuti võib pilet muutuda olekusse Valmis, sel juhul jääb vastutavaks administraator, kuna tema viis ketta rotatsiooni. Täielik skeem näeb välja järgmine.
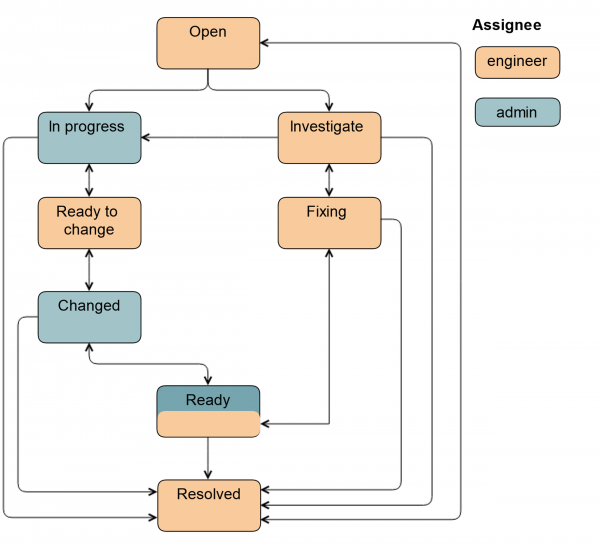
Uute väljade lisamine on meie elu oluliselt lihtsustanud. Meeskond on hakanud töötama struktureeritud teabega, mistõttu on selge, milliseid samme tuleb teha ja millal. Prioriteedid on nüüd palju asjakohasemad, kuna need määrab administraator.
Kohandatud suhtluskanalite vajadus on kadunud. Loomulikult võib administraator kirjutada insenerile, et "siin tuleb kiiremini vahetada" või "õhtu on käes, kas jõuad vahetada?" Kuid me ei suhtle enam igapäevaselt nende küsimuste osas.
Kettad vahetatakse nüüd partiidena. Kui administraator tuleb tööle veidi varem, on tal vaba aega ja midagi pole veel juhtunud, võib ta valmistada ette rida servereid vahetamiseks: määrata väljad, võtta kettad rotatsioonist välja ja edastada ülesanne insenerile. Insener tuleb hiljem andmekeskusesse, näeb ülesannet, võtab ladudest vajalikud salvestusseadmed ja vahetab need välkkiirusel. Tulemuseks on vahetuse kiirus suurenenud.
Teadmised, mis on saadud Workflow'i loomisel
- Protseduuri koostamisel tuleb koguda teavet erinevatest allikatest.
Mõned meie administraatorid ei teadnud, et insener vahetab kettaid iseseisvalt. Mõned arvasid, et MD RAID'i sünkroniseerimise eest hoolitsevad insenerid, kuigi mõnedel isegi ei olnud sellele ligipääsu. Mõned juhtivinsenerid tegid seda, kuid mitte alati, sest protsess ei olnud kuskil kirjas. - Protseduur peaks olema lihtne ja arusaadav.
Inimesel on raske meeles pidada mitmeid samme. Kõige olulisemad kõrvalolevad staatused jiras tuleb tuua põhiekraanile. Me võime neid ümber nimetada, näiteks In progress me nimetame Ready to change. Teised staatused võiks peita rippmenüüsse, et nad ei vaevaks silma. Kuid parem on mitte piirata inimesi, vaid anda võimalus teha üleminek.
Selgitage välja uute algatuste väärtus. Kui inimesed mõistavad, aktsepteerivad nad uue protseduuri paremini. Meie jaoks oli väga oluline, et inimesed ei klõpsaks kogu protsessi läbides, vaid järgiksid seda. Hiljem ehitasime selle põhjal automatiseerimise. - Oota, analüüsi, uurige.
