

See pole isegi nali, tundub, et see konkreetne pilt peegeldab kõige täpsemalt nende andmebaaside olemust ja lõpuks saab selgeks, miks:

DB-Engines Rankingu järgi on kaks populaarseimat NoSQL-i veergude andmebaasi Cassandra (edaspidi CS) ja HBase (HB).
Saatuse tahtel on meie Sberbanki andmete laadimise juhtimismeeskond seda juba teinud ja teeb tihedat koostööd HB-ga. Selle aja jooksul uurisime päris hästi selle tugevaid ja nõrku külgi ning õppisime seda küpsetama. Alternatiivi olemasolu CS-i näol sundis meid aga alati pisut piinama kahtlustega: kas tegime õige valiku? Pealegi tulemused , mille esitas DataStax, ütlesid nad, et CS võidab kergesti HB-d peaaegu purustava skooriga. Teisest küljest on DataStax huvitatud osapool ja te ei tohiks nende sõna võtta. Meid ajas segadusse ka üsna väike info testimistingimuste kohta, mistõttu otsustasime omal käel uurida, kes on BigData NoSql kuningas ning saadud tulemused osutusid väga huvitavateks.
Enne tehtud testide tulemuste juurde asumist on aga vaja kirjeldada keskkonnakonfiguratsioonide olulisi aspekte. Fakt on see, et CS-i saab kasutada režiimis, mis võimaldab andmete kadumist. Need. see on siis, kui teatud võtme andmete eest vastutab ainult üks server (sõlm) ja kui see mingil põhjusel ebaõnnestub, läheb selle võtme väärtus kaotsi. Paljude ülesannete puhul pole see kriitilise tähtsusega, kuid pangandussektori jaoks on see pigem erand kui reegel. Meie puhul on usaldusväärseks salvestamiseks oluline andmete mitu koopiat.
Seetõttu arvestati ainult CS töörežiimi kolmekordse replikatsiooni režiimis, s.o. Juhtumiruumi loomine viidi läbi järgmiste parameetritega:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Järgmiseks on nõutava järjepidevuse tagamiseks kaks võimalust. Üldreegel:
NW + NR > RF
Mis tähendab, et sõlmede kinnituste arv kirjutamisel (NW) pluss sõlmede kinnituste arv lugemisel (NR) peab olema suurem kui replikatsioonitegur. Meie puhul on RF = 3, mis tähendab, et sobivad järgmised valikud:
2 + 2 > 3
3 + 1 > 3
Kuna meie jaoks on põhimõtteliselt oluline andmete võimalikult usaldusväärne talletamine, valiti 3+1 skeem. Lisaks töötab HB sarnasel põhimõttel, st. selline võrdlus on õiglasem.
Tuleb märkida, et DataStax tegi oma uuringus vastupidist, nad määrasid nii CS kui ka HB jaoks RF = 1 (viimase jaoks HDFS-i seadeid muutes). See on tõesti oluline aspekt, kuna mõju CS-i jõudlusele on antud juhul tohutu. Näiteks alloleval pildil on näha andmete CS-i laadimiseks kuluva aja pikenemist:
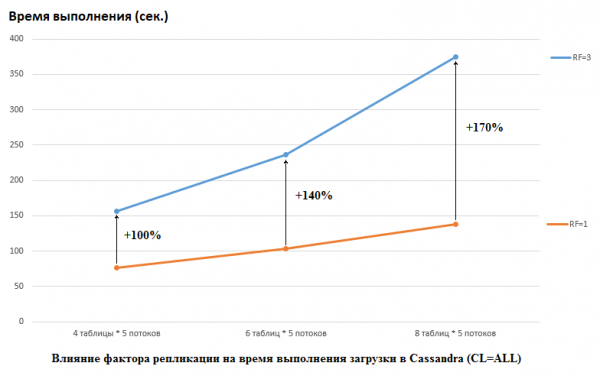
Siin näeme järgmist: mida rohkem konkureerivaid lõime andmeid kirjutab, seda kauem see aega võtab. See on loomulik, kuid on oluline, et RF=3 jõudluse halvenemine oleks oluliselt suurem. Teisisõnu, kui kirjutame 4 lõime 5 tabelisse (kokku 20), siis RF=3 kaotab umbes 2 korda (150 sekundit RF=3 puhul versus 75 RF=1 puhul). Aga kui tõstame koormust, laadides andmed 8 tabelisse, millest igaühes on 5 lõime (kokku 40), siis on RF=3 kadu juba 2,7 korda (375 sekundit versus 138).
