

Alguses oli tehnoloogia, mida nimeti BPF-iks. Olles vaadanud sellele , vanas testamendis, artiklis sellest tsüklist. 2013. aastal Aleksei Starovoitovi ja Daniel Borkmani jõupingutuste tulemusena töötati välja ja kaasati see Linuxi tuumasse täiustatud versioon, mis on optimeeritud kaasaegsetele 64-bitistele masinatele. See uus tehnoloogia kandis lühikest aega nime Internal BPF, hiljem nimetati see ümber Extended BPF-iks ning nüüd, paar aastat hiljem, kutsutakse seda lihtsalt BPF-iks.
Üldiselt võimaldab BPF käivitada kasutaja pakutavat suvalist koodi Linuxi tuumaruumi ning uus arhitektuur osutus sedavõrd edukaks, et meie jaoks on vajalik veel umbes tosin artiklit, et kirjeldada kõiki selle kasutusvõimalusi. (Ainus asi, millega arendajad hakkama ei saanud, nagu võite allolevalt pildilt näha, on korraliku logosuunuse loomine.)
Selles artiklis käsitletakse BPF virtuaalmasina ülesehitust, tuuma liideseid BPF-i töötlemiseks, arendustööriistu ning lühikest ülevaadet olemasolevatest omadustest, st kõike, mis on vajalik BPF-i praktiliste rakenduste süvitsi uurimiseks.
Artikli lühikokkuvõte
Alustuseks vaatame BPF arhitektuuri linnulennult ja määratleme peamised komponendid.
Nüüd, kui meil on üldine arusaam arhitektuurist, kirjeldame BPF virtuaalmasina ülesehitust.
Selles osas vaatame lähemalt BPF objektide — programmide ja kaartide — elutsüklit.
Olles omandanud mõningase arusaama süsteemist, vaatame lõpuks, kuidas luua ja hallata objekte kasutajakulust spetsiaalse süsteemikõne kaudu — bpf(2).
Programmi kirjutamine süsteemikutse kaudu on muidugi võimalik. Kuid see on keeruline. Reaalsetes stsenaariumites on tuumaprogrammeerijate poolt välja töötatud teek libbpf. Loome kõige lihtsama BPF rakenduse kontuur, mida kasutame järgmistes näidetes.
Siin õpime, kuidas BPF programmid saavad pöörduda tuuma abifunktsioonide poole — tööriist, mis koos kaardiga muudab uue BPF võimalused oluliselt suuremaks kui klassikaline.
Selleks ajaks teame piisavalt, et mõista, kuidas luua programme, mis kasutavad kaarte. Ja isegi piilume suuresse ja võimsasse valideerijasse.
Viidatud jaotis, kuidas koguda vajalikke utiliite ja tuuma katsetamiseks.
Artikli lõpus leiavad need, kes sinna jõuavad, motiveerivaid sõnu ja lühikese kirjelduse sellest, mis järgmistes artiklites olema hakkab. Loetleme ka mitmeid linke iseseisvaks uurimiseks neile, kellel ei ole soovi või võimalust jätku oodata.
BPF arhitektuuri sissejuhatus
Enne kui hakkame BPF arhitektuuri vaatama, viidame viimast korda (kas tõesti?) , mis loodi vastuseks RISC masinate tekkele ja lahendas pakettide tõhusat filtreerimist. Arhitektuur osutus nii õnnelikuks, et sündides pöörasesse üheksakümnendatesse Berkeley UNIXis, portiti see enamikule olemasolevatest operatsioonisüsteemidest, elas üle pöörased kahekümnendad ja leiab endiselt uusi rakendusi.
Uus BPF loodi vastuseks 64-bitiste masinate, pilveteenuste laialdasele levikule ja suurenenud vajadusele SDN tööriistade järele (Starkvaradefineddvõrgustiku n). Arendatud tuumavõrkude inseneride poolt klassikalise BPF täiendava asendusena, leidis uus BPF juba kuue kuu pärast rakendust Linuxi süsteemide jälgimisel, ja nüüd, kuus aastat pärast selle ilmumist, on meil vajalik kogu järgmine artikkel, et loetleda erinevad programmide tüübid.
VeSöLüE KaRtIinKi
BPF on peamiselt virtuaalne liivakast, mis võimaldab käivitada "suvalist" koodi tuuma ruumis ilma turvalisust ohustamata. BPF programmid luuakse kasutaja ruumis, laaditakse tuuma ja ühendatakse mõne sündmuse allikaga. Sündmus võib olla näiteks paketi vastuvõtmine võrguliidesele, tuuma mõne funktsiooni käivitamine jne. Paketi puhul on BPF programmile kergesti juurdepääsetavad paketi andmed ja metaandmed (lugemiseks ja võib-olla ka kirjutamiseks, sõltuvalt programmi tüübist), tuuma funktsiooni käivitamise korral — funktsiooni argumendid, sealhulgas viidatud tuuma mälu, jne.
Vaadakem seda protsessi lähemalt. Alustuseks räägime esimesest erinevusest klassikalisest BPF-st, mille programmid kirjutati assembleris. Uues versioonis on arhitektuurit täiendatud nii, et programme saab kirjutada kõrge taseme keeltes, eelkõige, muidugi, C keeles. Selle jaoks on loodud llvm-i tagumine osa, mis võimaldab genereerida baidikoodi BPF arhitektuuri jaoks.

BPF arhitektuur on loodud selleks, et toimida tõhusalt kaasaegsetes masinates. Selleks, et see praktikas töötaks, tõlgitakse BPF bait-kood, pärast laadimist kernelisse, koheselt masinakoodiks komponenti nimega JIT compiler.Just In Time). Kui meenutada, siis klassikalises BPF-s laaditi programm kernelisse ja kinnitati sündmuste allikale atomaarsetena — ühe süsteemikõne kontekstis. Uues arhitektuuris toimub see kaks etappi: esmalt laaditakse kood kernelisse süsteemikõne abil, bpf(2), ja seejärel, hiljem, teiste mehhanismide abil, mis erinevad sõltuvalt programmi tüübist, programm kinnitatakse (attaches) sündmuste allikale.
Siit võib lugejal tekkida küsimus: kas see oli tõesti võimalik? Kuidas tagatakse sellise koodi täitmise ohutus? Täitmise ohutust tagab BPF programmide laadimise etapp, mida nimetatakse verifikaatoriks (inglise keeles seda etappi nimetatakse verifier ja ma kasutan edaspidi ingliskeelset sõna):

Verifier — see staatiline analüsaator, mis tagab, et programm ei riku tuuma normaalset töövoogu. See ei tähenda, et programm ei saaks süsteemi sekkuda — BPF programmid, sõltuvalt tüübist, võivad lugeda ja kirjutada tuuma mälupiirkondi, muuta funktsioonide tagastatud väärtusi, kärpida, täiendada, kirjutada üle ja isegi suunata võrgupakette. Verifier tagab, et BPF programmi käivitamine ei kahanda tuuma ja et programm, millele reeglite kohaselt on kirjutamisõigus, näiteks väljuva paketi andmetele, ei saa kirjutada üle tuuma mälu paketi väliselt. Täpsemalt vaatame verifierit vastavas osas, pärast seda, kui oleme tutvunud kõikide teiste BPF komponentidega.
Nii et, mida me siiani õppinud oleme? Kasutaja kirjutab programmi C keeles ja laadib selle tuuma süsteemi kõne abil. bpf(2), kus see läbib verifitseerimise ja tõlgitakse natiivseks käskkoodiks. Seejärel ühendab sama või teine kasutaja programmi sündmuste allikaga ning see hakkab töötama. Laadimise ja ühendamise eraldamine on vajalik mitmel põhjusel. Esiteks, verifitseerimise käivitamine on suhteliselt kulukas ning kui me laadime sama programmi mitmeid kordi, raiskame me arvuti aega. Teiseks, programmide ühendamise viis sõltub nende tüübist ja üks 'ühtne' liides, mis loodi aasta tagasi, ei pruugi sobida uute programmide tüüpide jaoks. (Kuigi nüüd, kui arhitektuur muutub küpsemaks, on idee sellele liidesele ühtlustada selle tasemel libbpf.)
Hooliv lugeja võib märgata, et me ei ole veel piltidega lõpetanud. Tõepoolest, kõik eelnevalt öeldud ei selgita, kuidas BPF põhimõtteliselt muudab olukorda võrreldes klassikalise BPF-iga. Kaks uuendust, mis oluliselt laiendavad kasutusala, on jagatud mälu kasutamise võimalus ja kernel-probleemide abifunktsioonid (kernel helpers). BPF-is on jagatud mälu ellu viidud nn maps'i abil — jagatud andmestruktuurid, millel on kindel API. Nimi tuleneb ilmselt sellest, et esimene tüüpi map, mis ilmus, oli räsitabel. Hiljem ilmusid massiivid, kohalike (per-CPU) räsitabelite ja kohalike massiivide, otsingupuude, BPF-programmide viidete sisaldavad mappid ja palju muud. Meie jaoks on oluline asjaolu, et BPF-programmid saavad hoida olekut väljakutsete vahel ja jagada seda teiste programmide ja kasutajate ruumiga.
Maps'idele pääseb ligi kasutaja protsesside kaudu süsteemi kutse abil. bpf(2), ja BPF-programmid, mis töötavad tuumas — abifunktsioonide abil. Veelgi enam, abifunktsioonid ei eksisteeri ainult kaartide töötlemiseks, vaid ka teiste tuuma võimaluste kasutamiseks. Näiteks saavad BPF-programmid kasutada abifunktsioone pakettide suunamiseks teistele liidestele, perf-alamvõrgustiku sündmuste genereerimiseks, tuuma struktuuridele juurdepääsemiseks jne.

Kokkuvõttes pakub BPF võimalust laadida juhuslikku, st verifikaatoriga kontrollitud, kasutaja koodi tuuma ruumi. See kood võib säilitada oleku kutsungite vahel ja vahetada andmeid kasutajaruumiga, samuti on tal juurdepääs tuuma alamvõrgustikele, mis on antud tüüpi programmidele lubatud.
See juba sarnane funktsionaalsus on tuumamoodulite pakkumistega, mille suhtes BPF-l on teatud eelised (loomulikult saab võrrelda ainult sarnaseid rakendusi, näiteks süsteemi jälgimist — BPF-le ei saa kirjutada suvalist draiverit). Tasub välja tuua madalam sisenemisbarjäär (mõned BPF-i kasutavad utiliidid ei eelda, et kasutajal oleks tuuma programmeerimise oskusi, nagu ka üleüldiselt programmeerimisoskusi), käitusaegne turvalisus (kellel ei ole olnud probleeme süsteemi katkeid kirjutades või testides mooduleid, andke kommentaarides teada), aatomaarne — moodulite taaskäivitamisel on seisaku aeg, samas kui BPF-i alamsüsteem garanteerib, et ükski sündmus ei jää vahele (õigluse nimel, see ei kehti kõigi BPF-i programmi tüüpide kohta).
Selle võimaluse olemasolu teeb BPF-st universaalse tööriista tuuma laiendamiseks, nagu praktika kinnitab: järjest rohkem uusi programmiliike lisandub BPF-i, järjest rohkem suured ettevõtted kasutavad BPF-i tootmisserverites 24×7, ja järjest rohkem idufirmasid ehitab oma äri lahendustele, mille aluseks on BPF. BPF-i kasutatakse kõikjal: DDoS-rünnakute kaitses, SDN-i loomisel (näiteks Kubernetes'i võrke), peamise süsteemide jälgimise ja statistika kogumise tööriistana, sissetungi tuvastamise süsteemides ning liivakastisüsteemides jne.
Lõpetame sellel ülevaateosa artiklist ja vaatame virtuaalmasinat ja BPF-i ökosüsteemi lähemalt.
Käigult: utiliidid
Et saaksite järgmistes osades näiteid käitada, võib teil olla vaja mõningaid utiliite, vähemalt llvm/clang BPF-i toe ja bpftool. Jaotises saate lugeda utiliitide ja oma tuuma koostamise juhiseid. See jaotus on paigutatud madalamale, et mitte segada meie põhisisu esitlust.
