


Yandexi panus järgmiste andmebaaside arendamisse.
- ClickHouse
- Odyssey
- Ajaloolise taastamine (WAL-G)
- PostgreSQL (sealhulgas logerrors, Amcheck, heapcheck)
- Greenplum
Video:

Tere maailm! Minu nimi on Andrei Borodin. Yandex.Cloud'is töötan avatud relatsiooniliste andmebaaside arendamisega Yandex.Cloudi ja Yandex.Cloudi klientide huvides.

Selles ettekandes räägime probleemidest, millega avatud andmebaasid silmitsi seisavad suurel skaalal. Miks see on oluline? Sest väikesed probleemid, nagu sääsed, võivad hiljem muutuda elevantideks. Need muutuvad suurteks, kui teil on palju klastreid.
Kuid see ei ole peamine. Toimuvad uskumatud asjad. Asjad, mis juhtuvad ühes miljonis juhusest. Ja pilvekeskkonnas peate olema poolest saadik valmis, sest uskumatud asjad muutuvad üsna tõenäoliseks, kui midagi eksisteerib suurel skaalal.
Aga! Milles on avatud andmebaaside eelis? Teil on teoreetiline võimalus iga probleemiga tegeleda. Teil on lähtekood ja programmeerimise teadmised. Ühendame ja see töötab.

Millised lähenemisviisid on avatud tarkvara arendamisel?
- Kõige arusaadavam lähenemine on tarkvara kasutamine. Kui kasutate protokolle, kui järgite standardeid, kui kasutate formaate, kui kirjutate avatud lähtekoodiga tarkvara jaoks päringuid, siis toetate te seda juba.
- Teete selle ökosüsteemi suuremaks. Suurendate tõenäosust, et viga avastatakse varem. Parandate selle süsteemi usaldusväärsust. Suuate arendajate kättesaadavust turul. Parandate seda tarkvara. Te olete juba kaasautor, kui olete lihtsalt stiili üles toonud ja seal midagi nokitsenud.
- Teine arusaadav lähenemine on avatud tarkvara rahastamine. Näiteks tuntud programm Google Summer of Code, kus Google maksab paljudele tudengitele üle kogu maailma arusaadavat raha avatud tarkvaraprojektide arendamiseks, mis vastavad teatud litsentsinõuetele.
- See on väga huvitav lähenemine, kuna see võimaldab arendada tarkvara, mitte kõrvale suunata kogukonna fookust. Google, kui tehnoloogia hiiglane, ei ütle, et me tahame seda funktsiooni, soovime lahendada seda viga ja seal tuleb sügavamale minna. Google ütleb: „Tehke seda, mida teete. Lihtsalt jätkake oma tavapärast tööd ja kõik läheb hästi.“
- Järgmine osalemise lähenemine avatud lähtekoodiga on kaasõhutus. Kui teil on probleeme avatud tarkvaraga ja on arendajad, hakkavad teie arendajad neid probleeme lahendama. Nad teevad teie infrastruktuuri tõhusamaks, teie programmidest kiiremad ja usaldusväärsemad.

Üks tuntumaid Yandexi projekte avatud lähtekoodi valdkonnas on ClickHouse. See on andmebaas, mis sündis vastusena Yandex.Metrika ees seisvatele väljakutsetele.
Ja kui andmebaas, loodi see avatud lähtekoodina, et luua ökosüsteemi ja koostöös teiste arendajatega (mitte ainult Yandexi sees) seda arendada. Ja praegu on see suur projekt, milles osaleb palju erinevaid ettevõtteid.

Yandex Cloud'is oleme ClickHouse'i rakendanud Yandex Object Storage'i peal, st pilvehoidla peal.
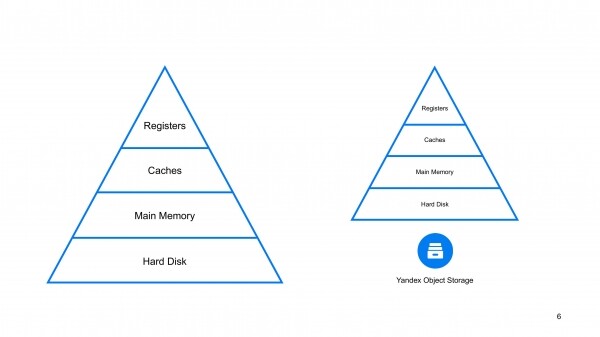
Miks on see just pilves oluline? Sest iga andmebaas töötab selles kolmnurgas, selles püramiidis, selles mälu tüüpide hierarhias. Teil on kiired, kuid väikesed registrid ja odavad suured, kuid aeglasemad SSD-diskid, kõvakettad ja muud plokk-seadmed. Ja kui olete tõhus püramiidi tipus, siis on teie andmebaas kiire. Kui olete tõhus püramiidi põhjas, siis on teie andmebaas skaleeritav. Ja sellega seoses on veel ühe kihi lisamine põhjas mõistlik lähenemine andmebaasi skaleeritavuse suurendamiseks.

