

Täna on olemas 100500 Data Science'i kursust ja on ammu teada, et enamasti teenitakse kõige rohkem raha just Data Science'i kursustega (miks kaevata, kui saab müüa labidaid?). Peamine probleem nende kursustega on see, et need ei oma mingit seost tegeliku tööga: keegi ei anna teile puhtaid, töödeldud andmeid õiges vormingus. Ja kui te väljud kursustelt ja hakkate lahendama päris probleemi — ilmnevad paljud nüansid.
Seetõttu alustame artiklite sarja "Mis võib Data Science'is valesti minna", mis põhinevad tõeliselt juhtunud juhtumitel, mis on juhtunud minuga, minu sõprade ja kolleegidega. Toome välja reaalseid näiteid tüüpilistest Data Science'i ülesannetest: kuidas see tegelikult toimub. Alguses käsitleme andmete kogumise ülesannet.
Ja esimene, millele inimesed, kes hakkavad töötama reaalsete andmetega, komistavad — on tegelikult nende asjakohaste andmete kogumine. Selle artikli põhikohustus:
Me alahindame järjepidevalt aega, ressursse ja pingutusi andmete kogumiseks, puhastamiseks ja ettevalmistamiseks.
Ja olulisem, arutame, mida teha, et seda vältida.
Erinevate hinnangute kohaselt kulub andmete puhastamiseks, töötlemiseks, omaduste inseneriks ja muuks 80-90% ajast, samas kui analüüs võtab vaid 10-20%, kuigi peaaegu kogu õppeaine keskendub ainult analüüsile.
Vaatame, kuidas üks tüüpiline analüüsik ülesanne lahendada kolme variandi kaudu ja näeme, millised on „kergitavad asjaolud”.
Ja näiteks vaatame sarnaseid andmete kogumise ja kogukondade võrdlemise ülesande variatsioone:
- Kahte Redditi alafoorumit
- Kahte Habra jaotust
- Kahte Klassikaaslaste gruppi
Lihtne lähenemine teooriast
Avage veebisait ja lugege näiteid, kui on arusaadav, kulutage paar tundi lugemisele, paar tundi koodi näidetes ja silumisele. Lisage paar tundi kogumiseks. Lisage paar tundi varuks (korrutage kaheks ja lisage N tundi).
Peamine punkt: ajahinnang põhineb oletustel ja oletustel selle kohta, kui kaua see aega võtab.
Aja analüüsi alustamiseks on oluline hinnata järgmisi parameetreid eelnevalt kirjeldatud tingimusliku ülesande puhul:
- Milline on andmete maht ja kui palju neid tuleb füüsiliselt koguda (*vt allpool*).
- Kui kaua ühe kirje kogumine aega võtab ja kui kaua tuleb oodata, enne kui saab teise koguda.
- Koodimise kirjutamine, mis säilitab oleku ja alustab taaskäivitamist, kui (mitte kui) kõik kokku kukub.
- Tuleb välja selgitada, kas meil on vaja autoriseerimist ja arvestada API juurdepääsu saamise aega.
- Tuleb arvestada vigade arvu kui andmete keerukuse funktsiooni — hinnata konkreetse ülesande põhjal: struktuur, kui palju teisendusi, mida ja kuidas ekstraktime.
- Tuleb arvestada võrgu vigu ja probleeme projekti mittestandardse käitumisega.
- Hinda, kas vajalikud funktsioonid on dokumentatsioonis, ja kui need pole olemas, siis kui palju on vajalik lahenduse leidmiseks.
Kõige olulisem, mida ajakava hindamiseks arvesse võtta — peate tegelikult kulutama aega ja pingutust „taktikalise uuringu” jaoks — alles siis on teie planeerimine adekvaatne. Seega, kui teid survestatakse ütlema „kui palju aega on andmete kogumiseks vajalik” — leidke aega eelanalüüsiks ja põhjendage, kui palju aega see tegelikult sõltub ülesande tegelikest parameetritest.
Ja nüüd demonstreerime konkreetseid näiteid, kus sellised parameetrid muutuvad.
Peamine punkt: hindamine põhineb võtmetegurite analüüsil, mis mõjutavad töömahtu ja keerukust.