BPF-i virtuaalmasina registrid ja käsusüsteem
BPF arhitektuur ja käskude süsteem on välja töötatud arvestades, et programmid luuakse C keeles ning laadimise järel tõlgitakse need natiivkoodiks. Seetõttu valiti registrite arv ja käskude hulk, lähtudes tänapäevaste masinate matemaatilisest võimekusest. Lisaks seati programmele mitmeid piiranguid, näiteks ei olnud pikka aega võimalik kirjutada tsükleid ja alamprogramme ning käsu arv oli piiratud 4096-ga (praegu saavad privileege omavad programmid laadida kuni miljon käsu).
BPF-s on üheteistkümme kasutajale kergesti kättesaadavat 64-bitist registrit. r0—r10 ja käsu loendur (program counter). Register r10 sisaldab viite virnale (frame pointer) ja on saadaval ainult lugemiseks. Programme täitmise ajal on juurdepääs 512-baidisele virnale ja piiramatule jagatud mälule kujul maps.
BPF programmidele on lubatud käivitada teatud programmiliigi põhjal abifunktsioonide komplekt (kernel helpers) ja, alates hiljutisest ajast, ka tavalisi funktsioone. Iga kutsutav funktsioon võib vastu võtta kuni viis argumenti, mis edastatakse registrites r1—r5, ja tagastatav väärtus edastatakse r0. Garantii on, et pärast funktsioonist naasmist registrite sisu r6—r9 ei muutu.
Tõhusaks programmide tõlkimiseks registrid r0—r11 kõigis toetatud arhitektuurides vastavad selgelt tegelikele registritele, arvestades praeguse arhitektuuri ABI eripära. Näiteks x86_64 registrid r1—r5, mida kasutatakse funktsioonide argumentide edastamiseks, vastavad registritele rdi, rsi, rdx, rcx, r8, mis on mõeldud argumentide edastamiseks funktsioonidesse x86_64. Näiteks vasakpoolne kood tõlgitakse parempoolseks järgmiselt:
1: (b7) r1 = 1 mov $0x1,%rdi
2: (b7) r2 = 2 mov $0x2,%rsi
3: (b7) r3 = 3 mov $0x3,%rdx
4: (b7) r4 = 4 mov $0x4,%rcx
5: (b7) r5 = 5 mov $0x5,%r8
6: (85) call pc+1 callq 0x0000000000001ee8Register r0 kasutatakse ka programmi teostamise tulemuse tagastamiseks, samuti registris r1 programmile antakse konteksti näitaja — sõltuvalt programmi tüübist võib see olla näiteks struktuur (XDP jaoks) või struktuur (erinevate võrguprogrammide jaoks) või struktuur (erinevate jälgimisprogrammide jaoks) jne.
Nii et meil oli registeride komplekt, kernel helpers, virn, konteksti näitaja ja jagatud mälu kujul maps. See ei olnud tingimata vajalik teel, kuid…
Jätkame kirjeldusega ja räägime nende objektidega töötamise käskudest. Kõik () BPF juhised on fikseeritud 64-bitised. Kui vaatate 64-bitise Big Endian masina instruktsiooni, näete
![]()
Siit Kood — see on juhise kodeering, Dst/Src — need on vastuvõtja ja allika kodeerimised, vastavalt, Väljas — 16-bitine allkirjastatud nihe ja Imm — see on 32-bitine allkirjastatud täisarv, mida kasutatakse mõnedes käskudes (analoog K konstandile cBPF). Kodeering Kood on ühe kahest tüübist:
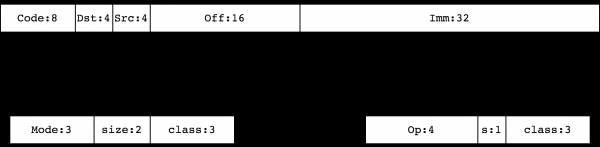
Juhiste klassid 0, 1, 2, 3 määravad mälu käsu. Need , BPF_LD, BPF_LDX, BPF_ST, BPF_STX, vastavalt. Klassid 4, 7 (BPF_ALU, BPF_ALU64) moodustavad ALU juhiste komplekti. Klassid 5, 6 (BPF_JMP, BPF_JMP32) sisaldavad üleminekuõpetusi.
Edasi mineku plaan BPF käsu süsteemi uurimiseks on järgmine: selle asemel, et hoolikalt loetleda kõik käsud ja nende parameetrid, vaatame antud osas paar näidet, millest saab selgeks, kuidas käsud tegelikult on üles ehitatud ja kuidas käsitsi disassembeldada igasuguseid binaarfailid BPF jaoks. Artikli edasise osa puhul kohtume individuaalsete käskudega mõnedes osades, mis käsitlevad Verifierit, JIT kompilaatorit, klassikalise BPF tõlkimist, samuti studeerimist maps'i, funktsioonide kõnet jne.
Kui räägime individuaalsetest käskudest, viitame kernelifailidele ja , milles defineeritakse BPF käskude numbrikoodid. Iseseisva uurimise ja/või binaarfailide analüüsi käigus leiate semantika järgmistest allikatest, järjestatud keerukuse järgi: , , ja loomulikult Linuxi lähtekoodides - verifier, JIT, BPF tõlkija.
Näide: disassembles BPF peaga
Vaatame näidet, kus kompileerime programmi readelf-example.c ja vaatame, milline binaarne fail välja tuleb. Me paljastame originaalse sisu readelf-example.c allpool, pärast seda, kui oleme taastanud selle loogika binaarkoodidest:
$ clang -target bpf -c readelf-example.c -o readelf-example.o -O2
$ llvm-readelf -x .text readelf-example.o
Hex dump of section '.text':
0x00000000 b7000000 01000000 15010100 00000000 ................
0x00000010 b7000000 02000000 95000000 00000000 ................Esimene veerg väljundis readelf — on taandamine ja meie programm koosneb seega neljast käsust:
Kood Dst Src Off Imm
b7 0 0 0000 01000000
15 0 1 0100 00000000
b7 0 0 0000 02000000
95 0 0 0000 00000000Käskude koodid on võrdsed b7, 15, b7 ja 95. Meenutame, et kolm madalaimat bitti on käsu klass. Meie juhul on neljas bitt kõigil käskudel tühi, seega on käskude klassid võrdsed, vastavalt 7, 5, 7, 5. Klass 7 — see on BPF_ALU64, aga 5 — see on BPF_JMP. Mõlemal klassil on käsu vorm sama (vt ülal) ja me saame meie programmi üle kirjutada nii (samas muudame ka teised veerud inimlikku vormi):
Op S Klass Dst Src Off Imm
b 0 ALU64 0 0 0 1
1 0 JMP 0 1 1 0
b 0 ALU64 0 0 0 2
9 0 JMP 0 0 0 0Operatsioon b klass ALU64 — see on . See määrab väärtuse sihtrigistrile. Kui on seadistatud bitt s (source), siis väärtus võetakse registrist-allikast, ja kui, nagu meie puhul, see ei ole seadistatud, siis väärtus võetakse väljast Imm. Nii et esimeses ja kolmandas juhises teeme operatsiooni r0 = Imm. Edasi, 1. klassi JMP operatsioon on (hüpata, kui on võrdne). Meie puhul, kuna bit S on null, võrdleb see registri-allika väärtust väljadega Imm. Kui väärtused vastavad, toimub üleminek PC + Off, kus PC, nagu tavaliselt, sisaldab järgmise juhise aadressi. Lõpuks, 9. klassi JMP operatsioon on . See juhis lõpetab programmi, tagastades tuumale r0. Lisa meie tabelisse uus veerg:
Op S Class Dst Src Off Imm Disassm
MOV 0 ALU64 0 0 0 1 r0 = 1
JEQ 0 JMP 0 1 1 0 if (r1 == 0) goto pc+1
MOV 0 ALU64 0 0 0 2 r0 = 2
EXIT 0 JMP 0 0 0 0 exitSaame selle ümber kirjutada mugavamas vormis:
r0 = 1
if (r1 == 0) goto END
r0 = 2
END:
exitKui me meenutame, et registris r1 edastatakse konteksti osutaja tuumast, ja registris r0 tagastatakse väärtus tuumale, siis saame näha, et kui konteksti osutaja on null, siis tagastame 1, vastasel juhul — 2. Kontrollime, kas meil on õigus, vaadates lähtekoodi:
$ cat readelf-example.c
int foo(void *ctx)
{
return ctx ? 2 : 1;
}Jah, see on mõttetu programm, kuid see koostatakse vaid neljaks lihtsaks käsuks.
Näide-erand: 16-baidine käsk
Varasemalt mainisime, et mõned käsud võtavad rohkem kui 64 bitti. See kehtib näiteks käsu kohta lddw (Kood = 0x18 = | | ) — laadib registrisse topeltsõna väljadest Imm. Asi on selles, et Imm on suurusega 32, samas kui topeltsõna — 64 bitti, seega ei saa 64-bitist vahetut väärtust registrisse laadida ühes 64-bitises käsus. Selle jaoks kasutatakse kahte kõrvutiasuvat käsku, et salvestada 64-bitise väärtuse teine osa väljale Imm. Näide:
$ cat x64.c
long foo(void *ctx)
{
return 0x11223344aabbccdd;
}
$ clang -target bpf -c x64.c -o x64.o -O2
$ llvm-readelf -x .text x64.o
Hex dump of section '.text':
0x00000000 18000000 ddccbbaa 00000000 44332211 ............D3".
0x00000010 95000000 00000000 ........Binaarses programmis on vaid kaks käsku:
Binary Disassm
18000000 ddccbbaa 00000000 44332211 r0 = Imm[0]|Imm[1]
95000000 00000000 exitKohtume veel käsuga lddw, kui räägime reloatsioonidest ja maps’idega töötamisest.
Näide: disassambleerime BPF tavaliste vahenditega
Nii et oleme õppinud BPF binaarkoodide lugemist ja oleme valmis vajadusel mistahes instruktsiooni lahendama. Siiski tuleb tõdeda, et praktikas on mugavam ja kiirem kõrgkeele programme lahendada tavaliste vahenditega, näiteks:
$ llvm-objdump -d x64.o
Lahtimurdmine jaotisest .text:
0000000000000000 :
0: 18 00 00 00 dd cc bb aa 00 00 00 00 44 33 22 11 r0 = 1234605617868164317 ll
2: 95 00 00 00 00 00 00 00 exitBPF objektide elutsükkel, bpffs failisüsteem
(Mõned detailid, mida selles allosas kirjeldatakse, sain esmakordselt teada Alexei Starovoitovilt blogis .)
BPF objektid — programmid ja mapid — luuakse kasutaja ruumist süsteemikõne kaudu, kasutades käske BPF_PROG_LOAD ja BPF_MAP_CREATE süsteemikõne bpf(2), me arutame, kuidas see täpselt juhtub, järgmises osas. Sellega luuakse tuuma andmestruktuurid ja igas neist refcount (viidete loendur) seatakse üheks, ja kasutajale tagastatakse objekti viitav failikirjeldaja. Pärast kirjelduse sulgemist refcount asutuse viidete loendur väheneb ühe võrra, ja kui see jõuab nullini, hävitatakse objekt.
Kui programm kasutab mappe, siis refcount nende mapide arv suureneb ühe võrra pärast programmi laadimist, st nende failides olevaid deskriptorit saab kasutaja protsessist sulgeda ja sellegipoolest refcount ei muutu nulliks:
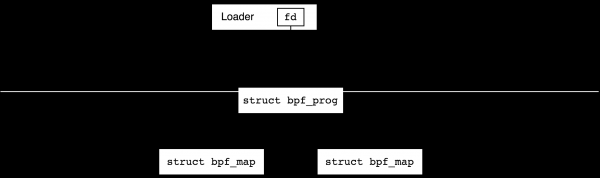
Pärast programmi edukat laadimist seome selle tavaliselt mõne sündmuste generaatoriga. Näiteks võime selle kinnitada võrgu liidesesse sissetulevate paketide töötlemiseks või ühendada seda mingiga tracepoint tuumas. Sel hetkel suureneb ka viidete loendur ühe võrra ja saame sulgeda failides deskriptorit laadimisprogrammis.
