

Итак, вы собираете метрики. Как и мы. Мы тоже собираем метрики. Конечно же, нужные для бизнеса. Сегодня мы расскажем о самом первом звене системы нашего мониторинга — statsd-совместимом сервере агрегации , зачем мы его написали и почему отказались от brubeck.
Из предыдущих наших статей (, ) можно узнать, что до некоторого времени метки мы собирали при помощи . Он написан на C. С точки зрения кода — простой как пробка (это важно, когда вы хотите контрибьютить) и, самое главное, без особых проблем справляется с нашими объёмами в 2 млн. метрик в секунду (MPS) в пике. Документация заявляет поддержку 4 млн. MPS со звёздочкой. Это означает, что заявленную цифру вы получите, если правильно настроите сеть на Linux. (Сколько MPS можно получить, если оставить сеть как есть, нам неизвестно). Несмотря на эти преимущества, к brubeck у нас было несколько серьёзных претензий.
Претензия 1. Github — разработчик проекта — перестал его поддерживать: публиковать патчи и фиксы, принимать наши и (не только наши) PR. В последние несколько месяцев (где-то с февраля-марта 2018) активность возобновилась, но перед этим было почти 2 года полного затишья. Кроме того, проект разрабатывается , что может стать серьёзным препятствием для внедрения новых возможностей.
Претензия 2. Точность вычислений. Brubeck собирает для агрегации всего 65536 значений. В нашем случае для некоторых метрик в период агрегации (30 сек) может приходить гораздо больше значений (1 527 392 в пике). В результате такого семплирования, значения максимумов и минимумов выглядят бесполезными. Например, вот так:
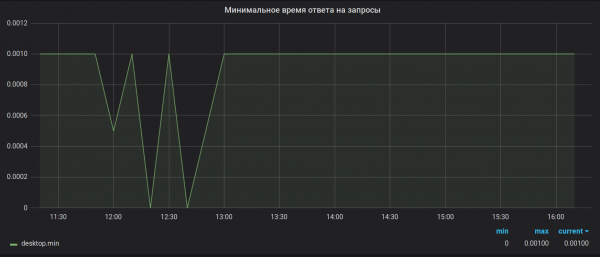
Kuidas oli
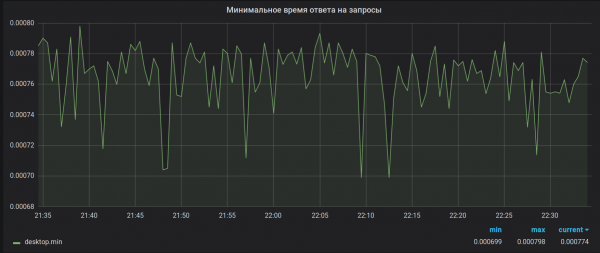
Как должно было быть
По той же причине суммы вообще считаются некорректно. Добавьте сюда баг с переполнением 32-битного float, которое вообще отправляет сервер в segfault при получении с виду невинной метрики, и становится вообще отлично. Баг, кстати, так и не исправлен.
Ja lõpuks, Претензия X. На момент написания статьи мы готовы предъявить её всем 14 более-менее работающим реализациям statsd, которые нам удалось найти. Давайте представим, что некоторая отдельно взятая инфраструктура выросла настолько, что принимать 4 млн MPS уже недостаточно. Или пусть ещё не выросла, но метрики для вас уже важны настолько, что даже короткие, 2-3 минутные провалы на графиках уже могут стать критичными и вызвать приступы непреодолимой депрессии у менеджеров. Так как лечение депрессии — дело неблагодарное, необходимы технические решения.
Во-первых, отказоустойчивость, чтобы внезапная проблема на сервере не устроила в офисе психиатрический зомби апокалипсис. Во-вторых, масштабирование, чтобы получить возможность принимать больше 4 млн MPS, при этом не копать вглубь сетевого стека Linux и спокойно расти «вширь» до нужных размеров.
