

Jaotatud arvutuste ja suurte andmete turg, kui uskuda , kasvab 18–19% aastas. See tähendab, et tarkvara valiku küsimus jääb endiselt актуálseks. Selles postituses räägime sellest, miks on jaotatud arvutused vajalikud, keskendume tarkvara valikule, tutvustame Hadoopi rakendamist Cloudera abil ning lõpuks arutame riistvara valikut ja seda, kuidas see erinevates viisides tootlikkusele mõjub.

Miks on jaotatud arvutused tavalisel äril vajalikud? Siin on kõik lihtsalt ja keeruliselt samal ajal. Lihtne — sest enamikul juhtudel teeme me suhteliselt lihtsaid arvutusi teabeühiku kohta. Keeruline — sest sellist teavet on palju. Üksnes väga palju. Seetõttu tuleb . Seega on kasutusstsenaariumid üsna universaalsed: arvutusi saab rakendada igal pool, kus on vajalik arvesse võtta suurt hulka mõõdikuid veelgi suuremas andmemassis.
Üks hiljutine näide: pizzeriate kett Dodo Pizza kunde tellimuste andmebaasi analüüsi põhjal selgus, et kui valida pitsat juhuslikke koostisosadega, siis opereerivad kasutajad tavaliselt vaid kuue põhikoostisosade komplektiga pluss paar juhuslikku. Selle alusel kohandas pitsabaar oma ostustrateegiat. Lisaks suudeti paremini soovitada kasutajatele lisatooteid, mis pakuti tellimise käigus, mis tõstis kasumlikkust.
Veel üks näide: toodete valik võimaldas H&M-l vähendada teatud kauplustes valikut 40% võrra, säilitades siiski müügitaseme. Seda õnnestus saavutada halvasti müüdavate toodete välistamisega, arvesse võttes hooajalisust.
Tööriista valik
Hadoop on tööstusstandard, kui räägime sellistest arvutustest. Miks? Sest Hadoop on suurepärane, hästi dokumenteeritud raamistik (isegi Habr avaldab sellel teemal hulgaliselt üksikasjalikke artikleid), mis kaasneb terve hulga utiliitide ja teekidega. Saate esitada tohutuid koguseid nii struktureeritud kui ka struktureerimata andmeid, ning süsteem jaotab need automaatselt arvutusressursside vahel. Neid ressursse saab igal ajal suurendada või vähendada — see ongi horisontaalne skaleeritavus.
2017. aastal jõudis mõjuka konsultatsioonifirma Gartner , et Hadoop kaotab peagi oma tähtsuse. Põhjus on üsna lihtne: analüütikud usuvad, et ettevõtted hakkavad massiliselt liikuma pilve, kus nad saavad maksta tegelike arvutusressursside kasutamise eest. Teine oluline tegur, mis võib Hadoopi "hauda kanda", on töö kiirus. Sest sellised valikud nagu Apache Spark või Google Cloud DataFlow töötavad kiiremini kui Hadoopi aluseks olev MapReduce.
Hadoop toetub mitmele suurele tehnoloogiale, mille seas on kõige silmapaistvamad MapReduce (andmete jagamise süsteem arvutamisel serverite vahel) ja HDFS faili süsteem. Viimane on spetsiaalselt loodud jagatud teabe salvestamiseks klastrite sõlmede vahel: iga fikseeritud suurusega plokk võib olla paigutatud mitmesse sõlme ja replikatsiooni kaudu tagatakse süsteemi vastupidavus üksikute sõlmede riketest. Failide tabeli asemel kasutatakse spetsiaalset serverit, mida nimetatakse NameNode'iks.
Alloleval illustratsioonil on kujutatud MapReduce'i töö skeemi. Esimeses etapis jagatakse andmed teatud tunnuse järgi, teises - jagatakse need arvutusvõimsuse vahel ning kolmandas - toimub arvutamine.
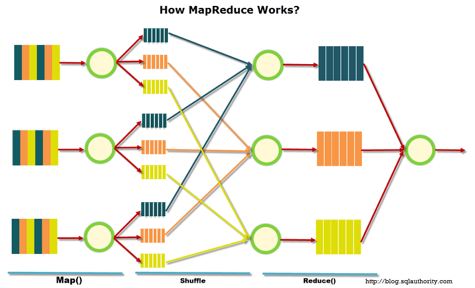
MapReduce loodi algselt Google'i vajadustele oma otsingu jaoks. Seejärel läks MapReduce vabakoodiks ja projekti võttis üle Apache. Google liikus järk-järgult teiste lahenduste suunas. Huvitav nüanss: hetkel on Google'il projekt nimega Google Cloud Dataflow, mis on positsioneeritud järgmise sammuna pärast Hadoopi, nagu kiire asend.