Kuidas seda ellu viia? See on oluline punkt selles ettekandes.
- Me oleksime võinud rakendada ClickHouse'i MDS üle. MDS on Yandexi sisemine pilvehoidla liides. See on keerulisem kui laialdaselt kasutatav S3 protokoll, kuid sobib paremini plokk-seadmestikule. See sobib paremini andmete kirjutamiseks. See nõuab rohkem programmeerimist. Programmi arendajad teevad tööd, see on isegi hea, huvitav.
- S3 – laialdaselt levinud lähenemine, mis loob lihtsama liidese, kuid alandab kohandamise taset teatud tüüpi koormuste jaoks.
Soovides loomulikult pakkuda funktsionaalsust kogu ClickHouse ökosüsteemis ja lahendada ülesanne, mis on vajalik Yandex.Cloudis, otsustasime, et sellel peab olema mõju kogu ClickHouse kogukonnale. Rakendasime ClickHouse'i üle S3, mitte ClickHouse'i üle MDS. See on tohutu hulk tööd.

Lingid:
„Failisüsteemi abstraktsioonikiht”
„AWS SDK S3 integraatsioon”
„IDisk liidese baasseadme rakendus S3 jaoks”
„Logi salvestusmootorite integreerimine IDisk liidesega”
„Logi mootori tugi S3 ja SeekableReadBuffer jaoks”
„Storage Stripe Log S3 tugi”
„Storage MergeTree algtugi S3 jaoks”
„MergeTree täielik tugi S3 jaoks”
„ReplicatedMergeTree tugi S3 üle”
„Lisa vaikimisi mandaadid ja kohandatud päised S3 salvestusele”
„S3 dünaamilise vaheühenduse seadistusega”
„S3 koos vaheühenduse lahendajaga”
See on pull requestide nimekiri, et rakendada ClickHouse'is virtuaalset failisüsteemi. See hõlmab suurt arvu pull request'e.

Lingid:
„DiskS3 kõv.linkide optimaalne rakendus”
„S3 HTTP klient — vältige vastuse voolu kopeerimist mällu”
„Vältige kogu vastuse voolu kopeerimist mällu S3 HTTP
klient»
„Võimalus vahemällu salvestada märk ja indeksifailid S3 kettale”
„Liigutage osi DiskLocal'ist DiskS3-sse paralleelselt”
Kuid see ei ole veel kõik. Pärast funktsiooni valmimist tuli teha veel palju tööd, et optimeerida seda funktsionaalsust.

Lingid:
«Lisa SelectedRows ja SelectedBytes sündmused»
«Lisa profiliseerimise sündmused S3 päringust süsteemi.sündmustesse»
«Lisa QueryTimeMicroseconds, SelectQueryTimeMicroseconds ja InsertQueryTimeMicroseconds»
Ja siis oli vaja teha see diagnostiseeritavaks, seadistada seire ja muuta see hallatavaks.
Ja kõik see tehti nii, et kogu ClickHouse kogukond, kogu ökosüsteem saaks tulemused sellest tööst.

Liigume edasi tehingute andmebaaside, OLTP andmebaaside suunas, mis on minu jaoks lähemal.

See on avatud koodiga andmebaasi arenduse haru. Need poisid teevad tänavamagiasi, et parandada tehingute avatud andmebaase.
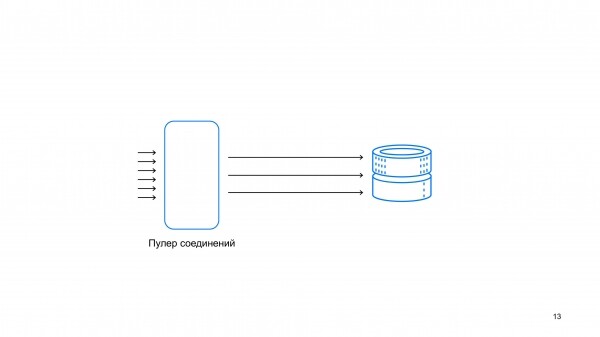
Üks projekt, mille kaudu saab rääkida, kuidas ja mida me teeme, on ühenduste tõmbur Postgresis.
Postgres on protsessipõhine andmebaas. See tähendab, et andmebaasi peaks minema võimalikult vähe võrguühendusi, mis tegelevad tehingutega.
Teisest küljest on pilvekeskkonnas tüüpiline olukord, kus ühte klastrisse jõuab korraga tuhat ühendust. Ühenduse balanseerija ülesanne on need tuhat ühendust kompaktseteks serveriühendusteks kokku pakkida.

Võib öelda, et ühenduse balanseerija on telefonist, kes suunab bite nii, et need jõuavad andmebaasi tõhusalt.
Kahjuks ei ole head eesti sõna ühenduse balanseerija jaoks. Mõnikord nimetatakse seda ühenduste multiplexeriks. Kui teate, kuidas öelda connection pooler eesti keeles, andke mulle kindlasti teada, ma oleksin väga rõõmus rääkida õige eesti tehnilise keele järgi.
Oleme uurinud ühenduse balanseerijaid, mis sobiksid hallatavale postgres' kliendiklasterile. Meile sobis kõige paremini PgBouncer. Kuid oleme PgBounceriga silmitsi seisnud mitmete probleemidega. Aastaid tagasi rääkis Volodja Borodin sellest, et me kasutame PgBouncet, meile meeldib see, kuid on nüansse, millega tuleb tööd teha.
Ja me tegime tööd. Need probleemid, millega silmitsi seisisime, parandasime, patšime Bouncerit ning püüdsime saata pull requeste upstream'i. Kuid põhjaliku ühesuunalisusega oli keeruline töötada.
Me pidime koguda kaskade muudetud Bouncers'itega. Kui meil on palju ühe niidi Bouncers'eid, siis ülemise tasandi Bouncers'ded aitavad suunata ühendusi sisemise tasandi Bouncers'itesse. See on halvasti juhitav ning keeruline süsteem ehitamiseks ja skaleerimiseks edasi-tagasi.