Hinnang, mis põhineb oletustel, on hea lähenemine, kui funktsionaalsed elemendid on piisavalt väikesed ja tegureid, mis võivad oluliselt mõjutada ülesande struktuuri, ei ole palju. Kuid mitme Data Science'i ülesande puhul muutub selliste tegurite arv äärmiselt suureks ja selline lähenemine osutub sobimatuks.
Redditi kogukondade võrdlemine
Alustame kõige lihtsamast juhtumist (nagu hiljem selgub). Üldiselt, kui olla täiesti aus, on meil peaaegu ideaalne juhtum, vaatame meie keerukuse kontrollnimekirja:
- Olemas on korralik, arusaadav ja dokumenteeritud API.
- Nii lihtne ja mis kõige tähtsam, saadakse automaatselt token.
- On — koos hulga näidistega.
- Kogukond, mis tegeleb Redditis andmete analüüsi ja kogumisega (kuni YouTube'i videodeni, mis selgitavad, kuidas kasutada python wrapperit) .
- Vajalikud meetodid eksisteerivad tõenäoliselt API-s. Veelgi enam, kood näeb välja kompaktne ja puhas, allpool on näide funktsioonist, mis kogub postituste kommentaare.
def get_comments(submission_id):
reddit = Reddit(check_for_updates=False, user_agent=AGENT)
submission = reddit.submission(id=submission_id)
more_comments = submission.comments.replace_more()
if more_comments:
skipped_comments = sum(x.count for x in more_comments)
logger.debug('Skipped %d MoreComments (%d comments)',
len(more_comments), skipped_comments)
return submission.comments.list()
Võetud mugavate utiliitide valik.
Kuigi meil on parim võimalik olukord, peaksime siiski arvestama mitme olulise teguriga reaalses elus:
- API piirangud — me peame andmeid koguma partiidena (undama päringute vahel jne).
- Kogumise aeg — täielikuks analüüsiks ja võrdlemiseks tuleb arvestada märkimisväärset aega, et lihtsalt spider saaks subreddit'i läbi käia.
- Bot peab töötama serveris — te ei saa lihtsalt seda sülearvutis käivitada, seljakotti panna ja ringi minna. Seetõttu käivitasin kõik VPS-is. Kasutades kupongi habrahabr10, saab veel 10% soodustust.
- Mõnede andmete füüsiline kätte saamata jäämine (need on nähtavad administraatoritele või liiga keeruline koguda) — see tuleb arvesse võtta, mitte kõik andmed ei ole üldse mõistliku aja jooksul kergesti kättesaadavad.
- Võrgu töövead: võrgu kasutamine on väljakutse.
- Need on elavad tõelised andmed — need ei ole kunagi puhtad.
Muidugi tuleb arvestada kõiki mainitud nüansse arenduses. Spetsiifilised tunnid/päevad sõltuvad arenduse kogemusest või sarnaste ülesannetega tegelemise kogemusest, kuid me näeme, et antud ülesanne on puhtalt inseneritehniline ja ei vaja lisategevusi lahendamiseks — kõike saab väga hästi hinnata, planeerida ja teostada.
Habrakohtade võrdlemine
Liigume edasi huvitavama ja ebatavalise juhtumi juurde, kus võrreldakse vooge ja/või Habrakohti.
Kontrollime meie keerukuse kontrollnimekirja — siin, et mõista iga punkti, tuleb natuke katsetada ülesande enda kallal ja eksperimenteerida.
- Esialgu arvasite, et API on olemas, kuid seda ei ole. Jah, Habraklubi on API, kuid see on kasutajatele kättesaamatu (võib-olla ei tööta see üldse).
- Siis hakkate lihtsalt HTML-i parsimiseks — "import requests", mis võib valesti minna?
- Aga kuidas üldse parsida? Lihtsaim ja kõige sagedamini kasutatav lähenemine on iteratsioon ID-de kaupa, märkides, et see ei ole kõige tõhusam ja peate käsitlema erinevaid juhtumeid — näiteks reaalse ID tihedus kõigi olemasolevate seas.

Võetud artiklist. - HTML-moodulite kaudu võrgus olev tooreandmed on suureks vaevaks. Näiteks, kui soovite koguda ja salvestada artikli hinnangut: olete välja nopinud score HTML-ist ja otsustanud salvestada selle numbrina edasiseks töötlemiseks.
