

In autumn 2019, a long-anticipated event occurred in the iOS team of Mail.ru Cloud. The primary database for persistently storing app state became a rather exotic choice for the mobile world. (LMDB). Below, you'll find a detailed overview presented in four parts. First, we'll discuss the reasons for such a non-trivial and challenging choice. Then, we'll explore three pillars of LMDB architecture: memory-mapped files, B+-trees, and the copy-on-write approach for implementing transactionality and multi-versioning. Finally, we'll dive into a practical section where we'll design and implement a scheme with multiple tables on top of a low-level key-value API, including indexing.
Sisu
3.1.
3.2.
3.3.
4.1.
4.2.
4.3.
1. Motivation for adoption
Kordagi 2015. aastal muretsesime selle üle, kui sageli meie rakenduse liides laguneb. Meie tegevus ei olnud juhuslik, kuna saime järjest rohkem kaebusi selle kohta, et rakendus ei reageeri mõnikord kasutaja toimingutele: nupud ei tööta, loendid ei kerida jne. Mõõtmise mehhanikast olen ma AvitoTech'is, seetõttu toon siin välja ainult number.
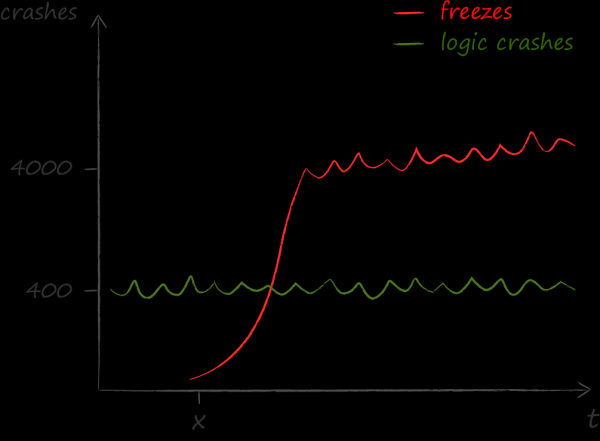
Mõõtmise tulemused olid meile jahmatavad. Selgus, et probleeme, mis tekivad külmumiste tõttu, on palju rohkem kui muude probleemidega. Kui enne selle fakti mõistmist oli peamine tehniline kvaliteedi näitaja crash free, siis pärast keskendus freeze free'ile.
Ehitasime ja viisime läbi ja analüüsi nende põhjuste osas, mis aitasid mõista peamist vaenlast — keeruline äriloogika, mis täidetakse rakenduse põhijoone jooksul. Loomulik reaktsioon sellisele olukorrale oli tungiv soov jaotada see tööliste voogude vahel. Selle probleemi süsteemseks lahendamiseks kasutasime kergkaaluliste aktorite põhjal mitme tahkuse arhitektuuri. Selle kohandust iOSi maailmas pühendasin kollektiivses Twitteris ja . Käesoleva jutustuse raames soovin rõhutada neid lahendusi, mis mõjutasid andmebaasi valikut.
Actorite mudel süsteemi korraldamiseks eeldab, et mitme süsteemi samaaegne töötamine muutub selle teiseks olemuseks. Mudeli objektid armastavad ületada voogude piire. Ja nad teevad seda mitte mõnikord ja kusagil, vaid praktiliselt pidevalt ja igal pool.
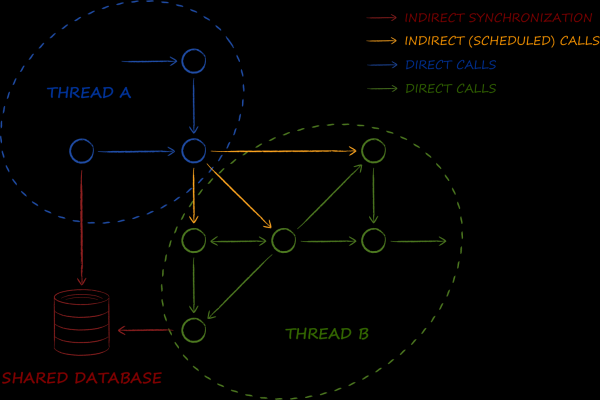
Andmebaas on üks esmatähtsaid komponente esitatud skeemis. Selle peamine ülesanne on makromustri rakendamine. . Kui ettevõtlusmaailmas organiseeritakse andmete sünkroniseerimist teenuste vahel, siis näitlejarakendusarkitektuuris – andmed voogude vahel. Seetõttu vajasime andmebaasi, mille kasutamine mitme lõime keskkonnas ei põhjusta isegi minimaalset raskust. Üksnes see tähendab, et sellest saadud objektid peavad olema vähemalt lõimekindlad ja ideaaljuhul täiesti muutumatud. Nagu on teada, saab viimaseid kasutada korraga mitmest lõimest, vältides igasuguseid lukustusi, mis toob kaasa parema jõudluse.
 Teiseks oluliseks teguriks, mis mõjutas andmebaasi valikut, oli meie pilve API. See sai inspiratsiooni sünkroniseerimise lähenemisest, mida kasutatakse git'is. Nagu see, sihitasime , которое для облачных клиентов выглядит более чем уместно. Предполагалось, что они будут лишь однажды выкачивать полное состояние облака, а затем синхронизация в подавляющем числе случаев будет происходить через накатывание изменений. Увы, эта возможность всё ещё находится лишь в теоретической зоне, а на практике работать с патчами клиенты так и не научились. Тому есть ряд объективных причин, которые, дабы не затягивать введение, оставим за скобками. Сейчас же гораздо больший интерес представляют поучительные итоги урока о том, что происходит когда API сказало «А», а его потребитель не сказал «Б».
Teiseks oluliseks teguriks, mis mõjutas andmebaasi valikut, oli meie pilve API. See sai inspiratsiooni sünkroniseerimise lähenemisest, mida kasutatakse git'is. Nagu see, sihitasime , которое для облачных клиентов выглядит более чем уместно. Предполагалось, что они будут лишь однажды выкачивать полное состояние облака, а затем синхронизация в подавляющем числе случаев будет происходить через накатывание изменений. Увы, эта возможность всё ещё находится лишь в теоретической зоне, а на практике работать с патчами клиенты так и не научились. Тому есть ряд объективных причин, которые, дабы не затягивать введение, оставим за скобками. Сейчас же гораздо больший интерес представляют поучительные итоги урока о том, что происходит когда API сказало «А», а его потребитель не сказал «Б».
Kujutage nüüd ette git'i, mis käskluse pull täitmisel mitte ei rakenda plekke kohaliku snappimisele, vaid võrdleb selle täielikku seisundit serveri täieliku seisundiga. See annab piisava ettekujutuse, kuidas sünkroniseerimine toimub pilveklientides. Pole raske arvata, et selle teostamiseks tuleb mälus eraldada kaks DOM-puulehte, mis sisaldavad metaandmeid kõigi serveri ja kohalike failide kohta. Seega, kui kasutaja salvestab pilves 500 tuhat faili, tuleb tema sünkroniseerimiseks luua ja hävitada kaks puu lehte, mis sisaldavad 1 miljon sõlme. Iga sõlm on aggregaat, mis sisaldab endas graafi objektide alamgruppidest. Sellest vaatenurgast osutusid profiliseerimise tulemused ootuspärasteks. Selgus, et isegi ilma sulandumisalgoritmita maksab juba iseenesest tohutu hulga pisikeste objektide loomise ja hävitamise protseduur. Olukorda süvendab see, et põhitegevus sünkroniseerimine on kaasatud paljude kasutajate stsenaariumidesse. Seega fikseerime teise olulise kriteeriumi andmebaasi valikul — CRUD-operatsioonide teostamise võimalus ilma dünaamiliste objektide eraldamiseta.
Teised nõuded on traditsioonilisemad ja nende täielik nimekiri on järgmine.
- Voogude turvalisus.
- Mitme protsessori kasutamine. See tuleneb soovist kasutada sama andmebaasi eksemplari, et sünkroniseerida olekut mitte ainult voogude vahel, vaid ka peamise rakenduse ja iOSi laienduste vahel.
- Võime esitada salvestatud entiteedid kui muutumatuid objekte.
- Dünaamiliste määramiste puudumine CRUD-operatsioonide käigus.
- Toe toimetamine põhiväärtustele : aatomilisus, järjepidevus, isoleeritus ja usaldusväärsus.
- Kiirus kõige populaarsemates kasutusjuhtumites.
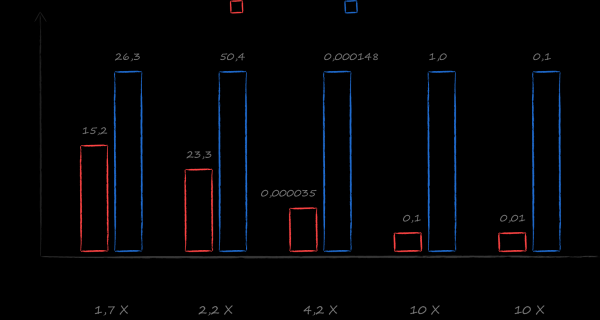
Hea valik sellise nõuete kogumi jaoks oli ja jääb SQLite. Kuid alternatiivide uurimise raames sai minu kätte raamat . Tema juhtimisel koostati benchmark, mis võrdles erinevate andmebaaside töökiirusest reaalses pilvescenaaris. Tulemused ületasid kõige julgemad ootused. Kõige populaarsemates juhtumites – kursori saamine kõigi failide järjestatud loendisse ja määratud katalooge kõigi failide järjestatud loendisse – osutus LMDB 10 korda kiiremaks kui SQLite. Valik on ilmne.
2. LMDB positsioon
LMDB on väga väike teek (ainult 10K rida), millel on rakendatud andmebaaside kõige madalam põhikiht – säilitamine.