Võib-olla on see osaliselt DataStaxi CS-i eduka koormustesti saladus, sest HB jaoks meie stendis replikatsiooniteguri muutmine 2-lt 3-le ei avaldanud mingit mõju. Need. kettad ei ole meie konfiguratsiooni HB kitsaskoht. Siin on aga palju muid lõkse, sest tuleb märkida, et meie HB versiooni sai veidi lapitud ja timmitud, keskkonnad on täiesti erinevad jne. Samuti väärib märkimist, et võib-olla ma lihtsalt ei tea, kuidas CS-i õigesti ette valmistada ja sellega töötamiseks on mõned tõhusamad viisid ning ma loodan, et saame selle kommentaarides teada. Aga kõigepealt asjad kõigepealt.
Kõik testid viidi läbi riistvaraklastris, mis koosnes neljast serverist, millest igaühel oli järgmine konfiguratsioon:
Protsessor: Xeon E5-2680 v4 @ 2.40 GHz 64 keermega.
Kettad: 12 tükki SATA HDD
java versioon: 1.8.0_111
CS-i versioon: 3.11.5
cassandra.yml parameetridmärkide_arv: 256
hinted_handoff_enabled: tõsi
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
vihjete_kataloog: /data10/cassandra/hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
autentija: AllowAllAuthenticator
autoriseerija: AllowAllAuthorizer
roll_manager: CassandraRoleManager
rolls_validity_in_ms: 2000
permissions_validity_in_ms: 2000
volituste_kehtivus_ms: 2000
partitsioonija: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
- /data1/cassandra/data # iga dataN kataloog on eraldi ketas
- /data2/cassandra/data
- /data3/cassandra/data
- /data4/cassandra/data
- /data5/cassandra/data
- /data6/cassandra/data
- /data7/cassandra/data
- /data8/cassandra/data
commitlogi_kataloog: /data9/cassandra/commitlog
cdc_enabled: vale
disk_failure_policy: stop
commit_failure_policy: stop
ready_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
salvestatud_vahemälukataloog: /data10/cassandra/salvestatud_vahemälud
commitlog_sync: perioodiline
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
- klassi_nimi: org.apache.cassandra.locator.SimpleSeedProvider
parameetrid:
— seemned: "*,*"
concurrent_reads: 256 # proovitud 64 - erinevust ei märganud
concurrent_writes: 256 # proovisin 64 - erinevust ei märganud
concurrent_counter_writes: 256 # proovisin 64 - erinevust ei märganud
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # proovis 16 GB - see oli aeglasem
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: vale
trickle_fsync_interval_in_kb: 10240
salvestusport: 7000
ssl_storage_port: 7001
kuula_aadress: *
saate_aadress: *
listen_on_broadcast_address: tõsi
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: tõsi
native_transport_port: 9042
start_rpc: tõsi
rpc_address: *
rpc_port: 9160
rpc_keepalive: tõsi
rpc_serveri_tüüp: sünkroonimine
thrift_framed_transport_size_in_mb: 15
incremental_backups: vale
snapshot_before_compaction: false
auto_snapshot: tõsi
veeru_indeksi_suurus_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: vale
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: puudub
client_encryption_options:
lubatud: vale
internode_compression: dc
inter_dc_tcp_nodelay: vale
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparent_data_encryption_options:
lubatud: vale
tombstone_warn_threshold: 1000
hauakivi_tõrgete_lävi: 100000 XNUMX
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: vale
enable_materialized_views: tõene
enable_sasi_indexes: tõene
GC seaded:
### CMS-i seaded-XX:+UseParNewGC
-XX:+Kasutage ConcMarkSweepGC-d
-XX:+CMSParallelRemarkEnabled
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=1
-XX:CMSIinitiatingOccupancyFraction=75
-XX:+Kasuta CMSIinitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
jvm.options mälule eraldati 16Gb (proovisime ka 32 Gb, vahet ei märganud).