Oleme loonud oma ühenduste halduri, mida nimetatakse Odyssey. Kirjutasime selle nullist.

2019. aastal esitlesin ma seda haldurit PgCon konverentsil arendajate kogukonnale. Hetkel on meil veidi vähem kui 2000 tähte GitHubis, st projekt elab ja on populaarne.
Ja kui loote Postgresi klastri Yandex.Cloudis, siis saab sellest klaster, mille sees on integreeritud Odyssey, mis kohandub klastrite skaleerimisega edasi-tagasi.

Mida me selle projekti käigus õppisime? Konkurentsivõimelise projekti käivitamine on alati agressiivne samm, äärmuslik lahendus, kui me ütleme, et on probleeme, mis ei lahene kiiresti piisavalt, mida ei lahendata meie jaoks sobivates ajavahemikes. Kuid see on tõhus meetod.
PgBouncer hakkas kiiresti arenema.
Ja nüüd on tekkinud teised projektid. Näiteks pgagroal, mille arendavad Red Hat'i arendajad. Neil on sarnased eesmärgid ja nad realiseerivad sarnaseid ideid, kuid omamoodi oma spetsiifikaga, mis on lähemal pgagroal'i arendajatele.

Veel üks näide Postgres'i kogukonnaga töötamisest on taastamine ajapunktist. See on taastamine pärast tõrget, taastamine varukoopiast.

Varukoopia lahendusi on palju ja need kõik on erinevad. Peaaegu igal Postgres'i pakkujal on oma varukoopia lahendus.
Kui võtta kõik varundussüsteemid, koostada funktsioonide maatriks ja naljatledes arvutada selle maatriksi determinant, siis see oleks null. Mida see tähendab? Et kui võtta mingi konkreetne varukoopia lahendus, siis ei saa seda kokku panna kõigi teiste osade põhjal. See on oma rakenduses ainulaadne, oma otstarbel ainulaadne, oma ideedelt ainulaadne. Ja kõik need on spetsiifilised.
Kui me selle küsimusega tegelesime, käivitas ettevõte CitusData WAL-G projekti. See on varundussüsteem, mis on loodud pilvekeskkonna jaoks. Praegu on CitusData juba Microsofti osa. Sel hetkel meeldisid meile väga algsete WAL-G väljaannete ideed. Ja me hakkasime sellesse projekti panustama.
Praegu on selles projektis palju kümneid arendajaid, kuid WAL-G kümne parima panustaja hulka kuulub 6 yandexoid. Oleme sinna toonud palju oma ideid. Ja loomulikult oleme need ise ellu viinud, ise testinud, ise tootmisse viinud, ise kasutame neid ja ise mõtleme, kuhu edasi liikuda, samal ajal tegutsedes suure WAL-G kogukonnaga.

Ja meie arvates on nüüd see varundussüsteem, arvestades meie pingutusi, pälvinud parimaks pilvekeskkonnas. See on parem, kui varundada Postgresit pilves.
Mis see tähendab? Me edendasime piisavalt suurt ideed: varundamine peaks olema ohutu, odav ja maksimaalselt kiire taastamisel.
Miks see peaks olema töö käigus odav? Kui midagi ei purunenud, ei pea te teadma, et teil on varukoopiaid. Kõik töötab normaalselt, kasutate võimalikult vähe protsessorit, kasutate võimalikult vähe oma kettaressursse ja edastate võimalikult vähe baite võrku, et mitte segada teie väärtuslike teenuste kasulikku koormust.
Ja kui kõik puruneb, näiteks admin viskas andmed minema, läks midagi valesti ja peate kiiresti tagasi minevikku, taastate end maksimumi eest, sest te tahate oma andmeid kiiresti ja tervena tagasi saada.
Ja me edendasime seda lihtsat ideed. Ja, nagu me tunneme, oleme suutnud selle ellu viia.

Aga see ei ole veel kõik. Me soovisime veel ühte väikest asja. Soovisime palju erinevaid andmebaase. Mitte kõik meie kliendid ei kasuta Postgresi. Mõned kasutavad MySQL-i, MongoDB-d. Teised arendajad kogukonnas toetasid FoundationDB-d. Ja see nimekiri laieneb pidevalt.
Mõte, et andmebaas töötab hallatud keskkonnas pilves, meeldib kogukonnale. Arendajad toetavad oma andmebaase, mida ühtlaselt koos Postgresiga meie varukoopiate süsteemiga saab kopeerida.

Mida me sellest loost oleme õppinud? Meie toode, kui arenduse allüksus, ei ole koodiread, ei ole operaatorid, ei ole failid. Meie toode ei ole pull request'id. Need on ideed, mida me edastame kogukonnale. See on tehniline ekspertiis ja tehnoloogia liikumine pilves olevatesse keskkondadesse.

On olemas andmebaas, nagu Postgres. Mulle meeldib Postgresi tuum kõige rohkem. Ma kulutan palju aega, et arendada Postgresi tuuma koos kogukonnaga.