Mida juhtub, kui lõpetame laadimistöötluse? See sõltub sündmuse generaatori tüübist (hook). Kõik võrgu hook'id eksisteerivad pärast laadijate lõpetamist, need on nii-öelda globaalhook'id. Näiteks jälgimisprogrammid vabastatakse pärast protsessi lõpetamist, mis neid lõi (ja seetõttu nimetatakse neid kohalikeks, tõlgituna kui 'local to the process'). Tehniliselt on kohalikud hook'id alati seotud vastava failikirjeldajaga kasutajaruumi, seetõttu suletakse need protsessi sulgemisel, samas globaalhook'id mitte. Järgmisel joonisel püüan punaste ristidega näidata, kuidas laadimisprogrammi lõpetamine mõjutab objektide eluea kestust kohalikest ja globaalsetest hook'idest.
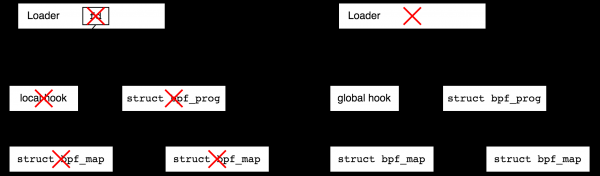
Miks on vajalik kohalike ja globaalsete hookide eraldamine? Mõne tüüpi võrguprogrammide käivitamine on mõttekas ka ilma userspace'ita. Näiteks, kujutlege DDoS-i kaitset: laadija kirjutab reeglid ja ühendab BPF programmi võrguliidesega, pärast mida võib laadija minna ja lõppeda. Teisalt, kujutage ette silumise programmi, mille te olete kümne minutiga kokku keevitanud — pärast selle lõpetamist sooviksite, et süsteemis ei jääks prügi, ja kohalikud hookid tagavad selle.
Teiselt poolt, kujutage ette, et soovite ühendada küljepunkti kernelis ja koguda statistikat aastaid. Sellisel juhul sooviksite lõpetada kasutajaosa ja aeg-ajalt tagasi statistikale pöörduda. Selleks annab BPF failisüsteem. See on pseudofailisüsteem, mis eksisteerib ainult mälus ja mis võimaldab luua faile, mis viitavad BPF objektidele, ning seega suurendavad refcount objekte. Pärast seda võib laadija lõpetada töö, kuid loodud objektid jäävad ellu.
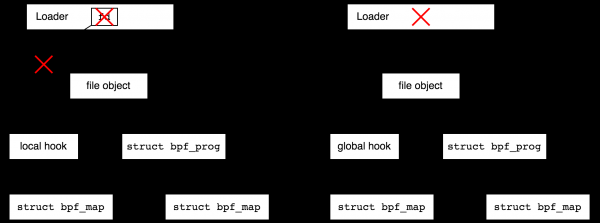
BPF objektidele viitavad failide loomine bpffsis nimetatakse «kinnihoidmiseks» («pin», nagu järgmises lauses: «process can pin a BPF program or map»). BPF objektide jaoks failide loomine on mõttekas mitte ainult kohalike objektide elu pikendamiseks, vaid ka globaalsete objektide mugavamaks kasutamiseks — tagasi tulles DDoS kaitse globaalse programmi näite juurde, soovime mõnikord vaadata statistikat.
BPF failisüsteem mountitakse tavaliselt /sys/fs/bpf, kuid seda saab mountida ka kohalikult, näiteks järgmiselt:
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointFailisüsteemis luuakse nimesid käsuga BPF_OBJ_PIN BPF süsteemikõne. Illustratsiooniks võtame mingi programmi, kompileerime, laadime üles ja kinnitame selle bpffs. Meie programm ei tee midagi kasulikku, toome selle koodi vaid selleks, et saaksite näidet uuesti luua:
$ cat test.c
__attribute__((section("xdp"), used))
int test(void *ctx)
{
return 0;
}
char _license[] __attribute__((section("license"), used)) = "GPL";Kompileerime selle programmi ja loome failisüsteemi kohalikku koopia bpffs:
$ clang -target bpf -c test.c -o test.o
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointLaadime nüüd oma programmi tööriista abil bpftool ja vaatame süsteemikõnesid bpf(2) (strace väljastusest on eemaldatud mõned ebaolulised read):
$ sudo strace -e bpf bpftool prog load ./test.o bpf-mountpoint/test
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="test", ...}, 120) = 3
bpf(BPF_OBJ_PIN, {pathname="bpf-mountpoint/test", bpf_fd=3}, 120) = 0Siin laadisime programmi tööriista abil BPF_PROG_LOAD, saime kernelilt failifiltri 3 ja käsu abil BPF_OBJ_PIN sidusime selle failifiltri faili kujul "bpf-mountpoint/test". Pärast seda lõpetas laadimisprogramm oma töö, kuid meie programm jäi kernelisse, kuigi me ei sidunud seda ühegi võrgu liidesega: bpftool $ sudo bpftool prog | tail -3 783: xdp name test tag 5c8ba0cf164cb46c gpl loaded_at 2020-05-05T13:27:08+0000 uid 0 xlated 24B jited 41B memlock 4096B
Saame faili objekti tavaliseunlink(2) abil eemaldada ja pärast seda vastav programm eemaldatakse: $ sudo rm ./bpf-mountpoint/test $ sudo bpftool prog show id 783 Error: get by id (783): No such file or directory
Objektide eemaldamineObjektide eemaldamine
Rääkides objektide eemaldamisest, tuleb täpsustada, et pärast selle ühenduse lõppemist (sündmuste generaatoriga) ei käivitu ükski uus sündmus, kuid kõik aktiivsed programmi eksemplarid lõpetatakse normaalselt.
Mõned BPF programmide tüübid võimaldavad programme jooksvalt asendada, st nad pakuvad järjepidevuse atomaarset teostust. replace = eemalda vana programm, lisa uus programm. Samal ajal lõpetavad kõik vana versiooni aktiivsed eksemplarid oma töö ning uued sündmuste töötlejad luuakse juba uuest programmist, ja "atomaarne" siin tähendab, et ühtegi sündmust ei jää vahele.
Programmide ühendamine sündmuste allikatega
Selles artiklis me ei kirjeldada eraldi programmide ühendamist sündmuste allikatega, kuna see on mõistlik uurida konkreetse programmitüübi kontekstis. Vt. allpool, kus me näitame, kuidas XDP tüüpi programme ühendatakse.
Objektide haldamine bpf süsteemi kõne abil
BPF programmid
Kõik BPF objektid luuakse ja neid hallatakse kasutajaruumi kaudu bpf süsteemi kõne abil , millel on järgmine prototüüp:, millel on järgmine prototüüp:
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);Siin on meeskond cmd — see on üks väärtustest tüübile , attr — näitaja konkreetse programmi parameetritele ja size — objekti suurus näitaja järgi, st tavaliselt see on sizeof(*attr). Kerneli versioonis 5.8 toetab süsteemikõne , millel on järgmine prototüüp: 34 erinevat käsku, ja union bpf_attr võtab 200 rida. Kuid see ei tohiks meid hirmutada, sest tutvume käskude ja parameetritega järgnevatel artiklitel.
Alustame käskudest BPF_PROG_LOAD, mis loob BPF programme — võtab BPF käsu kogumi ja laadib selle kernelisse. Laadimise ajal käivitub verifitseerija, seejärel JIT kompilaator ja pärast eduka täitmise lõpetamist tagastatakse kasutajale programmi failideskreeptor. Oleme näinud, mis temaga edasi toimub eelmises osas .
Praegu kirjutame kasutaja programmi, mis laadib lihtsa BPF programmi, kuid kõigepealt peame otsustama, millise programmi me soovime laadida — peame valima ja selle tüübi raames kirjutama programm, mis läbib verifitseerija kontrolli. Kuid et protsessi mitte keerulisemaks muuta, on siin valmis lahendus: võtame programmi tüübi BPF_PROG_TYPE_XDP, mis tagastab väärtuse XDP_PASS (jätab kõik paketid vahele). BPF-i assembleris näeb see väga lihtne välja:
r0 = 2
exitPärast seda, kui oleme määratlenud, mida me laadime, saame rääkida, kuidas me seda teeme:
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
static inline __u64 ptr_to_u64(const void *ptr)
{
return (__u64) (unsigned long) ptr;
}
int main(void)
{
struct bpf_insn insns[] = {
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_0,
.imm = XDP_PASS
},
{
.code = BPF_JMP | BPF_EXIT
},
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_XDP,
.insns = ptr_to_u64(insns),
.insn_cnt = sizeof(insns)/sizeof(insns[0]),
.license = ptr_to_u64("GPL"),
};
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
for ( ;; )
pause();
}Huvitavad sündmused programmis algavad massiivi määratlemisega insns — meie BPF programm masinkoodides. Iga BPF programmi käsk pakitakse struktuuri . Esimene element insns vastab käsklusele r0 = 2, teine — exit.
Tagasihoidlikult. Kerneli raamistikus on määratletud mugavamad makrod masinkoodide kirjutamiseks ning kasutades kerneli pealkirja faili tools/include/linux/filter.h võiksime kirjutada
struct bpf_insn insns[] = {
BPF_MOV64_IMM(BPF_REG_0, XDP_PASS),
BPF_EXIT_INSN()
};Kuna BPF programmide kirjutamine masinkoodides on vajalik ainult testide ja BPF-i kohta käivate artiklite jaoks, ei muuda nende makrode puudumine tõeliselt arendaja elu keeruliseks.
Pärast BPF programmi määratlemist liigume edasi selle laadimisele kerneli. Meie minimalistlik parameetrite komplekt attr kätkeb endas programmi tüüpi, käsu komplekti ja hulka, kohustuslikku litsentsi ning nime "woo", mida kasutame, et leida meie programm süsteemis pärast laadimist. Programm laaditakse süsteemi nagu lubatud süsteemikõne kaudu. , millel on järgmine prototüüp:.
Programm lõpuks siseneeb lõpmatusse tsükli, mis simuleerib koormust. Ilma selleta hävitatakse programm südamiku poolt failikirjeldaja sulgemise korral, mille andis meile süsteemikõne. , millel on järgmine prototüüp:, ja me ei näe seda süsteemis.
Noh, me oleme testimiseks valmis. Kogume kokku ja käivitame programmi all strace, et kontrollida, kas kõik töötab nagu peab:
$ clang -g -O2 simple-prog.c -o simple-prog
$ sudo strace ./simple-prog
execve("./simple-prog", ["./simple-prog"], 0x7ffc7b553480 /* 13 vars */) = 0
...
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0x7ffe03c4ed50, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(0, 0, 0), prog_flags=0, prog_name="woo", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS}, 72) = 3
pause(Kõik on korras, bpf(2) tagastas meile deskriptor 3 ja me sisenesime lõpmatusse tsüklisse koos pause(). Proovime leida meie programmi süsteemis. Selleks läheme teise terminali ja kasutame utiliiti bpftool:
# bpftool prog | grep -A3 woo
390: xdp name woo tag 3b185187f1855c4c gpl
loaded_at 2020-08-31T24:66:44+0000 uid 0
xlated 16B jited 40B memlock 4096B
pids simple-prog(10381)Külastame, et süsteemis on laaditud programm woo , mille globaalne ID on 390, ning et hetkeseis on protsessis simple-prog on avatud failikirje, mis viitab programmile (ja kui simple-prog tape, siis woo kaob). Nagu oodata oli, programm woo võtab 16 bitti — kaks instruktsiooni — binaarkoodid BPF arhitektuuris, kuid kohalikus vormis (x86_64) on see juba 40 bitti. Vaatame meie programmi originaalversioonis:
# bpftool prog dump xlated id 390
0: (b7) r0 = 2
1: (95) exitilma üllatusteta. Nüüd vaatame koodi, mille on loonud JIT-kompilaator:
# bpftool prog dump jited id 390
bpf_prog_3b185187f1855c4c_woo:
0: nopl 0x0(%rax,%rax,1)
5: push %rbp
6: mov %rsp,%rbp
9: sub $0x0,%rsp
10: push %rbx
11: push %r13
13: push %r14
15: push %r15
17: pushq $0x0
19: mov $0x2,%eax
1e: pop %rbx
1f: pop %r15
21: pop %r14
23: pop %r13
25: pop %rbx
26: leaveq
27: retqei ole just eriti efektiivne exit(2), kuid õiguse nimel, meie programm on liiga lihtne, ja mitte triviaalsetele programmidele on proloog ja epiloog, mille JIT-kompilaator lisab, kindlasti vajalikud.