Tabelid loodi käsuga:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};HB versioon: 1.2.0-cdh5.14.2 (klassis org.apache.hadoop.hbase.regionserver.HRegion jätsime välja MetricsRegion, mis viis GC-ni, kui RegionServeris oli piirkondade arv üle 1000)
HBase'i vaikeparameetridloomaaiapidaja.session.timeout: 120000
hbase.rpc.timeout: 2 minutit
hbase.client.scanner.timeout.period: 2 minut(i)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minut(i)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 tundi(t)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 päev(i)
HBase'i teenuse täpsema konfiguratsiooni fragment (kaitseklapp) hbase-site.xml jaoks:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Java konfiguratsioonisuvandid HBase RegionServeri jaoks:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minut(i)
hbase.snapshot.region.timeout: 2 minut(i)
hbase.snapshot.master.timeout.millis: 2 minut(i)
HBase REST serveri maksimaalne logi suurus: 100 MiB
HBase REST serveri logifailide maksimaalsed varukoopiad: 5
HBase Thrift Serveri maksimaalne logi suurus: 100 MiB
HBase Thrift Serveri maksimaalne logifaili varukoopia: 5
Master Max Logi suurus: 100 MiB
Peamised logifailide maksimaalsed varukoopiad: 5
RegionServeri maksimaalne logi suurus: 100 MiB
RegionServeri logifailide maksimaalsed varukoopiad: 5
HBase'i aktiivne põhituvastusaken: 4 minutit
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 millisekundit
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maksimaalne protsessifaili kirjeldus: 180000 XNUMX
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Piirkonna liikuja teemad: 6
Kliendi Java kuhja suurus baitides: 1 GiB
HBase REST serveri vaikerühm: 3 GiB
HBase Thrift Serveri vaikerühm: 3 GiB
Java kuhja HBase Masteri suurus baitides: 16 GiB
HBase RegionServeri Java kuhja suurus baitides: 32 GiB
+ZooKeeper
maxClientCnxns: 601
max SessionTimeout: 120000
Tabelite koostamine:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
muuda 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Siin on üks oluline punkt – DataStaxi kirjeldus ei ütle, mitut piirkonda HB tabelite loomisel kasutati, kuigi see on suurte mahtude puhul kriitiline. Seetõttu valiti testide jaoks kogus = 64, mis võimaldab salvestada kuni 640 GB, s.o. keskmise suurusega laud.
Testimise ajal oli HBase'il 22 tuhat tabelit ja 67 tuhat piirkonda (see oleks olnud surmav versiooni 1.2.0 jaoks, kui mitte ülalmainitud plaastrit).
Nüüd koodist. Kuna polnud selge, millised konfiguratsioonid olid konkreetse andmebaasi jaoks soodsamad, viidi testid läbi erinevates kombinatsioonides. Need. mõnes testis laaditi korraga 4 tabelit (ühendamiseks kasutati kõiki 4 sõlme). Teistes testides töötasime 8 erineva tabeliga. Mõnel juhul oli partii suurus 100, teistel 200 (partii parameeter - vt allpool olevat koodi). Väärtuse andmemaht on 10 baiti või 100 baiti (dataSize). Kokku kirjutati ja loeti igasse tabelisse iga kord 5 miljonit kirjet. Samal ajal kirjutati / loeti igasse tabelisse 5 lõime (lõime number - thNum), millest igaüks kasutas oma võtmevahemikku (loendus = 1 miljon):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Sellest lähtuvalt pakuti HB jaoks sarnast funktsiooni:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Kuna HB-s peab klient hoolitsema andmete ühtlase jaotuse eest, nägi võtmesoolamise funktsioon välja järgmine:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Nüüd kõige huvitavam osa – tulemused:
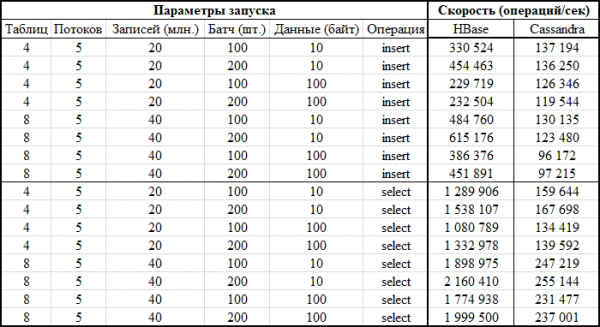
Sama asi graafiku kujul:
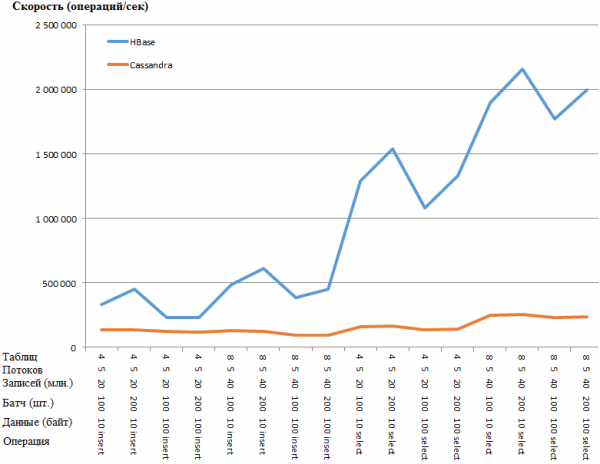
HB eelis on nii üllatav, et tekib kahtlus, et CS-i seadistuses on mingi kitsaskoht. Googeldamine ja kõige ilmsemate parameetrite otsimine (nt concurrent_writes või memtable_heap_space_in_mb) aga asja ei kiirendanud. Samal ajal on palgid puhtad ja ei vannu midagi.
