

Berkeley Packet Filters (BPF) — on Linuxi tuumorihn, mis on mitu aastat järjest esinenud ingliskeelsete tehniliste väljaannete esikülgedel. Konverentsid on täis ettekandeid BPF-i kasutamisest ja arendamisest. David Miller, Linuxi võrgualaste alamsüsteemide hoidja, nimetab oma ettekannet Linux Plumbers 2018. (XDP – on üks BPF-i kasutamise variante). Brendan Gregg teeb ettekande pealkirjaga . Toke Høiland-Jørgensen , et see on nüüd microkernel. Thomas Graf propageerib ideed, et .
Habr.ee-le pole siiani BPF-i süsteemset kirjeldust, seetõttu püüan ma artiklite seerias rääkida tehnoloogia ajaloost, kirjeldada arhitektuuri ja arendusvahendeid, määratleda kasutusvaldkondi ja praktikad BPF-i kasutamisel. Selles, null-ses artiklis, käsitletakse klassikalise BPF-i ajalugu ja arhitektuuri, samuti paljastatakse seccomp'i tööpõhimõtted tcpdump, , ja palju muud., straceBPF-i arendust juhib Linuxi võrgu kogukond, ning peamised olemasolevad BPF-i rakendused on seotud võrguga ja seetõttu, @eucariot'i luba küsides, nimetasin seeriat "BPF kõige väiksematele" suurte seeriate auks.
Разработка BPF контролируется сетевым сообществом Linux, основные существующие применения BPF связаны с сетями и поэтому, с позволения , я назвал серию "BPF для самых маленьких", в честь великой серии .
Lühike BPF ajalugu (c)
Kaasaegne BPF tehnoloogia on täiustatud ja täiustatud versioon vana tehnoloogiast sama nimega, mida nimetatakse nüüd, et vältida segadust, klassikaliseks BPF-iks. Klassikalise BPF-i baasil on loodud tuntud tööriistad, tcpdumpmehanismid , ja palju muud., samuti vähem tuntud moodulid xt_bpf kuna iptables ja klassifitseerija cls_bpf. Kaasaegses Linuxis tõlgitakse klassikalised BPF programmid automaatselt uude vormi, kuid kasutajate vaatepunktist on API jäänud paika ja klassikalise BPF uued rakendused, nagu me näeme selles artiklis, on endiselt olemas. Just seetõttu, et jälgides klassikalise BPF-i arengulugu Linuxis, selgub, kuidas ja miks see on arenenud kaasaegsesse vormi, otsustasin alustada just klassikalisest BPF-ist.
1980. aastate lõpus hakkasid tuntud Lawrence Berkeley Laboratory insenerid uurima, kuidas õigesti filtreerida võrgu pakette tollase arvutitehnika jaoks. Filtreerimise põhikontseptsioon, mis sai alguse CSPF (CMU/Stanford Packet Filter) tehnoloogiast, seisnes selles, et liigseid pakette filtreeriti võimalikult varakult, st tuumaruumi tasandil, et vältida liigsete andmete kopeerimist kasutajaruumi. Käituse ohutuse tagamiseks, et kasutajakoodi saaks tuumaruumi käivitada, kasutati virtuaalmasinat — liivakasti.
Kuid olemasolevate filtrite virtuaalmasinad olid kavandatud tööks virnastusega arhitektuuriga masinatel ja uutel RISC masinatel ei töötanud need nii efektiivselt. Lõpuks Berkeley Labs'i inseneride jõupingutuste tulemusena töötati välja uus tehnoloogia BPF (Berkeley Packet Filters), mille virtuaalmasina arhitektuur oli projekteeritud Motorola 6502 protsessori põhjal — töö tegemiseks sellistes tuntud toodetes nagu või . Uus virtuaalne masin suurendas filtrite jõudlust kümneid kordi võrreldes olemasolevate lahendustega.
BPF masina arhitektuur
Käime läbi arhitektuuri tööstuslikult, analüüsides näiteid. Kuid kõigepealt ütleme, et masinal oli kaks kasutajale juurdepääsetavat 32-bitist registrit, akumulaaror A ja indeksregister X, 64 baiti mälu (16 sõna), mis oli kirjutamiseks ja lugemiseks saadaval, ning väike käskude süsteem nende objektidega töötamiseks. Programmid sisaldasid ka hüpikdirektiive tingimuslike avalduste rakendamiseks, kuid programmid pidid lõpetama töö õigeaegselt, seega oli ainult edasi liikumine lubatud, st tsüklite loomine oli rangelt keelatud.
Üldine masina käivitamise skeem on järgmine. Kasutaja loob BPF arhitektuuri jaoks programmi ja mingi mehhanismi kernel (näiteks süsteemikõne) abil laadib ja ühendab programmi mingi какому-то sündmuste generaator tuumas (näiteks sündmus on uue paketi saabumine võrguadapterisse). Sündmuse tekkimisel käivitab tuum programmi (näiteks tõlgendis), samal ajal kui masina mälu vastab какому-то tuuma mälu piirkonnale (näiteks saabunud paketi andmetele).
Ülaltoodust piisab, et alustada näidete käsitlemist: tutvume süsteemi ja käskude vorminguga vastavalt vajadusele. Kui aga soovite kohe uurida virtuaalmasina käsusüsteemi ja teada kõiki selle võimalusi, siis saate lugeda originaalartiklit ja/või faili esimest poolt tuuma dokumentatsioonist. Lisaks sellele võite tutvuda esitusega , kus McCanne, üks BPF autoritest, räägib loomise ajaloost libpcap.