Aga siin tuleb öelda, et Yandex.Cloud'il on hallatud andmebaaside sisene paigaldus. Ja see algas ammu Yandex.Mailis. See ekspertiis, mis viis meid hallatud Postgresi, kogunes siis, kui postiteenus soovis siseneda Postgresisse.
Postita nõudmised sarnanevad pilve nõudmistega. See vajab, et saaksite skaleerida ootamatute eksponentsiaalsete kasvude korral teie andmetes. Ja postil on juba olnud koormus sadade miljonite postkastidega tohutul hulgal kasutajatelt, kes pidevalt esitavad palju päringuid.
See oli üsna tõsine väljakutse Postgresi arendamise meeskonnale. Kõik probleemid, millega silmitsi seisime, kanti kogukonnale edasi. Need probleemid lahendati ning kohati isegi paremini kui mõnede teiste andmebaaside tasulise toe tasemel. Ehk siis, kui saatsite kirja PgSQL häkkerile, võisite vastuse saada 40 minuti jooksul. Tasuline tugi mõnes andmebaasis võib arvata, et on teie veast prioriteetsed asjad.
Praeguseks on Postgresi sisene paigaldus petabaidandmeid. See genereerib miljoneid päringuid sekundis. Need on tuhanded klastrid. See on väga skaleeritav.
Kuid on üks nüanss. See ei tööta moodsates võrgukettas, vaid üsna lihtsal riistvaral. Seal on testimisprotseduur uute huvitavate asjade jaoks.

Ja mingil hetkel testkeskkonnas saime sellise sõnumi, mis näitas, et andmebaasi indeksite sisemised invariantid on rikutud.
Invariandiks on mingi suhe, mida me eeldame, et see on alati kehtiv.
See on meie jaoks väga kriitiline olukord. See viitab sellele, et mingid andmed on tõenäoliselt kaotsi läinud. Andmete kaotus on midagi täiesti katastroofilist.
Üldine idee, mida me hallatavate andmebaaside puhul järgime, on see, et isegi pingutades on andmete kaotamine keeruline. Isegi kui te need sihikindlalt kustutate, peate ka ignoreerima nende puudumist pika aja jooksul. Andmete säilitamine on religioon, mida me järgime üsna tõsiselt.
Aga siin tekib olukord, mis ütleb, et võib olla olukord, milleks me ei pruugi valmis olla. Ja me hakkasime valmistuma selle olukorra jaoks.
Esimene asi, mida tegime, oli logide skaneerimine neist tuhandest klastrist. Me leidsime, millised klastrid paiknevad probleemsete püsivaimudega ketastel, mis kaotasid andmete lehtede uuenduse. Me tähistasime kogu PostgreSQL koodipõhja. Ja need teated, mis viitavad sisemiste invariandide rikkumisele, märgistasime koodiga, mis on mõeldud andmepettuste avastamiseks.
See patch võeti kogukonna poolt praktiliselt vastu ilma suure arutelu, sest iga konkreetse juhtumi puhul oli selge, et juhtus midagi halba, ning sellest tuli logides teatada.

Pärast seda jõudsime järeldusele, et meil on seire, mis skaneerib logisid. Ja kahtlaste teatiste korral äratab see valvevaht, ja valvevaht lahendab probleemi.
Aga! Logide skaneerimine on odav operatsioon ühes klastris ja katastroofiliselt kallis tuhandes klastris.
Me kirjutasime laienduse, mida nimetatakse . See loob andmete baasi, kus saab kiirelt ja odavalt valida statistikat varasemate vigade kohta. Ja kui on vaja ärgata valvepidaja, saame sellest teada, skaneerimata gigabaidi suurustes faile, vaid tõmmates mõned baitide hash-tabelist.
Seda laiendust on näiteks kasutatud repozitooriumis . Kui soovite seda kasutada, saate selle paigaldada. Muidugi on see open source.

Aga see pole veel kõik. Me hakkasime kasutama Amcheck'i — laiendust, mis on loodud kogukonna poolt, et tuvastada invariantmurdmisi indeksites.
Ja me avastasime, et kui seda kasutada suuremas ulatuses, leidub seal vigu. Hakkasime neid parandama. Meie parandused võeti vastu.
Leidsime, et see laiendus ei oska analüüsida GiST & GIT indekseid. Me lisasime nende toe. Kuid see tugi on praegu kogukonnas arutlusel, kuna see on suhteliselt uus funktsionaalsus ja seal on palju detaile.
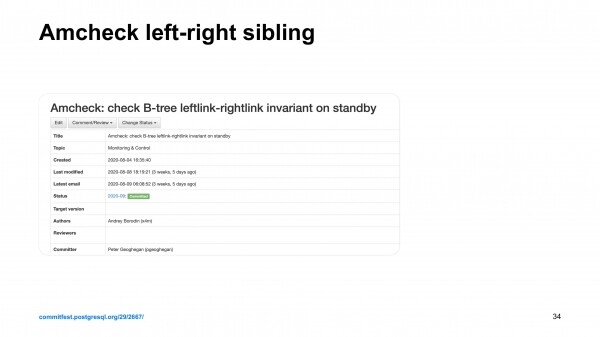
Ja me avastasime, et replikatsiooni juhtlindi kontrollimise korral töötab master hästi, kuid fännide puhul ei ole kahjustuste otsimine nii efektiivne. Kõiki invariantse ei kontrollita. Üks invariant muretses meid tõsiselt. Oleme poolteist aastat arutanud kogukonnaga, et panustada see kontroll replikatsioonidesse.
Kood, mille me kirjutasime, pidi järgima kõiki can… protokolle. Arutasime seda pikka aega Peter Geighaniga Crunchy Datast. Tal tuli veidi olemasolevat B-puudet Postgresis modifitseerida, et see patch vastu võtta. See võeti vastu. Ja nüüd on replikatsioonide puhul indekseerimise kontroll samuti piisavalt efektiivne, et avastada neid rikkumisi, millega me silmitsi seisime. Need rikkumised, mis võivad olla tingitud ketaste püsivana vigadest, Postgresi tõrgetest, Linuxi tuuma tõrgetest, riistvara probleemidest. Aega, millega me valmistusime, on üsna suur hulk probleemide allikaid.