Maps
BPF programmid võivad kasutada struktureeritud mälupiirkondi, mis on ligipääsetavad nii teistele BPF programmidele kui ka kasutajaruumi programmidele. Need objektid nimetatakse kaarditeks ja selles jaotises näitame, kuidas nendega süsteemikõnede abil hallata. , millel on järgmine prototüüp:.
Alustame sellega, et kaardirakenduste võimalused ei piirdu vaid ühise mälu juurdepääsuga. On olemas spetsiaalse otstarbega kaardid, mis sisaldavad näiteks BPF programmide jaotusnäidikuid või võrgu liideseid, kaarte, mis töötavad perf events'iga jne. Me ei käsitle neid siin, et mitte lugejat segadusse ajada. Lisaks ignoreerime sünkroniseerimise probleeme, kuna need pole olulised meie näidete jaoks. Täieliku loendi saadaval olevatest kaarditüüpidest leiate , ja selles jaotises toome näitena välja esimesena ajalooliselt tuntud tüübi, hash-tabeli. BPF_MAP_TYPE_HASH.
Kui loote hash-tabeli, näiteks C++ keeles, ütlete unordered_map woo, mis tähendab eesti keeles „mul on vaja tabelit, woo mille suurus on piiramatult suur, kus võtmed on tüüpi int, ja väärtused on tüüpi long.” BPF hash-tabeli loomiseks peame tegema peaaegu sama, lisades vaid tingimuse, et peame näitama tabeli maksimaalset suurust, ning võtmete ja väärtuste tüüpide asemel peame näitama nende suurusi baitides. Kaartide loomisel kasutatakse käsku BPF_MAP_CREATE süsteemikõne , millel on järgmine prototüüp:. Vaatame nüüd enam-vähem minimaalset programmi, mis loob kaardi. Pärast eelmist programmi, mis laadis BPF programe, peaks see teile tunduma lihtsalt arusaadav:
$ cat simple-map.c
#define _GNU_SOURCE
#include
#include
#include
#include
int main(void)
{
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 4,
};
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
for ( ;; )
pause();
}Siin määratleme hulga parameetreid attr, kus ütleme, "mul on vaja räsivaba tabelit, mille võtmed ja väärtused on suurusega sizeof(int), kuhu ma saan panna maksimaalselt neli elementi." BPF kaardid luues saab määrata ka teisi parameetreid, näiteks, nagu ka näites programmi puhul, määrasime objekti nimeks "woo".
Kompileerime ja käivitame programmi:
$ clang -g -O2 simple-map.c -o simple-map
$ sudo strace ./simple-map
execve("./simple-map", ["./simple-map"], 0x7ffd40a27070 /* 14 vars */) = 0
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=4, max_entries=4, map_name="woo", ...}, 72) = 3
pause(Siin süsteemi väljakutse bpf(2) tagastas meile kaardi deskriptor number 3 ja edasi programm, nagu oodata, ootab edasisi juhiseid süsteemi väljakutses pause(2).
Nüüd saadame meie programmi taust tööle või avame teise terminali ning vaatame meie objekti sisu utiliidi abil bpftool (me saame eristada meie kaarti teistest selle nime järgi):
$ sudo bpftool map
...
114: hash nimi woo lipud 0x0
võti 4B väärtus 4B maksimaalne_kogus 4 mälulukk 4096B
...Number 114 on meie objekti globaalne ID. Iga programm süsteemis saab kasutada seda ID-d, et avada juba olemasolev kaart käsuga BPF_MAP_GET_FD_BY_ID süsteemikõne , millel on järgmine prototüüp:.
Nüüd saame mängida oma räsitihedusega. Vaatame selle sisu:
$ sudo bpftool map dump id 114
Leitud 0 elementiTühi. Paneme sinna väärtuse hash[1] = 1:
$ sudo bpftool map update id 114 key 1 0 0 0 value 1 0 0 0Vaatame tabelit veel kord:
$ sudo bpftool map dump id 114
võti: 01 00 00 00 väärtus: 01 00 00 00
Leitud 1 elementHurraa! Oleme suutnud lisada ühe elemendi. Pange tähele, et selleks peame töötama baiditasandil, kuna bpftool ei tea, milline tüüp on väärtustel räsitiheduses. (Seda teadmist saab edastada, kasutades BTF-d, kuid sellest ei räägi me praegu.)
Kuidas bpftool tegelikult loeb ja lisab elemente? Vaatame mootori alla:
$ sudo strace -e bpf bpftool map dump id 114
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x55856ab65280}, 120) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0x55856ab65280, value=0x55856ab652a0}, 120) = 0
key: 01 00 00 00 value: 01 00 00 00
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0x55856ab65280, next_key=0x55856ab65280}, 120) = -1 ENOENTEsimene, avasime kaardi selle globaalse ID abil käsuga BPF_MAP_GET_FD_BY_ID ja bpf(2) tagastas meile deskriptor 3. Edasi käsu abil BPF_MAP_GET_NEXT_KEY leidsime tabelis esimese võtme, edastades NULL kui indikaator "eelmine" võti. Kui võtme olemasolu, saame teha BPF_MAP_LOOKUP_ELEM, mis tagastab väärtuse indikaatorile value. Järgmine samm on proovida leida järgmine element, edastades indikaatori hetke võtmele, kuid meie tabel sisaldab ainult ühte elementi ja käsk BPF_MAP_GET_NEXT_KEY tagastab ENOENT.
Hästi, muudame väärtust võtme 1 järgi, ütleme, meie äriloogika nõuab kirjutamist hash[1] = 2:
$ sudo strace -e bpf bpftool map update id 114 key 1 0 0 0 value 2 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x55dcd72be260, value=0x55dcd72be280, flags=BPF_ANY}, 120) = 0Nagu oodata, on see väga lihtne: käsk BPF_MAP_GET_FD_BY_ID avatakse meie kaart ID järgi, ja käsk BPF_MAP_UPDATE_ELEM ülendab elementi.
Kokkuvõttes, pärast ühe programmi häshtabeli loomist saame lugeda ja kirjutada selle sisu teisest. Pange tähele, et kui me suutsime seda teha käsurealt, siis saavad seda teha ka kõik teised süsteemi programmid. Lisaks eespool kirjeldatud käskele on kasutajaruumi maadega töötamiseks saadaval :
BPF_MAP_LOOKUP_ELEM: leidke väärtus võti järgiBPF_MAP_UPDATE_ELEM: uuendage/looge väärtusBPF_MAP_DELETE_ELEM: eemaldage võtiBPF_MAP_GET_NEXT_KEY: leidke järgmine (või esimene) võtiBPF_MAP_GET_NEXT_ID: võimaldab käia läbi kõik olemasolevad maad, see onbpftool mapBPF_MAP_GET_FD_BY_ID: avada olemasolev maa selle globaalsete ID järgiBPF_MAP_LOOKUP_AND_DELETE_ELEM: atomaarne objekti väärtuse uuendamine ja vana tagastamineBPF_MAP_FREEZE: muuta maa muutumatuks kasutajaruumielt (seda operatsiooni ei saa tühistada)BPF_MAP_LOOKUP_BATCH,BPF_MAP_LOOKUP_AND_DELETE_BATCH,BPF_MAP_UPDATE_BATCH,BPF_MAP_DELETE_BATCH: masstoimingud. Näiteks,BPF_MAP_LOOKUP_AND_DELETE_BATCH— see on ainus usaldusväärne viis lugeda ja nullida kõik väärtused maast
Kuid mitte kõik need käsud ei tööta kõikide maade tüüpide jaoks, kuid üldiselt näeb teiste maadega töötamine kasutajaruumi kaudu täpselt sama välja, nagu töötamine häshtabelitega.
Korra jaoks lõpetame meie eksperimentide seeriad hash-tabeliga. Kas mäletate, et lõime tabeli, kuhu mahub kuni neli võtit? Lisame veel mõned elemendid:
$ sudo bpftool map update id 114 key 2 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 3 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 4 0 0 0 value 1 0 0 0Siiani kõik korras:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
key: 02 00 00 00 value: 01 00 00 00
key: 04 00 00 00 value: 01 00 00 00
key: 03 00 00 00 value: 01 00 00 00
Leitud 4 elementiProovime lisada veel ühe:
$ sudo bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
Error: update failed: Argument list too longNagu oodata võis, ei õnnestunud meil. Vaadake vea üksikasju lähemalt:
$ sudo strace -e bpf bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, info_len=80, info=0x7ffe6c626da0}}, 120) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x56049ded5260, value=0x56049ded5280, flags=BPF_ANY}, 120) = -1 E2BIG (Argument list too long)
Error: update failed: Argument list too long
+++ exited with 255 +++Kõik on korras: nagu oodata võis, käsk BPF_MAP_UPDATE_ELEM üritab luua uut, viiendat võtit, kuid kukub alla E2BIG.
Nüüd oskame luua ja laadida BPF-i programme ning hallata maapealseid kaarte kasutajate ruumist. On mõistlik vaadata, kuidas me saame maapealseid kaarte kasutada BPF-i programmides ise. Me võiksime sellest rääkida keerulise masinakoodiga, kuid nüüd on aeg näidata, kuidas BPF-i programme tegelikult kirjutatakse ja hooldatakse — kasutades libbpf.
(Lugemiseks, kes on rahul allavoolu madala taseme näidise puudumisega: uurime üksikasjalikult programme, mis kasutavad kaarte ja abifunktsioone, mis on loodud libbpf ja räägime, mis juhtub käsu tasemel. Lugemiseks, kes on rahul väga palju, oleme lisanud artikli vastavasse kohta.)
Kirjutame BPF programme libbpf-iga
BPF-i programmide kirjutamine masinakoodide abil on huvitav vaid alguses, kuid siis muutub see ülekaaluks. Sel hetkel peab pöörama pilgu llvm, millel on BPF-i arhitektuuri koodi genereerimise tagumine osa ja samuti raamatukogu libbpf, mis võimaldab kirjutada BPF-i rakenduste kasutajapoolset osa ja laadida BPF-i programme, mis on genereeritud llvm/clang.
Tegelikult, nagu me näeme käesolevas ja järgmistes artiklites, libbpf teeb üsna palju tööd ka ilma selleta (või sarnaste tööriistadega — iproute2, libbcc, libbpf-go, jne.) elamine pole võimalik. Üks projekti killer-funktsioone libbpf on BPF CO-RE (Compile Once, Run Everywhere) — projekt, mis võimaldab kirjutada BPF programme, mis on ülekantavad ühe kernelitüübi pealt teisele, võimalusega käivitada erinevatel API-del (näiteks kui kernelistruktuur muutub versioonide vahel). Selleks, et CO-RE-ga töötada, peab teie kernel olema koostatud BTF toe lisamisega (kuidas seda teha, räägime me jaotisest . Veenduda, et teie kernel on BTF-ga või mitte, on väga lihtne — vaadates järgmise faili olemasolu:
$ ls -lh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 2.6M Jul 29 15:30 /sys/kernel/btf/vmlinuxSee fail sisaldab teavet kõigi andmetüüpide kohta, mida kernelis kasutatakse, ja seda kasutatakse kõigis meie näidetes, mis kasutavad libbpf. Räägime CO-RE-st üksikasjalikult järgmises artiklis, kuid praeguses — lihtsalt ehitage endale kernel koos CONFIG_DEBUG_INFO_BTF.
Raamatukogu libbpf asub otse kataloogis tools/lib/bpf kernel ja selle arendust juhitakse meilisti kaudu bpf@vger.kernel.org. Kuid rakenduste vajaduste jaoks, mis elavad südamikust väljaspool, on eraldi hoidla. millest südamiku teek peegeldatakse lugemiseks enam-vähem sellisena, nagu see on.