Me liigume edasi, et käsitleda kõiki olulisi klassikalise BPF rakendamise näiteid Linuxis: tcpdump (libpcap), seccomp, xt_bpf, cls_bpf.
tcpdump
BPF arendamine toimus paralleelselt pakettide filtreerimise frontendi, üldiselt tuntud utiliidi, väljatöötamisega. tcpdump. Kuna see on kõige vanem ja kõige tuntum klassikalise BPF kasutamise näide, mis on saadaval mitmetes operatsioonisüsteemides, alustame tehnoloogia õppimist just selle pealt.
(Kõik näited käivitasin ma Linuxis 5.6.0-rc6. Mõnede käskude väljund on suurema loetavuse tagamiseks muudetud.)
Näide: vaatleme IPv6 pakette
Kujutame ette, et soovime jälgida kõiki IPv6 pakette liidesel eth0. Selleks võime käivitada programmi tcpdump lihtsa filtriga ip6:
$ sudo tcpdump -i eth0 ip6Samal ajal tcpdump kompileerib filtri ip6 BPF arhitektuuri baitkoodiks ja saadab selle kärku (vaata lisainfot jaotisest ). Laaditud filtrit käitatakse iga paketi puhul, mis liigub läbi liidese eth0. Kui filter tagastab mittetühja väärtuse n, siis n paketi baitide koopia kopeeritakse kasutajaruumi ja näeme seda väljundis. tcpdump.
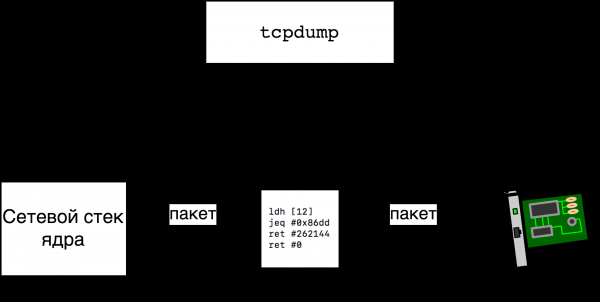
Selgub, et me saame hõlpsasti teada, millist baitkoodi me kärku saatsime tcpdump kasutades iseennast tcpdump, kui käivitame selle valikuga -d:
$ sudo tcpdump -i eth0 -d ip6
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 3
(002) ret #262144
(003) ret #0Esimeses reas käivitame käsu ldh [12], mis tõlgitakse kui „laadi registrisse“ A pool-sõnad (16 bitti) asuvad aadressil 12» ja ainus küsimus on, millist mälu me aadresseerime? Vastus on see, et aadressil x alustab (x+1)-ndat baiti analüüsitavas võrgu paketis. Loeme pakette Etherneti liidesest eth0, ja see on , mis pakett välja näeb (lihtsuse huvides oletame, et paketis ei ole VLAN silte):
6 6 2
|Siht MAC|Allika MAC|Ether Type|...|Seega, pärast käsu täitmist ldh [12] registreerimisel A on väli Ether Type — edastatava Ethernet-raami paketi tüüp. Real 1 võrreldakse registri sisu A (paketi tüüp) c 0x86dd, ja see on meid huvitav tüüpi IPv6. Reas 1, lisaks võrdlus käsule, on veel kaks veergu — jt 2 ja jf 3 — märgid, kuhu minna, kui võrdlus on edukas (A == 0x86dd) ja ebaõnnestub. Nii et, edukal juhul (IPv6) liikume reale 2, ja ebaõnnestumisel — reale 3. Reas 3 lõpetatakse programm koodiga 0 (ärge kopeerige paketti), reaas 2 lõpetatakse programm koodiga 262144 (kopeerige mulle maksimaalselt 256 kilobaiti paketti).
Veidi keerukam näide: vaatame TCP pakette sihtporti
Vaadake, kuidas töötab filter, mis kopeerib kõik TCP paketid sihtportiga 666. Keskendume IPv4 puhul, kuna IPv6 on lihtsam. Pärast seda näidet võite harjutuseks ise uurida filterit IPv6 jaoks (ip6 and tcp dst port 666) ja filtri üldiseks juhtumiks (tcp dst port 666). Seega näeb meid huvitav filter välja järgmine:
$ sudo tcpdump -i eth0 -d ip and tcp dst port 666
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 10
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 10
(004) ldh [20]
(005) jset #0x1fff jt 10 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 16]
(008) jeq #0x29a jt 9 jf 10
(009) ret #262144
(010) ret #0Ridade 0 ja 1 kohta teame me juba. Reas 2 oleme juba kontrollinud, et tegemist on IPv4 paketiga (Ether Type = 0x800) ja laadime registrisse A paketi 24. bait. Meie pakett näeb välja nagu
14 8 1 1
|ethernet header|ip fields|ttl|protocol|...mis tähendab, et laadime registrisse A IP pealkirja Protocol välja, mis on loogiline, kuna soovime kopeerida ainult TCP pakette. Võrdleme Protocol'i 0x6 () reas 3.
Ridades 4 ja 5 laadime poole sõna, mis asub aadressil 20, ja kasutame käsku jset kontrollime, kas üks kolmest on seatud — antud maskis jset kolm kõrgeimat bitti on puhastatud. Kaks bitti kolmest ütlevad meile, kas pakk on fragmentiseeritud IP-paketi osa ja kui jah, siis kas see on viimane fragment. Kolmas bitt on reserveeritud ja peab olema null. Me ei soovi kontrollida ei mitteotsi ega rikutud pakette, seega kontrollime kõiki kolme bitti.