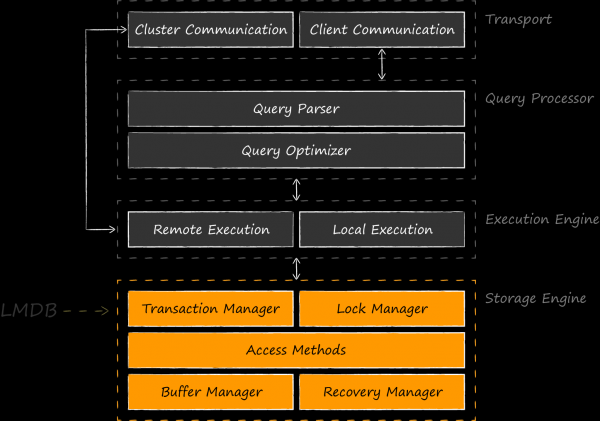
Esitatud skeem näitab, et LMDB-d ei ole korrektne võrrelda SQLite-ga, mis rakendab ka kõrgemaid tasemeid, sama nagu ei ole korrektne võrrelda SQLite-d Core Data-ga. Võrdsete konkurentidena oleks õiglasem tuua välja sarnased säilitustehnikad – BerkeleyDB, LevelDB, Sophia, RocksDB jne. On isegi arendusi, kus LMDB toimib SQLite säilituse komponendina. Esimese sellise eksperimendi viidi läbi 2012. aastal. LMDB autor . olid nii intrigeerivad, et tema algatus võeti üle OSS entusiastide poolt ja leidis jätku . Jaanuaris 2020 esitas projekti autor Den Shearer LinuxConfAu-l.
LMDB peamine rakendus on rakenduslike andmebaaside mootorina. Raamatukogu sai alguse arendajatelt , kes olid väga rahulolematud BerkeleyDB-ga oma projekti aluseks. Alustades tagasihoidlikust raamatukogust , suutis Howard Chu luua ühe kõige populaarsema alternatiivi tänapäeval. Sellele loole ja LMDB sisemisele seadistusele pühendas ta oma laheda ettekande . Hea näite andmete talletamise valdamise kohta jagas Leonid Jurjev (aka ) Positive Technologies'il oma ettekandes Highload 2015 konverentsil . Selles räägib ta LMDB-st sarnase ülesande kontekstis, rakendades ReOpenLDAP, samal ajal kui LevelDB sai kriitilise hinnangu. Tulemuseks oli, et Positive Technologies'il tekkis aktiivselt arenev forkk , millel on palju häid funktsioone, optimeerimisi ja .
LMDB-d kasutatakse sageli andmete talletuseks. Näiteks valis brauser Mozilla Firefox mitmete vajaduste jaoks, ja alates versioonist 9 on Xcode seda SQLite-le indeksite talletamiseks.
Mootor on saanud tähelepanu mobiilse arenduse maailmas. Selle kasutamise jälgi võib Telegrami iOS-äpis. LinkedIn läks veelgi kaugemale ja valis LMDB vaikimisi andmete salvestusruumiks oma kohandatud andmevahemiku raamistikus Rocket Data, millest oma artiklis 2016. aastal.
LMDB võitleb edukalt oma kohta päikese all niššis, mille jättis BerkeleyDB pärast üleminekut Oracle'i kontrolli alla. Raamatukogu on saanud armastust oma kiirusest ja usaldusväärsusest isegi võrreldes sarnaste lahendustega. Nagu teada, ei ole tasuta lõunaid ning tahetakse rõhutada kompromissi, millega tuleb silmitsi seista valides LMDB ja SQLite vahel. Ülalolev skeem näitab selgelt, kuidas saavutatakse suurenenud kiirus. Esiteks, me ei maksa lisatasu diskihaldurite peal olevate abstraktsioonikihtide eest. Selge on see, et hea arhitektuur ei saa ilma nendeta hakkama, ja need ilmuvad nõnda või teisiti rakenduste koodis, kuid need on kindlasti palju õhemad. Nendes ei ole funktsioone, mida konkreetne rakendus ei vaja, nagu näiteks SQL-i keelepäringute toetamine. Teiseks, avaneb võimalus rakendada optimaalselt rakenduslike operatsioonide mappimist diskihalduri päringutele. Kui SQLite lähtub keskmiste vajaduste keskmiselt rakendusest, siis olete rakenduse arendajana hästi teadlik peamistest koormuse stsenaariumidest. Tootlikuma lahenduse eest tuleb maksta kõrgemat hinda nii esialgse lahenduse arendamise kui ka selle edasise toe eest.
3. Kolm LMDB alustala
Vaadates LMDB-d linnulennult, on aeg laskuda süg deeper. Järgmised kolm osa käsitlevad peamisi tugisambasid, millel hoone arhitektuur põhineb:
- Mälu kaardistatud failid kui mehhanism ketas-tööks ja sisemiste andmestruktuuride sünkroonimiseks.
- B+-puu kui salvestatud andmete struktuuri korraldamise viis.
- Copy-on-write kui lähenemine tehingute ACID-omaduste tagamiseks ja mitme versiooni haldamiseks.
3.1. Alustala nr 1. Mälu kaardistatud failid
Mälufailid on nii olulised arhitektuuri elemendid, et need kajastuvad isegi salvestusruumi nimekirjas. Kittimiste ja salvestatud teabele juurdepääsu sünkroniseerimise küsimused on täielikult operatsioonisüsteemi ülesanne. LMDB ei sisalda endas mingeid vahemälusid. See on autori teadlik valik, kuna andmete lugemine otse kaardistatud failidest võimaldab rakenduse põhjal palju nurki lõigata. Allpool on toodud kindlasti mitte ammendav nimekiri mõnest neist.
- Andmete järjepidevuse säilitamine salvestusruumis, kui sellega töötavad mitu protsessi, muutub operatsioonisüsteemi ülesandeks. Järgmises osas käsitletakse seda mehhanismi üksikasjalikult ja koos joonistega.
- Vahemälude puudumine vabastab LMDB täielikult dünaamilise jaotusega seotud kuludest. Andmete lugemine on praktikas lihtsalt viitamine õigele aadressile virtuaalses mälus ja mitte midagi enamat. See kõlab nagu ulme, kuid salvestusruumi lähtefailides on kõik salloc'i kutsed koondatud salvestuse konfigureerimise funktsiooni.
- Vahetevaheline vahemälu puudumine tähendab, et sünkroniseerimine nende juurde pääsemise osas ei põhjusta mingeid blokeeringuid. Samaaegselt võib olla suvaline hulk lugejaid, kes ei kohtu andmete teel ühtegi mälukeelt. Seetõttu on lugemise kiirus ideaalne lineaarselt skaleeritav iga CPU arvu järgi. LMDB-s on sünkroniseeritud ainult muudatusoperatsioonid. Iga hetke jooksul võib kirjutaja olla vaid üks.
- Madal vahemälu ja sünkroniseerimislähenemise loogika vabastab koodi äärmiselt keerulistest vigadest, mis on seotud mitme niidi tööga. Usenix OSDI 2014 konverentsil oli kaks huvitavat uurimistööd andmebaaside kohta: ja . Nendest saab teavet nii LMDB enneolematust usaldusväärsusest kui ka praktiliselt veatut ACID-tehingute omaduste rakendust, mis ületab samas SQLite'i.
- LMDB minimalistlikkus võimaldab masina esitluse koodi täielikult paigutada protsessori L1-vahemällu, mis toob kaasa kiirusomadused.
Kahjuks ei ole iOS-is mälu kaardistatud failidega kõik nii roosiline, nagu sooviks. Seotud puuduste teadlikumaks arutamiseks on oluline meenutada selle mehhanismi rakendamise üldpõhimõtteid operatsioonisüsteemides.
Ülevaade mälu kaardistatud failidest
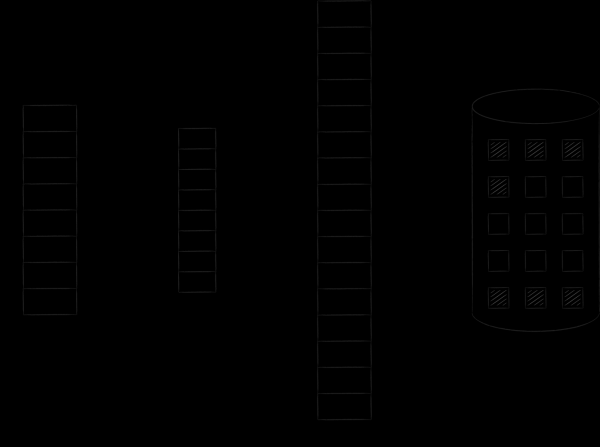
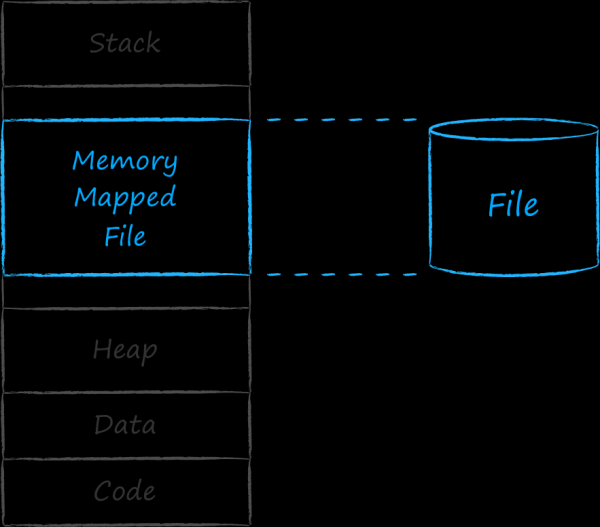 Iga käivitatava rakendusega seondub operatsioonisüsteemile üksus nimega protsess. Iga protsessile eraldatakse pidev aadressivahemik, kus ta paigutab kogu vajalikud tööks. Aadresside madalamates osades paiknevad koodi ning kõvakettale kirjutatud andmete ja ressursside sektsioonid. Seejärel järgneb ülespoole kasvav dünaamiline aadressiruum, mis on meile tuttav nime all heap. See sisaldab aadresse üksustele, mis ilmuvad programmi töö käigus. Üksuse ülemises osas asub mälu ala, mida rakendus kasutab steki jaoks. See kasvab ja kahaneb, teisisõnu, selle suurus on samuti dünaamiline. Et stekki ja heap'i ei segataks ja teineteist ei segaks, on need paigutatud aadressiruumi erinevatesse otste. Kahe dünaamilise sektsiooni vahel ülal ja all on auk. Aadresse keskmises osas kasutab operatsioonisüsteem, et seostada protsessiga erinevaid üksusi. Konkreetsemalt võib see seostada mingi pideva aadresside kogumiga — faili kettal. Sellist faili nimetatakse mällu kaardistatud failiks.