Selles jaotises vaatame, kuidas luua projekt, mis kasutab libbpf, kirjutame mõned (peaaegu mõttetud) testprogrammid ja uurime, kuidas see kõik töötab. See aitab meil järgmistes jaotistes hõlpsamini selgitada, kuidas täpselt BPF programmid suhtlevad maps, kernel helpers, BTF jms.
Tavaliselt lisavad projektid, mis kasutavad libbpf GitHubi hoidla git submodule’ina, teeme seda ka meie:
$ mkdir /tmp/libbpf-example
$ cd /tmp/libbpf-example/
$ git init-db
Alustatud tühi Git-hoidla aadressil /tmp/libbpf-example/.git/
$ git submodule add https://github.com/libbpf/libbpf.git
Kloonimine kausta '/tmp/libbpf-example/libbpf'...
remotelt: Objektide loendamine: 200, valmis.
remotelt: Objektide arvestamine: 100% (200/200), valmis.
remotelt: Objektide tihendamine: 100% (103/103), valmis.
remotelt: Kokku 3354 (delta 101), taaskasutatud 118 (delta 79), gepakki taaskasutatud 3154
Objektide vastuvõtt: 100% (3354/3354), 2.05 MiB | 10.22 MiB/s, valmis.
Deltade lahendamine: 100% (2176/2176), valmis.Kogumine libbpf on väga lihtne:
$ cd libbpf/src
$ mkdir build
$ OBJDIR=build DESTDIR=root make -s install
$ find root
root
root/usr
root/usr/include
root/usr/include/bpf
root/usr/include/bpf/bpf_tracing.h
root/usr/include/bpf/xsk.h
root/usr/include/bpf/libbpf_common.h
root/usr/include/bpf/bpf_endian.h
root/usr/include/bpf/bpf_helpers.h
root/usr/include/bpf/btf.h
root/usr/include/bpf/bpf_helper_defs.h
root/usr/include/bpf/bpf.h
root/usr/include/bpf/libbpf_util.h
root/usr/include/bpf/libbpf.h
root/usr/include/bpf/bpf_core_read.h
root/usr/lib64
root/usr/lib64/libbpf.so.0.1.0
root/usr/lib64/libbpf.so.0
root/usr/lib64/libbpf.a
root/usr/lib64/libbpf.so
root/usr/lib64/pkgconfig
root/usr/lib64/pkgconfig/libbpf.pcMeie plaan selles osas on järgmine: me kirjutame BPF tüüpi programmi BPF_PROG_TYPE_XDP, sama programmi nagu eelnevas näites, kuid C keeles, kompileerime selle clang, ja kirjutame abiprogrammi, mis laadib selle tuumasse. Järgmistes osades laiendame nii BPF programmi kui ka abiprogrammi võimekust.
Näide: loome täieliku rakenduse libbpf abil
Alustuseks kasutame faili /sys/kernel/btf/vmlinux, millest juttu oli, ja loome selle ekvivalent pealkirjafailina:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.hSelles failis hoitakse kõiki andmestruktuure, mis on tuumas olemas, näiteks määratakse IPv4 päis tuumas nii:
$ grep -A 12 'struct iphdr {' vmlinux.h
struct iphdr {
__u8 ihl: 4;
__u8 version: 4;
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
};Nüüd kirjutame meie BPF programmi C keeles:
$ cat xdp-simple.bpf.c
#include "vmlinux.h"
#include
SEC("xdp/simple")
int simple(void *ctx)
{
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Kuigi meie programm on väga lihtne, peame siiski tähelepanu pöörama mitmetele detailidele. Esiteks on esimene pealkirja fail, mille me lisame, vmlinux.h, mille me just genereerisime kasutades bpftool btf dump — nüüd ei pea me kernel-headers paketti installima, et teada saada, kuidas kernelistruktuurid välja näevad. Järgmine pealkirja fail tuleb meile raamatukogust libbpf. Praegu on see meist vajalik ainult selleks, et määratleda makro SEC, mis saadab sümboli vastavasse ELF objekti faili sektsiooni. Meie programm asub sektsioonis xdp/simple, kus enne kaldkriipsu määrame BPF programmi tüübi — see on kokkulepe, mida kasutatakse libbpf, sektsiooni nime põhjal paneb see käivitamisel õigesse tüüpi. bpf(2)Ise BPF programm on C — väga lihtne ja koosneb ühest reast return XDP_PASS. Lõpuks, eraldi sektsioon "license" sisaldab litsentsi nime.
Saame meie programmi koostada llvm/clang abil, versiooniga >= 10.0.0, veelgi parem — suurem (vt jaotist ):
$ clang --version
clang version 11.0.0 (https://github.com/llvm/llvm-project.git afc287e0abec710398465ee1f86237513f2b5091)
...
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.oHuvitavad omadused: määrame sihitarbeks arhitektuuri -target bpf ja tee pealkirjadele libbpf, mida me hiljuti installisime. Samuti ärge unustage -O2, ilma selle valikuta võivad teid oodata üllatused edaspidiseks. Vaatame meie koodi, kas suutsime kirjutada programmi, mida soovisime?
$ llvm-objdump --section=xdp/simple --no-show-raw-insn -D xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: r0 = 2
1: exitJah, läks läbi! Nüüd on meil binaarfail programmiga ja soovime luua rakenduse, mis laadib selle kernelisse. Selleks on vajalik teek libbpf pakub meile kahte võimalust — kasutada madalama taseme API-d või kõrgema taseme API-d. Valime teise tee, kuna soovime õppida, kuidas kirjutada, laadida ja ühendada BPF programme minimaalsete pingutustega nende edasiseks uurimiseks.
Alustamiseks peame genereerima meie programmi „skeleti” selle binaarfailist sama utiliidi abil, bpftool — BPF maailma Šveitsi armutera (mida võib võtta ka sõna otseses mõttes, kuna Daniel Borkman — üks BPF-i loojaid ja hooldajaid — on šveitslane):
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.hFailis xdp-simple.skel.h sisaldab meie programmi binaarkoodi ja funktsioone haldamiseks — laadimiseks, ühendamiseks, meie objekti eemaldamiseks. Meie lihtsas näites tundub see üleliigne, kuid see töötab ka juhul, kui objekti fail sisaldab palju BPF programme ja mape ning selle hiiglasliku ELF-i laadimiseks piisab vaid skeleti genereerimisest ja ühest-kahest funktsioonist, mida me kirjutatavas kasutajarakenduses nüüd kasutame.
Tegelikult on meie laadimisprogramm triviaalne:
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
pause();
xdp_simple_bpf__destroy(obj);
}Siit struct xdp_simple_bpf määratletakse failis xdp-simple.skel.h ja kirjeldab meie objekti faili:
struct xdp_simple_bpf {
struct bpf_object_skeleton *skeleton;
struct bpf_object *obj;
struct {
struct bpf_program *simple;
} progs;
struct {
struct bpf_link *simple;
} links;
};Siit võime märgata madalama taseme API jälgi: struktuuri struct bpf_program *simple ja struct bpf_link *simple. Esimene struktuur kirjeldab konkreetselt meie programmi, mis on kirja pandud sektsioonis xdp/simple, teine aga kirjeldab, kuidas programm on ühendatud sündmuste allikaga.
Function xdp_simple_bpf__open_and_load, avab ELF objekti, analüüsib seda, loob kõik struktuurid ja alastruktuurid (kuna ELF-is on ka teisi sektsioone — data, readonly data, silumisinfot, litsents ja nii edasi), ja seejärel laadib selle tuumasse süsteemikõne kaudu , millel on järgmine prototüüp:, mida saame kontrollida, kompileerides ja käivitades programmi:
$ clang -O2 -I ./libbpf/src/root/usr/include/ xdp-simple.c -o xdp-simple ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_BTF_LOAD, 0x7ffdb8fd9670, 120) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0xdfd580, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 8, 0), prog_flags=0, prog_name="simple", prog_ifindex=0, expected_attach_type=0x25 /* BPF_??? */, ...}, 120) = 4Vaadakem nüüd meie programmi abi bpftool. Leiame selle ID:
# bpftool p | grep -A4 simple
463: xdp name simple tag 3b185187f1855c4c gpl
loaded_at 2020-08-01T01:59:49+0000 uid 0
xlated 16B jited 40B memlock 4096B
btf_id 185
pids xdp-simple(16498)ja väljavõtame (kasutame komandi lühendatud vormi bpftool prog dump xlated):
# bpftool p d x id 463
int simple(void *ctx):
; return XDP_PASS;
0: (b7) r0 = 2
1: (95) exitMidagi uut! Programm printis välja osi meie lähtekoodifailist C-keeles. Selle tegi raamatukogu libbpf, mis leidis silumise osa binaarfailis, kompileeris selle objektiks BTF, laadis selle kernelisse kasutades BPF_BTF_LOAD, ja seejärel näitas saadud faili descriptorit programmi laadimist suunava käsu BPG_PROG_LOAD.
Kernel Helpers
BPF-programmid võivad käivitada "välist" funktsioone — kernel helpers. Need abifunktsioonid võimaldavad BPF-programmidel pääseda juurde kernelistruktuuridele, hallata maps-nimekirju, ning suhelda "reaalse maailmaga" — luua perf events, hallata riistvara (nt suunata pakette) jne.
Näide: bpf_get_smp_processor_id
Õppeparadigma "õppimine näidete põhjal" raames vaatleme ühte abifunktsiooni, bpf_get_smp_processor_id(), failis kernel/bpf/helpers.c. See tagastab protsessori numbri, millel käivitatakse selle funktsiooni kutsuv BPF-programm. Kuid meid rohkem huvitab selle rakenduse ühe rea jõud.
BPF_CALL_0(bpf_get_smp_processor_id)
{
return smp_processor_id();
}BPF-i abifunktsioonide määratlemine sarnaneb Linuxi süsteemikutsungite määratlemisega. Siin, näiteks, määratletakse funktsioon, millel ei ole argumete. (Funktsioon, mis võtab näiteks kolm argumenti, määratletakse makro abil. BPF_CALL_3. Kõige rohkem argumente võib olla kuni viis.) Siiski on see ainult määratlemise esimene osa. Teine osa hõlmab tüübi struktuuri määratlemist struct bpf_func_proto, mis sisaldab verifierile arusaadavat abifunktsiooni kirjeldust:
const struct bpf_func_proto bpf_get_smp_processor_id_proto = {
.func = bpf_get_smp_processor_id,
.gpl_only = false,
.ret_type = RET_INTEGER,
};Abifunktsioonide registreerimine
Selleks, et teatud tüüpi BPF-programmid saaksid seda funktsiooni kasutada, peavad nad selle registreerima, näiteks tüübi jaoks BPF_PROG_TYPE_XDP tuumas määratletakse funktsioon xdp_func_proto, mis määratleb abifunktsiooni ID järgi, kas XDP toetab seda funktsiooni või mitte. Meie funktsioon :
static const struct bpf_func_proto *
xdp_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
...
case BPF_FUNC_get_smp_processor_id:
return &bpf_get_smp_processor_id_proto;
...
}
}Uued BPF-programmide tüübid «määratletakse» failis makro abil BPF_PROG_TYPE. Määratakse tsitaatides, kuna see on loogiline määratlemine, ning keeles C määratletakse terve hulk konkreetseid struktuure mujal. Eriti failis kernel/bpf/verifier.c kõik määratlemised failist bpf_types.h kasutatakse struktuuride massiivi loomiseks bpf_verifier_ops[]:
static const struct bpf_verifier_ops *const bpf_verifier_ops[] = {
#define BPF_PROG_TYPE(_id, _name, prog_ctx_type, kern_ctx_type)
[_id] = &_name ## _verifier_ops,
#include
#undef BPF_PROG_TYPE
};See tähendab, et iga BPF programmi tüübi jaoks määratakse andmestruktuuri tüübi näidik struct bpf_verifier_ops, mis inicialiseeritakse väärtusega _name ## _verifier_ops, st, xdp_verifier_ops kuna xdp. Struktuur xdp_verifier_ops failis net/core/filter.c järgmiselt:
const struct bpf_verifier_ops xdp_verifier_ops = {
.get_func_proto = xdp_func_proto,
.is_valid_access = xdp_is_valid_access,
.convert_ctx_access = xdp_convert_ctx_access,
.gen_prologue = bpf_noop_prologue,
};Siin näeme meie tuttavat funktsiooni xdp_func_proto, mida käivitab verifier iga kord, kui see kohtub mõne funktsiooniga BPF programmis, vt. .