Rida 6 on kõige huvitavam selles loendis. Väljend ldxb 4*([14]&0xf) tähendab, et laadime registrisse X nelja madalaima bitti viieteistkümnendast baitist pakett, korrutatud 4-ga. Neli madalaimat bitti viieteistkümnendast baitist on väli IPv4 päises, kus hoitakse päise pikkust sõnades, seega tuleb korrutada 4-ga. Huvi pakub, et väljend 4*([14]&0xf) on erilise adresseerimise skeemi märgistus, mida saab kasutada ainult sellisel kujul ja ainult registri jaoks X, st me ei saa öelda ei ldb 4*([14]&0xf) ei ldxb 5*([14]&0xf) (saame vaid määrata teise nihke, näiteks ldxb 4*([16]&0xf)). Selge on, et see adresseerimise skeem lisati BPF-s täpselt selleks, et saada X (indeksiregister) IPv4 päise pikkust.
Seega, real 7 püüame laadida poole sõna aadressilt (X+16). Meenutades, et Etherneti päis võtab 14 baiti, ja X SEE sisaldab IPv4 päise pikkust, mõistame, et A laetakse TCP sihtport:
14 X 2 2
|ethernet päis|ip päis|allikas|sihtport|Lõpuks, real 8 võrdleme sihtporti otsitava väärtusega ning ridadel 9 või 10 tagastame tulemuse — kas koopida paketti või mitte.
Tcpdump: laadimine
Eelnevatel näidetel ei peatunud me põhjalikult sellel, kuidas me laadime BPF baitkoodi tuuma pakettide filtreerimiseks. Üldiselt, tcpdump on portitud paljudele süsteemidele ja tööks filtritega kasutab raamatukogu . Lühidalt, et rakendada filtrit liidese kaudu, libpcap, peate tegema järgmist:
- looma tüüpi deskriptor
pcap_tliidese nime põhjal: , - aktiveerima liidese: ,
- filtri kompileerimiseks: ,
- filtri ühendamiseks: .
Kuna soovime näha, kuidas funktsioon pcap_setfilter on Linuxis rakendatud, kasutame strace (mõned read on eemaldatud):
$ sudo strace -f -e trace=%network tcpdump -p -i eth0 ip
socket(AF_PACKET, SOCK_RAW, 768) = 3
bind(3, {sa_family=AF_PACKET, sll_protocol=htons(ETH_P_ALL), sll_ifindex=if_nametoindex("eth0"), sll_hatype=ARPHRD_NETROM, sll_pkttype=PACKET_HOST, sll_halen=0}, 20) = 0
setsockopt(3, SOL_SOCKET, SO_ATTACH_FILTER, {len=4, filter=0xb00bb00bb00b}, 16) = 0
...Esimese kahe rea väljundis loome kõigi Etherneti raamide lugemiseks ja seome selle eth0. Shotcutist on esile tõstetav mitme takistusega redigeerimisvõime, mis võimaldab koostada videoid fragmentidest erinevates algvormingutes, ilma nende eelneva sissetoomise või ümberkodeerimiseta. On olemas sisseehitatud vahendid ekraanikaamerate loomiseks, pilditöötluseks veebikaamerast ja voogedastuse video vastuvõtmiseks. Kasutajaliidese loomiseks kasutatakse Qt5. Kood me teame, et filter ip koosneb neljast BPF käsklusest, ja kolmandal real näeme, kuidas kasutades valikut süsteemikõne setsockopt laadime ja ühendame 4-pikuse filtri. See on meie filter.
Tasub märkida, et klassikalises BPF-s toimub filtri laadimine ja ühendamine alati aatomaarse tehinguna, samas kui uue BPF versioonis on programmi laadimine ja selle sidumine sündmuste generaatoriga ajaliselt eraldi.
Peidetud tõde
Veidi täielikum väljund näeb välja nii:
$ sudo strace -f -e trace=%network tcpdump -p -i eth0 ip
socket(AF_PACKET, SOCK_RAW, 768) = 3
bind(3, {sa_family=AF_PACKET, sll_protocol=htons(ETH_P_ALL), sll_ifindex=if_nametoindex("eth0"), sll_hatype=ARPHRD_NETROM, sll_pkttype=PACKET_HOST, sll_halen=0}, 20) = 0
setsockopt(3, SOL_SOCKET, SO_ATTACH_FILTER, {len=1, filter=0xbeefbeefbeef}, 16) = 0
recvfrom(3, 0x7ffcad394257, 1, MSG_TRUNC, NULL, NULL) = -1 EAGAIN (Ressurss on ajutiselt saadaval)
setsockopt(3, SOL_SOCKET, SO_ATTACH_FILTER, {len=4, filter=0xb00bb00bb00b}, 16) = 0
...Nagu eelpool toodud, laadime ja ühendame meie filtri soketiga real 5, kuid mis toimub ridades 3 ja 4? Tundub, et see libpcap hooldus meie jaoks — et meie filtri väljundisse ei satu paketid, mis ei vasta standarditele, raamatukogu vale filter ret #0 (langetada kõik paketid), üle viib soketi mitte-blokeerivasse režiimi ja püüab lugeda kõik paketid, mis võisid jääda eelmistelt filtritelt.
Kokkuvõttes, et filtreerida pakette Linuxis klassikalise BPF abil, peab olema filter struktuuri tüübina struct sock_fprog ja avatud soket, seejärel saab filtri soketiga ühendada süsteemikutsungi abil setsockopt.
Huvitav on see, et filtri saab ühendada igasuguste soketitega, mitte ainult toorega. Siin on programm, mis kärbib kõik välja, peale kahe esimese baidi kõigist sissetulevatest UDP datagrammidest. (Kommentaarid on koodis lisatud, et artiklit mitte üle koormata.)
Rohkem kasutamise kohta setsockopt filtrite ühendamiseks vt , ja oma filtrite kirjutamise kohta struct sock_fprog ilma abita tcpdump räägime peatükis .
