

Kuidas saab äritegevuse nõuded konkreetseteks andmestruktuurdeks tõlkida, kasutades näiteks "nullist" saadud andmebaasi projekteerimist sõnumivahetuseks.
- Osa 1: projekteerime andmebaasi karkassi

Meie andmebaas ei saa olema nii ulatuslik ja jaotatud, või , vaid pigem "et oleks", aga siiski hästi — funktsionaalne, kiire ja mahtuks ühele serverile. PostgreSQL — et saaksime käivitada eraldi teenuse eksemplari kuskil kõrval, näiteks.
Seega ei käsitle me shardimise, replikatsiooni ja geograafiliste süsteemide küsimusi, vaid keskendume skeemilistele lahendustele andmebaasi sees.
Samm 1: Veidi ärispetsiifikat.
Meie sõnumivahetust projekteerime mitte abstraktselt, vaid integreerime ettevõtte sotsiaalvõrku. . Millised äriülesanded on? Vaatame näiteks Vassili näitel — arendusosakonna juhti.
"Nikolai, selle ülesande jaoks on täna juba vajalik patch!"
- See tähendab, et suhtlemine võib toimuma näiteks mingis kontekstis
"Kola, lähme täna õhtul Dota mängima?" dokument. - See tähendab, et isegi ühe paarikese vestluses võib suhtlemine samal ajal toimuda.
То есть даже у одной пары собеседников общение одновременно может вестись erinevate teemadega. - „Petr, Nikolai, vaadake manuses uusi serveri hindu.“
Ühel sõnumil võib olla mitu saajat. Samuti võib sõnum sisaldada manustatud faile. - „Semen, ka sina vaata seda.“
Ja peab olema võimalus juba olemasolevasse vestlusse kaasa kutsuda uus osaleja.
Peatume praegu sellel nimekirjal „ilmselgetest“ vajadustest.
Ilma rakenduslikke eripärasid ülesande ja selle kehtestatud piirangute mõistmata on praktiliselt võimatu projekteerida tõhusat andmebaasi skeemi selle lahendamiseks.
2. samm: minimaalne loogiline skeem
Skeemiliselt tundub kõik väga sarnane e-kirjadevahetusele — traditsioonilisele ärivahendile. Jah, „algtude“ paljud äriülesanded näevad välja sarnased, seega on ka nende lahendamiseks vajalikud tööriistad struktuurselt sarnased.
Kinnitatame juba saadud loogilise suhete skeemi. Arusaamise lihtsustamiseks meie mudelisse kasutame kõige primitiivsemaid kuvamisviise ilma UML või IDEF-märkuste keerukusteta:
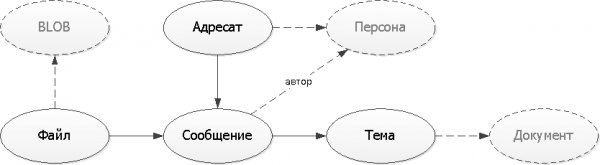
Meie näites on tegelane, dokument ja faili binaarne "keha" "välistest" üksustest, mis eksisteerivad iseseisvalt ilma meie teenuseta. Seetõttu tajume neid edaspidi kui mõningaid linke "kuidas iganes", kasutades UUID-d.
Joonistage skeeme nii lihtsalt kui võimalik — enamiku nende jaoks, kellele te neid näitate, ei ole UML/IDEF lugemise eksperdid. Kuid — kindlasti joonistage.
Samm 3: Joonistame tabelite struktuuri
Tabelite ja väljade nimedestK 'vene' tabeli ja väljade nimede suhtes võib suhtuda erinevalt, kuid see on maits küsimus. Kuna ei ole välismaalaste arendajaid, ja PostgreSQL võimaldab meil nime anda isegi hieroglüüfidega, kui need on jutumärkides, siis eelistame nimetada objekte üheselt mõistetavalt, et vältida tõlgenduste erinevusi.
Kuna sõnumeid kirjutab meil mitu inimest korraga, võivad mõned neist seda teha offline-režiimis, siis kõige lihtsam variant on kasutada UUID-d identifikaatoritena mitte ainult välistes üksustes, vaid ka kõigi objektide jaoks meie teenuses. Täiendavaks plussiks on see, et neid saab genereerida isegi kliendi poolel — see aitab meil sõnumite saatmist toetada lühiajalise andmebaasi kättesaamatuse korral, ja kokkupõrke tõenäosus on äärmiselt madal.