1) int(score) viskab vea: kuna Habril on miinus, näiteks read "–5" — see on lühike side ja mitte miinusmärk (üllatav, ei?). Seetõttu tuli mingil hetkel aktiveerida parser sellise kohutava fikseerimisega.
try: score_txt = post.find(class_="score").text.replace(u"–","-").replace(u"+","+") score = int(score_txt) if check_date(date): post_score += scoreKuupäevasid, plusse ja miinuseid ei pruugi üldse olla (kui vaatame üle check_date funktsiooni ja selline on olnud).
2) Eespool kodutööde tulemusi peaks arvesse võtma — nad tulevad, peate olema valmis.
3) Struktuur muutub vastavalt postituse tüübile.
4) Vanematel postitustel võib olla **veider struktuur**.
- Sisuliselt tuleb vigu ja võimalikke olukordi käsitleda ning ei saa ette näha, mis võib valesti minna ja mis veel struktuur olla võib ning kust midagi välja kukub — tuleb lihtsalt proovida ja arvesse võtta parseri visatud vigu.
- Siis mõistate, et andmeid tuleb töödelda mitme töörühmaga, vastasel juhul kulub ühe-poolse töötlemise jaoks 30+ tundi (see on ainult olemasoleva ühe-poolse andmete töötleja tööaeg, mis magab ja ei saa ühtegi reegli rikkumist). artiklis, viis see mingil hetkel sarnase skeemini:
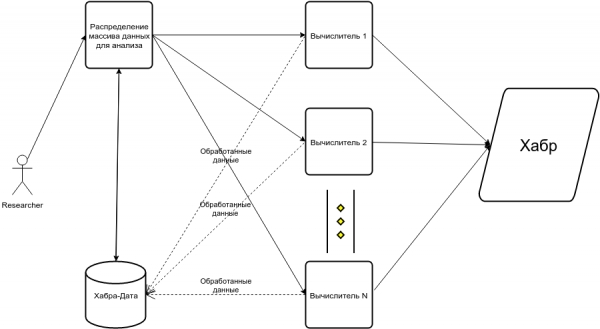
Kokkuvõtteks kontrollnimekiri keerukuse kohta:
- Töötamine võrgu ja HTML andmete töötlemisega ID-de iteratsiooni ja genereerimise käigus.
- Dokumendid on mitmekesise struktuuriga.
- Palju kohti, kus kood võib kergesti kukkuda.
- On vajalik kirjutada || kood.
- Puudub vajalik dokumentatsioon, koodinäidised ja/või kogukond.
Kohandatud ajahinnang sellele ülesandele on 3-5 korda suurem kui andmete kogumine Redditist.
Võrdlemine Odnoklassniki gruppidega
Liigume edasi kõige tehniliselt huvitavama juhtumi juurde. Minu jaoks oli see huvitav just seetõttu, et see näeb esmapilgul piisavalt triviaalne välja, kuid ei ole nii — nii pea kui te sellesse puutikku lükkate.
Alustame meie keerukuse kontrollnimekirjaga ja märkime, et paljusid neist osutuvad palju keerulisemaks, kui alguses tunduvad:
- API on olemas, kuid see on peaaegu täielikult vajalikke funktsioone ilma.
- Mõnedele funktsioonidele on vajalik juurdepääsu taotlemine e-posti teel, seega ei ole juurdepääs instantne.
- Dokumentatsioon on kohutav (alustame sellest, et kõikjal segunevad vene ja ingliskeelsed terminid, täiesti ebajärjekindlalt — mõnikord peate lihtsalt ära arvama, mida teilt kuskil oodatakse) ning mis ühtlasi ei sobi andmete hankimiseks disaini poolest, näiteks .
- Nõuab dokumentatsioonis sessiooni, kuid reaalselt seda ei kasuta — ja pole mingit viisi, kuidas kõiki API režiimide nüansse selgeks saada, välja arvatud klikkida ja loota, et midagi töötab.
- Puuduvad näited ja kogukond, ainus tugikoht teabe kogumiseks on väike Pythonis (ilma suure hulga kasutusnäidisteta).