Iga käivitatava rakendusega seondub operatsioonisüsteemile üksus nimega protsess. Iga protsessile eraldatakse pidev aadressivahemik, kus ta paigutab kogu vajalikud tööks. Aadresside madalamates osades paiknevad koodi ning kõvakettale kirjutatud andmete ja ressursside sektsioonid. Seejärel järgneb ülespoole kasvav dünaamiline aadressiruum, mis on meile tuttav nime all heap. See sisaldab aadresse üksustele, mis ilmuvad programmi töö käigus. Üksuse ülemises osas asub mälu ala, mida rakendus kasutab steki jaoks. See kasvab ja kahaneb, teisisõnu, selle suurus on samuti dünaamiline. Et stekki ja heap'i ei segataks ja teineteist ei segaks, on need paigutatud aadressiruumi erinevatesse otste. Kahe dünaamilise sektsiooni vahel ülal ja all on auk. Aadresse keskmises osas kasutab operatsioonisüsteem, et seostada protsessiga erinevaid üksusi. Konkreetsemalt võib see seostada mingi pideva aadresside kogumiga — faili kettal. Sellist faili nimetatakse mällu kaardistatud failiks.
Eraldatud protsessorile adresseeritud mäluruum on tohutu. Teoreetiliselt on aadresside arv piiratud vaid näitajate suurusega, sõltudes süsteemi bitilisusest. Kui see oleks 1-1 vastavuses füüsilise mäluga, siis esimene protsess neelaks kogu RAMi, ja multitaskingust ei saaks juttugi olla.
Kuid oma kogemustest teame, et kaasaegsed operatsioonisüsteemid saavad samal ajal käitada piiramatul hulgal protsesse. See on võimalik tänu sellele, et nad jagavad protsessidele mäluruumi vaid paberil, samas kui tegelikku füüsilist mälu laaditakse ainult selle osa jaoks, mis on hetkel vajalik. Seetõttu nimetatakse protsessiga seotud mälu virtuaalseks.
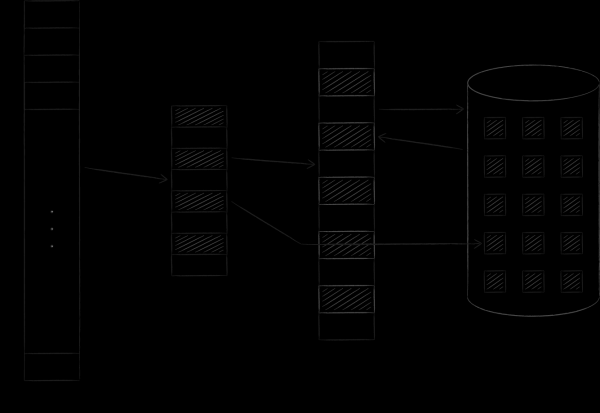
Operatsioonisüsteem korraldab nii virtuaalset kui füüsilist mälu kindlate suurustega lehtedena. Kui mõni virtuaalmälu leht osutub vajalikuks, laadib operatsioonisüsteem selle füüsilisse mällu ja koostab nende vahel vastavuse spetsiaalses tabelis. Kui vabu kohti ei ole, kopeeritakse üks varem laaditud leht kettale, ja nõutav leht asetatakse selle kohale. Seda protseduuri, millega me peagi tagasi tuleme, nimetatakse vahetuseks (swapping). Allolev joonis illustreerib kirjeldatud protsessi. Sellel on leht A aadressiga 0, mis on laaditud ja asetatud põhimuudesse lehe aadressiga 4. See fakt leidis kajastust vastavustabelis lahtris number 0.
Failide mälus kuvatud ajalugu on sama. Loogiliselt väidetakse, et need paigutatakse pidevalt ja koos kogu ulatuses virtuaalsesse aadressiruumi. Siiski jõuavad nad füüsilisse mällu lehekaupa ja ainult nõudmisel. Selliste lehtede muutmine sünkroniseeritakse diskifailiga. Seega on võimalik failide sisendi/väljundi teostamine, töötades lihtsalt mälus baitidega — kõik muutused kantakse operatsioonisüsteemi tuuma poolt automaatselt algsesse faili.
Allolev pilt näitab, kuidas LMDB sünkroniseerib oma olekut, töötades andmebaasiga erinevatest protsessidest. Kaardistades erinevate protsesside virtuaalmälu ühte ja samasse faili, kohustame me tegelikult operatsioonisüsteemi transitiivselt sünkroniseerima teatud plokke nende aadressiruumi vahel, kuhu LMDB vaatab.
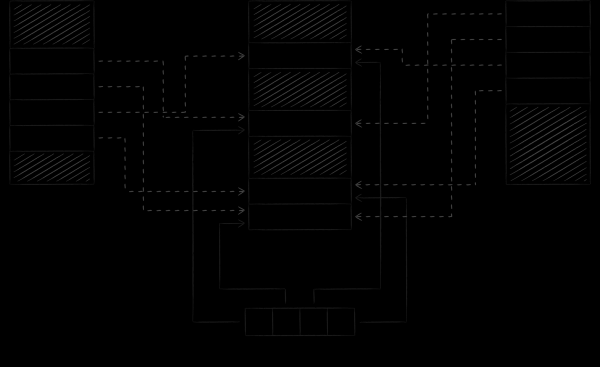
Oluline nüanss on see, et LMDB muudab vaikimisi andmefaili läbi süsteemikõne write, samas kui fail ise on avatud ainult lugemiseks. Selle lähenemisega on kaks olulist tagajärge.
Esimene järeldus kehtib kõigi operatsioonisüsteemide puhul. Selle olemus seisneb andmebaasi kaitsmas tahtmatu kahjustamise eest vigase koodi tõttu. Nagu teada, võivad protsessi käivitatavad käsud juurdepääseda andmetele mis tahes kohast oma aadressiruumi. Samas, nagu just mainisime, tähendab faili avamine lugemis-kirjutamisrežiimis, et iga käsk võib seda ka modifitseerida. Kui ta teeb seda ekslikult, püüdes näiteks kirjutada massiivi elementi, mille indeks ei eksisteeri, võib ta sellisel juhul juhuslikult muuta sellele aadressile kaardistatud faili, mis viib andmebaasi rikkumiseni. Kui fail on avatud ainult lugemiseks, siis vastava aadressiruumi muutmine viib programmi ootamatu lõpetamiseni signaaliga SIGSEGV, ja fail jääb terviklikuks.
Teine järeldus on spetsiifiline juba iOS-ile. Ei autor ega ükski teine allikas ei maini seda selgelt, kuid ilma selleta ei oleks LMDB selle mobiilse operatsioonisüsteemi jaoks kasutatav. Sellele pühendatakse järgmine jagu.
Специфика отображённых в память файлов в iOS
В 2018 году на WWDC был замечательный доклад . В нём рассказывается, что в iOS все страницы, расположенные в физической памяти, относятся к одному из 3 типов: dirty, compressed и clean.

Puhas mälu — see on lehtede kogum, mille saab füüsilisest mälust valutult eemaldada. Nendes leiduvad andmed saab vajadusel uuesti algallikatest laadida. Üksnes lugemiseks mõeldud mäluga kaardistatud failid kuuluvad just sellesse kategooriasse. iOS ei pelga igal ajal lehti mälu täitmise ajal välja laadida, kuna need on garanteeritult sünkroniseeritud failiga kettal.
Määrdunud mälu hõlmab kõiki muudetud lehti, sõltumata nende algsest asukohast. Eelkõige klassifitseeritakse sellesse ka mäluga kaardistatud failid, mida on muudetud kirjutamise kaudu nendele vastavasse virtuaalsesse mällu. Avades LMDB lipuga MDB_WRITEMAP, pärast muudatuste tegemist saab seda isiklikult kinnitada.
Kui rakendus hakkab tarbima liiga palju füüsilist mälu, siis iOS kompressib selle dirty leheküljed. Dirty ja kompressitud lehekülgede mälukoormus koos moodustab rakenduse nii-öelda memory footprint. Kui see saavutab teatud piirväärtuse, siis sekkub süsteemne daemon OOM killer ja sunnib protsessi lõpetama. See on iOS eripära võrreldes lauaarvutite opsüsteemidega. Erinevalt neist ei ole iOS-is võimalik memory footprinti vähendada lehekülgede vahetamise kaudu füüsilisest mälust kettale. Põhjustest võib vaid spekuleerida. Võib-olla on lehekülgede intensiivne liikumine kettale ja tagasi mobiilseadmete jaoks liiga energiat nõudev või püüab iOS säästa SSD-de lahtrite ülekirjutamise ressursse, või ei olnud projekteerijate jaoks süsteemi üldine jõudlus, kus kõik pidevalt vahetub, rahuldav. Kuidas iganes, fakt jääb faktiks.
Hea uudis, nagu varem mainitud, on see, et LMDB ei kasuta vaikimisi failide uuendamiseks mmap mehhanismi. Seetõttu klassifitseerib iOS kuvatud andmed kui puhas mälu, mis ei mõjuta mälu jalajälge. Selle tõestamiseks saab kasutada Xcode'i tööriista nimega VM Tracker. Alloleval ekraanipildil on kujutatud iOS rakenduse Oblaak virtuaalse mälu seisundit töötamise ajal. Alguses oli initsialiseeritud 2 LMDB instantsi. Esimesele oli lubatud kaardistada oma fail 1GiB virtuaalsele mälule, teisele - 512MiB. Kuigi mõlemad salvestused võtavad teatud koguse residentset mälu, ei pane kumbki neist kaasa määrdunud suurusele.