Поскольку по масштабированию запас у нас был, мы решили начать с отказоустойчивости. «О! Отказоустойчивость! Это просто, это мы умеем», — подумали мы и запустили 2 сервера, подняв на каждом копию brubeck. Для этого нам пришлось копировать трафик с метриками на оба сервера и даже написать для этого . Проблему отказоустойчивости мы этим решили, но… не очень хорошо. Сначала всё было вроде бы здорово: каждый brubeck собирает свой вариант агрегации, пишет данные в Graphite раз в 30 секунд, перезаписывая старый интервал (это делается на стороне Graphite). Если вдруг один сервер откажет, у нас всегда есть второй с собственной копией агрегированных данных. Но вот проблема: если сервер отказывает, на графиках возникает «пила». Связано это с тем, что 30-секундные интервалы у brubeck не синхронизированы, и в момент падения один из них не перезаписывается. В момент запуска второго сервера происходит то же самое. Вполне терпимо, но хочется лучше! Проблема масштабируемости тоже никуда не делась. Все метрики по-прежнему «летят» на одиночный сервер, и поэтому мы ограничены теми же самыми 2-4 млн MPS в зависимости от прокачки сети.
Если немного подумать о проблеме и одновременно покопать лопатой снег, то в голову может прийти такая очевидная идея: нужен statsd, умеющий работать в распределённом режиме. То есть такой, в котором реализована синхронизация между нодами по времени и метрикам. «Конечно же, такое решение наверняка уже есть», — сказали мы и пошли гуглить…. И ничего не нашли. Прошерстив документацию по разным statsd ( на момент 11.12.2017), мы не нашли ровным счётом ничего. Видимо, ни разработчики, ни пользователи этих решений с ТАКИМ количеством метрик пока ещё не сталкивались, иначе они бы обязательно что-нибудь придумали.
И тут мы вспомнили про «игрушечный» statsd — bioyino, который писали на хакатоне just for fun (название проекта сгенерировал скрипт перед началом хакатона) и поняли, что нам срочно нужен собственный statsd. Зачем?
- потому что в мире слишком мало клонов statsd,
- потому что можно обеспечить желаемую или близкую к желаемой отказоустойчивость и масштабируемость (в том числе синхронизировать агрегированные метрики между серверами и решить проблему конфликтов при отправке),
- потому что можно считать метрики точнее, чем это делает brubeck,
- потому что можно самим собирать более детальную статистику, которую brubeck нам практически не предоставлял,
- потому что предоставился шанс запрограммировать свой собственный хайперформансдистрибьютедскейлаблапликейшен, который не будет полностью повторять архитектуру другого такого же хайперфор… нувыпонели.
На чём писать? Конечно же, на Rust. Почему?
- потому что уже был прототип решения,
- потому что автор статьи на тот момент уже знал Rust и рвался написать на нём что-нибудь для продакшена с возможностью выложить это в open-source,
- потому что языки с GC нам не подходят в силу природы получаемого трафика (практически realtime) и GC-паузы практически недопустимы,
- потому что нужна максимальная производительность, сравнимая с C
- потому что Rust предоставляет нам fearless concurrency, а начав писать это на C/C++, мы бы огребли ещё больше, чем у brubeck, уязвимостей, переполнений буфера, race conditions и других страшных слов.
Был и аргумент против Rust. У компании не было опыта создания проектов на Rust, и сейчас мы тоже не планируем использовать его в основном проекте. Поэтому были серьёзные опасения, что ничего не получится, но мы решили рискнуть и попробовали.
Шло время…
Наконец, после нескольких неудачных попыток, первая работающая версия была готова. Что получилось? Получилось вот такое.