- Töötav variant näib olevat Selenium, kuna paljud vajalikud andmed on lukustatud.
1) Autoriseerimine toimub fiktiivse kasutaja kaudu (ja registreerimine käsitsi).2) Siiski ei ole Seleniumiga mingit garantiid korrektse ja korduva töö osas (vähemalt ok.ru puhul kindlasti).
3) Oks.ru veebisaidil on JavaScripti vigu ja see käitub mõnikord kummaliselt ja ebajärjekindlalt.
4) Hoolitseda on vajalik pagineerimine, elementide laadimine jne…
5) API vead, mida wrapper annab, tuleb kohandada, näiteks так (katkestus eksperimentaalkoodist):
def get_comments(args, context, discussions): pause = 1 if args.extract_comments: all_comments = set() #on mõistlik jälgida juba töödeldud arutelusid for discussion in tqdm(discussions): try: comments = get_comments_from_discussion_via_api(context, discussion) except odnoklassniki.api.OdnoklassnikiError as e: if "NOT_FOUND" in str(e): comments = set() else: print(e) bp() pass all_comments |= comments time.sleep(pause) return all_commentsMinu lemmik viga oli:
OdnoklassnikiError("Error(code: 'None', description: 'HTTP error', method: 'discussions.getComments', params: …)")6) Lõppkokkuvõttes näeb Selenium + API variant kõige ratsionaalsem välja.
- On vajalik olekute säilitamine ja süsteemi taaskäivitamine, paljude vigade töötlemine, sealhulgas veebisaidi ettearvamatu käitumine — ja need vead on üsna keerulised ette kujutada (kui te ei kirjuta professionaalselt parsereid, loomulikult).
Antud ülesande ajahinnang on 3-5 korda kõrgem kui andmete kogumine Habrist. Kuigi Habriga töötades kasutame HTML-parsingu otse lähenemist, saame OК puhul kriitilistes kohtades töötada API-ga.
Järeldused
Kuigi te võite nõuda, et hindaksime mõistes "kohapeal" (meil on täna planeerimine!) mahuka andmetöötluse pipelini, on täitmise aega praktiliselt võimatu isegi kvaliteetselt hinnata ilma ülesande parameetrite analüüsimiseta.
Kui rääkida veidi filosoofilisemalt, siis agiilsed hindamisstrateegiad sobivad hästi inseneritegevuste jaoks, kuid eksperimentaalsemate ning mingil määral "loominguliste" ja uurimistegevustega, st vähem ettearvatavate ülesannetega, tekivad raskused, nagu näidatud siinsetes näidetes.
Muidugi, andmete kogumine on lihtsalt elav näide — tavaliselt näib see ülesanne uskumatult lihtne ja tehniliselt lihtne, kuid just detailides peitub sageli kurat. Ja just selle ülesande kaudu on võimalik näidata kogu spektrit võimalikke variante, mis võivad valesti minna, ja kui kaua võib töö venida.
Kui kiiresti ülesande omadustele pilk heita, tunduvad Reddit ja OK sarnased: mõlemal on API, Python'i wrapper, kuid tegelikult on erinevus tohutu. Kui neid parameetreid võrrelda, siis Habr'i andmete kogumine tundub keerulisem kui OK — kuid tegelikult on vastupidi, ja seda saab selgeks teha, viies läbi lihtsaid katseid ülesande parameetrite analüüsimiseks.
Minu kogemuste kohaselt on kõige tõhusam lähenemine umbkaudne ajakava, mis põhineb eeltööl ja lihtsatel esimestel katsetel, dokumentatsiooni lugemisel – just need tegevused annavad võimaluse teha täpne hinnang kogu töö ulatusele. Populaarse agiilse metoodika terminoloogias palun, et luuakse mulle pilet „ülesande parameetrite hindamiseks“, mille alusel saan hinnata, mida on võimalik „sprintide“ raames rakendada ja anda täpsem hinnang iga ülesande kohta.
Seega tundub, et kõige tõhusam on argumendi esitlemine, mis näitab „mitte-tehnilisele“ spetsialistile, kui palju võivad aja ja ressursside kulud varieeruda sõltuvalt parameetritest, mida tuleb veel hinnata.
Allikas: habr.com