Aga peale indeksite on olemas ka osa, mis puudutab heap'i, st kohta, kus andmeid hoitakse. Ja seal ei ole palju invariantse, mida võiks kontrollida.
Meil on laiendus nimega Heapcheck. Oleme hakanud seda arendama. Samuti on ettevõte EnterpriseDB hakanud kirjutama moodulit, mille nad kutsuvad samuti Heapcheckiks. Meie oleme selle nimetatud PgHeapcheckiks, nemad aga lihtsalt Heapcheckiks. Neil on sarnased funktsioonid, kuid veidi erineva signatuuri ja sama ideega. Nad on paaris kohas natuke paremini realiseerinud ja avaldanud selle avatud lähtekoodiga varem.
Nüüd tegeleme nende laienduse arendamisega, kuna see ei ole enam nende laiendus, vaid kogukonna laiendus. Tulevikus – see on osa tuumast, mis saadetakse kõigile, et oleks võimalik ette teada tulevasi probleeme.
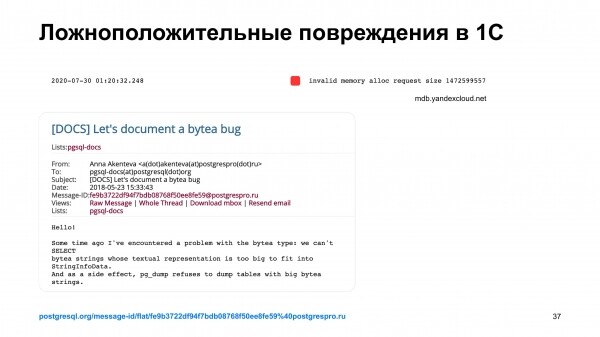
Mõnes kohas oleme isegi jõudnud olukorda, kus meie jälgimisseadmetel on valepositiivseid tulemusi. Näiteks süsteem 1C. Postgresi andmebaasi kasutamisel kirjutatakse mõnikord selliseid andmeid, mida süsteem ise suudab lugeda, kuid pg_dump neid ei suuda.
See olukord nägi meie probleemide tuvastamise süsteemile välja nagu korruptsioon. Vahtkunstnik äratati. Vahtkunstnik vaatas, mis toimub. Peagi tuli klient ja ütles, et tal on probleeme. Vahtkunstnik selgitas, mis probleem on. Kuid probleem on Postgresi tuumas.
Leidsin arutelu sellest funktsioonist. Ja kirjutasin, et me kohtusime selle funktsiooniga ja see oli ebameeldiv, et inimene pidi öösel üles ärkama, et aru saada, mis see on.

Kogukond vastas: „Oh, tõepoolest, tuleb parandada.“
Mul on lihtne analoogia. Kui käite kingas, kuhu on sattunud liivaterake, siis tegelikult pole hullu midagi. Kui müüte kingi tuhandetele inimestele, siis teeme kingad ilma liivata üldse. Ja kui keegi teie kingi kandjatest plaanib joosta maratoni, siis soovite teha väga head kingad ja seejärel juba skaleerida kõigile oma kasutajatele. Sellised ootamatud kasutajad on alati pilvekeskkonnas. Alati leidub kasutajaid, kes kasutavad klastrit mingil originaalsel viisil. Sellega tuleb alati valmis olla.

Mille siin õppisime? Õppisime üht lihtsat asja: kõige olulisem on selgitada kogukonnale, et probleem on olemas. Kui kogukond on probleemi teadvustanud, tekib loomulik konkurents selle lahendamiseks. Sest tähtsa probleemi soovib igaüks lahendada. Kõik teenusepakkujad, kõik häkkerid mõistavad, et võivad ise nendele takistustele astuda, seega soovivad nad need kõrvaldada.
Kui töötate mingi probleemiga, kuid see ei puuduta kedagi peale teie, ja te teete selle nimel süsteemselt tööd, kuni see lõpuks loetakse probleemiks, siis teie pull request võetakse kindlasti vastu. Teie parandused võetakse vastu, teie muudatused või isegi muudatusettepanekud vaadatakse kogukonnas üle. Lõppude lõpuks teeme me andmebaasi paremaks üksteise jaoks.