Me võttis umbes kuu, et välja töötada protseduur, tehnilised lahendused, kohtumised ja arutelud. Rakendamiseks kulus aga rohkem kui kolm kuud. Olen näinud, kuidas inimesed järk-järgult hakkavad uut lahendust kasutama. Esimestel etappidel oli palju negatiivsust. Kuid see ei tulenenud protseduurist endast ega selle tehnilisest teostusest. Näiteks üks administraator kasutas mitte Jira't, vaid Jira-pluginat Confluence'is, ja mõned asjad ei olnud talle kergesti kättesaadavad. Näitasime talle Jira't ning administraatori tootlikkus kasvas nii üldiste ülesannete kui ka ketaste vahetuste osas.
Automatiseerimine ketaste vahetamiseks
Oleme ketaste vahetamise automatiseerimisega mitmeid kordi lähenenud. Meil olid juba olemasolevad lahendused, skriptid, kuid need töötasid kas interaktiivses või käsi-režiimis ning vajasid käivitamist. Ja alles pärast uue protseduuri rakendamist mõistsime, et see on see, mida me tegelikult vajasime.
Kuna nüüd on asendamisprotsess jagatud etappideks, mille igaühe puhul on määratud vastutav isik ja tegevuste loend, saame automatiseerimist järk-järgult lisada, mitte kohe kogu ulatuses. Näiteks kõige lihtsam etapp — Ready (RAID/andmete sünkroonimise kontroll) — saab kergesti delegeerida robotile. Kui robot veidi õpib, saame talle anda vastutustundlikuma ülesande — ketta rotatsiooni sisseviimise jne.
Seadistuste loomine
Enne kui räägime robotist, teeme väikese ekskursiooni meie seadistuste loomise maailmas. Esiteks tuleneb see meie infrastruktuuri hiiglaslikust mahust. Teiseks püüame iga teenuse jaoks leida optimaalse riistvara konfiguratsiooni. Meil on umbes 20 erinevat mudelit riistvara RAID, enamasti LSI ja Adaptec, kuid esinevad ka HP ja DELL erinevad versioonid. Igal RAID-kontrolleril on oma haldustööriist. Käskude komplekt ja nende väljund võib iga RAID-kontrolleri puhul versioonist sõltuvalt erineda. Seal, kus HW-RAID-i ei kasutata, võib olla mdraid.
Peaaegu kõik uued installatsioonid teeme ilma kettade varundamiseta. Püüame enam mitte kasutada riistvaralist ja tarkvaralist RAIDi, kuna varundame meie süsteeme andmekeskuse tasemel, mitte serverite tasemel. Kuid loomulikult on palju vanemaid servereid, mida tuleb toetada.
Kusagil on kettad RAID-kontrollerites ühendatud raw-seadmetena, kusagil kasutatakse JBODi. On konfiguratsioone, kus serveris on ainult üks süsteemiketas, ja kui see tuleb asendada, tuleb server uuesti üles seada, installides operatsioonisüsteemi ja rakendused, sealhulgas samade versioonide kaudu, seejärel lisama konfiguratsioonifailid ja käivitama rakendused. Samuti on palju serverigruppide, kus varundamine toimub mitte kettasüsteemi tasemel, vaid otse rakendustes endis.
Kokku on meil üle 400 ainulaadse serverigruppi, kus töötab umbes 100 erinevat rakendust. Sellise tohutu hulga variantide katmiseks vajasime mitmekesist automatiseerimistööriista. Soovitavalt lihtsa DSL-iga, et seda saaks toetada mitte ainult see, kes selle kirjutas.
Valisime Ansible'i, kuna see on agentvaba: ei olnud vaja infrastruktuuri ette valmistada ja see võimaldas kiiret algust. Lisaks on see kirjutatud Pythonis, mis on meeskonnas standardiks.