Vaadakem, kuidas hüpoteetiline BPF programm kasutab funktsiooni bpf_get_smp_processor_id. Selleks kirjutame meie eelmise jaotise programmi ümber järgmiselt:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
if (bpf_get_smp_processor_id() != 0)
return XDP_DROP;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Sümbol bpf_get_smp_processor_id ühes <bpf/bpf_helper_defs.h> raamatukogud libbpf kuidas
staatiline u32 (*bpf_get_smp_processor_id)(void) = (void *) 8;nimelt, bpf_get_smp_processor_id — see on funktsiooni näitaja, mille väärtus on 8, kus 8 on väärtus BPF_FUNC_get_smp_processor_id tüüp enum bpf_fun_id, mis määratletakse meile failis vmlinux.h (fail bpf_helper_defs.h tuumas genereeritakse skripti poolt, seega on "maagilised" numbrid okei). See funktsioon ei võta argumente ja tagastab väärtuse tüüpi __u32. Kui käivitame selle oma programmis, clang genereerib käsu BPF_CALL "õige tüübi". Kompileerime programmi ja vaatame sektsiooni xdp/simple:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ llvm-objdump -D --section=xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: faili formaat elf64-bpf
Sektsiooni xdp/simple desassembleerimine:
0000000000000000 :
0: 85 00 00 00 08 00 00 00 call 8
1: bf 01 00 00 00 00 00 00 r1 = r0
2: 67 01 00 00 20 00 00 00 r1 <>= 32
4: b7 00 00 00 02 00 00 00 r0 = 2
5: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1
6: b7 00 00 00 01 00 00 00 r0 = 1
0000000000000038 :
7: 95 00 00 00 00 00 00 00 exitEsimeses real näeme käsku call, parameeter IMM mille väärtus on 8, ja SRC_REG — null. ABI-kokkuleppe kohaselt, mida verifier kasutab, on see abifunktsiooni number kaheksa kutsumine. Pärast selle käivitamist on loogika lihtne. Registist tagastatud väärtus r0 kopeeritakse r1 ja ridadel 2,3 muudetakse tüübiks u32 — ülemised 32 bitti nullitakse. Ridadel 4,5,6,7 tagastame 2 (XDP_PASS) või 1 (XDP_DROP) sõltuvalt sellest, kas abifunktsioon real 0 tagastas nulli või mitte-nullilise väärtuse.
Kontrollime end: laadime programmi ja vaatame väljundit bpftool prog dump xlated:
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simple &
[2] 10914
$ sudo bpftool p | grep simple
523: xdp name simple tag 44c38a10c657e1b0 gpl
pids xdp-simple(10915)
$ sudo bpftool p d x id 523
int simple(void *ctx):
; if (bpf_get_smp_processor_id() != 0)
0: (85) call bpf_get_smp_processor_id#114128
1: (bf) r1 = r0
2: (67) r1 <>= 32
4: (b7) r0 = 2
; }
5: (15) if r1 == 0x0 goto pc+1
6: (b7) r0 = 1
7: (95) exitHästi, verifier leidis õige kernel-helperi.
Näide: edastame argumendid ja lõpuks käivitame programmi!
Kõigil käivitusjärgsetel abifunktsioonidel on prototüüp
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)Parameetrid edastatakse abifunktsioonidele registrites r1—r5, ja väärtus tagastatakse registris r0. Funktsioone, mis võtavad rohkem kui viis argumenti — ei ole ja nende toe lisamist tulevikus ei kavandata.
Tutvume uue kernel helperiga ja sellega, kuidas BPF edastab parameetreid. Kirjutame ümber xdp-simple.bpf.c nagu allpool (ülejäänud read ei muutunud):
SEC("xdp/simple")
int simple(void *ctx)
{
bpf_printk("töötame CPU%un", bpf_get_smp_processor_id());
return XDP_PASS;
}Meie programm prindib välja CPU numbri, millel see töötab. Kompileerime selle ja vaatame koodi:
$ llvm-objdump -D --section=xdp/simple --no-show-raw-insn xdp-simple.bpf.o
0000000000000000 :
0: r1 = 10
1: *(u16 *)(r10 - 8) = r1
2: r1 = 8441246879787806319 ll
4: *(u64 *)(r10 - 16) = r1
5: r1 = 2334956330918245746 ll
7: *(u64 *)(r10 - 24) = r1
8: call 8
9: r1 = r10
10: r1 += -24
11: r2 = 18
12: r3 = r0
13: call 6
14: r0 = 2
15: exitRidades 0-7 kirjutame kuhja stringi töötame CPU%un, ja siis on ridal 8 käivitame meile tuttava bpf_get_smp_processor_id. Ridades 9-12 valmistame ette abifunktsiooni bpf_printk — registrid r1, r2, r3. Miks neid on kolm, mitte kaks? Sest bpf_printk — ümbritsev tõeline abifunktsioon bpf_trace_printk, millele tuleb edastada formaadirea suurus.
Nüüd lisame paar rida xdp-simple.c, et meie programm ühenduks liidesega lo ja tõeliselt käivituks!
$ cat xdp-simple.c
#include
#include
#include
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
__u32 flags = XDP_FLAGS_SKB_MODE;
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
bpf_set_link_xdp_fd(1, -1, flags);
bpf_set_link_xdp_fd(1, bpf_program__fd(obj->progs.simple), flags);
cleanup:
xdp_simple_bpf__destroy(obj);
}Siin kasutame funktsiooni bpf_set_link_xdp_fd, mis ühendab XDP tüüpi BPF programme võrguliidestega. Oleme kõvaketastanud liidese numbri, lomis on alati 1. Käivitame funktsiooni kaks korda, et kõigepealt katkestada vana programm, kui see oli ühendatud. Pange tähele, et nüüd ei ole meil vajadust spetsiaalse kutsumise järele pause või lõputu tsükkel: meie laadimisprogramm lõpetab töö, kuid BPF programm ei hävitatud, kuna see on ühendatud sündmuse allikaga. Pärast eduka laadimise ja ühendamise käivitub programm iga võrgu paketi jaoks, mis tuleb lo.
Laadime programmi ja vaatame liidest lo:
$ sudo ./xdp-simple
$ sudo bpftool p | grep simple
669: xdp name simple tag 4fca62e77ccb43d6 gpl
$ ip l show dev lo
1: lo: mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 669Laaditud programmil on ID 669 ja sama ID on nähtav liideses. lo. Saatke paar paketti aadressile 127.0.0.1 (taotlus + vastus):
$ ping -c1 localhostja vaatame nüüd silumise virtuaalse faili sisu /sys/kernel/debug/tracing/trace_pipe, kuhu bpf_printk oma sõnumeid kirjutab:
# cat /sys/kernel/debug/tracing/trace_pipe
ping-13937 [000] d.s1 442015.377014: bpf_trace_printk: running on CPU0
ping-13937 [000] d.s1 442015.377027: bpf_trace_printk: running on CPU0Kaks paketti tuvastati lo ja töödeldi CPU0-l — meie esimene tõeliselt mitteiuline BPF programm toimis!
Oluline on märkida, et bpf_printk kirjutab silumise faili põhjusel: see ei ole parim abi tootmisest kasutamiseks, kuid meie eesmärk oli näidata midagi lihtsat.
Access maps from BPF programs
Näide: kasutame BPF programmist mapi
Eelnevates osades õppisime looma ja kasutama mape kasutajaruumi, nüüd vaatame põhijagu. Alustada tuleks näitest. Kirjutame meie programmi ümber xdp-simple.bpf.c järgmiselt:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 8);
__type(key, u32);
__type(value, u64);
} woo SEC(".maps");
SEC("xdp/simple")
int simple(void *ctx)
{
u32 key = bpf_get_smp_processor_id();
u32 *val;
val = bpf_map_lookup_elem(&woo, &key);
if (!val)
return XDP_ABORTED;
*val += 1;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Programmi alguses lisasime mapi määratluse woo: see on 8 elemendist koosnev massiiv, mille sees on tüüpi u64 (C keeles määraksime selle massiivi kui u64 woo[8]). Programmis "xdp/simple" me saame praeguse protsessori numbri muutujasse key ja seejärel abifunktsiooni kaudu bpf_map_lookup_element saame vastava kirje viite massiivis, mille suurendame ühe võrra. Eestikeelsena: loeme statistikat selle kohta, millisel CPU-l on töödeldud sisendpakette. Proovime programmi käivitada:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simpleKontrollime, kas see on külge ühendatud lo ja saadame paar paketti:
$ ip l show dev lo
1: lo: mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 108
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; doneNüüd vaatame massiivi sisu:
$ sudo bpftool map dump name woo
[
{ "key": 0, "value": 0 },
{ "key": 1, "value": 400 },
{ "key": 2, "value": 0 },
{ "key": 3, "value": 0 },
{ "key": 4, "value": 0 },
{ "key": 5, "value": 0 },
{ "key": 6, "value": 0 },
{ "key": 7, "value": 46400 }
]Peaaegu kõik protsessid on töödeldud CPU7-l. See pole meile oluline, peamine on see, et programm töötab ja me mõistsime, kuidas pääseda BPF-programmidest ligipääsu kaartidele — abifunktsioonide kaudu .
Müstiline näidik
Nii saame BPF programmi abil juurde pääseda kaardile, tehes järgmisi kutsungeid
val = bpf_map_lookup_elem(&woo, &key);kus abifunktsioon näeb välja nagu
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)aga me edastame näidiku &woo nimetamata struktuuri struct { ... }…
Kui vaatame programmi assemblerit, siis näeme, et väärtus &woo ei ole tegelikult määratletud (rea 4):
llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: faili formaat elf64-bpf
Jaotus jaotises xdp/simple:
0000000000000000 :
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
...ja sisaldub relokatsioonides:
$ llvm-readelf -r xdp-simple.bpf.o | head -4
Relokatsioonide jaotis '.relxdp/simple' offset'is 0xe18 sisaldab 1 kirjet:
Offset Info Tüüp Sümboli väärtus Sümboli nimi
0000000000000020 0000002700000001 R_BPF_64_64 0000000000000000 wooAga kui vaatame juba laaditud programmi, siis näeme viidatud õigele kaardile (rea 4):
$ sudo bpftool prog dump x name simple
int simple(void *ctx):
0: (85) call bpf_get_smp_processor_id#114128
1: (63) *(u32 *)(r10 -4) = r0
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = kaardil[id:64]
...Nii saame järeldada, et meie laadimisprogrammi käivitamise hetkel viidati &woo millegagi, mille asendas teek libbpf. Alustuseks vaatame väljundit strace:
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, key_size=4, value_size=8, max_entries=8, map_name="woo", ...}, 120) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="simple", ...}, 120) = 5Näeme, et libbpf loodi kaart woo ja seejärel laadis meie programmi simple. Vaatame lähemalt, kuidas me programmi laadime:
- kutsume välja
xdp_simple_bpf__open_and_loadfailistxdp-simple.skel.h - mis kutsub välja
xdp_simple_bpf__loadfailistxdp-simple.skel.h - mis kutsub välja
bpf_object__load_skeletonfailistlibbpf/src/libbpf.c - mis kutsub välja
bpf_object__load_xattrkohastlibbpf/src/libbpf.c
Viimane funktsioon kutsub muuhulgas välja bpf_object__create_maps, mis loob või avab olemasolevad kaardid, muutes need failide descriptoriteks. (Siin näeme BPF_MAP_CREATE väljundis strace.) Edasi kutsutakse funktsioon bpf_object__relocate ja just see meid huvitab, kuna mäletame, et oleme näinud woo relokatsioonide tabelis. Uurides seda, jõuame lõpuks funktsiooni bpf_program__relocate, mis :
case RELO_LD64:
insn[0].src_reg = BPF_PSEUDO_MAP_FD;
insn[0].imm = obj->maps[relo->map_idx].fd;
break;Nii võtame meie käsu
18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 llja asendame selle registri-allika BPF_PSEUDO_MAP_FD, ja meie kaardi faili deskriptorile esimene IMM, ja kui see on näiteks 0xdeadbeef, siis saame me tulemuseks käsu
18 11 00 00 ef eb ad de 00 00 00 00 00 00 00 00 r1 = 0 llJust nii edastatakse kaarditeave konkreetse laaditud BPF programmi. Samal ajal võib kaart olla loodud BPF_MAP_CREATE, või avatud ID abil BPF_MAP_GET_FD_BY_ID.