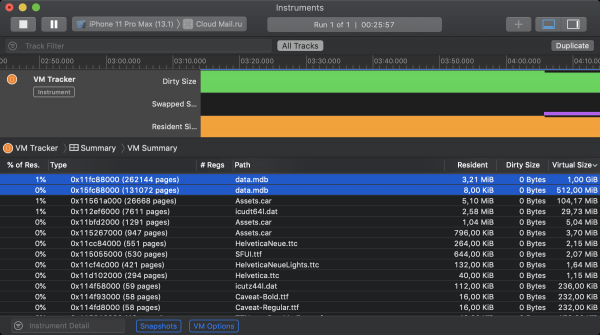
Ja nüüd on aeg halbadeks uudisteks. 64-bitistes lauaarvutite operatsioonisüsteemides käivitusmehhanismi tõttu võib iga protsess hõivata nii palju virtuaalset aadressiruumi, kui lubab vabade kohtade olemasolu kõvakettal selle potentsiaalse vahetuse jaoks. Vahetuse asendamine iOS-is kompressiooniga vähendab teoreetilist maksimaalset raunditavate ressursside arvu. Nüüd peavad kõik aktiivsed protsessid mahtuma põhisse (loe: operatiivmälu), ning kõik, mis ei mahtunud, tuleb sundida lõpetama. Sellest räägitakse ka eespool mainitud , kui ka . Selle tulemusena piirab iOS rangelt mälu hulka, mis on saadaval mmap-i kaudu eraldamiseks. Siin on seda saab uurida eksperimentaalseid mälumahtude piire, mida on võimalik erinevates seadmetes selle süsteemi kõne abil eraldada. Kõige kaasaegsematel iOS nutitelefonidel on saadaval 2 gigabayti, samas kui tippversioonidel iPadidel kuni 4 gigabayti. Praktiliselt tuleb aga arvestada kõige madalamate toetatavate seadmete mudelitega, kus olukord on üsna kehv. Veelgi hullem, kui vaadata rakenduse mälu staatust VM Tracker'is, võib avastada, et LMDB ei ole ainus, kes pretendeerib memory-mapped mälule. Suured osad varastavad süsteemi allocatorid, ressurssifailid, pildi töötlemise raamistikud ja teised väiksemad röövlid.
Katsede tulemuste põhjal pilves jõudsime järgmiste kompromissväärtusteni, mida eraldatakse LMDB mälule: 384 megabaiti 32-bitiste seadmete jaoks ja 768 64-bitiste jaoks. Pärast selle mahu kasutamist hakkavad kõik muutmisoperatsioonid lõpule viima koodiga MDB_MAP_FULL. Selliseid vigu jälgime meie jälgimises, kuid neid on piisavalt vähe, et neid sellel etapil võiks ignoreerida.
Üks vähem ilmne põhjus mälukaubanduse liigseks tarbimiseks võivad olla pikaajalised tehingud. Selle kahe nähtuse omavahelise seose mõistmiseks aitab meil kahe ülejäänud LMDB tiigri arutamine.
3.2. Tiiger nr 2. B+-puu
Key-value salvestuskihi peal tabelite emuleerimiseks peab selle API-s olema järgmised toimingud:
- Uue elemendi lisamine.
- Elemendi otsimine antud võtmega.
- Elemendi eemaldamine.
- Itereerimine võtmevahemike kaudu nende sorteerimise järjekorras.
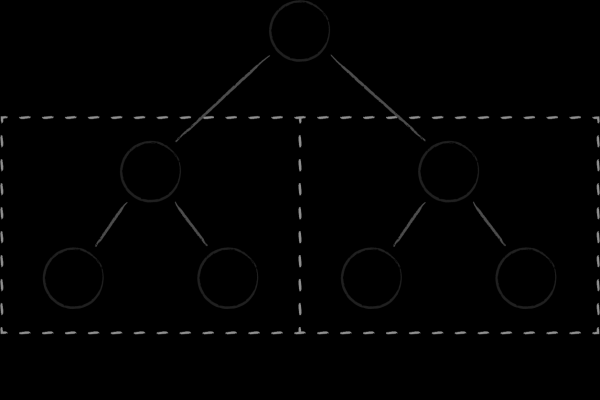 Kõige lihtsam and structure, millega kõiki nelja toimingut on lihtne teostada, on binaarne otsingupuu. Iga tema sõlm esindab võtme, jagades kogu alamkogumi tütarvõtmeid kaheks alampuuks. Vasakul on need, mis on vanemast väiksemad, ja paremal need, mis on suuremad. Sorteeritud võtme kogumi saamine saavutatakse ühe klassikalise puu läbimise meetodi kaudu.
Kõige lihtsam and structure, millega kõiki nelja toimingut on lihtne teostada, on binaarne otsingupuu. Iga tema sõlm esindab võtme, jagades kogu alamkogumi tütarvõtmeid kaheks alampuuks. Vasakul on need, mis on vanemast väiksemad, ja paremal need, mis on suuremad. Sorteeritud võtme kogumi saamine saavutatakse ühe klassikalise puu läbimise meetodi kaudu.
Binaarset puud on kaks fundamentaalset puudust, mis takistavad nende efektiivsust kettastruktuuride andmetena. Esiteks on nende tasakaaluaste ettearvamatu. On märkimisväärne risk saada puid, mille erinevate oksade kõrgus võib tugevalt erineda, mis halvendab oluliselt otsingu algoritmilist keerukust võrreldes oodatuga. Teiseks, sõlmede vaheline rikkaid ristviiteid röövivad binaarsed puud mälu lokaliseerimisest. Lähedased sõlmed (suhete poolest) võivad asuda täiesti erinevates lehtedes virtuaalses mälus. Selle tagajärjel võib isegi mitme naabrussõlme lihtne läbimine puud väärtuda sarnase arvu lehekülgede külastamise. See on probleem isegi siis, kui arutame binaarsete puude efektiivsust in-memory andmestruktuuridena, sest pidev lehtede rotatsioon protsessori vahemälus on kulukas rõõm. Kui aga jutt käib sageli sõlmedega seotud lehtede diskilt üles tõstmisest, siis on olukord täiesti .
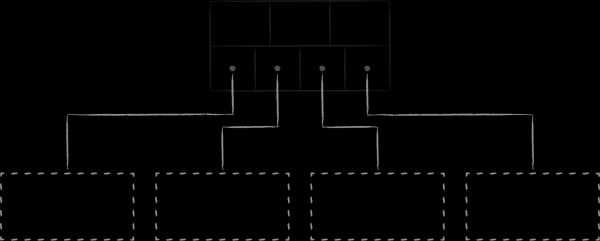 B-puude, olles binaarpuude evolutsioon, lahendavad eelnevalt mainitud probleemid. Esiteks on nad ise balansseeruvad. Teiseks, iga nende sõlm jagab hulga laste võtmeid mitte 2, vaid M järjestatud alamhulkadeks, kusjuures M võib olla suhteliselt suur, ulatudes sadadeni või isegi tuhandeteni.
B-puude, olles binaarpuude evolutsioon, lahendavad eelnevalt mainitud probleemid. Esiteks on nad ise balansseeruvad. Teiseks, iga nende sõlm jagab hulga laste võtmeid mitte 2, vaid M järjestatud alamhulkadeks, kusjuures M võib olla suhteliselt suur, ulatudes sadadeni või isegi tuhandeteni.
Selle tõttu:
- Igas sõlmes on suur hulk juba järjestatud võtmeid ja puude kõrgeus on väga madal.
- PUU omandab mälu kohalikkuse omaduse, kuna sarnaste võtmete väärtused asuvad loomulikult üksteise lähedal samades või naaber sõlmedes.
- Vähenevad ülemineku sõlmede arv puust laskumisel otsinguoperatsiooni ajal.
- Vähenevad lugemise sihtmärkide sõlmede arv range-päringute ajal, kuna igas neist on juba suur hulk järjestatud võtmeid.
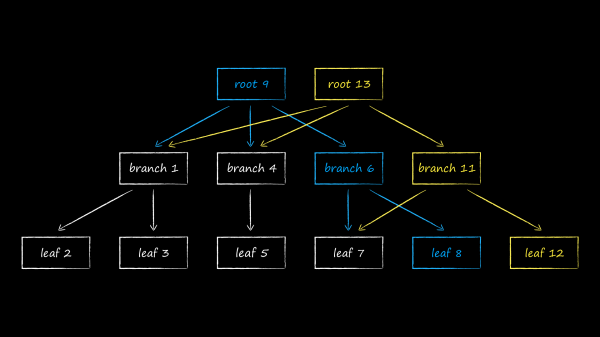
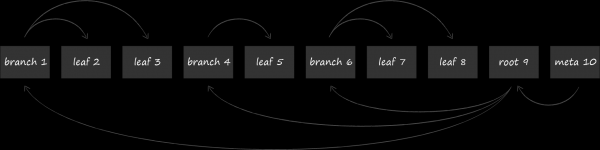
LMDB-s andmete salvestamiseks kasutatakse ühte B-puude variatsiooni, mida nimetatakse B+-puuks. Ülaltoodud skeemil on kujutatud kolme tüüpi sõlmi, mis selles esinevad:
- Tipus asub juur (root). See materialiseerib andmebaasi kontseptsiooni salvestuses. Ühes LMDB instantsis saab luua mitu andmebaasi, mis jagavad kaartide virtuaalset aadressiruumi. Igaüks neist algab omaenda juurest.
- Alumise taseme moodustavad lehed (leaf). Just nemad sisaldavad andmebaasis hoitavaid võtme-väärtuse paare. See ongi B+-puude eripära. Kui tavaline B-puu hoiab väärtuste osi kõikide tasemete sõlmedes, siis B+-variandis ainult kõige alumisel tasemel. Seda fakti silmas pidades, nimetame edaspidi LMDB-s kasutatavat puu alamtüüpi lihtsalt B-puuks.
- Juure ja lehtede vahel asub 0 või enam tehnilist taset, kus asuvad navigeerimis (branch) sõlmed. Nende ülesanne on jagada sorteeritud võtmete kogum lehtede vahel.
Füüsilised sõlmed on eelnevalt määratletud pikkusega mälublockid. Nende suurus on mälulehtede suurusele operatsioonisüsteemis, millest oleme varem rääkinud, kordaja. Allpool on esitatud sõlme struktuur. Pealkirjas on metaandmed, kõige silmatorkavam neist — kontrollsummad. Järgneb teave offset'ide kohta, mille alusel asuvad andmeühikud. Andmed võivad olla kas võtmed, kui räägime navigatsioonisõlmedest, või täielikud võtme-väärtuse paarid lehtede puhul. Täiendavalt veebilehtede struktuurist saab lugeda töös .
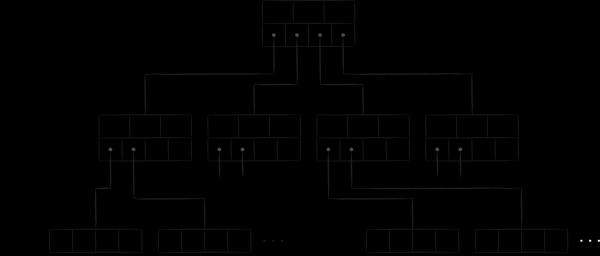
Pärast sõlme-lehtede sisuga tutvumist esitame LMDB B-puude lihtsustatud vormis järgmiselt.