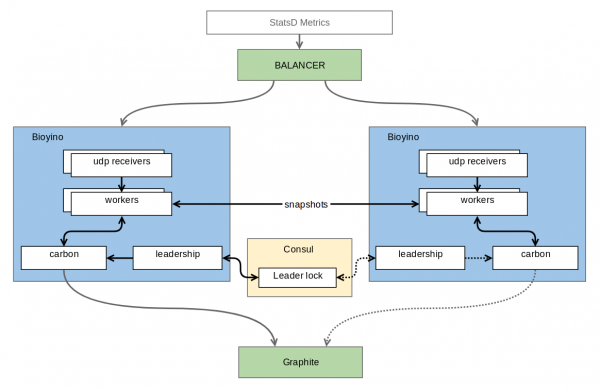
Каждая нода получает свой собственный набор метрик и накапливает их у себя, причём не агрегирует метрики для тех типов, где для финальной агрегации потребуется их полный набор. Ноды соединены между собой некоторым протоколом распределённой блокировки (distributed lock), который позволяет выбрать среди них ту единственную (здесь мы плакали), которая достойна отправлять метрики Великому. В данный момент эта проблема решается средствами , но в будущем амбиции автора простираются до Raft, где той самой достойной будет, конечно же, нода-лидер консенсуса. Кроме консенсуса, ноды достаточно часто (по умолчанию один раз в секунду) досылают своим соседям те части предагрегированных метрик, которые удалось за эту секунду набрать. Получается, что масштабирование и отказоустойчивость сохраняются — каждая из нод по-прежнему держит у себя полный набор метрик, но метрики при этом отправляются уже агрегированными, по TCP и с кодированием в бинарный протокол, поэтому расходы на дублирование по сравнению с UDP значительно снижаются. Несмотря на довольно большое количество входящих метрик, накопление требует совсем немного памяти и ещё меньше CPU. Для наших хорошо сжимаемых мертик это всего лишь несколько десятков мегабайт данных. Дополнительным бонусом получаем отсутствие лишних перезаписей данных в Graphite, как это было в случае с burbeck.
UDP-пакеты с метриками разбалансированы между нодами на сетевом оборудовании через простой Round Robin. Само собой, сетевая железяка не разбирает содержимое пакетов и поэтому может потянуть гораздо больше, чем 4M пакетов в секунду, не говоря уже о метриках, про которые она вообще ничего не знает. Если учесть, что метрики приходят не по одной в каждом пакете, то проблем с производительностью в этом месте мы не предвидим. В случае падения сервера сетевое устройство быстро (в течение 1-2 секунд) обнаруживает этот факт и убирает упавший сервер из ротации. В результате этого пассивные (т.е. не являющиеся лидером) ноды можно включать и выключать практически не замечая просадок на графиках. Максимум, что мы теряем — это часть метрик, пришедших за последнюю секунду. Внезапная потеря/выключение/переключение лидера по-прежнему нарисует незначительную аномалию (30-секундный интервал по-прежнему рассинхронизирован), но при наличии связи между нодами можно свести к минимуму и эти проблемы, например, путём рассылки синхронизирующих пакетов.
Немного о внутреннем устройстве. Приложение, конечно же, многопоточное, но архитектура потоков отличается от той, что использована в brubeck. Потоки в brubeck — одинаковые — каждый из них отвечает одновременно и за сбор информации, и за агрегацию. В bioyino рабочие потоки (workers) разделены на две группы: ответственные за сеть и ответственные за агрегацию. Такое разделение позволяет более гибко управлять приложением в зависимости от типа метрик: там где требуется интенсивная агрегация, можно прибавить агрегаторов, там где много сетевого трафика — прибавить количество сетевых потоков. В данный момент на наших серверах мы работаем в 8 сетевых и 4 агрегирующих потока.
Считающая (ответственная за агрегацию) часть достаточно скучная. Заполненные сетевыми потоками буферы распределяются между считающими потоками, где в дальнейшем парсятся и агрегируются. По запросу метрики отдаются для отправки на другие ноды. Всё это, включая пересылку данных между нодами и работу с Consul, выполняется асинхронно, работает на фреймворке .
Гораздо больше проблем при разработке вызвала сетевая часть, ответственная за приём метрик. Основной задачей выделения сетевых потоков в отдельные сущности было стремление уменьшить время, которое поток затрачивает ei на чтение данных из сокета. Варианты с использованием асинхронного UDP и обычного recvmsg быстро отпали: первый ест слишком много user-space CPU на обработку событий, второй — слишком много переключений контекста. Поэтому сейчас используется с большими буферами (а буфера, господа офицеры, это вам не абы что!). Поддержка обычного UDP оставлена для ненагруженных случаев, когда в recvmmsg нет необходимости. В режиме multimessage удаётся достичь главного: подавляющее большинство времени сетевой поток разгребает очередь ОС — вычитывает данные из сокета и перекладывает их в userspace-буфер, только изредка переключаясь на то, чтобы отдать заполненный буфер агрегаторам. Очередь в сокете практически не накапливается, количество отброшенных пакетов практически не растёт.