Kokkuvõttes järgib see algoritmi: libbpf kompileerimise ajal luuakse kaardiviidete jaoks ümberpaigutustabeli kirjed
- ava ELF objekt, leidke kõik kasutatavad kaardid ja looge neile faili deskriptorid
libbpffaili deskriptorid laaditakse tuuma kui osa käsust- LD64
Kuidas te mõistate, see pole veel kõik ja me peame pilku tuumale viskama. Õnneks on meil vihje — oleme registreerinud väärtuse
allikas registrisse ja saame otsida, mis viib meid pühakotta, BPF_PSEUDO_MAP_FD , kus funktsioon iseloomuliku nimega asendab faili deskriptorit struktuuri aadressiga kernel/bpf/verifier.cstruct bpf_map static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) { ...f = fdget(insn[0].imm); map = __bpf_map_get(f); if (insn->src_reg == BPF_PSEUDO_MAP_FD) { addr = (unsigned long)map; } insn[0].imm = (u32)addr; insn[1].imm = addr >> 32;:
(täielikku koodi saab leida(täielik kood on saadaval ). Nii et saame täiendada oma algoritmi:
- programmi laadimise ajal kontrollib verifier kaardi korrektset kasutamist ja kirjutab vastava struktuuri aadressi
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) { ...f = fdget(insn[0].imm); map = __bpf_map_get(f); if (insn->src_reg == BPF_PSEUDO_MAP_FD) { addr = (unsigned long)map; } insn[0].imm = (u32)addr; insn[1].imm = addr >> 32;
ELF binaari laadimisel kasutades libbpf juhtuda veel palju sündmusi, kuid arutame seda teiste artiklite raames.
Laadime programme ja kaarte ilma libbpfita
Nagu lubatud, siin on näide lugejatele, kes soovivad teada, kuidas luua ja laadida programmi, mis kasutab kaarte, ilma abita libbpf. See võib olla kasulik, kui töötate keskkonnas, kus te ei saa sõltuvusi kokku panna, või säästate iga bitti, või kirjutate programmi, mis on , mis genereerib BPF binaarkoodi reaalajas.
Et oleks lihtsam järgida loogikat, kirjutame selle näite jaoks oma näite ümber xdp-simple. Selle näite arutamiseks oleva programmi täieliku ja veidi laiendatud koodi leiate sellest .
Meie rakenduse loogika on järgmine:
- luua kaarditüüp
BPF_MAP_TYPE_ARRAYkäsugaBPF_MAP_CREATE, - luua programm, mis kasutab seda kaarti,
- ühendada programm liidesele
lo,
mis tõlgitakse inimkeelde kui
int main(void)
{
int map_fd, prog_fd;
map_fd = map_create();
if (map_fd < 0)
err(1, "bpf: BPF_MAP_CREATE");
prog_fd = prog_load(map_fd);
if (prog_fd < 0)
err(1, "bpf: BPF_PROG_LOAD");
xdp_attach(1, prog_fd);
}Siit map_create loodab uusi mappi täpselt nagu me tegime seda esimeses näites süsteemikutsest , millel on järgmine prototüüp: — "tuum, palun tee mulle uus mapp, mis on 8 elementi tüüpi __u64 ja palun too mulle faili deskriptor":
static int map_create()
{
union bpf_attr attr;
memset(&attr, 0, sizeof(attr));
attr.map_type = BPF_MAP_TYPE_ARRAY,
attr.key_size = sizeof(__u32),
attr.value_size = sizeof(__u64),
attr.max_entries = 8,
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
return syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
}Programm laaditakse samuti lihtsalt:
static int prog_load(int map_fd)
{
union bpf_attr attr;
struct bpf_insn insns[] = {
...
};
memset(&attr, 0, sizeof(attr));
attr.prog_type = BPF_PROG_TYPE_XDP;
attr.insns = ptr_to_u64(insns);
attr.insn_cnt = sizeof(insns)/sizeof(insns[0]);
attr.license = ptr_to_u64("GPL");
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}Raskem osa prog_load — see on meie BPF programmi määratlemine struktuuride massiivina struct bpf_insn insns[]. Kuid kuna me kasutame C keeles kirjutatud programmi, saame natuke petta:
$ llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
0000000000000000 :
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
7: b7 01 00 00 00 00 00 00 r1 = 0
8: 15 00 04 00 00 00 00 00 if r0 == 0 goto +4
9: 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0)
10: 07 01 00 00 01 00 00 00 r1 += 1
11: 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1
12: b7 01 00 00 02 00 00 00 r1 = 2
0000000000000068 :
13: bf 10 00 00 00 00 00 00 r0 = r1
14: 95 00 00 00 00 00 00 00 exitKokkuvõttes peame kirjutama 14 käsku struktuuri tüüpidena struct bpf_insn (soovitus: võtke ülalolev dump, lugege läbi juhend käskude kohta, avage ja ja proovige määrata struct bpf_insn insns[] ise):
struct bpf_insn insns[] = {
/* 85 00 00 00 08 00 00 00 call 8 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 8,
},
/* 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0 */
{
.code = BPF_MEM | BPF_STX,
.off = -4,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_10,
},
/* bf a2 00 00 00 00 00 00 r2 = r10 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_10,
.dst_reg = BPF_REG_2,
},
/* 07 02 00 00 fc ff ff ff r2 += -4 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_2,
.imm = -4,
},
/* 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll */
{
.code = BPF_LD | BPF_DW | BPF_IMM,
.src_reg = BPF_PSEUDO_MAP_FD,
.dst_reg = BPF_REG_1,
.imm = map_fd,
},
{ }, /* placeholder */
/* 85 00 00 00 01 00 00 00 call 1 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 1,
},
/* b7 01 00 00 00 00 00 00 r1 = 0 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 0,
},
/* 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2> */
{
.code = BPF_JMP | BPF_JEQ | BPF_K,
.off = 4,
.src_reg = BPF_REG_0,
.imm = 0,
},
/* 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0) */
{
.code = BPF_MEM | BPF_LDX,
.off = 0,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_1,
},
/* 07 01 00 00 01 00 00 00 r1 += 1 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 1,
},
/* 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1 */
{
.code = BPF_MEM | BPF_STX,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* b7 01 00 00 02 00 00 00 r1 = 2 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 2,
},
/* <LBB0_2>: bf 10 00 00 00 00 00 00 r0 = r1 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* 95 00 00 00 00 00 00 00 exit */
{
.code = BPF_JMP | BPF_EXIT
},
};Harjutus neile, kes ei hakanud seda ise kirjutama — leidke map_fd.
Meie programmis on veel üks avaldamata osa — xdp_attach. Kahjuks ei saa XDP-tüüpi programme liita süsteemikõne abil , millel on järgmine prototüüp:. Inimesed, kes lõid BPF-i ja XDP-d, olid Linuxi võrguühiskonnast, mistõttu kasutasid nad neile tuttavat (kuid mitte tavalistele inimestele) suhtluse liidest kerneliga: , vt ka . Kõige lihtsam viis ellu viia xdp_attach — on koodi kopeerimine failist libbpf, nimelt failist , mida me ka tegime, seda veidi lühendades:
Tere tulemast netlink socketide maailma
Avame netlink socketi tüübiga NETLINK_ROUTE:
int netlink_open(__u32 *nl_pid)
{
struct sockaddr_nl sa;
socklen_t addrlen;
int one = 1, ret;
int sock;
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
if (sock < 0)
err(1, "socket");
if (setsockopt(sock, SOL_NETLINK, NETLINK_EXT_ACK, &one, sizeof(one)) < 0)
warnx("netlinki veateade ei ole toetatud");
if (bind(sock, (struct sockaddr *)&sa, sizeof(sa)) < 0)
err(1, "bind");
addrlen = sizeof(sa);
if (getsockname(sock, (struct sockaddr *)&sa, &addrlen) < 0)
err(1, "getsockname");
*nl_pid = sa.nl_pid;
return sock;
}Lugemine sellisest socketist:
static int bpf_netlink_recv(int sock, __u32 nl_pid, int seq)
{
bool multipart = true;
struct nlmsgerr *errm;
struct nlmsghdr *nh;
char buf[4096];
int len, ret;
while (multipart) {
multipart = false;
len = recv(sock, buf, sizeof(buf), 0);
if (len nlmsg_pid != nl_pid)
errx(1, "wrong pid");
if (nh->nlmsg_seq != seq)
errx(1, "INVSEQ");
if (nh->nlmsg_flags & NLM_F_MULTI)
multipart = true;
switch (nh->nlmsg_type) {
case NLMSG_ERROR:
errm = (struct nlmsgerr *)NLMSG_DATA(nh);
if (!errm->error)
continue;
ret = errm->error;
// libbpf_nla_dump_errormsg(nh); too many code to copy...
goto done;
case NLMSG_DONE:
return 0;
default:
break;
}
}
}
ret = 0;
done:
return ret;
}Lõpuks, siin on meie funktsioon, mis avab soketi ja saadab sellesse spetsiaalse sõnumi, mis sisaldab failide deskriptorit:
static int xdp_attach(int ifindex, int prog_fd)
{
int sock, seq = 0, ret;
struct nlattr *nla, *nla_xdp;
struct {
struct nlmsghdr nh;
struct ifinfomsg ifinfo;
char attrbuf[64];
} req;
__u32 nl_pid = 0;
sock = netlink_open(&nl_pid);
if (sock nla_type = NLA_F_NESTED | IFLA_XDP;
nla->nla_len = NLA_HDRLEN;
/* add XDP fd */
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FD;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(int);
memcpy((char *)nla_xdp + NLA_HDRLEN, &prog_fd, sizeof(prog_fd));
nla->nla_len += nla_xdp->nla_len;
/* if user passed in any flags, add those too */
__u32 flags = XDP_FLAGS_SKB_MODE;
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FLAGS;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(flags);
memcpy((char *)nla_xdp + NLA_HDRLEN, &flags, sizeof(flags));
nla->nla_len += nla_xdp->nla_len;
req.nh.nlmsg_len += NLA_ALIGN(nla->nla_len);
if (send(sock, &req, req.nh.nlmsg_len, 0) < 0)
err(1, "send");
ret = bpf_netlink_recv(sock, nl_pid, seq);
cleanup:
close(sock);
return ret;
}Nüüd on kõik testimiseks valmis:
$ cc nolibbpf.c -o nolibbpf
$ sudo strace -e bpf ./nolibbpf
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, map_name="woo", ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=15, prog_name="woo", ...}, 72) = 4
+++ exited with 0 +++Vaadatakse, kas meie programm on ühendatud lo:
$ ip l show dev lo
1: lo: mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 160Saadame pingid ja vaatame kaarti:
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; done
$ sudo bpftool m dump name woo
key: 00 00 00 00 value: 90 01 00 00 00 00 00 00
key: 01 00 00 00 value: 00 00 00 00 00 00 00 00
key: 02 00 00 00 value: 00 00 00 00 00 00 00 00
key: 03 00 00 00 value: 00 00 00 00 00 00 00 00
key: 04 00 00 00 value: 00 00 00 00 00 00 00 00
key: 05 00 00 00 value: 00 00 00 00 00 00 00 00
key: 06 00 00 00 value: 40 b5 00 00 00 00 00 00
key: 07 00 00 00 value: 00 00 00 00 00 00 00 00
Found 8 elementsHurraa, kõik töötab. Pange tähele, et meie kaart kuvab end taas baitidena. See juhtub, kuna erinevalt libbpf me ei ole laadinud tüüpide teavet (BTF). Kuid räägime sellest rohkem järgmisel korral.