Meie andmebaasi tööversioon tabelite struktuur näeb välja järgmine:
Tabelid: RU
LOOJA TABEL "Teema"(
"Teema"
uuid
PEAMISED VÕTME
, "Dokument"
uuid
, "Pealkiri"
tekst
);
LOOJA TABEL "Sõnum"(
"Sõnum"
uuid
PEAMISED VÕTME
, "Teema"
uuid
, "Autor"
uuid
, "KuupäevAeg"
timestamp
, "Tekst"
tekst
);
LOOJA TABEL "Aadressaat"(
"Sõnum"
uuid
, "Isik"
uuid
, PEAMISED VÕTME("Sõnum", "Isik")
);
LOOJA TABEL "Fail"(
"Fail"
uuid
PEAMISED VÕTME
, "Sõnum"
uuid
, "BLOB"
uuid
, "Nimi"
tekst
);Tabelid : EN
LOOJA TABEL teema(
teema
uuid
PEAMISED VÕTME
, dokument
uuid
, pealkiri
tekst
);
LOOJA TABEL sõnum(
sõnum
uuid
PEAMISED VÕTME
, teema
uuid
, autor
uuid
, dt
timestamp
, keha
tekst
);
LOOJA TABEL sõnum_aadressaat(
sõnum
uuid
, isik
uuid
, PEAMISED VÕTME(sõnum, isik)
);
LOOJA TABEL sõnum_fail(
fail
uuid
PEAMISED VÕTME
, sõnum
uuid
, sisu
uuid
, failinimi
tekst
);Lihtsaim viis formaadi kirjeldamiseks on alustada suhete graafist tabelitest, mis ei viita mingile teisele.
Samm 4: Selgitame välja mitte ilmsed vajadused
Oleme projekteerinud andmebaasi, kuhu on suurepärane kirjutada ja kuidagi lugeda.
Pange end meie teenuse kasutaja olukorda — mida me sooviksime selle abil teha?
- Viimased sõnumid
See kronoloogiliselt järjestatud minu sõnumite register eri kriteeriumide järgi. Kus ma olen üks adressaatidest, kus ma olen autor, kus kirjutati mulle, aga ma ei vastanud, kus mulle ei vastatud, … - Vestluse osalejad
Kes on üldse selles pikale veninud vestluses osalised?
Meie struktuur võimaldab lahendada mõlemat ülesannet „üldiselt“, kuid kiiresti - ei. Probleem on selles, et esimese ülesande raames sortimise jaoks pole võimalik luua indeksi, mis sobib igale osalejale (ja tuleb välja võtta kõik salvestised), ning teise ülesande lahendamiseks on vajalik välja võtta kõik sõnumid teema kohta.
Ette nähtud kasutajaprobleemid võivad tõsiselt kahjustada tulemusi.
Samm 5: Mõistlik denormaalimine
Mõlemad meie probleemid aitavad lahendada täiendavad tabelid, kuhu me kavatseme duplitseerida osa andmeid, mis on vajalik nendele ülesannetele vastavate indeksite moodustamiseks.
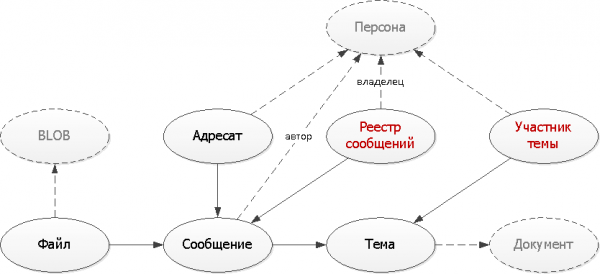
Tabelid: RU
Loo tabel "SõnumiteRegister"(
"Omanik"
uuid
, "RegistriTüüp"
smallint
, "KuupäevAeg"
timestamp
, "Sõnum"
uuid
, PRIMARY KEY("Omanik", "RegistriTüüp", "Sõnum")
);
Loo indeks "SõnumiteRegister"("Omanik", "RegistriTüüp", "KuupäevAeg" DESC);
Loo tabel "TeemaOsaleja"(
"Teema"
uuid
, "Isik"
uuid
, PRIMARY KEY("Teema", "Isik")
);Tabelid : EN
Loo tabel message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
Loo indeks message_registry(owner, registry, dt DESC);
Loo tabel theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);Siin rakendasime kahte tüüpilist lähenemist, mida kasutatakse abitaabelite loomisel:
- Kirjete paljundamine
Loome ühe algse sõnumi põhjal mitu järgmise kirje varianti eri registrites erinevatele omanikele — nii saatjale kui ka saajale. Nüüd sobitub iga register indeksisse, sest tüüpiliselt tahame näha ainult esimest lehte. - Kirjete unikaalsus
Iga sõnumi saatmise korral antud teemas piisab, et kontrollida, kas selline kirje juba eksisteerib. Kui ei, siis lisame selle meie "sõnaraamatusse".
Järgmises artikli osas räägime meie andmebaasi struktuuri.
Allikas: habr.com