Huvitav andmebaas – Greenplum. See on tugevalt paralleelne andmebaas, mis põhineb Postgresi koodibaasil, millega olen hästi tuttav.
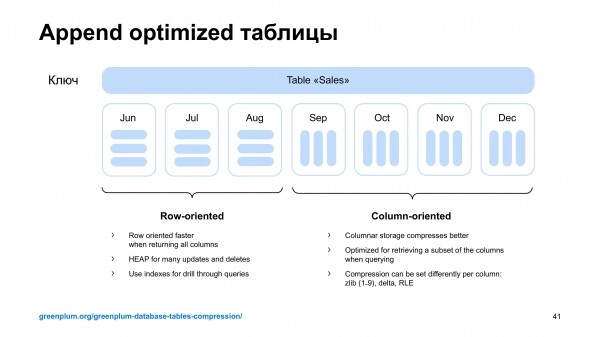
Ja Greenplumis on huvitav funktsionaalsus – append optimized tabelid. Need on sellised tabelid, kuhu saab kiiresti andmeid lisada. Need võivad olla kas veergude või ridade põhised.
Aga seal ei olnud klasterdamist ehk ei olnud funktsionaalsust, millega saaks andmeid, mis on tabelis, korraldada mingis kindlas indeksi järjekorras.
Tulid taksojuhid ja ütlesid: "Andrei, sa ju tead Postgres't. Siin on peaaegu sama. Üleminek 20 minutiks. Võta ja tee." Mõtlesin, et jah, ma ju tean Postgres't, üleminek 20 minutiga – sellega tuleb tegeleda.
Aga ei, see ei olnud 20 minutit, ma kirjutasin seda mitu kuud. PgConf.Russia konverentsil läksin Heikki Linakangase juurde Pivotalist ja küsisin: "Kas sellega on mingeid probleeme? Miks ei ole klasterdamine append optimized tabelil?" Tema ütles: "Võta andmed. Sorteeri, pane uuele kohale. See on lihtsalt töö." Mina: "Oh, jah, selle peab lihtsalt võtma ja tegema." Tema ütles: "Jah, vajatakse vabade kätega inimesi, kes seda teevad." Mõtlesin, et seda tuleb kindlasti teha.
Ja paar kuud hiljem saatsin pull request'i, mis rakendas seda funktsionaalsust. Seda pull request'i vaadati Pivotalis koos kogukonnaga. Loomulikult olid seal vead.
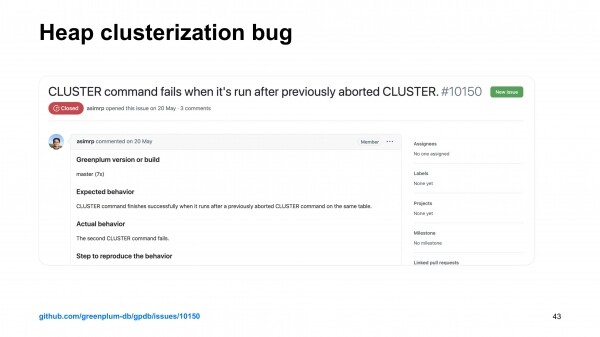
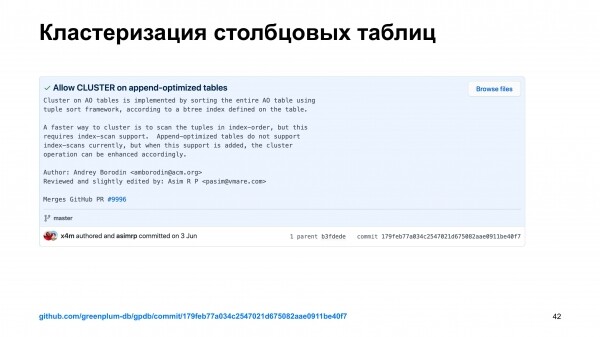
Aga kõige huvitavam on see, et selle pull request'i ühendamise käigus leiti Greenplum'is vigu. Me avastasime, et heap-tabelid klasterdamisel rikuvad mõnikord tehingute järjepidevust. Ja see on asi, mida tuleb parandada. Ja see on seal, kus ma just töötasin. Minu loomulik reaktsioon oli – hästi, las ma teen sellega ka tegelema.
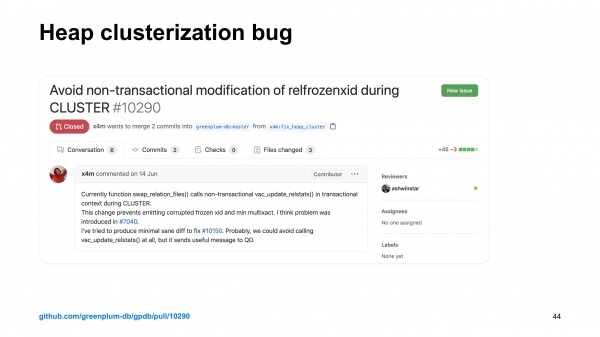
Ma parandasin selle vea. Saatsin pull request'i parandustele. See ühendati.
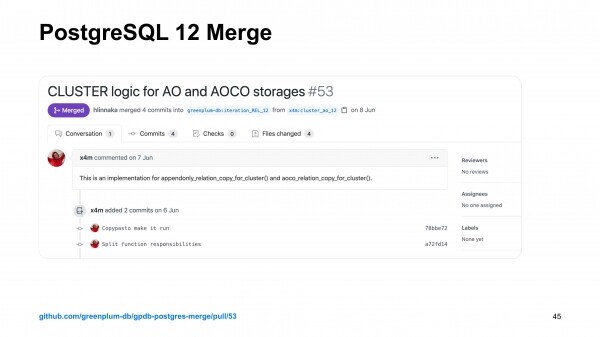
Pärast seda selgus, et see funktsionaalsus tuleb saada ka PostgreSQL 12 versioonis Greenplum'ile. See tähendab, et seiklused 20 minutiga jätkuvad uute huvitavate seiklustega. Oli huvitav tutvuda hetke arenguga, kus kogukond arendab uusi ja kõige tähtsamaid funktsioone. See ühendati.
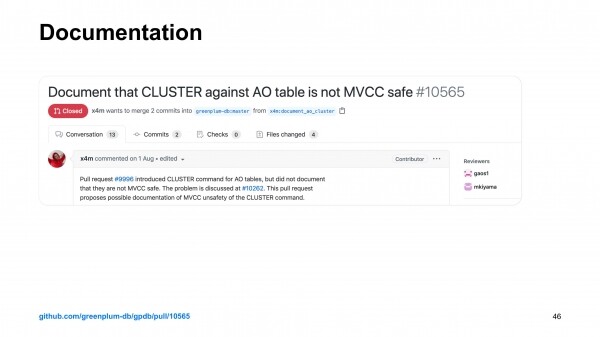
Aga sellega kõik ei lõppenud. Pärast seda selgus, et tuleb kirjutada ka dokumentatsioon selle jaoks.
Hakkasin kirjutama dokumentatsiooni. Õnneks tulid Pivotal'ist dokumenteerijad. Nende jaoks on inglise keel emakeel. Nad aitasid mind dokumentatsiooniga. Põhimõtteliselt kirjutasid nad ise ümber selle, mida ma pakkusin, õigesse inglise keelde.
Ja selle näiliselt seikluse fooni pealt juhtus see, et tuli taksojuhte ja nad ütlesid: "Siin on veel kaks seiklust, igaüks 10 minutit." Mida ma neile pidin ütlema? Ma vastasin, et teen enne oma ettekande scale'i teemal, siis vaatame teie seiklusi, sest see on huvitav töö.