Sõlmede lehed paiknevad diskil järjestikku. Suuremad lehed asuvad faili lõpu poole. Nii öeldud meta-leht (meta page) sisaldab teavet offset'ide kohta, mille abil leida kõigi puude juured. LMDB avamisel skaneerib fail lehti tagurpidi, otsides kehtivat meta-lehte, mille kaudu leitakse olemasolevad andmebaasid.
Nüüd, kui on arusaam andmete organisatsiooni loogilisest ja füüsilisest Struktuurist, ehk on võimalik minna edasi LMDB kolmanda samba käsitlemisega. Just selle abil toimuvad kõik muutused hoidlas tehingu- ja eraldusprotsessis, andes andmebaasile tervikuna ka multi-versioonilisuse tunnuse.
3.3. Samba nr 3. Copy-on-write
Mõned B-puuga seotud toimingud hõlmavad mitmeid muudatusi selle sõlmedes. Üheks näiteks on uue võtme lisamine sõlmesse, kus on juba saavutatud maksimaalne maht. Sellisel juhul on kõigepealt vajalik sõlm jagada kaheks ja teiseks lisada viide uuele välja kasvanud lastesõlmele tema vanemasse. See protseduur on potentsiaalselt väga ohtlik. Kui mingil põhjusel (krahh, toitekatkestus jne) toimub ainult osa muudatusi järjest, jääb puu järjepidevusseolekusse.
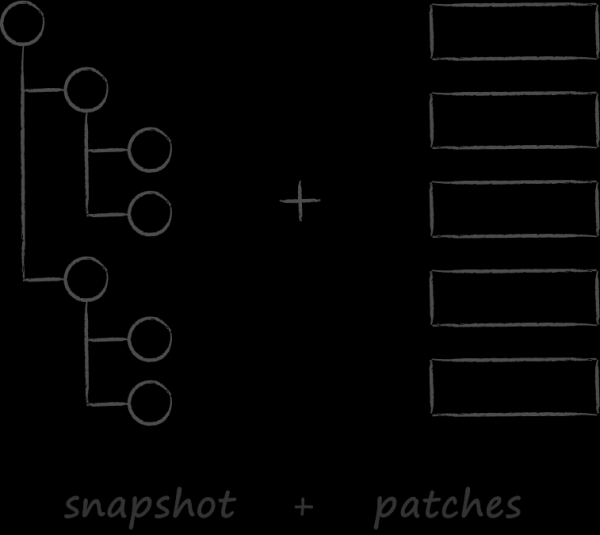
Ühe traditsioonilise lahendusena andmebaasi tõrgetest kaitsmiseks on lisaks B-puule andmestruktuuri diskimooduli — tehingute logi, mida tuntakse ka kui write-ahead log (WAL) — lisamine. See on fail, kuhu kirjutatakse oodataolev toiming enne B-puu enda muutmist. Seega, kui isediagnoosimise käigus avastatakse andmete kahjustus, pöördub andmebaas logi poole, et ennast korda seada.
LMDB on valinud andmebaasi tõrgetest kaitsmiseks teistsuguse meetodi, mida nimetatakse copy-on-write. Selle põhimõte seisneb selles, et andmete uuendamisel olemasoleval lehel koopiat ei muudeta, vaid kopeeritakse täielikult ja kõik muudatused tehakse juba koopias.
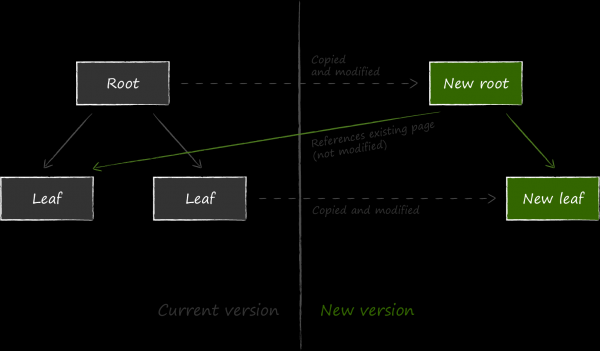
Edasi, et uuendatud andmed oleksid kergesti kättesaadavad, tuleb muuta viidet uuele sõlmele vanemas oma vanem sõlmes. Kuna ka seda tuleb modifitseerida, kopeeritakse see eelnevalt. Protsess jätkub rekursiivselt juurest. Viimaks muudetakse andmeid meta-lehel.
Kui uuendamise protsessi ajal juhtub ootamatu katkestus, siis ei pruugi uus meta-leht üldse luua või ei salvestata seda kettale täielikult, mille tulemusel on selle kontrollsummad vigased. Ühes neist olukordadest on uued lehed kättesaamatud, samas kui vanad lehed jäävad puutumatuks. See vabastab LMDB vajadusest pidada kirjutamislogi andmete järjepidevuse tagamiseks. Ülaltoodud kirjeldatud andmestruktuur täidab samal ajal ka selle funktsiooni. Tehingulogide puudumine nähtavas vormis on üks LMDB omadustest, mis tagab andmete lugemise kõrge kiirus.
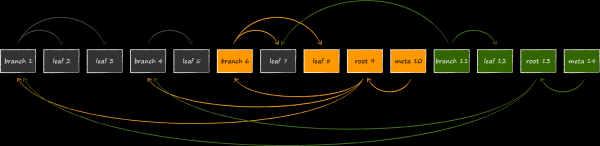
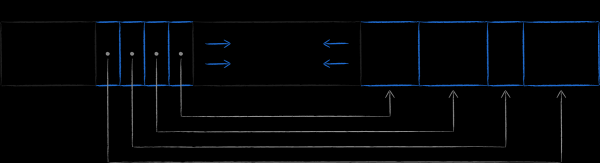
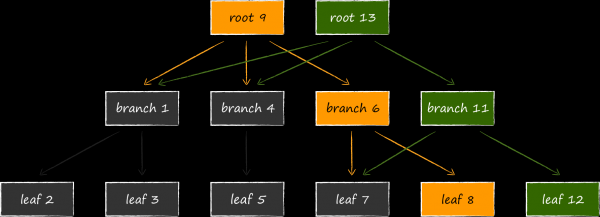
Tekst, mille nimi on append-only B-puu, tagab loomulikul viisil tehingute isoleerituse ja mitme versiooni. LMDB-s seondub iga avatud tehingu puhul praegune puu juur. Kuni tehing ei ole lõpule viidud, ei muudeta ega kasutata uuesti seotud puu lehti uute andmeversioonide jaoks. Seega saab töötada ka lõputult täpselt nende andmete komplektiga, mis oli aktuaalne tehingu avamise hetkel, isegi kui salvestus jätkab aktiivset värskendamist. See on mitme versiooni olemus, mis teeb LMDB-st ideaalse andmeallika meie lemmikute jaoks. UICollectionView. Tehingu avamisel ei ole vaja suurendada rakenduse mälu tarbimist, kiirustades vajalikke andmeid mõnda in-memory struktuuri, kartes jääda tühjade kätega. See omadus eristab LMDB-d SQLite'ist, mis ei saa sellise täieliku isolatsiooniga kiidelda. Kui avada viimases kaks tehingut ja kustutada üks rida ühe nende raames, ei saa seda rida teises tehingus enam kätte.
Medali tagaküljeks on potentsiaalselt oluliselt suurem virtuaalse mälu kulu. Tootepildil on näha, milline näeb välja andmebaasi struktuur, kui selle modifitseerimine toimub samal ajal kolme avatud lugemise tehinguga, mis vaatavad erinevatele andmebaasi versioonidele. Kuna LMDB ei saa taaskasutada sõlmi, mis on seotud aktiivsete tehingutega, ei jää ladustamisele muud võimalust, kui paigutada mälu veel üks neljas juur ja veel kord kloonida muudetavad leheküljed.
Siin oleks kasulik meenutada mälu kaardistamise failide jaotust. Tundub, et täiendav virtuaalmälu kulu ei tohiks meid liialt häirida, kuna see ei too kaasa rakenduse mälu jalajälge. Siiski on tähelepanuväärne, et iOS on ehtsalt kitsi selle eraldamisega, ja me ei saa nagu serveris või lauaarvutis laialdaselt jagada 1 terabaiti LMDB piirkonda, mõtlemapanevalt sellest omadusest täiesti mööda. Kui võimalik, tuleks püüda teha tehingute eluiga võimalikult lühikeseks.
4. Andmeskeemi projekteerimine key-value API peal
Analüüsime API-d, alustades LMDB pakutavatest põhistruktuuridest: keskkond ja andmebaasid, võtmed ja väärtused, tehingud ja kursori.
Märkus koodilistingute kohta
Kõik LMDB avaliku API funktsioonid tagastavad oma töö tulemuse veakoodina, kuid kõigil järgnevates koodilistingutes on selle kontrollimine vahele jäetud kokkuvõtlikkuse huvides. Praktikas kasutasime me hoopis oma C++ wrapper'it , kus vead materialiseeruvad C++ erandite näol.
Kiiruselt kõige efektiivsema viisina LMDB ühendamiseks iOS või macOS projektiga pakun välja oma CocoaPodi .
4.1. Põhiabstraktsioonid
Keskkond (environment)
Struktuur MDB_env on LMDB sisemise oleku hoidla. Funktsioonide pere prefiksiga mdb_env lubab konfigureerida teatud atribuute. Lihtsaimal juhul näeb mootori initsialiseerimine välja järgmiselt.
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);Mail.ru Cloud rakenduses muutsime vaikeväärtusi ainult kahe parameetri jaoks.