Andmed jaotati sõlmede vahel ühtlaselt, kõigi sõlmede statistika oli ligikaudu sama.
Nii näeb tabeli statistika ühest sõlmest väljaKlahviruum: ks
Lugemiste arv: 9383707
Lugemise latentsusaeg: 0.04287025042448576 ms
Kirjade arv: 15462012
Kirjutamise latentsusaeg: 0.1350068438699957 ms
Ootel mastid: 0
Tabel: t1
SST-tabelite arv: 16
Kasutatud ruum (otses): 148.59 MiB
Kasutatud ruum (kokku): 148.59 MiB
Hetketõmmiste jaoks kasutatud ruum (kokku): 0 baiti
Kasutatud mälumaht (kokku): 5.17 MiB
SST-tabeli tihendussuhe: 0.5720989576459437
Vaheseinte arv (hinnanguline): 3970323
Mäletatavate rakkude arv: 0
Mäletatava andmemaht: 0 baiti
Kasutatud kuhjavälismälu: 0 baiti
Mäletatavate lülitite arv: 5
Kohalik loetud arv: 2346045
Kohaliku lugemise latentsus: NaN ms
Kohalike kirjade arv: 3865503
Kohaliku kirjutamise latentsus: NaN ms
Ootel loputusi: 0
Parandatud protsent: 0.0
Õitsemisfiltri valepositiivsed tulemused: 25
Õitsemise filtri valesuhe: 0.00000
Kasutatud Bloom filtri ruum: 4.57 MiB
Kasutatud Bloom-filtri kuhjamälu: 4.57 MiB
Kasutatud kuhjamälu indeksi kokkuvõte: 590.02 KiB
Kasutatud kuhjamälu tihendamise metaandmed: 19.45 KiB
Tihendatud partitsiooni minimaalsed baidid: 36
Tihendatud partitsiooni maksimaalne bait: 42
Tihendatud partitsiooni keskmine bait: 42
Keskmine elusrakkude arv viilu kohta (viimased viis minutit): NaN
Maksimaalne elusrakkude arv viilu kohta (viimased viis minutit): 0
Keskmine hauakivide arv viilu kohta (viimase viie minuti jooksul): NaN
Maksimaalne hauakivide arv viilu kohta (viimased viis minutit): 0
Tühistatud mutatsioonid: 0 baiti
Katse partii suurust vähendada (isegi eraldi saatmine) ei andnud mingit mõju, läks ainult hullemaks. Võimalik, et tegelikult on see CS-i jaoks tõesti maksimaalne jõudlus, kuna CS-i tulemused on sarnased DataStaxi puhul saadud tulemustega - umbes sadu tuhandeid toiminguid sekundis. Lisaks, kui vaatame ressursside kasutamist, näeme, et CS kasutab palju rohkem protsessorit ja kettaid:
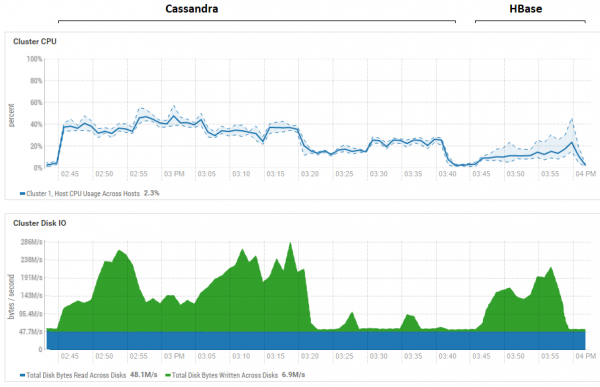
Joonisel on näidatud mõlema andmebaasi kõigi järjestikuste testide kasutamine.