Mida me sellest olukorrast õppisime? Et open source'i töö on alati töö konkreetse inimesega, see on alati töö kogukonnaga. Igas etapis töötasin ma kellegi arendaja, kellegi testija, kellegi häkkeri, kellegi dokumenteerija, kellegi arhitektiga. Ma ei töötanud Greenplumiga, vaid töötasin inimesega, kes on Greenplumi ümber.
Kuid! On veel üks oluline punkt – see on lihtsalt töö. See tähendab, et tuled, jood kohvi, kirjutad koodi. Töötab palju lihtsaid invariante. Tee hästi – kõik läheb hästi! See on üsna huvitav töö. Selle töö järele on nõudlus Yandex. Cloud'i klientide seas, meie klastrite kasutajate seas nii sees kui väljas. Ja ma arvan, et projektide arv, milles me osaleme, suureneb ning meie kaasamise sügavus suureneb samuti.
Sellega ongi kõik. Liigume küsimuste juurde.

Küsimuste sessioon
Tere! Meil on järgmine küsimuste ja vastuste sessioon. Ja stuudios on Andrei Borodin. See on inimene, kes just rääkis Yandex. Cloud'i ja YandeXi panusest avatud lähtekoodiga. Meie arutelu ei ole täiesti pilveteema, kuid samal ajal põhineme me just sellistel tehnoloogiatel. Kui te ei oleks teinud, mis te Yandexis tegite, ei oleks Yandex. Cloud'is teenust, seega aitäh sulle isiklikult. Ja esimene küsimus ülekanne: "Millisel platvormil on iga projekt, mida sa mainisid?"
WAL-G varundamissüsteem on kirjutatud Go keeles. See on üks meie uusimaid projekte, millega oleme töötanud. Selle vanus on kõigest 3 aastat. Andmebaase iseloomustab sageli usaldusväärsus. See tähendab, et andmebaasid on üsna vanad ja need on tavaliselt kirjutatud C keeles. Postgres'i projekt sai alguse umbes 30 aastat tagasi. Tol ajal oli õige valik C89. Ja just sellel keelel on Postgres kirjutatud. Kaasaegsed andmebaasid, nagu ClickHouse, kirjutatakse enamasti C++ keeles.
Küsimus meie finantsjuhilt, kes vastutab pilves kulude eest: "Miks pilv kulutab raha avatud lähtekoodiga toe eest?"
Siin on lihtne vastus finantsjuhi jaoks. Me teeme selle, et oma teenuseid paremaks muuta. Milles me saame paremad olla? Me saame olla tõhusamad, kiiremad, teha midagi skaleeritavamalt. Kuid meie jaoks on see lugu eelkõige usaldusväärsusest. Näiteks varundamissüsteemis vaatame üle 100% patšidest, mis sellele rakendatakse. Me teame, mis see kood on. Ja me julgeme välja anda uusi versioone tootmisse. See tähendab, et see on eelkõige kindluse, arenguga valmisoleku ja usaldusväärsuse küsimus.
Küsimus veel: "Kas väliste kasutajate nõuded, kes elavad Yandex.Cloudis, erinevad sisemistest kasutajatest, kes elavad sisemises pilves?".
Koormusprofiilid on muidugi erinevad. Kuid minu osakonna perspektiivist vaadatuna on kõik erilised ja huvitavad olukorrad loodud ebatavalise koormuse korral. Kujutlusvõimega arendajad, kes teevad ootamatuid asju, esinevad tõenäoliselt nii sees kui väljas. Selles mõttes oleme me kõik enam-vähem ühesugused. Ja ilmselt on ainus oluline omadus Jaandexi andmebaasi halduses see, et meil on õppimisprotsess. Mingil hetkel muutub mingi kättesaadavusala täielikult varjatud ja kõik Jaandexi teenused peavad selle mallei jäädes ikkagi kuidagi toimima. See on väike erinevus. Kuid see loob palju uurimis- ja arendustööd andmebaasi ja võrgu struktuuri piirialal. Muul juhul tekitavad välised ja sisemised paigaldused samu funktsioonisoove ja sarnaseid vajadusi töökindluse ja tulemuslikkuse parandamiseks.