Arendustööriistad
Selles osas vaatame BPF arendaja minimaalse tööriistakomplekti.
Üldiselt ei ole BPF programmide arendamiseks midagi erilist vajalik — BPF töötab igas korralikus jaotuses tuumaga ning programmid kompileeritakse abiga clang, mida saab pakettide kaudu installida. Kuna BPF on arendusfaasis, muutuvad tuum ja tööriistad pidevalt. Kui te ei soovi kirjutada BPF programme vana moe järgi 2019. aastast, siis peate kokku panema
llvm/clangpahole- oma tuuma
bpftool
(Teabe jaoks: see ja kõik artikli näited käivitati Debian 10-l.)
llvm/clang
BPF töötab koos LLVM-ga, ja kuigi hiljuti saab BPF programme kompileerida ka gcc abil, toimub kogu praegune arendus LLVM jaoks. Seetõttu kogume kõigepealt praeguse versiooni clang git-ist:
$ sudo apt install ninja-build
$ git clone --depth 1 https://github.com/llvm/llvm-project.git
$ mkdir -p llvm-project/llvm/build/install
$ cd llvm-project/llvm/build
$ cmake .. -G "Ninja" -DLLVM_TARGETS_TO_BUILD="BPF;X86"
-DLLVM_ENABLE_PROJECTS="clang"
-DBUILD_SHARED_LIBS=OFF
-DCMAKE_BUILD_TYPE=Release
-DLLVM_BUILD_RUNTIME=OFF
$ time ninja
... palju aega hiljem
$Nüüd saame kontrollida, kas kõik on õigesti kokku pandud:
$ ./bin/llc --version
LLVM (http://llvm.org/):
LLVM versioon 11.0.0git
Optimeeritud build.
Vaikesiht: x86_64-unknown-linux-gnu
Host CPU: znver1
Registreeritud sihtmärgid:
bpf - BPF (host endian)
bpfeb - BPF (suur endiaan)
bpfel - BPF (väike endiaan)
x86 - 32-bitine X86: Pentium-Pro ja uuemad
x86-64 - 64-bitine X86: EM64T ja AMD64(Kogumise juhend clang on minu poolt võetud .)
Me ei hakka installima just kokku pandud programme, vaid lisame need lihtsalt PATH, näiteks:
export PATH="`pwd`/bin:$PATH"(Seda saab lisada .bashrc või eraldi faili. Isiklikult lisatakse sellised asjad ~/bin/activate-llvm.sh ja kui on vaja, teen . activate-llvm.sh.)
Pahole ja BTF
Tööriist pahole kasutatakse tuuma kompileerimisel BTF formaadis silumise teabe loomiseks. Me ei hakka selles artiklis BTF tehnoloogia üksikasjadesse laskuma, välja arvatud see, et see on mugav ja me tahame seda kasutada. Seega, kui kavatsete oma tuuma kompileerida, kompileerige esmalt pahole (ilma pahole te ei saa kompileerida tuuma valikuga CONFIG_DEBUG_INFO_BTF:
$ git clone https://git.kernel.org/pub/scm/devel/pahole/pahole.git
$ cd pahole/
$ sudo apt install cmake
$ mkdir build
$ cd build/
$ cmake -D__LIB=lib ..
$ make
$ sudo make install
$ which pahole
/usr/local/bin/paholeTuuma eksperimenteerimiseks BPF-iga
BPF võimaluste uurimisel soovitakse koostada oma kernel. Üldiselt ei ole see vajalik, kuna saate koguda ja laadida BPF programme ka jaotuse kerneliga, kuid oma kernel võimaldab kasutada kõige uuemaid BPF funktsioone, mis jõuavad teie jaotusse parimal juhul kuude pärast või, nagu mõne silumise tööriista puhul, ei paketita neid lähitulevikus üldse. Samuti annab oma kernel võimaluse end tähtsana tunda ning katsetada koodiga.
Kernel'i ülesehitamiseks on teie vajaduses, esiteks, see ise ja teiseks, kernel'i konfiguratsioonifail. BPF katsetamiseks võime kasutada tavalist kerneid või ühte arenduskernel'ist. Ajalooliselt toimub BPF arendus Linuxi võrgukohtades ning seetõttu läbivad kõik muudatused varem või hiljem David Milleri (David Miller) — Linuxi võrguosade haldaja. Sõltuvalt oma olemusest — muudatused või uued funktsioonid — jõuavad võrgu muudatused ühte kahest kernel'ist — või . BPF muudatused jaotatakse samuti ja , mis siis saadetakse net'i ja net-next'i, vastavalt. Lisainfot vaata ja . Nii et vali kernel vastavalt oma maitsele ja süsteemi stabiilsuse vajadustele, millel sa testid (*-next kerneli versioonid on kõige ebastabiilsemad loetletud).
Käesoleva artikli raames ei käsitleta, kuidas kärni konfiguratsioonifailidega hakkama saada — arvestatakse, et sa kas juba oskad seda teha või ise. Siiski, järgmised juhised peaksid olema rohkem-vähem piisavad, et sul oleks töötav süsteem, mis toetab BPF-i.
Laadi alla üks ülalmainitud kerneli versioonidest:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git
$ cd bpf-nextKogu minimaalne töötav kernelein konfiguratsioon:
$ cp /boot/config-`uname -r` .config
$ make localmodconfigLülita BPF valikud sisse failis .config oma valiku järgi (tõenäoliselt, ise CONFIG_BPF on juba sisse lülitatud, kuna seda kasutab systemd). Siin on valik kernelivalikutest, mida selle artikli koostamisel kasutati:
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_LSM=y
CONFIG_BPF_SYSCALL=y
CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_IPV6_SEG6_BPF=y
# CONFIG_NETFILTER_XT_MATCH_BPF ei ole seadistatud
# CONFIG_BPFILTER ei ole seadistatud
CONFIG_NET_CLS_BPF=y
CONFIG_NET_ACT_BPF=y
CONFIG_BPF_JIT=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
CONFIG_DEBUG_INFO_BTF=ySeejärel saame hõlpsasti mooduleid ja kernelit kompileerida ja installida (muide, kernelit saab kompileerida just eelmisega clang, lisades CC=clang):
$ make -s -j $(getconf _NPROCESSORS_ONLN)
$ sudo make modules_install
$ sudo make installja taaskäivitama uue kerneli (kasutan selleks kexec pakett kexec-tools):
v=5.8.0-rc6+ # kui teete praeguse kerneli ümberkompileerimist, siis võib teha v=`uname -r`
sudo kexec -l -t bzImage /boot/vmlinuz-$v --initrd=/boot/initrd.img-$v --reuse-cmdline &&
sudo kexec -ebpftool
Käesolevas artiklis kõige sagedamini kasutatav utiliit on bpftool, mis on kaasas Linuxi kernega. See on kirjutatud ja hooldatud BPF arendajate poolt BPF arendajate jaoks ning selle abil saab hallata kõiki BPF objekti tüüpe — programme laadida, kaarte luua ja muuta, uurida BPF ökosüsteemi elu jne. Dokumentatsiooni allika kujul man-pages'i kohta võib leida või juba kompileerituna, .
Artikli kirjutamise hetkel bpftool toodetakse valmisseatud kujul ainult RHEL-i, Fedora ja Ubuntu jaoks (vt näiteks , mis räägib lõpetamata loo pakendamisest bpftool Debianis). Kuid kui olete oma tuuma juba kokku pannud, siis on kokku panna bpftool kergemast kergem:
$ cd ${linux}/tools/bpf/bpftool
# ... sisestage teed viimasele clangile, nagu eespool kirjeldatud
$ make -s
Süsteemi omaduste automaatne tuvastamine:
... libbfd: [ on ]
... disassembler-four-args: [ on ]
... zlib: [ on ]
... libcap: [ on ]
... clang-bpf-co-re: [ on ]
Süsteemi omaduste automaatne tuvastamine:
... libelf: [ on ]
... zlib: [ on ]
... bpf: [ on ]
$(siin ${linux} — see on teie tuuma kaust.) Pärast nende käskude täitmist bpftool koostatakse kausta ${linux}/tools/bpf/bpftool ja seda saab lisada teele (esmaselt kasutajale root) või lihtsalt kopeerida /usr/local/sbin.
Koostamine bpftool on parim teostada viimasega clang, mis on kokku pandud, nagu eespool kirjeldatud, ja kontrollida, kas see on õigesti kokku pandud - näiteks käsuga
$ sudo bpftool feature probe kernel
Skaneerimine süsteemi konfiguratsioon...
bpf() syscall unprivileegitud kasutajatele on lubatud
JIT-komplekt on lubatud
JIT-komplektide tugevdamine on keelatud
JIT-komplekt kallsyms ekspordid on juur kasutajatele lubatud
...mis näitab, millised BPF-i omadused on teie tuumas sisse lülitatud.
Muide, eelmist käsku saab käivitada kui
# bpftool f p kSee on tehtud sarnaselt paketist pärit utiliitidele iproute2, kus me võime näiteks öelda ip a s eth0 asetatakse ip addr show dev eth0.
Kokkuvõte
BPF võimaldab põhilisel tasemel tõhusalt mõõta ja kohandada tuuma funktsionaalsust. Süsteem on väga edukas, järgides parimaid UNIX'i traditsioone: lihtne mehhanism, mis võimaldab (uuesti) programmeerida tuuma, on andnud võimaluse paljudele inimestele ja organisatsioonidele eksperimenteerida. Ja kuigi eksperimendid, nagu ka BPF infrastruktuuri areng, pole veel kaugel lõpetamisest, on süsteemil juba stabiilne ABI, mis võimaldab üles ehitada usaldusväärset ja, mis kõige tähtsam, tõhusat äriloogikat.
Tahaksin märkida, et minu arvates on tehnoloogia saanud nii populaarseks just seepärast, et ühel poolt saab sellega mängida (masina arhitektuuri on võimalik enam-vähem mõista ühe õhtu jooksul), kuid teisest küljest — lahendada probleeme, mida ei saanud (ilusalt) enne selle ilmumist lahendada. Need kaks komponenti koos panevad inimesi eksperimenteerima ja unistama, mis toob endaga kaasa üha uusi ja uusi innovaatilisi lahendusi.
Kuigi see artikkel ei ole eriti lühike, on see vaid sissejuhatus BPF maailma ning ei käsitle „edasijõudnud” võimalusi ega olulisi arhitektuuri osi. Edasi liikudes on plaan järgmine: järgmine artikkel tutvustab BPF programmide tüüpe (tuumas 5.8 toetatakse 30 programmi tüüpi), seejärel vaatame, kuidas kirjutada tõelisi BPF rakendusi tuuma jälgimise programmide näitel, pärast seda tuleb süvitsi minek BPF arhitektuuri kursusele, ning lõpuks näited BPF võrgu- ja turvarakendustest.
Selle tsükli eelnevad artiklid
Lingid
— BPF dokumentatsioon Ciliumilt, täpsemalt Daniel Borkmanilt, ühelt BPF loojalt ja hooldajalt. See on üks esimesi tõsiseid kirjeldusi, mis eristub teistest sellega, et Daniel teab täpselt, millest ta räägib, ning vigu seal ei esine. Eriti selgitatakse, kuidas töötada XDP ja TC tüüpi BPF programmidega tuntud utiliidi abil.
ippakettiproute2.— originaaldokument klassikalise ja seejärel laiendatud BPF-i kohta. Kasulik lugeda, kui soovite süveneda assemblerisse ja tehnilistesse detailidesse.
. Uuendatakse harva, kuid täpselt, sest kirjutavad Alexei Starovoitov (eBPF autor) ja Andrii Nakryiko — (hooldaja
libbpf).. Huvitav Twitteri teema Quentin Monnetilt bpftooli kasutamise näidete ja saladustega.
. Hiiglaslik (ja endiselt hooldatav) BPF-i dokumentatsiooni linkide loetelu Quentin Monnetilt.
Allikas: habr.com