Seoses HB võimsa lugemiseelisega. Siin on näha, et mõlema andmebaasi puhul on ketta kasutamine lugemise ajal äärmiselt madal (lugemistestid on iga andmebaasi testimistsükli viimane osa, näiteks CS puhul on see 15:20 kuni 15:40). HB puhul on põhjus selge – suurem osa andmetest ripub mällu, memstore’is ja osa on vahemällu plokivahemälus. Mis puutub CS-i, siis pole väga selge, kuidas see töötab, kuid ketta taaskasutust pole ka näha, kuid igaks juhuks prooviti lubada vahemälu row_cache_size_in_mb = 2048 ja määrata caching = {'keys': 'ALL', 'rows_per_partition': ' 2000000'}, kuid see tegi asja veelgi hullemaks.
Samuti tasub veel kord mainida olulist punkti HB piirkondade arvu kohta. Meie puhul määrati väärtuseks 64. Kui vähendame seda ja teeme selle võrdseks näiteks 4-ga, siis lugemisel langeb kiirus 2 korda. Põhjus on selles, et memstore täitub kiiremini ja faile loputatakse sagedamini ning lugemisel tuleb rohkem faile töödelda, mis on HB jaoks üsna keeruline toiming. Reaalsetes tingimustes saab seda ravida, mõeldes läbi eeljaotamise ja tihendamise strateegia; eelkõige kasutame ise kirjutatud utiliiti, mis kogub prügi kokku ja tihendab pidevalt taustal HFilesi. On täiesti võimalik, et DataStaxi testide jaoks eraldasid nad ainult 1 piirkonna tabeli kohta (mis pole õige) ja see selgitaks mõnevõrra, miks HB nende lugemistestides nii kehvem oli.
Sellest tehakse järgmised esialgsed järeldused. Kui eeldada, et testimisel suuri vigu ei tehtud, siis näeb Cassandra välja nagu savijalgadega koloss. Täpsemalt, kui ta tasakaalustab ühel jalal, nagu pildil artikli alguses, näitab ta suhteliselt häid tulemusi, kuid võitluses samadel tingimustel kaotab ta otse. Samal ajal, võttes arvesse meie riistvara madalat protsessori kasutamist, õppisime iga hosti kohta kaks RegionServer HB-d ja kahekordistasime seeläbi jõudlust. Need. Võttes arvesse ressursside kasutamist, on CS-i olukord veelgi nukram.
Loomulikult on need testid üsna sünteetilised ja siin kasutatud andmemaht on suhteliselt tagasihoidlik. Võimalik, et terabaitidele üle minnes oleks olukord teine, kuid kui HB puhul saame laadida terabaite, siis CS-i puhul osutus see problemaatiliseks. Sageli viskas see isegi nende mahtude puhul OperationTimedOutExceptioni, kuigi vastuse ootamise parameetreid suurendati juba mitu korda võrreldes vaikeväärtustega.
Loodan, et ühisel jõul leiame CS kitsaskohad ja kui suudame seda kiirendada, siis postituse lõppu lisan kindlasti info lõpptulemuste kohta.
UPD: Tänu seltsimeeste nõuannetele õnnestus mul lugemist kiirendada. Oli:
159 644 operatsiooni (4 lauda, 5 voogu, partii 100).
Lisatud:
.with LoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
Ja ma mängisin niitide arvuga ringi. Tulemus on järgmine:
4 lauda, 100 niiti, partii = 1 (tükk tüki haaval): 301 969 operatsiooni
4 tabelit, 100 lõime, partii = 10: 447 608 operatsiooni
4 tabelit, 100 lõime, partii = 100: 625 655 operatsiooni
Hiljem rakendan muid tuunimisnippe, jooksen läbi täiskatsetsükli ja lisan tulemused postituse lõppu.
Allikas: www.habr.com