Esimene neist on virtuaalse aadressiruumi suurus, kuhu andmesalvestuse fail kaardistatakse. Kahjuks võib isegi samas seadmes konkreetne väärtus märkimisväärselt erineda käivituse kaupa. Selle eripära arvestamiseks iOSis valitakse mälumaht dünaamiliselt. Alustades mingist väärtusest, vähendatakse seda järjestikku, kuni funktsioon mdb_env_open tagastab tulemuse, mis ei ole ENOMEM. Teoreetiliselt on võimalik ka vastupidine tee — kõigepealt eraldada mootorile minimaalne mälu ja seejärel, kui tekivad vead. MDB_MAP_FULL, suurendama seda. Kuid see on palju keerulisem. Põhjus peitub selles, et mälu ümberjaotamise protseduur (remap) funktsiooni abil mdb_env_set_map_size makeb kõik entiteedid (kursused, tehingud, võtmed ja väärtused), mis on varem mootori poolt saadud. Sellise sündmuse arvestamine koodis muudab selle oluliselt keerulisemaks. Kui virtuaalne mälu on siiski teile väga oluline, siis võib see olla põhjus, miks tasub vaadata edasi arenenud forkide poole , kus üheks lubatud omaduseks on „automaatne andmebaasi suuruse kohandamine reaalajas“.
Teine parameeter, mille vaikeseade ei sobinud, reguleerib niiditurbemehhanismi. Kahjuks on vähemalt iOS 10-l probleeme niidilokaalse salvestamise toe osas. Seetõttu avatakse eespool toodud näites salvestus lipuga MDB_NOTLS. Lisaks oli vajalik ka C++ mähis , et eemaldada selle omadusega muutujad ka sellest.
Andmebaasid
Andmebaas on eraldi B-puu instants, millest rääkisime varem. Selle avamine toimub tehingu sees, mis esialgu võib tunduda veidi kummaline.
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);Tõepoolest, LMDB-s toimub tehing mitte konkreetse andmebaasi, vaid andmehoidla kontekstis. See lähenemisviis võimaldab teostada aatomite operatsioone erinevates andmebaasides olevate üksustega. Teoreetiliselt avab see võimaluse modelleerida tabeleid erinevate andmebaasidena, kuid ma valisin varem teistsuguse tee, mida kirjeldan allpool.
Võtmed ja väärtused
Struktuur MDB_val mudel ei erista võtme ja väärtuse kontseptsiooni. Andmehoidla ei tea nende semantikast midagi. Nad on vaid määratletud suurusega baitide massiiv. Maksimaalne võtme suurus on 512 baiti.
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;Andmehoidla järjestab võtmed kasvavas järjekorras, kasutades võrdlejat. Kui pole määratud oma, kasutatakse vaikimisi, mis järjestab need baitide kaupa leksikograafilises järjekorras.
Tehingud
Tehingute struktuur on detailne. , seetõttu kordaksin siin neid põhiomadusi lühidalt:
- Toetab kõiki põhijooni : aatomika, järjepidevus, isoleeritus ja usaldusväärsus. Pean märkima, et macOS-i ja iOS-i osas on durability puhul rike, mis on MDBX-is parandatud. Täiendava teabe leiate nende .
- Mitmeprotsessilisuse lähenemine on kirjeldatud skeemiga «üks kirjanik / mitu lugejat». Kirjanikud blokivad üksteist, kuid mitte lugejaid. Lugejad ei blokeeri ei kirjanikke ega teisi lugejaid.
- Toetab sisemist tehingute korrutamist.
- Toetab mitme versiooni kasutamist.
Mitme versiooni tugi LMDB-s on nii hea, et soovin seda teostuses demonstreerida. Allpool olevast koodist on näha, et iga tehing töötab just selle andmebaasi versiooniga, mis oli avamise hetkel aktuaalne, olles täielikult isoleeritud kõikidest järgnevates muudatustest. Andmehoidla initsialiseerimine ja testkirje lisamine ei paku midagi huvitavat, seega on need rituaalid jäetud spoilerisse.
Testkirje lisamine
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Avame 2 tehingut, millest igaüks vaatab
tutvustanud andmebaasi versiooni ühe kirje kohta.
mdb_txn_begin(env, NULL, 0, &txn1); // lugemiseks ja kirjutamiseks
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // ainult lugemiseks
// Esimese tehingu raames eemaldame andmebaasist olemasoleva kirje.
mdb_del(txn1, dbi, &key, NULL);
// Kinnitage eemaldamine.
mdb_txn_commit(txn1);
// Avame kolmanda tehingu, mis vaatab
eaktsialiseeritud andmebaasi versiooni, kus kirje on juba kadunud.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Veendume, et otsitud võtme alusel kirje ei eksisteeri enam.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Lõpetame tehingu.
mdb_txn_abort(txn3);
// Veendume, et teise tehingu raames, mis oli avatud kirje olemasolu ajal,
// on selle ikka veel võimalik leida võtme alusel.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Kontrollime, et võtme alusel on saadud mitte mingit prügi, vaid kehtivad andmed.
assert(*(int *)val.mv_data == 997);
// Lõpetame tehingu, mis töötas koos, kuigi aegunud, kuid järjekindla andmebaasiga.
mdb_txn_abort(txn2);Soovitan proovida sama trikki SQLite'iga ja vaadata, mis juhtub.
Mitmeversioonilisus toob iOS-arendaja ellu palju meeldivaid funktsioone. Selle omaduse abil on lihtne ja mugav reguleerida andmeallika (data source) värskenduse kiirus ekraanivormide jaoks, lähtudes kasutajakogemusest. Näiteks võivad Mail.ru pilve rakenduse funktsiooni alla laadida sisu süsteemi meediagalerii. Hea ühenduse korral suudab klient lisada serverisse mitu fotot sekundis. Kui pärast iga üleslaadimist ajak Aktualiseerida UICollectionView kasutaja pilves oleva meediakoguga, siis võib 60 fps ja sujuva kerimise selle protsessi ajal unustada. Peale sagedaste ekraani värskenduste ennetamiseks on vajalik mingil moel piirata andmete muutmise kiirus aluses UICollectionViewDataSource.
Kui andmebaas ei toeta multiversioonilisust ja võimaldab töötada ainult praeguse kehtiva olekuga, siis stabiilse ajas kinnitatud andmesnapshoti loomiseks tuleb see kopeerida kas mingisse in-memory andmestruktuuri või ajutisse tabelisse. Mõlemad lähenemised on väga kulukad. In-memory ladustamise puhul toovad kaasa kulud nii mälus, mis on seotud konstrueritud objektide salvestamisega, kui ka ajaga, mis on seotud liialdustega ORM-i teisendustes. Mis puudutab ajutist tabelit, siis see on veelgi kallim lahendus, millel on mõtet ainult keerukates juhtumites.
LMDB multiversioonilisus lahendab stabiilse andmeallika säilitamise ülesande väga elegantset. Piisab lihtsalt tehingu avamisest ja voilà — seni, kuni me selle lõpetame, on andmehulk meil garanteeritult fikseeritud. Ajakohastamise kiirus on nüüd täielikult ja täielikult esituskihtide kätes, ilma oluliste ressursside kulu.
Kursorid
Kursorid pakuvad mehhanismi paari võtme-väärtuse järkjärguliseks iteratsiooniks B-puu kaudu. Ilma nendeta oleks andmebaasi tabelite tõhus modelleerimine enne seisukohta võimatu.
4.2. Tabelite modelleerimine
Võtmete järjekorrastatuse omadus võimaldab luua kõrgema taseme konstruktsioone, nagu tabel, baaspõhimõtete peale. Vaatame seda protsessi pilku alla peamise tabeli näitel, kus on vahemälus kogu kasutaja failide ja kaustade teave.
Tabeli skeem
Üks levinumaid stsenaariume, mille jaoks peab kaustade puu struktuur olema kohandatud – on kõikide elementide valimine, mis asuvad antud kataloogis. Hea andmete organiseerimise mudel, mis sobib selliste tõhusate päringute jaoks, on . Selle teostamiseks tuleb key-value salvestuses korraldada failide ja kaustade võtmed nii, et need grupeeritakse vastavalt vanemkausta kuuluvusele. Lisaks, et kuvada kausta sisu Windowsi kasutaja jaoks tuttaval kujul (esiteks kaustad, seejärel failid, ning mõlemad sorteeritakse tähestiku järjekorras), tuleb võtmesse lisada vastavad täiendavad väljad.
Alloleval pildil on näidatud, kuidas ülesande põhjal võiks võtmete esitus välja näha baitide massiivina. Alustatakse, paigutades baitidega vanemkausta identifikaatori (punased), seejärel – tüübiga (rohelised) ja lõpuks – nimega (sinised). Kui need on LMDB vaikimisi võrdlejaga leksikograafilises järjekorras sorteeritud, siis korraldatakse need nõutud viisil. Järjestikune võtmete läbimine sama punase prefiksiga annab meile nendega seotud väärtused sellises järjestuses, nagu need peavad olema esitatud kasutajaliideses (paremal), ilma et oleks vaja mingit täiendavat järeltöötlemist.

Võtmete ja väärtuste serialiseerimine
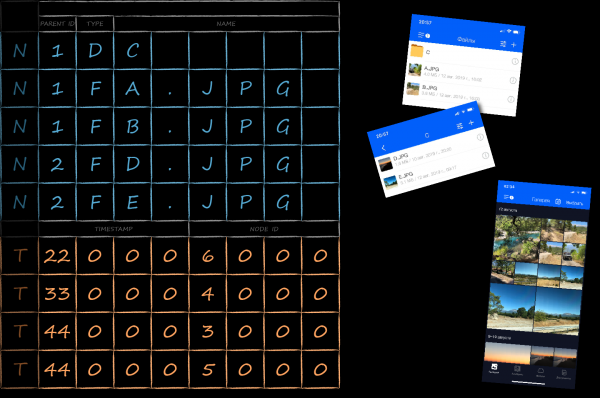
Maailmas on välja mõeldud palju meetodeid objektide serialiseerimiseks. Kuna meie ainus nõue oli kiirus, valisime enda jaoks kõige kiirema võimaliku — C keele struktuuri instantsi mäludumpi. Nii saab kataloogelementi näidata järgmise struktuuriga. NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Säilitamiseks NodeKey salvestusruumis tuleb objektis MDB_val andmete aadress suunata struktuuri algusesse ja nende suurus arvutada funktsiooniga sizeof.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}Esimeses peatükis andmebaasi valimise kriteeriumide kohta mainisin olulise tegurina dünaamiliste allokatsioonide minimeerimist CRUD operatsioonide raames. Funktsiooni kood serialize näitab, kuidas LMDB puhul on võimalik uute kirjeid andmebaasi lisamisel täielikult vältida. Serverilt saabunud baitide massiiv transformeeritakse esmalt virnstruktuurideks ning seejärel talletatakse need triviaalsetena ladustamisse. Arvestades, et LMDB-s ei ole ka dünaamilisi allokatsioone, võib saada fantastilise olukorra iOS-i mõõtmete järgi — töötada andmetega kogu nende teekonnal veebist kettale ainult virna mälu!
võtmete järjestamine binaarse võrreldava meetodiga
Võtmete järjestusesuhte määrab spetsiaalne funktsioon, mida nimetatakse võrreldavaks. Kuna mootor ei tea midagi nende sees olevate baitide semantika kohta, ei jää vaikimisi võrreldavale midagi muud, kui sorteerida võtmed leksikograafilises järjekorras, tuginedes nende baitide võrdlemisele. Selle kasutamine struktuuride järjestamiseks on sarnane lõhe pööramisega. Siiski, lihtsate juhtumite puhul pean ma seda meetodit vastuvõetavaks. Alternatiiv on kirjeldatud allpool, ja siin toon välja paar komistamist antud teel.