Klassikaline BPF ja XXI sajand
BPF lisati Linuxisse 1997. aastal ja püsis kaua tööhobuse rollis libpcap ilma eriliste muudatusteta (Linuxi-spetsiifilised muudatused muidugi, , но они не меняли глобальной картины). Первые серьезные признаки того, что BPF будет эволюционировать появились в 2011 году, когда Eric Dumazet предложил , добавляющий в ядро Just In Time Compiler — транслятор для перевода байткода BPF в нативный x86_64 код.
JIT compiler был первым в цепочке изменений: в 2012 году возможность писать фильтры для , используя BPF, в январе 2013 был mooduli xt_bpf, позволяющий писать правила для iptables при помощи BPF, а в октябре 2013 был еще и модуль cls_bpf, позволяющий писать при помощи BPF классификаторы трафика.
Мы скоро рассмотрим все эти примеры подробнее, однако сначала нам будет полезно научиться писать и компилировать произвольные программы для BPF, так как возможности, предоставляемые библиотекой libpcap ограничены (простой пример: фильтр, сгенерированный libpcap может вернуть только два значения — 0 или 0x40000) или вообще, как в случае seccomp, неприменимы.
Programmeerime BPF oma kätega
Познакомимся с бинарным форматом инструкций BPF, он очень простой:
16 8 8 32
| code | jt | jf | k |Каждая инструкция занимает 64 бита, в которых первые 16 бит — это код команды, потом идут два восьмибитных отступа, jt ja jf, и 32 бита для аргумента K, mille tähenduses, mis muutub meeskonnast meeskonda. Näiteks meeskond ret, mis lõpetab programmi töö, on koodiga 6, ja tagastatav väärtus saadakse konstantidest K. Keeles C esindab üks BPF käsk struktuuri
struct sock_filter {
__u16 code;
__u8 jt;
__u8 jf;
__u32 k;
}ja terve programm — struktuuri
struct sock_fprog {
unsigned short len;
struct sock_filter *filter;
}Nii saame juba kirjutada programme (käskude koodid, oletame, et teame neid ). Nii näeb filter välja ip6 kohast :
struct sock_filter code[] = {
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 1, 0x000086dd },
{ 0x06, 0, 0, 0x00040000 },
{ 0x06, 0, 0, 0x00000000 },
};
struct sock_fprog prog = {
.len = ARRAY_SIZE(code),
.filter = code,
};Programm prog saame seaduslikult kasutada kõnes
setsockopt(sk, SOL_SOCKET, SO_ATTACH_FILTER, &prog, sizeof(prog))Programmide kirjutamine masinkoodidena ei ole eriti mugav, kuid mõnikord on see vajalik (näiteks silumiseks, üksuse testide loomiseks, artiklite kirjutamiseks Habr'is jne). Mugavuse nimel failis <linux/filter.h> defineeritakse abimakrod — sama näidet, nagu eespool, saaks ümber kirjutada järgmiselt
struct sock_filter code[] = {
BPF_STMT(BPF_LD|BPF_H|BPF_ABS, 12),
BPF_JUMP(BPF_JMP|BPF_JEQ|BPF_K, ETH_P_IPV6, 0, 1),
BPF_STMT(BPF_RET|BPF_K, 0x00040000),
BPF_STMT(BPF_RET|BPF_K, 0),
}Kuid selline variant ei ole kuigi mugav. Nii arvasid ka Linuxi tuuma programmeerijad ning selle tõttu on kataloogis tuumas saadaval assembler ja debuggeri klassikalise BPF-i jaoks.
Assembleerimiskeel on väga sarnane tõrkeväljastusele tcpdump, kuid lisaks saame määrata sümboolsed sildid. Näiteks siin on programm, mis blokeerib kõik paketid, välja arvatud TCP/IPv4:
$ cat /tmp/tcp-over-ipv4.bpf
ldh [12]
jne #0x800, drop
ldb [23]
jneq #6, drop
ret #-1
drop: ret #0Vaikimisi genereerib assembler koodi formaadis , ,..., meie TCP juhtumi jaoks on tulemus
$ tools/bpf/bpf_asm /tmp/tcp-over-ipv4.bpf
6,40 0 0 12,21 0 3 2048,48 0 0 23,21 0 1 6,6 0 0 4294967295,6 0 0 0,C programmeerijate mugavuse huvides saab kasutada teistsugust väljundformaati:
$ tools/bpf/bpf_asm -c /tmp/tcp-over-ipv4.bpf
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 3, 0x00000800 },
{ 0x30, 0, 0, 0x00000017 },
{ 0x15, 0, 1, 0x00000006 },
{ 0x06, 0, 0, 0xffffffff },
{ 0x06, 0, 0, 0000000000 },Seda teksti saab kopeerida struktuuri määratlemiseks, tüübi struct sock_filter, nagu me käesoleva peatüki alguses tegime.
Linuxi ja netsniff-ng laiendused
Lisaks standardsetele BPF juhistele, Linux ja tools/bpf/bpf_asm toetavad ja . Peamiselt teenivad juhised struktuuri väljadele juurdepääsu tagamiseks struct sk_buff, mis kirjeldab võrgupaketti kernelis. Kuid on ka abijuhiseid teist tüüpi, näiteks ldw cpu laeb registrisse A tuuma funktsiooni käivitamise tulemuse raw_smp_processor_id(). (Uues BPF versioonis on neid ebatavalisi laiendusi laiendatud, pakkudes programmidele kernel helpers pakettide andmete, struktuuride ja sündmuste genereerimise juurde pääsemiseks.) Siin on huvitav näide filtrist, kus kopeerime kasutaja ruumi ainult pakettide päised, kasutades laiendust poff, koormuse offset:
ld poff
ret aBPF laiendusi ei saa kasutada tcpdump, kuid see on hea põhjus tutvuda utiliitide paketiga , mis sisaldab muuhulgas ka arenenud programmi netsniff-ng, mis lisaks BPF kaudu filtreerimisele sisaldab ka tõhusat liiklusgeneraatorit, ja on keerukam, kui tools/bpf/bpf_asm, BPF assemblçisi nimega bpfc. Pakett sisaldab üsna põhjalikku dokumentatsiooni, vt ka viiteid artikli lõpus.