Pöörates tähelepanu näeme, et Google Cloud Dataflow põhineb Apache Beami variandil, samas kui Apache Beam sisaldab hästi dokumenteeritud Apache Spark raamistikku, mis võimaldab rääkida praktiliselt sama täitmise kiirusest. Apache Spark töötab suurepäraselt HDFS-failisüsteemis, mis võimaldab selle seadistamist Hadoopi serverites.
Lisame siia Hadoopi ja Sparki dokumentatsiooni ja valmislahenduste mahu võrreldes Google Cloud Dataflow'ga ning tööriista valik muutub ilmseks. Veelgi enam, insenerid saavad ise otsustada, millist koodi - Hadoopi või Sparki - nad peavad täitma, lähtudes ülesandest, kogemusest ja kvalifikatsioonist.
Pilv või kohalik server
Pilve kõikehõlmavaks üleminekuks on tekkinud isegi selline huvitav mõisted nagu Hadoop-as-a-service. Sellises stsenaariumis on serverite haldamine muutunud äärmiselt oluliseks. Kahjuks, hoolimata oma populaarsusest, on puhas Hadoop üsna keeruline seadistada, kuna palju tuleb teha käsitsi. Näiteks serverite eraldi konfigureerimine, nende näitajate jälgimine, erinevate parameetrite ettevaatlik seadistamine. Ühesõnaga, see on amatööride töö ja on suur oht, et kuskil tehakse viga või midagi jäetakse tähelepanuta.
Seetõttu on populaarsust kogunud erinevad distributsioonid, mis on algselt varustatud mugavate juurutamise ja haldamise vahenditega. Üks kõige populaarsemaid distributsioone, mis toetavad Spark’i ja muudavad kõike lihtsamaks, on Cloudera. Sellel on nii tasuline kui ka tasuta versioon — ja tasuta versioonis on kogu peamine funktsionaalsus saadaval, ilma sõlmede arvu piiranguta.

Cloudera Manager seondub teie serveritega SSH kaudu seadistamise ajal. Huvitav detail: paigaldamisel on parem märkida, et see toimuks nn parsellid: spetsiaalsete pakettidega, milles on kõik vajalikud komponendid, mis on omavahel töötamiseks seadistatud. Sisuliselt on see täiustatud versioon pakettide haldurist.
Pärast installimist saame klastrite halduskeskkonna, kust on võimalik näha klastrite telemeetriat, paigaldatud teenuseid ning saate lisada/maha võtta ressursse ja muuta klastrite konfiguratsiooni.
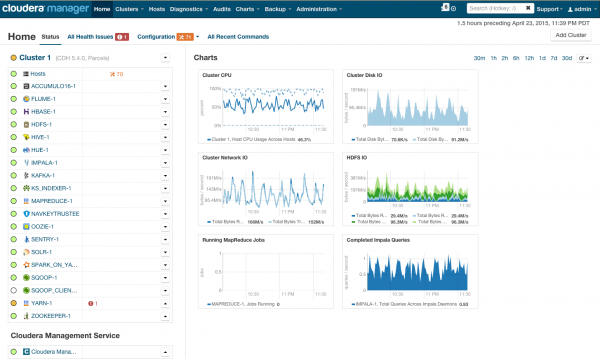
Tulemuseks on teie ees raketi salong, mis viib teid BigData säravasse tulevikku. Kuid enne, kui ütlete „minema”, võtame lähemalt pilgu kaanelt.
Riistvaranõuded
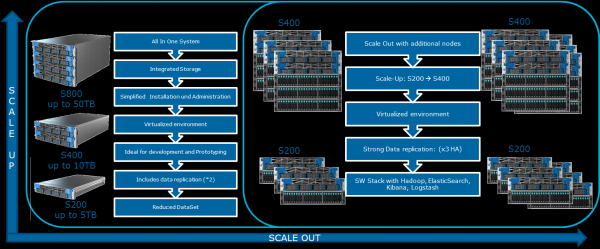
Oma veebisaidil mainib Cloudera erinevaid võimalikke konfiguratsioone. Üldised põhimõtted, mille alusel need koostatakse, on illustratsioonil:
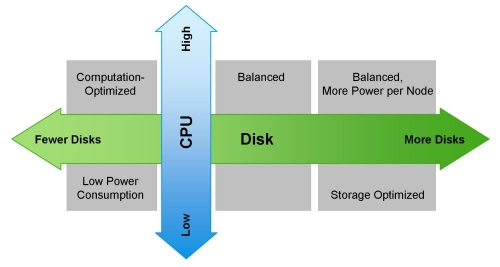
Seda optimistlikku pilti võib rikkuda MapReduce. Kui vaadata uuesti eelnevas jaotises esitatud skeemi, muutub selgeks, et peaaegu kõigil juhtudel võib MapReduce'i ülesanne kohtuda 'kitsaskoha' probleemiga andmete lugemisel kettalt või võrgust. Seda on märgitud ka Cloudera blogis. Seetõttu on igasuguste kiirete arvutuste, sealhulgas Spark'i kaudu, mis on sageli kasutusel reaalajas arvutustes, sisend/väljund kiirus ülioluline. Seega on Hadoop-i kasutamisel väga oluline, et klastrisse jõuavad tasakaalustatud ja kiired masinad, mis, pehmelt öeldes, ei pruugi alati pilvetehnoloogias tagatud olla.