Esimene asi, mida meeles pidada, on primitiivsete andmastatüüpide esitus mälus. Nii et kõigil Apple'i seadmetel hoitakse täisarvulisi muutujaid formaadis . See tähendab, et vähem oluline bait asub vasakul ning täisarve ei saa sorteerida nende baitide põhjaliste võrdlemisega. Näiteks katse teha seda numbrite komplektiga vahemikus 0 kuni 511 annab järgmise tulemuse.
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)Selle probleemi lahendamiseks peavad täisarvud olema salvestatud võtmesse sobivas formaadis baitide võrdlejale. Vajalikku teisendust aitavad täita funktsioonid perekonnast hton* (eriti htons näite kahe baitide numbrite jaoks).
Reastamine märkide esitamiseks programmeerimises on, nagu teatakse, terviklik . Kui stringide semantika ja mälus nende esitamiseks kasutatav kodeering eeldab, et iga sümbol võib sisaldada rohkem kui ühte bait, siis on mõistlik loobuda defolti võrdlejast.
Teine asi, mida meeles pidada — struktuuri väljade kompilaatorist. Nende tõttu võivad mälus väljade vahel tekkida tühjade väärtustega baitide korraldus, mis muidugi rikub baitide kaupa sorteerimist. Prügi kõrvaldamiseks tuleb kas deklareerida väljad rangelt kindlaksmääratud järjekorras, järgides joondamise reegleid, või kasutada struktuuri deklareerimisel atribuuti packed.
Võtmete järjestamine välist poolverifikaatori abil
Võtmete võrdlemise loogika võib osutuda liiga keeruliseks binaarsete võrdlejate jaoks. Üks paljusid põhjusi on tehnikaväljade olemasolu struktuuride sees. Illustreerin nende tekkimist tuttava direktori elemendi võtme näitel.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Hoolimata oma lihtsusest tarbib see enamikul juhtudel liiga palju mälu. Nimepuhver võtab 256 baiti, kuigi keskmiselt ei ületa failide ja kaustade nimed harva 20-30 tähemärki.
Üks standardmeetod kirje suuruse optimeerimiseks on selle 'lõikamine' vastavalt tegelikule suurusele. Selle põhiolemus seisneb selles, et kõik muutuva pikkusega väljade sisu salvestatakse struktuuri lõpus asuvasse puhverdatud mälu, samas kui nende pikkused salvestatakse eraldi muutujatesse. Selle lähenemise kohaselt võti NodeKey muudetakse järgmiselt.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Jätkates, serialiseerimisel määratakse andmete suuruseks mitte sizeof kogu struktuuri suurus, vaid kõikide fikseeritud pikkusega väljade suurus pluss reaalselt kasutatava osa puhvri suurus.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength,
.mv_data = (void *)key
};
}Tehtud refaktoreerimise tulemusena saime märgatava kokkuhoiu võtme ruumipaigutusest. Kuid tehnilise väljaga nameLength, ei sobi vaikimisi binaarne võrdleja enam võtmete võrdlemiseks. Kui me ei asenda seda oma funktsiooniga, on nime pikkus prioriteediks sorteerimisel rohkem kui nimi ise.
LMDB võimaldab igale andmebaasile määrata oma võtmete võrdlemise funktsiooni. See toimub funktsiooni abil mdb_set_compare täpselt enne avamist. Ilmselgetel põhjustel ei saa andmebaasi kogu elu jooksul muuta. Komparaator saab sisendiks kaks binaarfaili võtit ning väljastab võrdlustulemuse: väiksem (-1), suurem (1) või võrdsed (0). Pseudokood näeb välja järgnev: NodeKey nägema nii.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}Nii kaua, kui andmebaasis on kõik võtmed ühte tüüpi, on nende baitide esitluse sundimine rakendusstruktuuri võtme tüübiks seaduslik. Siin on üks nüanss, kuid sellest räägitakse allpool jaotises „Kirjete lugemine“.
Väärtuste serialiseerimine
LMDB salvestusvõtmete võrdlemine toimub väga intensiivselt. Nende omavaheline võrdlemine toimub igas rakendustegevuses ja kogu lahenduse jõudlus sõltub võrdleja kiirusest. Ideaalsetes tingimustes peaks vaikimisi binaarne võrdleja olema piisav, kuid kui tuleb kasutada oma lahendust, peaks võtmete deserialiseerimise protseduur olema võimalikult kiire.
Andmebaas ei huvita eriti väärtuse osa (value). Selle muutmine baitide esituses objektiks toimub ainult siis, kui rakenduskood seda vajab, näiteks ekraanil kuvamiseks. Kuna see juhtub suhteliselt harva, siis pole sellele protseduurile kiirusenõuded nii kriitilised ja selle rakenduses saame palju vabamalt orienteeruda mugavusele. Näiteks nende metaandmete serialiseerimiseks, mis puudutavad veel mittelaaditud faile, kasutame NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};Siiski on olukordi, kus jõudlus on endiselt tähtis. Näiteks, et säilitada meta teavet kasutaja pilvefailide struktuuri kohta, kasutame sama objekti mäludumpi. Üks väljakutse nende serialiseeritud esitluse genereerimisel on see, et kaustade elemendid mudeldatakse klasside hierarhiaga.
Selle rakendamiseks C keeles tõstetakse spetsiifilised laste väljad eraldi struktuuridesse ja nende seos põhiklassiga määratakse union tüübi kaudu. Aktiivne sisu ühenduses määratakse tehnilise atribuudi type kaudu.
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;Kirjete lisamine ja uuendamine
Serialiseeritud võti ja väärtus saab lisada salvestusse. Selleks kasutatakse funktsiooni mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);Konfiguratsiooni etapis on võimalik salvestamisele lubada või keelata mitu kirje, millel on sama võti. Kui võtmete dubleerimine on keelatud, siis kirje sisestamisel saab määrata, kas olemasolevat kirjet võib uuendada või mitte. Kui ülekatte tegemine võib toimuda ainult koodi vea tõttu, siis saab selle eest kaitsta, märkides lipu NOOVERWRITE.
Kirjade lugemine
Kirjade lugemiseks on LMDB-s ette nähtud funktsioon mdb_get. Kui võtme-väärtuse paar on varem salvestatud struktuurides, siis näeb see protseduur välja järgmiselt.
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}Esitatud loend näitab, kuidas struktuuride kaudu serialiseerimine võimaldab vabaneda dünaamilistest jaotustest mitte ainult kirjutamisel, vaid ka andmete lugemisel. Funktsioonist saadud mdb_get näidik viib otse sinna, kus andmebaas hoiab objekti baitide esindust virtuaalses mälus. Tegelikult on meil olemas peaaegu tasuta ORM, mis tagab väga kõrge andme lugemise kiiruse. Kuigi lähenemine on ilus, tuleb meeles pidada mitmeid kaasnevaid eripärasid.
- Readonly tehingu puhul jääb struktuuri- ja väärtuse näidik kehtivaks vaid kuni tehingu sulgemiseni. Nagu varasemalt mainitud, jäävad B-puu lehed, kus objekt asub, copy-on-write põhimõtte tõttu muutumatuks, kuni neid viidatakse vähemalt ühe tehingu kaudu. Samas, niipea kui viimane seotud tehing lõpeb, võivad lehed saada uute andmete jaoks uuesti kasutatud. Kui on vajalik, et objektid üle elaksid neid loonud tehingu, tuleb need siiski kopeerida.
- Readwrite tehingu puhul jääb struktuuri- ja väärtuse näidik kehtivaks vaid esimesse muudatuste proseduurini (andmete salvestamine või kustutamine).
- Kuigi struktuur
NodeValuesee also section «Order of keys with an external comparator», it can be accessed calmly through a pointer to its fields. Just be careful not to dereference it! - Under no circumstances should the structure be modified through the obtained pointer. All changes must be made only through the method
mdb_put. However, no matter how much you want to do this, it won't work, as the memory area where this structure is located is mapped in readonly mode. - Remapping the file into the process's address space to, for example, increase the maximum storage size using the function
mdb_env_set_map_sizecompletely invalidates all transactions and related entities in general and pointers to read objects in particular.
Finally, there's another feature so insidious that revealing its essence simply cannot fit into another point. In the chapter about B-trees, I provided a diagram of its pages in memory. It indicates that the address of the beginning of the buffer with serialized data can be completely arbitrary. Because of this, the pointer to them obtained in the structure MDB_val ja ja viidatud struktuuri osas ei ole see üldiselt joondatud. Samas nõuavad teatud kiibi arhitektuurid (iOS-i puhul on see armv7), et iga andmeaadress oleks masinasõna suuruse korrelatsioonis, ehk süsteemi bitisusega (armv7 puhul on see 32 bitti). Teisisõnu, selline operatsioon nagu *(int *foo)0x800002 neile on võrdne põgenemisega ja viib hukkamiseni otsusega EXC_ARM_DA_ALIGN. Sellisest kurvast saatusest pääsemiseks on kaks võimalust.