Märkus
В настройках по умолчанию размер буфера выставлен достаточно большим. Если вы вдруг решите опробовать сервер самостоятельно, то, возможно, столкнётесь с тем, что после отправки маленького количества метрик, они не прилетят в Graphite, оставшись в буфере сетевого потока. Для работы с небольшим количеством метрик нужно выставить в конфиге bufsize и task-queue-size значения поменьше.
Напоследок — немного графиков для любителей графиков.
Статистика количества входящих метрик по каждому серверу: более 2 млн MPS.
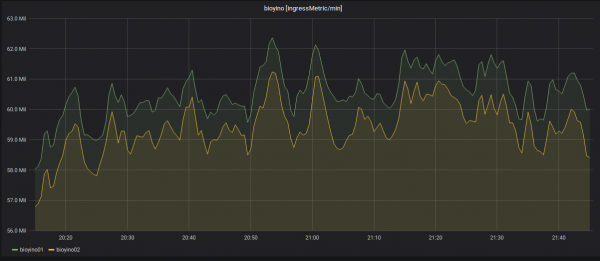
Отключение одной из нод и перераспределение входящих метрик.
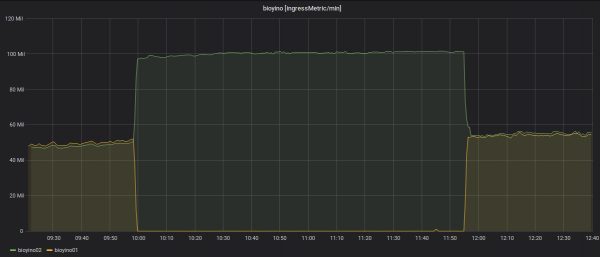
Статистика по исходящим метрикам: отправляет всегда только одна нода — рейдбосс.
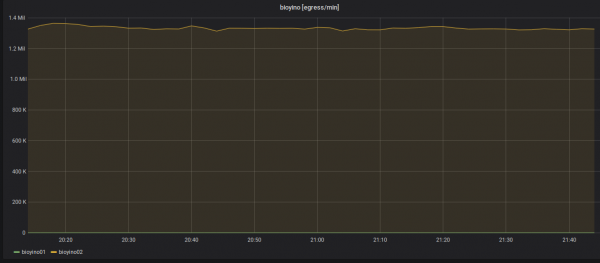
Статистика работы каждой ноды с учетом ошибок в различных модулях системы.
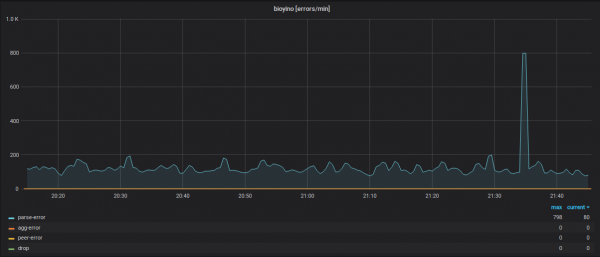
Детализация входящих метрик (имена метрик скрыты).
Что мы планируем с этим всем делать дальше? Конечно же писать код, бл…! Проект изначально планировался как open-source и останется таким всю его жизнь. В ближайших планах — переход на собственную версию Raft, смена peer-протокола на более переносимый, внесение дополнительной внутренней статистики, новых типов метрик, исправление ошибок и другие улучшения.
Конечно же, приветствуются все желающие помогать в развитии проекта: создавайте PR, Issues, по возможности будем отвечать, дорабатывать и т. д.
На этом, как говорится, that’s all folks, покупайте наших слонов!

Allikas: habr.com