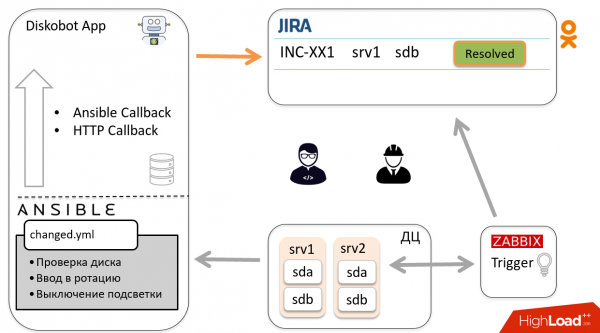
Üldine skeem
Vaatame üldist automatiseerimise skeemi ühe intsidendi näitel. Zabbix tuvastab, et disk sdb on rikki läinud, süttib käivitus ja luuakse pilet Jira-s. Administraator vaatab selle üle, mõistab, et see ei ole duplikaat ega vale positiivne ning otsustab, et disk tuleb vahetada, ja viib pileti olekusse In progress.
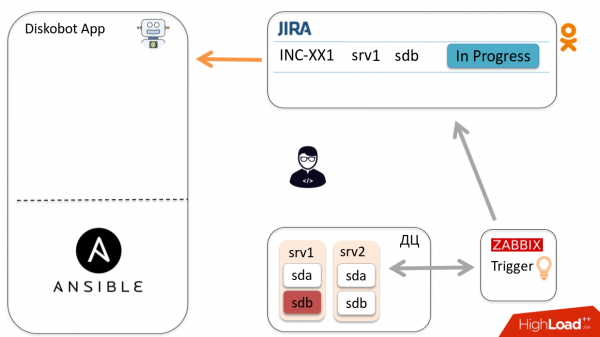
Rakendus DiskoBot, mis on kirjutatud Pythonis, küsib perioodiliselt Jira-st uusi pileteid. See tuvastab, et on ilmunud uus pilet olekuga In progress, aktiveerub vastav thread, mis käivitab playbook'i Ansible'is (see toimub iga Jira oleku jaoks). Antud juhul käivitub Prepare2change.
Ansible saadetakse hostile, eemaldab disk rotatsioonist ja teatab oleku rakendusele läbi Callbacks.
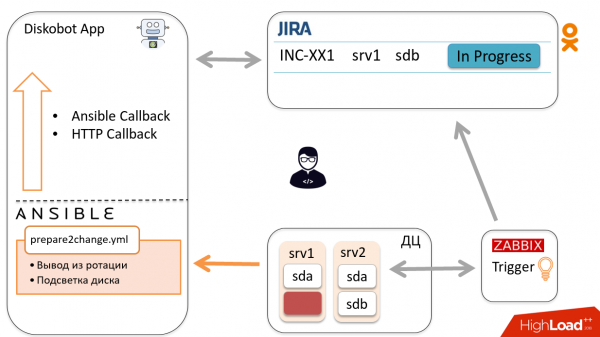
Tulemuste põhjal viib bot automaatselt pileti olekusse Ready to change. Insener saab teate ja läheb diski vahetama, pärast mida viib pileti olekusse Changed.
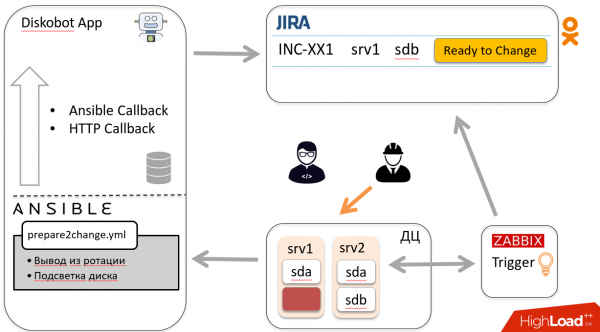
Ülaltoodud skeemi kohaselt jõuab pilet tagasi botile, kes käivitab teise playbook'i, läheb hosti ja lisab ketta rotatsiooni. Bot sulgeb pileti. Hurra!
Nüüd räägime süsteemi mõnest komponendist.
Diskobot
See rakendus on kirjutatud Pythonis. See valib tikette Jira's vastavalt JQL-ile. Pileti staatuse põhjal jõuab see vastava töötleja juurde, kes omakorda käivitab vastavalt olekule Ansible playbook'i.