Esimene viis on eelnevalt andmete kopeerimine eelnevalt joondatud struktuuri. Näiteks peegeldub see järgmises kohandatud võrdlejas.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}Alternatiivne tee on eelnevalt teavitada kompilaatorit, et võtme ja väärtuse struktuurid võivad olla joondamata, kasutades atribuuti aligned(1). ARM-i puhul on sarnase efekti saavutamine võimalik ka packed atribuudi abil. Arvestades, et see toetab ka struktuuri kasutatava ruumi optimeerimist, paistab see viis mulle eelistatavam, kuigi see andmete juurdepääsu operatsioonide kallinemine.
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Vahemiku päringud
LMDB-s on määratud kursori abstraktsioon kirjekogumi itereerimiseks. Kuidas sellega töötada, käsitleme juba tuttava kasutaja pilve metaandmete tabeli näitel.
Failide loendi kuvamise raames tuleb leida kõik võtmed, millega on seotud tema alamfailid ja kaustad. Eelnevates alakapitlites oleme järjestanud võtmed NodeKey selliselt, et need oleksid kõigepealt järjestatud vanema kausta ID järgi. Seega tehniliselt on kausta sisu saamise ülesanne kursori seadmine soovitud prefiksiga võtmete rühma ülemisele piirile ja seejärel itereerimine alumise piirini.

Ülemise piiri leidmine on võimalik "otse" järjestikuse otsimisega. Selleks seadistatakse kursori algus kogu andmebaasi võtmete loendis ja seejärel suurendatakse seda, kuni selle all on võtme ID vanema kausta numbriga. Selle lähenemise kaks ilmsed puudust on:
- Otsingu lineaarne keerukus, kuigi on teada, et puudes ja eriti B-puudes saab seda teostada logaritmilise ajaga.
- Mõttetult laaditakse kõik otsitavale eelnevad lehed failist peamällu, mis on äärmiselt kallis.
Õnneks on API LMDB-s ette nähtud tõhus viis kursori algse positsioneeringu jaoks. Selleks tuleb luua selline võti, mille väärtus on ette teada, et olla väiksem või võrdne ülemise piiri võtmega. Näiteks kasutades ülemisel joonisel olevat loendit, saame teha sellise võtme, kus väli parentId on 2, ja kõik teised on täidetud nullidega. Selline osaliselt täidetud võti antakse funktsiooni mdb_cursor_get kutses, koos näidatud operatsiooniga MDB_SET_RANGE.
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);Kui võtmete ülemine piir on leitud, siis jätkame selle kaudu iteratsiooni, kuni kas seisame silmitsi teise võtmega parentId, või võtmed ei lõppe täielikult.
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// töötlemine...
} while (MDB_NOTFOUND != rc && // kontrolli tabeli lõppu
IsTargetKey(key)); // kontrolli võtme rühma lõppuHea uudis on see, et mdb_cursor_get iitriitimise käigus saame mitte ainult võtme, vaid ka väärtuse. Kui valikutingimuste täitmiseks on vajalik kontrollida ka записи value-osast, on need täiesti kergesti kätte saadavad ilma täiendavate pingutusteta.
4.3. Suhete modelleerimine tabelite vahel
Oleme selles etapis käsitlenud kõiki tahveldatud andmebaasi projekteerimise ja töötamise aspekte. Võib öelda, et tabel on sorteeritud rekordite kogum, mis koosneb sarnastest võtme-väärtuse paaridest. Kui kuvada võti ristkülikuna ja selle seotud väärtus parallelepipedina, saame visuaalse andmebaasi skeemi.
![]()
Kuid reaalses elus on harva võimalik nii vähese vaevaga läbi saada. Sageli on andmebaasis vaja, esiteks, mitut tabelit ja teiseks, teha valikuid järjestuses, mis erineb esmase võtme omast. Selle viimane jaotis on pühendatud nende loomisele ja omavahel sidumisele.
Indekseerimistabelid
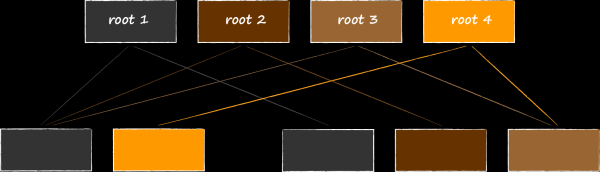
Pilve rakenduses on jaotis „Galerii“. Seal kuvatakse kogu pilve meedia sisu, sorteeritud kuupäeva järgi. Sellise valimise optimaalseks rakendamiseks tuleb põhitaabeli kõrvale luua veel üks uus võtmetüüp. Neis sisaldub faili loomise kuupäev, mis töötab esmase sorteerimiskriteeriumina. Kuna uued võtmed viitavad samadele andmetele nagu põhitaabeli võtmed, nimetatakse neid indeksvõtmeteks. Alloleval pildil on need esile tõstetud oranžiga.
Et eristada erinevate tabelite võtmeid ühes andmebaasis, on igale lisatud täiendav tehniline väli tableId. Kui ta teha sorteerimise kõige prioriteetsemaks, saame võtmed kõigepealt rühmitada tabelite kaupa ja juba tabelite sees oma reeglite kohaselt.
Indeksvõti viitab samadele andmetele nagu esmane. Selle omaduse otsekohene rakendamine, seostades selle esmase võtme value-osa koopiaga, ei ole mitmest aspektist vaadates üldse optimaalne:
- Ahnake ruumiga, kuna metadata võib olla üsna rikkalik.
- Töötamise seisukohalt, kuna sõlmede metaandmete uuendamisel tuleb kirjutada kahe võtme kaudu.
- Koodi toe seisukohalt, sest kui unustame andmete värskendamise ühe võtme osas, võib tekkida keeruline andmete järjepidevuse viga salvestuses.
Vaadakem edasi, kuidas neid puudusi kõrvaldada.
Tabelitevaheliste suhete korraldamine
Indekseeritud tabeli ja põhietabeli seostamiseks sobib hästi muster „võti väärtusena“. Nagu nimigi ütleb, on indeksikirje väärtusosana primaarse võtme koopia. See lähenemine kõrvaldab kõik eelnevalt loetletud puudused, mis on seotud primaarsete kirjade väärtuse koopia salvestamisega. Ainsaks puuduseks on see, et indekseeritud võtme väärtuse saamiseks on vaja teha kaks päringut andmebaasi ühe asemel. Skeemiliselt näeb saadud andmebaasi skeem välja järgmine.
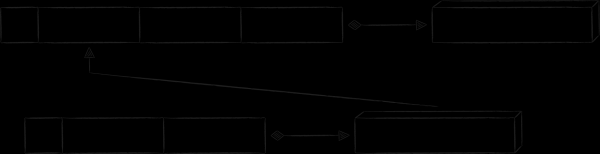
Teine muster tabelitevahelise seose korraldamiseks on „ülemäärane võti“. Selle eesmärk on lisada võtmesse täiendavaid atribuute, mis ei ole vajalikud sortimiseks, vaid seotud võtme rekonstrueerimiseks. Mail.ru pilves rakenduses on selle kasutamise kohta reaalsed näited, kuid sügava sukeldumise vältimiseks spetsiifiliste iOS-raamistike konteksti toome välja väljamõeldud, kuid seetõttu arusaadavama näite.
Pilves mobiilirakendustes on leht, kus kuvatakse kõik failid ja kaustad, millele kasutaja on teistele inimestele ligipääsu andnud. Kuna selliseid faile on üsna vähe, ja seotud teabe osas, mis puudutab avalikkust (kellele on ligipääs antud, milliste õigustega jne), on palju, pole mõistlik peamise tabeli väärtuste osa selle teabega üle koormata. Kuid kui soovitakse neid faile ilma internetita kuvada, siis tuleb neid siiski kusagile salvestada. Loomulik lahendus on selle jaoks eraldi tabeli loomine. Alloleval skeemil on selle võtmel eelprefiks «P», ning kohatäidet «propname» saab asendada konkreetsema väärtusega «avalik teave».
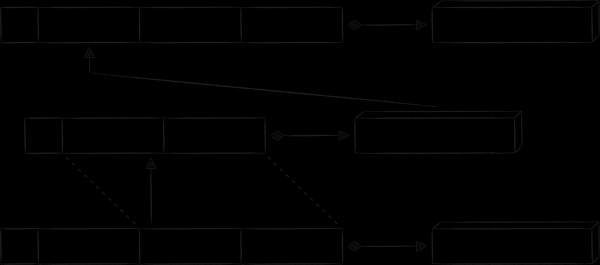
Kõik unikaalsed metaandmed, mille jaoks uus tabel loodi, kantakse kirje value-osasse. Samas ei soovi me duplikeerida neid faili- ja kaustandmeid, mis juba peamises tabelis on. Selle asemel lisatakse võtmesse „P“ liigselt andmeid väärtuste „node ID“ ja „timestamp“ näol. Nende abil on võimalik konstrueerida indeksivõti, mille alusel saada esmavõti ja lõpuks saada nodi metaandmed.
Kokkuvõte
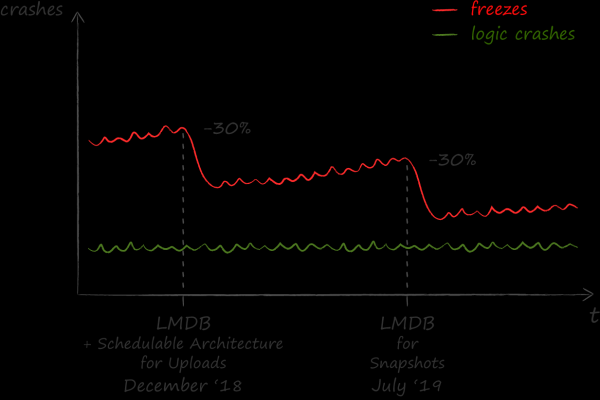
Hindame LMDB rakendamise tulemusi positiivselt. Pärast seda vähenes rakenduse peatuste arv 30%.
Tehtud töö tulemused on leidnud vastukaja ka väljaspool iOS-i meeskonda. Praeguseks on üks peamisi jaotisi „Failid“ Androidi rakenduses samuti üle läinud LMDB kasutamisele ning muud osad on tulekul. C-keel, milles key-value andmehoidjat rakendati, osutus heaks abiks, et algselt luua selle ümber rakenduslik kattekiht platvormideüleselt C++ keeles. Saadud C++ raamatukogude sujuvaks ühendamiseks platvormikoodiga Objective-C ja Kotlinis kasutati koodigeneraatorit. Dropboxilt, kuid see on juba hoopis teine lugu.
Allikas: habr.com