Järgmine küsimus: „Kuidas isiklikult suhtud sellesse, et palju sellest, mida sa teed, kasutatakse teiste pilvede poolt?” Me ei hakka nimetama konkreetseid, kuid paljusid projekte, mis on loodud Yandex. Pilves, kasutatakse teistes pilvedes.
See on suurepärane. Esiteks, see näitab, et oleme midagi õigesti teinud. Ja see kõditab ego. Oleme kindlamad, et tegime õige otsuse. Teiselt poolt, see on lootus, et tulevikus toob see meile uusi ideid ja uusi päringuid väliselt kasutajalt. Enamik probleeme GitHubis loovad erinevad süsteemihaldurid, erinevad andmebaasi administraatorid, erinevad arhitektid, erinevad insenerid, kuid vahel tulevad inimesed, kellel on süsteemne kogemus, ja ütlevad, et teatud 30 % juhtudest on meil selline probleem ja mõtleme, kuidas seda lahendada. Just seda ootame kõige rohkem. Ootame, et meil oleks kogemuste vahetus teiste pilveplatvormidega.
Sa rääkisid palju maratoni kohta. Ma tean, et sa jooksid maratoni Moskvas. Kuidas läks? Kas sa edestasid Postgres Pro tiimi?
Ei, Oleg Bartunov jookseb väga kiiresti. Ta lõpetas tunni varem kui mina. Üldiselt olen rahul, et ma lõpetasin. Minu jaoks oli finish saavutuseks. Üldiselt on üllatav, et PostgreSQLi kogukonnas on nii palju jooksjaid. Tundub, et aerobsete spordialade ja süsteemitarkvara vahel on mingi seos.
Kas sa tahad öelda, et ClickHouse'is pole jooksjaid?
Ma tean kindlasti, et seal on. ClickHouse on ka andmebaas. Huvitaval kombel kirjutab Oleg mulle praegu: „Kas jooksma pärast ettekannet?“. See on suurepärane idee.
Veel üks küsimus Nikitalt: „Miks sa parandad vea Greenplumis ise, mitte ei andnud seda junior'itele?“. Tõsi, siin ei ole eriti selgitatud, mis viga ja millisest teenusest, aga ilmselt on see see, millest sa rääkisid.
Jah, põhimõtteliselt oleks võinud kellegile anda. Lihtsalt see oli kood, mida ma just muutnud olin. Ja tundus loomulik jätkata seda kohe siin. Üldiselt on hea idee jagada oma teadmisi meeskonnaga. Me kindlasti jagame Greenplumi ülesandeid meie osakonna kõigi liikmete vahel.
Kui räägime junior’itest, siis selline küsimus. Inimene otsustas teha esimese commits Postgresisse. Mida peab ta tegema, et luua esimene commit?
See küsimus on tõeliselt huvitav: "Kust alustada?". Tavaliselt on alustamine kuskilt tuumast üsna keeruline. Näiteks Postgreses on olemas to do list. Kuid tegelikult on see nimekiri asjadest, mida üritati teha, kuid ei õnnestunud. Need on keerulised asjad. Ja tavaliselt võib ekosüsteemist leida mõned utiliidid, mõned laiendused, mida saaks täiustada, mis tõmbavad tuumaarendajate tähelepanu vähem. Seetõttu on seal rohkem kasvukohti. Google Summer of Code'i programmil esitleb Postgrese kogukond igal aastal palju erinevaid teemasid, millega tegeleda. Sel aastal tundub, et meil oli kolm üliõpilast. Üks kirjutas isegi WAL-G teemadel, mis on Yandexi jaoks olulised. Greenplumis on kõik lihtsam kui Postgrese kogukonnas, sest Greenplumi häkkerite suhtumine pull request'idessse on väga positiivne, ja nad hakkavad kohe üle vaatama. Patchesi saatmine Postgresse on kuude kaupa kestev lugu, samas kui Greenplumis tullakse päeva jooksul ja vaadatakse, mida oled teinud. Teine asi on see, et Greenplumis tuleb lahendada aktuaalseid probleeme. Greenplum ei ole nii laialdaselt kasutuses, seega on oma probleemi leidmine üsna raske. Ja esmalt tuleb lahendada muidugi probleemid.
Allikas: habr.com