JQL ja küsitluse intervallid on määratud rakenduse konfiguratsioonifailis.
jira_states:
investigate:
jql: '… staatuse = Avatud ja "Ketta suurus" on TÜHI'
interval: 180
inprogress:
jql: '… ja "Ketta suurus" ei ole TÜHI ning "Seadmere nimi" ei ole TÜHI'
ready:
jql: '… ja (sildid ei ole ("dbot_ignore") või sildid on TÜHI)'
interval: 7200
Näiteks valitakse In progress olekus olevate tikettide hulgast välja ainult need, millel on täidetud väljad Ketta suurus ja Seadmere nimi. Seadmere nimi on plokkseadmest saadud nimi, mis on vajalik playbook'i täitmiseks. Ketta suurus on vajalik, et insener teaks, kui suurel kettal on vajadus.
Ja Ready olekus olevate tikettide hulgast filtreeritakse välja tikettide, millel on sildid dbot_ignore. Üldiselt kasutame Jira silte nii sarnaste filtreerimiste kui ka piletite dubleerimise märgistamiseks ning statistika kogumiseks.
Jira määrab playbook’i tõrke korral sildiks dbot_failed, et hiljem olukorda lahendada.
Koostöö Ansible'iga
Rakendus suhtleb Ansible'iga läbi . playbook_executor'is edastame faili nime ja muutujate kogumi. See võimaldab hoida Ansible projekti tavaliste yml-failidena, mitte kirjeldada seda Python koodis.
Lisaks edastatakse Ansible’ile *extra_vars* kaudu plokkseadmise nimi, piletiseis ja callback_url, kus on peidetud issue key — seda kasutatakse HTTP callback’is.
Iga käivituse jaoks genereeritakse ajutine inventuur, mis koosneb ühest hostist ja grupist, kuhu see host kuulub, et rakendada group_vars.
Siin on näide ülesandest, kus on rakendatud HTTP callback.
Saame playbook’ide käitamise tulemusi callback(-ide) kaudu. Need on kahte tüüpi:
- , see esitab andmed playbook’i käitamise tulemuste kohta. Seal on kirjeldatud ülesandeid, mis on käivitatud, edukalt või ebaõnnestunult täidetud. See callback kutsutakse välja playbook’i esitamise lõppedes.
- HTTP callback, et saada teavet playbook’i esitamise ajal. Ansible ülesandes teeme POST/GET päringu meie rakenduse suunas.
HTTP callback(-ite) kaudu edastatakse muutujad, mis on määratud playbook'i täitmise ajal ja mida soovime salvestada ning kasutada järgnevates käivitustes. Need andmed salvestame sqlite'sse.
Samuti jätame HTTP callback'i kaudu kommentaare ja muudame pileti staatust.
HTTP callback
# Make callback to Diskobot App
# Variables:
# callback_post_body: # A dict with follow keys. All keys are optional
# msg: If exist it would be posted to Jira as comment
# data: If exist it would be saved in Incident.variables
# desire_state: Set desire_state for incident
# status: If exist Proceed issue to that status
- name: Callback to Diskobot app (jira comment/status)
uri:
url: "{{ callback_url }}/{{ devname }}"
user: "{{ diskobot_user }}"
password: "{{ diskobot_pass }}"
force_basic_auth: True
method: POST
body: "{{ callback_post_body | to_json }}"
body_format: json
delegate_to: 127.0.0.1
Nagu paljusid sarnaseid ülesandeid, oleme selle välja viinud eraldi yhte failina ja lisame vajadusel, et mitte pidevalt playbook'idest korrata. Siin figureerib callback_url, kuhu on embeditud issue key ja host name. Kui Ansible täidab selle POST-päringu, mõistab bot, et see tuli teatud sündmuse raames.