, ja palju muud.
Nii et, me oskame juba kirjutada BPF programme suvalise keerukusega ja oleme valmis vaatama uusi näiteid, millest esimene on tehnoloogia seccomp, mis võimaldab BPF filtrite abil hallata hulka ja argumentide kogumit süstemaatilistele kutsungitele, mis on saadaval antud protsessile ja tema järeltulijatele.
Esimene versioon seccomp'ist lisati kernelisse 2005. aastal ja ei olnud eriti populaarne, kuna pakkus vaid ühte võimalust — piirata hulka süstemaatilisi kutsungeid, mis on protsessile kättesaadavad, järgmiselt: read, write, exit ja sigreturn, ja protsess, mis rikkus reegleid, tapeti kasutades SIGKILL. Kuid 2012. aastal lisati seccomp'isse võimalus kasutada BPF filtreid, mis võimaldavad määrata hulga lubatud süstemaatilisi kutsungeid ja isegi kontrollida nende argumente. (Huvitav, et üks esimesi selle funktsionaalsuse kasutajaid oli Chrome, ja hetkel töötavad Chrome'i inimesed uue BPF versiooni põhjal mehhanismi KRSI, mis võimaldab kohandada Linuxi turvamooduleid.) Lingid täiendavale dokumentatsioonile leiate artikli lõpust.
Tasub märkida, et Habré on juba olnud artikleid seccomp'i kasutamise kohta, võib-olla soovib keegi neid lugeda enne (või selle asemel), kui liigub järgmiste alajaotuste juurde. Artiklis on toodud näited seccomp'i kasutamisest, nii 2007. aasta versioonide kui ka BPF-i kasutamise versioonide kohta (filtrid genereeritakse libseccomp'i abil), räägitakse seccomp'i seostest Dockeriga ja tuuakse välja palju kasulikke linke. Artiklis räägitakse muu hulgas sellest, kuidas lisada mustaid või valgeid loendeid süsteemi kutsungitele systemd'i halduses olevate deemonite jaoks.
Edasi vaatame, kuidas kirjutada ja laadida filtreid , ja palju muud. tavalise C keele ja libseccomp'i abil ning millised on iga variandi plussid ja miinused, ning lõpuks vaatame, kuidas seccomp'i kasutab programm strace.
Kirjutame ja laadime filtreid seccomp'i jaoks
Me juba oskame kirjutada BPF programme ja seega vaatame esmalt seccomp'i programmiliidest. Filtri saab seadistada protsessi tasemel, samal ajal kui kõik alamprotsessid pärivad piirangud. Seda tehakse süsteemi kutsungi abil :
seccomp(SECCOMP_SET_MODE_FILTER, flags, &filter)kus &filter — on viidatud juba tuntud struktuurile struct sock_fprog, st. BPF programmile.
Kuidas erinevad seccomp programmid sokettide programmiingest? Edastatav kontekst. Sokettide puhul edastati meile mälu piirkond, mis sisaldas paketti, kuid seccompi puhul edastatakse meile struktuur, mis näeb välja järgmine
struct seccomp_data {
int nr;
__u32 arch;
__u64 instruction_pointer;
__u64 args[6];
};Siit nr — see on käivitatava süsteemi kutse number, arch — praegune arhitektuur (sellest allpool), args — kuni kuus süsteemi kutse argumenti, ja instruction_pointer — see on viidatud juhisele kasutajaruumi, mis tegi antud süsteemikutsumise. Seega, näiteks, et laadida süsteemikutsumise number registrisse A peame ütlema
ldw [0]Seccomp programmide puhul on veel muid omadusi, näiteks on juurdepääs kontekstile võimalik ainult 32-bitise ühtluse järgi ning ei saa laadida pool-sõna ega baiti — kui üritate laadida filtrit ldh [0] süsteemikutsumine , ja palju muud. tagastab EINVAL. Laetavate filtrite kontrolli teostab funktsioon tuumad. (Naljakas on see, et algses kommitees, mis lisas seccomp'i funktsionaalsuse, unustati see käsklus lubada lisada. mod (jääk) ja nüüd pole see seccomp BPF programmidele kätte saadav, kuna selle lisamine ABI.)
Põhimõtteliselt teame me juba kõike, et kirjutada ja lugeda seccomp programme. Tavaliselt on programmi loogika üles ehitatud nagu valge või must nimekiri süsteemi kutsest, näiteks programm
ld [0]
jeq #304, bad
jeq #176, bad
jeq #239, bad
jeq #279, bad
good: ret #0x7fff0000 /* SECCOMP_RET_ALLOW */
bad: ret #0kontrollib musta nimekirja neljast süsteemi kutsest numbritega 304, 176, 239, 279. Mis need süsteemi kutsed on? Me ei saa öelda täpselt, kuna me ei tea, millise arhitektuuri jaoks programm kirjutati. Seega seccomp autorid peavad kõiki programme alustama arhitektuuri kontrollimisega (praegune arhitektuur on kontekstis määratletud kui väli arch struktuurid struct seccomp_data). Arhitektuuri kontrollimisega näeks näide välja nagu:
ld [4]
jne #0xc000003e, bad_arch ; SCMP_ARCH_X86_64ja siis oleksid meie süsteemi kutsed kindlate väärtustega.