Koormuse tasakaalu saavutatakse Openstack virtualiseerimise abil võimsates mitme tuumaga protsessoritega serverites. Andmepunktidele on eraldatud oma protsessorivõimsus ja kindlad kettad. Meie lahenduses Atos Codex Data Lake Engine saavutatakse ulatuslik virtualiseerimine, mille tõttu võidame nii jõudluses (minimeeritakse võrgu infrastruktuuri mõju) kui ka TCO-s (välistatakse liigsed füüsilised serverid).
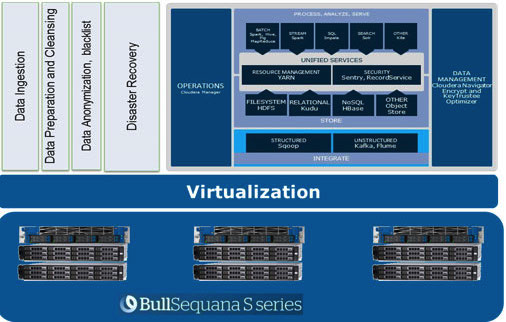
BullSequana S200 serverite kasutamisel saavutame väga ühtlase koormuse, ilma kitsaskohtade osaluseta. Minimummoodul sisaldab 3 BullSequana S200 serverit, kummaski kahe JBOD-iga, lisaks on valikuliselt võimalik ühendada täiendavaid S200 servereid, milles on neli andmemoodulit. Siin on koormuse näide TeraGen testis:
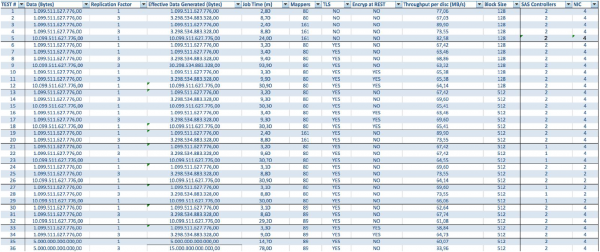
Erinevate andmete mahtude ja replikatsiooni väärtustega testid näitavad koormuse jaotuse osas klastrite sõlmede vahel ühtlaseid tulemusi. Allpool on diskreetsete testide tulemustele tuginev graafik andmesalvestuse juurdepääsu jaotusest.
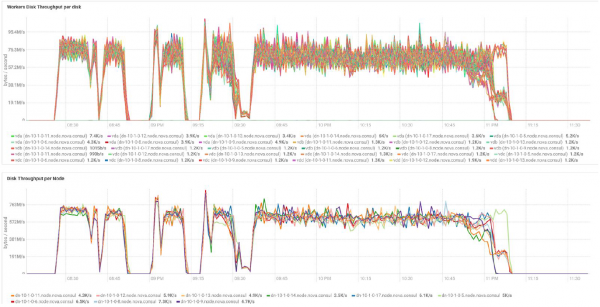
Arvutused on tehtud 3 BullSequana S200 serverist koosneva minimaalse konfigureerimise põhjal. See sisaldab 9 andmemoodulit ja 3 peamoodulit, samuti reserveeritud virtuaalmasinaid OpenStack Virtualization põhjaliku kaitse rakendamise juhtudeks. TeraSort testi tulemus: ploki suurus 512 MB kolmekordse replikatsiooni koefitsiendiga salastatuna on 23,1 min.
Kuidas saab süsteemi laiendada? Data Lake Engine'i jaoks on saadaval mitmesugused laiendused:
- Andmeedastusmoodulid: iga 40 TB kasuliku ruumi kohta
- Analüüsimoodulid, millega on võimalik paigaldada graafikaprotsessor
- Muud võimalused, olenevalt ettevõtte vajadustest (näiteks, kui on vajalik Kafka jne)
Atos Codex Data Lake Engine'i kompleks koosneb nii serveritest kui ka eelinstallitud tarkvarast, mis hõlmab Cloudera litsentsiga komplekti; ise Hadoop, OpenStack RedHat Enterprise Linuxi põhiste virtuaalmasinatega, andmete replikatsiooni ja varundamise süsteemid (sealhulgas varundamisnode ja Cloudera BDR — varukoopia ja katastroofide taastamise lahendus). Atos Codex Data Lake Engine oli esimene virtualiseerimist kasutav lahendus, mis sai sertifitseeritud .
Kui olete huvitatud üksikasjadest, vastame me rõõmuga teie küsimustele kommentaarides.
Allikas: habr.com