Siin on näide playbook'ist, kus väljastasime ketta MD-seadmest:
# Save mdadm configuration
- include: common/callback.yml
vars:
callback_post_body:
status: 'Ready to change'
msg: "Removed disk from mdraid {{ mdadm_remove_disk.msg | comment_jira }}"
data:
mdadm_data: "{{ mdadm_remove_disk.removed }}"
parted_info: "{{ parted_info | default() }}"
when:
- mdadm_remove_disk | changed
- mdadm_remove_disk.removed
See ülesanne viib Jira pileti staatuse „Ready to change“ ja lisab kommentaari. Samuti salvestatakse muutuja mdam_data md-seadmete nimekiri, kust ketas eemaldati, ning parted_info sisaldab partitsiooni dumpi parted'ilt.
Kui insener paigaldab uue ketta, saame neid muutujaid kasutada partitsioonide dumpi taastamiseks, samuti lisada ketta neisse md-seadmetesse, kust see eemaldati.
Ansible kontrollrežiim
Automaadi käivitamine oli hirmutav. Seetõttu otsustasime käivitada kõik playbook'id režiimis
, milles Ansible ei teosta serveritel mingeid toiminguid, vaid ainult simuleerib neid.
Selline käivitamine käib läbi eraldi callback-mooduli ning playbook'i käitamise tulemus salvestatakse Jira's kommentaarina.
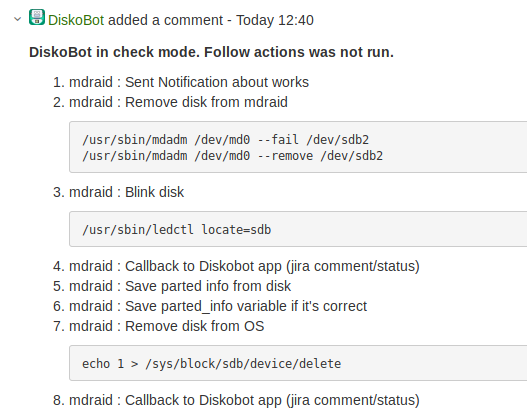
Esiteks, see võimaldas kontrollida boti ja playbook'ide tööd. Teiseks, see tõstis administraatorite usaldust boti vastu.
Kui olime valideerimise läbinud ja mõistsime, et Ansible’i saab käivitada mitte ainult dry run režiimis, siis lisasime Jira'sse nupu Run Diskobot, et käivitada sama playbook'i samade muutujaid samas hostis, kuid tavarežiimis.
Lisaks kasutatakse nuppu playbook'i uuesti käivitamiseks, kui see ebaõnnestub.
Playbook'ide struktuur
Olen juba maininud, et sõltuvalt Jira-piletist käivitab bot erinevaid playbook'e.
Esiteks, nii on palju lihtsam sisendit korraldada.
Teiseks, mõnel juhul on see lihtsalt vajalik.
Näiteks, kui vahetame süsteemis ketast, tuleb kõigepealt minna deploy-süsteemi, luua ülesanne ja pärast õiget deployd muutub server juurdepääsetavaks ssh kaudu, ning sinna saab installida rakenduse. Kui me teeksime kõike seda ühes playbook’is, ei suudaks Ansible seda täita, kuna host ei oleks juurdepääsetav.
Kasutame Ansible rolle igas serverigrupis. Siin on näha, kuidas on playbook’id üles ehitatud ühes neist.
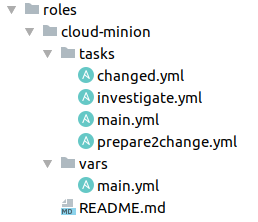
See on mugav, kuna on kohe selge, kus asuvad erinevad ülesanded. Failis main.yml, mis on Ansible rolli sissepääs, võib meil olla lihtsalt include vastavalt pileti staatusele või üldised ülesanded, mis on vajalikud kõigile, näiteks identifitseerimise läbimine või tokeni saamine.
Investigation.yml
Käivitatakse piletite jaoks, mille staatus on Investigation ja Open. Selle playbook’i jaoks on kõige olulisem plokiseadmise nimi. See teave ei pruugi alati olla saadaval.