Kirjutame ja laadime seccomp filtreid kasutades. libseccomp'i abil
Masinkoodide või BPF assembleri filtrite kirjutamine võimaldab saavutada täielikku kontrolli tulemuste üle, kuid vahel on eelistatum omada ülekantavat ja/või loetavat koodi. Siin tuleb appi raamatukogu , mis pakub standardset liidest mustade või valge filtrite kirjutamiseks.
Võtame näiteks, et kirjutame programmi, mis käivitab binaarfaili, valides kasutaja, eelnevalt seadistades süsteemikutsungite musta nimekirja (programm on lihtsustatud suurema loetavuse huvides, täieliku variandi leiate ):
#include <seccomp.h>
#include <unistd.h>
#include <err.h>
static int sys_numbers[] = {
__NR_mount,
__NR_umount2,
// ... еще 40 системных вызовов ...
__NR_vmsplice,
__NR_perf_event_open,
};
int main(int argc, char **argv)
{
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_ALLOW);
for (size_t i = 0; i < sizeof(sys_numbers)/sizeof(sys_numbers[0]); i++)
seccomp_rule_add(ctx, SCMP_ACT_TRAP, sys_numbers[i], 0);
seccomp_load(ctx);
execvp(argv[1], &argv[1]);
err(1, "execlp: %s", argv[1]);
}Alustuseks määrame massiivi sys_numbers üle 40 süsteemikutsungi numbriga, mida blokeerida. Seejärel initsialiseerime konteksti ctx ja ütleme raamatukogule, et tahame lubada (SCMP_ACT_ALLOW) kõik süsteemikutsungid vaikimisi (mustade nimekirjade koostamine on lihtsam). Seejärel lisame, üks haaval, kõik mustade nimekirja süsteemikutsungid. Vastusena loetletud süsteemikutsungile küsime SCMP_ACT_TRAP, sel juhul saadab seccomp protsessile signaali SIGSYS süsteemikõne, mis rikkus reegleid. Lõpuks laadime programmi tuumale läbi seccomp_load, mis kompileerib programmi ja seob selle protsessiga süsteemikõne abil seccomp(2).
Eduka kompileerimise jaoks peab programm olema seotud raamatukoguga libseccomp'i abil, näiteks:
cc -std=c17 -Wall -Wextra -c -o seccomp_lib.o seccomp_lib.c
cc -o seccomp_lib seccomp_lib.o -lseccompEdukate käivituste näide:
$ ./seccomp_lib echo ok
okBlokeeritud süsteemikõne näide:
$ sudo ./seccomp_lib mount -t bpf bpf /tmp
Halb süsteemikõneKasutame strace, et saada rohkem teavet:
$ sudo strace -e seccomp ./seccomp_lib mount -t bpf bpf /tmp
seccomp(SECCOMP_SET_MODE_FILTER, 0, {len=50, filter=0x55d8e78428e0}) = 0
--- SIGSYS {si_signo=SIGSYS, si_code=SYS_SECCOMP, si_call_addr=0xboobdeadbeef, si_syscall=__NR_mount, si_arch=AUDIT_ARCH_X86_64} ---
+++ SIGSYS tõttu tapetud (kernel dump) +++
Halb süsteemikõnemillest saame teada, et programm lõpetati keelatud süsteemikõne kasutamise tõttu mount(2).
Kokkuvõttes kirjutasime filtri läbi raamatukogu libseccomp'i abil, mahutades keerulise koodi nelja rida. Eespooltoodud näites, kui on palju süsteemikõnesid, võib täitmiskiirus märgatavalt väheneda, kuna kontrollimine on lihtsalt loend võrdlustest. Optimeerimise jaoks on hiljuti libseccompis , lisades filtri atribuutide toe SCMP_FLTATR_CTL_OPTIMIZE. Kui seate selle atribuudi väärtuseks 2, muutub filter binaarse otsingu programmiks.
Kui soovite näha, kuidas binaarse otsingu filtrid töötavad, vaadake , mis genereerib selliseid BPF-i assemblerprogramme süsteemikutsungite nimekirja põhjal, näiteks:
$ echo 1 3 6 8 13 | ./generate_bin_search_bpf.py
ld [0]
jeq #6, bad
jgt #6, check8
jeq #1, bad
jeq #3, bad
ret #0x7fff0000
check8:
jeq #8, bad
jeq #13, bad
ret #0x7fff0000
bad: ret #0Mitte midagi oluliselt kiiremat kirjutada ei õnnestu, kuna BPF-programmid ei saa haruteed teha (me ei saa näiteks teha, jmp A või jmp [label+X]) ja seetõttu on kõik harud staatilised.
seccomp ja strace
Kõik teavad utiliiti strace — asendamatu tööriist protsesside käitumise uurimisel Linuxis. Kuid paljud on ka teadlikud selle utiliidi kasutamisega. Asi on selles, et strace on teostatud ptrace(2), ja selles mehhanismis ei saa me määrata, millistel süsteemikutsungite kogumitel peame protsessi peatama, st näiteks käsud
$ time strace du /usr/share/ > /dev/null 2>&1
real 0m3.081s
user 0m0.531s
sys 0m2.073sja
$ time strace -e open du /usr/share/ >/dev/null 2>&1
real 0m2.404s
user 0m0.193s
sys 0m1.800stoimivad umbes sama aja jooksul, kuigi teisel juhul soovime jälgida ainult ühte süsteemikõnet.