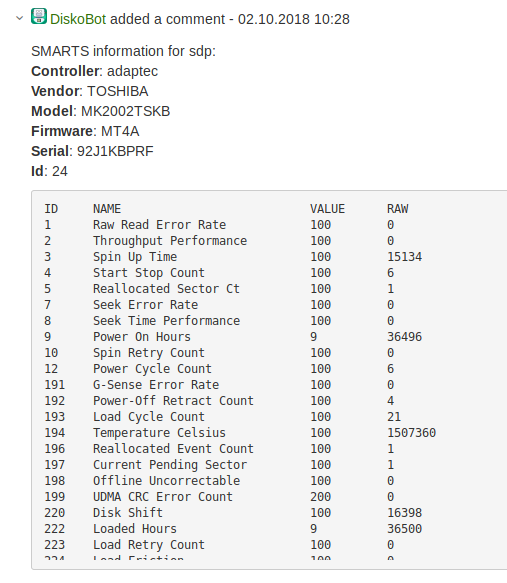
Selle saamiseks analüüsime Jira kokkuvõtet ja Zabbixi käivitaja viimast väärtust. Seal võib olla plokiseadmestiku nimi — vedamine. Võib aga ka olla mount point, — siis tuleb minna serverisse, seda analüüsida ja vajalikket kettamahtusid arvutada. Samuti võib käivitaja edastada SCSI-aadressi või mõnda muud teavet. Kuid juhtub ka nii, et mingeid vihjeid pole, ja tuleb analüüsida.
Selgitanud plokiseadmestiku nime, kogume selle kohta teavet ketta tüübi ja suuruse kohta, et täita väljad Jira-s. Kogume ka teavet tootja, mudeli, tarkvara, ID, SMART kohta ja kõik need andmed lisame Jira piletile kommentaarina. Nüüd ei pea administraator ja insener neid andmeid enam otsima. 🙂
prepare2change.yml
Ketta eemaldamine rotatsioonist, valmistumine asendamiseks. Kõige keerulisem ja vastutusrikkam etapp. Just siin saab rakenduse peatada, kui seda ei tohiks peatada. Või eemaldada ketas, mille replikad puuduvad, ja seeläbi mõjutada kasutajaid, kaotades mõningaid andmeid. Siin on meil kõige rohkem kontrollimisi ja teavitusi vestluses.
Kõige lihtsamal juhul räägime ketta eemaldamisest HW/MD RAID-ist.
Kuidas keerulisemates olukordades (meie salvestussüsteemides), kui varundamine toimub rakenduse tasemel, tuleb rakendust kasutada API kaudu, et disk välja lülitada, deaktiveerida see ja alustada taastamist.
Me liigume nüüd massiliselt , ja kui server on pilves, siis Diskobot pöördub pilve API poole, teatab, et ta kavandab töötada selle minioniga — serveriga, kus konteinerid on tööle pandud — ja palub, et "migreerige kõik konteinerid sellest minionist". Ja lisaks lülitab ta sisse ketta esiletõstmise, et insener saaks kohe aru, milline tuleb välja võtta.
changed.yml
Pärast ketta vahetamist kontrollime kõigepealt selle kättesaadavust.
Insenerid ei paigalda alati uusi kettaid, seetõttu lisasime SMART-i nõuete kontrollimise.
Milliseid atribuute me vaatameReallocated Sectors Count (5) < 100
Current Pending Sector Count (107) == 0
Kui ketas ei vasta kontrollile, teavitatakse inseneri uuest vahetusest. Kui kõik on korras, lülitatakse esiletõstmine välja, märgistatakse ja ketas viiakse rotatsiooni.
ready.yml
Lihtsaim juhtum: HW/SW raid sünkroonimise kontroll või andmete sünkroniseerimise lõpetamine rakenduses.
Rakenduste API
Olen korduvalt maininud, et bot kutsub sageli rakenduste API-d. Loomulikult ei olnud kõikidel rakendustel vajalikud meetodid, mistõttu tuli neid täiustada. Siin on kõige olulisemad meetodid, mida me kasutame:
- Staatus. Klastri või ketta staatus, et mõista, kas sellega on võimalik töötada;
- Käivita/peata. Ketaste aktiveerimine-deaktiveerimine;
- Migreeri/taasta. Andmete migreerimine ja taastamine ketta vahetamise ajal ja pärast seda.
Kogemuste jagamine Ansible'ist
Mulle väga meeldib Ansible. Kuid sageli, kui vaatan erinevaid avatud lähtekoodiga projekte ja näen, kuidas inimesed kirjutavad playbook'e, tunnen ma end natuke ärevalt. Komplitseeritud loogilised seosed when/loop, paindlikkuse ja idempotentsuse puudumine tiheda shell/komandi kasutamise tõttu.
Oleme otsustanud kõik võimalikult lihtsaks teha, kasutades Ansible'i modulaarset lähenemist. Kõige kõrgemal tasemel on playbook'id, mida võib kirjutada iga administraator või sõltumatu arendaja, kes natuke tunneb Ansible'it.
- name: Blink disk
become: True
register: locate_action
disk_locate:
locate: '{{ locate }}'
devname: '{{ devname }}'
ids: '{{ locate_ids | default(pd_id) | default(omit) }}'
Kui mõni loogika on playbook'idel keeruliselt elluviidav, viime selle Ansible moodulisse või filtrisse. Skripte võib kirjutada nii Pythonis kui ka mõnes muus keeles.
Need on lihtsad ja kiired kirjutada. Näiteks diskihighlighting moodul, mille näidet kasutame üleval, koosneb 265 realt.

Alumisel tasemel on raamatukogu. Selle projekti jaoks kirjutasime eraldi rakenduse, omamoodi abstraktsiooni riistvara ja tarkvara RAID'ide üle, mis teevad vastavad päringud.
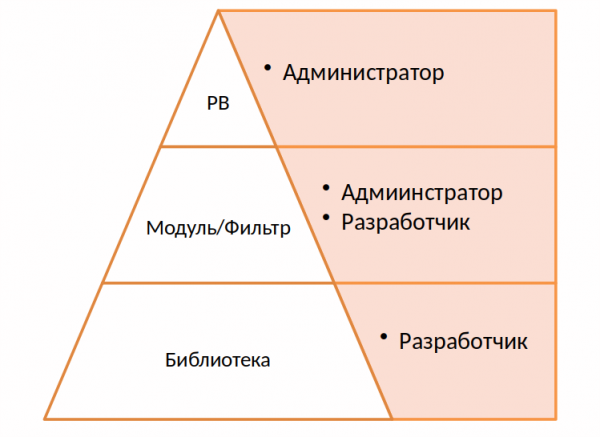
Ansible'i kõige tugevamad küljed on lihtsus ja arusaadavad playbook'id. Usun, et sellest tuleb kasu lõigata ja mitte genereerida kohutavaid yaml-faile ning tohutut hulka tingimusi, shell-koodi ja silmusid.
Kui soovite meie Ansible API kogemust korrata, pange tähele kaht asja:
- Playbook_executor ja üldiselt playbook'i ei saa anda timeout'i. SSH-seansil on timeout, kuid playbook'il ei ole timeout'i. Kui proovime lahti monteerida kettast, mis süsteemis enam ei eksisteeri, siis playbook käivitub lõpmatult, seega tuli selle käivitamine panna eraldi wrapper'i ja tappa see timeout'i järgi.
- Ansible töötab fork-protsesside alusel, seega ei ole selle API reentrant. Käivitame kõik meie playbook'id ühes harutorus.
Lõpuks õnnestus meil automatiseerida umbes 80 % ketaste asendamisest. Üldiselt on asendamise kiirus kahekordistunud. Täna vaatab administraator lihtsalt intsidendi üle ja otsustab, kas ketas tuleb välja vahetada või mitte, seejärel teeb ühe klõpsu.
Aga nüüd hakkame kokku puutuma teise probleemiga: mõned uued administraatorid ei tea, kuidas kettaid vahetada. 🙂
Allikas: habr.com