Uus valik --seccomp-bpf, mis lisati strace versioonis 5.3, võimaldab oluliselt kiirendada protsessi ja ühe süsteemikõne jälgimise käivitusaeg on juba võrreldav tavalise käivitamise ajaga:
$ time strace --seccomp-bpf -e open du /usr/share/ >/dev/null 2>&1
real 0m0.148s
user 0m0.017s
sys 0m0.131s
$ time du /usr/share/ >/dev/null 2>&1
real 0m0.140s
user 0m0.024s
sys 0m0.116s(Siin on muidugi väike vale, et me ei jälgi selle käsu peamist süsteemikõnet. Kui me jälgiksime näiteks newfsstat, siis strace tõkestaks ta nii palju kui ka ilma --seccomp-bpf.)
Kuidas see valik töötab? Ilma selleta strace ühendab protsessi ja käivitab selle abil PTRACE_SYSCALL. Kui juhitav protsess käivitab (iga) süsteemikõne, antakse juhtimine strace, mis vaatab süsteemikõne argumendid üle ja käivitab selle abil PTRACE_SYSCALL. Mõne aja pärast lõpetab protsess süsteemikõne ja väljudes antakse juhtimine taas strace, mis vaatab tagastatavad väärtused üle ja käivitab protsessi abil PTRACE_SYSCALL, jne.

Seccomp'i abilitesega saame selle protsessi optimeerida just nii, nagu me soovime. Kui soovime keskenduda ainult süsteemikõnedele, X, saame kirjutada BPF filtri, mis X tagastab väärtuse SECCOMP_RET_TRACE, samas kui meile mittehuvitavad kõned — SECCOMP_RET_ALLOW:
ld [0]
jneq #X, ignore
trace: ret #0x7ff00000
ignore: ret #0x7fff0000Sel juhul strace käivitame protsessi esmalt kui PTRACE_CONT, iga süsteemikõne kohaselt töötab meie filter. Kui süsteemikõne ei X, siis protsess jätkab töötamist, kuid kui see on X, siis seccomp edastab kontrolli strace, mis vaatab argumentoone ja käivitab protsessi kui PTRACE_SYSCALL (kuna seccomp ei võimalda käivitada programmi süsteemikõne väljundist). Kui süsteemikõne naaseb, strace käivitab protsessi uuesti PTRACE_CONT ja ootab uusi sõnumeid seccompilt.

Valiku kasutamisel --seccomp-bpf on kaks piirangut. Esiteks, ei saa liituda juba olemasoleva protsessiga (valik -p programmede strace), kuna seda ei toeta seccomp. Teiseks, ei ole võimalik ei vaadata tütarprotsesse, kuna seccomp filtrid pärandatakse kõigile tütarprotsessidele, ilma võimaluseta see välja lülitada.
Veidi rohkem teavet selle kohta, kuidas strace töötleb , ja palju muud. saab teada . Meie jaoks on kõige huvitavam fakt see, et klassikaline BPF, esindatud seccomp'iga, leiab endiselt rakendamist.
xt_bpf
Mineme nüüd tagasi võrkude maailma.
Eellugu: ammu, 2007. aastal, lisati tuuma mooduli xt_u32 netfilter'ile. See kirjutati analoogia alusel veelgi vanema liikluse klassifikaatoriga cls_u32 ja võimaldas kirjutada mis tahes binaarseid reegleid iptables'i abil järgmiste lihtsate toimingute kaudu: laadida 32 bitti paketist ja teha nendega hulga aritmeetilisi operatsioone. Näiteks,
sudo iptables -A INPUT -m u32 --u32 "6&0xFF=1" -j LOG --log-prefix "seen-by-xt_u32"Laeb 32 bitti IP-peast, alustades nihkest 6, ja rakendab sellele maski 0xFF (võta madalam bait). See on IP-ape ja me võrreldame seda 1-ga (ICMP). Ühes reeglites saab kombineerida palju kontrolle ja samuti saab teha operaatori protocol — liikuda X bitti paremale. Näiteks, reegel @ iptables -m u32 --u32 "6&0xFF=0x6 && 0>>22&0x3C@4=0x29"
kontrollib, kas TCP järjestuse number. Ei hakka rohkem detailidesse minema, kuna on juba selge, et käsitsi selliseid reegleid kirjutada pole eriti mugav. Artiklis 0x29BPF — unustatud baitkood , on mitmeid linke, mis sisaldavad näiteid eeskirjade rakendamise ja genereerimise kohta, xt_u32. Vaata ka allolevaid linke artikli lõpus.
Alates 2013. aastast on mooduli asemel saadaval xt_u32 BPF-põhine moodul, xt_bpf. Kõigile, kes siiani on lugenud, peab olema selge selle tööpõhimõte: BPF-bytecode käivitamine iptables reeglite kujul. Uue reegli saab luua näiteks järgmiselt:
iptables -A INPUT -m bpf --bytecode -j LOGsiit <байткод> — see on assembleri väljundformaadis kood bpf_asm vaikesätetega, näiteks,
$ cat /tmp/test.bpf
ldb [9]
jneq #17, ignore
ret #1
ignore: ret #0
$ bpf_asm /tmp/test.bpf
4,48 0 0 9,21 0 1 17,6 0 0 1,6 0 0 0,
# iptables -A INPUT -m bpf --bytecode "$(bpf_asm /tmp/test.bpf)" -j LOGSelles näites filtreerime kõik UDP paketid. BPF programmi kontekst moodulis xt_bpf, näitab loomulikult paketi andmeid, iptables puhul IPv4 pealkirja algust. BPF-programmist tagastatav väärtus , kus false tähendab, et pakett ei ühti.
On selge, et moodul xt_bpf toetab keerukamaid filtreid kui eespool toodud näites. Vaatame tõelisi näiteid ettevõttelt Cloudflare. Veel hiljuti kasutasid nad moodulit xt_bpf DDoS rünnakute kaitsmiseks. Artiklis nad räägitakse, kuidas (ja miks) nad genereerivad BPF filtreid ja avaldavad linke tööriistade kogumile nende filtrite loomiseks. Näiteks tööriista abil bpfgen saab luua BPF programmi, mis matšib DNS-päringu nimega habr.com:
$ ./bpfgen --assembly dns -- habr.com
ldx 4*([0]&0xf)
ld #20
add x
tax
lb_0:
ld [x + 0]
jneq #0x04686162, lb_1
ld [x + 4]
jneq #0x7203636f, lb_1
ldh [x + 8]
jneq #0x6d00, lb_1
ret #65535
lb_1:
ret #0Programmis laadime me alguses registrisse X stringi alguspunkti aadressi x04habrx03comx00 UDP-datagrammi sees ja seejärel kontrollime päringut: 0x04686162 "x04hab" Kui kaua aega kulub väljastamiseks?
Veidi hiljem avaldas Cloudfare p0f kompilaatori koodi -> BPF. Artiklis räägitakse, mis on p0f ja kuidas p0f allkirju BPF-ks teisendada:
$ ./bpfgen p0f -- 4:64:0:0:*,0::ack+:0
39,0 0 0 0,48 0 0 8,37 35 0 64,37 0 34 29,48 0 0 0,
84 0 0 15,21 0 31 5,48 0 0 9,21 0 29 6,40 0 0 6,
...Praegu ei kasuta Cloudfare enam xt_bpf, kuna nad on üle kolinud XDP-le — üks võimalustest kasutada BPF uue versiooni, vt. .
cls_bpf
Viimane klassikalise BPF kasutamise näide tuumas on klassifikaator cls_bpf Linuxi liikluse kontrolli alamsüsteemis, mis lisati Linuxisse 2013. aasta lõpus ja asendas kontseptuaalselt vana cls_u32.
Me ei hakka praegu klassikalise BPF toimimist kirjeldama. cls_bpf, kuna selle klassikalise BPF ülevaade ei anna meile uusi teadmisi — oleme juba tutvunud kõigi funktsioonidega. Lisaks kohtame edasistes artiklites, mis räägivad Extended BPF-st, selle klassifikaatoriga veel korduvalt.
Veel üks põhjus, miks klassikalise BPF kasutamisest mitte rääkida, cls_bpf on see, et võrreldes Extended BPF-iga on selle kasutusala oluliselt kitsendatud: klassikalised programmid ei saa pakettide sisu muuta ega saa säilitada olekut kutsungite vahel.
Nii et on aeg klassikalisest BPF-ist lahkuda ja tulevikku vaatama.
Hüvasti klassikalise BPF-ga
Oleme vaadanud, kuidas BPF tehnoloogia, mille arendasid välja 90ndate alguses, on edukalt üle elanud veeranda sajandi ja leidnud uusi kasutusvõimalusi. Kuid just nagu siirdumine virnamasinatelt RISC-le, mis andis tõuke klassikalise BPF arendusele, toimus 2000ndatel üleminek 32-bitistelt 64-bitiste masinatele ning klassikaline BPF hakkas vananema. Peale selle on klassikalise BPF võimalused tugevalt piiratud: koos vananenud arhitektuuriga — meil puudub võimalus salvestada olekut BPF programmide vahel, puudub võimalus otse kasutajaga suhelda, ning meil puudub interaktsioon tuumaga, välja arvatud piiratud struktuuri väljade lugemine. sk_buff ja kõige lihtsamate abifunktsioonide käivitamine, ei saa pakettide sisu muuta ega neid suunata.
Tegelikult on tänapäeval klassikalisest BPF-st Linuxis jäänud vaid API-liides, samas kui kõik klassikalised programmid, olgu need siis sokli filtrid või seccomp filtrid, tõlgitakse automaatselt uude formaati, Extended BPF. (Me räägime, kuidas see täpselt toimub järgmisel artiklil.)
Uue arhitektuuri üleminek algas 2013. aastal, kui Aleksei Starovoitov pakkus välja BPF-i uuendamise skeemi. 2014. aastal alanud vastavad patchid kerneles. Nii palju, kui ma tean, oli algselt plaanis vaid arhitektuuri ja JIT-kompilaatori optimeerimine, et saavutada tõhusam töö 64-bitistes masinates, kuid selle asemel andsid need optimeerimised uue peatüki alguse Linuxi arenduses.
Edasi järgmistes artiklites selgitatakse uue tehnoloogia arhitektuuri ja rakendusi, mis algselt oli tuntud kui internal BPF, hiljem extended BPF ja nüüd lihtsalt BPF.
Lingid
- Steven McCanne ja Van Jacobson, "BSD Packet Filter: Uus arhitektuur kasutaja tasemel paketikaaperduseks",
https://www.tcpdump.org/papers/bpf-usenix93.pdf - Steven McCanne, "libpcap: Arhitektuuri ja optimeerimise metodologia paketikaaperduseks",
https://sharkfestus.wireshark.org/sharkfest.11/presentations/McCanne-Sharkfest'11_Keynote_Address.pdf tcpdump,libpcap:- .
- BPF — unustatud baitkood:
https://blog.cloudflare.com/bpf-the-forgotten-bytecode/ - BPF tööriista tutvustus:
https://blog.cloudflare.com/introducing-the-bpf-tools/ bpf_cls:http://man7.org/linux/man-pages/man8/tc-bpf.8.html- Seccomp ülevaade:
https://lwn.net/Articles/656307/ https://github.com/torvalds/linux/blob/master/Documentation/userspace-api/seccomp_filter.rst- Paul Chaignon, "strace —seccomp-bpf: pilk kapoti alla"
https://fosdem.org/2020/schedule/event/debugging_strace_bpf/ netsniff-ng:http://netsniff-ng.org/
Allikas: habr.com
